
ভবিষ্যদ্বাণীমূলক (বা বিশ্লেষণাত্মক) এআই হল অ্যালগরিদমের একটি সংগ্রহ যা আপনাকে বিদ্যমান ডেটা বুঝতে এবং পরবর্তীতে কী ঘটতে পারে তা ভবিষ্যদ্বাণী করতে সাহায্য করে। ঐতিহাসিক নিদর্শনগুলির উপর ভিত্তি করে, ভবিষ্যদ্বাণীমূলক এআই মডেলগুলি বিভিন্ন বিশ্লেষণাত্মক কাজ শেখে যা ব্যবহারকারীদের তাদের ডেটা বুঝতে সাহায্য করে:
- শ্রেণীবিভাগ : তথ্যের ধরণ অনুসারে পূর্বনির্ধারিত শ্রেণীতে আইটেমগুলিকে ভাগ করুন। উদাহরণস্বরূপ, একটি অনলাইন দোকান দর্শকদের উদ্দেশ্য (গবেষণা, ক্রয়, রিটার্ন) অনুসারে শ্রেণীবদ্ধ করতে পারে, যাতে এটি তার সুপারিশগুলি সেই অনুযায়ী মানিয়ে নিতে পারে।
- রিগ্রেশন : সংখ্যাসূচক মান পূর্বাভাস দিন, যেমন এনগেজমেন্ট রেট, সেশনের সময়কাল, অথবা কনভার্সন সম্ভাব্যতা।
- সুপারিশ : নির্দিষ্ট ব্যবহারকারী বা প্রসঙ্গের সাথে সবচেয়ে প্রাসঙ্গিক আইটেমগুলি সুপারিশ করুন। "আপনার মতো ব্যবহারকারীরাও দেখেছেন" বা "আপনার অগ্রগতির উপর ভিত্তি করে প্রস্তাবিত টিউটোরিয়াল" ভাবুন।
- পূর্বাভাস এবং অসঙ্গতি সনাক্তকরণ : মডেলটি ভবিষ্যতের ঘটনাগুলির পূর্বাভাস দেয়, যেমন ট্র্যাফিক বৃদ্ধি, অথবা অস্বাভাবিক আচরণ সনাক্ত করে, যেমন অর্থপ্রদানের অসঙ্গতি বা জালিয়াতি।
কিছু পণ্য সম্পূর্ণরূপে ভবিষ্যদ্বাণীমূলক AI-এর উপর ভিত্তি করে তৈরি করা হয়, যেমন সঙ্গীত আবিষ্কারের সরঞ্জাম। অন্যগুলিতে, ভবিষ্যদ্বাণীমূলক AI একটি নির্ণায়ক অভিজ্ঞতা বৃদ্ধি করে, যেমন ব্যক্তিগতকৃত সুপারিশ সহ একটি স্ট্রিমিং ওয়েবসাইট। ভবিষ্যদ্বাণীমূলক AI একটি শক্তিশালী অভ্যন্তরীণ সক্ষমকারীও হতে পারে: আপনি অন্তর্দৃষ্টি উন্মোচন করতে এবং পরবর্তী পদক্ষেপগুলি আরও স্মার্টভাবে পরিচালনা করতে পণ্য এবং ব্যবহারকারীর ডেটা বিশ্লেষণ করতে এটি ব্যবহার করতে পারেন।
ভবিষ্যদ্বাণীমূলক এআই লুপ
একটি ভবিষ্যদ্বাণীমূলক এআই সিস্টেমের বিকাশ একটি পুনরাবৃত্তিমূলক চক্র অনুসরণ করে: আপনার সুযোগ সংজ্ঞায়িত করুন, আপনার ডেটা প্রস্তুত করুন, মডেলটিকে প্রশিক্ষণ দিন, মডেলটি মূল্যায়ন করুন এবং মডেলটি স্থাপন করুন।
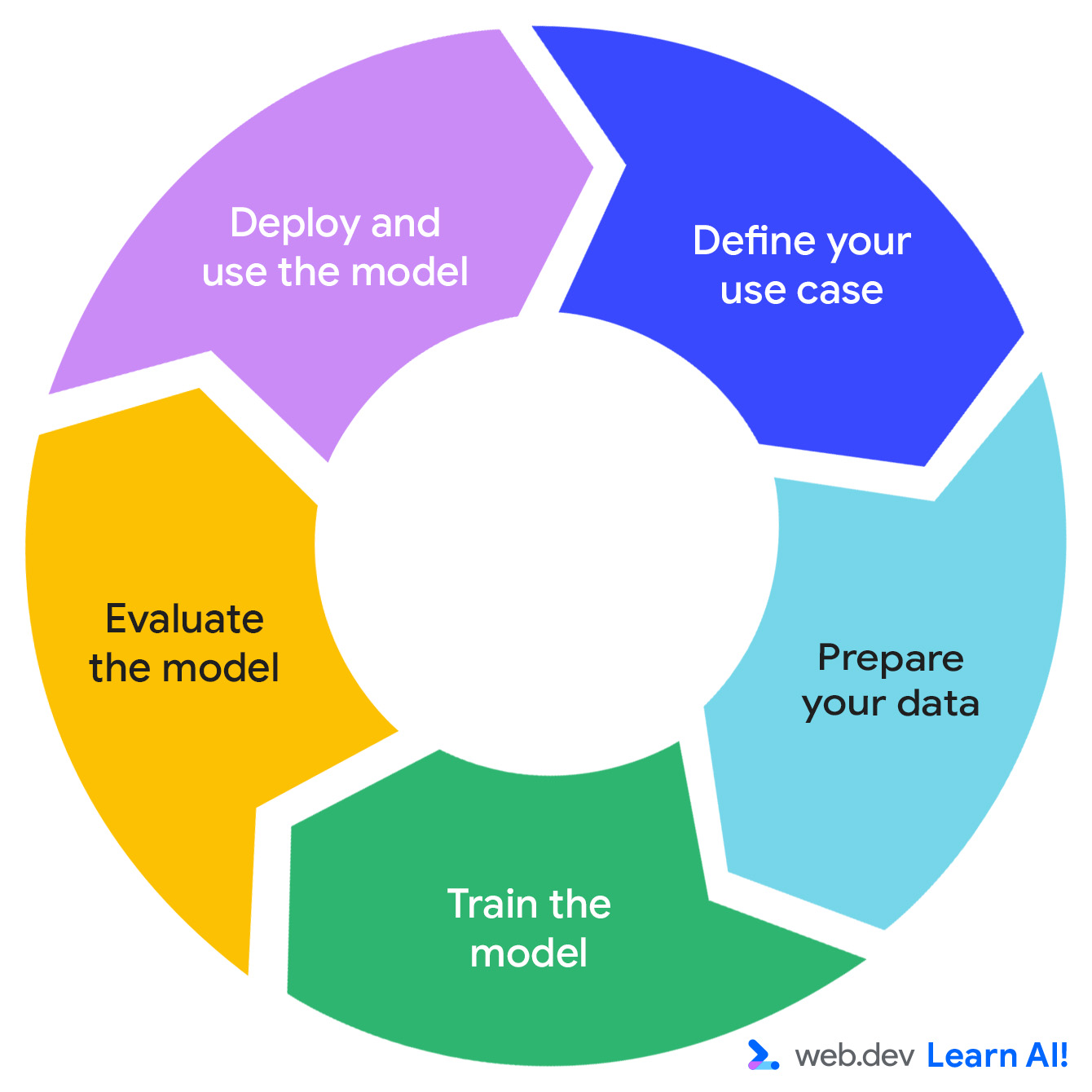
কল্পনা করুন আপনি একটি সাবস্ক্রিপশন-ভিত্তিক উৎপাদনশীলতা অ্যাপ, "Do All The Things"- এ কাজ করছেন। আপনি ইতিমধ্যেই পৃষ্ঠা দর্শন, সেশনের দৈর্ঘ্য, বৈশিষ্ট্য ব্যবহার এবং সাবস্ক্রিপশন পুনর্নবীকরণের মতো ব্যবহারের ডেটা সংগ্রহ করছেন। এখন, আপনি ডেটা থেকে আরও কার্যকর মূল্য বের করতে চান। ভবিষ্যদ্বাণীমূলক AI লুপের মধ্য দিয়ে আপনি কীভাবে ভ্রমণ করেন তা এখানে।
আপনার ব্যবহারের ধরণ নির্ধারণ করুন

{kind=link}
গত তিন মাস ধরে আপনার পরিবর্তনের হার বেড়েছে। ব্যবহারকারীরা বাতিল করার পরে প্রতিক্রিয়া দেখানোর পরিবর্তে, আপনি ভবিষ্যদ্বাণীমূলক AI ব্যবহার করতে চান এমন ব্যবহারকারীদের সনাক্ত করতে যারা বাতিল করার আগে পরিবর্তন করতে পারে। লক্ষ্য হল আপনার গ্রাহক সাফল্য দলকে প্রাথমিক সংকেত দিয়ে সহায়তা করা, যাতে তারা ঝুঁকিপূর্ণ ব্যবহারকারীদের ধরে রাখতে লক্ষ্যবস্তু, সক্রিয় পদক্ষেপ নিতে পারে।
ভবিষ্যদ্বাণীমূলক AI ব্যবহারের ক্ষেত্রে সংজ্ঞা দেওয়ার সময়, প্রশ্নটির উত্তর ডেটা দিয়ে দেওয়া যেতে পারে তা যাচাই করে শুরু করুন। এটি এমন ডেটা হতে পারে যা আপনি ইতিমধ্যেই সংগ্রহ করেছেন অথবা ভবিষ্যতে বাস্তবসম্মতভাবে সংগ্রহ করতে পারেন। এই পদক্ষেপের জন্য প্রায়শই ডোমেন বিশেষজ্ঞদের সাথে সহযোগিতা প্রয়োজন, যেমন গ্রাহক সাফল্য, বৃদ্ধি, বা বিপণন দল, যাতে ভবিষ্যদ্বাণীটি অর্থপূর্ণ এবং কার্যকর উভয়ই হয়।
একটি শক্তিশালী সমস্যার সংজ্ঞায় উল্লেখ করা উচিত:
- লক্ষ্য : আপনি কোন ব্যবসায়িক ফলাফলকে প্রভাবিত করার চেষ্টা করছেন? উদাহরণস্বরূপ, আপনি সক্রিয় আউটরিচ সক্ষম করে মন্থন কমাতে চান।
- ইনপুট ডেটা : মডেলটি কোন ঐতিহাসিক সংকেত থেকে শিখে? উদাহরণস্বরূপ, আপনি ব্যবহারের ধরণ, পরিকল্পনার ধরণ এবং সহায়তা মিথস্ক্রিয়া সরবরাহ করেন।
- আউটপুট : মডেলটি কী তৈরি করবে? উদাহরণস্বরূপ, আপনি চান যে মডেলটি প্রতিটি ব্যবহারকারীর জন্য একটি মন্থন সম্ভাব্যতা স্কোর তৈরি করুক।
- ব্যবহারকারী : কে ভবিষ্যদ্বাণী ব্যবহার করে বা তার উপর কাজ করে? উদাহরণস্বরূপ, এই তথ্যটি গ্রাহক সাফল্য পরিচালকদের জন্য তৈরি।
- সাফল্যের মানদণ্ড : আপনি কীভাবে প্রভাব পরিমাপ করেন? উদাহরণস্বরূপ, আপনি মর্নিং কমিয়েছেন কিনা তা নির্ধারণ করার জন্য ধরে রাখার হার পরিমাপ করেন।
শুরুতেই এই বিশদগুলি চিহ্নিত করে, আপনি একটি সাধারণ ফাঁদ এড়াতে পারেন: এমন একটি কাস্টম মডেল তৈরি করা যা প্রযুক্তিগতভাবে উপযুক্ত, কিন্তু কখনও ব্যবহৃত হয় না।
তথ্য প্রস্তুত করুন
আপনার মডেলকে দরকারী শিক্ষণ সংকেত প্রদানের জন্য, আপনার ঐতিহাসিক তথ্যকে আদর্শ ভবিষ্যদ্বাণী সহ লেবেল করতে হবে। ডু অল দ্য থিংস ব্যবহারকারীদের "মন্থিত" বা "মন্থিত নয়" হিসাবে লেবেল করুন।
এরপর, আপনার গ্রাহক সাফল্য দলের সাথে সহযোগিতা করুন এবং কোন আচরণগত বৈশিষ্ট্যগুলি মন্থন পূর্বাভাসের জন্য সবচেয়ে প্রাসঙ্গিক তা সনাক্ত করুন। আপনার ডেটাসেটকে এই মূল বৈশিষ্ট্যগুলিতে সীমাবদ্ধ করুন এবং অপ্রয়োজনীয় ক্ষেত্রগুলি সরিয়ে ফেলুন যাতে আপনার মডেলকে শব্দের সাথে মোকাবিলা করতে না হয়। ডেটা গোপনীয়তা বিবেচনা করতে ভুলবেন না। ব্যক্তিগতভাবে সনাক্তযোগ্য তথ্য (PII) যেমন নাম বা ইমেলগুলি সরিয়ে ফেলুন এবং শুধুমাত্র সমষ্টিগত আচরণগত ডেটা সংরক্ষণ করুন।
নিম্নলিখিত টেবিলটি আপনার ফলাফলযুক্ত ডেটাসেট থেকে একটি অংশ দেখায়:
user_id | plan_type | avg_session_time (min) | logins_last_30d | features_used | support_tickets | churned |
| 00123 এর বিবরণ | প্রিমিয়াম | ১২.৪ | ২২ | ৫ | 0 | 0 |
| 00124 এর বিবরণ | বিচার | ৫.৮ | ৩ | ১ | ২ | ১ |
| 00125 এর বিবরণ | বিনামূল্যে | ১৮.১ | ৩০ | ৭ | 0 | 0 |
| 00126 এর বিবরণ | প্রিমিয়াম | ৯.৭ | ১২ | ৪ | ১ | 0 |
| 00127 এর বিবরণ | বিচার | ৪.২ | ২ | ১ | ৩ | ১ |
এটি আপনার মডেলকে পরিষ্কার সংখ্যাসূচক এবং শ্রেণীগত ইনপুট (যেমন plan_type বা avg_session_time ) এবং একটি স্পষ্ট লক্ষ্য লেবেল ( churned ) দেয়। বিভাগগুলিকে অনন্য সংখ্যাসূচক শনাক্তকারীতে রূপান্তরিত করা উচিত।
অবশেষে, আপনার ডেটাসেটটিকে তিনটি উপসেটে ভাগ করুন:
- মডেলটি শেখানোর জন্য প্রশিক্ষণ সেট (সাধারণত প্রায় ৭০ থেকে ৮০%),
- হাইপারপ্যারামিটারগুলি সুরক্ষিত করতে এবং অতিরিক্ত ফিটিং প্রতিরোধ করার জন্য ভ্যালিডেশন সেট (কখনও কখনও ডেভেলপমেন্ট সেটও বলা হয়)।
- সম্পূর্ণ অদৃশ্য ডেটার উপর মডেলটি কীভাবে কাজ করে তা মূল্যায়ন করার জন্য পরীক্ষা সেট।
এটি আপনার মডেলকে মুখস্থ ঐতিহাসিক উদাহরণের উপর নির্ভর করার পরিবর্তে সিদ্ধান্তগুলিকে সাধারণীকরণ করতে সাহায্য করে।
মডেলকে প্রশিক্ষণ দিন
জেনারেটিভ এআই এর বিপরীতে, যা প্রায়শই বৃহৎ, পূর্ব-প্রশিক্ষিত মডেলের উপর নির্মিত হয়, বেশিরভাগ ভবিষ্যদ্বাণীমূলক এআই সিস্টেম স্ব-প্রশিক্ষিত মডেলের উপর নির্ভর করে। কারণ ভবিষ্যদ্বাণীমূলক কাজগুলি আপনার পণ্য এবং আপনার ব্যবহারকারীদের জন্য অত্যন্ত নির্দিষ্ট। scikit-learn (Python), AutoML (no-code or low-code), অথবা TensorFlow.js (JavaScript) এর মতো সরঞ্জামগুলি অন্তর্নিহিত গণিত সম্পর্কে চিন্তা না করে ভবিষ্যদ্বাণীমূলক মডেলগুলিকে প্রশিক্ষণ এবং মূল্যায়ন করা সহজ করে তোলে।
আমাদের মর্নিং উদাহরণে, আমরা পরিষ্কার প্রশিক্ষণ সেটটিকে একটি তত্ত্বাবধানে থাকা শ্রেণিবিন্যাস অ্যালগরিদমে ফিড করি, যেমন লজিস্টিক রিগ্রেশন বা নিউরাল নেটওয়ার্ক । আপনার ডেটার জন্য কোনটি সবচেয়ে ভালো কাজ করে তা নির্ধারণ করতে একাধিক বিকল্প চেষ্টা করুন।
তোমার মডেল শিখবে কোন আচরণের ধরণগুলি মর্নের সাথে সম্পর্কিত। শেষে, এটি প্রতিটি ব্যবহারকারীকে একটি সম্ভাব্যতা স্কোর নির্ধারণ করতে পারে। উদাহরণস্বরূপ, ৭২% ঝুঁকি রয়েছে যা ব্যবহারকারী X পরের মাসে বাতিল করবে।
প্রতিটি প্রশিক্ষণ পুনরাবৃত্তির পরে, বৈধতা সেট ব্যবহার করে ফলাফল মডেল মূল্যায়ন করুন। হাইপারপ্যারামিটারগুলি সামঞ্জস্য করে একটি মডেলের কর্মক্ষমতা উন্নত করা যেতে পারে, তবে আপনার ডেটাসেটে লক্ষ্যবস্তু উন্নতি করেও।
মডেলটি মূল্যায়ন করুন
আপনার ডেটাসেটের লেবেলগুলি সেই বাস্তব সত্য প্রদান করে যার সাথে আপনি মডেল আউটপুটগুলির তুলনা করতে পারেন। ট্র্যাক করার জন্য মূল মেট্রিক্সগুলি হল:
- যথার্থতা : "মন্থন" হিসেবে চিহ্নিত সকল ব্যবহারকারীর মধ্যে, আসলে কতজন মন্থন করেছেন?
- মনে রাখবেন : যারা মন্থন করেছিলেন, তাদের মধ্যে কতজন মডেলটি ধরেছিল?
- F1 স্কোর : একটি একক সংখ্যা যা নির্ভুলতা এবং প্রত্যাহারের ভারসাম্য বজায় রাখে, যখন আপনি একটির খরচে অন্যটির অতিরিক্ত অপ্টিমাইজ না করে নির্ভুলতার সামগ্রিক পরিমাপ চান তখন এটি কার্যকর।
অনেক বেশি মিথ্যা ইতিবাচক তথ্য গ্রাহকদের ধরে রাখার প্রচেষ্টা নষ্ট করে, অন্যদিকে অনেক বেশি মিথ্যা নেতিবাচক তথ্য গ্রাহকদের হারাতে বাধ্য করে। সঠিক লেনদেন আপনার ব্যবসায়িক অগ্রাধিকারের উপর নির্ভর করে। উদাহরণস্বরূপ, আপনার কোম্পানি যদি আরও বেশি ব্যবহারকারীকে ছেড়ে যাওয়ার আগে ধরার সম্ভাবনা বাড়িয়ে তোলে তবে কয়েকটি মিথ্যা সতর্কতা মোকাবেলা করতে পছন্দ করতে পারে।
মডেলটি স্থাপন এবং রক্ষণাবেক্ষণ করুন
একবার যাচাই হয়ে গেলে, আপনি মডেলটিকে একটি API দিয়ে অথবা আপনার অ্যানালিটিক্স ড্যাশবোর্ডে ইন্টিগ্রেটেড একটি হালকা ক্লায়েন্ট-সাইড পরিষেবা হিসাবে স্থাপন করতে পারেন। প্রতিদিন, এটি ব্যবহারকারীদের স্কোর করতে পারে এবং একটি মন্থন ঝুঁকি ভিজ্যুয়ালাইজেশন আপডেট করতে পারে, যা আপনার দলকে আউটরিচকে অগ্রাধিকার দেওয়ার অনুমতি দেয়। এটিকে সঠিক এবং নির্ভরযোগ্য রাখতে, মেশিন লার্নিং অপারেশন টিম (MLOps) থেকে এই শিক্ষাগুলি গ্রহণ করুন:
- ডেটা ড্রিফট পর্যবেক্ষণ করুন : ব্যবহারকারীর আচরণ কখন পরিবর্তিত হয় এবং আপনার প্রশিক্ষণের ডেটা আর বাস্তবতা উপস্থাপন করে না তা সনাক্ত করুন।
- উদাহরণস্বরূপ, একটি প্রধান UI রিডিজাইন চালু করার পর, ব্যবহারকারীরা বৈশিষ্ট্যগুলির সাথে ভিন্নভাবে ইন্টারঅ্যাক্ট করে, যার ফলে মর্ন ভবিষ্যদ্বাণীগুলি কম নির্ভুল হয়ে যায়।
- ভুল থেকে শিক্ষা নিন : ভুল ভবিষ্যদ্বাণীর পিছনে সাধারণ ধরণগুলি চিহ্নিত করুন এবং পরবর্তী প্রশিক্ষণ চক্র উন্নত করার জন্য লক্ষ্যযুক্ত উদাহরণ যুক্ত করুন।
- উদাহরণস্বরূপ, মডেলটি প্রায়শই বিদ্যুৎ ব্যবহারকারীদেরকে মন্থন ঝুঁকি হিসেবে চিহ্নিত করে কারণ তারা অনেক সাপোর্ট টিকিট খুলে দেয়। পর্যালোচনার পরে, আপনি নতুন বৈশিষ্ট্য যুক্ত করেন যা সমস্যা সমাধান এবং বিচ্ছিন্নতাকে আলাদা করে।
- নিয়মিত পুনরায় প্রশিক্ষণ দিন : কর্মক্ষমতা স্থিতিশীল দেখালেও, মৌসুমী প্যাটার্ন, পণ্য আপডেট বা মূল্য পরিবর্তনের জন্য পর্যায়ক্রমে মডেলটি রিফ্রেশ করুন।
- উদাহরণস্বরূপ, বার্ষিক পরিকল্পনা প্রবর্তনের পরে আপনি মডেলটিকে পুনরায় প্রশিক্ষণ দেন, কারণ মূল্য কাঠামো পুনর্নবীকরণের আগে ব্যবহারকারীদের আচরণ পরিবর্তন করে।
এই জীবনচক্রটি ভবিষ্যদ্বাণীমূলক AI-এর মেরুদণ্ড। MLflow এবং Weights & Biases- এর মতো টুলগুলির সাহায্যে, আপনি গভীর ML দক্ষতা ছাড়াই এই প্রক্রিয়াটি চালাতে পারেন।
সাধারণ ক্ষতি এবং প্রশমন
যদিও মাঝে মাঝে ত্রুটি দেখা দেবে, আপনি সাধারণ মূল কারণগুলি থেকে সাবধান থাকতে পারেন যা কর্মক্ষমতা এবং ব্যবহারকারীর আস্থা হ্রাস করতে পারে:
- নিম্নমানের ডেটা : যদি আপনার ইনপুট ডেটা গোলমাল বা অসম্পূর্ণ হয়, তাহলে আপনার ভবিষ্যদ্বাণীগুলিও হবে। প্রশিক্ষণের আগে আপনার ডেটা প্রশমিত করতে, কল্পনা করতে এবং যাচাই করতে। নিশ্চিত করুন যে আপনার কাছে প্রয়োজনীয় শেখার সংকেত রয়েছে এবং অনুপস্থিত মানগুলি পরিচালনা করুন। উৎপাদনে ডেটার গুণমান পর্যবেক্ষণ করুন।
ওভারফিটিং : মডেলটি প্রশিক্ষণের ডেটাতে খুব ভালো পারফর্ম করে, কিন্তু নতুন ক্ষেত্রে ব্যর্থ হয়। প্রশমনের জন্য, ক্রস-ভ্যালিডেশন , রেগুলারাইজেশন এবং হোল্ডআউট ডেটা সেট ব্যবহার করুন। এটি আপনার মডেলকে প্রশিক্ষণের উদাহরণের বাইরেও সাধারণীকরণ করতে সাহায্য করে।
ডেটা ড্রিফট : ব্যবহারকারীর আচরণ এবং পরিবেশ পরিবর্তিত হয়, কিন্তু আপনার মডেলটি পরিবর্তিত হয় না। প্রশমিত করার জন্য, পুনঃপ্রশিক্ষণের সময়সূচী নির্ধারণ করুন এবং সঠিকতা কখন কমতে শুরু করে তা সনাক্ত করার জন্য পর্যবেক্ষণ যোগ করুন।
খারাপ মেট্রিক্স : সামগ্রিক নির্ভুলতা সবসময় আপনার ব্যবহারকারীদের অগ্রাধিকার প্রতিফলিত করে না। উদাহরণস্বরূপ, কখনও কখনও, একটি নির্দিষ্ট ভুলের "মূল্য" বেশি গুরুত্বপূর্ণ। জালিয়াতি সনাক্তকরণে, একটি জালিয়াতির ঘটনা (মিথ্যা নেতিবাচক) মিস করা একটি নির্দোষকে চিহ্নিত করার চেয়ে (মিথ্যা ইতিবাচক) অনেক বেশি খারাপ। প্রশমনের জন্য, জালিয়াতি সনাক্তকরণের জন্য বাস্তব-বিশ্বের লক্ষ্যগুলির সাথে মেট্রিক্স সারিবদ্ধ করুন।
এই সমস্যাগুলির বেশিরভাগই মারাত্মক নয়। ধীরে ধীরে আপনার সিস্টেম চালু করুন এবং সমস্যাগুলি দেখা দেওয়ার সাথে সাথে সমাধান করুন।
এই নমনীয়, নমনীয় পদ্ধতির মূল চাবিকাঠি হল পর্যবেক্ষণযোগ্যতা। আপনার মডেলগুলি, লগ নির্ভুলতার বৈশিষ্ট্য এবং মডেল তৈরিতে ব্যবহৃত সরঞ্জামগুলি সংস্করণ করুন, সময়ের সাথে সাথে কর্মক্ষমতা ট্র্যাক করুন এবং পর্যবেক্ষণ সক্রিয় রাখুন। যখন কিছু সরে যায় বা ভেঙে যায়, তখন ব্যবহারকারীরা লক্ষ্য করার আগেই আপনি সমস্যাটি ধরতে এবং সমাধান করতে সক্ষম হবেন।
আপনার টেকওয়ে
ভবিষ্যদ্বাণীমূলক AI আপনার বিদ্যমান ডেটাকে দূরদর্শিতায় পরিণত করে, পরবর্তীতে কী ঘটতে পারে এবং কোথায় পদক্ষেপ নিতে হবে তা প্রকাশ করে। এটি AI-এর সবচেয়ে সুনির্দিষ্ট এবং পরিমাপযোগ্য রূপ। ডেটাতে প্রকাশ করা যেতে পারে এমন সুনির্দিষ্ট সমস্যাগুলির উপর মনোযোগ দিন, আপনার পণ্যের বিকশিত হওয়ার সাথে সাথে পুনরাবৃত্তি করতে থাকুন এবং সময়ের সাথে সাথে কর্মক্ষমতা পর্যবেক্ষণ করুন।
আমাদের পরবর্তী মডিউলে, আপনি জেনারেটিভ এআই সম্পর্কে শিখবেন, যা আপনাকে উপলব্ধ তথ্যের উপর ভিত্তি করে নতুন কিছু তৈরি করতে সাহায্য করে।
রিসোর্স
যদি আপনি ভবিষ্যদ্বাণীমূলক AI-এর পিছনের গণিত বুঝতে আগ্রহী হন, তাহলে আমরা আপনাকে এই সংস্থানগুলি পর্যালোচনা করার পরামর্শ দিচ্ছি:
- শ্রেণীবিভাগ , রৈখিক রিগ্রেশন এবং লজিস্টিক রিগ্রেশনের উপর মেশিন লার্নিং ক্র্যাশ কোর্স।
- আপনার কোর্সের লেখক, জান্না লিপেনকোভা, "দ্য আর্ট অফ এআই প্রোডাক্ট ডেভেলপমেন্ট: ডেলিভারিং বিজনেস ভ্যালু" এর ৪র্থ অধ্যায়ে ভবিষ্যদ্বাণীমূলক এআই বিষয় সম্পর্কে আরও লিখেছেন।
- স্টুয়ার্ট জোনাথন রাসেল এবং পিটার নরভিগের লেখা "কৃত্রিম বুদ্ধিমত্তা: একটি আধুনিক পদ্ধতি" বইটি। এই বইটি প্রাথমিকভাবে ১৯৯৫ সালে প্রকাশিত হয়েছিল এবং এর সর্বশেষ সংস্করণটি ২০২১ সালে প্রকাশিত হয়েছিল। এটি সাধারণত এআই ইঞ্জিনিয়ারিং প্রোগ্রামগুলিতে পড়ানো হয়।
- ক্রিস্টোফার এম. বিশপের প্যাটার্ন রিকগনিশন এবং মেশিন লার্নিং , ভবিষ্যদ্বাণীমূলক এআই শেখার জন্য একটি অত্যন্ত ব্যাপক এবং একাডেমিক পদ্ধতির জন্য।
তোমার বোধগম্যতা পরীক্ষা করো।
প্রেডিক্টিভ এআই এর প্রাথমিক কাজ কী?
কোন কাজে প্যাটার্নের উপর ভিত্তি করে পূর্বনির্ধারিত শ্রেণীতে আইটেমগুলিকে গোষ্ঠীভুক্ত করা হয়?
"প্রেডিক্টিভ এআই লুপ"-এ, কেন আপনার ডেটাসেটকে প্রশিক্ষণ, বৈধতা এবং পরীক্ষার সেটে ভাগ করা উচিত?
কোন মেট্রিক নির্ভুলতা এবং প্রত্যাহারের ভারসাম্য বজায় রেখে সামগ্রিকভাবে নির্ভুলতার পরিমাপ প্রদান করে?