
Para crear una experiencia sin conexión sólida, tu APW necesita administración de almacenamiento. En el capítulo sobre el almacenamiento en caché, aprendiste que el almacenamiento en caché es una opción para guardar datos en un dispositivo. En este capítulo, te mostraremos cómo administrar los datos sin conexión, incluidos la persistencia de los datos, los límites y las herramientas disponibles.
Almacenamiento
El almacenamiento no se trata solo de archivos y recursos, sino que puede incluir otros tipos de datos. En todos los navegadores que admiten PWA, las siguientes APIs están disponibles para el almacenamiento en el dispositivo:
- IndexedDB: Es una opción de almacenamiento de objetos NoSQL para datos estructurados y BLOB (datos binarios).
- WebStorage: Es una forma de almacenar pares de cadenas clave-valor con almacenamiento local o almacenamiento de sesión. No está disponible en el contexto de un service worker. Esta API es síncrona, por lo que no se recomienda para el almacenamiento de datos complejos.
- Cache Storage: Como se explicó en el módulo sobre almacenamiento en caché.
Puedes administrar todo el almacenamiento del dispositivo con la API de Storage Manager en las plataformas compatibles. Las APIs de Cache Storage y IndexedDB proporcionan acceso asíncrono al almacenamiento persistente para las PWA y se puede acceder a ellas desde el subproceso principal, los trabajadores web y los service workers. Ambos desempeñan un papel esencial para que las APW funcionen de manera confiable cuando la red es inestable o no existe. Pero, ¿cuándo deberías usar cada una?
Usa la API de Cache Storage para los recursos de red, es decir, los elementos a los que accederías solicitándolos a través de una URL, como HTML, CSS, JavaScript, imágenes, videos y audio.
Usa IndexedDB para almacenar datos estructurados. Esto incluye los datos que deben poder buscarse o combinarse de manera similar a NoSQL, o bien otros datos, como los datos específicos del usuario, que no necesariamente coinciden con una solicitud de URL. Ten en cuenta que IndexedDB no está diseñado para la búsqueda en el texto completo.
IndexedDB
Para usar IndexedDB, primero abre una base de datos. Esto crea una base de datos nueva si no existe una.
IndexedDB es una API asíncrona, pero toma una devolución de llamada en lugar de devolver una promesa. En el siguiente ejemplo, se usa la biblioteca idb de Jake Archibald, que es un wrapper pequeño de Promise para IndexedDB. No es necesario usar bibliotecas de ayuda para usar IndexedDB, pero, si quieres usar la sintaxis de Promise, la biblioteca idb es una opción.
En el siguiente ejemplo, se crea una base de datos para almacenar recetas de cocina.
Cómo crear y abrir una base de datos
Para abrir una base de datos, sigue estos pasos:
- Usa la función
openDBpara crear una nueva base de datos IndexedDB llamadacookbook. Dado que las bases de datos de IndexedDB tienen versiones, debes aumentar el número de versión cada vez que realices cambios en la estructura de la base de datos. El segundo parámetro es la versión de la base de datos. En el ejemplo, se establece en 1. - Se pasa un objeto de inicialización que contiene una devolución de llamada
upgrade()aopenDB(). Se llama a la función de devolución de llamada cuando se instala la base de datos por primera vez o cuando se actualiza a una versión nueva. Esta función es el único lugar donde pueden ocurrir acciones. Las acciones pueden incluir la creación de nuevos almacenes de objetos (las estructuras que IndexedDB usa para organizar los datos) o índices (en los que te gustaría realizar búsquedas). Aquí también se debe realizar la migración de datos. Por lo general, la funciónupgrade()contiene una instrucciónswitchsin instruccionesbreakpara permitir que cada paso se realice en orden, según la versión anterior de la base de datos.
import { openDB } from 'idb';
async function createDB() {
// Using https://github.com/jakearchibald/idb
const db = await openDB('cookbook', 1, {
upgrade(db, oldVersion, newVersion, transaction) {
// Switch over the oldVersion, *without breaks*, to allow the database to be incrementally upgraded.
switch(oldVersion) {
case 0:
// Placeholder to execute when database is created (oldVersion is 0)
case 1:
// Create a store of objects
const store = db.createObjectStore('recipes', {
// The `id` property of the object will be the key, and be incremented automatically
autoIncrement: true,
keyPath: 'id'
});
// Create an index called `name` based on the `type` property of objects in the store
store.createIndex('type', 'type');
}
}
});
}
En el ejemplo, se crea un almacén de objetos dentro de la base de datos cookbook llamado recipes, con la propiedad id establecida como la clave de índice del almacén, y se crea otro índice llamado type, basado en la propiedad type.
Veamos el almacén de objetos que acabamos de crear. Después de agregar recetas al almacén de objetos y abrir Herramientas para desarrolladores en navegadores basados en Chromium o el Inspector web en Safari, deberías ver lo siguiente:
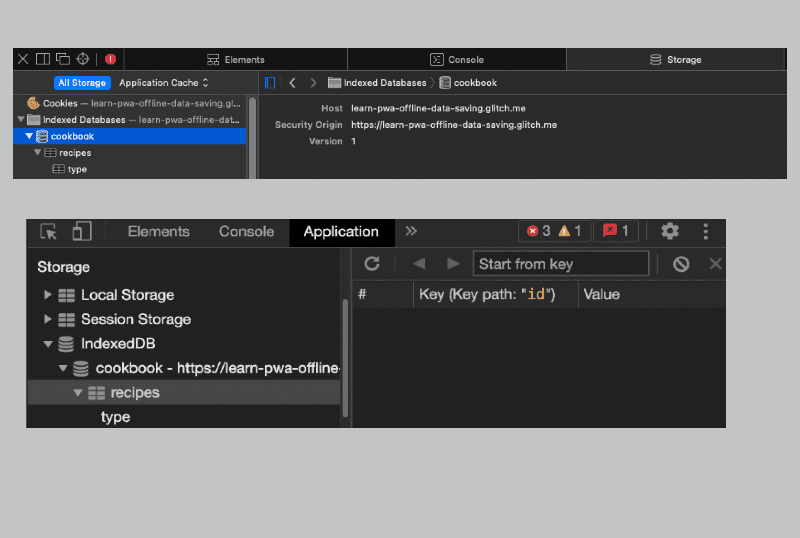
Agrega datos
IndexedDB usa transacciones. Las transacciones agrupan acciones para que se realicen como una unidad. Ayudan a garantizar que la base de datos siempre se encuentre en un estado coherente. También son fundamentales, si tienes varias copias de tu app en ejecución, para evitar la escritura simultánea en los mismos datos. Para agregar datos, sigue estos pasos:
- Inicia una transacción con el parámetro
modeestablecido enreadwrite. - Obtén el almacén de objetos, en el que agregarás datos.
- Llama a
add()con los datos que guardas. El método recibe datos en forma de diccionario (como pares clave-valor) y los agrega al almacén de objetos. El diccionario se debe poder clonar con la clonación estructurada. Si quisieras actualizar un objeto existente, llamarías al métodoput().
Las transacciones tienen una promesa done que se resuelve cuando la transacción se completa correctamente o se rechaza con un error de transacción.
Como se explica en la documentación de la biblioteca de IDB, si escribes en la base de datos, tx.done es el indicador de que todo se confirmó correctamente en la base de datos. Sin embargo, es beneficioso esperar las operaciones individuales para que puedas ver los errores que hacen que la transacción falle.
// Using https://github.com/jakearchibald/idb
async function addData() {
const cookies = {
name: "Chocolate chips cookies",
type: "dessert",
cook_time_minutes: 25
};
const tx = await db.transaction('recipes', 'readwrite');
const store = tx.objectStore('recipes');
store.add(cookies);
await tx.done;
}
Una vez que agregues las cookies, la receta estará en la base de datos con otras recetas. IndexedDB establece y aumenta el ID automáticamente. Si ejecutas este código dos veces, tendrás dos entradas de cookies idénticas.
Recuperando datos
A continuación, se explica cómo obtener datos de IndexedDB:
- Inicia una transacción y especifica el almacén de objetos o los almacenes de objetos, y, de manera opcional, el tipo de transacción.
- Llama a
objectStore()desde esa transacción. Asegúrate de especificar el nombre del almacén de objetos. - Llama a
get()con la clave que deseas obtener. De forma predeterminada, el almacén usa su clave como índice.
// Using https://github.com/jakearchibald/idb
async function getData() {
const tx = await db.transaction('recipes', 'readonly')
const store = tx.objectStore('recipes');
// Because in our case the `id` is the key, we would
// have to know in advance the value of the id to
// retrieve the record
const value = await store.get([id]);
}
El administrador de almacenamiento
Saber cómo administrar el almacenamiento de tu PWA es especialmente importante para almacenar y transmitir las respuestas de la red de forma correcta.
La capacidad de almacenamiento se comparte entre todas las opciones de almacenamiento, incluido Cache Storage, IndexedDB, Web Storage y hasta el archivo de Service Worker y sus dependencias.
Sin embargo, la cantidad de almacenamiento disponible varía de un navegador a otro. Es poco probable que te quedes sin espacio, ya que los sitios pueden almacenar megabytes e incluso gigabytes de datos en algunos navegadores. Por ejemplo, Chrome permite que el navegador use hasta el 80% del espacio total del disco, y un origen individual puede usar hasta el 60% de todo el espacio del disco. En los navegadores que admiten la API de Storage, puedes saber cuánto almacenamiento está disponible para tu app, su cuota y su uso.
En el siguiente ejemplo, se usa la API de Storage para obtener la cuota y el uso estimados, y, luego, se calcula el porcentaje de bytes usados y restantes. Ten en cuenta que navigator.storage devuelve una instancia de StorageManager. Hay una interfaz Storage independiente, y es fácil confundirlas.
if (navigator.storage && navigator.storage.estimate) {
const quota = await navigator.storage.estimate();
// quota.usage -> Number of bytes used.
// quota.quota -> Maximum number of bytes available.
const percentageUsed = (quota.usage / quota.quota) * 100;
console.log(`You've used ${percentageUsed}% of the available storage.`);
const remaining = quota.quota - quota.usage;
console.log(`You can write up to ${remaining} more bytes.`);
}
En las Herramientas para desarrolladores de Chromium, puedes ver la cuota de tu sitio y cuánto almacenamiento se usa desglosado por lo que lo usa. Para ello, abre la sección Almacenamiento en la pestaña Aplicación.
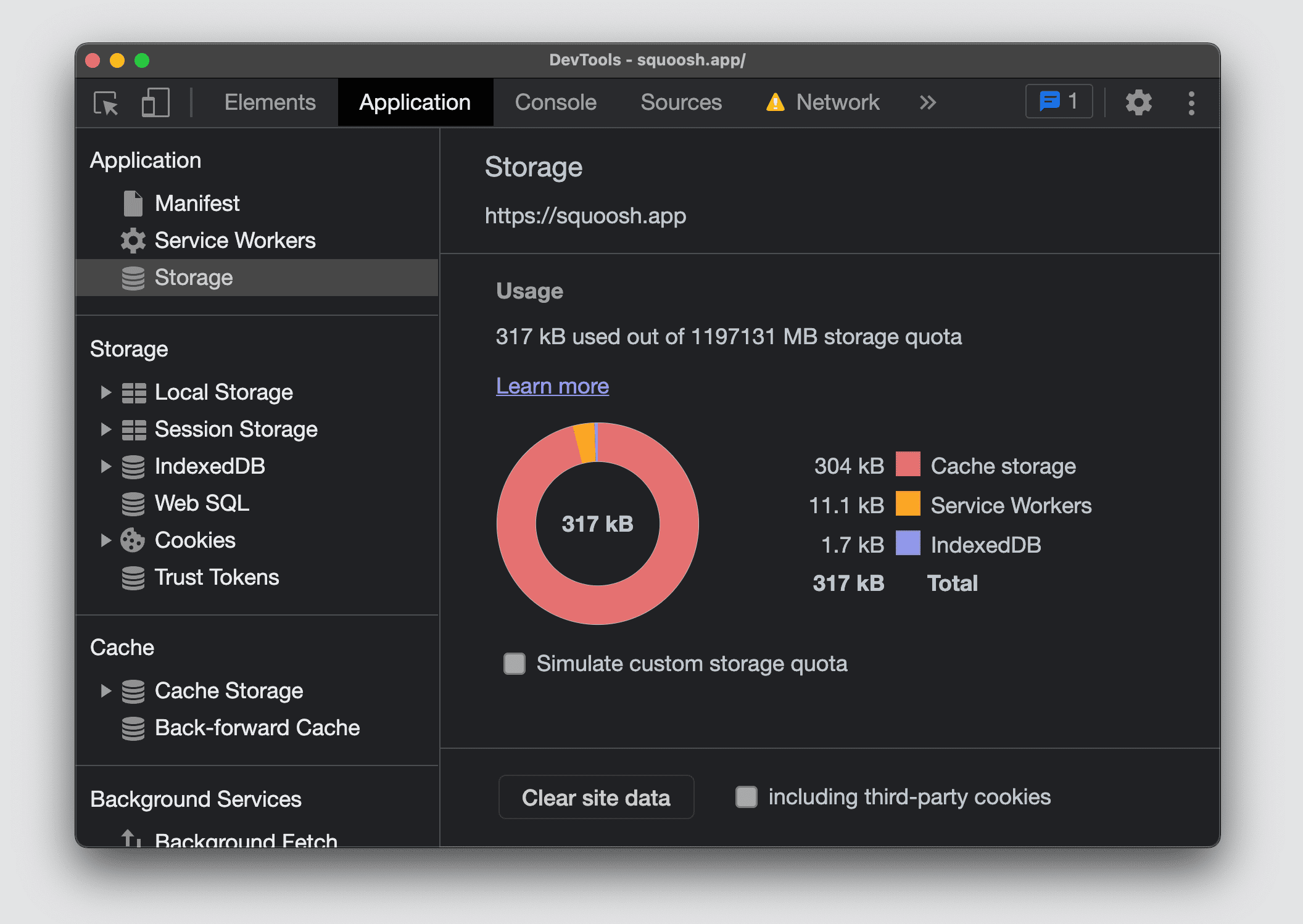
Firefox y Safari no ofrecen una pantalla de resumen para ver toda la cuota de almacenamiento y el uso del origen actual.
Persistencia de datos
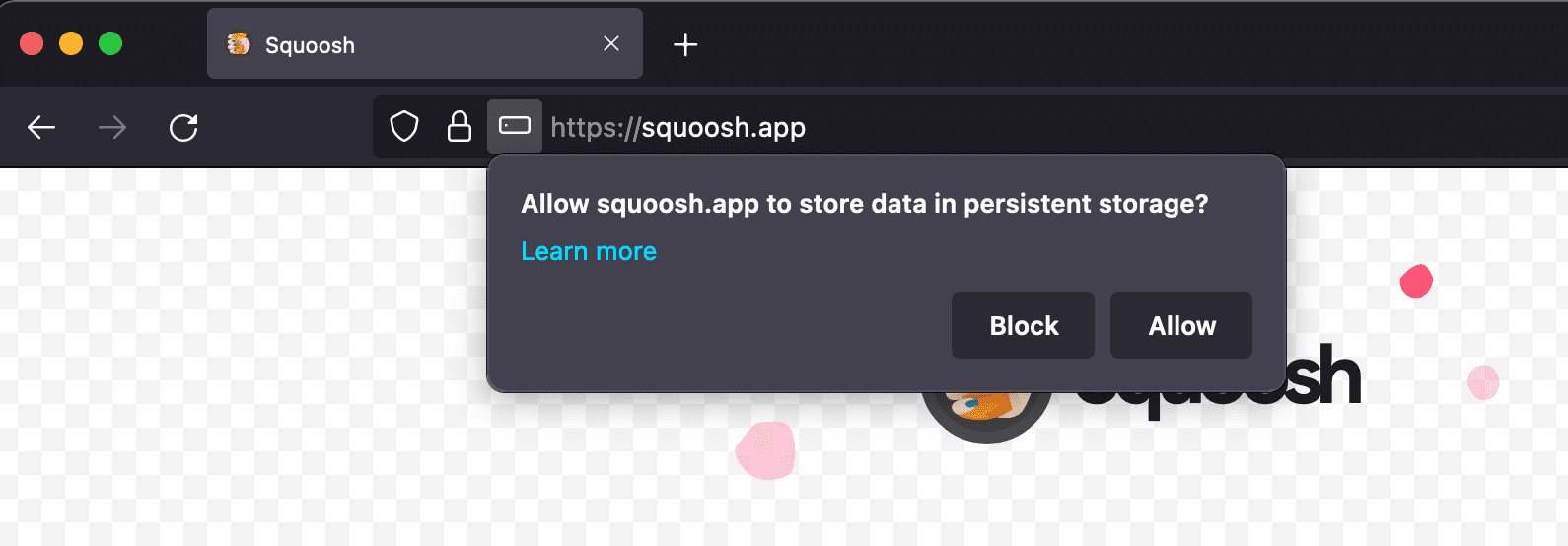
Puedes solicitarle al navegador almacenamiento persistente en plataformas compatibles para evitar el desalojo automático de datos después de un período de inactividad o cuando haya presión de almacenamiento. Si se otorga, el navegador nunca expulsará datos del almacenamiento. Esta protección incluye el registro del service worker, las bases de datos de IndexedDB y los archivos en el almacenamiento de caché. Ten en cuenta que los usuarios siempre tienen el control y pueden borrar el almacenamiento en cualquier momento, incluso si el navegador otorgó almacenamiento persistente.
Para solicitar almacenamiento persistente, llama a StorageManager.persist(). Al igual que antes, se accede a la interfaz StorageManager a través de la propiedad navigator.storage.
async function persistData() {
if (navigator.storage && navigator.storage.persist) {
const result = await navigator.storage.persist();
console.log(`Data persisted: ${result}`);
}
También puedes llamar a StorageManager.persisted() para verificar si el almacenamiento persistente ya se otorgó en el origen actual. Firefox solicita permiso al usuario para usar el almacenamiento persistente. Los navegadores basados en Chromium otorgan o niegan la persistencia según una heurística para determinar la importancia del contenido para el usuario. Un criterio para Google Chrome es, por ejemplo, la instalación de AWP. Si el usuario instaló un ícono para la PWA en el sistema operativo, es posible que el navegador otorgue almacenamiento persistente.
Compatibilidad con el Explorador de APIs
Almacenamiento web
' d='M96 183a64 64 0 0 1-23-23L17 64a128 128 0 0 0 111 192l55-96a64 64 0 0 1-87 23Z'/%3E%3Cpath fill='url(%23b)' d='M192 128a64 64 0 0 1-9 32l-55 96A128 128 0 0 0 239 64H128a64 64 0 0 1 64 64Z'/%3E%3Ccircle cx='128' cy='128' r='52' fill='%231a73e8'/%3E%3Cpath fill='url(%23c)' d='M96 73a64 64 0 0 1 32-9h111a128 128 0 0 0-222 0l56 96a64 64 0 0 1 23-87Z'/%3E%3C/svg%3E)
' xlink:href='%23A'%3E%3Cstop offset='.76' stop-opacity='0'/%3E%3Cstop offset='.95' stop-opacity='.5'/%3E%3Cstop offset='1'/%3E%3C/radialGradient%3E%3CradialGradient id='F' cx='2523' cy='4680' r='20243' gradientTransform='matrix(-.03715 .99931 -2.12836 -.07913 13579 3530)' xlink:href='%23A'%3E%3Cstop offset='0' stop-color='%2335c1f1'/%3E%3Cstop offset='.11' stop-color='%2334c1ed'/%3E%3Cstop offset='.23' stop-color='%232fc2df'/%3E%3Cstop offset='.31' stop-color='%232bc3d2'/%3E%3Cstop offset='.67' stop-color='%2336c752'/%3E%3C/radialGradient%3E%3CradialGradient id='G' cx='24247' cy='7758' r='9734' gradientTransform='matrix(.28109 .95968 -.78353 .22949 24510 -16292)' xlink:href='%23A'%3E%3Cstop offset='0' stop-color='%2366eb6e'/%3E%3Cstop offset='1' stop-color='%2366eb6e' stop-opacity='0'/%3E%3C/radialGradient%3E%3Cpath id='H' d='M24105 20053a9345 9345 0 01-1053 472 10202 10202 0 01-3590 646c-4732 0-8855-3255-8855-7432 0-1175 680-2193 1643-2729-4280 180-5380 4640-5380 7253 0 7387 6810 8137 8276 8137 791 0 1984-230 2704-456l130-44a12834 12834 0 006660-5282c220-350-168-757-535-565z'/%3E%3Cpath id='I' d='M11571 25141a7913 7913 0 01-2273-2137 8145 8145 0 01-1514-4740 8093 8093 0 013093-6395 8082 8082 0 011373-859c312-148 846-414 1554-404a3236 3236 0 012569 1297 3184 3184 0 01636 1866c0-21 2446-7960-8005-7960-4390 0-8004 4166-8004 7820 0 2319 538 4170 1212 5604a12833 12833 0 007684 6757 12795 12795 0 003908 610c1414 0 2774-233 4045-656a7575 7575 0 01-6278-803z'/%3E%3Cpath id='J' d='M16231 15886c-80 105-330 250-330 566 0 260 170 512 472 723 1438 1003 4149 868 4156 868a5954 5954 0 003027-839 6147 6147 0 001133-850 6180 6180 0 001910-4437c26-2242-796-3732-1133-4392-2120-4141-6694-6525-11668-6525-7011 0-12703 5635-12798 12620 47-3654 3679-6605 7996-6605 350 0 2346 34 4200 1007 1634 858 2490 1894 3086 2921 618 1067 728 2415 728 2952s-271 1333-780 1990z'/%3E%3Cuse fill='url(%23B)' xlink:href='%23H'/%3E%3Cuse fill='url(%23D)' opacity='.35' xlink:href='%23H'/%3E%3Cuse fill='url(%23C)' xlink:href='%23I'/%3E%3Cuse fill='url(%23E)' opacity='.4' xlink:href='%23I'/%3E%3Cuse fill='url(%23F)' xlink:href='%23J'/%3E%3Cuse fill='url(%23G)' xlink:href='%23J'/%3E%3C/svg%3E)
' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.2' stop-color='%239059ff' stop-opacity='0'/%3E%3Cstop offset='.3' stop-color='%238c4ff3' stop-opacity='.1'/%3E%3Cstop offset='.8' stop-color='%237716a8' stop-opacity='.5'/%3E%3Cstop offset='1' stop-color='%236e008b' stop-opacity='.6'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-g' cx='239.1' cy='34.6' r='171.6' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='0' stop-color='%23ffe226'/%3E%3Cstop offset='.1' stop-color='%23ffdb27'/%3E%3Cstop offset='.3' stop-color='%23ffc82a'/%3E%3Cstop offset='.5' stop-color='%23ffa930'/%3E%3Cstop offset='.7' stop-color='%23ff7e37'/%3E%3Cstop offset='.8' stop-color='%23ff7139'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-h' cx='374' cy='-74.3' r='732.2' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.5' stop-color='%23ff980e'/%3E%3Cstop offset='.6' stop-color='%23ff5634'/%3E%3Cstop offset='.7' stop-color='%23ff3647'/%3E%3Cstop offset='.9' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-i' cx='304.6' cy='7.1' r='536.4' gradientTransform='rotate(84 303 4)' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='0' stop-color='%23fff44f'/%3E%3Cstop offset='.1' stop-color='%23ffe847'/%3E%3Cstop offset='.2' stop-color='%23ffc830'/%3E%3Cstop offset='.3' stop-color='%23ff980e'/%3E%3Cstop offset='.4' stop-color='%23ff8b16'/%3E%3Cstop offset='.5' stop-color='%23ff672a'/%3E%3Cstop offset='.6' stop-color='%23ff3647'/%3E%3Cstop offset='.7' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-j' cx='235' cy='98.1' r='457.1' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.5' stop-color='%23ff980e'/%3E%3Cstop offset='.6' stop-color='%23ff5634'/%3E%3Cstop offset='.7' stop-color='%23ff3647'/%3E%3Cstop offset='.9' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-k' cx='355.7' cy='124.9' r='500.3' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.2' stop-color='%23ffe141'/%3E%3Cstop offset='.5' stop-color='%23ffaf1e'/%3E%3Cstop offset='.6' stop-color='%23ff980e'/%3E%3C/radialGradient%3E%3ClinearGradient id='ff-a' x1='446.9' y1='76.8' x2='47.9' y2='461.8' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.1' stop-color='%23ffe847'/%3E%3Cstop offset='.2' stop-color='%23ffc830'/%3E%3Cstop offset='.4' stop-color='%23ff980e'/%3E%3Cstop offset='.4' stop-color='%23ff8b16'/%3E%3Cstop offset='.5' stop-color='%23ff672a'/%3E%3Cstop offset='.5' stop-color='%23ff3647'/%3E%3Cstop offset='.7' stop-color='%23e31587'/%3E%3C/linearGradient%3E%3ClinearGradient id='ff-l' x1='442.1' y1='74.8' x2='102.6' y2='414.3' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.2' stop-color='%23fff44f' stop-opacity='.8'/%3E%3Cstop offset='.3' stop-color='%23fff44f' stop-opacity='.6'/%3E%3Cstop offset='.5' stop-color='%23fff44f' stop-opacity='.2'/%3E%3Cstop offset='.6' stop-color='%23fff44f' stop-opacity='0'/%3E%3C/linearGradient%3E%3C/defs%3E%3Cpath d='M479 166c-11-25-32-52-49-60a249 249 0 0 1 25 73c-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-60 35-81 101-83 134a120 120 0 0 0-66 25 71 71 0 0 0-6-5 111 111 0 0 1-1-58c-25 11-44 29-58 44-9-12-9-52-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73l-1 2-2 15a229 229 0 0 0-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121zM202 355l3 1-3-1zm55-145zm198-31z' fill='url(%23ff-a)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60 14 26 22 53 25 72v1a207 207 0 0 1-206 279c-113-3-212-87-231-197-3-17 0-26 2-40-2 11-3 14-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121z' fill='url(%23ff-b)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60 14 26 22 53 25 72v1a207 207 0 0 1-206 279c-113-3-212-87-231-197-3-17 0-26 2-40-2 11-3 14-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121z' fill='url(%23ff-c)'/%3E%3Cpath d='m362 195 1 1a130 130 0 0 0-22-29C266 92 322 5 331 0c-60 35-81 101-83 134l9-1c45 0 84 25 105 62z' fill='url(%23ff-d)'/%3E%3Cpath d='M257 210c-1 6-22 26-29 26-68 0-80 41-80 41 3 35 28 64 57 79l4 2 7 3a107 107 0 0 0 31 6c120 6 143-143 57-186 22-4 45 5 58 14-21-37-60-62-105-62l-9 1a120 120 0 0 0-66 25l17 16c16 16 58 33 58 35z' fill='url(%23ff-e)'/%3E%3Cpath d='M257 210c-1 6-22 26-29 26-68 0-80 41-80 41 3 35 28 64 57 79l4 2 7 3a107 107 0 0 0 31 6c120 6 143-143 57-186 22-4 45 5 58 14-21-37-60-62-105-62l-9 1a120 120 0 0 0-66 25l17 16c16 16 58 33 58 35z' fill='url(%23ff-f)'/%3E%3Cpath d='m171 151 5 3a111 111 0 0 1-1-58c-25 11-44 29-58 44 1 0 36 0 54 11z' fill='url(%23ff-g)'/%3E%3Cpath d='M18 261a242 242 0 0 0 231 197 207 207 0 0 0 206-279c8 56-20 110-64 146-86 71-169 43-186 31l-3-1c-50-24-71-70-67-110-42 0-57-35-57-35s38-28 89-4c46 22 90 4 90 4 0-2-42-19-58-35l-17-16a71 71 0 0 0-6-5l-5-3c-18-11-52-11-54-11-9-12-9-51-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73c0 1-9 38-5 57z' fill='url(%23ff-h)'/%3E%3Cpath d='M341 167a130 130 0 0 1 22 29 46 46 0 0 1 4 3c55 50 26 121 24 126 44-36 72-90 64-146-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-9 5-65 92 10 167z' fill='url(%23ff-i)'/%3E%3Cpath d='M367 199a46 46 0 0 0-4-3l-1-1c-13-9-36-18-58-15 86 44 63 193-57 187a107 107 0 0 1-31-6 131 131 0 0 1-11-5c17 12 99 39 186-31 2-5 31-76-24-126z' fill='url(%23ff-j)'/%3E%3Cpath d='M148 277s12-41 80-41c7 0 28-20 29-26s-44 18-90-4c-51-24-89 4-89 4s15 35 57 35c-4 40 16 85 67 110l3 1c-29-15-54-44-57-79z' fill='url(%23ff-k)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60a249 249 0 0 1 25 73c-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-60 35-81 101-83 134l9-1c45 0 84 25 105 62-13-9-36-18-58-14 86 43 63 192-57 186a107 107 0 0 1-31-6 131 131 0 0 1-11-5l-3-1 3 1c-29-15-54-44-57-79 0 0 12-41 80-41 7 0 28-20 29-26 0-2-42-19-58-35l-17-16a71 71 0 0 0-6-5 111 111 0 0 1-1-58c-25 11-44 29-58 44-9-12-9-52-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73l-1 2-2 15a279 279 0 0 0-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121zm-24 13z' fill='url(%23ff-l)'/%3E%3C/svg%3E)
' xlink:href='%23s-b'%3E%3Cstop offset='0' stop-color='%2324a5f3' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%231e8ceb' /%3E%3C/radialGradient%3E%3CradialGradient id='s-j' cx='109.3' cy='13.8' r='93.1' gradientTransform='matrix(-.02 1.1 -1.04 -.02 137 -115)' xlink:href='%23s-b'%3E%3Cstop offset='0' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%235488d6' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%235d96eb' /%3E%3C/radialGradient%3E%3C/defs%3E%3Crect width='220' height='220' x='22' y='-107' fill='url(%23s-a)' ry='49' transform='matrix(.57 0 0 .57 187 256)' /%3E%3Cg transform='translate(194 190)'%3E%3Ccircle cx='67.8' cy='67.7' fill='url(%23s-c)' paint-order='stroke fill markers' r='54' /%3E%3Ccircle cx='-69.9' cy='69.3' fill='url(%23s-i)' transform='translate(138 -2)' r='54' /%3E%3C/g%3E%3Cellipse cx='120' cy='14.2' fill='url(%23s-j)' rx='93.1' ry='93.7' transform='matrix(.58 0 0 .58 192 250)' /%3E%3Cg transform='matrix(.58 0 0 .57 197 182)'%3E%3Cpath fill='%23cac7c8' d='M46 192h1l72-48-7-9-66 57Z' /%3E%3Cpath fill='%23fbfffc' d='M46 191v1l66-57-7-9-59 65Z' /%3E%3Cpath fill='url(%23s-d)' d='m119 144-7-9 66-57-59 66Z' /%3E%3Cpath fill='%23fb645c' d='m105 126 7 9 66-57-1-1-72 49Z' /%3E%3C/g%3E%3Cpath stroke='%23fff' stroke-linecap='round' stroke-miterlimit='1' stroke-width='1.3' d='m287 278 3-2m-12-17 8-2m-8-3h4m-4-13 8 2m-8 3h4m-1-13 7 3m-4-11 7 4m-2-11 6 6m0-12 6 7m1-11 4 6m4-10 3 7m5-9 2 7m15-7-1 7m10-5-3 7m11-4-4 7m11-2-5 6m16 7-7 4m10 4-7 3m10 6-8 1m8 16-8-2m5 10-7-3m4 11-7-4m2 11-6-5m0 11-5-6m-2 11-4-7m-4 11-3-8m-6 10-1-8m-16 8 2-8m-10 5 3-7m-11 4 4-7m-11 2 5-6m-8 3 3-3m4 8 2-3m5 8 2-4m6 7 1-4m8 5v-4m8 4v-4m9 3-1-4m9 1-2-4m9 0-2-4m9-2-3-3m8-4-3-2m8-5-4-2m7-6-4-1m5-8h-4m4-8h-4m3-9-4 1m1-9-4 2m-1-9-3 2m-2-9-3 3m-4-8-2 3m-5-8-2 4m-6-6-1 3m-8-5v4m-8-4v4m-9-2 1 3m-9 0 2 3m-9 1 2 3m-9 2 3 3m-8 4 3 2m-8 5 4 2m-7 6 4 1m-4 25 4-1m-2 5 7-3m-6 7 4-2m-2 6 7-4m-13-21h8m41-41v-8m0 99v-8m49-42h-8' transform='translate(-65 8)' /%3E%3C/svg%3E)
Acceso al sistema de archivos
Administrador de almacenamiento