
了解如何针对 Time to First Byte 指标进行优化。


发布时间:2023 年 1 月 19 日;最后更新时间:2025 年 11 月 28 日
Time to First Byte (TTFB) 是一项基础的 Web 效果指标,它先于所有其他有意义的用户体验指标,例如 First Contentful Paint (FCP) 和 Largest Contentful Paint (LCP)。这意味着,较高的 TTFB 值会增加后续指标的时间。
建议您的服务器能够足够快速地响应导航请求,以便 75% 的用户体验到 “良好”阈值范围内的 FCP。作为大致的参考,大多数网站应力求将 TTFB 控制在 0.8 秒或更短的时间内。

如何衡量 TTFB
在优化 TTFB 之前,您需要了解它对网站用户的影响。您应将实地数据作为观察 TTFB 的主要来源,因为实地数据会受到重定向的影响,而基于实验室的工具通常使用最终网址进行衡量,因此会忽略这种额外的延迟。
PageSpeed Insights 是一种获取 Chrome 用户体验报告中提供的公开网站的实测数据和实验数据的途径。
真实用户的 TTFB 显示在顶部的了解真实用户的体验部分中:

对于实验数据,TTFB 问题会显示在文档请求延迟时间数据分析中:

如需了解在实地和实验室内衡量 TTFB 的更多方法,请参阅 TTFB 指标页面。
了解实地 TTFB 与实验室 TTFB 之间的差异
实验室内 TTFB 和实际 TTFB 可能因多种原因而有所不同。如果两者确实不同,请务必了解原因,以便有效利用实验室数据来改善用户体验。
如果实验室 TTFB 远大于实际 TTFB,则表明实验室环境比典型用户体验更受限。这不一定是个问题,因为实验室结果和建议仍然有效,但可能会夸大影响和改进。
如果字段 TTFB 远大于实验 TTFB,则表示存在实验室运行中不明显的问题,例如使用服务器端缓存、重定向或网络差异。在这种情况下,实验结果和建议可能不太有用,因为它们遗漏了一个主要问题。
如需了解服务器端缓存是否会影响实验室 TTFB,请尝试测试不太常见的网页或使用不同的网址参数来获取未缓存的内容,看看 TTFB 是否更符合实际 TTFB。能够使用特定网址参数绕过服务器端缓存也很有用。请参阅缓存内容部分。
对于重定向和网络差异,分析流量如何到达我们的网站以及流量的来源有助于诊断这些是否是潜在问题。
使用 Server-Timing 调试现场的高 TTFB
您可以在应用后端使用 Server-Timing 响应标头来衡量可能导致高延迟的不同后端进程。标头值的结构非常灵活,至少可以接受您定义的句柄。可选值包括时长值(通过 dur 提供)以及可选的直观易懂的说明(通过 desc 提供)。
Serving-Timing 可用于衡量许多应用后端进程,但您可能需要特别注意以下进程:
- 数据库查询
- 服务器端渲染时间(如果适用)
- 磁盘寻道
- 边缘服务器缓存命中或未命中(如果使用 CDN)
Server-Timing 条目的所有部分都以英文冒号分隔,多个条目可以以英文逗号分隔:
// Two metrics with descriptions and values
Server-Timing: db;desc="Database";dur=121.3, ssr;desc="Server-side Rendering";dur=212.2
您可以使用所选的应用后端语言来设置标头。例如,在 PHP 中,您可以按如下方式设置标头:
<?php
// Get a high-resolution timestamp before
// the database query is performed:
$dbReadStartTime = hrtime(true);
// Perform a database query and get results...
// ...
// Get a high-resolution timestamp after
// the database query is performed:
$dbReadEndTime = hrtime(true);
// Get the total time, converting nanoseconds to
// milliseconds (or whatever granularity you need):
$dbReadTotalTime = ($dbReadEndTime - $dbReadStartTime) / 1e+6;
// Set the Server-Timing header:
header('Server-Timing: db;desc="Database";dur=' . $dbReadTotalTime);
?>
在该字段中,任何设置了 Server-Timing 响应标头的网页都会在 Navigation Timing API 中填充 serverTiming 属性:
// Get the serverTiming entry for the first navigation request:
performance.getEntries('navigation')[0].serverTiming.forEach(entry => {
// Log the server timing data:
console.log(entry.name, entry.description, entry.duration);
});
在实验中,来自 Server-Timing 响应标头的数据会显示在 Chrome 开发者工具的网络标签页的时间轴面板中:

在此示例中,Server-Timing 用于衡量资源请求是否命中 CDN 缓存,以及请求命中 CDN 边缘服务器和源服务器所需的时间。
服务器计时也会显示在 Chrome 开发者工具的性能面板的网络轨道中:
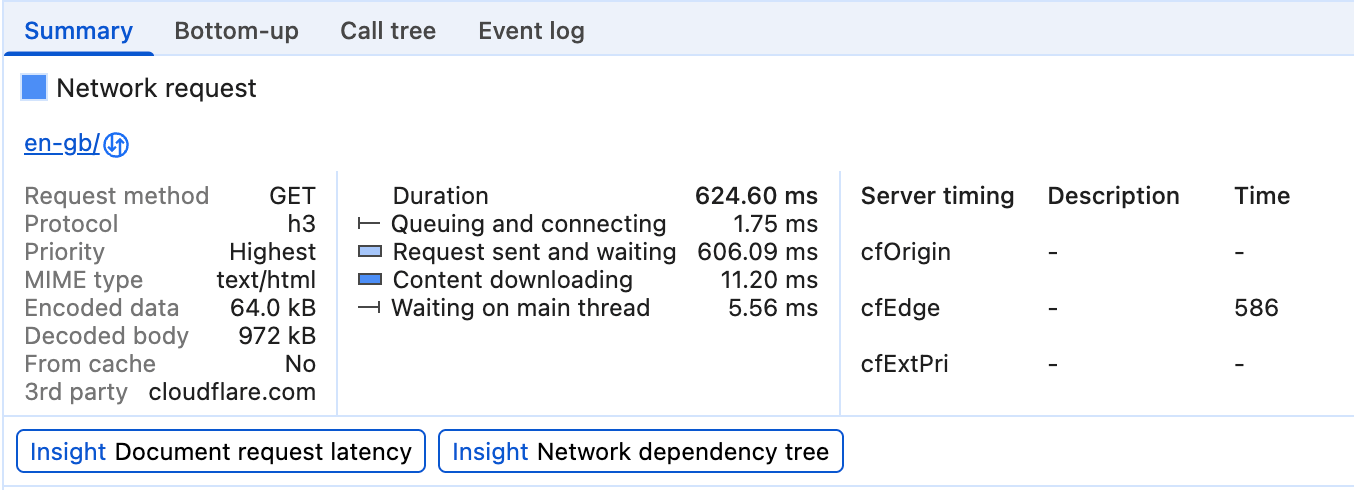
通过分析现有数据确定 TTFB 存在问题后,您就可以着手解决问题了。
优化 TTFB 的方法
优化 TTFB 最具挑战性的方面在于,虽然 Web 的前端堆栈始终是 HTML、CSS 和 JavaScript,但后端堆栈可能会有很大差异。有许多后端堆栈和数据库产品,每种都有自己的优化技术。因此,本指南侧重于适用于大多数架构的内容,而不是仅侧重于特定于堆栈的指南。
针对具体平台的指南
您用于网站的平台可能会对 TTFB 产生很大影响。例如,WordPress 性能会受到插件数量和质量或所用主题的影响。当平台经过自定义时,其他平台也会受到类似的影响。您应查阅平台文档,获取特定于供应商的建议,以补充本文中更通用的性能建议。Lighthouse 洞见还包含一些有限的特定于堆栈的指南。
托管、托管、托管
在考虑其他优化方法之前,您应首先考虑托管。我们无法在此提供太多具体指导,但一般而言,请确保您的网站主机能够处理您发送给它的流量。
共享托管通常速度较慢。如果您运营的是主要用于传送静态文件的小型个人网站,这可能没问题。使用以下一些优化技术有助于尽可能缩短 TTFB。
不过,如果您运行的是涉及个性化、数据库查询和其他密集型服务器端操作的大型应用,那么选择合适的托管服务对于降低实际 TTFB 至关重要。
选择托管服务提供商时,请注意以下几点:
- 为应用实例分配了多少内存?如果您的应用内存不足,则会频繁换页,并尽力以最快的速度提供网页。
- 您的托管服务提供商是否会及时更新后端堆栈?随着应用后端语言、HTTP 实现和数据库软件的新版本发布,相应软件的性能会随着时间的推移而得到提升。因此,与优先考虑此类关键维护的托管服务提供商合作至关重要。
- 如果您有非常具体的应用要求,并且希望获得对服务器配置文件的最低级别访问权限,请咨询是否可以自定义您自己的应用实例的后端。
许多托管服务提供商会为您处理这些事宜,但如果您发现即使是专用托管服务提供商也出现了较长的 TTFB 值,则可能表明您需要重新评估当前托管服务提供商的功能,以便提供尽可能出色的用户体验。
使用内容分发网络 (CDN)
CDN 使用情况是一个老生常谈的话题,但这是有充分理由的:您可能拥有经过高度优化的应用后端,但距离源服务器较远的用户在实际使用中仍可能会遇到较高的 TTFB。
CDN 通过使用分布式服务器网络来解决用户距离源服务器较远的问题,该网络会在距离用户较近的服务器上缓存资源。这些服务器称为“边缘服务器”。
CDN 提供商还可能提供边缘服务器以外的优势:
- CDN 提供商通常提供极快的 DNS 解析时间。
- CDN 可能会使用 HTTP/2 或 HTTP/3 等现代协议从边缘服务器提供您的内容。
- HTTP/3 特别通过使用 UDP 协议解决了 TCP(HTTP/2 依赖于此协议)中存在的队首阻塞问题。
- CDN 可能提供新版 TLS,从而缩短 TLS 协商时间,降低延迟时间。尤其是 TLS 1.3,旨在尽可能缩短 TLS 协商时间。
- 部分 CDN 提供商提供了一项通常称为“边缘工作器”的功能,该功能使用类似于 Service Worker API 的 API 来拦截请求、以编程方式管理边缘缓存中的响应,或完全重写响应。
- CDN 提供商非常擅长优化压缩。自行正确实现压缩功能非常困难,并且在某些情况下,如果动态生成的标记必须实时压缩,可能会导致响应时间变慢。
- 此外,CDN 提供商还会自动缓存静态资源的压缩响应,从而实现压缩比和响应时间的最佳组合。
虽然采用 CDN 所需的工作量各不相同(从微不足道到非常大),但如果您的网站尚未使用 CDN,那么在优化 TTFB 时,应优先考虑采用 CDN。
尽可能使用缓存的内容
如果内容配置了适当的 Cache-Control HTTP 标头,CDN 允许在更靠近访问者的边缘服务器上缓存内容。虽然这不适合个性化内容,但要求每次都返回源服务器会大大降低 CDN 的价值。
对于经常更新内容的网站,即使缓存时间很短,也能显著提升繁忙网站的性能,因为只有该时间段内的第一位访问者会体验到源服务器的完整延迟,而所有其他访问者都可以重复使用来自边缘服务器的缓存资源。某些 CDN 允许在网站发布时进行缓存失效,从而兼具长缓存时间和即时更新的优点。
即使缓存配置正确,也可以通过使用唯一的查询字符串参数进行分析衡量来忽略此问题。尽管内容相同,但对于 CDN 而言,这些内容可能看起来不同,因此系统不会使用缓存版本。
较旧或访问次数较少的内容也可能不会被缓存,这可能会导致某些网页的 TTFB 值高于其他网页。增加缓存时间可以减少此影响,但请注意,缓存时间越长,提供过时内容的可能性就越大。
缓存内容的影响不仅限于使用 CDN 的用户。当无法重复使用缓存内容时,服务器基础架构可能需要通过代价高昂的数据库查找来生成内容。经常访问的数据或预缓存的网页通常可以获得更好的效果。
避免多次网页重定向
导致 TTFB 较高的一个常见原因是重定向。当针对文档的导航请求收到告知浏览器资源位于其他位置的响应时,就会发生重定向。一次重定向肯定会给导航请求增加不必要的延迟,但如果该重定向指向导致另一次重定向的另一个资源,情况肯定会更糟,依此类推。这可能会对通过广告或简报获得大量访问者的网站产生特别的影响,因为这些网站通常会通过分析服务进行重定向以进行衡量。消除您可直接控制的重定向有助于实现良好的 TTFB。
重定向分为两种类型:
- 同源重定向,即重定向完全在您的网站上进行。
- 跨源重定向,即重定向最初发生在其他来源(例如,来自社交媒体网址缩短服务),然后才到达您的网站。
重点在于消除同源重定向,因为这是您可以直接控制的。这需要检查您网站上的链接,看看是否有任何链接导致 302 或 301 响应代码。通常,这可能是因为未包含 https:// 方案(因此浏览器默认使用 http://,然后重定向),或者因为网址中未正确包含或排除末尾斜线。
跨源重定向比较棘手,因为这些重定向通常不受您的控制,但请尽可能避免多次重定向,例如在分享链接时避免使用多个链接缩短服务。确保提供给广告客户或简报的网址是正确的最终到达网址,以免在这些服务使用的重定向网址中再添加一个重定向网址。
重定向时间的另一个重要来源可能是 HTTP 到 HTTPS 的重定向。一种解决方法是使用 Strict-Transport-Security 标头 (HSTS),该标头会在首次访问源时强制使用 HTTPS,然后告知浏览器在日后访问时立即通过 HTTPS 方案访问该源。
在制定了完善的 HSTS 政策后,您可以将您的网站添加到 HSTS 预加载列表,从而加快用户首次访问来源的速度。
将标记流式传输到浏览器
浏览器经过优化,可在标记以流式传输时高效处理标记,这意味着标记会以块的形式从服务器到达,并被相应处理。这对于大型标记载荷至关重要,因为这意味着浏览器可以逐步解析标记块,而不是等待整个响应到达后再开始解析。
虽然浏览器非常擅长处理流式标记,但务必要尽一切努力保持该流的畅通,以便尽快发送这些初始标记位。如果后端拖慢了速度,那就是问题所在。由于后端堆栈数量众多,因此本指南无法涵盖每个堆栈以及每个特定堆栈中可能出现的问题。
例如,React 和其他可以按需在服务器上呈现标记的框架一直以来都采用同步方法进行服务器端呈现。不过,新版 React 已实现用于在渲染时流式传输标记的服务器方法。这意味着,您不必等待 React 服务器 API 方法呈现整个响应,然后再发送该响应。
确保标记快速流式传输到浏览器的另一种方法是依赖于在构建时间生成 HTML 文件的静态渲染。由于完整文件可立即使用,因此 Web 服务器可以立即开始发送文件,而 HTTP 的固有特性会导致标记以流式传输。虽然这种方法并不适合每个网站上的每个网页(例如需要动态响应才能实现良好用户体验的网页),但对于那些不需要根据特定用户进行个性化标记的网页来说,这种方法可能很有用。
使用 Service Worker
Service Worker API 可以对文档及其加载的资源的 TTFB 产生重大影响。这是因为,Service Worker 充当浏览器和服务器之间的代理,但对网站 TTFB 的影响取决于您如何设置 Service Worker,以及该设置是否符合您的应用要求。
- 为资源使用过时重验证策略。如果资源(无论是文档还是文档所需的资源)位于 service worker 缓存中,则 stale-while-revalidate 策略会先从缓存中提供该资源,然后在后台下载该资源,并从缓存中提供该资源以供日后互动。
- 如果您有不经常更改的文档资源,使用 stale-while-revalidate 策略可使网页的 TTFB 几乎达到即时效果。不过,如果您的网站发送的是动态生成的标记(例如,根据用户是否已通过身份验证而变化的标记),此方法的效果就不是很好。在这种情况下,您始终希望先访问网络,以便获取尽可能最新的文档。
- 如果您的文档加载的非关键资源会以一定频率发生变化,但提取过时的资源不会对用户体验造成太大影响(例如,某些非关键图片或其他资源),则可以使用 stale-while-revalidate 策略大幅缩短这些资源的 TTFB。
- 对于客户端渲染的应用,请使用应用 Shell 模型。此模型最适合 SPA,因为页面的“外壳”可以立即从 Service Worker 缓存中传送,而页面的动态内容会在页面生命周期的后期填充和呈现。
为渲染关键资源使用 103 Early Hints
无论您的应用后端优化得多么出色,服务器仍可能需要执行大量工作才能准备好响应,包括昂贵(但必要)的数据库工作,这会延迟导航响应的到达时间。这可能会导致一些后续的渲染关键资源(例如 CSS 或在某些情况下在客户端上渲染标记的 JavaScript)延迟加载。
103 Early Hints 标头是一种早期响应代码,当后端忙于准备标记时,服务器可以将其发送给浏览器。此标头可用于向浏览器提示,在准备标记时,网页应开始下载渲染关键资源。对于支持的浏览器,此功能可加快文档渲染速度 (CSS) 并缩短网页加载时间。
103 Early Hints 的一个缺点是,与缓存一样,它们可能会掩盖网站的“真实”TTFB。如果服务器基础架构速度较慢(无论是由于功率不足还是代码需要优化),那么在使用 103 Early Hints 时,由于 TTFB 看起来很快,因此可能不太明显。使用 103 Early Hints 的网站应考虑测量实际服务器时间(通过 PerformanceNavigationTiming API 的 Server-Timing 或 finalResponseHeadersStart)。
总结
由于后端应用堆栈的组合非常多,因此没有一篇文章可以囊括降低网站 TTFB 的所有方法。不过,您可以尝试以下方法,以加快服务器端的速度。
与优化所有其他指标一样,优化 TTFB 的方法也大致相同:在实际环境中衡量 TTFB,使用实验室工具深入分析原因,然后尽可能应用优化措施。虽然某些技巧可能不适合您的情况,但有些技巧很可能适合。与往常一样,您需要密切关注实地数据,并根据需要进行调整,以确保尽可能为用户提供最快的体验。