
L'IA prédictive (ou analytique) est un ensemble d'algorithmes qui vous aident à comprendre les données existantes et à prédire ce qui est susceptible de se produire ensuite. En s'appuyant sur des tendances historiques, les modèles d'IA prédictive apprennent différentes tâches analytiques qui aident les utilisateurs à comprendre leurs données :
- Classification : regroupez les éléments dans des catégories prédéfinies en fonction des tendances dans les données. Par exemple, une boutique en ligne peut classer les visiteurs par intention (recherche, achat, retours) afin d'adapter ses recommandations en conséquence.
- Régression : prédisez des valeurs numériques, comme le taux d'engagement, la durée de session ou la probabilité de conversion.
- Recommandation : suggérer les articles les plus pertinents pour un utilisateur ou un contexte donné. Pensez à la section "Les utilisateurs comme vous ont aussi consulté" ou "Tutoriels recommandés en fonction de votre progression".
- Prévision et détection des anomalies : le modèle prédit les événements futurs, comme un pic de trafic, ou identifie les comportements inhabituels, comme les anomalies de paiement ou la fraude.
Certains produits sont entièrement basés sur l'IA prédictive, comme les outils de découverte musicale. Dans d'autres, l'IA prédictive améliore une expérience déterministe, comme un site Web de streaming avec des recommandations personnalisées. L'IA prédictive peut également être un puissant catalyseur interne : vous pouvez l'utiliser pour analyser les données produit et utilisateur afin d'obtenir des insights et de guider les prochaines actions de manière plus intelligente.
Boucle d'IA prédictive
Le développement d'un système d'IA prédictive suit un cycle itératif : définissez votre opportunité, préparez vos données, entraînez le modèle, évaluez le modèle et déployez le modèle.
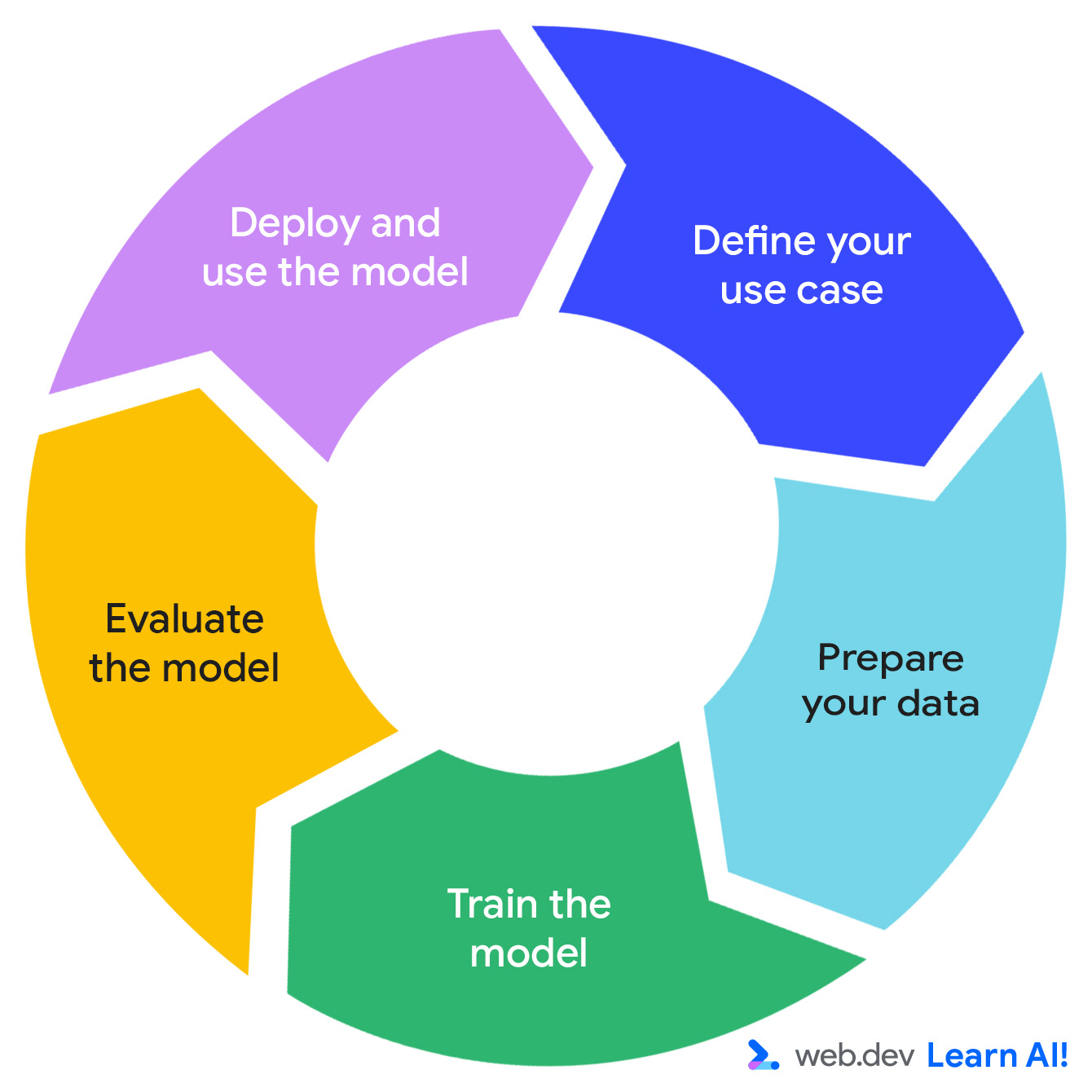
Imaginez que vous travaillez sur une application de productivité par abonnement, Do All The Things. Vous collectez déjà des données d'utilisation telles que les pages vues, la durée des sessions, l'utilisation des fonctionnalités et les renouvellements d'abonnement. Vous souhaitez à présent extraire davantage de valeur exploitable des données. Voici comment parcourir la boucle de l'IA prédictive.
Définir votre cas d'utilisation

{kind=link}
Votre taux de désabonnement a augmenté au cours des trois derniers mois. Au lieu de réagir après la résiliation d'un utilisateur, vous souhaitez utiliser l'IA prédictive pour identifier les utilisateurs susceptibles de résilier leur abonnement avant qu'ils ne le fassent. L'objectif est d'aider votre équipe chargée du succès client en lui fournissant des signaux précoces. Elle pourra ainsi prendre des mesures ciblées et proactives pour fidéliser les utilisateurs à risque.
Lorsque vous définissez un cas d'utilisation de l'IA prédictive, commencez par vérifier que la question peut être résolue à l'aide de données. Il peut s'agir de données que vous avez déjà collectées ou de données que vous pourriez collecter à l'avenir. Cette étape nécessite souvent de collaborer avec des experts du domaine, tels que les équipes chargées du succès client, de la croissance ou du marketing, pour s'assurer que la prédiction est à la fois pertinente et exploitable.
Une définition solide du problème doit spécifier :
- Objectif : quel résultat commercial souhaitez-vous influencer ? Par exemple, vous souhaitez réduire le taux de désabonnement en activant la prise de contact proactive.
- Données d'entrée : à partir de quels signaux historiques le modèle apprend-il ? Par exemple, vous fournissez des modèles d'utilisation, des types de forfaits et des interactions d'assistance.
- Sortie : qu'est-ce que le modèle va produire ? Par exemple, vous souhaitez que le modèle crée un score de probabilité de perte pour chaque utilisateur.
- Utilisateur : qui utilise la prédiction ou agit en fonction de celle-ci ? Par exemple, ces données sont destinées aux responsables de la réussite des clients.
- Critères de réussite : comment mesurez-vous l'impact ? Par exemple, vous mesurez le taux de fidélisation pour déterminer si vous avez réduit le taux de désabonnement.
En identifiant ces détails au début, vous pouvez éviter un piège courant : créer un modèle personnalisé techniquement solide, mais qui n'est jamais utilisé.
Préparer les données
Pour fournir à votre modèle des signaux d'apprentissage utiles, vous devez étiqueter vos données historiques avec des prédictions idéales. Marquez les utilisateurs du libellé Do All The Things comme "désabonnés" ou "non désabonnés".
Ensuite, collaborez avec votre équipe chargée de la réussite client pour identifier les caractéristiques comportementales les plus pertinentes pour la prédiction du taux de désabonnement. Limitez votre ensemble de données à ces caractéristiques clés et supprimez les champs inutiles afin que votre modèle n'ait pas à gérer le bruit. N'oubliez pas de tenir compte de la confidentialité des données. Supprimez les informations permettant d'identifier personnellement l'utilisateur (PII), comme les noms ou les adresses e-mail, et ne stockez que les données comportementales agrégées.
Le tableau suivant présente un extrait de l'ensemble de données obtenu :
user_id |
plan_type |
avg_session_time (min) |
logins_last_30d |
features_used |
support_tickets |
churned |
| 00123 | premium | 12.4 | 22 | 5 | 0 | 0 |
| 00124 | de 6 mois | 5,8 | 3 | 1 | 2 | 1 |
| 00125 | zéros frais | 18.1 | 30 | 7 | 0 | 0 |
| 00126 | premium | 9,7 | 12 | 4 | 1 | 0 |
| 00127 | de 6 mois | 4.2 | 2 | 1 | 3 | 1 |
Votre modèle reçoit ainsi des entrées numériques et catégorielles propres (telles que plan_type ou avg_session_time) et un libellé cible clair (churned). Les catégories doivent être converties en identifiants numériques uniques.
Enfin, divisez votre ensemble de données en trois sous-ensembles :
- Ensemble d'entraînement (généralement entre 70 % et 80 %) pour entraîner le modèle.
- Ensemble de validation (parfois appelé ensemble de développement) pour ajuster les hyperparamètres et éviter le surapprentissage.
- Ensemble de test pour évaluer les performances du modèle sur des données totalement inconnues.
Cela aide votre modèle à généraliser les décisions au lieu de s'appuyer sur des exemples historiques mémorisés.
Entraîner le modèle
Contrairement à l'IA générative, qui repose souvent sur de grands modèles pré-entraînés, la plupart des systèmes d'IA prédictive s'appuient sur des modèles auto-entraînés. En effet, les tâches prédictives sont très spécifiques à votre produit et à vos utilisateurs. Des outils tels que scikit-learn (Python), AutoML (sans code ou avec peu de code) ou TensorFlow.js (JavaScript) facilitent l'entraînement et l'évaluation des modèles prédictifs sans se soucier des mathématiques sous-jacentes.
Dans notre exemple de perte de clients, nous fournissons l'ensemble d'entraînement nettoyé à un algorithme de classification supervisé, tel que la régression logistique ou un réseau de neurones. Essayez plusieurs options pour déterminer celle qui convient le mieux à vos données.
Votre modèle apprend les schémas de comportement corrélés au churn. À la fin, il peut attribuer un score de probabilité à chaque utilisateur. Par exemple, il existe un risque de 72 % que l'utilisateur X résilie son abonnement le mois prochain.
Après chaque itération d'entraînement, évaluez le modèle obtenu à l'aide de l'ensemble de validation. Les performances d'un modèle peuvent être améliorées en ajustant les hyperparamètres, mais aussi en apportant des améliorations ciblées à votre ensemble de données.
Évaluer le modèle
Les libellés de votre ensemble de données fournissent la vérité terrain à laquelle vous pouvez comparer les sorties du modèle. Voici les métriques clés à suivre :
- Précision : sur tous les utilisateurs signalés comme "ayant résilié", combien ont réellement résilié ?
- Rappel : parmi tous les utilisateurs qui ont résilié leur abonnement, combien ont été identifiés par le modèle ?
- Score F1 : nombre unique qui équilibre la précision et le rappel. Il est utile lorsque vous souhaitez obtenir une mesure globale de la précision sans sur-optimiser l'une au détriment de l'autre.
Trop de faux positifs entraînent un gaspillage des efforts de fidélisation, tandis que trop de faux négatifs entraînent une perte de clients. Le bon compromis dépend des priorités de votre entreprise. Par exemple, votre entreprise peut préférer gérer quelques faux positifs si cela lui permet de toucher plus d'utilisateurs avant qu'ils ne partent.
Déployer et gérer le modèle
Une fois validé, vous pouvez déployer le modèle avec une API ou en tant que service léger côté client intégré à votre tableau de bord d'analyse. Chaque jour, il peut attribuer un score aux utilisateurs et mettre à jour une visualisation du risque de désabonnement, ce qui permet à votre équipe de prioriser les actions de sensibilisation. Pour qu'il reste précis et fiable, adoptez les leçons suivantes des équipes d'opérations de machine learning (MLOps) :
- Surveiller la dérive des données : détectez les changements de comportement des utilisateurs et les cas où vos données d'entraînement ne représentent plus la réalité.
- Par exemple, après le lancement d'une refonte majeure de l'UI, les utilisateurs interagissent différemment avec les fonctionnalités, ce qui rend les prédictions de churn moins précises.
- Apprenez de vos erreurs : identifiez les schémas courants à l'origine des prédictions incorrectes et ajoutez des exemples ciblés pour améliorer le prochain cycle d'entraînement.
- Par exemple, le modèle signale fréquemment les utilisateurs expérimentés comme présentant un risque de désabonnement, car ils ouvrent de nombreux tickets d'assistance. Après examen, vous ajoutez de nouvelles fonctionnalités qui distinguent le dépannage du désengagement.
- Réentraînez régulièrement : même si les performances semblent stables, actualisez le modèle régulièrement pour tenir compte des tendances saisonnières, des mises à jour des produits ou des changements de prix.
- Par exemple, vous réentraînez le modèle après avoir introduit des forfaits annuels, car la structure tarifaire modifie le comportement des utilisateurs avant le renouvellement.
Ce cycle de vie est le pilier de l'IA prédictive. Grâce à des outils tels que MLflow et Weights & Biases, vous pouvez exécuter ce processus sans expertise approfondie en ML.
Problèmes courants et solutions
Bien que des erreurs occasionnelles se produisent, vous pouvez vous prémunir contre les causes premières courantes qui peuvent nuire aux performances et à la confiance des utilisateurs :
- Données de mauvaise qualité : si vos données d'entrée sont bruyantes ou incomplètes, vos prédictions le seront également. Pour atténuer ce problème, visualisez et validez vos données avant l'entraînement. Assurez-vous de disposer des signaux d'apprentissage requis et de gérer les valeurs manquantes. Surveillez la qualité des données en production.
Surapprentissage : le modèle donne de très bons résultats avec les données d'entraînement, mais échoue dans de nouveaux cas. Pour l'éviter, utilisez la validation croisée, la régularisation et les ensembles de données de validation. Cela aide votre modèle à généraliser au-delà des exemples d'entraînement.
Dérive des données : le comportement et les environnements des utilisateurs changent, mais pas votre modèle. Pour atténuer ce problème, planifiez un réentraînement et ajoutez une surveillance pour détecter quand la précision commence à diminuer.
Métriques incorrectes : la précision globale ne reflète pas toujours les priorités de vos utilisateurs. Par exemple, le "coût" d'une erreur spécifique peut parfois être plus important. Dans la détection des fraudes, il est bien pire de manquer un cas de fraude (faux négatif) que de signaler un cas innocent (faux positif). Pour atténuer ce problème, alignez les métriques sur les objectifs réels de détection des fraudes.
La plupart de ces problèmes ne sont pas fatals. Lancez votre système progressivement et résolvez les problèmes au fur et à mesure.
L'observabilité est la clé de cette approche agile et flexible. Versionnez vos modèles, enregistrez les caractéristiques de précision et les outils utilisés pour créer le modèle, suivez les performances au fil du temps et maintenez la surveillance active. Lorsque quelque chose dérive ou se casse, vous pouvez détecter et résoudre le problème avant que les utilisateurs ne le remarquent.
Vos points à retenir
L'IA prédictive transforme vos données existantes en prévisions, en révélant ce qui est susceptible de se produire ensuite et où agir. Il s'agit de la forme d'IA la plus concrète et la plus mesurable. Concentrez-vous sur des problèmes bien définis qui peuvent être exprimés dans les données, continuez à itérer à mesure que votre produit évolue et surveillez les performances au fil du temps.
Dans le prochain module, vous découvrirez l'IA générative, qui vous aide à créer quelque chose de nouveau à partir des données disponibles.
Ressources
Si vous souhaitez comprendre les mathématiques qui sous-tendent l'IA prédictive, nous vous recommandons de consulter les ressources suivantes :
- Cours intensifs sur le machine learning concernant la classification, la régression linéaire et la régression logistique.
- L'auteur de votre cours, Janna Lipenkova, a écrit un article sur l'IA prédictive dans le chapitre 4 de The Art of AI Product Development: Delivering Business Value.
- Artificial Intelligence: A Modern Approach de Stuart Jonathan Russell et Peter Norvig. Ce livre a été publié pour la première fois en 1995 et sa dernière édition date de 2021. Il est couramment enseigné dans les programmes d'ingénierie de l'IA.
- Pattern Recognition and Machine Learning de Christopher M. Bishop, pour une approche très complète et académique de l'apprentissage de l'IA prédictive.
Vérifier que vous avez bien compris
Quelle est la fonction principale de l'IA prédictive ?
Quelle tâche consiste à regrouper des éléments dans des catégories prédéfinies en fonction de modèles ?
Dans la boucle d'IA prédictive, pourquoi devez-vous diviser votre ensemble de données en ensembles d'entraînement, de validation et de test ?
Quelle métrique équilibre la précision et le rappel pour fournir une mesure globale de l'exactitude ?
Qu'est-ce que la dérive des données et comment l'atténuer ?