

Pengantar
Media Source Extensions (MSE)
menyediakan kontrol buffering dan pemutaran yang diperluas untuk elemen HTML5 <audio> dan
<video>. Meskipun awalnya dikembangkan untuk memfasilitasi
Dynamic Adaptive Streaming over HTTP (DASH)
pemutar video berbasis, di bawah ini kita akan melihat bagaimana MSE dapat digunakan untuk audio, khususnya untuk
pemutaran tanpa jeda.
Anda mungkin pernah mendengarkan album musik yang lagunya mengalir dengan lancar di seluruh trek. Anda bahkan mungkin sedang mendengarkannya sekarang. Artis membuat pengalaman pemutaran tanpa jeda ini sebagai pilihan artistik serta artefak rekaman vinyl dan CD tempat audio ditulis sebagai satu aliran berkelanjutan. Sayangnya, karena cara kerja codec audio modern seperti MP3 dan AAC bekerja, pengalaman pendengaran yang lancar ini sering kali hilang saat ini.
Kita akan membahas detailnya di bawah, tetapi untuk saat ini mari kita mulai dengan demonstrasi. Di bawah ini adalah tiga puluh detik pertama dari Sintel yang sangat bagus, dipotong menjadi lima file MP3 terpisah dan dirakit ulang menggunakan MSE. Garis merah menunjukkan jeda yang diperkenalkan selama pembuatan (encoding) setiap MP3. Anda akan mendengar gangguan pada titik-titik ini.
Aduh! Pengalaman ini tidak bagus. Kita bisa melakukan yang lebih baik. Dengan sedikit lebih banyak upaya, menggunakan file MP3 yang sama persis dalam demo di atas, kita dapat menggunakan MSE untuk menghapus jeda yang mengganggu tersebut. Garis hijau dalam demo berikutnya menunjukkan tempat file telah digabungkan dan jeda dihapus. Di Chrome 38+, pemutaran ini akan lancar.
Ada berbagai cara untuk membuat konten tanpa jeda. Untuk tujuan demo ini, kita akan berfokus pada jenis file yang mungkin dimiliki pengguna biasa. Setiap file telah dienkode secara terpisah tanpa memperhatikan segmen audio sebelum atau sesudahnya.
Penyiapan Dasar
Pertama, mari kita kembali dan membahas penyiapan dasar instance MediaSource.
Media Source Extensions, seperti namanya, hanyalah ekstensi untuk elemen media yang ada. Di bawah, kita menetapkan
Object URL,
yang mewakili instance MediaSource, ke atribut sumber elemen audio
; seperti yang Anda lakukan saat menetapkan URL standar.
var audio = document.createElement('audio');
var mediaSource = new MediaSource();
var SEGMENTS = 5;
mediaSource.addEventListener('sourceopen', function () {
var sourceBuffer = mediaSource.addSourceBuffer('audio/mpeg');
function onAudioLoaded(data, index) {
// Append the ArrayBuffer data into our new SourceBuffer.
sourceBuffer.appendBuffer(data);
}
// Retrieve an audio segment via XHR. For simplicity, we're retrieving the
// entire segment at once, but we could also retrieve it in chunks and append
// each chunk separately. MSE will take care of assembling the pieces.
GET('sintel/sintel_0.mp3', function (data) {
onAudioLoaded(data, 0);
});
});
audio.src = URL.createObjectURL(mediaSource);
Setelah terhubung, objek MediaSource akan melakukan beberapa inisialisasi
dan akhirnya memicu peristiwa sourceopen. Pada saat itu, kita dapat membuat
SourceBuffer. Dalam
contoh di atas, kita membuat audio/mpeg, yang dapat mengurai dan
mendekode segmen MP3 kita. Ada beberapa
jenis lain yang tersedia.
Bentuk Gelombang Anomali
Kita akan kembali ke kode dalam beberapa saat, tetapi sekarang mari kita lihat lebih dekat file yang baru saja kita tambahkan, khususnya di bagian akhirnya. Di bawah ini adalah grafik 3.000 sampel terakhir yang dirata-ratakan di kedua saluran dari trek sintel_0.mp3. Setiap piksel pada garis merah adalah
sampel floating point
dalam rentang [-1.0, 1.0].

Ada apa dengan semua sampel nol (senyap) itu? Sebenarnya, sampel tersebut disebabkan oleh artefak kompresi yang diperkenalkan selama encoding. Hampir setiap encoder memperkenalkan beberapa jenis padding. Dalam hal ini, LAME menambahkan tepat 576 sampel padding ke akhir file.
Selain padding di akhir, setiap file juga memiliki padding yang ditambahkan di awal. Jika kita melihat trek sintel_1.mp3, kita akan melihat 576 sampel padding lainnya di bagian depan. Jumlah
padding bervariasi menurut encoder dan konten, tetapi kita mengetahui nilai pastinya berdasarkan
metadata yang disertakan dalam setiap file.
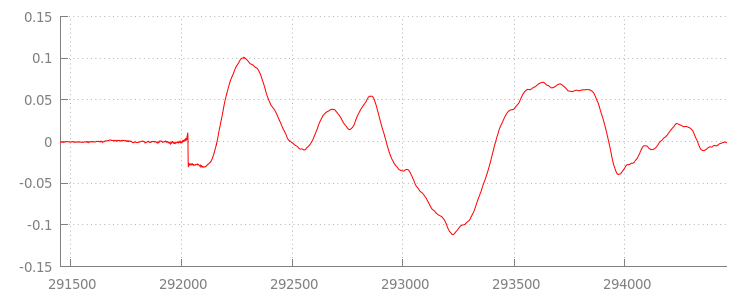
Bagian senyap di awal dan akhir setiap file adalah penyebab gangguan antara segmen dalam demo sebelumnya. Untuk mencapai pemutaran tanpa jeda, kita perlu menghapus bagian senyap ini. Untungnya, hal ini dapat dilakukan dengan mudah menggunakan MediaSource. Di bawah, kita akan mengubah metode onAudioLoaded() untuk menggunakan
jendela penambahan dan offset
stempel waktu guna menghapus kesunyian ini.
Kode Contoh
function onAudioLoaded(data, index) {
// Parsing gapless metadata is unfortunately non trivial and a bit messy, so
// we'll glaze over it here; see the appendix for details.
// ParseGaplessData() will return a dictionary with two elements:
//
// audioDuration: Duration in seconds of all non-padding audio.
// frontPaddingDuration: Duration in seconds of the front padding.
//
var gaplessMetadata = ParseGaplessData(data);
// Each appended segment must be appended relative to the next. To avoid any
// overlaps, we'll use the end timestamp of the last append as the starting
// point for our next append or zero if we haven't appended anything yet.
var appendTime = index > 0 ? sourceBuffer.buffered.end(0) : 0;
// Simply put, an append window allows you to trim off audio (or video) frames
// which fall outside of a specified time range. Here, we'll use the end of
// our last append as the start of our append window and the end of the real
// audio data for this segment as the end of our append window.
sourceBuffer.appendWindowStart = appendTime;
sourceBuffer.appendWindowEnd = appendTime + gaplessMetadata.audioDuration;
// The timestampOffset field essentially tells MediaSource where in the media
// timeline the data given to appendBuffer() should be placed. I.e., if the
// timestampOffset is 1 second, the appended data will start 1 second into
// playback.
//
// MediaSource requires that the media timeline starts from time zero, so we
// need to ensure that the data left after filtering by the append window
// starts at time zero. We'll do this by shifting all of the padding we want
// to discard before our append time (and thus, before our append window).
sourceBuffer.timestampOffset =
appendTime - gaplessMetadata.frontPaddingDuration;
// When appendBuffer() completes, it will fire an updateend event signaling
// that it's okay to append another segment of media. Here, we'll chain the
// append for the next segment to the completion of our current append.
if (index == 0) {
sourceBuffer.addEventListener('updateend', function () {
if (++index < SEGMENTS) {
GET('sintel/sintel_' + index + '.mp3', function (data) {
onAudioLoaded(data, index);
});
} else {
// We've loaded all available segments, so tell MediaSource there are no
// more buffers which will be appended.
mediaSource.endOfStream();
URL.revokeObjectURL(audio.src);
}
});
}
// appendBuffer() will now use the timestamp offset and append window settings
// to filter and timestamp the data we're appending.
//
// Note: While this demo uses very little memory, more complex use cases need
// to be careful about memory usage or garbage collection may remove ranges of
// media in unexpected places.
sourceBuffer.appendBuffer(data);
}
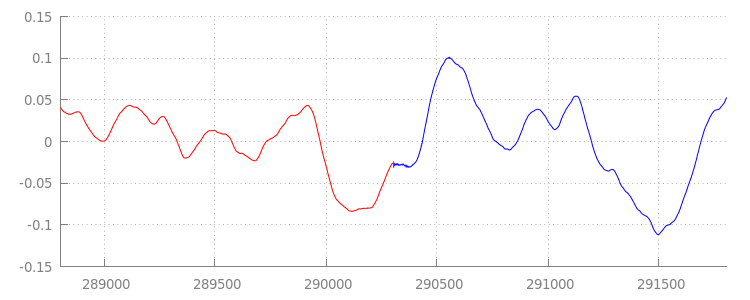
Bentuk Gelombang yang Lancar
Mari kita lihat apa yang telah dicapai oleh kode baru kita yang bagus dengan melihat kembali bentuk gelombang setelah kita menerapkan jendela penambahan. Di bawah, Anda dapat melihat bahwa bagian senyap di akhir sintel_0.mp3 (dengan warna merah) dan bagian senyap di awal sintel_1.mp3 (dengan warna biru) telah dihapus, sehingga kita mendapatkan transisi yang lancar antar-segmen.
Kesimpulan
Dengan demikian, kita telah menggabungkan kelima segmen dengan lancar menjadi satu dan kemudian mencapai akhir demo. Sebelum kita melanjutkan, Anda mungkin telah memperhatikan bahwa metode onAudioLoaded() kita tidak mempertimbangkan container atau codec.
Artinya, semua teknik ini akan berfungsi terlepas dari jenis container atau codec. Di bawah, Anda dapat memutar ulang demo asli MP4 terfragmentasi yang siap untuk DASH, bukan MP3.
Jika Anda ingin mengetahui lebih lanjut, lihat lampiran di bawah untuk melihat lebih dalam pembuatan konten tanpa jeda dan penguraian metadata. Anda juga dapat menjelajahi
gapless.js untuk melihat lebih dekat
kode yang mendukung demo ini.
Terima kasih telah membaca.
Lampiran A: Membuat Konten Tanpa Jeda
Membuat konten tanpa jeda bisa jadi sulit. Di bawah, kita akan membahas pembuatan media Sintel yang digunakan dalam demo ini. Untuk memulai, Anda memerlukan salinan soundtrack FLAC lossless untuk Sintel. Untuk posterity, SHA1 disertakan di bawah. Untuk alat, Anda memerlukan FFmpeg, MP4Box, LAME, dan instalasi OSX dengan afconvert.
unzip Jan_Morgenstern-Sintel-FLAC.zip
sha1sum 1-Snow_Fight.flac
# 0535ca207ccba70d538f7324916a3f1a3d550194 1-Snow_Fight.flac
Pertama, kita akan memisahkan 31,5 detik pertama dari trek 1-Snow_Fight.flac. Kita juga ingin menambahkan fade out 2,5 detik yang dimulai pada detik ke-28 untuk menghindari klik setelah pemutaran selesai. Dengan command line FFmpeg di bawah, kita dapat mencapai semua ini dan menempatkan hasilnya di sintel.flac.
ffmpeg -i 1-Snow_Fight.flac -t 31.5 -af "afade=t=out:st=28:d=2.5" sintel.flac
Selanjutnya, kita akan membagi file menjadi 5 file gelombang
masing-masing 6,5 detik.Cara termudah adalah menggunakan gelombang karena hampir setiap encoder
mendukung penyerapan. Sekali lagi, kita dapat melakukannya dengan tepat menggunakan FFmpeg, setelah itu kita akan memiliki: sintel_0.wav, sintel_1.wav, sintel_2.wav, sintel_3.wav, dan sintel_4.wav.
ffmpeg -i sintel.flac -acodec pcm_f32le -map 0 -f segment \
-segment_list out.list -segment_time 6.5 sintel_%d.wav
Selanjutnya, mari kita buat file MP3. LAME memiliki beberapa opsi untuk membuat konten tanpa jeda. Jika Anda mengontrol konten, sebaiknya gunakan --nogap dengan encoding batch semua file untuk menghindari padding antar-segmen.
Namun, untuk tujuan demo ini, kita menginginkan padding tersebut sehingga kita akan menggunakan encoding VBR berkualitas tinggi standar dari file gelombang.
lame -V=2 sintel_0.wav sintel_0.mp3
lame -V=2 sintel_1.wav sintel_1.mp3
lame -V=2 sintel_2.wav sintel_2.mp3
lame -V=2 sintel_3.wav sintel_3.mp3
lame -V=2 sintel_4.wav sintel_4.mp3
Hanya itu yang diperlukan untuk membuat file MP3. Sekarang mari kita bahas pembuatan file MP4 terfragmentasi. Kita akan mengikuti petunjuk Apple untuk membuat media yang dikuasai untuk iTunes. Di bawah, kita akan mengonversi file gelombang menjadi file CAF perantara, sesuai petunjuk, sebelum mengenkodekannya sebagai AAC dalam container MP4 menggunakan parameter yang direkomendasikan.
afconvert sintel_0.wav sintel_0_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_1.wav sintel_1_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_2.wav sintel_2_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_3.wav sintel_3_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_4.wav sintel_4_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_0_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_0.m4a
afconvert sintel_1_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_1.m4a
afconvert sintel_2_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_2.m4a
afconvert sintel_3_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_3.m4a
afconvert sintel_4_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_4.m4a
Sekarang kita memiliki beberapa file M4A yang perlu kita
fragmentasi
dengan tepat sebelum dapat digunakan dengan
MediaSource. Untuk tujuan kita, kita akan menggunakan ukuran fragmen satu detik. MP4Box akan menulis setiap MP4 terfragmentasi sebagai sintel_#_dashinit.mp4 bersama dengan manifes MPEG-DASH (sintel_#_dash.mpd) yang dapat dihapus.
MP4Box -dash 1000 sintel_0.m4a && mv sintel_0_dashinit.mp4 sintel_0.mp4
MP4Box -dash 1000 sintel_1.m4a && mv sintel_1_dashinit.mp4 sintel_1.mp4
MP4Box -dash 1000 sintel_2.m4a && mv sintel_2_dashinit.mp4 sintel_2.mp4
MP4Box -dash 1000 sintel_3.m4a && mv sintel_3_dashinit.mp4 sintel_3.mp4
MP4Box -dash 1000 sintel_4.m4a && mv sintel_4_dashinit.mp4 sintel_4.mp4
rm sintel_{0,1,2,3,4}_dash.mpd
Selesai! Sekarang kita memiliki file MP4 dan MP3 terfragmentasi dengan metadata yang benar dan diperlukan untuk pemutaran tanpa jeda. Lihat Lampiran B untuk mengetahui detail selengkapnya tentang tampilan metadata tersebut.
Lampiran B: Mengurai Metadata Tanpa Jeda
Sama seperti membuat konten tanpa jeda, mengurai metadata tanpa jeda bisa jadi sulit karena tidak ada metode standar untuk penyimpanan. Di bawah, kita akan membahas cara dua encoder paling umum, LAME dan iTunes, menyimpan metadata tanpa jeda. Mari kita mulai dengan menyiapkan beberapa metode helper dan garis besar untuk ParseGaplessData() yang digunakan di atas.
// Since most MP3 encoders store the gapless metadata in binary, we'll need a
// method for turning bytes into integers. Note: This doesn't work for values
// larger than 2^30 since we'll overflow the signed integer type when shifting.
function ReadInt(buffer) {
var result = buffer.charCodeAt(0);
for (var i = 1; i < buffer.length; ++i) {
result <<= 8;
result += buffer.charCodeAt(i);
}
return result;
}
function ParseGaplessData(arrayBuffer) {
// Gapless data is generally within the first 512 bytes, so limit parsing.
var byteStr = new TextDecoder().decode(arrayBuffer.slice(0, 512));
var frontPadding = 0, endPadding = 0, realSamples = 0;
// ... we'll fill this in as we go below.
Kita akan membahas format metadata iTunes Apple terlebih dahulu karena format ini paling mudah diurai dan dijelaskan. Dalam file MP3 dan M4A, iTunes (dan afconvert) menulis bagian singkat dalam ASCII seperti berikut:
iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00
Ini ditulis di dalam tag ID3 dalam container MP3 dan dalam atom metadata di dalam container MP4. Untuk tujuan kita, kita dapat mengabaikan token 0000000 pertama. Tiga token berikutnya adalah padding depan, padding akhir, dan jumlah sampel non-padding total. Membagi masing-masing dengan frekuensi sampel audio akan memberi kita durasi untuk setiap.
// iTunes encodes the gapless data as hex strings like so:
//
// 'iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00'
// 'iTunSMPB[ 26 bytes ]####### frontpad endpad real samples'
//
// The approach here elides the complexity of actually parsing MP4 atoms. It
// may not work for all files without some tweaks.
var iTunesDataIndex = byteStr.indexOf('iTunSMPB');
if (iTunesDataIndex != -1) {
var frontPaddingIndex = iTunesDataIndex + 34;
frontPadding = parseInt(byteStr.substr(frontPaddingIndex, 8), 16);
var endPaddingIndex = frontPaddingIndex + 9;
endPadding = parseInt(byteStr.substr(endPaddingIndex, 8), 16);
var sampleCountIndex = endPaddingIndex + 9;
realSamples = parseInt(byteStr.substr(sampleCountIndex, 16), 16);
}
Di sisi lain, sebagian besar encoder MP3 open source akan menyimpan metadata tanpa jeda dalam header Xing khusus yang ditempatkan di dalam frame MPEG senyap (senyap sehingga decoder yang tidak memahami header Xing hanya akan memutar kesunyian). Sayangnya, tag ini tidak selalu ada dan memiliki sejumlah kolom opsional. Untuk tujuan demo ini, kita memiliki kontrol atas media, tetapi dalam praktiknya, beberapa pemeriksaan sensitivitas tambahan akan diperlukan untuk mengetahui kapan metadata tanpa jeda benar-benar tersedia.
Pertama, kita akan mengurai jumlah total sampel. Untuk mempermudah, kita akan membacanya dari
header Xing, tetapi dapat dibuat dari
header audio MPEG normal.
Header Xing dapat ditandai dengan tag Xing atau Info. Tepat 4 byte setelah tag ini, ada 32 bit yang mewakili jumlah total frame dalam file. Mengalikan nilai ini dengan jumlah sampel per frame akan memberi kita total sampel dalam file.
// Xing padding is encoded as 24bits within the header. Note: This code will
// only work for Layer3 Version 1 and Layer2 MP3 files with XING frame counts
// and gapless information. See the following document for more details:
// http://www.codeproject.com/Articles/8295/MPEG-Audio-Frame-Header
var xingDataIndex = byteStr.indexOf('Xing');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Info');
if (xingDataIndex != -1) {
// See section 2.3.1 in the link above for the specifics on parsing the Xing
// frame count.
var frameCountIndex = xingDataIndex + 8;
var frameCount = ReadInt(byteStr.substr(frameCountIndex, 4));
// For Layer3 Version 1 and Layer2 there are 1152 samples per frame. See
// section 2.1.5 in the link above for more details.
var paddedSamples = frameCount * 1152;
// ... we'll cover this below.
Setelah mengetahui jumlah total sampel, kita dapat melanjutkan untuk membaca jumlah sampel padding. Bergantung pada encoder Anda, hal ini dapat ditulis di bawah tag LAME atau Lavf yang berada di dalam header Xing. Tepat 17 byte setelah header ini, ada 3 byte yang mewakili padding depan dan akhir masing-masing dalam 12 bit.
xingDataIndex = byteStr.indexOf('LAME');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Lavf');
if (xingDataIndex != -1) {
// See http://gabriel.mp3-tech.org/mp3infotag.html#delays for details of
// how this information is encoded and parsed.
var gaplessDataIndex = xingDataIndex + 21;
var gaplessBits = ReadInt(byteStr.substr(gaplessDataIndex, 3));
// Upper 12 bits are the front padding, lower are the end padding.
frontPadding = gaplessBits >> 12;
endPadding = gaplessBits & 0xFFF;
}
realSamples = paddedSamples - (frontPadding + endPadding);
}
return {
audioDuration: realSamples * SECONDS_PER_SAMPLE,
frontPaddingDuration: frontPadding * SECONDS_PER_SAMPLE
};
}
Dengan demikian, kita memiliki fungsi lengkap untuk mengurai sebagian besar konten tanpa jeda. Namun, kasus ekstrem tentu saja banyak, jadi sebaiknya berhati-hatilah sebelum menggunakan kode serupa dalam produksi.
Lampiran C: Tentang Pengumpulan Sampah
Memori milik instance SourceBuffer secara aktif
dikumpulkan sampah
sesuai dengan jenis konten, batas khusus platform, dan posisi pemutaran
saat ini. Di Chrome, memori akan pertama-tama diambil kembali dari buffer yang sudah diputar.
Namun, jika penggunaan memori melebihi batas khusus platform, memori akan dihapus dari buffer yang belum diputar.
Saat pemutaran mencapai jeda di linimasa karena memori yang diambil kembali, pemutaran mungkin mengalami gangguan jika jedanya cukup kecil atau berhenti sepenuhnya jika jedanya terlalu besar. Keduanya bukan pengalaman pengguna yang baik, jadi penting untuk menghindari penambahan terlalu banyak data sekaligus dan menghapus rentang dari linimasa media secara manual yang tidak lagi diperlukan.
Rentang dapat dihapus melalui metode
remove()
pada setiap SourceBuffer, yang memerlukan rentang [start, end] dalam detik.
Mirip dengan appendBuffer(), setiap remove() akan memicu peristiwa updateend setelah selesai. Penghapusan atau penambahan lainnya tidak boleh dikeluarkan hingga peristiwa dipicu.
Di Chrome desktop, Anda dapat menyimpan sekitar 12 megabyte konten audio dan 150 megabyte konten video dalam memori sekaligus. Anda tidak boleh mengandalkan nilai ini di seluruh browser atau platform. Misalnya, nilai ini tentu saja tidak mewakili perangkat seluler.
Pengumpulan sampah hanya memengaruhi data yang ditambahkan ke SourceBuffers. Tidak ada batasan jumlah data yang dapat Anda simpan dalam variabel JavaScript. Anda juga dapat menambahkan kembali data yang sama di posisi yang sama jika diperlukan.