
Dowiedz się, czym jest skaner wstępnego wczytywania przeglądarki, jak wpływa na wydajność i jak możesz uniknąć jego blokowania.

Jednym z pomijanych aspektów optymalizacji Page Speed jest znajomość wewnętrznych mechanizmów przeglądarki. Przeglądarki przeprowadzają pewne optymalizacje, aby poprawić wydajność w sposób, w jaki my, jako programiści, nie możemy tego zrobić – ale tylko wtedy, gdy te optymalizacje nie są nieumyślnie udaremniane.
Jedną z optymalizacji przeglądarki, którą warto poznać, jest skaner wstępnego wczytywania przeglądarki. Z tego posta dowiesz się, jak działa skaner wstępnego wczytywania, a co ważniejsze – jak uniknąć przeszkadzania mu w pracy.
Czym jest skaner wstępnego wczytywania?
Każda przeglądarka ma podstawowy parser HTML, który dzieli surowe znaczniki na tokeny i przetwarza je w model obiektowy. Wszystko to przebiega sprawnie, dopóki parser nie napotka zasobu blokującego, np. arkusza stylów wczytanego za pomocą elementu <link> lub skryptu wczytanego za pomocą elementu <script> bez atrybutu async lub defer.

<link> dla zewnętrznego pliku CSS, który blokuje przeglądarce analizowanie pozostałej części dokumentu, a nawet renderowanie jego fragmentów, dopóki plik CSS nie zostanie pobrany i przeanalizowany.
W przypadku plików CSS renderowanie jest blokowane, aby zapobiec mignięciu nieostylowanej treści (FOUC), czyli sytuacji, w której nieostylowana wersja strony jest przez chwilę widoczna, zanim zostaną do niej zastosowane style.
Gdy przeglądarka napotka elementy <script> bez atrybutu defer lub async, blokuje też analizowanie i renderowanie strony.
Dzieje się tak, ponieważ przeglądarka nie może mieć pewności, czy dany skrypt zmodyfikuje DOM, gdy główny parser HTML nadal będzie wykonywać swoją pracę. Dlatego powszechną praktyką jest wczytywanie JavaScriptu na końcu dokumentu, aby zminimalizować skutki blokowania analizowania i renderowania.
To dobre powody, dla których przeglądarka powinna blokować zarówno analizowanie, jak i renderowanie. Blokowanie któregokolwiek z tych ważnych kroków jest jednak niepożądane, ponieważ może opóźnić wyświetlanie strony przez opóźnienie wykrywania innych ważnych zasobów. Na szczęście przeglądarki starają się ograniczyć te problemy za pomocą dodatkowego analizatora HTML o nazwie skaner wstępnego wczytywania.

<body>. Skaner wstępnego wczytywania może jednak przejrzeć surowy kod, aby znaleźć zasób obrazu i zacząć go wczytywać, zanim główny parser HTML zostanie odblokowany.
Rola skanera wstępnego ładowania jest spekulatywna, co oznacza, że analizuje on surowy kod znaczników, aby znaleźć zasoby do pobrania w odpowiednim momencie, zanim odkryje je główny parser HTML.
Jak sprawdzić, czy skaner wstępnego wczytywania działa
Skaner wstępnego wczytywania istnieje z powodu zablokowanego renderowania i parsowania. Gdyby te 2 problemy z wydajnością nigdy nie istniały, skaner wstępnego wczytywania nie byłby zbyt przydatny. Kluczem do ustalenia, czy strona internetowa korzysta ze skanera wstępnego załadowania, są te zjawiska blokujące. Aby to zrobić, możesz wprowadzić sztuczne opóźnienie w żądaniach, aby sprawdzić, gdzie działa skaner wstępnego wczytywania.
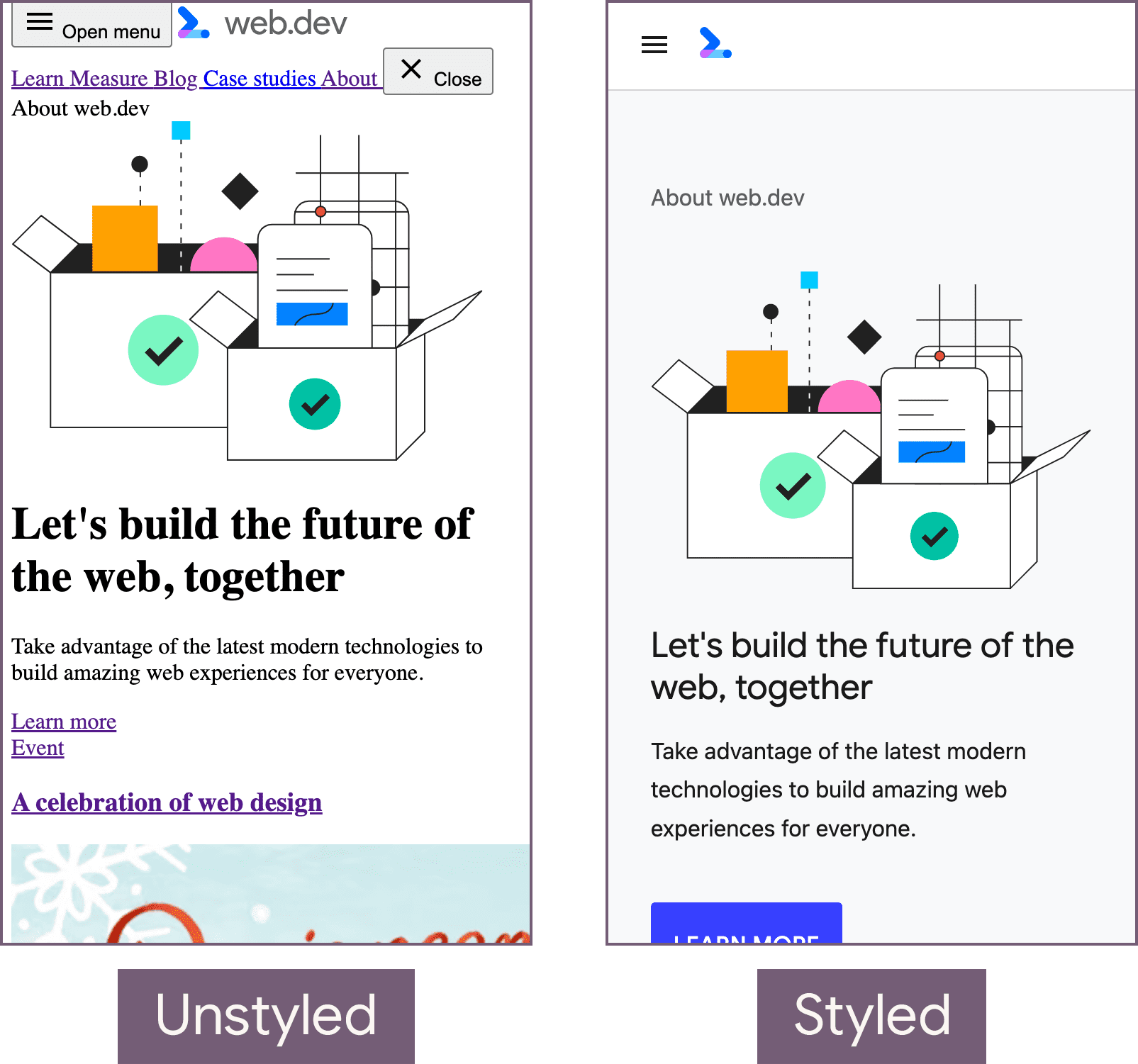
Weźmy na przykład tę stronę z podstawowym tekstem i obrazami z arkuszem stylów. Pliki CSS blokują zarówno renderowanie, jak i parsowanie, dlatego za pomocą usługi proxy wprowadzisz sztuczne opóźnienie arkusza stylów o 2 sekundy. To opóźnienie ułatwia sprawdzenie w kaskadzie sieci, gdzie działa skaner wstępnego wczytywania.

Jak widać na wykresie kaskadowym, skaner wstępnego załadowania wykrywa element <img> nawet wtedy, gdy renderowanie i parsowanie dokumentu są zablokowane. Bez tej optymalizacji przeglądarka nie może pobierać elementów w okresie blokowania, a więcej żądań zasobów byłoby kolejnych, a nie równoległych.
Po tym prostym przykładzie przyjrzyjmy się rzeczywistym wzorcom, w których skaner wstępnego wczytywania może zostać pokonany, i sposobom ich naprawy.
Wstrzyknięte skrypty async
Załóżmy, że w tagu <head> masz kod HTML, który zawiera wbudowany kod JavaScript, np. taki:
<script>
const scriptEl = document.createElement('script');
scriptEl.src = '/yall.min.js';
document.head.appendChild(scriptEl);
</script>
Wstrzykiwane skrypty są domyślnie async, więc po wstrzyknięciu ten skrypt będzie się zachowywać tak, jakby zastosowano do niego atrybut async. Oznacza to, że skrypt zostanie uruchomiony tak szybko, jak to możliwe, i nie będzie blokować renderowania. Brzmi optymalnie, prawda? Jeśli jednak założysz, że ten wbudowany styl <script> występuje po elemencie <link>, który wczytuje zewnętrzny plik CSS, uzyskasz nieoptymalny wynik:
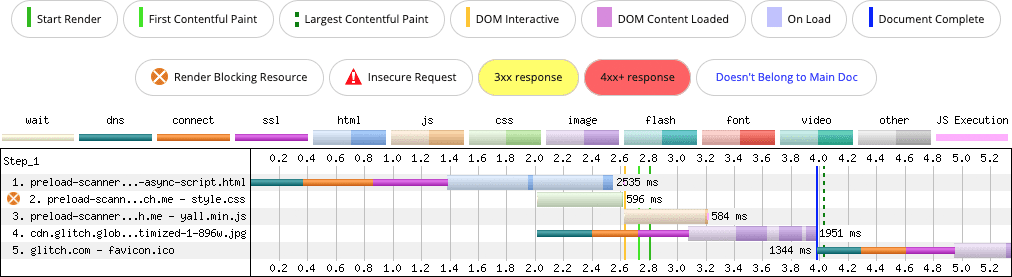
async. Skaner wstępnego wczytywania nie może wykryć skryptu w fazie blokowania renderowania, ponieważ jest on wstrzykiwany po stronie klienta.
Przeanalizujmy, co się stało:
- W 0 sekundzie wysyłana jest prośba o główny dokument.
- Po 1, 4 sekundy dociera pierwszy bajt żądania nawigacji.
- Po 2 sekundach wysyłane są żądania dotyczące CSS i obrazu.
- Parser blokuje wczytywanie arkusza stylów i wbudowanego kodu JavaScript, który wstawia skrypt
async.Ten kod pojawia się po arkuszu stylów po 2,6 sekundy, więc funkcje, które zapewnia ten skrypt, nie są dostępne tak szybko, jak mogłyby być.
Jest to nieoptymalne, ponieważ żądanie skryptu następuje dopiero po zakończeniu pobierania arkusza stylów. Opóźnia to uruchomienie skryptu tak szybko, jak to możliwe. Natomiast element <img> jest wykrywalny w dostarczonym przez serwer znaczniku, więc jest wykrywany przez skaner wstępnego ładowania.
Co się stanie, jeśli użyjesz zwykłego tagu <script> z atrybutem async zamiast wstrzykiwać skrypt do modelu DOM?
<script src="/yall.min.js" async></script>
Oto wynik:

async <script>. Skaner wstępnego wczytywania wykrywa skrypt w fazie blokowania renderowania i wczytuje go równolegle z arkuszem CSS.
Może pojawić się pokusa, aby zasugerować, że te problemy można rozwiązać za pomocą rel=preload. To z pewnością zadziała, ale może mieć pewne skutki uboczne. Po co używać rel=preload, aby rozwiązać problem, którego można uniknąć, nie wstrzykując elementu <script> do DOM?
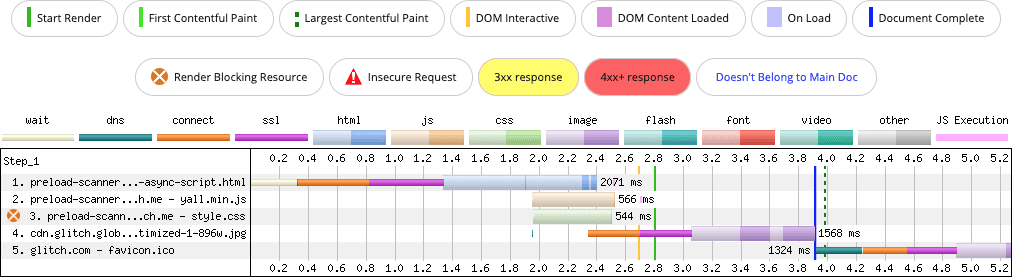
async, ale skrypt async jest wstępnie wczytany, aby można go było szybciej wykryć.
Wstępne wczytywanie „rozwiązuje” ten problem, ale wprowadza nowy: skrypt async w pierwszych 2 wersjach demonstracyjnych – mimo że jest wczytywany w <head> – jest wczytywany z priorytetem „Niski”, podczas gdy arkusz stylów jest wczytywany z priorytetem „Najwyższy”. W ostatnim przykładzie, w którym skrypt async jest wstępnie wczytany, arkusz stylów jest nadal wczytywany z priorytetem „Najwyższy”, ale priorytet skryptu został podniesiony do „Wysoki”.
Gdy priorytet zasobu zostanie podniesiony, przeglądarka przydzieli mu więcej przepustowości. Oznacza to, że mimo że arkusz stylów ma najwyższy priorytet, podniesiony priorytet skryptu może powodować rywalizację o przepustowość. Może to być problem w przypadku wolnych połączeń lub gdy zasoby są dość duże.
Odpowiedź jest prosta: jeśli skrypt jest potrzebny podczas uruchamiania, nie należy go wstrzykiwać do DOM, aby nie utrudniać działania skanera wstępnego ładowania. W razie potrzeby eksperymentuj z umiejscowieniem elementu <script> oraz atrybutami, takimi jak defer i async.
Leniwe ładowanie za pomocą JavaScriptu
Leniwe ładowanie to świetna metoda oszczędzania danych, często stosowana w przypadku obrazów. Czasami jednak leniwe ładowanie jest nieprawidłowo stosowane do obrazów, które znajdują się „nad granicą wyznaczającą część strony widoczną na ekranie”.
Może to powodować problemy z wykrywalnością zasobów w przypadku skanera wstępnego wczytywania i niepotrzebnie opóźniać wykrywanie odwołania do obrazu, jego pobieranie, dekodowanie i wyświetlanie. Weźmy na przykład ten kod obrazu:
<img data-src="/sand-wasp.jpg" alt="Sand Wasp" width="384" height="255">
Użycie prefiksu data- to powszechny wzorzec w ładowarkach leniwych opartych na JavaScript. Gdy obraz zostanie przewinięty do obszaru widocznego, moduł wczytywania z opóźnieniem usuwa prefiks data-, co oznacza, że w powyższym przykładzie data-src staje się src. Ta aktualizacja powoduje pobranie zasobu przez przeglądarkę.
Ten wzorzec nie jest problematyczny, dopóki nie zostanie zastosowany do obrazów, które są widoczne w obszarze wyświetlania podczas uruchamiania. Skaner wstępnego wczytywania nie odczytuje atrybutu data-src w taki sam sposób jak atrybutu src (lub srcset), więc odwołanie do obrazu nie jest wykrywane wcześniej. Co gorsza, obraz jest ładowany dopiero po pobraniu, skompilowaniu i wykonaniu kodu JavaScript leniwego ładowania.
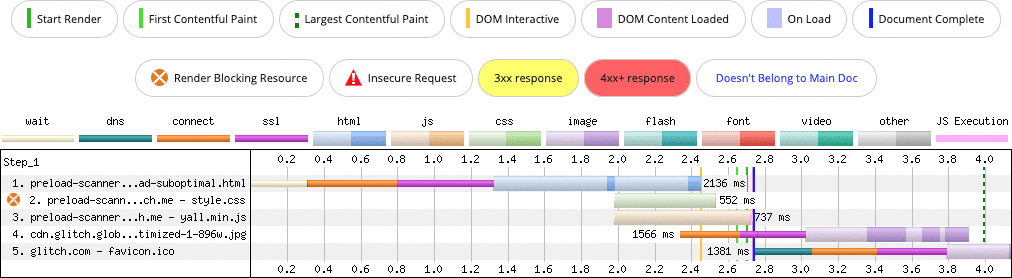
W zależności od rozmiaru obrazu, który może zależeć od rozmiaru widocznego obszaru, może on być elementem kandydującym do największego wyrenderowania treści (LCP). Gdy skaner wstępnego wczytywania nie może spekulacyjnie pobrać zasobu obrazu z wyprzedzeniem – być może w momencie, gdy arkusze stylów strony blokują renderowanie – wartość LCP jest niższa.
Rozwiązaniem jest zmiana kodu obrazu:
<img src="/sand-wasp.jpg" alt="Sand Wasp" width="384" height="255">
Jest to optymalny wzorzec w przypadku obrazów, które są widoczne w obszarze widoku podczas uruchamiania, ponieważ skaner wstępnego wczytywania szybciej wykryje i pobierze zasób obrazu.
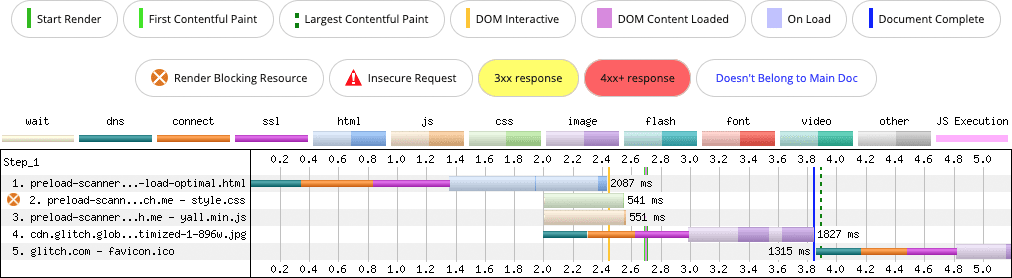
W tym uproszczonym przykładzie wskaźnik LCP poprawił się o 100 milisekund przy wolnym połączeniu. Może się to nie wydawać dużą poprawą, ale jest nią, jeśli weźmiesz pod uwagę, że rozwiązanie to szybka poprawka znaczników, a większość stron internetowych jest bardziej złożona niż ten zestaw przykładów. Oznacza to, że kandydaci do LCP mogą musieć konkurować o przepustowość z wieloma innymi zasobami, więc optymalizacje takie jak ta stają się coraz ważniejsze.
Obrazy tła CSS
Pamiętaj, że skaner wstępnego załadowania przeglądarki skanuje markup. Nie skanuje innych typów zasobów, takich jak CSS, które mogą obejmować pobieranie obrazów, do których odwołuje się właściwość background-image.
Podobnie jak w przypadku HTML, przeglądarki przetwarzają CSS na własny model obiektowy, zwany CSSOM. Jeśli podczas tworzenia modelu CSSOM zostaną wykryte zasoby zewnętrzne, są one żądane w momencie wykrycia, a nie przez skaner wstępnego wczytywania.
Załóżmy, że kandydatem do LCP na Twojej stronie jest element z właściwością CSS background-image. Podczas wczytywania zasobów dzieje się to, co opisano poniżej:
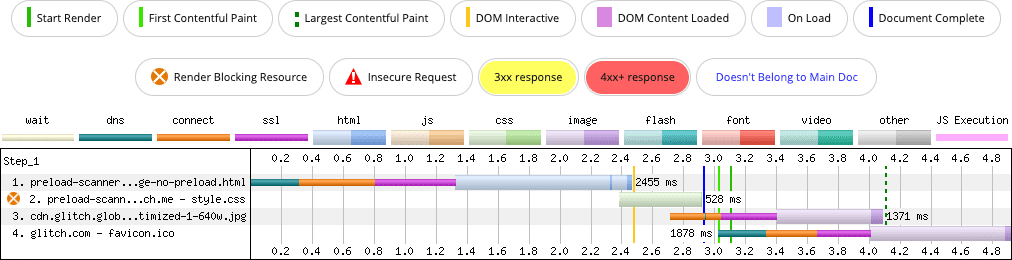
background-image (wiersz 3). Obraz, o który prosi, nie zacznie się pobierać, dopóki nie znajdzie go parser CSS.
W tym przypadku skaner wstępnego wczytywania nie jest pokonany, tylko nie jest zaangażowany. Jeśli jednak kandydat na element LCP na stronie pochodzi z background-imagewłaściwości CSS, warto wstępnie załadować ten obraz:
<!-- Make sure this is in the <head> below any
stylesheets, so as not to block them from loading -->
<link rel="preload" as="image" href="lcp-image.jpg">
Ta wskazówka rel=preload jest niewielka, ale pomaga przeglądarce szybciej wykryć obraz:
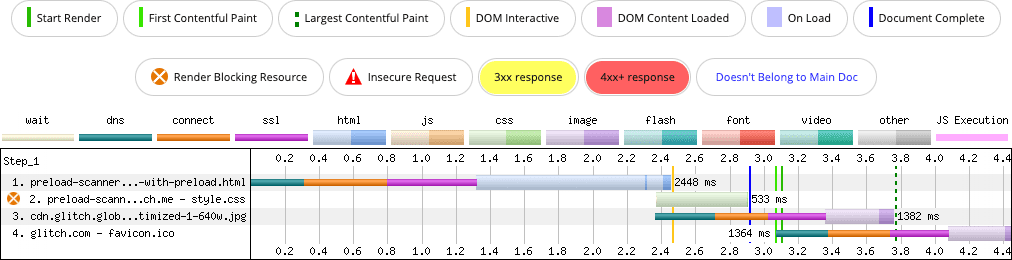
background-image (wiersz 3). Wskazówka rel=preload pomaga przeglądarce wykryć obraz o około 250 milisekund wcześniej niż bez niej.
Dzięki wskazówce rel=preload kandydat na LCP jest wykrywany wcześniej, co skraca czas LCP. Ta wskazówka pomaga rozwiązać problem, ale lepszym rozwiązaniem może być sprawdzenie, czy kandydat do LCP obrazu musi być wczytywany z CSS. Tag <img> zapewnia większą kontrolę nad wczytywaniem obrazu odpowiedniego dla obszaru wyświetlania, a jednocześnie umożliwia skanerowi wstępnego wczytywania jego wykrycie.
Wstawianie zbyt wielu zasobów
Wstawianie to praktyka umieszczania zasobu w kodzie HTML. Możesz wstawiać arkusze stylów w elementach <style>, skrypty w elementach <script> i praktycznie wszystkie inne zasoby za pomocą kodowania base64.
Wstawianie zasobów może być szybsze niż ich pobieranie, ponieważ nie jest wysyłane osobne żądanie zasobu. Jest on umieszczony bezpośrednio w dokumencie i wczytuje się natychmiast. Ma jednak istotne wady:
- Jeśli nie buforujesz kodu HTML (a nie możesz tego robić, jeśli odpowiedź HTML jest dynamiczna), zasoby wstawione w kodzie nigdy nie są buforowane. Ma to wpływ na wydajność, ponieważ zasoby wstawione w kodzie nie są wielokrotnego użytku.
- Nawet jeśli możesz zapisywać HTML w pamięci podręcznej, zasoby wbudowane nie są udostępniane między dokumentami. Zmniejsza to skuteczność buforowania w porównaniu z plikami zewnętrznymi, które można buforować i ponownie wykorzystywać w całym źródle.
- Jeśli umieścisz w kodzie zbyt dużo treści, opóźnisz skaner wstępnego ładowania, który nie będzie mógł wykryć zasobów znajdujących się w dalszej części dokumentu, ponieważ pobieranie dodatkowych treści umieszczonych w kodzie zajmuje więcej czasu.
Weźmy na przykład tę stronę. W określonych warunkach kandydatem do LCP jest obraz u góry strony, a CSS znajduje się w osobnym pliku wczytywanym przez element <link>. Strona korzysta też z 4 czcionek internetowych, które są pobierane jako osobne pliki z zasobu CSS.
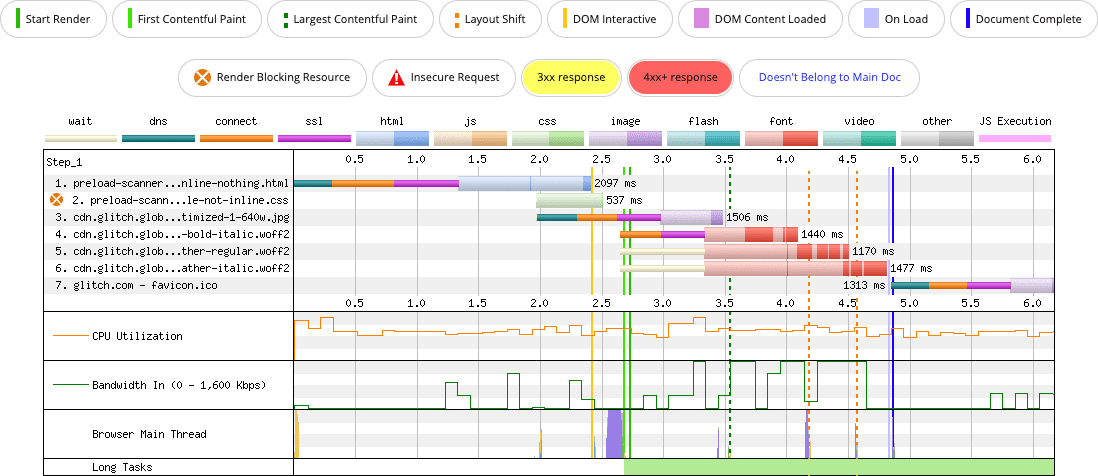
<img>, ale wykryty przez skaner wstępnego wczytywania, ponieważ CSS i czcionki wymagane do wczytania strony znajdują się w oddzielnych zasobach, co nie opóźnia działania skanera wstępnego wczytywania.
Co się stanie, jeśli CSS i wszystkie czcionki zostaną wstawione jako zasoby Base64?
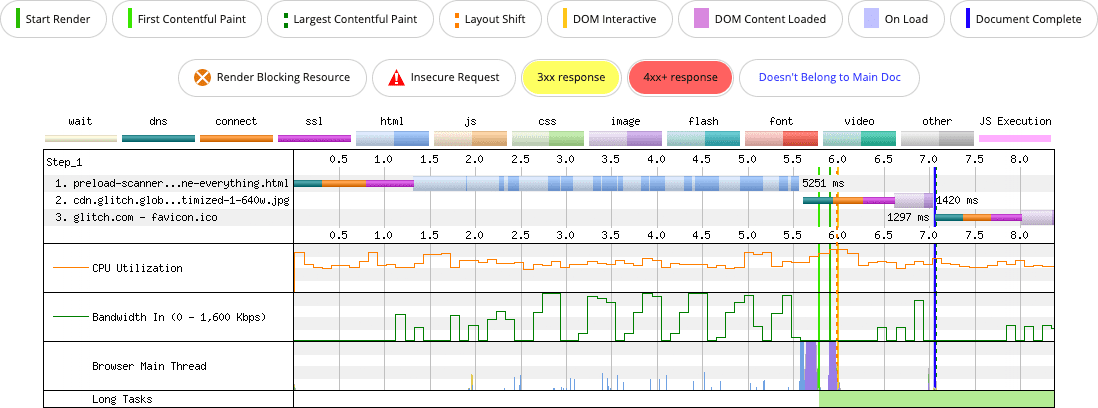
<img>, ale wstawienie CSS i 4 zasobów czcionek w sekcji `` opóźnia wykrycie obrazu przez skaner wstępnego wczytywania, dopóki te zasoby nie zostaną w pełni pobrane.
W tym przykładzie wstawianie treści w kodzie ma negatywny wpływ na LCP i ogólną wydajność. Wersja strony, która nie zawiera niczego w formie inline, renderuje obraz LCP w około 3,5 sekundy. Strona, która zawiera wszystko w formie inline, nie renderuje obrazu LCP przez ponad 7 sekund.
W tym przypadku chodzi o coś więcej niż tylko skaner wstępnego wczytywania. Osadzanie czcionek nie jest dobrą strategią, ponieważ base64 to nieefektywny format zasobów binarnych. Kolejnym czynnikiem jest to, że zewnętrzne zasoby czcionek nie są pobierane, chyba że CSSOM uzna je za niezbędne. Gdy te czcionki są wstawiane w kodzie jako base64, są pobierane niezależnie od tego, czy są potrzebne na bieżącej stronie.
Czy wstępne wczytywanie może coś tu poprawić? Jasne. Możesz wstępnie załadować obraz LCP i skrócić czas LCP, ale dodanie do potencjalnie niepodlegającego buforowaniu kodu HTML zasobów wstawionych w kodzie ma inne negatywne konsekwencje dla wydajności. Ten wzorzec ma też wpływ na pierwsze wyrenderowanie treści (FCP). W wersji strony, w której nic nie jest wstawione w kodzie, FCP wynosi około 2,7 sekundy. W wersji, w której wszystko jest wstawione w kodzie, FCP wynosi około 5,8 sekundy.
Zachowaj szczególną ostrożność podczas wstawiania elementów do kodu HTML, zwłaszcza zasobów zakodowanych w formacie Base64. Zasadniczo nie jest to zalecane, z wyjątkiem bardzo małych zasobów. Wstawiaj jak najmniej elementów w tekście, ponieważ wstawianie zbyt wielu elementów jest ryzykowne.
Renderowanie znaczników za pomocą JavaScriptu po stronie klienta
Nie ma wątpliwości, że JavaScript zdecydowanie wpływa na Page Speed. Deweloperzy nie tylko polegają na nim w zakresie interaktywności, ale też coraz częściej wykorzystują go do dostarczania treści. W pewnym sensie poprawia to komfort pracy deweloperów, ale korzyści dla nich nie zawsze przekładają się na korzyści dla użytkowników.
Jednym ze sposobów na obejście skanera wstępnego wczytywania jest renderowanie znaczników za pomocą JavaScriptu po stronie klienta:
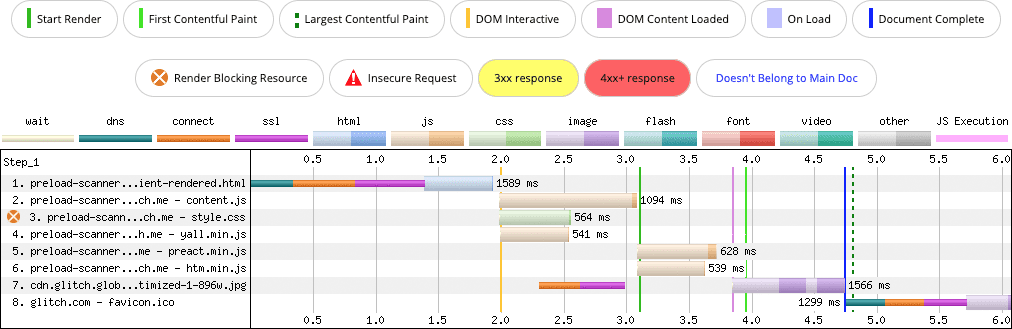
Gdy ładunki znaczników są zawarte w kodzie JavaScript i w całości renderowane przez ten kod w przeglądarce, wszystkie zasoby w tych znacznikach są niewidoczne dla skanera wstępnego ładowania. Opóźnia to wykrywanie ważnych zasobów, co z pewnością wpływa na LCP. W tych przykładach żądanie obrazu LCP jest znacznie opóźnione w porównaniu z odpowiednim renderowaniem po stronie serwera, które nie wymaga wyświetlania JavaScriptu.
To odbiega nieco od tematu tego artykułu, ale efekty renderowania znaczników po stronie klienta wykraczają daleko poza pokonanie skanera wstępnego wczytywania. Po pierwsze, wprowadzenie JavaScriptu do obsługi funkcji, która go nie wymaga, powoduje niepotrzebne wydłużenie czasu przetwarzania, co może wpłynąć na interakcję do kolejnego wyrenderowania (INP). Renderowanie bardzo dużych ilości kodu po stronie klienta częściej generuje długie zadania niż wysyłanie tej samej ilości kodu przez serwer. Powodem tego jest nie tylko dodatkowe przetwarzanie, które wymaga JavaScript, ale też to, że przeglądarki przesyłają strumieniowo znaczniki z serwera i dzielą renderowanie w taki sposób, aby ograniczać długie zadania. Z kolei znacznik renderowany po stronie klienta jest traktowany jako jedno monolityczne zadanie, co może mieć wpływ na INP strony.
Rozwiązanie w tej sytuacji zależy od odpowiedzi na to pytanie: Czy istnieje powód, dla którego serwer nie może dostarczyć kodu strony, zamiast renderować go na urządzeniu klienta? Jeśli odpowiedź na to pytanie brzmi „nie”, warto rozważyć renderowanie po stronie serwera (SSR) lub statyczne generowanie znaczników, ponieważ pomoże to skanerowi wstępnego wczytywania wcześniej wykrywać i pobierać ważne zasoby.
Jeśli Twoja strona wymaga JavaScriptu, aby dodać funkcje do niektórych części kodu strony, możesz to zrobić za pomocą SSR, używając zwykłego JavaScriptu lub hydratacji, aby uzyskać najlepsze efekty.
Pomoc dla skanera wstępnego wczytywania
Skaner wstępnego wczytywania to bardzo skuteczna optymalizacja przeglądarki, która pomaga szybciej wczytywać strony podczas uruchamiania. Unikanie wzorców, które uniemożliwiają wcześniejsze wykrywanie ważnych zasobów, nie tylko ułatwia Ci pracę, ale też pozwala tworzyć lepsze wrażenia użytkowników, co przekłada się na lepsze wyniki w wielu wskaźnikach, w tym w przypadku niektórych wskaźników internetowych.
Podsumowując, z tego posta warto zapamiętać te informacje:
- Skaner wstępnego wczytywania przeglądarki to pomocniczy parser HTML, który skanuje przed głównym parserem, jeśli jest on zablokowany, aby oportunistycznie wykrywać zasoby, które można pobrać wcześniej.
- Zasoby, których nie ma w znacznikach dostarczonych przez serwer w odpowiedzi na początkowe żądanie nawigacji, nie mogą zostać wykryte przez skaner wstępnego wczytywania. Sposoby obejścia skanera wstępnego mogą obejmować (ale nie tylko):
- Wstrzykiwanie zasobów do DOM za pomocą JavaScriptu, niezależnie od tego, czy są to skrypty, obrazy, arkusze stylów czy inne elementy, które lepiej byłoby umieścić w początkowym ładunku znaczników z serwera.
- Leniwe ładowanie obrazów i elementów iframe widocznych na ekranie za pomocą rozwiązania JavaScript.
- Renderowanie znaczników na kliencie, które mogą zawierać odwołania do zasobów podrzędnych dokumentu za pomocą JavaScriptu.
- Skaner wstępnego załadowania skanuje tylko HTML. Nie analizuje zawartości innych zasobów, zwłaszcza CSS, które mogą zawierać odwołania do ważnych zasobów, w tym kandydatów do LCP.
Jeśli z jakiegoś powodu nie możesz uniknąć wzorca, który negatywnie wpływa na zdolność skanera wstępnego ładowania do przyspieszania ładowania, rozważ użycie wskazówki dotyczącej zasobu rel=preload. Jeśli używasz rel=preload, przetestuj je w narzędziach laboratoryjnych, aby upewnić się, że daje oczekiwany efekt. Nie wczytuj też wstępnie zbyt wielu zasobów, ponieważ jeśli wszystko będzie priorytetem, nic nim nie będzie.
Zasoby
- Szkodliwe „skrypty niesynchroniczne” wstawiane przez skrypt
- Jak wstępne wczytywanie w przeglądarce przyspiesza wczytywanie stron
- Wstępne wczytywanie najważniejszych zasobów w celu zwiększenia szybkości wczytywania
- Wcześniejsze nawiązywanie połączeń sieciowych w celu zwiększenia postrzeganej szybkości działania strony
- Optymalizacja największego wyrenderowania treści
Baner powitalny z Unsplash, autor: Mohammad Rahmani .