

Embora a "L" em modelos de linguagem grandes (LLMs) sugira uma escala enorme, a realidade é mais sutil. Alguns LLMs contêm trilhões de parâmetros, e outros operam de maneira eficaz com muito menos.
Confira alguns exemplos reais e as implicações práticas de diferentes tamanhos de modelo.
Tamanhos e classes de tamanho de LLM
Como desenvolvedores da Web, tendemos a pensar no tamanho de um recurso como o tamanho do download. O tamanho documentado de um modelo se refere ao número de parâmetros. Por exemplo, Gemma 2B significa Gemma com 2 bilhões de parâmetros.
Os LLMs podem ter centenas de milhares, milhões, bilhões ou até trilhões de parâmetros.
Os LLMs maiores têm mais parâmetros do que os menores, o que permite capturar relações de linguagem mais complexas e processar comandos com nuances. Eles também são treinados com conjuntos de dados maiores.
Você pode ter notado que alguns tamanhos de modelo, como 2 bilhões ou 7 bilhões, são comuns. Por exemplo, Gemma 2B, Gemma 7B ou Mistral 7B. As classes de tamanho do modelo são agrupamentos aproximados. Por exemplo, o Gemma 2B tem aproximadamente 2 bilhões de parâmetros, mas não exatamente.
As classes de tamanho de modelo oferecem uma maneira prática de avaliar o desempenho do LLM. Pense nelas como classes de peso no boxe: modelos da mesma classe de tamanho são mais comparáveis. Dois modelos 2B devem oferecer desempenho semelhante.
No entanto, um modelo menor pode ter o mesmo desempenho que um modelo maior para tarefas específicas.

Embora os tamanhos de modelo para os LLMs mais recentes, como GPT-4 e Gemini Pro ou Ultra, não sejam sempre divulgados, acredita-se que eles estejam na ordem de centenas de bilhões ou trilhões de parâmetros.

Nem todos os modelos indicam o número de parâmetros no nome. Alguns modelos têm um sufixo com o número da versão. Por exemplo, o Gemini 1.5 Pro se refere à versão 1.5 do modelo (após a versão 1).
LLM ou não?
Quando um modelo é muito pequeno para ser um LLM? A definição de LLM pode ser um tanto fluida na comunidade de IA e ML.
Alguns consideram que apenas os modelos maiores com bilhões de parâmetros são LLMs reais, enquanto modelos menores, como o DistilBERT, são considerados modelos simples de PNL. Outros incluem modelos menores, mas ainda poderosos, na definição de LLM, como o DistilBERT.
LLMs menores para casos de uso no dispositivo
Os LLMs maiores exigem muito espaço de armazenamento e muita capacidade de computação para inferência. Eles precisam ser executados em servidores dedicados e poderosos com hardware específico, como TPUs.
Como desenvolvedores da Web, queremos saber se um modelo é pequeno o suficiente para ser transferido por download e executado no dispositivo de um usuário.
Mas essa é uma pergunta difícil de responder. Atualmente, não há uma maneira fácil de saber se "esse modelo pode ser executado na maioria dos dispositivos de nível intermediário" por alguns motivos:
- Os recursos do dispositivo variam muito de acordo com a memória, as especificações da GPU/CPU e muito mais. Um smartphone Android de baixo custo e um laptop NVIDIA® RTX são muito diferentes. Talvez você tenha alguns pontos de dados sobre os dispositivos dos seus usuários. Ainda não temos uma definição para um dispositivo de referência usado para acessar a Web.
- Um modelo ou o framework em que ele é executado pode ser otimizado para execução em determinado hardware.
- Não há uma maneira programática de determinar se um LLM específico pode ser feito o download e executado em um dispositivo específico. O recurso de download de um dispositivo depende de quanto VRAM há na GPU, entre outros fatores.
No entanto, temos alguns conhecimentos empíricos: hoje, alguns modelos com alguns milhões a alguns bilhões de parâmetros podem ser executados no navegador, em dispositivos de consumo.
Exemplo:
- Gemma 2B com a API MediaPipe LLM Inference (adequada até mesmo para dispositivos somente de CPU). Teste.
- DistilBERT com Transformers.js.
Este é um campo em desenvolvimento. É possível esperar que o cenário evolua:
- Com as inovações do WebAssembly e do WebGPU, o suporte do WebGPU para mais bibliotecas, novas bibliotecas e otimizações, espera-se que os dispositivos dos usuários sejam cada vez mais capazes de executar LLMs de vários tamanhos com eficiência.
- Os LLMs menores e de alto desempenho vão se tornar cada vez mais comuns, com técnicas de redução.
Considerações para LLMs menores
Ao trabalhar com LLMs menores, sempre considere a performance e o tamanho do download.
Desempenho
A capacidade de qualquer modelo depende muito do seu caso de uso. Um LLM menor ajustado para seu caso de uso pode ter um desempenho melhor do que um LLM genérico maior.
No entanto, na mesma família de modelos, os LLMs menores têm menos recursos do que os maiores. Para o mesmo caso de uso, normalmente é necessário fazer mais trabalho de engenharia imediato ao usar um LLM menor.
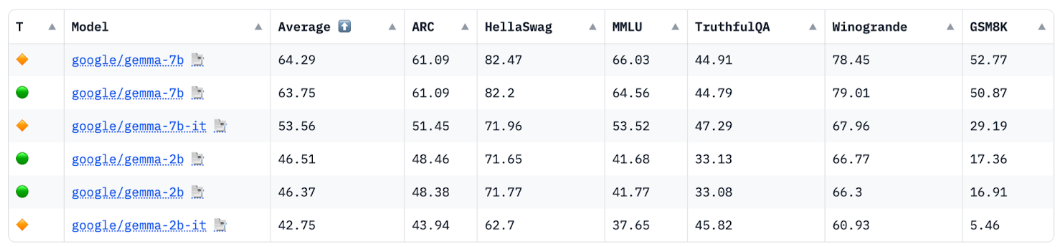
Fonte: placar do LLM aberto do HuggingFace, abril de 2024
Tamanho do download
Mais parâmetros significam um tamanho de download maior, o que também afeta se um modelo, mesmo que considerado pequeno, pode ser baixado de forma razoável para casos de uso no dispositivo.
Embora existam técnicas para calcular o tamanho de download de um modelo com base no número de parâmetros, isso pode ser complexo.
No início de 2024, os tamanhos de download de modelos raramente eram documentados. Portanto, para seus casos de uso no dispositivo e no navegador, recomendamos que você analise o tamanho do download empiricamente, no painel Rede do Chrome DevTools ou com outras ferramentas para desenvolvedores de navegador.

O Gemma é usado com a API de inferência de LLM do MediaPipe. O DistilBERT é usado com o Transformers.js.
Técnicas de redução de modelo
Existem várias técnicas para reduzir significativamente os requisitos de memória de um modelo:
- LoRA (Adaptação de Baixa Classificação): técnica de ajuste fino em que os pesos pré-treinados são congelados. Saiba mais sobre o LoRA.
- Poda: remoção de pesos menos importantes do modelo para reduzir o tamanho dele.
- Quantização: redução da precisão de pesos de números de ponto flutuante (como 32 bits) para representações de bits mais baixos (como 8 bits).
- Destilação de conhecimento: treinar um modelo menor para imitar o comportamento de um modelo maior e pré-treinado.
- Compartilhamento de parâmetros: usar os mesmos pesos para várias partes do modelo, reduzindo o número total de parâmetros exclusivos.