

Wprowadzenie
Media Source Extensions (MSE) zapewniają rozszerzone buforowanie i sterowanie odtwarzaniem w przypadku elementów HTML5 <audio> i <video>. Chociaż początkowo zostały opracowane z myślą o odtwarzaczach wideo opartych na dynamicznym adaptacyjnym strumieniowym przesyłaniu danych przez HTTP (DASH), poniżej zobaczymy, jak można ich używać w przypadku dźwięku, a konkretnie do odtwarzania bez przerw.
Pewnie zdarzyło Ci się słuchać albumu muzycznego, na którym utwory płynnie przechodziły jeden w drugi. Być może słuchasz takiego albumu właśnie teraz. Wykonawcy tworzą te doświadczenia odtwarzania bez przerw zarówno jako wybór artystyczny, jak i jako artefakt płyt winylowych i CD, na których dźwięk był zapisywany jako jeden ciągły strumień. Niestety ze względu na sposób działania nowoczesnych kodeków audio, takich jak MP3 i AAC, to płynne wrażenie słuchowe jest dziś często tracone.
Poniżej wyjaśnimy, dlaczego tak się dzieje, ale na razie zacznijmy od demonstracji. Poniżej znajdziesz pierwsze 30 sekund doskonałego filmu Sintel, które zostały podzielone na 5 osobnych plików MP3 i ponownie zmontowane za pomocą MSE. Czerwone linie oznaczają przerwy wprowadzone podczas tworzenia (kodowania) każdego pliku MP3. W tych miejscach usłyszysz zakłócenia.
Fuj! To nie jest najlepsze rozwiązanie. Możemy to poprawić. Wkładając nieco więcej pracy, możemy użyć dokładnie tych samych plików MP3 co w powyższym przykładzie i za pomocą MSE usunąć te irytujące przerwy. Zielone linie w następnej prezentacji pokazują, gdzie pliki zostały połączone, a luki usunięte. W Chrome w wersji 38 lub nowszej odtwarzanie będzie przebiegać bezproblemowo.
Istnieje wiele sposobów na tworzenie treści bez przerw. Na potrzeby tej prezentacji skupimy się na typach plików, które zwykły użytkownik może mieć na komputerze. Każdy plik jest kodowany oddzielnie, bez względu na segmenty audio przed nim i po nim.
Konfiguracja podstawowa
Najpierw cofnijmy się i omówmy podstawową konfigurację instancji MediaSource.
Media Source Extensions, jak sama nazwa wskazuje, są po prostu rozszerzeniami istniejących elementów multimedialnych. Poniżej przypisujemy Object URL, reprezentujący naszą instancję MediaSource, do atrybutu source elementu audio, tak jak w przypadku standardowego adresu URL.
var audio = document.createElement('audio');
var mediaSource = new MediaSource();
var SEGMENTS = 5;
mediaSource.addEventListener('sourceopen', function () {
var sourceBuffer = mediaSource.addSourceBuffer('audio/mpeg');
function onAudioLoaded(data, index) {
// Append the ArrayBuffer data into our new SourceBuffer.
sourceBuffer.appendBuffer(data);
}
// Retrieve an audio segment via XHR. For simplicity, we're retrieving the
// entire segment at once, but we could also retrieve it in chunks and append
// each chunk separately. MSE will take care of assembling the pieces.
GET('sintel/sintel_0.mp3', function (data) {
onAudioLoaded(data, 0);
});
});
audio.src = URL.createObjectURL(mediaSource);
Po połączeniu obiektu MediaSource zostanie przeprowadzona inicjalizacja i wywołane zdarzenie sourceopen. W tym momencie możemy utworzyć obiekt SourceBuffer. W przykładzie powyżej tworzymy element audio/mpeg, który może analizować i dekodować segmenty MP3. Dostępnych jest kilka innych typów.
Nietypowe przebiegi
Za chwilę wrócimy do kodu, ale teraz przyjrzyjmy się dokładniej plikowi, który właśnie dołączyliśmy, a zwłaszcza jego końcowi. Poniżej znajduje się wykres ostatnich 3000 próbek uśrednionych w obu kanałach ze ścieżki sintel_0.mp3. Każdy piksel na czerwonej linii to próbka zmiennoprzecinkowa w zakresie [-1.0, 1.0].

Dlaczego jest tak dużo próbek o wartości zero (cichych)? Są one spowodowane artefaktami kompresji, które pojawiają się podczas kodowania. Prawie każdy koder wprowadza jakiś rodzaj wypełnienia. W tym przypadku koder LAME dodał dokładnie 576 próbek dopełniających na końcu pliku.
Oprócz dopełnienia na końcu każdy plik miał też dopełnienie na początku. Jeśli zajrzymy do sintel_1.mp3ścieżki, zobaczymy, że na początku znajduje się kolejne 576 próbek dopełnienia. Wielkość dopełnienia różni się w zależności od kodera i treści, ale znamy dokładne wartości na podstawie metadata zawartych w każdym pliku.
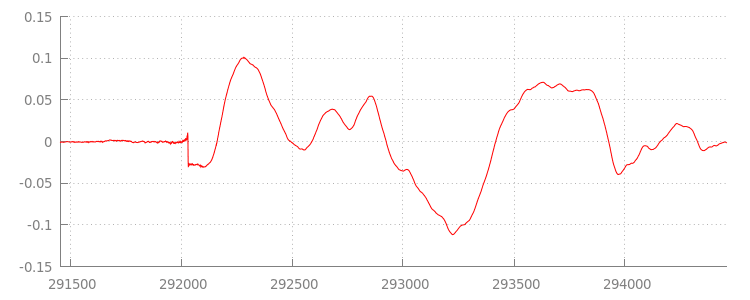
Fragmenty ciszy na początku i na końcu każdego pliku powodują zakłócenia między segmentami w poprzedniej wersji demonstracyjnej. Aby uzyskać odtwarzanie bez przerw, musimy usunąć te fragmenty ciszy. Na szczęście można to łatwo zrobić za pomocą MediaSource. Poniżej zmodyfikujemy naszą metodę onAudioLoaded(), aby użyć okna dołączania i przesunięcia sygnatury czasowej w celu usunięcia ciszy.
Przykładowy kod
function onAudioLoaded(data, index) {
// Parsing gapless metadata is unfortunately non trivial and a bit messy, so
// we'll glaze over it here; see the appendix for details.
// ParseGaplessData() will return a dictionary with two elements:
//
// audioDuration: Duration in seconds of all non-padding audio.
// frontPaddingDuration: Duration in seconds of the front padding.
//
var gaplessMetadata = ParseGaplessData(data);
// Each appended segment must be appended relative to the next. To avoid any
// overlaps, we'll use the end timestamp of the last append as the starting
// point for our next append or zero if we haven't appended anything yet.
var appendTime = index > 0 ? sourceBuffer.buffered.end(0) : 0;
// Simply put, an append window allows you to trim off audio (or video) frames
// which fall outside of a specified time range. Here, we'll use the end of
// our last append as the start of our append window and the end of the real
// audio data for this segment as the end of our append window.
sourceBuffer.appendWindowStart = appendTime;
sourceBuffer.appendWindowEnd = appendTime + gaplessMetadata.audioDuration;
// The timestampOffset field essentially tells MediaSource where in the media
// timeline the data given to appendBuffer() should be placed. I.e., if the
// timestampOffset is 1 second, the appended data will start 1 second into
// playback.
//
// MediaSource requires that the media timeline starts from time zero, so we
// need to ensure that the data left after filtering by the append window
// starts at time zero. We'll do this by shifting all of the padding we want
// to discard before our append time (and thus, before our append window).
sourceBuffer.timestampOffset =
appendTime - gaplessMetadata.frontPaddingDuration;
// When appendBuffer() completes, it will fire an updateend event signaling
// that it's okay to append another segment of media. Here, we'll chain the
// append for the next segment to the completion of our current append.
if (index == 0) {
sourceBuffer.addEventListener('updateend', function () {
if (++index < SEGMENTS) {
GET('sintel/sintel_' + index + '.mp3', function (data) {
onAudioLoaded(data, index);
});
} else {
// We've loaded all available segments, so tell MediaSource there are no
// more buffers which will be appended.
mediaSource.endOfStream();
URL.revokeObjectURL(audio.src);
}
});
}
// appendBuffer() will now use the timestamp offset and append window settings
// to filter and timestamp the data we're appending.
//
// Note: While this demo uses very little memory, more complex use cases need
// to be careful about memory usage or garbage collection may remove ranges of
// media in unexpected places.
sourceBuffer.appendBuffer(data);
}
Płynna fala
Sprawdźmy, co udało się osiągnąć dzięki naszemu nowemu kodowi. W tym celu ponownie przyjrzyjmy się przebiegowi fali po zastosowaniu okien dołączania. Poniżej widać, że usunięto cichą sekcję na końcu sintel_0.mp3 (na czerwono) i cichą sekcję na początku sintel_1.mp3 (na niebiesko), dzięki czemu przejście między segmentami jest płynne.
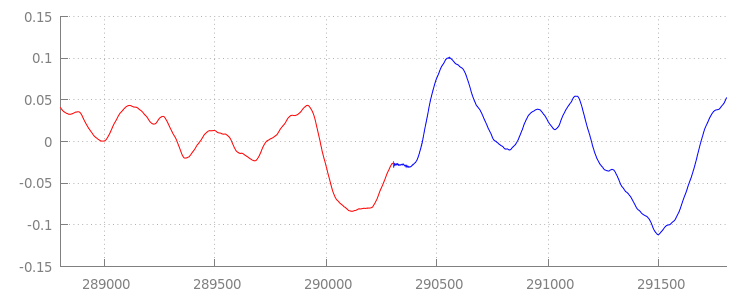
Podsumowanie
Połączyliśmy wszystkie 5 segmentów w jeden i na tym kończymy naszą prezentację. Zanim skończymy, warto zauważyć, że nasza metoda onAudioLoaded() nie uwzględnia kontenerów ani kodeków.
Oznacza to, że wszystkie te techniki będą działać niezależnie od kontenera lub typu kodeka. Poniżej możesz odtworzyć oryginalną wersję demonstracyjną DASH w postaci podzielonego pliku MP4 zamiast MP3.
Jeśli chcesz dowiedzieć się więcej, zapoznaj się z załącznikami poniżej, w których znajdziesz szczegółowe informacje o tworzeniu treści bez przerw i parsowaniu metadanych. Możesz też gapless.js, aby przyjrzeć się bliżej kodowi, który obsługuje tę wersję demonstracyjną.
Dziękujemy za uwagę!
Dodatek A. Tworzenie treści bez przerw
Tworzenie treści bez przerw może być trudne. Poniżej przedstawimy proces tworzenia multimediów Sintel użytych w tej wersji demonstracyjnej. Na początek potrzebujesz kopii bezstratnej ścieżki dźwiękowej FLAC do filmu Sintel. Poniżej znajdziesz SHA1. Do korzystania z narzędzi potrzebne będą: FFmpeg, MP4Box, LAME i instalacja OSX z afconvert.
unzip Jan_Morgenstern-Sintel-FLAC.zip
sha1sum 1-Snow_Fight.flac
# 0535ca207ccba70d538f7324916a3f1a3d550194 1-Snow_Fight.flac
Najpierw wyodrębnimy pierwsze 31, 5 sekundy ścieżki 1-Snow_Fight.flac. Chcemy też dodać 2,5-sekundowe wyciszenie, które zacznie się w 28 sekundzie, aby uniknąć kliknięć po zakończeniu odtwarzania. Za pomocą poniższego wiersza poleceń FFmpeg możemy wykonać wszystkie te czynności i umieścić wyniki w pliku sintel.flac.
ffmpeg -i 1-Snow_Fight.flac -t 31.5 -af "afade=t=out:st=28:d=2.5" sintel.flac
Następnie podzielimy plik na 5 plików wave o długości 6,5 sekundy każdy.Najłatwiej jest użyć formatu wave, ponieważ prawie każdy koder obsługuje jego wczytywanie. Możemy to zrobić precyzyjnie za pomocą FFmpeg, po czym otrzymamy: sintel_0.wav, sintel_1.wav, sintel_2.wav, sintel_3.wav i sintel_4.wav.
ffmpeg -i sintel.flac -acodec pcm_f32le -map 0 -f segment \
-segment_list out.list -segment_time 6.5 sintel_%d.wav
Teraz utwórzmy pliki MP3. LAME ma kilka opcji tworzenia treści bez przerw. Jeśli masz kontrolę nad treścią, możesz użyć --nogap
z kodowaniem wsadowym wszystkich plików, aby całkowicie uniknąć dopełniania między segmentami.
Na potrzeby tej wersji demonstracyjnej chcemy jednak zachować dopełnienie, dlatego użyjemy standardowego kodowania VBR wysokiej jakości w przypadku plików wave.
lame -V=2 sintel_0.wav sintel_0.mp3
lame -V=2 sintel_1.wav sintel_1.mp3
lame -V=2 sintel_2.wav sintel_2.mp3
lame -V=2 sintel_3.wav sintel_3.mp3
lame -V=2 sintel_4.wav sintel_4.mp3
To wszystko, co jest potrzebne do utworzenia plików MP3. Teraz omówimy tworzenie fragmentów plików MP4. Będziemy postępować zgodnie z instrukcjami Apple dotyczącymi tworzenia multimediów zoptymalizowanych pod kątem iTunes. Poniżej przekonwertujemy pliki WAV na pośrednie pliki CAF zgodnie z instrukcjami, a następnie zakodujemy je jako AAC w kontenerze MP4, używając zalecanych parametrów.
afconvert sintel_0.wav sintel_0_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_1.wav sintel_1_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_2.wav sintel_2_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_3.wav sintel_3_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_4.wav sintel_4_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_0_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_0.m4a
afconvert sintel_1_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_1.m4a
afconvert sintel_2_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_2.m4a
afconvert sintel_3_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_3.m4a
afconvert sintel_4_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_4.m4a
Mamy teraz kilka plików M4A, które musimy odpowiednio sfragmentować, zanim będzie można ich użyć w MediaSource. Na potrzeby tego przykładu użyjemy rozmiaru fragmentu wynoszącego 1 sekundę. MP4Box zapisze każdy fragmentowany plik MP4 jako sintel_#_dashinit.mp4 wraz z plikiem manifestu MPEG-DASH (sintel_#_dash.mpd), który można odrzucić.
MP4Box -dash 1000 sintel_0.m4a && mv sintel_0_dashinit.mp4 sintel_0.mp4
MP4Box -dash 1000 sintel_1.m4a && mv sintel_1_dashinit.mp4 sintel_1.mp4
MP4Box -dash 1000 sintel_2.m4a && mv sintel_2_dashinit.mp4 sintel_2.mp4
MP4Box -dash 1000 sintel_3.m4a && mv sintel_3_dashinit.mp4 sintel_3.mp4
MP4Box -dash 1000 sintel_4.m4a && mv sintel_4_dashinit.mp4 sintel_4.mp4
rm sintel_{0,1,2,3,4}_dash.mpd
To wszystko. Mamy teraz podzielone na fragmenty pliki MP4 i MP3 z prawidłowymi metadanymi niezbędnymi do odtwarzania bez przerw. Więcej informacji o tym, jak wyglądają te metadane, znajdziesz w Dodatku B.
Załącznik B. Analizowanie metadanych bez przerw
Podobnie jak w przypadku tworzenia treści bez przerw, analizowanie metadanych bez przerw może być trudne, ponieważ nie ma standardowej metody przechowywania. Poniżej wyjaśnimy, jak 2 najpopularniejsze kodery, LAME i iTunes, przechowują metadane bez przerw. Zacznijmy od skonfigurowania kilku metod pomocniczych i szkicu ParseGaplessData() użytego powyżej.
// Since most MP3 encoders store the gapless metadata in binary, we'll need a
// method for turning bytes into integers. Note: This doesn't work for values
// larger than 2^30 since we'll overflow the signed integer type when shifting.
function ReadInt(buffer) {
var result = buffer.charCodeAt(0);
for (var i = 1; i < buffer.length; ++i) {
result <<= 8;
result += buffer.charCodeAt(i);
}
return result;
}
function ParseGaplessData(arrayBuffer) {
// Gapless data is generally within the first 512 bytes, so limit parsing.
var byteStr = new TextDecoder().decode(arrayBuffer.slice(0, 512));
var frontPadding = 0, endPadding = 0, realSamples = 0;
// ... we'll fill this in as we go below.
Najpierw omówimy format metadanych iTunes firmy Apple, ponieważ jest on najłatwiejszy do przeanalizowania i wyjaśnienia. W plikach MP3 i M4A iTunes (i afconvert) zapisuje krótki fragment w ASCII w ten sposób:
iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00
Jest on zapisywany w tagu ID3 w kontenerze MP3 oraz w atomie metadanych w kontenerze MP4. Na potrzeby tego przykładu możemy zignorować pierwszy token 0000000. Kolejne 3 tokeny to dopełnienie z przodu, dopełnienie z tyłu i łączna liczba próbek bez dopełnienia. Podzielenie każdej z tych wartości przez częstotliwość próbkowania dźwięku daje czas trwania każdej z nich.
// iTunes encodes the gapless data as hex strings like so:
//
// 'iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00'
// 'iTunSMPB[ 26 bytes ]####### frontpad endpad real samples'
//
// The approach here elides the complexity of actually parsing MP4 atoms. It
// may not work for all files without some tweaks.
var iTunesDataIndex = byteStr.indexOf('iTunSMPB');
if (iTunesDataIndex != -1) {
var frontPaddingIndex = iTunesDataIndex + 34;
frontPadding = parseInt(byteStr.substr(frontPaddingIndex, 8), 16);
var endPaddingIndex = frontPaddingIndex + 9;
endPadding = parseInt(byteStr.substr(endPaddingIndex, 8), 16);
var sampleCountIndex = endPaddingIndex + 9;
realSamples = parseInt(byteStr.substr(sampleCountIndex, 16), 16);
}
Z drugiej strony większość koderów MP3 typu open source przechowuje metadane bez przerw w specjalnym nagłówku Xing umieszczonym w cichej ramce MPEG (jest ona cicha, więc dekodery, które nie rozumieją nagłówka Xing, po prostu odtworzą ciszę). Niestety ten tag nie zawsze występuje i ma kilka pól opcjonalnych. Na potrzeby tej wersji demonstracyjnej mamy kontrolę nad multimediami, ale w praktyce konieczne będzie przeprowadzenie dodatkowych testów, aby sprawdzić, kiedy metadane bez przerw są rzeczywiście dostępne.
Najpierw przeanalizujemy łączną liczbę próbek. Dla uproszczenia odczytamy tę wartość z nagłówka Xing, ale można ją też utworzyć na podstawie zwykłego nagłówka audio MPEG.
Nagłówki Xing mogą być oznaczone tagiem Xing lub Info. Dokładnie 4 bajty po tym tagu znajdują się 32-bitowe dane reprezentujące łączną liczbę klatek w pliku. Pomnożenie tej wartości przez liczbę próbek na klatkę da nam łączną liczbę próbek w pliku.
// Xing padding is encoded as 24bits within the header. Note: This code will
// only work for Layer3 Version 1 and Layer2 MP3 files with XING frame counts
// and gapless information. See the following document for more details:
// http://www.codeproject.com/Articles/8295/MPEG-Audio-Frame-Header
var xingDataIndex = byteStr.indexOf('Xing');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Info');
if (xingDataIndex != -1) {
// See section 2.3.1 in the link above for the specifics on parsing the Xing
// frame count.
var frameCountIndex = xingDataIndex + 8;
var frameCount = ReadInt(byteStr.substr(frameCountIndex, 4));
// For Layer3 Version 1 and Layer2 there are 1152 samples per frame. See
// section 2.1.5 in the link above for more details.
var paddedSamples = frameCount * 1152;
// ... we'll cover this below.
Teraz, gdy mamy łączną liczbę próbek, możemy przejść do odczytania liczby próbek dopełniających. W zależności od kodera może to być zapisane w tagu LAME lub Lavf zagnieżdżonym w nagłówku Xing. Dokładnie 17 bajtów po tym nagłówku znajdują się 3 bajty reprezentujące odpowiednio dopełnienie z przodu i z tyłu w 12-bitowych blokach.
xingDataIndex = byteStr.indexOf('LAME');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Lavf');
if (xingDataIndex != -1) {
// See http://gabriel.mp3-tech.org/mp3infotag.html#delays for details of
// how this information is encoded and parsed.
var gaplessDataIndex = xingDataIndex + 21;
var gaplessBits = ReadInt(byteStr.substr(gaplessDataIndex, 3));
// Upper 12 bits are the front padding, lower are the end padding.
frontPadding = gaplessBits >> 12;
endPadding = gaplessBits & 0xFFF;
}
realSamples = paddedSamples - (frontPadding + endPadding);
}
return {
audioDuration: realSamples * SECONDS_PER_SAMPLE,
frontPaddingDuration: frontPadding * SECONDS_PER_SAMPLE
};
}
Dzięki temu mamy kompletną funkcję do analizowania zdecydowanej większości treści bez przerw. Z pewnością istnieje wiele przypadków brzegowych, dlatego przed użyciem podobnego kodu w środowisku produkcyjnym zalecamy zachowanie ostrożności.
Załącznik C. Czyszczenie pamięci
Pamięć należąca do instancji SourceBuffer jest aktywnie oczyszczana zgodnie z typem treści, limitami specyficznymi dla platformy i bieżącą pozycją odtwarzania. W Chrome pamięć będzie najpierw odzyskiwana z buforów, które zostały już odtworzone.
Jeśli jednak wykorzystanie pamięci przekroczy limity określone dla danej platformy, usunie pamięć z nieodtwarzanych buforów.
Gdy odtwarzanie osiągnie lukę na osi czasu spowodowaną odzyskaniem pamięci, może wystąpić usterka, jeśli luka jest wystarczająco mała, lub całkowite zatrzymanie, jeśli luka jest zbyt duża. Żadne z tych rozwiązań nie zapewnia użytkownikom wygody, dlatego ważne jest, aby nie dołączać zbyt wielu danych naraz i ręcznie usuwać z osi czasu multimediów zakresów, które nie są już potrzebne.
Zakresy można usuwać za pomocą metody
remove()
w przypadku każdego SourceBuffer, która przyjmuje zakres [start, end] w sekundach.
Podobnie jak w przypadku appendBuffer(), każde remove() wywoła zdarzenie updateend po zakończeniu. Inne operacje usuwania lub dołączania nie powinny być wykonywane do czasu wywołania zdarzenia.
W Chrome na komputerze możesz przechowywać w pamięci jednocześnie około 12 MB treści audio i 150 MB treści wideo. Nie należy polegać na tych wartościach w różnych przeglądarkach ani na różnych platformach. Nie są one na przykład reprezentatywne dla urządzeń mobilnych.
Czyszczenie pamięci ma wpływ tylko na dane dodane do SourceBuffers. Nie ma ograniczeń co do ilości danych, które można przechowywać w zmiennych JavaScriptu. W razie potrzeby możesz też ponownie dodać te same dane w tym samym miejscu.