
予測(分析)AI は、既存のデータを理解し、次に何が起こるかを予測するのに役立つアルゴリズムの集合です。予測 AI モデルは、過去のパターンに基づいて、ユーザーがデータを理解するのに役立つさまざまな分析タスクを学習します。
- 分類: データのパターンに基づいて、アイテムを事前定義されたカテゴリにグループ化します。たとえば、オンライン ショップでは、ユーザーの意図(調査、購入、返品)に基づいてユーザーを分類し、それに応じておすすめを調整できます。
- 回帰: エンゲージメント率、セッション時間、コンバージョン確率などの数値を予測します。
- レコメンデーション: 特定のユーザーまたはコンテキストに最も関連性の高いアイテムを提案します。「あなたのようなユーザーが閲覧したコンテンツ」や「進捗状況に基づいておすすめのチュートリアル」のようなものです。
- 予測と異常検出: モデルは、トラフィックの急増などの将来のイベントを予測したり、支払いの異常や不正行為などの異常な動作を特定したりします。
音楽発見ツールなど、予測 AI を中心に構築されたプロダクトもあります。また、予測 AI によって、パーソナライズされたおすすめ情報が表示されるストリーミング ウェブサイトなど、決定論的なエクスペリエンスが強化される場合もあります。予測 AI は、強力な内部イネーブラーにもなります。予測 AI を使用して、プロダクト データとユーザーデータを分析し、分析情報を明らかにして、よりスマートな次のアクションを導き出すことができます。
予測 AI ループ
予測 AI システムの開発は、機会の定義、データの準備、モデルのトレーニング、モデルの評価、モデルのデプロイという反復サイクルに従います。
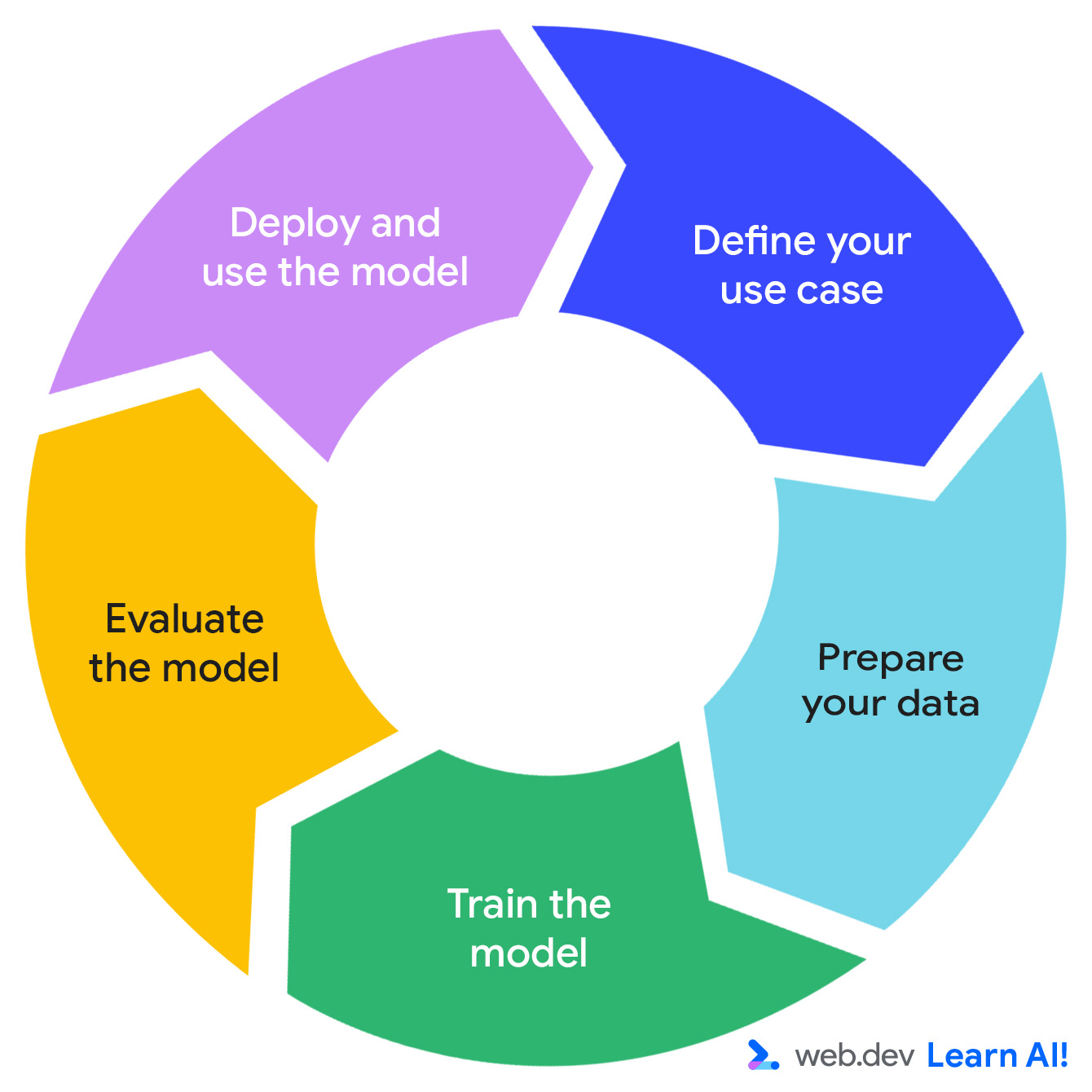
サブスクリプション ベースの生産性向上アプリ「Do All The Things」を開発しているとします。ページビュー、セッション時間、機能の使用状況、定期購入の更新などの使用状況データはすでに収集しています。ここで、データからより実用的な価値を引き出したいと考えます。予測 AI ループをたどる方法は次のとおりです。
ユースケースを定義する

{kind=link}
過去 3 か月間で離脱率が上昇しています。ユーザーが解約した後に対応するのではなく、予測 AI を使用して、解約する可能性の高いユーザーを解約前に特定します。この目標は、顧客成功チームを早期シグナルでサポートし、リスクのあるユーザーを維持するための的を絞った事前対応策を講じられるようにすることです。
予測 AI のユースケースを定義する場合は、まずデータで回答できる質問であることを確認します。これは、すでに収集したデータでも、今後現実的に収集できるデータでもかまいません。このステップでは、予測が有意義で実用的なものになるように、カスタマー サクセス、成長、マーケティングなどのチームのドメイン エキスパートとの連携が必要になることがよくあります。
明確な問題定義では、次の点を指定する必要があります。
- 目標: どのようなビジネス上の成果に影響を与えようとしていますか?たとえば、プロアクティブなアウトリーチを有効にして、顧客離れを減らしたいとします。
- 入力データ: モデルは過去のどのようなシグナルから学習しますか?たとえば、使用パターン、プランタイプ、サポート インタラクションを指定します。
- 出力: モデルはどのような出力を生成しますか?たとえば、各ユーザーの離反確率スコアをモデルで作成するとします。
- ユーザー: 予測を使用または実行するユーザー。たとえば、このデータはカスタマー サクセス マネージャーを対象としています。
- 成功基準: 貢献をどのように測定するか。たとえば、解約率が低下したかどうかを判断するために、継続率を測定します。
これらの詳細を最初に特定することで、技術的には優れているものの、実際には使用されないカスタムモデルを構築するという一般的な落とし穴を回避できます。
データを準備する
モデルに有用な学習シグナルを提供するには、過去のデータに理想的な予測のラベルを付ける必要があります。Do All The Things ユーザーに「解約した」または「解約していない」というラベルを付けます。
次に、カスタマー サクセス チームと協力して、解約予測に最も関連性の高い行動特徴を特定します。データセットをこれらのキー機能に絞り込み、不要なフィールドを削除して、モデルがノイズに対処する必要がないようにします。データ プライバシーを考慮することを忘れないでください。名前やメールアドレスなどの個人情報(PII)を削除し、集計された行動データのみを保存します。
次の表は、結果のデータセットの抜粋を示しています。
user_id |
plan_type |
avg_session_time (min) |
logins_last_30d |
features_used |
support_tickets |
churned |
| 00123 | プレミアム | 12.4 | 22 | 5 | 0 | 0 |
| 00124 | トライアル | 5.8 | 3 | 1 | 2 | 1 |
| 00125 | 無料 | 18.1 | 30 | 7 | 0 | 0 |
| 00126 | プレミアム | 9.7 | 12 | 4 | 1 | 0 |
| 00127 | トライアル | 4.2 | 2 | 1 | 3 | 1 |
これにより、モデルにはクリーンな数値入力とカテゴリ入力(plan_type や avg_session_time など)と、明確なターゲット ラベル(churned)が提供されます。カテゴリは一意の数値識別子に変換する必要があります。
最後に、データセットを 3 つのサブセットに分割します。
- モデルを学習させるためのトレーニング セット(通常は約 70 ~ 80%)。
- ハイパーパラメータを調整し、過学習を防ぐための検証セット(開発セットとも呼ばれます)。
- テストセットを使用して、完全に未知のデータに対するモデルのパフォーマンスを評価します。
これにより、モデルは過去の例を記憶するのではなく、意思決定を一般化できます。
モデルのトレーニング
大規模な事前トレーニング済みモデルに基づいて構築されることが多い生成 AI とは異なり、ほとんどの予測 AI システムは自己トレーニング モデルに依存しています。これは、予測タスクがプロダクトとユーザーに非常に固有のものであるためです。scikit-learn(Python)、AutoML(ノーコードまたはローコード)、TensorFlow.js(JavaScript)などのツールを使用すると、基盤となる数学を気にすることなく、予測モデルのトレーニングと評価を簡単に行うことができます。
解約の例では、クリーンアップされたトレーニング セットを教師ありの分類アルゴリズム(ロジスティック回帰やニューラル ネットワークなど)に渡します。複数のオプションを試して、データに最適な方法を特定します。
モデルは、どの行動パターンが解約と相関関係があるかを学習します。最後に、各ユーザーに確率スコアを割り当てることができます。たとえば、ユーザー X が翌月に解約するリスクは 72% です。
トレーニングの各イテレーションの後、検証セットを使用して結果のモデルを評価します。モデルのパフォーマンスは、ハイパーパラメータを調整するだけでなく、データセットに的を絞った改善を加えることでも向上させることができます。
モデルを評価する
データセット内のラベルは、モデルの出力を比較できるグラウンド トゥルースを提供します。追跡する主な指標は次のとおりです。
- 適合率: 「離脱」とフラグが付けられたユーザーのうち、実際に離脱したユーザーの割合。
- 再現率: 離脱したユーザーのうち、モデルが検出したユーザーの割合。
- F1 スコア: 適合率と再現率のバランスを取る単一の数値。一方を犠牲にして他方を過度に最適化することなく、精度の全体的な指標が必要な場合に便利です。
偽陽性が多すぎると、ユーザー維持の取り組みが無駄になり、偽陰性が多すぎると、顧客を失うことになります。適切なトレードオフは、ビジネスの優先順位によって異なります。たとえば、離脱するユーザーをより多くキャッチできる可能性が高まるのであれば、誤報が数件発生しても構わないと考える企業もあるでしょう。
モデルをデプロイして維持する
検証が完了したら、API または分析ダッシュボードに統合された軽量のクライアントサイド サービスとしてモデルをデプロイできます。毎日、ユーザーをスコアリングして解約リスクの可視化を更新し、チームがアウトリーチの優先順位付けを行えるようにします。正確性と信頼性を維持するには、機械学習運用チーム(MLOps)から次の教訓を学びましょう。
- データドリフトをモニタリングする: ユーザーの行動が変化し、トレーニング データが現実を反映しなくなったタイミングを検出します。
- たとえば、UI の大幅な再設計をリリースした後、ユーザーが機能の操作方法を変えたため、離脱予測の精度が低下したとします。
- 間違いから学ぶ: 誤予測の背後にある一般的なパターンを特定し、次のトレーニング サイクルを改善するためのターゲット例を追加します。
- たとえば、パワーユーザーはサポート チケットを多数開くため、モデルがチャーンのリスクとして頻繁にフラグを立てます。レビュー後、トラブルシューティングと離脱を区別する新機能を追加します。
- 定期的に再トレーニングする: パフォーマンスが安定しているように見えても、季節的なパターン、商品の更新、価格の変更を考慮して、モデルを定期的に更新します。
- たとえば、年間プランを導入した後にモデルを再トレーニングします。これは、料金体系の変更によって更新前のユーザーの行動が変わるためです。
このライフサイクルは予測 AI のバックボーンです。MLflow や Weights & Biases などのツールを使用すると、ML の深い専門知識がなくてもこのプロセスを実行できます。
一般的な問題と軽減策
エラーは発生することがありますが、パフォーマンスとユーザーの信頼を損なう可能性のある一般的な根本原因を防ぐことができます。
- 低品質のデータ: 入力データにノイズが含まれている場合や、データが不完全な場合、予測も同様になります。軽減するには、トレーニングの前にデータを可視化して検証します。必要な学習シグナルがあることを確認し、欠損値を処理します。本番環境でデータ品質をモニタリングする。
過学習: モデルはトレーニング データでは非常に優れたパフォーマンスを発揮しますが、新しいケースでは失敗します。軽減するには、交差検証、正則化、ホールドアウト データセットを使用します。これにより、モデルはトレーニング サンプルを超えて一般化できます。
データドリフト: ユーザーの行動や環境が変化しても、モデルは変化しません。軽減策として、再トレーニングをスケジュールし、精度が低下し始めたときに検出するモニタリングを追加します。
悪い指標: 全体的な精度は、必ずしもユーザーの優先順位を反映しているとは限りません。たとえば、特定のエラーの「コスト」がより重要になる場合があります。不正行為の検出では、不正行為のケースを見逃す(偽陰性)ことは、無実のケースにフラグを設定する(偽陽性)ことよりもはるかに悪いことです。軽減するには、不正行為検出の実際の目標に合わせて指標を調整します。
これらの問題のほとんどは致命的ではありません。システムを段階的にリリースし、問題が発生したら対処します。
このリーンで柔軟なアプローチの鍵は、オブザーバビリティです。モデルをバージョン管理し、モデルの構築に使用された精度特性とツールを記録し、経時的なパフォーマンスを追跡し、モニタリングをアクティブな状態に保ちます。何か問題が発生した場合、ユーザーが気付く前に問題を検知して修正できます。
要点
予測 AI は、既存のデータを予測に変換し、次に何が起こる可能性が高いか、どこで行動すべきかを明らかにします。これは、最も具体的で測定可能な AI の形式です。データで表現できる明確な問題に焦点を当て、プロダクトの進化に合わせて繰り返しを行い、パフォーマンスを長期的にモニタリングします。
次のモジュールでは、利用可能なデータに基づいて新しいものを作成するのに役立つ生成 AI について学習します。
リソース
予測 AI の背後にある数学について理解したい場合は、次のリソースを確認することをおすすめします。
- 分類、線形回帰、ロジスティック回帰に関する機械学習集中講座。
- コースの作成者である Janna Lipenkova は、The Art of AI Product Development: Delivering Business Value の第 4 章で予測 AI について詳しく説明しています。
- Stuart Jonathan Russell と Peter Norvig による Artificial Intelligence: A Modern Approach。この書籍は 1995 年に初版が発行され、2021 年に最新版が発行されました。AI エンジニアリング プログラムで一般的に教えられています。
- Christopher M. Bishop 著の Pattern Recognition and Machine LearningBishop 著の書籍は、予測 AI の学習に包括的かつ学術的なアプローチを提供します。
理解度を確認する
予測 AI の主な機能は何ですか?
パターンに基づいてアイテムを事前定義されたカテゴリにグループ化するタスクはどれですか?
「予測 AI ループ」で、データセットをトレーニング セット、検証セット、テストセットに分割する必要があるのはなぜですか?
適合率と再現率のバランスを取り、精度の全体的な指標を提供する指標はどれですか?
データドリフトとは何ですか?どのように軽減すればよいですか?