
Dołącz do wersji na komputer
Dlaczego importowanie?
Zastanów się, jak wczytujesz różne typy zasobów w internecie. W przypadku JS mamy <script src>. W przypadku usługi porównywania cen prawdopodobnie będzie to <link rel="stylesheet">. W przypadku obrazów jest to <img>. Film ma <video>. Dźwięk, <audio>… Pisz na temat. Większość treści w internecie jest wczytywana w prosty i deklaratywny sposób. Nie dotyczy to HTML. Dostępne opcje:
<iframe>– sprawdzone i ciężkie. Treści w ramce iframe znajdują się w zupełnie innym kontekście niż Twoja strona. Chociaż jest to świetna funkcja, stwarza dodatkowe wyzwania (dopasowywanie rozmiaru ramki do zawartości jest trudne, skomplikowane w skrypcie i prawie niemożliwe do sformatowania).- AJAX – Uwielbiam
xhr.responseType="document", ale czy to znaczy, że do wczytania HTML potrzebuję JS? To nie wygląda dobrze. - CrazyHacks™ – zakodowane w ciągu znaków, ukryte jako komentarze (np.
<script type="text/html">). Yuck!
Widzicie ironię? Najprostszy rodzaj treści internetowych, czyli HTML, wymaga największego nakładu pracy. Na szczęście komponenty sieciowe pomogą Ci wrócić na właściwe tory.
Pierwsze kroki
Importy HTML, które są częścią komponentów internetowych, to sposób na umieszczanie dokumentów HTML w innych dokumentach HTML. Nie musisz też ograniczać się do znaczników. Import może też zawierać pliki CSS, JavaScript lub inne elementy, które mogą się znajdować w pliku .html. Inaczej mówiąc, importowanie jest fantastycznym narzędziem do wczytywania powiązanych plików HTML/CSS/JS.
Podstawy
Aby uwzględnić import na stronie, zadeklaruj element <link rel="import">:
<head>
<link rel="import" href="/path/to/imports/stuff.html">
</head>
Adres URL importu nazywa się lokalizacją importu. Aby wczytywać treści z innej domeny, lokalizacja importu musi mieć włączoną obsługę CORS:
<!-- Resources on other origins must be CORS-enabled. -->
<link rel="import" href="http://example.com/elements.html">
Wykrywanie funkcji i obsługa
Aby wykryć obsługę, sprawdź, czy element .import zawiera element .import:<link>
function supportsImports() {
return 'import' in document.createElement('link');
}
if (supportsImports()) {
// Good to go!
} else {
// Use other libraries/require systems to load files.
}
Obsługa przeglądarek jest wciąż w początkowej fazie. Chrome 31 była pierwszą przeglądarką, w której zaimplementowano tę funkcję, ale inni dostawcy przeglądarek czekają na to, jak sprawdzą się moduły ES. W przypadku innych przeglądarek polyfill webcomponents.js działa świetnie, dopóki nie będzie powszechnie obsługiwany.
Pakowanie zasobów
Importy zapewniają konwencję grupowania plików HTML/CSS/JS (nawet innych importów HTML) w jednym pliku. Jest to funkcja nieodłączalna, ale bardzo przydatna. Jeśli tworzysz motyw lub bibliotekę albo chcesz podzielić aplikację na logiczne części, możesz udostępnić użytkownikom pojedynczy adres URL. Możesz nawet importować całą aplikację. Pomyśl o tym przez chwilę.
Przykładem jest tu Bootstrap. Bootstrap składa się z pojedynczych plików (bootstrap.css, bootstrap.js, czcionki), wymaga JQuery do swoich wtyczek i zawiera przykłady znaczników. Deweloperzy lubią elastyczność, jaką daje opcja „à la carte”. Umożliwia to im korzystanie z tych części platformy, które chcą stosować. Mimo to zakładam, że typowy programista JoeDeveloper™ wybierze łatwą drogę i pobierze cały Bootstrap.
Importowanie ma sens w przypadku takich narzędzi jak Bootstrap. Oto przyszłość wczytywania Bootstrap:
<head>
<link rel="import" href="bootstrap.html">
</head>
Użytkownicy po prostu wczytują link do importu HTML. Nie musisz się martwić o rozproszenie plików. Zamiast tego cały Bootstrap jest zarządzany i zapakowany w plik importu bootstrap.html:
<link rel="stylesheet" href="bootstrap.css">
<link rel="stylesheet" href="fonts.css">
<script src="jquery.js"></script>
<script src="bootstrap.js"></script>
<script src="bootstrap-tooltip.js"></script>
<script src="bootstrap-dropdown.js"></script>
...
<!-- scaffolding markup -->
<template>
...
</template>
Poczekaj chwilę. To ekscytujące.
Zdarzenia wczytywania i błędów
Element <link> powoduje wywołanie zdarzenia load, gdy import zostanie załadowany pomyślnie, oraz zdarzenia onerror, gdy próba się nie powiedzie (np. gdy zasób zwróci kod 404).
Importy są próbowane załadować natychmiast. Prostym sposobem na uniknięcie problemów jest użycie atrybutów onload/onerror:
<script>
function handleLoad(e) {
console.log('Loaded import: ' + e.target.href);
}
function handleError(e) {
console.log('Error loading import: ' + e.target.href);
}
</script>
<link rel="import" href="file.html"
onload="handleLoad(event)" onerror="handleError(event)">
Jeśli importujesz dane dynamicznie:
var link = document.createElement('link');
link.rel = 'import';
// link.setAttribute('async', ''); // make it async!
link.href = 'file.html';
link.onload = function(e) {...};
link.onerror = function(e) {...};
document.head.appendChild(link);
Korzystanie z treści
Włączenie importu na stronie nie oznacza „wstaw tutaj zawartość tego pliku”. Oznacza to „Parsorze, pobierz ten dokument, abym mógł go wykorzystać”. Aby faktycznie użyć treści, musisz podjąć działanie i napisać skrypt.
Ważnym aha!momentem jest zrozumienie, że importowany plik to tylko dokument. Właściwa treść importu jest nazywana dokumentem importu. Możesz zmienić zawartość importu za pomocą standardowych interfejsów DOM API.
link.import
Aby uzyskać dostęp do treści importu, użyj właściwości .import elementu linku:
var content = document.querySelector('link[rel="import"]').import;
link.import jest null, jeśli spełnia te warunki:
- Przeglądarka nie obsługuje importowania kodu HTML.
- Rola
<link>nie ma uprawnieniarel="import". - Element
<link>nie został dodany do DOM. - Element
<link>został usunięty z DOM. - Zasób nie obsługuje CORS.
Pełny przykład
Załóżmy, że warnings.html zawiera:
<div class="warning">
<style>
h3 {
color: red !important;
}
</style>
<h3>Warning!
<p>This page is under construction
</div>
<div class="outdated">
<h3>Heads up!
<p>This content may be out of date
</div>
Importujący mogą pobrać określoną część tego dokumentu i sklonować ją na swojej stronie:
<head>
<link rel="import" href="warnings.html">
</head>
<body>
...
<script>
var link = document.querySelector('link[rel="import"]');
var content = link.import;
// Grab DOM from warning.html's document.
var el = content.querySelector('.warning');
document.body.appendChild(el.cloneNode(true));
</script>
</body>
Skryptowanie w importach
Dane importowane nie znajdują się w dokumencie głównym. Są satelitami. Importowane dane mogą jednak działać na stronie głównej, nawet jeśli główny dokument ma najwyższy priorytet. Import może mieć dostęp do własnego modelu DOM lub modelu DOM strony, która go importuje:
Przykład: plik import.html, który dodaje jedną z swoich sformatowanych stron do strony głównej.
<link rel="stylesheet" href="http://www.example.com/styles.css">
<link rel="stylesheet" href="http://www.example.com/styles2.css">
<style>
/* Note: <style> in an import apply to the main
document by default. That is, style tags don't need to be
explicitly added to the main document. */
#somecontainer {
color: blue;
}
</style>
...
<script>
// importDoc references this import's document
var importDoc = document.currentScript.ownerDocument;
// mainDoc references the main document (the page that's importing us)
var mainDoc = document;
// Grab the first stylesheet from this import, clone it,
// and append it to the importing document.
var styles = importDoc.querySelector('link[rel="stylesheet"]');
mainDoc.head.appendChild(styles.cloneNode(true));
</script>
Zwróć uwagę na to, co się tu dzieje. Skrypt w ramach importu odwołuje się do zaimportowanego dokumentu (document.currentScript.ownerDocument) i dodaje część tego dokumentu do strony importowania (mainDoc.head.appendChild(...)). Moim zdaniem to całkiem niezły pomysł.
Reguły dotyczące JavaScripta w importowanym pliku:
- Skrypt w importowanym pliku jest wykonywany w kontekście okna, które zawiera importowany plik
document.window.documentodnosi się do dokumentu strony głównej. Ma to 2 przydatne konsekwencje:- funkcje zdefiniowane w importowanym pliku kończą się na
window. - nie musisz wykonywać skomplikowanych czynności, takich jak dołączanie bloków
<script>do strony głównej. Ponownie skrypt zostanie wykonany.
- funkcje zdefiniowane w importowanym pliku kończą się na
- Importy nie blokują analizowania strony głównej. Skrypty w nich zawarte są jednak przetwarzane w kolejności. Oznacza to, że działanie jest podobne do opóźnienia przy zachowaniu prawidłowej kolejności skryptu. Więcej informacji znajdziesz poniżej.
Udostępnianie komponentów internetowych
Zaimportowane pliki HTML są przydatne do wczytywania treści do wielokrotnego użytku w internecie. Jest to szczególnie przydatne do rozpowszechniania komponentów sieciowych. Wszystko od podstawowych tagów HTML <template> po niestandardowe elementy z Shadow DOM [1, 2, 3]. Gdy te technologie są używane w tandemie, importy stają się #include dla komponentów internetowych.
Uwzględnianie szablonów
Element szablonu HTML jest naturalnie przystosowany do importowania kodu HTML. <template> to świetny sposób na stworzenie szkieletu sekcji znaczników, które aplikacja importująca może wykorzystać według własnego uznania. Opakowanie treści w <template> daje też dodatkową korzyść, ponieważ czyni je nieaktywnymi do momentu użycia. Oznacza to, że skrypty nie są uruchamiane, dopóki szablon nie zostanie dodany do DOM. Wow!
import.html
<template>
<h1>Hello World!</h1>
<!-- Img is not requested until the <template> goes live. -->
<img src="world.png">
<script>alert("Executed when the template is activated.");</script>
</template>
index.html
<head>
<link rel="import" href="import.html">
</head>
<body>
<div id="container"></div>
<script>
var link = document.querySelector('link[rel="import"]');
// Clone the <template> in the import.
var template = link.import.querySelector('template');
var clone = document.importNode(template.content, true);
document.querySelector('#container').appendChild(clone);
</script>
</body>
Rejestrowanie elementów niestandardowych
Elementy niestandardowe to kolejna technologia Web Components, która świetnie współpracuje z importami HTML. Importy mogą wykonywać skrypty, więc zdefiniuj i zarejestruj elementy niestandardowe, aby użytkownicy nie musieli tego robić. Nazwij to „automatyczną rejestracją”.
elements.html
<script>
// Define and register <say-hi>.
var proto = Object.create(HTMLElement.prototype);
proto.createdCallback = function() {
this.innerHTML = 'Hello, <b>' +
(this.getAttribute('name') || '?') + '</b>';
};
document.registerElement('say-hi', {prototype: proto});
</script>
<template id="t">
<style>
::content > * {
color: red;
}
</style>
<span>I'm a shadow-element using Shadow DOM!</span>
<content></content>
</template>
<script>
(function() {
var importDoc = document.currentScript.ownerDocument; // importee
// Define and register <shadow-element>
// that uses Shadow DOM and a template.
var proto2 = Object.create(HTMLElement.prototype);
proto2.createdCallback = function() {
// get template in import
var template = importDoc.querySelector('#t');
// import template into
var clone = document.importNode(template.content, true);
var root = this.createShadowRoot();
root.appendChild(clone);
};
document.registerElement('shadow-element', {prototype: proto2});
})();
</script>
Ten import definiuje (i rejestruje) 2 elementy: <say-hi> i <shadow-element>. Pierwszy pokazuje podstawowy element niestandardowy, który rejestruje się w ramach importu. Drugi przykład pokazuje, jak zaimplementować element niestandardowy, który tworzy model Shadow DOM z elementu <template>, a następnie się rejestruje.
Największą zaletą rejestrowania elementów niestandardowych w importowanym pliku HTML jest to, że importujący po prostu deklaruje Twój element na swojej stronie. Nie musisz podłączać kabli.
index.html
<head>
<link rel="import" href="elements.html">
</head>
<body>
<say-hi name="Eric"></say-hi>
<shadow-element>
<div>( I'm in the light dom )</div>
</shadow-element>
</body>
Moim zdaniem ten proces sam w sobie sprawia, że importowanie HTML jest idealnym sposobem na udostępnianie komponentów internetowych.
Zarządzanie zależnościami i podimportami
Importy podrzędne
Może to być przydatne, jeśli jeden import ma zawierać inny. Jeśli na przykład chcesz ponownie użyć lub rozszerzyć inny komponent, zaimportuj go, aby załadować inne elementy.
Poniżej znajduje się rzeczywisty przykład z Polymer. Jest to nowy komponent karty (<paper-tabs>), który używa komponentu układu i selektora. Zależnośćami można zarządzać za pomocą importu HTML.
paper-tabs.html (uproszczony):
<link rel="import" href="iron-selector.html">
<link rel="import" href="classes/iron-flex-layout.html">
<dom-module id="paper-tabs">
<template>
<style>...</style>
<iron-selector class="layout horizonta center">
<content select="*"></content>
</iron-selector>
</template>
<script>...</script>
</dom-module>
Deweloperzy aplikacji mogą importować ten nowy element za pomocą:
<link rel="import" href="paper-tabs.html">
<paper-tabs></paper-tabs>
Gdy w przyszłości pojawi się nowa, lepsza wersja <iron-selector2>, możesz zastąpić <iron-selector> i od razu zacząć z niej korzystać. Dzięki importom i komponentom internetowym nie będziesz mieć problemów z użytkownikami.
Zarządzanie zależnościami
Wszyscy wiemy, że wczytywanie JQuery więcej niż raz na stronie powoduje błędy. Czy to nie będzie ogromnym problemem dla komponentów internetowych, gdy wiele komponentów będzie używać tej samej biblioteki? Nie, jeśli używamy importu HTML. Można ich używać do zarządzania zależnościami.
Owijanie bibliotek w import HTML powoduje automatyczne usuwanie duplikatów zasobów. Dokument jest tylko raz przeanalizowany. Skrypty są wykonywane tylko raz. Załóżmy, że definiujesz plik importu jquery.html, który wczytuje kopię biblioteki JQuery.
jquery.html
<script src="http://cdn.com/jquery.js"></script>
Ten import można ponownie wykorzystać w kolejnych importach w ten sposób:
import2.html
<link rel="import" href="jquery.html">
<div>Hello, I'm import 2</div>
ajax-element.html
<link rel="import" href="jquery.html">
<link rel="import" href="import2.html">
<script>
var proto = Object.create(HTMLElement.prototype);
proto.makeRequest = function(url, done) {
return $.ajax(url).done(function() {
done();
});
};
document.registerElement('ajax-element', {prototype: proto});
</script>
Nawet sama strona główna może zawierać plik jquery.html, jeśli potrzebuje tej biblioteki:
<head>
<link rel="import" href="jquery.html">
<link rel="import" href="ajax-element.html">
</head>
<body>
...
<script>
$(document).ready(function() {
var el = document.createElement('ajax-element');
el.makeRequest('http://example.com');
});
</script>
</body>
Pomimo że plik jquery.html jest uwzględniony w wielu różnych drzewach importu, przeglądarka pobiera i przetwarza go tylko raz. Sprawdziliśmy panel sieci:
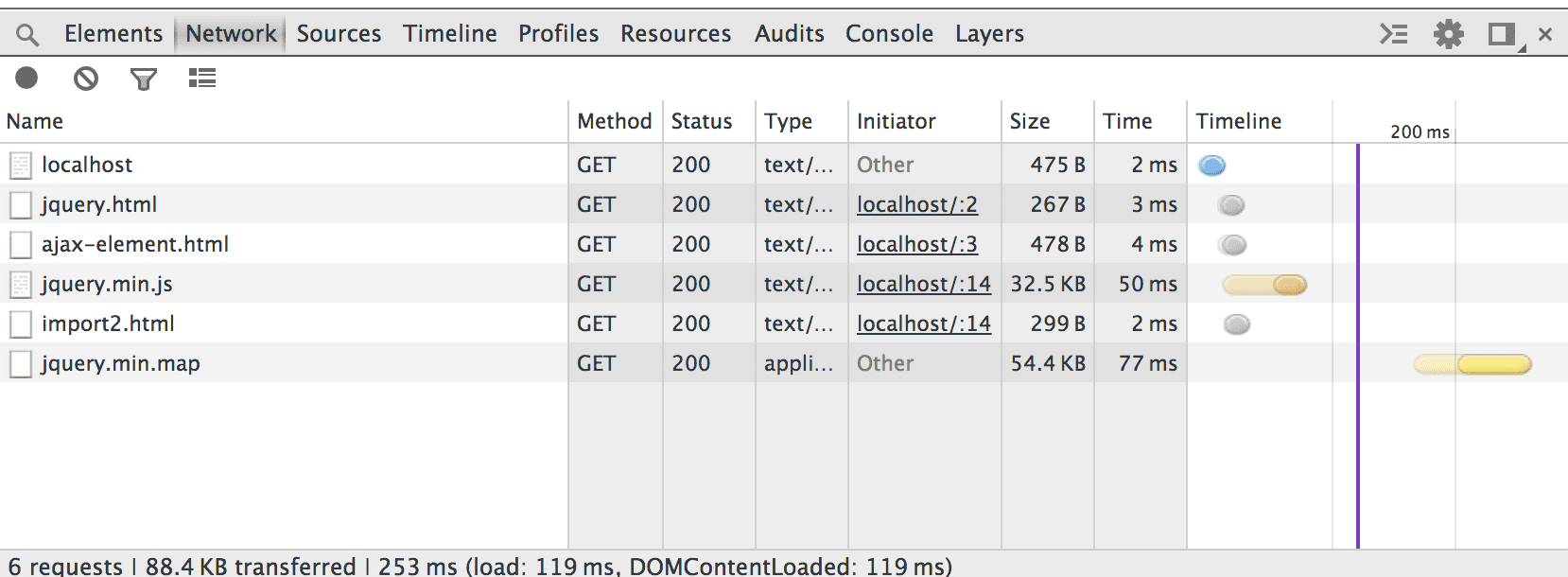
Możliwe spowolnienie działania witryny
Importowanie kodu HTML jest świetnym rozwiązaniem, ale tak jak w przypadku każdej nowej technologii internetowej, należy używać go rozważnie. Sprawdzone metody tworzenia stron internetowych nadal się sprawdzają. Poniżej przedstawiamy kilka kwestii, o których należy pamiętać.
Łączenie importów
Zmniejszenie liczby żądań sieciowych jest zawsze ważne. Jeśli masz wiele linków importu na najwyższym poziomie, zastanów się nad połączeniem ich w jeden zasób i zaimportowaniem tego pliku.
Vulcanize to narzędzie do kompilowania npm od zespołu Polymer, które rekurencyjnie spłaszcza zestaw plików HTML Imports do jednego pliku. Możesz je traktować jako etap kompilacji łańcucha znaków dla komponentów sieciowych.
Importowanie wykorzystuje pamięć podręczną przeglądarki
Wiele osób zapomina, że przez lata precyzyjnie dostosowywaliśmy warstwę sieciową przeglądarki. Importy (i importy podrzędne) również korzystają z tej logiki. Import http://cdn.com/bootstrap.html może zawierać zasoby podrzędne, ale zostaną one zapisane w pamięci podręcznej.
Treści są przydatne tylko wtedy, gdy je dodasz
Traktuj treści jako nieaktywne, dopóki nie wezwiesz ich usług. Weź zwykły arkusz stylów utworzony dynamicznie:
var link = document.createElement('link');
link.rel = 'stylesheet';
link.href = 'styles.css';
Przeglądarka nie żąda pliku styles.css, dopóki element link nie zostanie dodany do DOM:
document.head.appendChild(link); // browser requests styles.css
Innym przykładem jest znacznik generowany dynamicznie:
var h2 = document.createElement('h2');
h2.textContent = 'Booyah!';
Atrybut h2 nie ma większego znaczenia, dopóki nie dodasz go do DOM.
To samo dotyczy dokumentu importowanego. Jeśli nie dodasz jego zawartości do DOM, nie będzie ono działać. W fakcie jedyną rzeczą, która „wykonuje” się bezpośrednio w dokumencie importowanym, jest <script>. Zobacz skrypty w importach.
Optymalizacja pod kątem ładowania asynchronicznego
Importy blokują renderowanie
Importy blokują renderowanie strony głównej. Jest to podobne do tego, co robi <link rel="stylesheet">. Przeglądarka blokuje renderowanie sformatowanych stron, aby zminimalizować ilość elementów, które wymagają interakcji użytkownika. Importowane pliki działają podobnie, ponieważ mogą zawierać arkusze stylów.
Aby zapewnić całkowitą asynchroniczność i nie blokować parsowania ani renderowania, użyj atrybutu async:
<link rel="import" href="/path/to/import_that_takes_5secs.html" async>
Powód, dla którego async nie jest domyślnym ustawieniem importu kodu HTML, jest taki, że wymaga ono od programistów więcej pracy. Synchroniczne domyślnie oznacza, że importy HTML zawierające definicje elementów niestandardowych są gwarantowanie ładowane i aktualizowane w kolejności. W świecie całkowicie asynchronicznym deweloperzy musieliby samodzielnie zarządzać harmonogramem aktualizacji.
Import asynchroniczny możesz też utworzyć dynamicznie:
var l = document.createElement('link');
l.rel = 'import';
l.href = 'elements.html';
l.setAttribute('async', '');
l.onload = function(e) { ... };
Importy nie blokują analizowania
Importowanie nie blokuje analizowania strony głównej. Skrypty w importach są przetwarzane w kolejności, ale nie blokują strony importowania. Oznacza to, że działanie jest podobne do opóźnienia przy zachowaniu prawidłowej kolejności skryptu. Jedną z zalet umieszczania importowanych danych w folderze <head> jest to, że pozwala to parserzowi jak najszybciej rozpocząć przetwarzanie treści. Pamiętaj, że <script> w dokumencie głównym nadal blokuje stronę. Pierwsza <script> po imporcie spowoduje zablokowanie renderowania strony. Dzieje się tak, ponieważ plik importowany może zawierać skrypt, który musi zostać wykonany przed skryptem na stronie głównej.
<head>
<link rel="import" href="/path/to/import_that_takes_5secs.html">
<script>console.log('I block page rendering');</script>
</head>
W zależności od struktury i przypadku użycia aplikacji możesz optymalizować zachowanie asynchroniczne na kilka sposobów. Poniżej opisaliśmy techniki, które pozwalają uniknąć blokowania renderowania strony głównej.
Scenariusz 1 (preferowany): nie masz skryptu w pliku <head> ani wbudowanego w pliku <body>
Zalecamy, aby nie umieszczać tagów <script> bezpośrednio po zaimportowaniu danych. Przesuwaj skrypty jak najpóźniej, ale pewnie już to robisz, prawda? ;)
Oto przykład:
<head>
<link rel="import" href="/path/to/import.html">
<link rel="import" href="/path/to/import2.html">
<!-- avoid including script -->
</head>
<body>
<!-- avoid including script -->
<div id="container"></div>
<!-- avoid including script -->
...
<script>
// Other scripts n' stuff.
// Bring in the import content.
var link = document.querySelector('link[rel="import"]');
var post = link.import.querySelector('#blog-post');
var container = document.querySelector('#container');
container.appendChild(post.cloneNode(true));
</script>
</body>
Wszystko jest na dole.
Scenariusz 1.5: import dodaje się automatycznie
Inną opcją jest dodanie własnych treści podczas importowania. Jeśli autor importu zawiera umowę z deweloperem aplikacji, import może zostać dodany do obszaru strony głównej:
import.html:
<div id="blog-post">...</div>
<script>
var me = document.currentScript.ownerDocument;
var post = me.querySelector('#blog-post');
var container = document.querySelector('#container');
container.appendChild(post.cloneNode(true));
</script>
index.html
<head>
<link rel="import" href="/path/to/import.html">
</head>
<body>
<!-- no need for script. the import takes care of things -->
</body>
Scenariusz 2. Masz skrypt w pliku <head> lub wbudowany w pliku <body>
Jeśli wczytywanie importu trwa długo, pierwsza <script>, która pojawia się na stronie po importie, zablokuje renderowanie strony. Google Analytics zaleca umieszczenie kodu śledzenia w sekcji <head>. Jeśli nie możesz uniknąć umieszczenia w sekcji <head> tagu <script>, dodanie importu w sposób dynamiczny zapobiegnie blokowaniu strony:
<head>
<script>
function addImportLink(url) {
var link = document.createElement('link');
link.rel = 'import';
link.href = url;
link.onload = function(e) {
var post = this.import.querySelector('#blog-post');
var container = document.querySelector('#container');
container.appendChild(post.cloneNode(true));
};
document.head.appendChild(link);
}
addImportLink('/path/to/import.html'); // Import is added early :)
</script>
<script>
// other scripts
</script>
</head>
<body>
<div id="container"></div>
...
</body>
Możesz też dodać import na końcu pliku <body>:
<head>
<script>
// other scripts
</script>
</head>
<body>
<div id="container"></div>
...
<script>
function addImportLink(url) { ... }
addImportLink('/path/to/import.html'); // Import is added very late :(
</script>
</body>
Rzeczy, o których należy pamiętać
Typ MIME importu to
text/html.Zasoby z innych źródeł muszą mieć włączoną obsługę CORS.
Importy z tego samego adresu URL są pobierane i analizowane tylko raz. Oznacza to, że skrypt w importowanym pliku jest wykonywany tylko przy pierwszym zaimportowaniu.
Skrypty w importowanym pliku są przetwarzane w kolejności, ale nie blokują analizowania głównego dokumentu.
Link do importu nie oznacza „#include the content here”. Oznacza to „Parsorze, pobierz ten dokument, abym mógł go użyć później”. Skrypty są wykonywane w momencie importowania, ale arkuszy stylów, znaczników i innych zasobów należy dodawać do strony głównej w wyraźny sposób. Uwaga: nie musisz dodawać znaku
<style>. To główna różnica między importami HTML a tagami<iframe>, które mówią: „Tutaj wczytaj i wyświetl te treści”.
Podsumowanie
Importy HTML umożliwiają grupowanie plików HTML/CSS/JS w jeden zasób. Chociaż są one przydatne same w sobie, w świecie komponentów sieciowych ich możliwości są jeszcze większe. Deweloperzy mogą tworzyć komponenty wielokrotnego użytku, które inni mogą wykorzystać i wstawić do swoich aplikacji. Wszystko to jest dostępne w ramach <link rel="import">.
Importowanie kodu HTML to prosta koncepcja, która umożliwia jednak wiele ciekawych zastosowań na platformie.
Przypadki użycia
- Rozpowszechniaj powiązane pliki HTML/CSS/JS w ramach jednego pakietu. Teoretycznie możesz zaimportować całą aplikację internetową do innej.
- Organizacja kodu – podział koncepcji na logiczne segmenty w różnych plikach, co zachęca do tworzenia modułów i możliwości ponownego użycia kodu.**
- Przekaż co najmniej jedną definicję elementu niestandardowego. Importowanie może służyć do rejestrowania i uwzględniania ich w aplikacji. Jest to dobra praktyka, ponieważ pozwala oddzielić interfejs/definicję elementu od sposobu jego użycia.
- Zarządzaj zależnościami – zasoby są automatycznie usuwane z duplikatów.
- Podziel skrypty na części – przed importem duże pliki bibliotek JS były całkowicie analizowane, aby można było je uruchomić, co było czasochłonne. W przypadku importowania biblioteka może zacząć działać, gdy tylko zanalizowany zostanie fragment A. Mniejsze opóźnienie
// TODO: DevSite - Code sample removed as it used inline event handlers
Równoległe parsowanie kodu HTML – po raz pierwszy przeglądarka może uruchamiać równolegle 2 (lub więcej) parserów HTML.
Umożliwia przełączanie się między trybem debugowania i niedebugowania w aplikacji przez zmianę samego celu importu. Aplikacja nie musi wiedzieć, czy docelowy zasób do importowania to zasob zbiorczy lub skompilowany, czy drzewo importu.