
Projektowanie aplikacji w taki sposób, aby w pełni korzystać z technologii, która sprawia, że PWAs są niezawodne, można zainstalować i mają odpowiednie możliwości, zaczyna się od zrozumienia aplikacji i jej ograniczeń oraz wybrania odpowiedniej architektury.
SPA a MPA
Obecnie w programowaniu stron internetowych można wyróżnić 2 podstawowe wzorce architektury: aplikacje jednostronicowe (SPA) i aplikacje wielostronicowe (MPA).
Aplikacje jednostronicowe są zdefiniowane przez JavaScript po stronie klienta, który kontroluje większość lub całość renderowania HTML strony na podstawie danych pobranych przez aplikację lub jej dostarczonych. Aplikacja zastępuje wbudowaną nawigację przeglądarki, zastępując ją funkcjami kierowania i obsługi widoku.
Aplikacje wielostronicowe zwykle mają wstępnie renderowany kod HTML bezpośrednio do przeglądarki, często wzmacniany za pomocą JavaScriptu po stronie klienta po zakończeniu wczytywania kodu HTML przez przeglądarkę i wyświetlają kolejne wyświetlenia, korzystając z wbudowanych mechanizmów nawigacyjnych przeglądarki.
Obie architektury można używać do tworzenia aplikacji PWA.
Każdy z nich ma swoje zalety i wady, a wybranie odpowiedniego do przypadku użycia i kontekstu jest kluczowe dla zapewnienia użytkownikom szybkiego i niezawodnego działania.
Aplikacje jednostronicowe
- głównie atomowe aktualizacje na stronie.
- zależności po stronie klienta wczytywane podczas uruchamiania.
- Kolejne wczytywanie przebiega szybko ze względu na wykorzystanie pamięci podręcznej.
- Wysoki koszt wczytania początkowego.
- Wydajność zależy od sprzętu i połączenia sieciowego.
- Wymagana jest większa złożoność aplikacji.
Aplikacje jednostronicowe są dobrym rozwiązaniem pod względem architektury, jeśli:
- Interakcja użytkownika koncentruje się głównie na poszczególnych aktualizacjach powiązanych ze sobą danych wyświetlanych na tej samej stronie, np. w panelu danych w czasie rzeczywistym lub w aplikacji do edytowania filmów.
- Aplikacja ma zależności inicjializacji dostępne tylko po stronie klienta, np. zewnętrzny dostawca uwierzytelniania z wysokimi kosztami uruchomienia.
- Dane wymagane do załadowania widoku zależą od konkretnego kontekstu po stronie klienta, np. wyświetlania elementów sterujących dla podłączonego sprzętu.
- Aplikacja jest na tyle mała i prosta, że jej rozmiar i złożoność nie mają wpływu na wymienione powyżej wady.
Architektura SPA może nie być dobrym rozwiązaniem, jeśli:
- Ważne jest, aby wczytywanie początkowe było szybkie. Aplikacje SPA zwykle muszą wczytywać więcej kodu JavaScript, aby określić, co i w jaki sposób wyświetlać. Czas analizowania i wykonywania tego kodu JavaScriptu w połączeniu z pobieraniem treści jest dłuższy niż czas wysyłania wyrenderowanego kodu HTML.
- Aplikacja działa głównie na urządzeniach o niskiej lub średniej mocy. Ponieważ podczas renderowania reklamy SPA wykorzystują JavaScript, wrażenia użytkownika znacznie w większym stopniu zależą od możliwości konkretnego urządzenia niż w przypadku MPA.
Ponieważ SPA muszą zastąpić wbudowaną nawigację przeglądarki, wymagają minimalnej złożoności w zakresie efektywnego aktualizowania bieżącego widoku, zarządzania zmianami nawigacji i usuwania poprzednich widoków, które w przeciwnym razie byłyby obsługiwane przez przeglądarkę. W rezultacie są one trudniejsze w utrzymaniu i bardziej obciążające dla urządzenia użytkownika.
Aplikacje wielostronicowe
- Większość aktualizacji dotyczy całej strony.
- Szybkość początkowego renderowania ma kluczowe znaczenie.
- Skrypty po stronie klienta mogą być ulepszeniem.
- Widoki dodatkowe wymagają innego wywołania serwera.
- Kontekst nie jest przenoszony między widokami.
- Wymaga serwera lub prerenderowania.
Aplikacje wielostronicowe to dobry wybór pod względem architektury, jeśli:
- Interakcje użytkownika koncentrują się głównie na wyświetleniach pojedynczego elementu danych z opcjonalnymi danymi kontekstowymi, np. w przypadku aplikacji do przeglądania wiadomości lub e-commerce.
- Szybkość wstępnego renderowania jest kluczowa, ponieważ wysłanie wyrenderowanego kodu HTML do przeglądarki jest szybsze niż składanie go z żądania danych po wczytaniu, analizie i wykonaniu alternatywy opartej na języku JavaScript.
- Interakcje lub kontekst po stronie klienta można uwzględnić jako ulepszenie po początkowym załadowaniu, na przykład poprzez nałożenie profilu na wyrenderowaną stronę lub dodanie dodatkowych komponentów po stronie klienta zależnych od kontekstu.
Architektura MPA może nie być odpowiednia, jeśli:
- Ponowne pobieranie, parsowanie i wykonywanie kodu JavaScript lub CSS jest bardzo kosztowne. W przypadku PWA z użyciem skryptów service worker ten problem jest ograniczony.
- Kontekst po stronie klienta, np. lokalizacja użytkownika, nie jest płynnie przenoszony między widokami, a ponowne pobieranie tego kontekstu może być kosztowne. Trzeba go przechwycić i pobrać lub wysłać żądanie między widokami.
Ponieważ poszczególne widoki muszą być renderowane dynamicznie przez serwer lub renderowane wstępnie przed udostępnieniem, może to ograniczać hosting lub zwiększać złożoność danych.
Którą opcję wybrać?
Pomimo tych zalet i wad obie te architektury nadają się do tworzenia aplikacji PWA. Możesz nawet łączyć te architektury w różnych częściach aplikacji, w zależności od jej potrzeb. Możesz na przykład użyć architektury MPA w informacjach o aplikacji, a architektury SPA w procesie płatności.
Niezależnie od wyboru następnym krokiem jest zrozumienie, jak najlepiej wykorzystać mechanizmy Service Worker, aby zapewnić jak największą wygodę.
Możliwości skryptu service worker
Oprócz podstawowego przekierowywania i przekazywania odpowiedzi z pamięci podręcznej oraz z sieci, worker usługi ma wiele innych możliwości. Możemy tworzyć złożone algorytmy, które poprawiają wygodę użytkowników i wydajność.
Skrypt service worker zawiera (SWI)
Pojawia się nowy wzorzec używania skryptów service worker jako integralnej części architektury witryny. Jest to usługa skryptu service worker (SWI).
SWI dzieli poszczególne zasoby (zwykle stronę HTML) na części na podstawie ich potrzeb dotyczących buforowania, a następnie składa je ponownie w ramach skryptu service worker, aby zwiększyć spójność, wydajność i niezawodność, a zarazem zmniejszyć rozmiar pamięci podręcznej.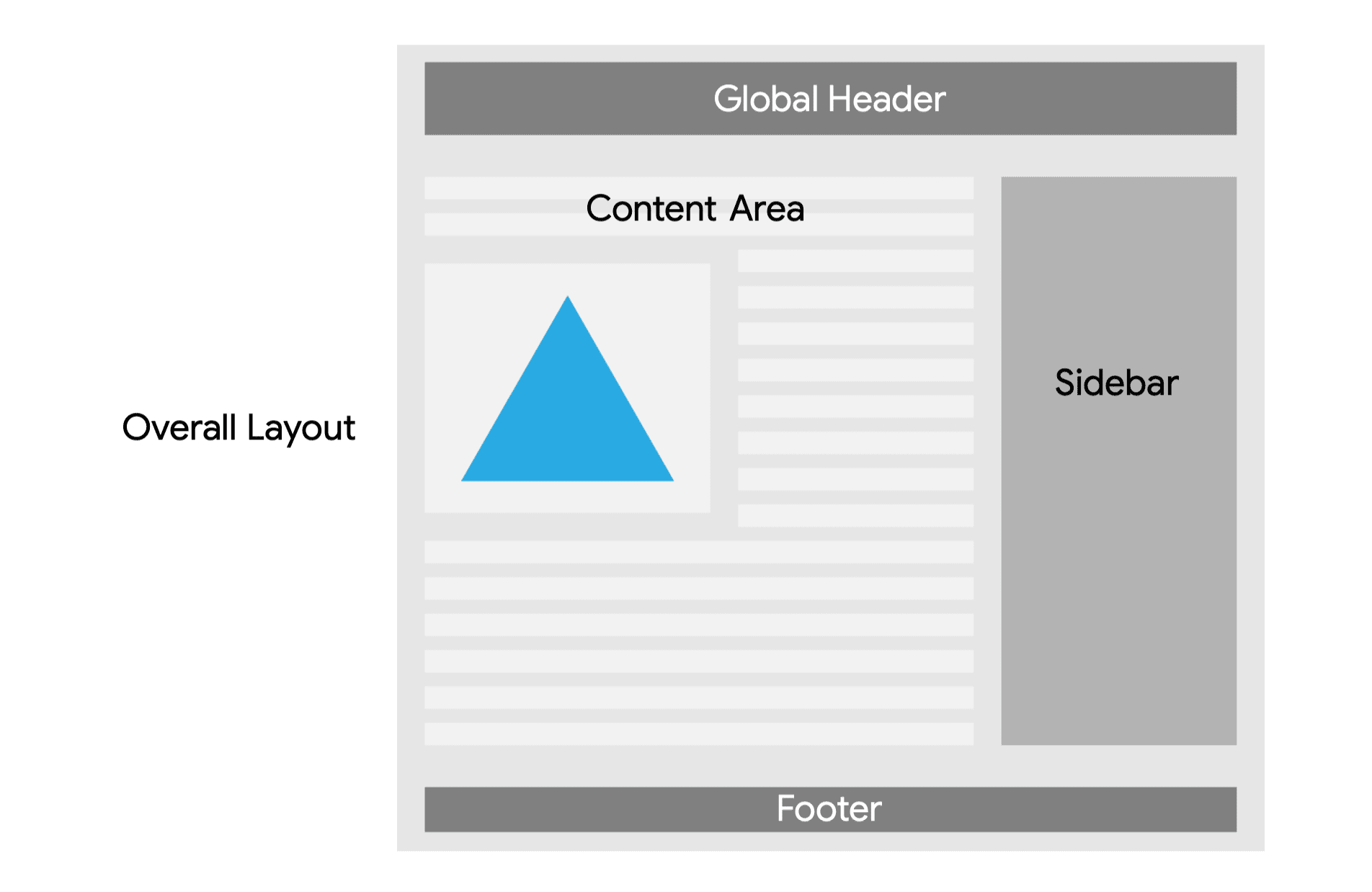
Obraz przedstawia przykładową stronę internetową. Składa się on z 5 sekcji:
- Ogólny układ.
- Globalny nagłówek (górny ciemny pasek).
- Obszar treści (pośrodku, z lewej strony, linie i obraz).
- Pasek boczny (wysoki, średnio ciemny pasek pośrodku po prawej stronie).
- Stopka (ciemny dolny pasek).
Ogólny układ
Ogólny układ nie zmienia się często i nie ma żadnych zależności. Jest to dobry kandydat do zapamiętania z poziomu pamięci podręcznej.
Nagłówek i stopka
Globalny nagłówek i stopka zawierają elementy takie jak menu górne i stopka witryny. Stanowią one szczególne wyzwanie: jeśli strona miałaby być przechowywana w pamięci podręcznej jako całość, elementy te mogłyby się zmieniać przy każdym wczytaniu strony, w zależności od tego, kiedy została ona zapisana w pamięci podręcznej.
Oddzielenie tych plików i przechowywanie ich w pamięci podręcznej niezależnie od treści sprawi, że użytkownicy będą zawsze mieli dostęp do tej samej wersji niezależnie od czasu przechowywania ich w pamięci podręcznej. Ponieważ są one aktualizowane rzadko, również nadają się do wstępnego buforowania. Mają jednak pewną zależność: pliki CSS i JavaScript witryny.
CSS i JavaScript
W idealnym przypadku kod CSS i JavaScript witryny powinien być przechowywany w pamięci podręcznej ze stanem nieaktualnym, a następnie należy ponownie zweryfikować strategię, aby umożliwić przyrostowe aktualizacje bez konieczności aktualizowania skryptu service worker, jak ma to miejsce w przypadku zasobów wstępnie buforowanych. Muszą też jednak utrzymywać się w minimalnej wersji, gdy skrypt service worker aktualizuje się o nowy globalny nagłówek lub stopkę. Dlatego podczas instalacji pracownika usługi powinna zostać zaktualizowana również pamięć podręczna z najnowszą wersją zasobów.
Obszar treści
Następnie obszar treści. W zależności od częstotliwości aktualizacji możesz wybrać strategię sieci w pierwszej kolejności lub stale podczas ponownej weryfikacji. Obrazy powinny być przechowywane w pamięci podręcznej zgodnie ze strategią „najpierw pamięć podręczna”, o której omawialiśmy wcześniej.
Pasek boczny
Przy założeniu, że zawartość paska bocznego zawiera treści dodatkowe, takie jak tagi i powiązane elementy, nie jest aż tak istotne, aby pobrać dane z sieci. W takim przypadku sprawdza się strategia sprawdzania poprawności w przypadku nieaktualnych danych.
Po zapoznaniu się z tymi informacjami możesz pomyśleć, że tego typu buforowanie według sekcji można stosować tylko w przypadku aplikacji jednostronicowych. Jednak dzięki zastosowaniu w usługach workerów wzorców zaczerpniętych z include’ów po stronie urządzenia lub include’ów po stronie serwera oraz za pomocą niektórych zaawansowanych funkcji usług workerów możesz to zrobić w przypadku każdej architektury.
Wypróbuj
Możesz wypróbować usługę workera w ramach tego ćwiczenia:
Strumieniowanie odpowiedzi
Poprzednia strona może być utworzona za pomocą modelu powłoki aplikacji w środowisku SPA, gdzie powłoka aplikacji jest buforowana, a następnie wyświetlana, a treści są wczytywane po stronie klienta. Dzięki wprowadzeniu i szerokiemu udostępnieniu interfejsu Streams API zarówno powłoka aplikacji, jak i treści mogą być łączone w usługach workera i przesyłane strumieniowo do przeglądarki, co zapewnia elastyczność pamięci podręcznej powłoki aplikacji z szybkością MPA.
Dzieje się tak, ponieważ:
- Strumienie można budować asynchronicznie, co pozwala na tworzenie różnych części strumienia z różnych źródeł.
- Osoba, która poprosiła o strumień, może zacząć pracować nad odpowiedzią, gdy tylko pojawi się pierwszy fragment danych, zamiast czekać na ukończenie całego zadania.
- Analizatory zoptymalizowane pod kątem strumieniowego przesyłania danych, w tym przeglądarka, mogą stopniowo wyświetlać zawartość strumienia przed jej zakończeniem, co przyspiesza odczuwalną wydajność odpowiedzi.
Dzięki tym 3 właściwościom strumieniowania architektury oparte na strumieniowaniu zwykle mają szybsze postrzegane działanie niż te, które nie są oparte na strumieniowaniu.
Praca z interfejsem Streams API może być trudna ze względu na to, że jest złożony i niski. Na szczęście jest moduł Workbox, który może pomóc w konfigurowaniu odpowiedzi strumieniowych dla Twoich usług działających w tle.
Domeny, pochodzenie i zakres PWA
Procesy robocze w internecie, w tym procesy robocze usługi, pamięć masowa, a nawet okno zainstalowanej aplikacji PWA, są regulowane przez jeden z najważniejszych mechanizmów zabezpieczeń w internecie: zasadę dotyczącą tego samego źródła. W ramach tego samego źródła uprawnienia są przyznawane, dane mogą być udostępniane, a skrypt service worker może komunikować się z różnymi klientami. Poza tym samym źródłem uprawnienia nie są przyznawane automatycznie, a dane są izolowane i nie są dostępne dla różnych źródeł.
Zasada o tym samym pochodzeniu
Dwa adresy URL mają to samo źródło, jeśli mają ten sam protokół, port i hosta.
Na przykład: https://squoosh.app i https://squoosh.app/v2 mają to samo pochodzenie, ale http://squoosh.app, https://squoosh.com, https://app.squoosh.app i https://squoosh.app:8080 mają inne źródła. Więcej informacji i przykłady znajdziesz w dokumentacji dotyczącej zasad MDN dotyczących tego samego pochodzenia.
Zmiana subdomen to nie jedyny sposób na zmianę hosta. Każdy host składa się z domeny najwyższego poziomu (TLD), domeny dodatkowego (SLD) i 0 lub większej liczby etykiet (czasami zwanych subdomenami), które są oddzielone kropkami i odczytywane od prawej do lewej w adresie URL. Zmiana dowolnego z tych elementów powoduje zmianę hosta.
W module zarządzania oknami widać już, jak wygląda przeglądarka w aplikacji, gdy użytkownik przechodzi do innej domeny z zainstalowanej aplikacji PWA.
Ten przeglądarka w aplikacji pojawi się nawet wtedy, gdy witryny mają ten sam TLD i SLD, ale różne etykiety, ponieważ są one wtedy uznawane za różne źródła.
Jednym z kluczowych aspektów pochodzenia w kontekście przeglądania stron internetowych jest sposób działania pamięci i uprawnień. Źródło udostępnia wiele funkcji wszystkim treściom i aplikacjom PWA, w tym:
- limit miejsca na dane i dane (IndexedDB, pliki cookie, Web Storage, pamięć podręczna);
- Rejestracje skryptów service worker.
- Przyznane lub zabronione uprawnienia (np. web push, geolokalizacja, czujniki).
- Rejestracje w trybie push.
Przejście z jednego źródła do drugiego powoduje unieważnienie wszystkich poprzednich uprawnień dostępu, więc trzeba ponownie przyznać uprawnienia, a aplikacja PWA nie może uzyskać dostępu do wszystkich danych zapisanych w pamięci.