
AI (בינה מלאכותית) חיזוי או אנליטי הוא אוסף של אלגוריתמים שעוזרים לכם להבין נתונים קיימים ולחזות מה צפוי לקרות בהמשך. על סמך דפוסים היסטוריים, מודלים של AI לחיזוי לומדים משימות אנליטיות שונות שעוזרות למשתמשים להבין את הנתונים שלהם:
- סיווג: קיבוץ פריטים לקטגוריות מוגדרות מראש על סמך דפוסים בנתונים. לדוגמה, חנות אונליין יכולה לסווג מבקרים לפי כוונת הרכישה שלהם (מחקר, רכישה, החזרות), כדי להתאים את ההמלצות שלה בהתאם.
- רגרסיה: חיזוי ערכים מספריים, כמו שיעור המעורבות, משך הזמן של הסשן או הסבירות להמרה.
- המלצה: הצעה של פריטים שהכי רלוונטיים למשתמש או להקשר מסוים. אפשר לחשוב על זה כמו "משתמשים כמוך צפו גם ב…" או "הדרכות מומלצות בהתאם להתקדמות שלך".
- חיזוי וזיהוי אנומליות: המודל חוזה אירועים עתידיים, כמו עלייה חדה בתנועה, או מזהה התנהגות חריגה, כמו אנומליות בתשלומים או הונאה.
חלק מהמוצרים מבוססים לחלוטין על AI ניבויי, כמו כלים לגילוי מוזיקה. במקרים אחרים, AI חיזוי משפר חוויה דטרמיניסטית, כמו אתר סטרימינג עם המלצות מותאמות אישית. AI חיזוי יכול גם להיות כלי פנימי רב עוצמה: אפשר להשתמש בו כדי לנתח נתוני מוצרים ומשתמשים, לקבל תובנות ולבצע פעולות חכמות יותר.
הלולאה של AI חיזוי
פיתוח של מערכת AI לחיזוי מתבצע במחזור איטרטיבי: הגדרת ההזדמנות, הכנת הנתונים, אימון המודל, הערכת המודל, ופריסת המודל.
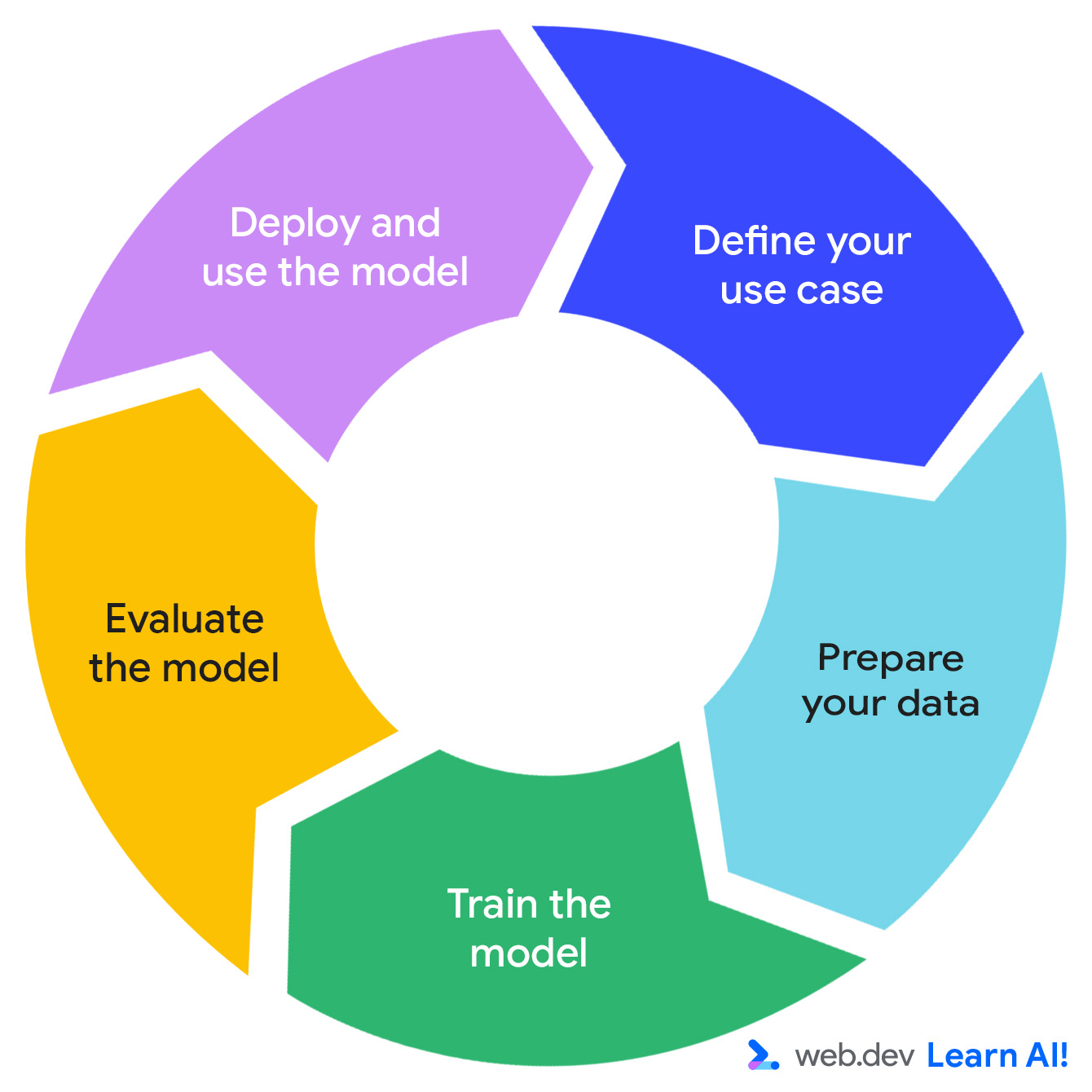
נניח שאתם עובדים על אפליקציה לשיפור הפרודוקטיביות שמבוססת על מינוי, Do All The Things. אתם כבר אוספים נתוני שימוש כמו צפיות בדפים, משך הסשן, שימוש בתכונות וחידושי מינוי. עכשיו אתם רוצים לחלץ מהנתונים ערך שימושי יותר. כך מתבצעת התנועה בלולאת הבינה המלאכותית החזויה.
הגדרת תרחיש השימוש

{kind=link}
שיעור הנטישה שלך עלה ב-3 החודשים האחרונים. במקום להגיב אחרי שהמשתמשים מבטלים את המינוי, אתם רוצים להשתמש ב-AI חיזוי כדי לזהות משתמשים שסביר שיבטלו את המינוי לפני שהם עושים את זה. המטרה היא לספק לצוות הצלחת הלקוח אותות מוקדמים, כדי שהוא יוכל לנקוט פעולות ממוקדות ויזומות לשימור משתמשים בסיכון.
כשמגדירים תרחיש לדוגמה של AI גנרטיבי, מתחילים באימות האפשרות לענות על השאלה באמצעות נתונים. אלה יכולים להיות נתונים שכבר אספתם או נתונים שתוכלו לאסוף בעתיד. לרוב, השלב הזה דורש שיתוף פעולה עם מומחים בתחום, כמו צוותים של הצלחת לקוחות, צמיחה או שיווק, כדי לוודא שהתחזית משמעותית וניתנת ליישום.
הגדרת בעיה טובה צריכה לכלול את הפרטים הבאים:
- יעד: איזו תוצאה עסקית אתם מנסים להשפיע עליה? לדוגמה, אתם רוצים לצמצם את שיעור הנטישה על ידי הפעלת פנייה יזומה ללקוחות.
- נתוני קלט: אילו אותות היסטוריים המודל לומד מהם? לדוגמה, אתם מספקים דפוסי שימוש, סוגי תוכניות ואינטראקציות עם התמיכה.
- פלט: מה המודל יפיק? לדוגמה, אתם רוצים שהמודל ייצור לכל משתמש ציון של הסתברות לנטישה.
- משתמש: מי משתמש בתחזית או פועל לפיה? לדוגמה, הנתונים האלה מיועדים למנהלי הצלחת לקוחות.
- קריטריונים להצלחה: איך מודדים את ההשפעה? לדוגמה, אתם מודדים את שיעור שימור הלקוחות כדי לקבוע אם הצלחתם להפחית את נטישת הלקוחות.
אם תזהו את הפרטים האלה בהתחלה, תוכלו להימנע ממלכודת נפוצה: בניית מודל בהתאמה אישית שהוא תקין מבחינה טכנית, אבל אף פעם לא נעשה בו שימוש.
הכנת הנתונים
כדי לספק למודל אותות למידה שימושיים, צריך להוסיף תוויות לנתונים ההיסטוריים עם חיזויים אידיאליים. התווית Do All The Things משמשת לסימון משתמשים כ'עזבו' או כ'לא עזבו'.
לאחר מכן, כדאי לשתף פעולה עם צוות הצלחת הלקוחות כדי לזהות אילו תכונות התנהגותיות רלוונטיות ביותר לחיזוי נטישה. כדאי לצמצם את מערך הנתונים לתכונות המרכזיות האלה ולהסיר שדות מיותרים, כדי שהמודל לא יצטרך להתמודד עם רעשי רקע. חשוב לזכור את נושא פרטיות הנתונים. הסרת פרטים אישיים מזהים (PII), כמו שמות או כתובות אימייל, ואחסון רק של נתונים מצטברים על התנהגות.
בטבלה הבאה מוצג קטע ממערך הנתונים שמתקבל:
user_id |
plan_type |
avg_session_time (min) |
logins_last_30d |
features_used |
support_tickets |
churned |
| 00123 | פרימיום | 12.4 | 22 | 5 | 0 | 0 |
| 00124 | ל-Google AI Pro | 5.8 | 3 | 1 | 2 | 1 |
| 00125 | בחינם | 18.1 | 30 | 7 | 0 | 0 |
| 00126 | פרימיום | 9.7 | 12 | 4 | 1 | 0 |
| 00127 | ל-Google AI Pro | 4.2 | 2 | 1 | 3 | 1 |
כך מקבלים מודל עם קלט מספרי וקלט קטגורי נקיים (כמו plan_type או avg_session_time) ותווית יעד ברורה (churned). צריך להמיר את הקטגוריות למזהים מספריים ייחודיים.
לבסוף, מפצלים את מערך הנתונים לשלוש קבוצות משנה:
- קבוצת אימון (בדרך כלל כ-70% עד 80%) לאימון המודל,
- קבוצת אימות (לפעמים נקראת גם קבוצת פיתוח) לשיפור היפרפרמטרים ולמניעת התאמת יתר.
- קבוצת בדיקה להערכת הביצועים של המודל על נתונים שלא נראו קודם.
כך המודל יכול להכליל החלטות במקום להסתמך על דוגמאות היסטוריות שהוא זוכר.
אימון המודל
בשונה מבינה מלאכותית גנרטיבית, שמבוססת לרוב על מודלים גדולים שעברו אימון מקדים, רוב מערכות הבינה המלאכותית לחיזוי מסתמכות על מודלים שעברו אימון עצמי. הסיבה לכך היא שמשימות חיזויות ספציפיות מאוד למוצר ולמשתמשים שלכם. כלים כמו scikit-learn (Python), AutoML (ללא קוד או עם קוד מועט) או TensorFlow.js (JavaScript) מקלים על אימון והערכה של מודלים לחיזוי בלי לדאוג לגבי המתמטיקה שמתחת לפני השטח.
בדוגמה שלנו לשיעור הנטישה, אנחנו מזינים את מערך האימון הנקי לאלגוריתם סיווג בפיקוח, כמו רגרסיה לוגיסטית או רשת נוירונים. כדאי לנסות כמה אפשרויות כדי להבין מה הכי מתאים לנתונים שלכם.
המודל לומד אילו דפוסי התנהגות קשורים לנטישת לקוחות. בסוף התהליך, המערכת יכולה להקצות לכל משתמש ציון הסתברות. לדוגמה, יש סיכון של 72% שמשתמש X יבטל את המינוי בחודש הבא.
אחרי כל איטרציה של אימון, מעריכים את המודל שנוצר באמצעות קבוצת האימות. אפשר לשפר את הביצועים של מודל על ידי שינוי היפרפרמטרים, וגם על ידי שיפורים ממוקדים של מערך הנתונים.
הערכת המודל
התוויות במערך הנתונים מספקות את האמת הבסיסית שאפשר להשוות אליה את התוצאות של המודל. המדדים העיקריים למעקב הם:
- דיוק: מתוך כל המשתמשים שסומנו כמשתמשים שנטשו את המינוי, כמה מהם באמת נטשו אותו?
- החזרה: מתוך כל המשתמשים שנטשו, כמה המודל זיהה?
- ציון F1: מספר יחיד שמשקלל את הדיוק וההחזרה, שימושי כשרוצים מדד כללי של דיוק בלי לבצע אופטימיזציה מוגזמת של אחד מהם על חשבון השני.
יותר מדי תוצאות חיוביות כוזבות מובילות לבזבוז מאמצי שימור, בעוד שיותר מדי תוצאות שליליות כוזבות מובילות לאובדן לקוחות. הפשרה הנכונה תלויה בסדרי העדיפויות של העסק. לדוגמה, יכול להיות שהחברה שלכם מעדיפה להתמודד עם כמה אזעקות שווא אם זה מגדיל את הסיכוי לתפוס יותר משתמשים לפני שהם עוזבים.
פריסה ותחזוקה של המודל
אחרי האימות, אפשר לפרוס את המודל באמצעות API או כשירות קל משקל בצד הלקוח שמשולב בלוח הבקרה של Analytics. מדי יום, המערכת יכולה לתת ניקוד למשתמשים ולעדכן את התרשים של סיכון הנטישה, כדי שהצוות יוכל לתת עדיפות לפניות למשתמשים. כדי לשמור על דיוק ומהימנות, כדאי לאמץ את הלקחים הבאים מצוותי MLOps (צוותים שעוסקים בתפעול של למידת מכונה):
- מעקב אחרי סחף נתונים: זיהוי של שינויים בהתנהגות המשתמשים, שגורמים לכך שנתוני האימון כבר לא מייצגים את המציאות.
- לדוגמה, אחרי השקת עיצוב מחדש משמעותי של ממשק המשתמש, המשתמשים מקיימים אינטראקציה עם התכונות בצורה שונה, ולכן התחזיות לגבי נטישה הופכות לפחות מדויקות.
- לומדים מהטעויות: מזהים דפוסים נפוצים שגורמים לחיזויים שגויים ומוסיפים דוגמאות ממוקדות כדי לשפר את מחזור האימון הבא.
- לדוגמה, המודל מסמן לעיתים קרובות משתמשים מתקדמים כסיכון לנטישה כי הם פותחים הרבה כרטיסי תמיכה. אחרי הבדיקה, מוסיפים תכונות חדשות שמבחינות בין פתרון בעיות לבין ביטול ההתקשרות.
- אימון מחדש באופן קבוע: גם אם נראה שהביצועים יציבים, כדאי לרענן את המודל מדי פעם כדי להביא בחשבון דפוסים עונתיים, עדכוני מוצרים או שינויים במחירים.
- לדוגמה, אתם מאמנים מחדש את המודל אחרי שאתם משיקים תוכניות שנתיות, כי מבנה התמחור משנה את התנהגות המשתמשים לפני החידוש.
מחזור החיים הזה הוא הבסיס ל-AI חיזוי. בעזרת כלים כמו MLflow ו-Weights & Biases, אתם יכולים להריץ את התהליך הזה בלי ידע מעמיק בלמידת מכונה.
בעיות נפוצות ופתרונות
למרות ששגיאות מדי פעם יקרו, אתם יכולים להתגונן מפני סיבות נפוצות שעלולות לפגוע בביצועים ובאמון המשתמשים:
- נתונים באיכות נמוכה: אם נתוני הקלט שלכם רועשים או לא מלאים, גם התחזיות יהיו כאלה. כדי לצמצם את הסיכון, כדאי להציג את הנתונים באופן חזותי ולאמת אותם לפני האימון. חשוב לוודא שיש לכם את אותות הלמידה הנדרשים ולטפל בערכים חסרים. מעקב אחרי איכות הנתונים בסביבת הייצור.
התאמת יתר (Overfitting): המודל פועל טוב מאוד על נתוני האימון, אבל נכשל במקרים חדשים. כדי לצמצם את הסיכון, כדאי להשתמש באימות צולב, ברגולריזציה ובמערכי נתונים להחזקה. ההגדרה הזו עוזרת למודל ליצור כללים שרלוונטיים לדוגמאות חדשות, מעבר לדוגמאות האימון.
סחף נתונים: התנהגות המשתמשים והסביבות משתנות, אבל המודל לא. כדי לצמצם את הסיכון, כדאי לתזמן אימון מחדש ולהוסיף מעקב כדי לזהות מתי רמת הדיוק מתחילה לרדת.
מדדים לא טובים: רמת הדיוק הכוללת לא תמיד משקפת את סדרי העדיפויות של המשתמשים. לדוגמה, לפעמים חשוב יותר לדעת מה העלות של טעות ספציפית. בזיהוי תרמיות, החמצה של מקרה תרמית (תוצאה שלילית מוטעית) היא הרבה יותר גרועה מסימון של מקרה תמים (תוצאה חיובית מוטעית). כדי לצמצם את הסיכון, צריך להתאים את המדדים למטרות בעולם האמיתי של זיהוי הונאות.
רוב הבעיות האלה לא קריטיות. השקת המערכת צריכה להתבצע בהדרגה, וצריך לטפל בבעיות שמתעוררות.
המפתח לגישה הרזה והגמישה הזו הוא ניראות (observability). כדאי ליצור גרסאות של המודלים, לרשום ביומן את מאפייני הדיוק ואת הכלים ששימשו לבניית המודל, לעקוב אחרי הביצועים לאורך זמן ולהמשיך לעקוב אחרי הפעילות. אם משהו משתבש, תוכלו לזהות את הבעיה ולתקן אותה לפני שהמשתמשים ישימו לב.
העיקריים מהשיחה
AI ניבויי הופך את הנתונים הקיימים שלכם לתובנות לגבי העתיד, ומגלה מה צפוי לקרות בהמשך ואיפה כדאי לפעול. זו הצורה המוחשית והניתנת למדידה ביותר של AI. חשוב להתמקד בבעיות מוגדרות היטב שאפשר לבטא באמצעות נתונים, להמשיך לבצע שיפורים ככל שהמוצר מתפתח ולעקוב אחר הביצועים לאורך זמן.
במודול הבא נלמד על AI גנרטיבי, שעוזר ליצור משהו חדש על סמך הנתונים הזמינים.
משאבים
אם אתם רוצים להבין את המתמטיקה שמאחורי AI חיזוי, מומלץ לעיין במקורות המידע הבאים:
- קורסים מקוצרים על למידת מכונה בנושאים סיווג, רגרסיה לינארית ורגרסיה לוגיסטית.
- מחברת הקורס, ג'אנה ליפנקובה, כתבה עוד על הנושא של AI חיזוי בפרק 4 של The Art of AI Product Development: Delivering Business Value.
- Artificial Intelligence: A Modern Approach (בינה מלאכותית: גישה מודרנית) מאת סטיוארט ג'ונתן ראסל ופיטר נורוויג. הספר הזה פורסם לראשונה בשנת 1995, והמהדורה האחרונה שלו פורסמה בשנת 2021. הוא נלמד בדרך כלל בתוכניות הנדסת AI.
- Pattern Recognition and Machine Learning מאת Christopher M. Bishop, לגישה מקיפה ואקדמית ללמידה של AI ניבויי.
בדיקת ההבנה
מהי הפונקציה העיקרית של AI ניבויי?
באיזו משימה נדרש לקבץ פריטים לקטגוריות מוגדרות מראש על סמך תבניות?
ב-'Predictive AI loop', למה כדאי לפצל את מערך הנתונים לקבוצות אימון, אימות ובדיקה?
איזה מדד מאזן בין דיוק לבין היזכרות כדי לספק מדד כולל של דיוק?
מהי סחף נתונים ואיך אפשר לצמצם אותו?