

Introducción
Las Extensiones de fuente de medios (MSE) proporcionan un control extendido del almacenamiento en búfer y la reproducción para los elementos <audio> y <video> de HTML5. Si bien se desarrollaron originalmente para facilitar los reproductores de video basados en la transmisión adaptable y dinámica a través de HTTP (DASH), a continuación, veremos cómo se pueden usar para el audio, específicamente para la reproducción sin interrupciones.
Es probable que hayas escuchado un álbum musical en el que las canciones fluyen sin problemas entre las pistas. Incluso es posible que estés escuchando uno ahora mismo. Los artistas crean estas experiencias de reproducción sin pausas como una elección artística y como un artefacto de los discos de vinilo y los CDs, en los que el audio se grababa como un flujo continuo. Lamentablemente, debido a la forma en que funcionan los códecs de audio modernos, como MP3 y AAC, esta experiencia auditiva fluida a menudo se pierde en la actualidad.
A continuación, analizaremos los detalles de por qué, pero, por ahora, comencemos con una demostración. A continuación, se muestran los primeros treinta segundos del excelente Sintel, divididos en cinco archivos MP3 separados y reensamblados con MSE. Las líneas rojas indican las brechas que se introdujeron durante la creación (codificación) de cada MP3. Escucharás fallas en estos puntos.
¡Qué asco! Esa no es una gran experiencia; podemos hacerlo mejor. Con un poco más de trabajo, y usando los mismos archivos MP3 de la demostración anterior, podemos usar MSE para quitar esos molestos espacios. Las líneas verdes de la siguiente demostración indican dónde se unieron los archivos y se quitaron los espacios. En Chrome 38 y versiones posteriores, se reproducirá sin problemas.
Existen varias formas de crear contenido sin interrupciones. Para los fines de esta demostración, nos enfocaremos en el tipo de archivos que un usuario normal podría tener. Cada archivo se codificó por separado sin tener en cuenta los segmentos de audio anteriores o posteriores.
Configuración básica
Primero, retrocedamos y veamos la configuración básica de una instancia de MediaSource.
Las Media Source Extensions, como su nombre lo indica, son solo extensiones de los elementos multimedia existentes. A continuación, asignamos un Object URL, que representa nuestra instancia de MediaSource, al atributo source de un elemento de audio, tal como establecerías una URL estándar.
var audio = document.createElement('audio');
var mediaSource = new MediaSource();
var SEGMENTS = 5;
mediaSource.addEventListener('sourceopen', function () {
var sourceBuffer = mediaSource.addSourceBuffer('audio/mpeg');
function onAudioLoaded(data, index) {
// Append the ArrayBuffer data into our new SourceBuffer.
sourceBuffer.appendBuffer(data);
}
// Retrieve an audio segment via XHR. For simplicity, we're retrieving the
// entire segment at once, but we could also retrieve it in chunks and append
// each chunk separately. MSE will take care of assembling the pieces.
GET('sintel/sintel_0.mp3', function (data) {
onAudioLoaded(data, 0);
});
});
audio.src = URL.createObjectURL(mediaSource);
Una vez que se conecta el objeto MediaSource, realizará alguna inicialización y, finalmente, activará un evento sourceopen, momento en el que podremos crear un SourceBuffer. En el ejemplo anterior, creamos un audio/mpeg, que puede analizar y decodificar nuestros segmentos MP3. Hay disponibles otros tipos.
Formas de onda anómalas
Volveremos al código en un momento, pero ahora analicemos con más detalle el archivo que acabamos de agregar, específicamente al final. A continuación, se muestra un gráfico de las últimas 3,000 muestras promediadas en ambos canales de la pista sintel_0.mp3. Cada píxel de la línea roja es una muestra de punto flotante en el rango de [-1.0, 1.0].

¿Por qué hay tantas muestras silenciosas? En realidad, se deben a artefactos de compresión que se introducen durante la codificación. Casi todos los codificadores introducen algún tipo de padding. En este caso, LAME agregó exactamente 576 muestras de padding al final del archivo.
Además del padding al final, también se agregó padding al comienzo de cada archivo. Si echamos un vistazo al segmento sintel_1.mp3, veremos que hay otros 576 samples de padding al principio. La cantidad de relleno varía según el codificador y el contenido, pero conocemos los valores exactos según el metadata incluido en cada archivo.
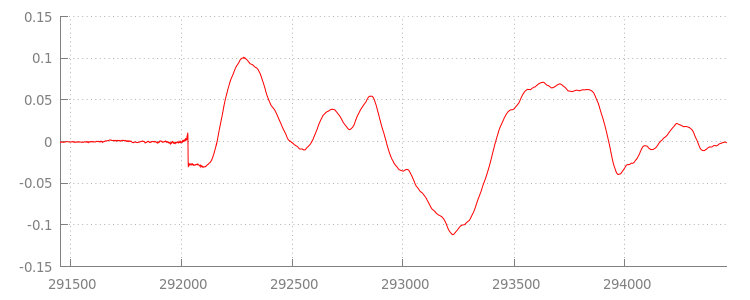
Las secciones de silencio al principio y al final de cada archivo son las que causan las interrupciones entre los segmentos de la demostración anterior. Para lograr una reproducción sin interrupciones, debemos quitar estas secciones de silencio. Por suerte, esto se puede hacer fácilmente con MediaSource. A continuación, modificaremos nuestro método onAudioLoaded() para usar una ventana de anexión y un desplazamiento de marca de tiempo para quitar este silencio.
Código de ejemplo
function onAudioLoaded(data, index) {
// Parsing gapless metadata is unfortunately non trivial and a bit messy, so
// we'll glaze over it here; see the appendix for details.
// ParseGaplessData() will return a dictionary with two elements:
//
// audioDuration: Duration in seconds of all non-padding audio.
// frontPaddingDuration: Duration in seconds of the front padding.
//
var gaplessMetadata = ParseGaplessData(data);
// Each appended segment must be appended relative to the next. To avoid any
// overlaps, we'll use the end timestamp of the last append as the starting
// point for our next append or zero if we haven't appended anything yet.
var appendTime = index > 0 ? sourceBuffer.buffered.end(0) : 0;
// Simply put, an append window allows you to trim off audio (or video) frames
// which fall outside of a specified time range. Here, we'll use the end of
// our last append as the start of our append window and the end of the real
// audio data for this segment as the end of our append window.
sourceBuffer.appendWindowStart = appendTime;
sourceBuffer.appendWindowEnd = appendTime + gaplessMetadata.audioDuration;
// The timestampOffset field essentially tells MediaSource where in the media
// timeline the data given to appendBuffer() should be placed. I.e., if the
// timestampOffset is 1 second, the appended data will start 1 second into
// playback.
//
// MediaSource requires that the media timeline starts from time zero, so we
// need to ensure that the data left after filtering by the append window
// starts at time zero. We'll do this by shifting all of the padding we want
// to discard before our append time (and thus, before our append window).
sourceBuffer.timestampOffset =
appendTime - gaplessMetadata.frontPaddingDuration;
// When appendBuffer() completes, it will fire an updateend event signaling
// that it's okay to append another segment of media. Here, we'll chain the
// append for the next segment to the completion of our current append.
if (index == 0) {
sourceBuffer.addEventListener('updateend', function () {
if (++index < SEGMENTS) {
GET('sintel/sintel_' + index + '.mp3', function (data) {
onAudioLoaded(data, index);
});
} else {
// We've loaded all available segments, so tell MediaSource there are no
// more buffers which will be appended.
mediaSource.endOfStream();
URL.revokeObjectURL(audio.src);
}
});
}
// appendBuffer() will now use the timestamp offset and append window settings
// to filter and timestamp the data we're appending.
//
// Note: While this demo uses very little memory, more complex use cases need
// to be careful about memory usage or garbage collection may remove ranges of
// media in unexpected places.
sourceBuffer.appendBuffer(data);
}
Una forma de onda fluida
Veamos qué logró nuestro nuevo y brillante código. Para ello, volvamos a observar la forma de onda después de aplicar nuestras ventanas de anexión. A continuación, puedes ver que se quitaron la sección silenciosa al final de sintel_0.mp3 (en rojo) y la sección silenciosa al principio de sintel_1.mp3 (en azul), lo que nos dejó una transición fluida entre los segmentos.
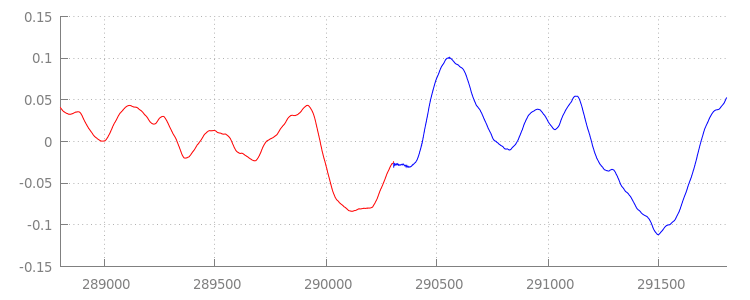
Conclusión
Con eso, unimos los cinco segmentos sin problemas en uno solo y, posteriormente, llegamos al final de nuestra demostración. Antes de continuar, es posible que hayas notado que nuestro método onAudioLoaded() no tiene en cuenta los contenedores ni los códecs.
Esto significa que todas estas técnicas funcionarán independientemente del contenedor o del tipo de códec. A continuación, puedes volver a reproducir el MP4 fragmentado original listo para DASH en lugar del MP3.
Si quieres obtener más información, consulta los apéndices a continuación para conocer en detalle la creación de contenido sin interrupciones y el análisis de metadatos. También puedes explorar gapless.js para ver más de cerca el código que impulsa esta demostración.
¡Gracias por leer esta información!
Apéndice A: Cómo crear contenido sin pausas
Crear contenido sin pausas puede ser difícil. A continuación, explicaremos cómo crear el contenido multimedia de Sintel que se usa en esta demostración. Para comenzar, necesitarás una copia de la pista de audio FLAC sin pérdida de Sintel. Para que quede registrado, se incluye el SHA1 a continuación. Para las herramientas, necesitarás FFmpeg, MP4Box, LAME y una instalación de OSX con afconvert.
unzip Jan_Morgenstern-Sintel-FLAC.zip
sha1sum 1-Snow_Fight.flac
# 0535ca207ccba70d538f7324916a3f1a3d550194 1-Snow_Fight.flac
Primero, dividiremos los primeros 31.5 segundos de la pista 1-Snow_Fight.flac. También queremos agregar un fundido de salida de 2.5 segundos a partir de los 28 segundos para evitar clics una vez que finalice la reproducción. Con la siguiente línea de comandos de FFmpeg, podemos lograr todo esto y colocar los resultados en sintel.flac.
ffmpeg -i 1-Snow_Fight.flac -t 31.5 -af "afade=t=out:st=28:d=2.5" sintel.flac
A continuación, dividiremos el archivo en 5 archivos wave de 6.5 segundos cada uno. Es más fácil usar wave, ya que casi todos los codificadores admiten su incorporación. Nuevamente, podemos hacer esto con precisión con FFmpeg, después de lo cual tendremos: sintel_0.wav, sintel_1.wav, sintel_2.wav, sintel_3.wav y sintel_4.wav.
ffmpeg -i sintel.flac -acodec pcm_f32le -map 0 -f segment \
-segment_list out.list -segment_time 6.5 sintel_%d.wav
A continuación, crearemos los archivos MP3. LAME tiene varias opciones para crear contenido sin pausas. Si controlas el contenido, puedes considerar usar --nogap con una codificación por lotes de todos los archivos para evitar el padding entre segmentos por completo.
Sin embargo, para los fines de esta demostración, queremos ese relleno, por lo que usaremos una codificación VBR estándar de alta calidad de los archivos de onda.
lame -V=2 sintel_0.wav sintel_0.mp3
lame -V=2 sintel_1.wav sintel_1.mp3
lame -V=2 sintel_2.wav sintel_2.mp3
lame -V=2 sintel_3.wav sintel_3.mp3
lame -V=2 sintel_4.wav sintel_4.mp3
Eso es todo lo que necesitas para crear los archivos MP3. Ahora veamos la creación de los archivos MP4 fragmentados. Seguiremos las instrucciones de Apple para crear contenido multimedia masterizado para iTunes. A continuación, convertiremos los archivos de onda en archivos CAF intermedios, según las instrucciones, antes de codificarlos como AAC en un contenedor MP4 con los parámetros recomendados.
afconvert sintel_0.wav sintel_0_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_1.wav sintel_1_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_2.wav sintel_2_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_3.wav sintel_3_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_4.wav sintel_4_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_0_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_0.m4a
afconvert sintel_1_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_1.m4a
afconvert sintel_2_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_2.m4a
afconvert sintel_3_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_3.m4a
afconvert sintel_4_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_4.m4a
Ahora tenemos varios archivos M4A que debemos fragmentar de forma adecuada antes de poder usarlos con MediaSource. Para nuestros fines, usaremos un tamaño de fragmento de un segundo. MP4Box escribirá cada MP4 fragmentado como sintel_#_dashinit.mp4 junto con un manifiesto de MPEG-DASH (sintel_#_dash.mpd) que se puede descartar.
MP4Box -dash 1000 sintel_0.m4a && mv sintel_0_dashinit.mp4 sintel_0.mp4
MP4Box -dash 1000 sintel_1.m4a && mv sintel_1_dashinit.mp4 sintel_1.mp4
MP4Box -dash 1000 sintel_2.m4a && mv sintel_2_dashinit.mp4 sintel_2.mp4
MP4Box -dash 1000 sintel_3.m4a && mv sintel_3_dashinit.mp4 sintel_3.mp4
MP4Box -dash 1000 sintel_4.m4a && mv sintel_4_dashinit.mp4 sintel_4.mp4
rm sintel_{0,1,2,3,4}_dash.mpd
Eso es todo. Ahora tenemos archivos MP4 y MP3 fragmentados con los metadatos correctos necesarios para la reproducción sin interrupciones. Consulta el Apéndice B para obtener más detalles sobre cómo se ven esos metadatos.
Apéndice B: Cómo analizar metadatos sin pausas
Al igual que con la creación de contenido sin pausas, analizar los metadatos sin pausas puede ser complicado, ya que no existe un método estándar para el almacenamiento. A continuación, explicaremos cómo los dos codificadores más comunes, LAME y iTunes, almacenan sus metadatos sin interrupciones. Comencemos por configurar algunos métodos auxiliares y un esquema para el ParseGaplessData() que se usó anteriormente.
// Since most MP3 encoders store the gapless metadata in binary, we'll need a
// method for turning bytes into integers. Note: This doesn't work for values
// larger than 2^30 since we'll overflow the signed integer type when shifting.
function ReadInt(buffer) {
var result = buffer.charCodeAt(0);
for (var i = 1; i < buffer.length; ++i) {
result <<= 8;
result += buffer.charCodeAt(i);
}
return result;
}
function ParseGaplessData(arrayBuffer) {
// Gapless data is generally within the first 512 bytes, so limit parsing.
var byteStr = new TextDecoder().decode(arrayBuffer.slice(0, 512));
var frontPadding = 0, endPadding = 0, realSamples = 0;
// ... we'll fill this in as we go below.
Primero, analizaremos el formato de metadatos de iTunes de Apple, ya que es el más fácil de analizar y explicar. En los archivos MP3 y M4A, iTunes (y afconvert) escriben una sección corta en ASCII de la siguiente manera:
iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00
Se escribe dentro de una etiqueta ID3 en el contenedor MP3 y dentro de un átomo de metadatos en el contenedor MP4. Para nuestros fines, podemos ignorar el primer token 0000000. Los siguientes tres tokens son el padding inicial, el padding final y el recuento total de muestras sin padding. Si dividimos cada uno de estos valores por la frecuencia de muestreo del audio, obtenemos la duración de cada uno.
// iTunes encodes the gapless data as hex strings like so:
//
// 'iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00'
// 'iTunSMPB[ 26 bytes ]####### frontpad endpad real samples'
//
// The approach here elides the complexity of actually parsing MP4 atoms. It
// may not work for all files without some tweaks.
var iTunesDataIndex = byteStr.indexOf('iTunSMPB');
if (iTunesDataIndex != -1) {
var frontPaddingIndex = iTunesDataIndex + 34;
frontPadding = parseInt(byteStr.substr(frontPaddingIndex, 8), 16);
var endPaddingIndex = frontPaddingIndex + 9;
endPadding = parseInt(byteStr.substr(endPaddingIndex, 8), 16);
var sampleCountIndex = endPaddingIndex + 9;
realSamples = parseInt(byteStr.substr(sampleCountIndex, 16), 16);
}
Por otro lado, la mayoría de los codificadores de MP3 de código abierto almacenan los metadatos sin pausas en un encabezado Xing especial que se coloca dentro de un fotograma MPEG silencioso (es silencioso para que los decodificadores que no comprenden el encabezado Xing simplemente reproduzcan silencio). Lamentablemente, esta etiqueta no siempre está presente y tiene varios campos opcionales. Para los fines de esta demostración, tenemos control sobre los medios, pero, en la práctica, se requerirán algunas verificaciones de sensibilidad adicionales para saber cuándo los metadatos sin interrupciones están disponibles.
Primero, analizaremos la cantidad total de muestras. Para simplificar, leeremos esto desde el encabezado Xing, pero se podría construir a partir del encabezado de audio MPEG normal.
Los encabezados de Xing se pueden marcar con una etiqueta Xing o Info. Exactamente 4 bytes después de esta etiqueta, hay 32 bits que representan la cantidad total de fotogramas en el archivo. Si multiplicamos este valor por la cantidad de muestras por fotograma, obtendremos la cantidad total de muestras en el archivo.
// Xing padding is encoded as 24bits within the header. Note: This code will
// only work for Layer3 Version 1 and Layer2 MP3 files with XING frame counts
// and gapless information. See the following document for more details:
// http://www.codeproject.com/Articles/8295/MPEG-Audio-Frame-Header
var xingDataIndex = byteStr.indexOf('Xing');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Info');
if (xingDataIndex != -1) {
// See section 2.3.1 in the link above for the specifics on parsing the Xing
// frame count.
var frameCountIndex = xingDataIndex + 8;
var frameCount = ReadInt(byteStr.substr(frameCountIndex, 4));
// For Layer3 Version 1 and Layer2 there are 1152 samples per frame. See
// section 2.1.5 in the link above for more details.
var paddedSamples = frameCount * 1152;
// ... we'll cover this below.
Ahora que tenemos la cantidad total de muestras, podemos pasar a leer la cantidad de muestras de padding. Según tu codificador, es posible que esto se escriba en una etiqueta LAME o Lavf anidada en el encabezado Xing. Exactamente 17 bytes después de este encabezado, hay 3 bytes que representan el padding inicial y final en 12 bits cada uno, respectivamente.
xingDataIndex = byteStr.indexOf('LAME');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Lavf');
if (xingDataIndex != -1) {
// See http://gabriel.mp3-tech.org/mp3infotag.html#delays for details of
// how this information is encoded and parsed.
var gaplessDataIndex = xingDataIndex + 21;
var gaplessBits = ReadInt(byteStr.substr(gaplessDataIndex, 3));
// Upper 12 bits are the front padding, lower are the end padding.
frontPadding = gaplessBits >> 12;
endPadding = gaplessBits & 0xFFF;
}
realSamples = paddedSamples - (frontPadding + endPadding);
}
return {
audioDuration: realSamples * SECONDS_PER_SAMPLE,
frontPaddingDuration: frontPadding * SECONDS_PER_SAMPLE
};
}
Con eso, tenemos una función completa para analizar la gran mayoría del contenido sin interrupciones. Sin embargo, abundan los casos extremos, por lo que se recomienda tener precaución antes de usar código similar en producción.
Apéndice C: Sobre la recolección de elementos no utilizados
La memoria que pertenece a las instancias de SourceBuffer se recolecta como basura de forma activa según el tipo de contenido, los límites específicos de la plataforma y la posición de reproducción actual. En Chrome, primero se recuperará la memoria de los búferes ya reproducidos.
Sin embargo, si el uso de memoria supera los límites específicos de la plataforma, se quitará memoria de los búferes no reproducidos.
Cuando la reproducción llega a una brecha en la línea de tiempo debido a la memoria recuperada, es posible que se produzca una falla si la brecha es lo suficientemente pequeña o que se detenga por completo si la brecha es demasiado grande. Ninguna de las dos opciones ofrece una buena experiencia del usuario, por lo que es importante evitar agregar demasiados datos a la vez y quitar manualmente los rangos de la línea de tiempo de los medios que ya no sean necesarios.
Los rangos se pueden quitar con el método remove() en cada SourceBuffer, que toma un rango [start, end] en segundos.
De manera similar a appendBuffer(), cada remove() activará un evento updateend una vez que se complete. No se deben emitir otras acciones de eliminación o anexión hasta que se active el evento.
En Chrome para computadoras, puedes mantener en la memoria aproximadamente 12 megabytes de contenido de audio y 150 megabytes de contenido de video a la vez. No debes confiar en estos valores en diferentes navegadores o plataformas. Por ejemplo, es casi seguro que no representan a los dispositivos móviles.
La recolección de elementos no utilizados solo afecta los datos que se agregan a SourceBuffers. No hay límites en la cantidad de datos que puedes mantener almacenados en búfer en variables de JavaScript. También puedes volver a agregar los mismos datos en la misma posición si es necesario.