

Введение
Расширения Media Source Extensions (MSE) обеспечивают расширенные возможности буферизации и управления воспроизведением для элементов HTML5 <audio> и <video> . Изначально разработанные для поддержки видеоплееров на основе Dynamic Adaptive Streaming over HTTP (DASH) , ниже мы рассмотрим, как их можно использовать для аудио, а именно для воспроизведения без пауз .
Вы наверняка слушали музыкальный альбом, где песни плавно перетекали одна в другую; возможно, вы слушаете такой альбом прямо сейчас. Исполнители создают подобные бесшовные воспроизведения как в качестве художественного замысла, так и как следствие эпохи виниловых пластинок и компакт-дисков , где аудиозапись велась в виде единого непрерывного потока. К сожалению, из-за особенностей современных аудиокодеков, таких как MP3 и AAC , это бесшовное звучание часто утрачивается сегодня.
Подробности ниже, почему так происходит, а пока давайте начнём с демонстрации. Ниже представлены первые тридцать секунд превосходного трека Sintel , разделённые на пять отдельных MP3-файлов и собранные заново с помощью MSE. Красные линии указывают на пробелы, возникшие во время создания (кодирования) каждого MP3-файла; в этих местах вы услышите помехи.
Фу! Это ужасно; мы можем сделать лучше. Немного поработав и используя те же самые MP3-файлы, что и в приведенной выше демонстрации, мы можем с помощью MSE удалить эти раздражающие пробелы. Зеленые линии в следующей демонстрации показывают, где файлы были объединены и пробелы удалены. В Chrome 38+ воспроизведение будет происходить без проблем!
Существует множество способов создания контента без пауз . В рамках этой демонстрации мы сосредоточимся на типах файлов, которые могут быть у обычного пользователя. В них каждый файл закодирован отдельно, без учета аудиосегментов до или после него.
Базовая настройка
Для начала давайте вернемся назад и рассмотрим базовую настройку экземпляра MediaSource . Расширения Media Source, как следует из названия, — это просто дополнения к существующим медиаэлементам. Ниже мы присваиваем Object URL , представляющий наш экземпляр MediaSource , атрибуту источника аудиоэлемента; точно так же, как вы бы задали стандартный URL-адрес.
var audio = document.createElement('audio');
var mediaSource = new MediaSource();
var SEGMENTS = 5;
mediaSource.addEventListener('sourceopen', function () {
var sourceBuffer = mediaSource.addSourceBuffer('audio/mpeg');
function onAudioLoaded(data, index) {
// Append the ArrayBuffer data into our new SourceBuffer.
sourceBuffer.appendBuffer(data);
}
// Retrieve an audio segment via XHR. For simplicity, we're retrieving the
// entire segment at once, but we could also retrieve it in chunks and append
// each chunk separately. MSE will take care of assembling the pieces.
GET('sintel/sintel_0.mp3', function (data) {
onAudioLoaded(data, 0);
});
});
audio.src = URL.createObjectURL(mediaSource);
После подключения объекта MediaSource будет выполнена некоторая инициализация, и в конечном итоге будет сгенерировано событие sourceopen ; после чего мы можем создать объект SourceBuffer . В приведенном выше примере мы создаем объект audio/mpeg , способный анализировать и декодировать наши MP3-сегменты; доступны и другие типы .
Аномальные формы волн
Мы вернемся к коду чуть позже, а сейчас давайте внимательнее рассмотрим только что добавленный файл, а именно его конец. Ниже представлен график последних 3000 выборок, усредненных по обоим каналам трека sintel_0.mp3 . Каждый пиксель на красной линии представляет собой значение с плавающей запятой в диапазоне [-1.0, 1.0] .

Что это за нулевые (тихие) сэмплы?! На самом деле они вызваны артефактами сжатия, возникающими во время кодирования. Практически каждый кодировщик добавляет какой-либо тип заполнения. В данном случае LAME добавил ровно 576 сэмплов заполнения в конец файла.
Помимо отступов в конце, каждый файл также содержал отступы в начале. Если мы посмотрим на трек sintel_1.mp3 то увидим еще 576 сэмплов отступов в начале. Количество отступов варьируется в зависимости от кодировщика и содержимого, но точные значения нам известны на основе metadata содержащихся в каждом файле.
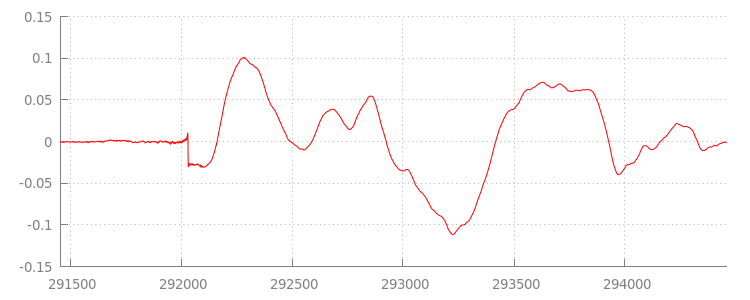
Участки тишины в начале и конце каждого файла — вот что вызывает сбои между сегментами в предыдущем примере. Для воспроизведения без пауз нам нужно удалить эти участки тишины. К счастью, это легко сделать с помощью MediaSource . Ниже мы изменим наш метод onAudioLoaded() , чтобы использовать добавление окна и смещения временной метки для удаления этой тишины.
Пример кода
function onAudioLoaded(data, index) {
// Parsing gapless metadata is unfortunately non trivial and a bit messy, so
// we'll glaze over it here; see the appendix for details.
// ParseGaplessData() will return a dictionary with two elements:
//
// audioDuration: Duration in seconds of all non-padding audio.
// frontPaddingDuration: Duration in seconds of the front padding.
//
var gaplessMetadata = ParseGaplessData(data);
// Each appended segment must be appended relative to the next. To avoid any
// overlaps, we'll use the end timestamp of the last append as the starting
// point for our next append or zero if we haven't appended anything yet.
var appendTime = index > 0 ? sourceBuffer.buffered.end(0) : 0;
// Simply put, an append window allows you to trim off audio (or video) frames
// which fall outside of a specified time range. Here, we'll use the end of
// our last append as the start of our append window and the end of the real
// audio data for this segment as the end of our append window.
sourceBuffer.appendWindowStart = appendTime;
sourceBuffer.appendWindowEnd = appendTime + gaplessMetadata.audioDuration;
// The timestampOffset field essentially tells MediaSource where in the media
// timeline the data given to appendBuffer() should be placed. I.e., if the
// timestampOffset is 1 second, the appended data will start 1 second into
// playback.
//
// MediaSource requires that the media timeline starts from time zero, so we
// need to ensure that the data left after filtering by the append window
// starts at time zero. We'll do this by shifting all of the padding we want
// to discard before our append time (and thus, before our append window).
sourceBuffer.timestampOffset =
appendTime - gaplessMetadata.frontPaddingDuration;
// When appendBuffer() completes, it will fire an updateend event signaling
// that it's okay to append another segment of media. Here, we'll chain the
// append for the next segment to the completion of our current append.
if (index == 0) {
sourceBuffer.addEventListener('updateend', function () {
if (++index < SEGMENTS) {
GET('sintel/sintel_' + index + '.mp3', function (data) {
onAudioLoaded(data, index);
});
} else {
// We've loaded all available segments, so tell MediaSource there are no
// more buffers which will be appended.
mediaSource.endOfStream();
URL.revokeObjectURL(audio.src);
}
});
}
// appendBuffer() will now use the timestamp offset and append window settings
// to filter and timestamp the data we're appending.
//
// Note: While this demo uses very little memory, more complex use cases need
// to be careful about memory usage or garbage collection may remove ranges of
// media in unexpected places.
sourceBuffer.appendBuffer(data);
}
Бесшовная форма волны
Давайте посмотрим, чего добился наш новый код, еще раз взглянув на осциллограмму после применения окон добавления. Ниже вы можете увидеть, что тихий участок в конце sintel_0.mp3 (красным) и тихий участок в начале sintel_1.mp3 (синим) были удалены, что обеспечило плавный переход между сегментами.
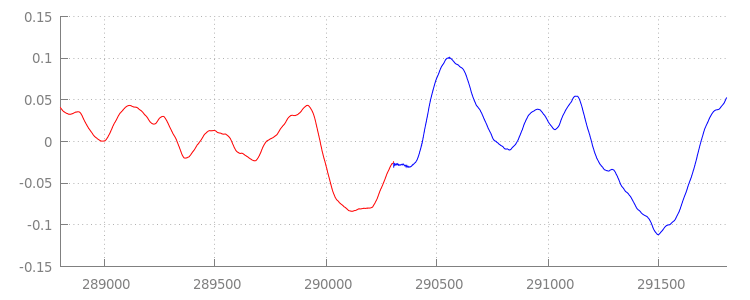
Заключение
Таким образом, мы плавно объединили все пять сегментов в один и подошли к концу нашей демонстрации. Прежде чем мы закончим, вы могли заметить, что наш метод onAudioLoaded() не учитывает контейнеры или кодеки. Это означает, что все эти методы будут работать независимо от типа контейнера или кодека. Ниже вы можете воспроизвести оригинальную демонстрацию в формате MP4, готовом для DASH, вместо MP3.
Если вы хотите узнать больше, ознакомьтесь с приложениями ниже, где более подробно рассматриваются создание контента без пауз и анализ метаданных. Вы также можете изучить gapless.js , чтобы подробнее изучить код, лежащий в основе этой демонстрации.
Спасибо за чтение!
Приложение А: Создание контента без пауз
Создание контента без пауз может быть сложной задачей. Ниже мы рассмотрим процесс создания медиафайлов Sintel , использованных в этой демонстрации. Для начала вам понадобится копия саундтрека Sintel в формате FLAC без потерь ; для истории, хеш SHA1 прилагается ниже. Из инструментов вам понадобятся FFmpeg , MP4Box , LAME и установленная OSX с afconvert .
unzip Jan_Morgenstern-Sintel-FLAC.zip
sha1sum 1-Snow_Fight.flac
# 0535ca207ccba70d538f7324916a3f1a3d550194 1-Snow_Fight.flac
Сначала выделим первые 31,5 секунды из трека 1-Snow_Fight.flac . Также добавим затухание длительностью 2,5 секунды, начиная с 28-й секунды, чтобы избежать щелчков после окончания воспроизведения. Используя приведенную ниже команду FFmpeg, мы сможем сделать все это и поместить результат в sintel.flac .
ffmpeg -i 1-Snow_Fight.flac -t 31.5 -af "afade=t=out:st=28:d=2.5" sintel.flac
Далее мы разделим файл на 5 файлов формата wave по 6,5 секунд каждый; проще всего использовать wave, поскольку почти каждый кодировщик поддерживает его обработку. Опять же, мы можем сделать это точно с помощью FFmpeg, после чего у нас будут: sintel_0.wav , sintel_1.wav , sintel_2.wav , sintel_3.wav и sintel_4.wav .
ffmpeg -i sintel.flac -acodec pcm_f32le -map 0 -f segment \
-segment_list out.list -segment_time 6.5 sintel_%d.wav
Далее, давайте создадим MP3-файлы. LAME предлагает несколько вариантов создания контента без пауз. Если вы контролируете контент, вы можете рассмотреть возможность использования --nogap с пакетным кодированием всех файлов, чтобы полностью избежать заполнения между сегментами. Однако для целей этой демонстрации нам необходимо это заполнение, поэтому мы будем использовать стандартное высококачественное VBR-кодирование файлов wave.
lame -V=2 sintel_0.wav sintel_0.mp3
lame -V=2 sintel_1.wav sintel_1.mp3
lame -V=2 sintel_2.wav sintel_2.mp3
lame -V=2 sintel_3.wav sintel_3.mp3
lame -V=2 sintel_4.wav sintel_4.mp3
Это всё, что необходимо для создания MP3-файлов. Теперь перейдём к созданию фрагментированных MP4-файлов. Мы будем следовать инструкциям Apple по созданию медиафайлов, предназначенных для iTunes . Ниже мы преобразуем файлы wave в промежуточные CAF- файлы в соответствии с инструкциями, а затем закодируем их в AAC в контейнере MP4 , используя рекомендуемые параметры.
afconvert sintel_0.wav sintel_0_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_1.wav sintel_1_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_2.wav sintel_2_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_3.wav sintel_3_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_4.wav sintel_4_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_0_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_0.m4a
afconvert sintel_1_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_1.m4a
afconvert sintel_2_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_2.m4a
afconvert sintel_3_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_3.m4a
afconvert sintel_4_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_4.m4a
Теперь у нас есть несколько файлов M4A, которые необходимо соответствующим образом фрагментировать , прежде чем их можно будет использовать с MediaSource . В наших целях мы будем использовать размер фрагмента в одну секунду. MP4Box запишет каждый фрагментированный MP4-файл как sintel_#_dashinit.mp4 вместе с манифестом MPEG-DASH ( sintel_#_dash.mpd ), который можно удалить.
MP4Box -dash 1000 sintel_0.m4a && mv sintel_0_dashinit.mp4 sintel_0.mp4
MP4Box -dash 1000 sintel_1.m4a && mv sintel_1_dashinit.mp4 sintel_1.mp4
MP4Box -dash 1000 sintel_2.m4a && mv sintel_2_dashinit.mp4 sintel_2.mp4
MP4Box -dash 1000 sintel_3.m4a && mv sintel_3_dashinit.mp4 sintel_3.mp4
MP4Box -dash 1000 sintel_4.m4a && mv sintel_4_dashinit.mp4 sintel_4.mp4
rm sintel_{0,1,2,3,4}_dash.mpd
Вот и всё! Теперь у нас есть фрагментированные файлы MP4 и MP3 с необходимыми метаданными для воспроизведения без пауз. Подробнее о том, как выглядят эти метаданные, см. в Приложении B.
Приложение B: Анализ метаданных без пропусков
Как и создание контента без пауз, разбор метаданных такого контента может быть сложной задачей, поскольку стандартного метода их хранения не существует. Ниже мы рассмотрим, как два наиболее распространенных кодировщика, LAME и iTunes, хранят свои метаданные для контента без пауз. Начнем с создания вспомогательных методов и схемы для функции ParseGaplessData() использованной выше.
// Since most MP3 encoders store the gapless metadata in binary, we'll need a
// method for turning bytes into integers. Note: This doesn't work for values
// larger than 2^30 since we'll overflow the signed integer type when shifting.
function ReadInt(buffer) {
var result = buffer.charCodeAt(0);
for (var i = 1; i < buffer.length; ++i) {
result <<= 8;
result += buffer.charCodeAt(i);
}
return result;
}
function ParseGaplessData(arrayBuffer) {
// Gapless data is generally within the first 512 bytes, so limit parsing.
var byteStr = new TextDecoder().decode(arrayBuffer.slice(0, 512));
var frontPadding = 0, endPadding = 0, realSamples = 0;
// ... we'll fill this in as we go below.
Сначала рассмотрим формат метаданных iTunes от Apple, поскольку его проще всего понять и объяснить. В файлах MP3 и M4A iTunes (и afconvert) записывают короткий фрагмент в формате ASCII следующим образом:
iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00
Эта информация записывается внутри тега ID3 в контейнере MP3 и внутри атома метаданных в контейнере MP4. В наших целях мы можем игнорировать первый токен 0000000 Следующие три токена — это начальное заполнение, конечное заполнение и общее количество сэмплов без заполнения. Разделив каждый из них на частоту дискретизации аудио, мы получим длительность каждого из них.
// iTunes encodes the gapless data as hex strings like so:
//
// 'iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00'
// 'iTunSMPB[ 26 bytes ]####### frontpad endpad real samples'
//
// The approach here elides the complexity of actually parsing MP4 atoms. It
// may not work for all files without some tweaks.
var iTunesDataIndex = byteStr.indexOf('iTunSMPB');
if (iTunesDataIndex != -1) {
var frontPaddingIndex = iTunesDataIndex + 34;
frontPadding = parseInt(byteStr.substr(frontPaddingIndex, 8), 16);
var endPaddingIndex = frontPaddingIndex + 9;
endPadding = parseInt(byteStr.substr(endPaddingIndex, 8), 16);
var sampleCountIndex = endPaddingIndex + 9;
realSamples = parseInt(byteStr.substr(sampleCountIndex, 16), 16);
}
С другой стороны, большинство кодеков MP3 с открытым исходным кодом хранят метаданные без пауз в специальном заголовке Xing , помещенном внутрь кадра MPEG без пауз (он без пауз, поэтому декодеры, которые не понимают заголовок Xing, просто будут воспроизводить тишину). К сожалению, этот тег присутствует не всегда и имеет ряд необязательных полей. В целях этой демонстрации мы контролируем медиафайл, но на практике потребуются дополнительные проверки чувствительности, чтобы определить, когда метаданные без пауз действительно доступны.
Сначала разберем общее количество сэмплов. Для простоты мы прочитаем его из заголовка Xing, но его можно составить из обычного заголовка аудиофайла MPEG . Заголовки Xing могут быть помечены либо тегом Xing , либо тегом Info . Ровно через 4 байта после этого тега находятся 32 бита, представляющие общее количество кадров в файле; умножив это значение на количество сэмплов в кадре, мы получим общее количество сэмплов в файле.
// Xing padding is encoded as 24bits within the header. Note: This code will
// only work for Layer3 Version 1 and Layer2 MP3 files with XING frame counts
// and gapless information. See the following document for more details:
// http://www.codeproject.com/Articles/8295/MPEG-Audio-Frame-Header
var xingDataIndex = byteStr.indexOf('Xing');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Info');
if (xingDataIndex != -1) {
// See section 2.3.1 in the link above for the specifics on parsing the Xing
// frame count.
var frameCountIndex = xingDataIndex + 8;
var frameCount = ReadInt(byteStr.substr(frameCountIndex, 4));
// For Layer3 Version 1 and Layer2 there are 1152 samples per frame. See
// section 2.1.5 in the link above for more details.
var paddedSamples = frameCount * 1152;
// ... we'll cover this below.
Теперь, когда у нас есть общее количество выборок, мы можем перейти к считыванию количества выборок заполнения. В зависимости от вашего кодировщика это может быть записано под тегом LAME или Lavf, вложенным в заголовок Xing. Ровно через 17 байт после этого заголовка находятся 3 байта, представляющие собой заполнение начала и конца, каждое по 12 бит.
xingDataIndex = byteStr.indexOf('LAME');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Lavf');
if (xingDataIndex != -1) {
// See http://gabriel.mp3-tech.org/mp3infotag.html#delays for details of
// how this information is encoded and parsed.
var gaplessDataIndex = xingDataIndex + 21;
var gaplessBits = ReadInt(byteStr.substr(gaplessDataIndex, 3));
// Upper 12 bits are the front padding, lower are the end padding.
frontPadding = gaplessBits >> 12;
endPadding = gaplessBits & 0xFFF;
}
realSamples = paddedSamples - (frontPadding + endPadding);
}
return {
audioDuration: realSamples * SECONDS_PER_SAMPLE,
frontPaddingDuration: frontPadding * SECONDS_PER_SAMPLE
};
}
Таким образом, мы получаем полноценную функцию для анализа подавляющего большинства контента без пауз. Однако, безусловно, существует множество исключительных случаев, поэтому следует проявлять осторожность, прежде чем использовать подобный код в рабочей среде.
Приложение C: О сборе мусора
Память, принадлежащая экземплярам SourceBuffer , активно очищается сборщиком мусора в зависимости от типа контента, ограничений платформы и текущей позиции воспроизведения. В Chrome память сначала освобождается из уже воспроизведенных буферов. Однако, если использование памяти превышает ограничения платформы, память удаляется из невоспроизведенных буферов.
Когда воспроизведение достигает разрыва на временной шкале из-за освобожденной памяти, оно может дать сбой, если разрыв достаточно мал, или полностью зависнуть, если разрыв слишком велик. Ни один из этих вариантов не является удобным для пользователя, поэтому важно избегать добавления слишком большого объема данных одновременно и вручную удалять из временной шкалы медиафайлов диапазоны, которые больше не нужны.
Удалять диапазоны можно с помощью метода remove() каждого SourceBuffer ; он принимает диапазон [start, end] в секундах. Аналогично методу appendBuffer() , каждый remove() после завершения вызовет событие updateend . Другие операции удаления или добавления не следует выполнять до тех пор, пока не сработает это событие.
В настольной версии Chrome одновременно в памяти можно хранить приблизительно 12 мегабайт аудиоконтента и 150 мегабайт видеоконтента. Не следует полагаться на эти значения в других браузерах или на других платформах; например, они, безусловно, не отражают ситуацию на мобильных устройствах.
Сборка мусора влияет только на данные, добавляемые в SourceBuffers ; нет ограничений на объем данных, которые можно хранить в буферах переменных JavaScript. При необходимости вы также можете повторно добавить те же данные в ту же позицию.