
L'AI predittiva (o analitica) è un insieme di algoritmi che ti aiutano a comprendere i dati esistenti e prevedere cosa accadrà probabilmente in futuro. In base ai pattern storici, i modelli di AI predittiva apprendono diverse attività di analisi che aiutano gli utenti a dare un senso ai loro dati:
- Classificazione: raggruppa gli elementi in categorie predefinite in base ai pattern nei dati. Ad esempio, un negozio online può classificare i visitatori in base all'intento (ricerca, acquisto, resi), in modo da poter adattare i propri consigli di conseguenza.
- Regressione: prevede valori numerici, ad esempio tasso di coinvolgimento, durata della sessione o probabilità di conversione.
- Consiglio: suggerisci gli articoli più pertinenti per un determinato utente o contesto. Pensa a "gli utenti come te hanno visualizzato anche" o "tutorial consigliati in base ai tuoi progressi".
- Previsione e rilevamento di anomalie: il modello prevede eventi futuri, come un picco di traffico, o identifica comportamenti insoliti, come anomalie di pagamento o frodi.
Alcuni prodotti sono basati interamente sull'AI predittiva, come gli strumenti di scoperta musicale. In altri, l'AI predittiva migliora un'esperienza deterministica, ad esempio un sito web di streaming con consigli personalizzati. L'AI predittiva può anche essere un potente strumento interno: puoi utilizzarla per analizzare i dati di prodotti e utenti per scoprire informazioni e guidare le azioni successive più intelligenti.
Il ciclo dell'AI predittiva
Lo sviluppo di un sistema di AI predittiva segue un ciclo iterativo: definisci l'opportunità, prepara i dati, addestra il modello, valuta il modello ed esegui il deployment del modello.
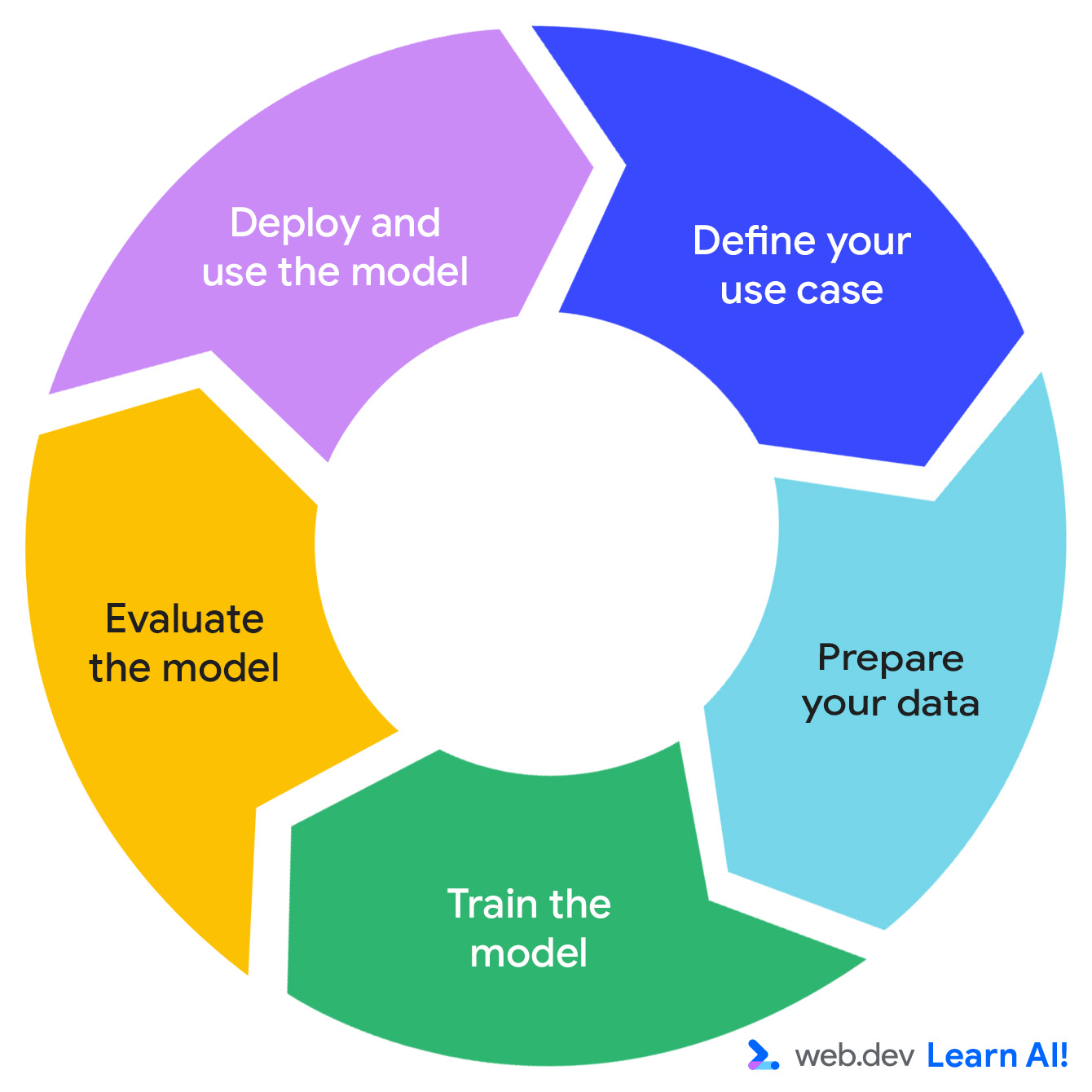
Immagina di lavorare a un'app di produttività basata su abbonamento, Do All The Things. Raccogli già dati sull'utilizzo, come visualizzazioni di pagina, durata della sessione, utilizzo delle funzionalità e rinnovi degli abbonamenti. Ora vorresti estrarre un valore più pratico dai dati. Ecco come funziona il ciclo dell'AI predittiva.
Definisci il tuo caso d'uso

{kind=link}
Il tasso di abbandono è aumentato negli ultimi tre mesi. Invece di reagire dopo l'annullamento degli utenti, vuoi utilizzare l'AI predittiva per identificare gli utenti che probabilmente abbandoneranno il servizio prima di annullare l'abbonamento. L'obiettivo è supportare il team Customer Success con indicatori tempestivi, in modo che possa intraprendere azioni mirate e proattive per fidelizzare gli utenti a rischio.
Quando definisci un caso d'uso dell'AI predittiva, inizia verificando che la domanda possa essere risolta con i dati. Possono essere dati che hai già raccolto o che potresti raccogliere in futuro. Questo passaggio spesso richiede la collaborazione con esperti del settore, come i team di customer success, crescita o marketing, per garantire che la previsione sia significativa e attuabile.
Una definizione efficace del problema deve specificare:
- Obiettivo: qual è il risultato commerciale che stai cercando di influenzare? Ad esempio, vuoi ridurre il tasso di abbandono abilitando il contatto proattivo.
- Dati di input: da quali indicatori storici apprende il modello? Ad esempio, fornisci pattern di utilizzo, tipi di piani e interazioni di assistenza.
- Output: che cosa produrrà il modello? Ad esempio, vuoi che il modello crei un punteggio di probabilità di abbandono per ogni utente.
- Utente: chi utilizza o agisce in base alla previsione? Ad esempio, questi dati sono destinati ai Customer Success Manager.
- Criteri di successo: come misuri l'impatto? Ad esempio, misuri il tasso di fidelizzazione per determinare se hai ridotto l'abbandono.
Identificando questi dettagli all'inizio, puoi evitare una trappola comune: creare un modello personalizzato tecnicamente valido, ma che non viene mai utilizzato.
Preparare i dati
Per fornire al modello segnali di apprendimento utili, devi etichettare i dati storici con le previsioni ideali. Etichetta gli utenti Do All The Things come "abbandonati" o "non abbandonati".
Successivamente, collabora con il team di customer success per identificare le funzionalità comportamentali più pertinenti per la previsione del churn. Restringi il set di dati a queste funzionalità chiave e rimuovi i campi non necessari in modo che il modello non debba gestire il rumore. Ricordati di considerare la privacy dei dati. Rimuovi le informazioni che consentono l'identificazione personale (PII), come nomi o email, e memorizza solo i dati comportamentali aggregati.
La tabella seguente mostra un estratto del set di dati risultante:
user_id |
plan_type |
avg_session_time (min) |
logins_last_30d |
features_used |
support_tickets |
churned |
| 00123 | premium | 12.4 | 22 | 5 | 0 | 0 |
| 00124 | di Google AI Pro | 5,8 | 3 | 1 | 2 | 1 |
| 00125 | Nessun costo | 18.1 | 30 | 7 | 0 | 0 |
| 00126 | premium | 9.7 | 12 | 4 | 1 | 0 |
| 00127 | di Google AI Pro | 4.2 | 2 | 1 | 3 | 1 |
In questo modo, il modello riceve input numerici e categorici puliti (ad esempio
plan_type o avg_session_time) e un'etichetta target chiara (churned).
Le categorie devono essere convertite in identificatori numerici univoci.
Infine, dividi il set di dati in tre sottoinsiemi:
- Set di addestramento (di solito circa il 70-80%) per addestrare il modello.
- Set di convalida (talvolta chiamato anche set di sviluppo) per ottimizzare gli iperparametri ed evitare l'overfitting.
- Set di test per valutare le prestazioni del modello su dati completamente sconosciuti.
In questo modo, il modello generalizza le decisioni anziché basarsi su esempi storici memorizzati.
Addestra il modello
A differenza dell'AI generativa, che spesso si basa su modelli di grandi dimensioni preaddestrati, la maggior parte dei sistemi di AI predittiva si basa su modelli autoaddestrati. Questo perché le attività predittive sono molto specifiche per il tuo prodotto e i tuoi utenti. Strumenti come scikit-learn (Python), AutoML (senza codice o con poco codice) o TensorFlow.js (JavaScript) semplificano l'addestramento e la valutazione di modelli predittivi senza preoccuparsi della matematica sottostante.
Nel nostro esempio di abbandono, inseriamo il set di addestramento pulito in un algoritmo di classificazione supervisionato, come la regressione logistica o una rete neurale. Prova più opzioni per determinare quella più adatta ai tuoi dati.
Il modello apprende quali pattern di comportamento sono correlati all'abbandono. Alla fine, può assegnare un punteggio di probabilità a ogni utente. Ad esempio, esiste un rischio del 72% che l'utente X annulli l'abbonamento il mese successivo.
Dopo ogni iterazione di addestramento, valuta il modello risultante utilizzando il set di convalida. Le prestazioni di un modello possono essere migliorate regolando gli iperparametri, ma anche apportando miglioramenti mirati al set di dati.
Valuta il modello
Le etichette nel set di dati forniscono i dati empirici reali con cui puoi confrontare gli output del modello. Le metriche chiave da monitorare sono:
- Precisione: di tutti gli utenti contrassegnati come "abbandonati", quanti lo sono effettivamente?
- Richiamo: di tutti gli utenti che hanno abbandonato, quanti sono stati rilevati dal modello?
- Punteggio F1: un singolo numero che bilancia precisione e richiamo, utile quando vuoi una misura complessiva dell'accuratezza senza ottimizzare eccessivamente una metrica a scapito dell'altra.
Troppi falsi positivi portano a sprecare gli sforzi di fidelizzazione, mentre troppi falsi negativi portano alla perdita di clienti. Il giusto compromesso dipende dalle priorità della tua attività. Ad esempio, la tua azienda potrebbe preferire gestire un paio di falsi allarmi se ciò aumenta la probabilità di intercettare più utenti prima che abbandonino.
Esegui il deployment e la manutenzione del modello
Una volta convalidato, puoi implementare il modello con un'API o come servizio lato client leggero integrato nella dashboard di analisi. Ogni giorno, può assegnare un punteggio agli utenti e aggiornare una visualizzazione del rischio di abbandono, consentendo al tuo team di dare la priorità al contatto. Per mantenerlo accurato e affidabile, adotta questi insegnamenti dei team di operazioni di machine learning (MLOps):
- Monitoraggio della deriva dei dati: rileva quando il comportamento degli utenti cambia e i dati di addestramento non rappresentano più la realtà.
- Ad esempio, dopo il lancio di una riprogettazione importante dell'interfaccia utente, gli utenti interagiscono con le funzionalità in modo diverso, il che rende le previsioni del churn meno accurate.
- Impara dagli errori: identifica i pattern comuni alla base delle previsioni errate e
aggiungi esempi mirati per migliorare il ciclo di addestramento successivo.
- Ad esempio, il modello spesso segnala gli utenti esperti come potenziali rischi di abbandono perché aprono molti ticket di assistenza. Dopo la revisione, aggiungi nuove funzionalità che distinguono la risoluzione dei problemi dal disimpegno.
- Riapprendimento regolare: anche se il rendimento sembra stabile, aggiorna il modello
periodicamente per tenere conto di pattern stagionali, aggiornamenti dei prodotti o modifiche
dei prezzi.
- Ad esempio, esegui il retraining del modello dopo aver introdotto i piani annuali, in quanto la struttura dei prezzi cambia il comportamento degli utenti prima del rinnovo.
Questo ciclo di vita è la base dell'AI predittiva. Con strumenti come MLflow e Weights & Biases, puoi eseguire questo processo senza competenze approfondite di ML.
Errori comuni e mitigazioni
Sebbene si verifichino errori occasionali, puoi proteggerti dalle cause principali comuni che possono compromettere il rendimento e la fiducia degli utenti:
- Dati di bassa qualità: se i dati di input sono rumorosi o incompleti, anche le previsioni lo saranno. Per mitigare, visualizzare e convalidare i dati prima dell'addestramento. Assicurati di disporre degli indicatori di apprendimento necessari e gestisci i valori mancanti. Monitorare la qualità dei dati in produzione.
Overfitting: il modello funziona molto bene con i dati di addestramento, ma non riesce a gestire nuovi casi. Per mitigarli, utilizza la cross-validation, la regolarizzazione e i set di dati di test. In questo modo, il modello può generalizzare oltre gli esempi di addestramento.
Deriva dei dati: il comportamento e gli ambienti degli utenti cambiano, ma il modello no. Per ridurre il problema, pianifica il riaddestramento e aggiungi il monitoraggio per rilevare quando la precisione inizia a diminuire.
Metriche errate: l'accuratezza complessiva non riflette sempre le priorità dei tuoi utenti. Ad esempio, a volte conta di più il "costo" di un errore specifico. Nel rilevamento delle frodi, mancare un caso fraudolento (falso negativo) è molto peggio che segnalarne uno innocente (falso positivo). Per mitigare, allinea le metriche agli obiettivi reali per il rilevamento delle frodi.
La maggior parte di questi problemi non è grave. Avvia il sistema gradualmente e risolvi i problemi man mano che si presentano.
La chiave di questo approccio snello e flessibile è l'osservabilità. Crea versioni dei modelli, registra le caratteristiche di precisione e gli strumenti utilizzati per creare il modello, monitora le prestazioni nel tempo e mantieni attivo il monitoraggio. Quando qualcosa va alla deriva o si rompe, potrai rilevare e risolvere il problema prima che gli utenti se ne accorgano.
I tuoi concetti principali
L'AI predittiva trasforma i tuoi dati esistenti in previsioni, rivelando cosa è probabile che accada in futuro e dove intervenire. È la forma più concreta e misurabile di AI. Concentrati su problemi ben definiti che possono essere espressi in dati, continua a iterare man mano che il prodotto si evolve e monitora il rendimento nel tempo.
Nel prossimo modulo, imparerai a conoscere l'AI generativa, che ti aiuta a creare qualcosa di nuovo in base ai dati disponibili.
Risorse
Se ti interessa capire la matematica alla base dell'AI predittiva, ti consigliamo di consultare queste risorse:
- Machine Learning Crash Courses su classificazione, regressione lineare e regressione logistica.
- L'autrice del corso, Janna Lipenkova, ha scritto di più sull'argomento dell'AI predittiva nel capitolo 4 di The Art of AI Product Development: Delivering Business Value.
- Artificial Intelligence: A Modern Approach di Stuart Jonathan Russell e Peter Norvig. Questo libro è stato pubblicato inizialmente nel 1995 e la sua edizione più recente è stata pubblicata nel 2021. Viene comunemente insegnato nei programmi di ingegneria dell'AI.
- Pattern Recognition and Machine Learning di Christopher M. Bishop, per un approccio accademico e altamente completo all'apprendimento dell'AI predittiva.
Verifica la tua comprensione
Qual è la funzione principale dell'AI predittiva?
Quale attività prevede il raggruppamento degli elementi in categorie predefinite in base a pattern?
Nel "ciclo dell'IA predittiva", perché dovresti dividere il set di dati in set di addestramento, convalida e test?
Quale metrica bilancia precisione e richiamo per fornire una misura complessiva dell'accuratezza?
Che cos'è la deriva dei dati e come deve essere mitigata?