

虽然网络上的大多数 AI 功能都依赖于服务器,但客户端 AI 会直接在用户的浏览器中运行。这具有诸多优势,包括延迟时间短、服务器端费用降低、无需 API 密钥、增强用户隐私保护和支持离线访问。您可以使用 TensorFlow.js、Transformers.js 和 MediaPipe GenAI 等 JavaScript 库实现可在不同浏览器中运行的客户端 AI。
客户端 AI 还会带来性能方面的问题:用户必须下载更多文件,浏览器也必须更努力地工作。为了让其正常运行,请考虑以下事项:
- 您的使用情形。客户端 AI 是否适合您的功能?您的功能是否位于关键用户历程中?如果是,您是否有后备方案?
- 有关模型下载和使用方面的良好做法。请继续阅读本文以了解详细信息。
模型下载前
Mind 库和模型大小
如需实现客户端 AI,您需要一个模型,通常还需要一个库。选择库时,请像评估任何其他工具一样评估其大小。
模型大小也很重要。什么是大型 AI 模型取决于具体情况。5MB 是一个实用的经验法则:它也是网页大小中位数的第 75 百分位数。更宽松的数字是 10MB。
以下是关于模型大小的一些重要注意事项:
- 许多特定于任务的 AI 模型可能非常小。BudouX 等用于准确分割亚洲语言字符的模型经过 GZIP 压缩后只有 9.4KB。MediaPipe 的语言检测模型为 315KB。
- 即使是视觉模型,也可以控制在合理的大小。Handpose 模型和所有相关资源总计 13.4MB。虽然这比大多数缩减后的前端软件包大得多,但与中位数网页(2.2MB,桌面版为 2.6MB)相当。
- 生成式 AI 模型可能会超出网站资源的推荐大小。DistilBERT 被认为是一个非常小的 LLM 或一个简单的 NLP 模型(观点各异),其大小为 67MB。即使是小型 LLM(例如 Gemma 2B),也可能达到 1.3GB。这比中位数网页的大小大 100 倍以上。
您可以使用浏览器的开发者工具评估您计划使用的模型的确切下载大小。


优化模型大小
- 比较模型质量和下载大小。较小的模型可能足以满足您的应用场景需求,同时体积要小得多。微调和模型缩减技术旨在显著缩减模型的大小,同时保持足够的精度。
- 尽可能选择专用模型。专为特定任务量身定制的模型往往较小。例如,如果您要执行情感分析或恶意言论分析等特定任务,请使用专门用于这些任务的模型,而不是通用 LLM。
虽然所有这些模型执行的任务相同,但准确率各不相同,并且大小也差异很大:从 3MB 到 1.5GB。
检查模型能否运行
并非所有设备都可以运行 AI 模型。如果在使用模型时运行或启动了其他耗费资源的进程,即使硬件规格足够的设备也可能会出现问题。
在解决方案推出之前,您可以执行以下操作:
- 检查 WebGPU 支持情况。包括 Transformers.js 版本 3 和 MediaPipe 在内的多个客户端 AI 库都使用 WebGPU。目前,如果不支持 WebGPU,其中一些库不会自动回退到 Wasm。如果您知道客户端 AI 库需要 WebGPU,则可以将与 AI 相关的代码封装在 WebGPU 功能检测检查中,以缓解此问题。
- 排除功率不足的设备。使用 Navigator.hardwareConcurrency、Navigator.deviceMemory 和 Compute Pressure API 估算设备功能和压力。并非所有浏览器都支持这些 API,而且这些 API 是故意不精确的,以防止进行设备指纹识别,但它们仍有助于排除看起来性能非常低下的设备。
指示下载内容较大
对于大型模型,请在下载前提醒用户。与移动用户相比,桌面用户更有可能接受大容量下载。如需检测移动设备,请使用 User-Agent Client Hints API 中的 mobile(如果 UA-CH 不受支持,则使用 User-Agent 字符串)。
限制下载大型文件
- 仅下载必要的内容。尤其是在模型较大的情况下,请仅在有充分把握 AI 功能会被使用时下载。例如,如果您有智能输入法建议 AI 功能,请仅在用户开始使用输入法功能时下载。
- 使用 Cache API 在设备上显式缓存模型,以避免每次访问时都下载该模型。请勿仅依赖于隐式 HTTP 浏览器缓存。
- 将模型下载分块。fetch-in-chunks 会将大下载内容拆分成较小的分块。
模型下载和准备
不要屏蔽用户
优先考虑顺畅的用户体验:即使 AI 模型尚未完全加载,也允许关键功能正常运行。
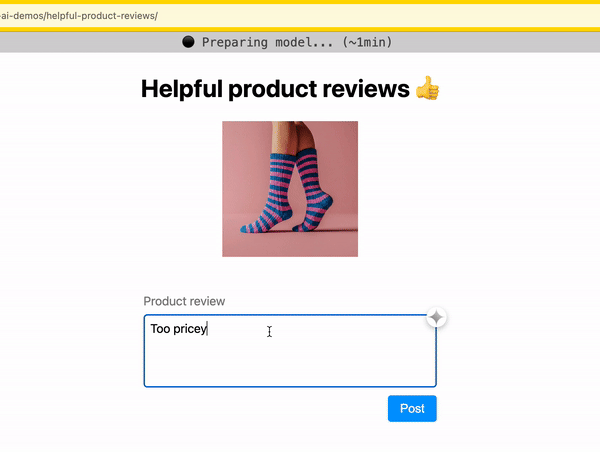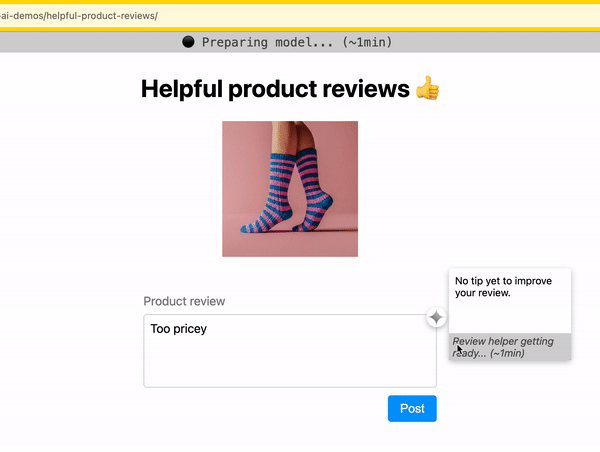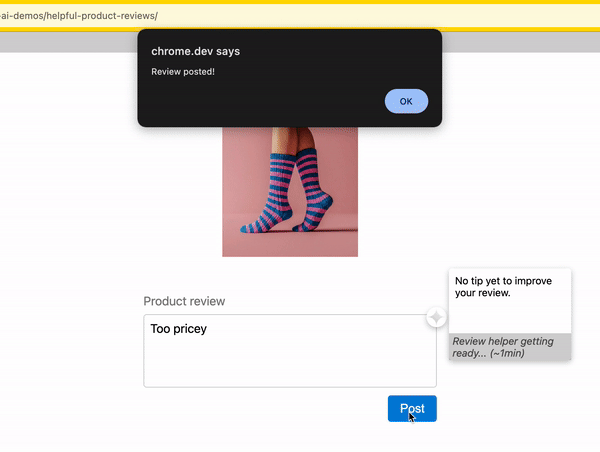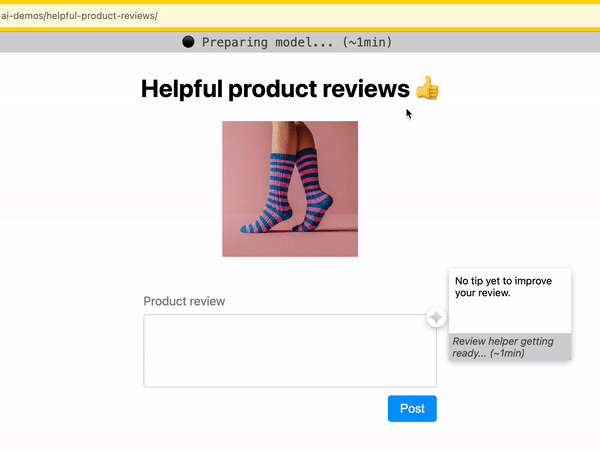
指示进度
在下载模型时,指明已完成的进度和剩余时间。
- 如果模型下载由客户端 AI 库处理,请使用下载进度状态向用户显示下载进度。如果此功能不可用,不妨考虑提交问题来请求此功能(或贡献此功能!)。
- 如果您在自己的代码中处理模型下载,则可以使用库(例如 fetch-in-chunks)分块提取模型,并向用户显示下载进度。
- 如需更多建议,请参阅动画进度指示器的最佳实践和针对长时间等待和中断进行设计。
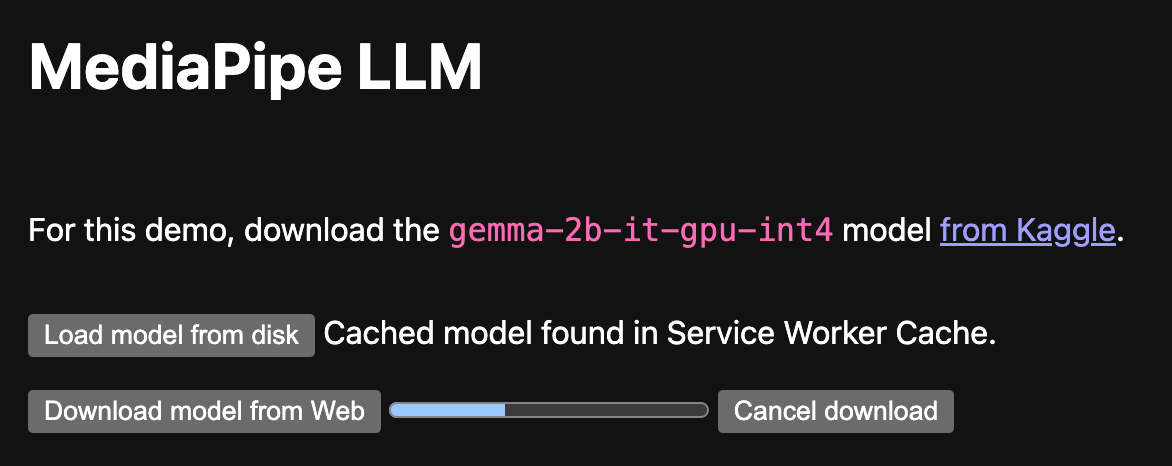
妥善处理网络中断
模型下载可能需要不同的时间,具体取决于模型的大小。 考虑在用户离线时如何处理网络中断。请尽可能告知用户连接中断,并在连接恢复后继续下载。
不稳定的网络连接也是分块下载的原因之一。
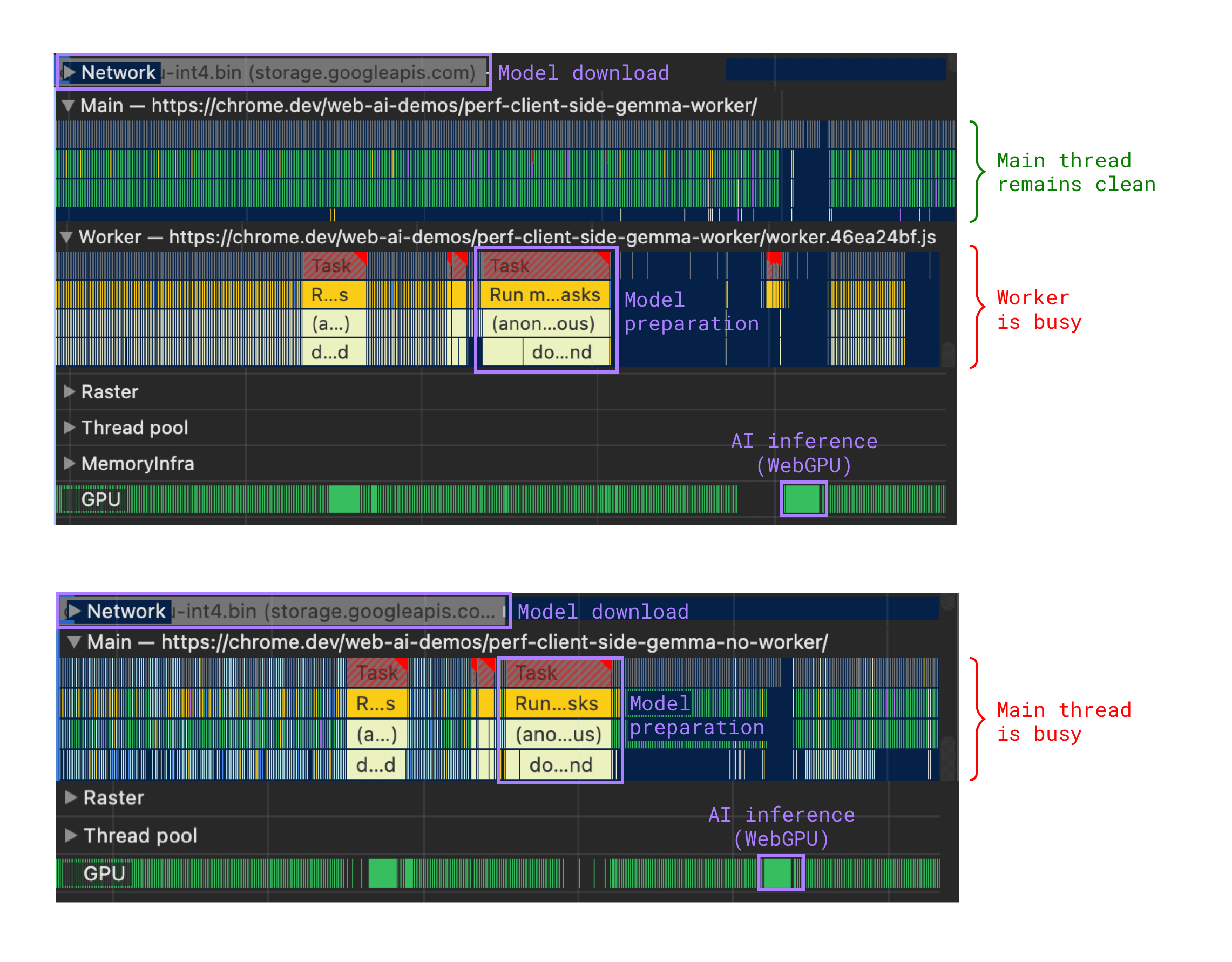
将耗时的任务分流到 Web Worker
耗时的任务(例如下载后的模型准备步骤)可能会阻塞主线程,导致用户体验不佳。将这些任务移至 Web Worker 有助于解决此问题。
查找基于 Web Worker 的演示和完整实现:
在推理期间
模型下载完毕并准备就绪后,您就可以运行推理了。推理可能需要大量计算资源。
将推理移至 Web Worker
如果推理是通过 WebGL、WebGPU 或 WebNN 进行的,则需要依赖 GPU。这意味着,它会在不会阻塞界面的单独进程中发生。
但是,对于基于 CPU 的实现(例如 Wasm,如果不支持 WebGPU,它可以作为 WebGPU 的后备),将推理移至 Web Worker 可确保您的网页保持响应能力,就像在模型准备期间一样。
如果所有与 AI 相关的代码(模型提取、模型准备、推理)都位于同一位置,您的实现可能会更简单。因此,无论 GPU 是否正在使用,您都可以选择 Web Worker。
处理错误
即使您已检查模型应在设备上运行,但用户日后可能会启动另一个会大量消耗资源的进程。为缓解此问题,请执行以下操作:
- 处理推理错误。将推理封装在
try/catch块中,并处理相应的运行时错误。 - 处理 WebGPU 错误,包括意外错误和 GPUDevice.lost 错误。
指示推理状态
如果推理所需时间超过用户认为的即时时间,请向用户发出模型正在思考的信号。使用动画来缓解等待时间,并向用户保证应用正在按预期运行。
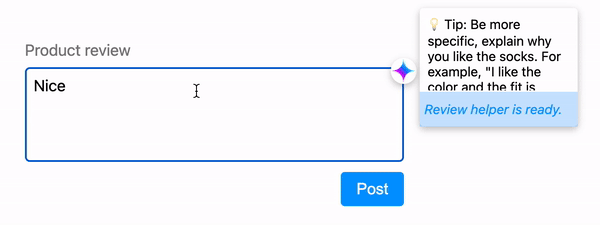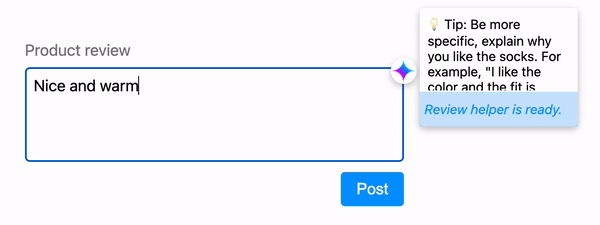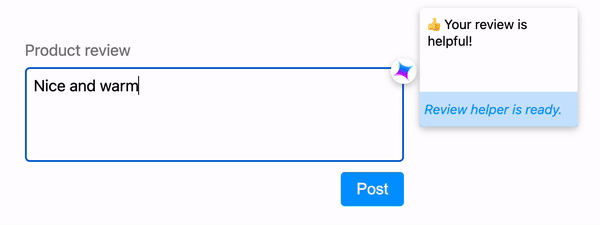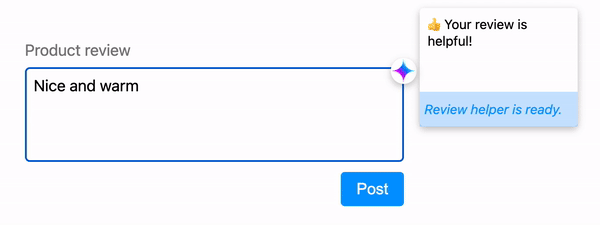
使推理可取消
允许用户动态优化其查询,而无需系统浪费资源来生成用户永远不会看到的响应。