
Prima di creare con l'AI, devi scegliere la piattaforma su cui è ospitata. La tua scelta influisce su velocità, costi, scalabilità e affidabilità del tuo sistema di AI. Puoi scegliere tra:
- AI lato client: viene eseguita direttamente nel browser. Ciò significa che i dati possono rimanere privati, sul dispositivo dell'utente, e non c'è latenza di rete. Tuttavia, per funzionare bene, l'AI lato client ha bisogno di casi d'uso altamente specifici e ben definiti.
- AI lato server: viene eseguita nel cloud. È altamente capace e scalabile, ma più costoso in termini di latenza e costi.
Ogni opzione comporta dei compromessi e la configurazione giusta dipende dal caso d'uso, dalle competenze del team e dalle risorse. Ad esempio, puoi offrire uno strumento di riepilogo che viene eseguito localmente, in modo che gli utenti possano porre domande personali senza dover gestire informazioni che consentono l'identificazione personale (PII). Tuttavia, un agente dell'assistenza clienti potrebbe fornire risposte più utili utilizzando un modello basato sul cloud che ha accesso a un ampio database di risorse.
In questo modulo imparerai a:
- Confronta i compromessi tra l'AI lato client e lato server.
- Scegli la piattaforma in base al tuo caso d'uso e alle capacità del team.
- Progetta sistemi ibridi, che offrono l'AI sul client e sul server, per crescere con il tuo prodotto.
Esamina le opzioni
Per l'implementazione, pensa alle piattaforme AI lungo due assi principali. Puoi scegliere tra:
- Dove viene eseguito il modello: viene eseguito lato client o lato server?
- Personalizzazione: quanto controllo hai sulle conoscenze e sulle funzionalità del modello? Se puoi controllare il modello, ovvero modificare i pesi del modello, puoi personalizzarne il comportamento per soddisfare i tuoi requisiti specifici.
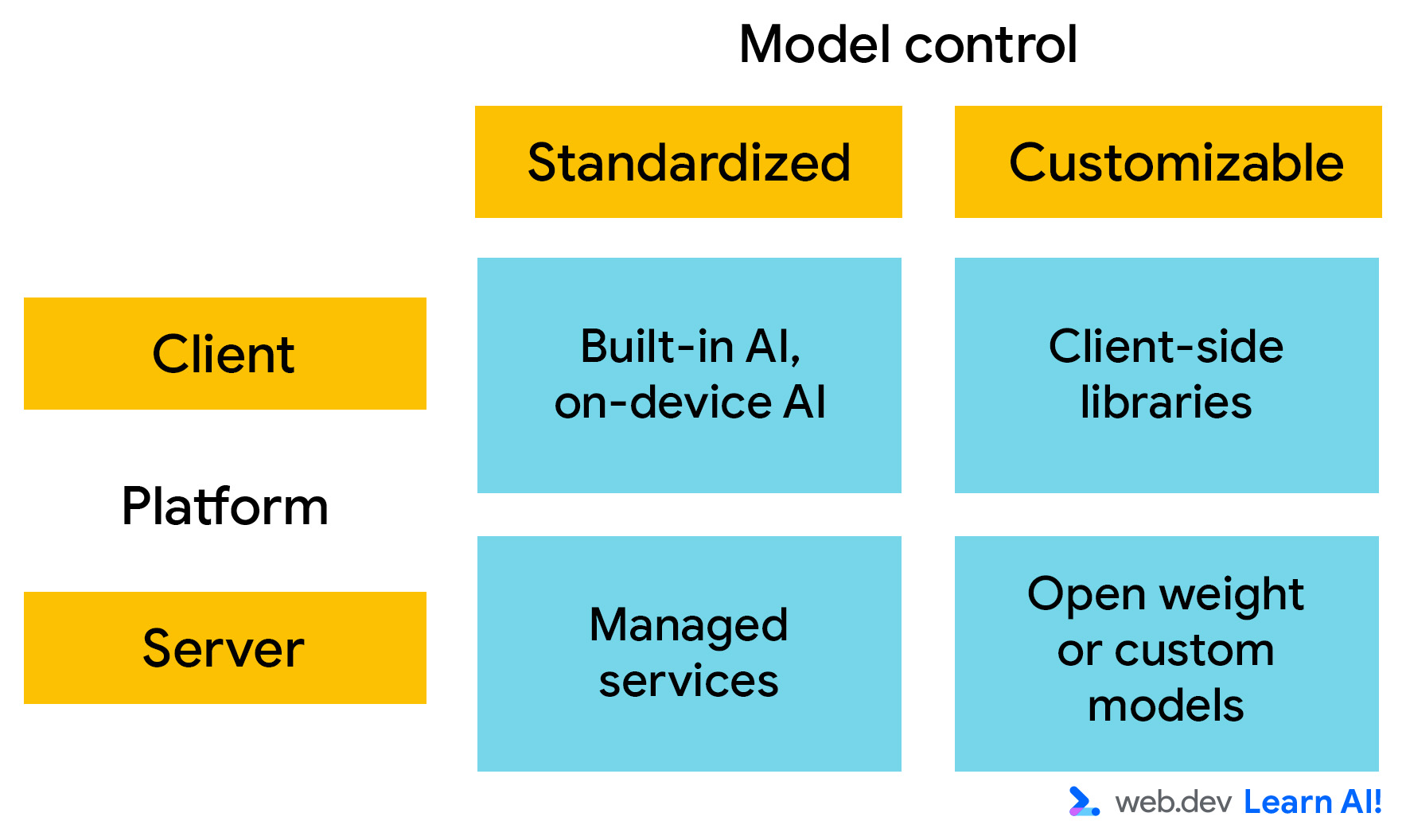
AI lato client
L'AI lato client viene eseguita nel browser e il calcolo avviene localmente sul dispositivo dell'utente. Non è necessario fornire risorse di calcolo in fase di inferenza e i dati rimangono sul computer dell'utente. In questo modo, l'esperienza è veloce, privata e adatta a esperienze interattive e leggere.
Tuttavia, i modelli lato client sono in genere piuttosto piccoli, il che può limitarne le funzionalità e le prestazioni. Sono più adatti ad attività altamente specializzate, come il rilevamento della tossicità o l'analisi del sentiment. Spesso si tratta di attività di IA predittiva con uno spazio di output limitato.
Esistono due opzioni principali:
- AI integrata: browser come Google Chrome e Microsoft Edge stanno integrando modelli di AI. Questi sono accessibili tramite chiamate JavaScript, senza necessità di configurazione o hosting. Una volta scaricato, il modello può essere richiamato da tutti i siti web che lo utilizzano.
- Modelli personalizzati: puoi utilizzare librerie lato client, come Transformers.js e MediaPipe, per integrare i modelli nella tua applicazione. Ciò significa che puoi controllare i pesi del modello. Tuttavia, ciò significa anche che ogni utente del tuo sito web deve scaricare il tuo modello personalizzato. Anche i modelli di AI più piccoli sono grandi nel contesto di un sito web.
AI lato server
Con l'AI lato server, la tua applicazione web chiama un'API per inviare input al modello di AI e ricevere i relativi output. Questa configurazione supporta modelli più grandi e complessi ed è indipendente dall'hardware dell'utente.
Le due categorie per l'AI lato server sono:
- Servizi gestiti: si tratta di modelli ospitati in data center da una terza parte, come Gemini 3 e GPT-5. Il proprietario del modello fornisce un'API per accedervi. Ciò significa che puoi utilizzare modelli all'avanguardia con una configurazione minima. Sono ideali per la prototipazione rapida, le conversazioni aperte e il ragionamento generico. Tuttavia, lo scaling su un servizio gestito può essere costoso.
- Modelli ospitati autonomamente: puoi eseguire il deployment di modelli open-weight, come Gemma o Llama, sulla tua infrastruttura o in un container gestito, come Vertex AI o Hugging Face Inference. Questo approccio ti consente di sfruttare il pre-addestramento eseguito dal creatore del modello, ma mantieni il controllo sul modello, sui dati di ottimizzazione e sulle prestazioni.
Scegliere una piattaforma iniziale
Esamina le caratteristiche architetturali delle piattaforme AI e analizza i compromessi per decidere la configurazione iniziale.
Definisci i requisiti architetturali
Ogni decisione comporta dei compromessi. Dai un'occhiata alle caratteristiche chiave che definiscono il costo e il valore della tua piattaforma AI:
- Potenza del modello: il rendimento del modello per un'ampia gamma di utenti e attività, senza ottimizzazione. Spesso, questo valore è correlato alla dimensione del modello.
- Personalizzazione: il livello di precisione con cui puoi perfezionare, modificare o controllare il comportamento e l'architettura del modello.
- Accuratezza: la qualità e l'affidabilità complessive delle previsioni o delle generazioni del modello.
- Privacy: il grado in cui i dati utente rimangono locali e sotto il controllo dell'utente.
- Costo fisso: la spesa ricorrente necessaria per il funzionamento del sistema di AI indipendentemente dall'utilizzo, inclusi il provisioning e la manutenzione dell'infrastruttura.
- Costo per richiesta: il costo aggiuntivo di ogni richiesta in entrata.
- Compatibilità: quanto ampiamente l'approccio funziona su browser, dispositivi e ambienti senza logica di fallback.
- Comodità per l'utente: se gli utenti devono eseguire passaggi aggiuntivi per utilizzare il sistema di AI, ad esempio scaricare un modello.
- Comodità per gli sviluppatori: quanto è facile e veloce per la maggior parte degli sviluppatori eseguire il deployment, l'integrazione e la manutenzione del modello, senza competenze specialistiche in AI.
La seguente tabella fornisce un esempio di stime del rendimento di ciascuna piattaforma per ogni criterio, dove 1 è il valore più basso e 5 il valore più alto.
| Criteri | Client | Server | ||
| AI integrata o on-device | Modello personalizzato | Servizio gestito | Modello self-hosted | |
| Potenza del modello |
Perché 2 stelle per la potenza del modello?L'AI integrata e sul dispositivo utilizza modelli di browser piccoli e precaricati ottimizzati per funzionalità specifiche e limitate, anziché per conversazioni o ragionamenti aperti. |
Perché 3 stelle per la potenza del modello?Le librerie lato client personalizzate offrono maggiore flessibilità rispetto all'AI integrata, ma sono comunque limitate dalle dimensioni del download, dai limiti di memoria e dall'hardware dell'utente. |
Perché 4 stelle per la potenza del modello?Con i servizi gestiti e l'hosting autonomo, hai accesso a modelli di grandi dimensioni e all'avanguardia, in grado di eseguire ragionamenti complessi, gestire contesti lunghi e coprire un'ampia gamma di attività. |
|
| Possibilità di personalizzazione |
Perché una stella per la personalizzazione?I modelli integrati non consentono l'accesso ai pesi del modello o ai dati di addestramento. Il modo principale per personalizzare il loro comportamento è tramite il prompt engineering |
Perché 5 stelle per la personalizzazione?Questa opzione ti consente di controllare la selezione e i pesi del modello. Molte librerie lato client consentono anche l'ottimizzazione e l'addestramento dei modelli. |
Perché una stella per la personalizzazione?I servizi gestiti espongono modelli potenti, ma offrono un controllo minimo sul loro comportamento interno. La personalizzazione è in genere limitata al prompt e al contesto di input. |
Perché 5 stelle per la personalizzazione?I modelli self-hosted offrono il controllo completo su pesi del modello, dati di addestramento, messa a punto e configurazione del deployment. |
| Accuratezza |
Perché 2 stelle per l'accuratezza?L'accuratezza dei modelli integrati è sufficiente per attività ben definite, ma le dimensioni e la generalizzazione limitate del modello riducono l'affidabilità per input complessi o sfumati. |
Perché 3 stelle per l'accuratezza?L'accuratezza del modello lato client personalizzato può essere migliorata durante la procedura di selezione del modello. Tuttavia, rimane vincolato dalle dimensioni del modello, dalla quantizzazione e dalla variabilità dell'hardware client. |
Perché 5 stelle per l'accuratezza?I servizi gestiti in genere offrono una precisione relativamente elevata, grazie a modelli di grandi dimensioni, dati di addestramento estesi e miglioramenti continui del fornitore. |
Perché 4 stelle per l'accuratezza?L'accuratezza può essere elevata, ma dipende dal modello selezionato e dall'impegno di ottimizzazione. Il rendimento potrebbe essere inferiore a quello dei servizi gestiti. |
| Latenza di rete |
Perché 5 stelle per la latenza di rete?L'elaborazione avviene direttamente sul dispositivo dell'utente. |
Perché 2 stelle per la latenza di rete?È presente un round trip a un server. |
||
| Privacy |
Perché 5 stelle per la privacy?Per impostazione predefinita, i dati utente devono rimanere sul dispositivo, riducendo al minimo l'esposizione dei dati e semplificando la conformità alla privacy. |
Perché 2 stelle per la privacy?Gli input degli utenti devono essere inviati a server esterni, aumentando l'esposizione dei dati e i requisiti di conformità. Tuttavia, esistono soluzioni specifiche per mitigare i problemi di privacy, come Private AI Compute. |
Perché 3 stelle per la privacy?I dati rimangono sotto il controllo della tua organizzazione, ma lasciano comunque il dispositivo dell'utente e richiedono misure di gestione e conformità sicure. |
|
| Costo fisso |
Perché 5 stelle per il costo fisso?I modelli vengono eseguiti sui dispositivi esistenti degli utenti, quindi non sono previsti costi aggiuntivi per l'infrastruttura. |
Perché 5 stelle per il costo fisso?La maggior parte delle API addebita i costi in base all'utilizzo, pertanto non è previsto alcun costo fisso. |
Perché 2 stelle per il costo fisso?I costi fissi includono infrastruttura, manutenzione e overhead operativo. |
|
| Costo per richiesta |
Perché 5 stelle per il costo per richiesta?Non è previsto alcun costo per richiesta, poiché l'inferenza viene eseguita sul dispositivo dell'utente. |
Perché 2 stelle per il costo per richiesta?I servizi gestiti tendono ad avere prezzi per richiesta. I costi di scalabilità possono diventare significativi, soprattutto in caso di volumi di traffico elevati. |
Perché 3 stelle per il costo per richiesta?Nessun costo diretto per richiesta; il costo effettivo per richiesta dipende dall'utilizzo dell'infrastruttura. |
|
| Compatibilità |
Perché due stelle per la compatibilità?La disponibilità varia in base al browser e al dispositivo, richiedendo fallback per gli ambienti non supportati. |
Perché una stella per la compatibilità?La compatibilità dipende dalle funzionalità hardware e dal supporto del runtime, limitando la copertura su più dispositivi. |
Perché 5 stelle per la compatibilità?Le piattaforme lato server sono ampiamente compatibili per tutti gli utenti, poiché l'inferenza avviene lato server e i client utilizzano solo un'API. |
|
| Comodità per l'utente |
Perché 3 stelle per la comodità dell'utente?In genere, una volta disponibile, l'esperienza è fluida, ma l'AI integrata richiede il download iniziale del modello e il supporto del browser. |
Perché 2 stelle per la comodità dell'utente?Gli utenti potrebbero riscontrare ritardi dovuti a download o hardware non supportato. |
Perché 4 stelle per la comodità dell'utente?Funziona immediatamente senza download o requisiti del dispositivo, offrendo un'esperienza utente fluida. Tuttavia, potrebbe esserci un ritardo se la connessione di rete è debole. |
|
| Comodità per gli sviluppatori |
Perché 5 stelle per la comodità degli sviluppatori?L'AI integrata richiede una configurazione minima, nessuna infrastruttura e competenze minime in materia di AI, il che la rende facile da integrare e gestire. |
Perché 2 stelle per la comodità degli sviluppatori?Richiede la gestione di modelli, runtime, ottimizzazione delle prestazioni e compatibilità tra i dispositivi. |
Perché 4 stelle per la comodità degli sviluppatori?I servizi gestiti semplificano il deployment e lo scaling. Tuttavia, richiedono comunque l'integrazione di API, la gestione dei costi e l'ingegneria del prompt. |
Perché 1 stella per la comodità degli sviluppatori?Un deployment lato server personalizzato richiede competenze significative in infrastruttura, gestione, monitoraggio e ottimizzazione dei modelli. |
| Impegno per la manutenzione |
Perché 4 stelle per l'impegno di manutenzione?I browser gestiscono gli aggiornamenti e l'ottimizzazione dei modelli, ma gli sviluppatori devono adattarsi alla disponibilità variabile. |
Perché 2 stelle per l'impegno di manutenzione?Richiede aggiornamenti continui per modelli, ottimizzazione delle prestazioni e compatibilità man mano che browser e dispositivi si evolvono. |
Perché 5 stelle per l'impegno di manutenzione?La manutenzione è gestita dal fornitore. |
Perché 2 stelle per l'impegno di manutenzione?Richiede una manutenzione continua, inclusi aggiornamenti del modello, gestione dell'infrastruttura, scalabilità e sicurezza. |
Analizzare i compromessi
Per illustrare il processo decisionale, aggiungeremo un'altra funzionalità a Example Shoppe, una piattaforma di e-commerce di medie dimensioni. Ti interessa risparmiare sull'assistenza clienti al di fuori dell'orario di lavoro, quindi decidi di creare un assistente basato sull'AI per rispondere alle domande degli utenti su ordini, resi e prodotti.

Puoi esaminare il progetto base completo del sistema di AI, che include l'opportunità e la soluzione.
{kind=link}
Analizza lo scenario utilizzando due punti di vista: i requisiti del caso d'uso e i vincoli aziendali o del team.
| Requisito | Analisi | Criteri | Implicazione |
| Elevata precisione e versatilità | Gli utenti pongono una serie di domande complesse su ordini, prodotti e resi. | Potenza e accuratezza del modello | Richiede un modello linguistico di grandi dimensioni (LLM). |
| Specificità dei dati | Deve rispondere a domande specifiche su dati, prodotti e norme dell'azienda. | Possibilità di personalizzazione | Richiede l'importazione di dati, ad esempio RAG, ma non l'ottimizzazione del modello. |
| Requisito | Analisi | Criteri | Implicazione |
| Base utenti | Centinaia di migliaia di utenti. | Scalabilità, compatibilità | Richiede un'architettura che gestisca un traffico elevato e affidabile. |
| Obiettivi post-lancio | Il team passerà ad altri progetti dopo il lancio della versione 1. | Impegno per la manutenzione | Hai bisogno di una soluzione con una manutenzione minima. |
| Competenze del team | Sviluppatori web esperti, competenze AI/ML limitate | Comodità per gli sviluppatori | La soluzione deve essere facile da implementare e integrare senza competenze specialistiche di AI. |
Ora che hai assegnato la priorità ai tuoi criteri, puoi consultare la tabella di stima dei compromessi per determinare quale piattaforma corrisponde ai tuoi criteri di massima priorità:
Da questa suddivisione è chiaro che devi utilizzare l'AI lato server e probabilmente un servizio gestito. In questo modo, viene offerto un modello versatile per le domande complesse dei clienti. Riduce al minimo l'impegno di manutenzione e sviluppo affidando al provider l'infrastruttura, la qualità del modello e l'uptime.
Sebbene la personalizzazione sia limitata, si tratta di un compromesso valido per un team di sviluppo web con esperienza limitata nell'ingegneria dei modelli.
Una configurazione RAG (Retrieval-Augmented Generation) può aiutarti a fornire il contesto pertinente al modello al momento dell'inferenza.
IA ibrida
I sistemi di AI maturi raramente vengono eseguiti su una singola piattaforma o con un solo modello. ma distribuiscono i workload AI per ottimizzare i compromessi.
Individuare opportunità per l'AI ibrida
Una volta lanciato, dovresti perfezionare i requisiti in base a dati e feedback reali. Nel nostro esempio, Example Shoppe, aspetti qualche mese per analizzare i risultati e scopri quanto segue:
- Circa l'80% delle richieste sono ripetitive ("Dov'è il mio ordine?", "How do I return this?" (come faccio a restituirlo?). L'invio di queste richieste a un servizio gestito comporta un notevole sovraccarico e costi.
- Solo il 20% delle richieste richiede un ragionamento più approfondito e una conversazione interattiva e aperta.
Un modello locale leggero potrebbe classificare gli input degli utenti e rispondere a query di routine, ad esempio "Quali sono le vostre norme sui resi?". Puoi indirizzare domande complesse, rare o ambigue al modello lato server.
Implementando l'AI lato server e lato client, puoi ridurre i costi e la latenza, mantenendo l'accesso a un ragionamento potente quando necessario.
Distribuire il carico di lavoro
Per creare questo sistema ibrido per Example Shoppe, devi iniziare definendo il sistema predefinito. In questo caso, è meglio iniziare dal lato client. L'applicazione deve indirizzare l'AI lato server in due casi:
- Fallback basato sulla compatibilità: se il dispositivo o il browser dell'utente non è in grado di gestire la richiesta, deve eseguire il fallback sul server
- Riassegnazione basata sulle funzionalità: se la richiesta è troppo complessa o aperta per il modello lato client, come definito da criteri predeterminati, deve essere riassegnata a un modello lato server più grande. Potresti utilizzare un modello per classificare la richiesta come comune, in modo da eseguire l'attività lato client, o non comune, in modo da inviare la richiesta al sistema lato server. Ad esempio, se il modello lato client determina che la domanda è correlata a un problema insolito, come l'ottenimento di un rimborso in una valuta diversa.
La flessibilità introduce una maggiore complessità
La distribuzione dei carichi di lavoro tra due piattaforme ti offre maggiore flessibilità, ma aumenta anche la complessità:
- Orchestrazione: due ambienti di esecuzione significano più parti mobili. Devi avere una logica per il routing, i nuovi tentativi e i fallback.
- Controllo delle versioni: se utilizzi lo stesso modello su più piattaforme, deve rimanere compatibile in entrambi gli ambienti.
- Ingegneria dei prompt e ingegneria del contesto: Se utilizzi modelli diversi su ogni piattaforma, devi eseguire l'ingegneria dei prompt per ciascuno.
- Monitoraggio: i log e le metriche sono suddivisi e richiedono un ulteriore sforzo di unificazione.
- Sicurezza: mantieni due superfici di attacco. È necessario proteggere sia gli endpoint locali che quelli cloud.
Questo è un altro compromesso da valutare. Se hai un piccolo team o stai creando una funzionalità non essenziale, potresti non voler aggiungere questa complessità.
I tuoi concetti principali
Tieni presente che la tua scelta della piattaforma potrebbe evolversi. Inizia dal caso d'uso, allineati all'esperienza e alle risorse del tuo team e itera man mano che il tuo prodotto e la tua maturità dell'AI crescono. Il tuo compito è trovare il giusto mix di velocità, privacy e controllo per i tuoi utenti, quindi creare con una certa flessibilità. In questo modo, puoi adattarti ai requisiti in evoluzione e usufruire dei futuri aggiornamenti della piattaforma e del modello.
Risorse
- Poiché la scelta della piattaforma e del modello è interdipendente, scopri di più sulla selezione del modello.
- Scopri come andare oltre il cloud con l'AI ibrida e lato client
Verifica la tua comprensione
Quali sono le due considerazioni principali da tenere presenti quando si seleziona una piattaforma AI per la tua applicazione?
Quando un servizio gestito lato server, come Gemini Pro, è la scelta migliore per la tua piattaforma?
Qual è il vantaggio principale dell'implementazione di un sistema di AI ibrida?