

发布时间:2024 年 10 月 21 日
通过展示商品评价,网店的转化次数可提高 270% 。负面评价也很重要,因为它们有助于建立信誉。82% 的在线买家会在购买前查看评价。
鼓励客户留下有用的商品评价(尤其是负面评价)可能很棘手。在本博文中,我们将探讨如何使用生成式 AI 帮助用户撰写信息丰富的评价,从而帮助他人做出购买决定。
演示和代码
试用我们的商品评价演示,并在 GitHub 上查看代码。
此功能的构建方式
客户端 AI
在本演示中,我们在客户端实现了此功能,原因如下:
- 延迟时间。我们希望在用户停止输入后立即提供建议。我们可以通过避免服务器往返来实现这一点。
- 费用。 虽然这只是一个演示,但如果您考虑在正式版中发布类似功能,不妨先进行实验,在没有任何服务器端开销的情况下验证该功能是否适合您的用户。
MediaPipe 生成式 AI
我们之所以选择通过 MediaPipe LLM Inference API(MediaPipe GenAI 软件包)使用 Gemma 2B 模型,是因为:
- 模型准确性:Gemma 2B 在大小和准确性方面取得了极佳的平衡。在适当的提示下,它为此演示提供了令人满意的结果。
- 跨浏览器支持:所有支持 WebGPU 的浏览器都支持 MediaPipe。
用户体验
应用性能最佳实践
虽然 Gemma 2B 是一款小型 LLM,但下载量仍然很大。 应用性能最佳实践,包括使用 Web Worker。
将功能设为可选
我们希望利用 AI 技术提供的评价建议来优化用户发布商品评价的工作流程。在我们的实现中,即使模型尚未加载,因此无法提供改进提示,用户也可以发布评价。

界面状态和动画
推理通常需要的时间比即时感觉要长,因此我们会向用户发出模型正在运行推理或“思考”的信号。我们使用动画来缓解等待时间,同时向用户保证应用正在按预期运行。了解我们在演示中实现的不同界面状态,这些状态由 Adam Argyle 设计。
其他注意事项
在生产环境中,您可能需要:
- 提供反馈机制。如果建议不太理想或不合理,该怎么办?实现快速反馈机制(例如点赞和不赞),并依靠启发词语来确定用户认为有用的内容。例如,评估有多少用户在与该功能互动,以及他们是否会将其关闭。
- 允许用户选择停用。如果用户更喜欢不使用 AI 协助而使用自己的字词,或者觉得该功能很烦人,该怎么办?允许用户根据需要选择停用和重新启用。
- 说明此功能的存在原因。简短的说明可能会鼓励用户使用反馈工具。例如,“更好的反馈有助于其他买家决定购买什么,也有助于我们打造您想要的产品。”您可以添加详细说明,介绍该功能的运作方式以及您提供该功能的原因,例如添加指向“了解详情”链接。
- 在适当情况下披露 AI 使用情况。借助客户端 AI,系统不会将用户的内容发送到服务器进行处理,因此可以保持私密性。不过,如果您构建了服务器端回退或以其他方式使用 AI 收集信息,不妨考虑将相关信息添加到隐私权政策、服务条款或其他位置。
实现
我们实现的产品评价建议功能适用于各种应用场景。请将以下信息视为您日后构建客户端 AI 功能的基础。
网页工作器中的 MediaPipe
借助 MediaPipe LLM 推理,AI 代码只需几行:通过向其传递模型网址来创建文件解析器和 LLM 推理对象,然后使用该 LLM 推理实例生成响应。
不过,我们的代码示例要详尽一些。这是因为它是在 Web Worker 中实现的,因此它会通过自定义消息代码将消息传递给主脚本。详细了解此模式。
// Trigger model preparation *before* the first message arrives
self.postMessage({ code: MESSAGE_CODE.PREPARING_MODEL });
try {
// Create a FilesetResolver instance for GenAI tasks
const genai = await FilesetResolver.forGenAiTasks(MEDIAPIPE_WASM);
// Create an LLM Inference instance from the specified model path
llmInference = await LlmInference.createFromModelPath(genai, MODEL_URL);
self.postMessage({ code: MESSAGE_CODE.MODEL_READY });
} catch (error) {
self.postMessage({ code: MESSAGE_CODE.MODEL_ERROR });
}
// Trigger inference upon receiving a message from the main script
self.onmessage = async function (message) {
// Run inference = Generate an LLM response
let response = null;
try {
response = await llmInference.generateResponse(
// Create a prompt based on message.data, which is the actual review
// draft the user has written. generatePrompt is a local utility function.
generatePrompt(message.data),
);
} catch (error) {
self.postMessage({ code: MESSAGE_CODE.INFERENCE_ERROR });
return;
}
// Parse and process the output using a local utility function
const reviewHelperOutput = generateReviewHelperOutput(response);
// Post a message to the main thread
self.postMessage({
code: MESSAGE_CODE.RESPONSE_READY,
payload: reviewHelperOutput,
});
};
export const MESSAGE_CODE ={
PREPARING_MODEL: 'preparing-model',
MODEL_READY: 'model-ready',
GENERATING_RESPONSE: 'generating-response',
RESPONSE_READY: 'response-ready',
MODEL_ERROR: 'model-error',
INFERENCE_ERROR: 'inference-error',
};
输入和输出

我们的完整提示是使用少样本提示构建的。其中包括用户的输入,也就是用户撰写的评价草稿。
为了根据用户输入生成提示,我们会在运行时调用实用程序函数 generatePrompt。
与服务器端 AI 相比,客户端 AI 模型和库通常附带的工具较少。例如,JSON 模式通常不可用。这意味着,我们需要在问题中提供所需的输出结构。与通过模型配置提供架构相比,这种方法的清晰性、可维护性和可靠性较低。此外,客户端模型通常较小,这意味着它们更容易在输出中出现结构错误。
在实践中,我们发现与 JSON 或 JavaScript 相比,Gemma 2B 在以文本形式提供结构化输出方面表现更好。因此,在本演示中,我们选择了基于文本的输出格式。模型会生成文本,然后我们将输出解析为 JavaScript 对象,以便在 Web 应用中进行进一步处理。
改进问题
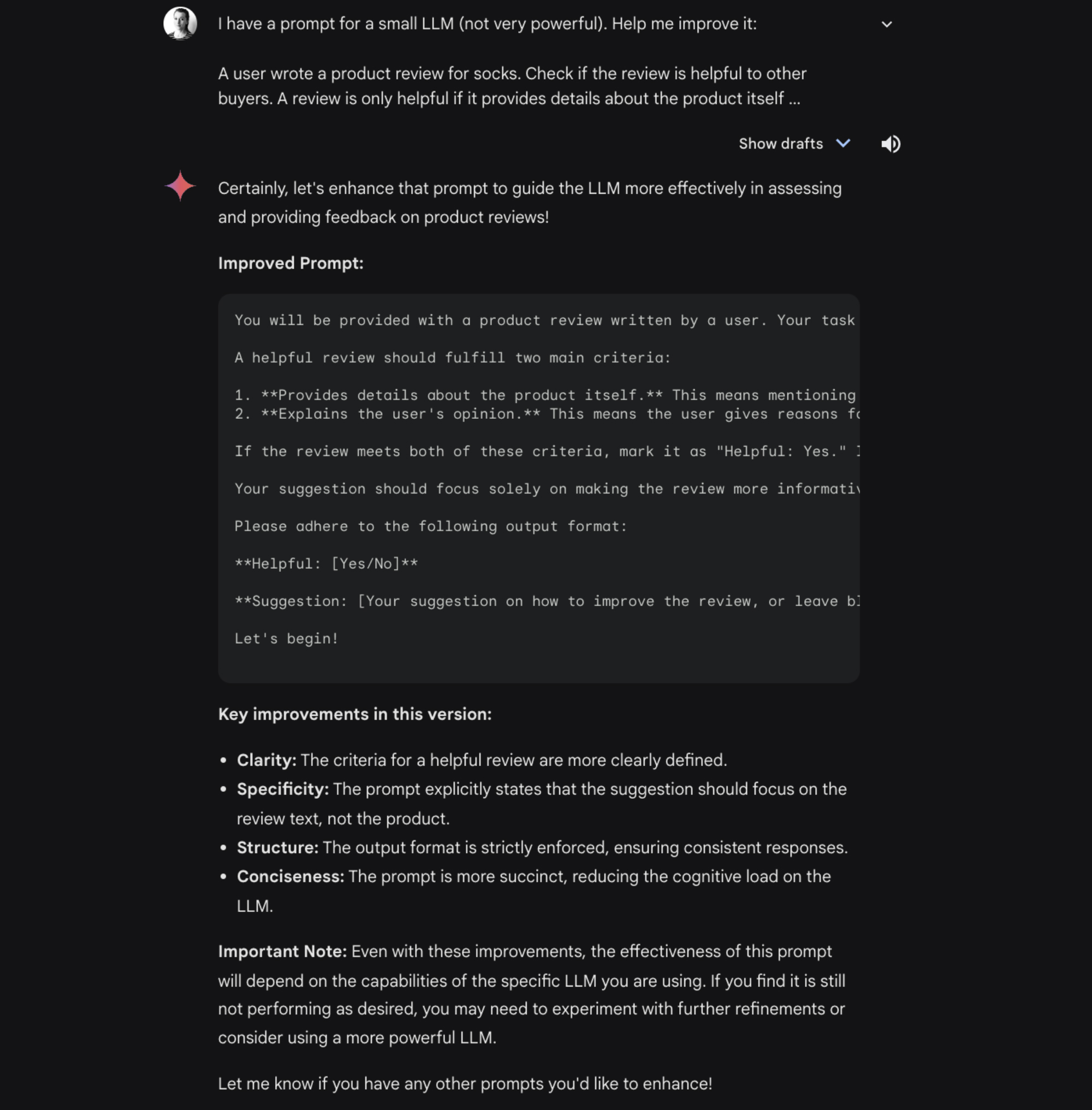
我们使用 LLM 迭代提示。
- 少样本提示。为了为少样本提示生成示例,我们依赖于 Gemini Chat。Gemini Chat 使用最强大的 Gemini 模型。这确保了我们生成了高质量的示例。
- 优化提示。问题结构确定后,我们还使用 Gemini Chat 优化了问题。这提高了输出质量。
利用情境信息提高质量
在问题中添加商品类型有助于模型提供更相关、更优质的建议。在此演示中,商品类型为静态。 在真实应用中,您可以根据用户正在访问的页面,将商品动态添加到提示中。
Review: "I love these."
Helpful: No
Fix: Be more specific, explain why you like these **socks**.
Example: "I love the blend of wool in these socks. Warm and not too heavy."
问题提示的“少样本”部分中的示例之一:建议的修复方法和示例评价中都包含商品类型(“袜子”)。
LLM 问题和解决方法
与功能更强大、体量更大的服务器端模型相比,Gemma 2B 通常需要更多提示工程。
我们在使用 Gemma 2B 时遇到了一些问题。我们改进了结果的方式如下:
- 太客气了。Gemma 2B 很难将评价标记为“无用”,似乎不愿做出判断。我们尝试让标签语言更中性化(使用“具体”和“不具体”而非“有用”和“无用”),并添加了示例,但效果没有改善。提高结果质量的方法是,在问题中坚持和重复。思维链方法也可能会带来改进。
说明不明确。模型有时会过度解读问题。系统没有评估评价,而是继续显示示例列表。为解决此问题,我们在提示中添加了清晰的过渡:
I'll give you example reviews and outputs, and then give you one review to analyze. Let's go: Examples: <... Examples> Review to analyze: <... User input>清晰地构建提示有助于模型区分示例列表(少量镜头)和实际输入。
目标错误。有时,模型会建议更改商品,而不是评价文本。例如,对于评价“我讨厌这些袜子”,模型可能会建议“考虑换个品牌或款式的袜子”,这并不是预期的效果。拆分问题有助于阐明任务,并提高模型对评价的专注度。