
前回のモジュールでは、ウェブ ワーカーの概要について説明しました。ウェブ ワーカーは、JavaScript をメインスレッドから別のウェブ ワーカー スレッドに移動することで、入力の応答性を高めることができます。これにより、メインスレッドに直接アクセスする必要のない作業がある場合に、ウェブサイトのインタラクションから次の描画までの時間(INP)を改善できます。ただし、概要だけでは十分ではありません。このモジュールでは、ウェブ ワーカーの具体的なユースケースを紹介します。
たとえば、画像から Exif メタデータを削除する必要があるウェブサイトが考えられます。これは、それほど突飛なコンセプトではありません。実際、Flickr などのウェブサイトでは、ユーザーが Exif メタデータを表示して、ホストされている画像の技術的な詳細(色深度、カメラのメーカーとモデルなど)を確認できるようになっています。
ただし、画像をフェッチして ArrayBuffer に変換し、Exif メタデータを抽出するロジックをすべてメインスレッドで実行すると、コストが高くなる可能性があります。幸いなことに、ウェブ ワーカーのスコープでは、この処理をメインスレッドから外して実行できます。次に、ウェブ ワーカーのメッセージ パイプラインを使用して、Exif メタデータが HTML 文字列としてメインスレッドに送信され、ユーザーに表示されます。
ウェブ ワーカーを使用しない場合のメインスレッド
まず、ウェブ ワーカーを使用せずにこの処理を行った場合のメインスレッドの様子を確認します。これを行う方法は次のとおりです。
- Chrome で新しいタブを開き、その DevTools を開きます。
- パフォーマンス パネルを開きます。
- https://chrome.dev/learn-performance-exif-worker/without-worker.html に移動します。
- パフォーマンス パネルで、DevTools ペインの右上にある [Record] をクリックします。
- フィールドにこの画像リンク(または Exif メタデータを含む別の画像リンク)を貼り付け、[Get that JPEG!] ボタンをクリックします。
- インターフェースに Exif メタデータが入力されたら、[Record] をもう一度クリックして録画を停止します。
{kind=link}
ラスタライザー スレッドなどの他のスレッドが存在する場合を除き、アプリ内のすべての処理はメインスレッドで実行されます。メインスレッドでは、次の処理が行われます。
- フォームは入力を受け取り、
fetchリクエストをディスパッチして、Exif メタデータを含む画像の最初の部分を取得します。 - 画像データは
ArrayBufferに変換されます。 exif-readerスクリプトは、画像から Exif メタデータを抽出するために使用されます。- メタデータがスクレイピングされて HTML 文字列が構築され、メタデータ ビューアにデータが入力されます。
次に、同じ動作をウェブ ワーカーを使用して実装した場合を見てみましょう。
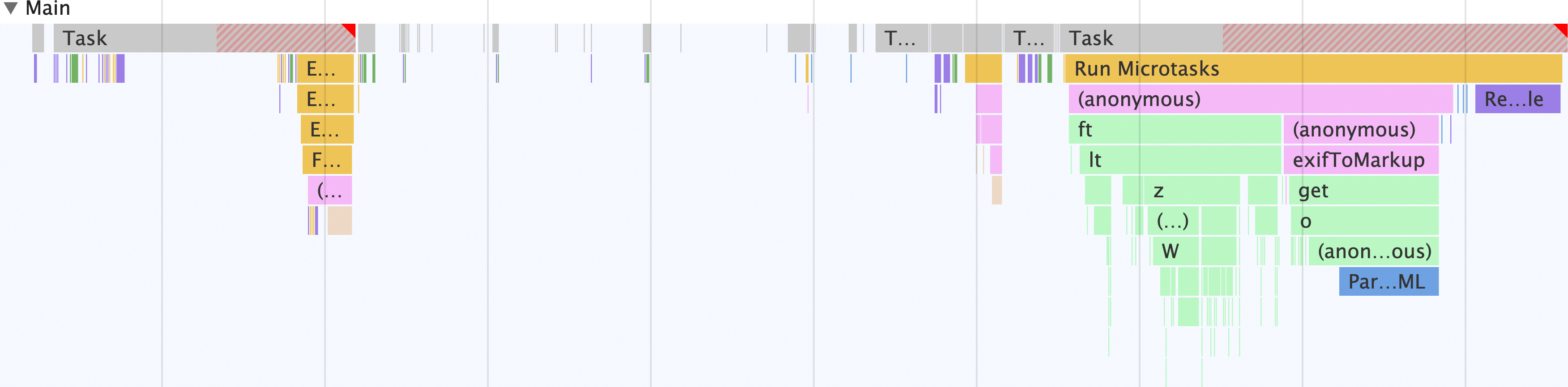
ウェブ ワーカーありのメインスレッド
メインスレッドで JPEG ファイルから Exif メタデータを抽出する際の処理を確認しました。次に、ウェブ ワーカーが関与する場合の処理を見てみましょう。
- Chrome で別のタブを開き、その DevTools を開きます。
- パフォーマンス パネルを開きます。
- https://chrome.dev/learn-performance-exif-worker/with-worker.html に移動します。
- パフォーマンス パネルで、DevTools ペインの右上にある録画ボタンをクリックします。
- フィールドにこの画像リンクを貼り付け、[Get that JPEG!] ボタンをクリックします。
- インターフェースに Exif メタデータが入力されたら、もう一度録画ボタンをクリックして録画を停止します。

これがウェブ ワーカーの力です。メインスレッドですべてを行うのではなく、メタデータ ビューアへの HTML の入力以外のすべてが別のスレッドで行われます。つまり、メインスレッドは他の処理を実行できるようになります。
ここで最も大きなメリットは、ウェブ ワーカーを使用しないこのアプリのバージョンとは異なり、exif-reader スクリプトがメインスレッドではなくウェブ ワーカー スレッドに読み込まれることです。つまり、exif-reader スクリプトのダウンロード、解析、コンパイルのコストはメインスレッド外で発生します。
それでは、これらを実現するウェブ ワーカーのコードを見ていきましょう。
ウェブ ワーカーコードの概要
ウェブ ワーカーの差を確認するだけでは不十分です。少なくともこのケースでは、ウェブ ワーカーのスコープで何が可能かを知るために、コードがどのようなものか理解しておく必要があります。
ウェブ ワーカーが処理を開始する前に実行する必要があるメインスレッドのコードから始めます。
// scripts.js
// Register the Exif reader web worker:
const exifWorker = new Worker('/js/with-worker/exif-worker.js');
// We have to send image requests through this proxy due to CORS limitations:
const imageFetchPrefix = 'https://res.cloudinary.com/demo/image/fetch/';
// Necessary elements we need to select:
const imageFetchPanel = document.getElementById('image-fetch');
const imageExifDataPanel = document.getElementById('image-exif-data');
const exifDataPanel = document.getElementById('exif-data');
const imageInput = document.getElementById('image-url');
// What to do when the form is submitted.
document.getElementById('image-form').addEventListener('submit', event => {
// Don't let the form submit by default:
event.preventDefault();
// Send the image URL to the web worker on submit:
exifWorker.postMessage(`${imageFetchPrefix}${imageInput.value}`);
});
// This listens for the Exif metadata to come back from the web worker:
exifWorker.addEventListener('message', ({ data }) => {
// This populates the Exif metadata viewer:
exifDataPanel.innerHTML = data.message;
imageFetchPanel.style.display = 'none';
imageExifDataPanel.style.display = 'block';
});
このコードはメインスレッドで実行され、画像 URL をウェブ ワーカーに送信するようにフォームを設定します。そこから、ウェブ ワーカーコードは外部 exif-reader スクリプトを読み込む importScripts ステートメントで始まり、メインスレッドへのメッセージ パイプラインを設定します。
// exif-worker.js
// Import the exif-reader script:
importScripts('/js/with-worker/exifreader.js');
// Set up a messaging pipeline to send the Exif data to the `window`:
self.addEventListener('message', ({ data }) => {
getExifDataFromImage(data).then(status => {
self.postMessage(status);
});
});
この JavaScript は、ユーザーが JPEG ファイルの URL を含むフォームを送信したときに、その URL がウェブ ワーカーに届くようにメッセージ パイプラインを設定します。次のコードは、JPEG ファイルから Exif メタデータを抽出し、HTML 文字列を構築して、その HTML を window に送り返し、最終的にユーザーに表示します。
// Takes a blob to transform the image data into an `ArrayBuffer`:
// NOTE: these promises are simplified for readability, and don't include
// rejections on failures. Check out the complete web worker code:
// https://chrome.dev/learn-performance-exif-worker/js/with-worker/exif-worker.js
const readBlobAsArrayBuffer = blob => new Promise(resolve => {
const reader = new FileReader();
reader.onload = () => {
resolve(reader.result);
};
reader.readAsArrayBuffer(blob);
});
// Takes the Exif metadata and converts it to a markup string to
// display in the Exif metadata viewer in the DOM:
const exifToMarkup = exif => Object.entries(exif).map(([exifNode, exifData]) => {
return `
<details>
<summary>
<h2>${exifNode}</h2>
</summary>
<p>${exifNode === 'base64' ? `<img src="data:image/jpeg;base64,${exifData}">` : typeof exifData.value === 'undefined' ? exifData : exifData.description || exifData.value}</p>
</details>
`;
}).join('');
// Fetches a partial image and gets its Exif data
const getExifDataFromImage = imageUrl => new Promise(resolve => {
fetch(imageUrl, {
headers: {
// Use a range request to only download the first 64 KiB of an image.
// This ensures bandwidth isn't wasted by downloading what may be a huge
// JPEG file when all that's needed is the metadata.
'Range': `bytes=0-${2 ** 10 * 64}`
}
}).then(response => {
if (response.ok) {
return response.clone().blob();
}
}).then(responseBlob => {
readBlobAsArrayBuffer(responseBlob).then(arrayBuffer => {
const tags = ExifReader.load(arrayBuffer, {
expanded: true
});
resolve({
status: true,
message: Object.values(tags).map(tag => exifToMarkup(tag)).join('')
});
});
});
});
少し長いですが、ウェブ ワーカーのかなり複雑なユースケースでもあります。ただし、結果は作業に見合うものであり、このユースケースに限定されるものではありません。ウェブ ワーカーは、fetch 呼び出しの分離とレスポンスの処理、メインスレッドをブロックせずに大量のデータを処理するなど、さまざまな用途に使用できます。
ウェブ アプリケーションのパフォーマンスを改善する場合は、ウェブ ワーカー コンテキストで合理的に実行できることを検討することから始めます。この改善は大きな効果をもたらし、ウェブサイトの全体的なユーザー エクスペリエンスの向上につながります。