

ভূমিকা
মিডিয়া সোর্স এক্সটেনশন (MSE) HTML5-এর <audio> এবং <video> এলিমেন্টগুলোর জন্য বর্ধিত বাফারিং ও প্লেব্যাক নিয়ন্ত্রণ প্রদান করে। যদিও এটি মূলত ডাইনামিক অ্যাডাপটিভ স্ট্রিমিং ওভার HTTP (DASH) ভিত্তিক ভিডিও প্লেয়ারগুলোকে সহজতর করার জন্য তৈরি করা হয়েছিল, নিচে আমরা দেখব কীভাবে এটি অডিওর জন্য, বিশেষ করে গ্যাপলেস প্লেব্যাকের জন্য ব্যবহার করা যেতে পারে।
আপনি সম্ভবত এমন কোনো মিউজিক অ্যালবাম শুনেছেন যেখানে গানগুলো একটি ট্র্যাক থেকে অন্য ট্র্যাকে নির্বিঘ্নে প্রবাহিত হয়েছে; এমনকি আপনি হয়তো এই মুহূর্তেও সেরকম একটি শুনছেন। শিল্পীরা এই বিরতিহীন প্লেব্যাক অভিজ্ঞতা তৈরি করেন, যা একদিকে যেমন একটি শৈল্পিক পছন্দ, তেমনই অন্যদিকে ভিনাইল রেকর্ড এবং সিডির একটি নিদর্শন, যেখানে অডিও একটি অবিচ্ছিন্ন প্রবাহ হিসেবে লেখা হতো। দুর্ভাগ্যবশত, MP3 এবং AAC-এর মতো আধুনিক অডিও কোডেকগুলোর কার্যপ্রণালীর কারণে, এই নির্বিঘ্ন শ্রাব্য অভিজ্ঞতা আজকাল প্রায়শই হারিয়ে যায়।
এর কারণ বিস্তারিতভাবে আমরা নিচে আলোচনা করব, কিন্তু আপাতত চলুন একটি প্রদর্শনী দিয়ে শুরু করা যাক। নিচে চমৎকার 'সিন্টেল' গানটির প্রথম ত্রিশ সেকেন্ড দেওয়া হলো, যা পাঁচটি আলাদা MP3 ফাইলে কেটে MSE ব্যবহার করে পুনরায় একত্রিত করা হয়েছে। লাল রেখাগুলো প্রতিটি MP3 ফাইল তৈরির (এনকোডিং) সময় সৃষ্ট ফাঁকগুলো নির্দেশ করে; এই জায়গাগুলোতে আপনি কিছু ত্রুটি শুনতে পাবেন।
উফ! এটা মোটেও ভালো অভিজ্ঞতা নয়; আমরা এর চেয়ে ভালো করতে পারি। আরেকটু পরিশ্রম করলে, উপরের ডেমোতে দেখানো হুবহু একই MP3 ফাইলগুলো ব্যবহার করে, আমরা MSE-এর সাহায্যে ওই বিরক্তিকর ফাঁকগুলো দূর করতে পারি। পরবর্তী ডেমোতে সবুজ লাইনগুলো নির্দেশ করে যে ফাইলগুলো কোথায় জোড়া লাগানো হয়েছে এবং ফাঁকগুলো সরানো হয়েছে। Chrome 38+ এ এটি নির্বিঘ্নে প্লেব্যাক হবে!
গ্যাপলেস কন্টেন্ট তৈরি করার বিভিন্ন উপায় রয়েছে। এই ডেমোর জন্য, আমরা সেই ধরনের ফাইলগুলোর উপর মনোযোগ দেব যা একজন সাধারণ ব্যবহারকারীর কাছে থাকতে পারে। যেখানে প্রতিটি ফাইল তার আগের বা পরের অডিও অংশগুলোকে বিবেচনা না করে আলাদাভাবে এনকোড করা হয়েছে।
বেসিক সেটআপ
প্রথমে, চলুন একটু পেছনে ফিরে যাই এবং একটি MediaSource ইনস্ট্যান্সের প্রাথমিক সেটআপ সম্পর্কে জেনে নিই। Media Source Extensions, নাম থেকেই বোঝা যায়, এগুলো হলো বিদ্যমান মিডিয়া এলিমেন্টগুলোরই এক্সটেনশন। নিচে, আমরা একটি অডিও এলিমেন্টের source অ্যাট্রিবিউটে আমাদের MediaSource ইনস্ট্যান্সকে প্রতিনিধিত্বকারী একটি Object URL অ্যাসাইন করছি; ঠিক যেমনভাবে আপনি একটি সাধারণ URL সেট করেন।
var audio = document.createElement('audio');
var mediaSource = new MediaSource();
var SEGMENTS = 5;
mediaSource.addEventListener('sourceopen', function () {
var sourceBuffer = mediaSource.addSourceBuffer('audio/mpeg');
function onAudioLoaded(data, index) {
// Append the ArrayBuffer data into our new SourceBuffer.
sourceBuffer.appendBuffer(data);
}
// Retrieve an audio segment via XHR. For simplicity, we're retrieving the
// entire segment at once, but we could also retrieve it in chunks and append
// each chunk separately. MSE will take care of assembling the pieces.
GET('sintel/sintel_0.mp3', function (data) {
onAudioLoaded(data, 0);
});
});
audio.src = URL.createObjectURL(mediaSource);
MediaSource অবজেক্টটি সংযুক্ত হয়ে গেলে, এটি কিছু ইনিশিয়ালাইজেশন সম্পন্ন করবে এবং অবশেষে একটি sourceopen ইভেন্ট ফায়ার করবে; এই পর্যায়ে আমরা একটি SourceBuffer তৈরি করতে পারি। উপরের উদাহরণে, আমরা একটি audio/mpeg তৈরি করছি, যা আমাদের MP3 সেগমেন্টগুলো পার্স এবং ডিকোড করতে সক্ষম; এ ধরনের আরও বেশ কয়েকটি প্রকার উপলব্ধ আছে।
অস্বাভাবিক তরঙ্গরূপ
আমরা একটু পরেই কোডে ফিরে আসব, কিন্তু এখন আমরা যে ফাইলটি এইমাত্র যুক্ত করেছি, বিশেষ করে এর শেষের অংশটি, আরও ভালোভাবে দেখি। নিচে sintel_0.mp3 ট্র্যাকের উভয় চ্যানেলের গড় করা শেষ ৩০০০ স্যাম্পলের একটি গ্রাফ দেওয়া হলো। লাল রেখার প্রতিটি পিক্সেল হলো [-1.0, 1.0] পরিসরের মধ্যে একটি ফ্লোটিং পয়েন্ট স্যাম্পল ।

ঐ যে এতগুলো শূন্য (নীরব) স্যাম্পল, ব্যাপারটা কী? আসলে এগুলো এনকোডিংয়ের সময় সৃষ্ট কম্প্রেশন আর্টিফ্যাক্টের কারণে হয়। প্রায় প্রতিটি এনকোডারই কোনো না কোনো ধরনের প্যাডিং যোগ করে। এই ক্ষেত্রে LAME ফাইলটির শেষে ঠিক ৫৭৬টি প্যাডিং স্যাম্পল যোগ করেছে।
ফাইলের শেষের প্যাডিং ছাড়াও, প্রতিটি ফাইলের শুরুতেও প্যাডিং যোগ করা হয়েছিল। যদি আমরা sintel_1.mp3 ট্র্যাকটি একটু দেখি, তাহলে দেখতে পাব যে এর শুরুতে আরও ৫৭৬টি স্যাম্পলের প্যাডিং রয়েছে। প্যাডিংয়ের পরিমাণ এনকোডার এবং কন্টেন্ট অনুযায়ী ভিন্ন হয়, কিন্তু প্রতিটি ফাইলের সাথে থাকা metadata উপর ভিত্তি করে আমরা এর সঠিক মান জানতে পারি।
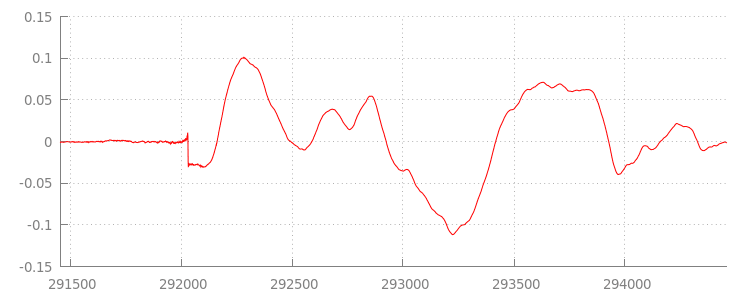
প্রতিটি ফাইলের শুরুতে এবং শেষে থাকা নীরব অংশগুলোই আগের ডেমোতে সেগমেন্টগুলোর মধ্যে ত্রুটির কারণ। গ্যাপহীন প্লেব্যাক পেতে, আমাদের এই নীরব অংশগুলো অপসারণ করতে হবে। সৌভাগ্যবশত, MediaSource ব্যবহার করে এটি সহজেই করা যায়। নিচে, আমরা এই নীরব অংশটি অপসারণ করার জন্য একটি অ্যাপেন্ড উইন্ডো এবং একটি টাইমস্ট্যাম্প অফসেট ব্যবহার করতে আমাদের onAudioLoaded() মেথডটি পরিবর্তন করব।
উদাহরণ কোড
function onAudioLoaded(data, index) {
// Parsing gapless metadata is unfortunately non trivial and a bit messy, so
// we'll glaze over it here; see the appendix for details.
// ParseGaplessData() will return a dictionary with two elements:
//
// audioDuration: Duration in seconds of all non-padding audio.
// frontPaddingDuration: Duration in seconds of the front padding.
//
var gaplessMetadata = ParseGaplessData(data);
// Each appended segment must be appended relative to the next. To avoid any
// overlaps, we'll use the end timestamp of the last append as the starting
// point for our next append or zero if we haven't appended anything yet.
var appendTime = index > 0 ? sourceBuffer.buffered.end(0) : 0;
// Simply put, an append window allows you to trim off audio (or video) frames
// which fall outside of a specified time range. Here, we'll use the end of
// our last append as the start of our append window and the end of the real
// audio data for this segment as the end of our append window.
sourceBuffer.appendWindowStart = appendTime;
sourceBuffer.appendWindowEnd = appendTime + gaplessMetadata.audioDuration;
// The timestampOffset field essentially tells MediaSource where in the media
// timeline the data given to appendBuffer() should be placed. I.e., if the
// timestampOffset is 1 second, the appended data will start 1 second into
// playback.
//
// MediaSource requires that the media timeline starts from time zero, so we
// need to ensure that the data left after filtering by the append window
// starts at time zero. We'll do this by shifting all of the padding we want
// to discard before our append time (and thus, before our append window).
sourceBuffer.timestampOffset =
appendTime - gaplessMetadata.frontPaddingDuration;
// When appendBuffer() completes, it will fire an updateend event signaling
// that it's okay to append another segment of media. Here, we'll chain the
// append for the next segment to the completion of our current append.
if (index == 0) {
sourceBuffer.addEventListener('updateend', function () {
if (++index < SEGMENTS) {
GET('sintel/sintel_' + index + '.mp3', function (data) {
onAudioLoaded(data, index);
});
} else {
// We've loaded all available segments, so tell MediaSource there are no
// more buffers which will be appended.
mediaSource.endOfStream();
URL.revokeObjectURL(audio.src);
}
});
}
// appendBuffer() will now use the timestamp offset and append window settings
// to filter and timestamp the data we're appending.
//
// Note: While this demo uses very little memory, more complex use cases need
// to be careful about memory usage or garbage collection may remove ranges of
// media in unexpected places.
sourceBuffer.appendBuffer(data);
}
একটি নির্বিঘ্ন তরঙ্গরূপ
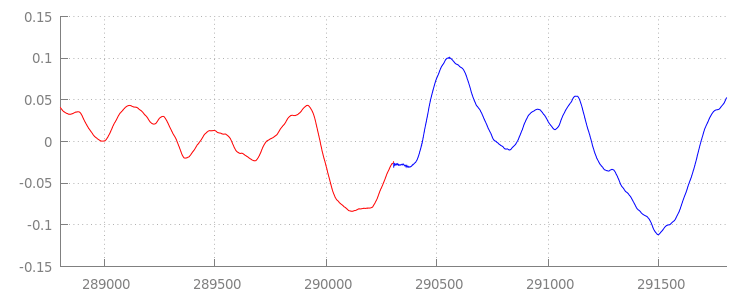
চলুন, আমাদের অ্যাপেন্ড উইন্ডোগুলো প্রয়োগ করার পর ওয়েভফর্মটি আরেকবার দেখে নেওয়া যাক, আমাদের নতুন কোডটি কী করেছে। নিচে, আপনি দেখতে পাচ্ছেন যে sintel_0.mp3 এর শেষের নীরব অংশটি (লাল রঙে) এবং sintel_1.mp3 এর শুরুর নীরব অংশটি (নীল রঙে) সরিয়ে ফেলা হয়েছে; ফলে সেগমেন্টগুলোর মধ্যে একটি নির্বিঘ্ন রূপান্তর তৈরি হয়েছে।
উপসংহার
এর মাধ্যমে, আমরা পাঁচটি অংশকে নির্বিঘ্নে একটিতে সংযুক্ত করেছি এবং ফলস্বরূপ আমাদের ডেমোর শেষ প্রান্তে পৌঁছেছি। যাওয়ার আগে, আপনারা হয়তো লক্ষ্য করেছেন যে আমাদের onAudioLoaded() মেথডটি কন্টেইনার বা কোডেক বিবেচনা করে না। এর মানে হলো, এই সমস্ত কৌশল কন্টেইনার বা কোডেকের ধরন নির্বিশেষে কাজ করবে। নিচে আপনারা MP3-এর পরিবর্তে মূল ডেমোটি DASH-রেডি খণ্ডিত MP4 ফরম্যাটে পুনরায় চালাতে পারেন।
আপনি যদি আরও জানতে চান, তাহলে গ্যাপলেস কন্টেন্ট তৈরি এবং মেটাডেটা পার্সিং সম্পর্কে বিস্তারিত জানতে নিচের পরিশিষ্টগুলো দেখুন। এই ডেমোটির পেছনের কোডটি আরও ভালোভাবে দেখার জন্য আপনি gapless.js ও দেখতে পারেন।
পড়ার জন্য ধন্যবাদ!
পরিশিষ্ট ক: ফাঁকহীন বিষয়বস্তু তৈরি করা
গ্যাপলেস কন্টেন্ট নিখুঁতভাবে তৈরি করা কঠিন হতে পারে। নিচে আমরা এই ডেমোতে ব্যবহৃত সিনটেল মিডিয়া তৈরির প্রক্রিয়াটি ধাপে ধাপে দেখাবো। শুরু করার জন্য আপনার সিনটেলের লসলেস FLAC সাউন্ডট্র্যাকের একটি কপি প্রয়োজন হবে; ভবিষ্যতের জন্য এর SHA1 ফাইলটি নিচে দেওয়া হলো। টুলস হিসেবে আপনার FFmpeg , MP4Box , LAME এবং afconvert সহ একটি OSX ইনস্টলেশন প্রয়োজন হবে।
unzip Jan_Morgenstern-Sintel-FLAC.zip
sha1sum 1-Snow_Fight.flac
# 0535ca207ccba70d538f7324916a3f1a3d550194 1-Snow_Fight.flac
প্রথমে, আমরা 1-Snow_Fight.flac ট্র্যাকটির প্রথম ৩১.৫ সেকেন্ড আলাদা করে নেব। এছাড়াও, প্লেব্যাক শেষ হওয়ার পর কোনো ক্লিক শব্দ এড়ানোর জন্য আমরা ২৮ সেকেন্ড থেকে একটি ২.৫ সেকেন্ডের ফেড-আউট যোগ করতে চাই। নিচের FFmpeg কমান্ড লাইনটি ব্যবহার করে আমরা এই সবকিছু করতে পারি এবং ফলাফলগুলো sintel.flac ফাইলে রাখতে পারি।
ffmpeg -i 1-Snow_Fight.flac -t 31.5 -af "afade=t=out:st=28:d=2.5" sintel.flac
এরপর, আমরা ফাইলটিকে ৬.৫ সেকেন্ডের পাঁচটি ওয়েভ ফাইলে ভাগ করব; ওয়েভ ফরম্যাট ব্যবহার করা সবচেয়ে সহজ, কারণ প্রায় সব এনকোডারই এটি গ্রহণ করতে পারে। এক্ষেত্রেও, আমরা FFmpeg ব্যবহার করে কাজটি নিখুঁতভাবে করতে পারি, যার পরে আমরা পাব: sintel_0.wav , sintel_1.wav , sintel_2.wav , sintel_3.wav , এবং sintel_4.wav ।
ffmpeg -i sintel.flac -acodec pcm_f32le -map 0 -f segment \
-segment_list out.list -segment_time 6.5 sintel_%d.wav
এরপর, চলুন MP3 ফাইলগুলো তৈরি করা যাক। গ্যাপলেস কন্টেন্ট তৈরির জন্য LAME-তে বেশ কিছু অপশন রয়েছে। যদি কন্টেন্টের নিয়ন্ত্রণ আপনার হাতে থাকে, তবে সেগমেন্টগুলোর মাঝের প্যাডিং পুরোপুরি এড়ানোর জন্য আপনি সব ফাইল ব্যাচ এনকোডিং করার সময় --nogap ব্যবহার করার কথা ভাবতে পারেন। তবে এই ডেমোর জন্য আমাদের ওই প্যাডিংটি প্রয়োজন, তাই আমরা ওয়েভ ফাইলগুলোর একটি সাধারণ উচ্চ মানের VBR এনকোডিং ব্যবহার করব।
lame -V=2 sintel_0.wav sintel_0.mp3
lame -V=2 sintel_1.wav sintel_1.mp3
lame -V=2 sintel_2.wav sintel_2.mp3
lame -V=2 sintel_3.wav sintel_3.mp3
lame -V=2 sintel_4.wav sintel_4.mp3
MP3 ফাইলগুলো তৈরি করার জন্য এটুকুই যথেষ্ট। এবার আমরা খণ্ডিত MP4 ফাইলগুলো তৈরির বিষয়টি দেখব। আমরা iTunes-এর জন্য মাস্টার করা মিডিয়া তৈরির ক্ষেত্রে Apple-এর নির্দেশনা অনুসরণ করব। নিচে, আমরা নির্দেশনা অনুযায়ী ওয়েভ ফাইলগুলোকে মধ্যবর্তী CAF ফাইলে রূপান্তর করব এবং এরপর প্রস্তাবিত প্যারামিটার ব্যবহার করে সেগুলোকে একটি MP4 কন্টেইনারে AAC হিসেবে এনকোড করব।
afconvert sintel_0.wav sintel_0_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_1.wav sintel_1_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_2.wav sintel_2_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_3.wav sintel_3_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_4.wav sintel_4_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_0_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_0.m4a
afconvert sintel_1_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_1.m4a
afconvert sintel_2_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_2.m4a
afconvert sintel_3_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_3.m4a
afconvert sintel_4_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_4.m4a
এখন আমাদের কাছে বেশ কয়েকটি M4A ফাইল আছে, যেগুলোকে MediaSource সাথে ব্যবহার করার আগে যথাযথভাবে খণ্ডিত করতে হবে। আমাদের কাজের জন্য, আমরা এক সেকেন্ডের একটি খণ্ড আকার ব্যবহার করব। MP4Box প্রতিটি খণ্ডিত MP4 ফাইলকে sintel_#_dashinit.mp4 নামে লিখে দেবে এবং এর সাথে একটি MPEG-DASH ম্যানিফেস্ট ( sintel_#_dash.mpd ) তৈরি করবে, যা বাতিল করা যেতে পারে।
MP4Box -dash 1000 sintel_0.m4a && mv sintel_0_dashinit.mp4 sintel_0.mp4
MP4Box -dash 1000 sintel_1.m4a && mv sintel_1_dashinit.mp4 sintel_1.mp4
MP4Box -dash 1000 sintel_2.m4a && mv sintel_2_dashinit.mp4 sintel_2.mp4
MP4Box -dash 1000 sintel_3.m4a && mv sintel_3_dashinit.mp4 sintel_3.mp4
MP4Box -dash 1000 sintel_4.m4a && mv sintel_4_dashinit.mp4 sintel_4.mp4
rm sintel_{0,1,2,3,4}_dash.mpd
ব্যাস! এখন আমাদের কাছে গ্যাপলেস প্লেব্যাকের জন্য প্রয়োজনীয় সঠিক মেটাডেটা সহ খণ্ডিত MP4 এবং MP3 ফাইল রয়েছে। সেই মেটাডেটা দেখতে ঠিক কেমন, সে সম্পর্কে আরও বিস্তারিত জানতে পরিশিষ্ট খ দেখুন।
পরিশিষ্ট খ: ফাঁকহীন মেটাডেটা পার্সিং
গ্যাপলেস কন্টেন্ট তৈরির মতোই, গ্যাপলেস মেটাডেটা পার্স করাও বেশ জটিল হতে পারে, কারণ এটি সংরক্ষণের কোনো প্রমিত পদ্ধতি নেই। নিচে আমরা আলোচনা করব, সবচেয়ে প্রচলিত দুটি এনকোডার, LAME এবং iTunes, কীভাবে তাদের গ্যাপলেস মেটাডেটা সংরক্ষণ করে। চলুন, উপরে ব্যবহৃত ParseGaplessData() ফাংশনটির জন্য কিছু সহায়ক মেথড এবং একটি রূপরেখা তৈরি করার মাধ্যমে শুরু করা যাক।
// Since most MP3 encoders store the gapless metadata in binary, we'll need a
// method for turning bytes into integers. Note: This doesn't work for values
// larger than 2^30 since we'll overflow the signed integer type when shifting.
function ReadInt(buffer) {
var result = buffer.charCodeAt(0);
for (var i = 1; i < buffer.length; ++i) {
result <<= 8;
result += buffer.charCodeAt(i);
}
return result;
}
function ParseGaplessData(arrayBuffer) {
// Gapless data is generally within the first 512 bytes, so limit parsing.
var byteStr = new TextDecoder().decode(arrayBuffer.slice(0, 512));
var frontPadding = 0, endPadding = 0, realSamples = 0;
// ... we'll fill this in as we go below.
আমরা প্রথমে অ্যাপলের আইটিউনস মেটাডেটা ফরম্যাট নিয়ে আলোচনা করব, কারণ এটি বোঝা ও ব্যাখ্যা করা সবচেয়ে সহজ। MP3 এবং M4A ফাইলের মধ্যে আইটিউনস (এবং afconvert) এইভাবে ASCII-তে একটি ছোট অংশ লেখে:
iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00
এটি MP3 কন্টেইনারের মধ্যে একটি ID3 ট্যাগের ভেতরে এবং MP4 কন্টেইনারের মধ্যে একটি মেটাডেটা অ্যাটমের ভেতরে লেখা থাকে। আমাদের কাজের সুবিধার জন্য, আমরা প্রথম 0000000 টোকেনটি উপেক্ষা করতে পারি। পরবর্তী তিনটি টোকেন হলো ফ্রন্ট প্যাডিং, এন্ড প্যাডিং এবং মোট নন-প্যাডিং স্যাম্পল সংখ্যা। এগুলোর প্রত্যেকটিকে অডিওর স্যাম্পল রেট দিয়ে ভাগ করলে আমরা প্রতিটির সময়কাল পেয়ে যাই।
// iTunes encodes the gapless data as hex strings like so:
//
// 'iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00'
// 'iTunSMPB[ 26 bytes ]####### frontpad endpad real samples'
//
// The approach here elides the complexity of actually parsing MP4 atoms. It
// may not work for all files without some tweaks.
var iTunesDataIndex = byteStr.indexOf('iTunSMPB');
if (iTunesDataIndex != -1) {
var frontPaddingIndex = iTunesDataIndex + 34;
frontPadding = parseInt(byteStr.substr(frontPaddingIndex, 8), 16);
var endPaddingIndex = frontPaddingIndex + 9;
endPadding = parseInt(byteStr.substr(endPaddingIndex, 8), 16);
var sampleCountIndex = endPaddingIndex + 9;
realSamples = parseInt(byteStr.substr(sampleCountIndex, 16), 16);
}
অন্যদিকে, বেশিরভাগ ওপেন সোর্স MP3 এনকোডার একটি বিশেষ Xing হেডারের মধ্যে গ্যাপলেস মেটাডেটা সংরক্ষণ করে, যা একটি সাইলেন্ট MPEG ফ্রেমের ভিতরে রাখা হয় (এটি সাইলেন্ট থাকে যাতে যে ডিকোডারগুলো Xing হেডার বোঝে না, তারা কেবল নীরবতা বাজায়)। দুর্ভাগ্যবশত, এই ট্যাগটি সবসময় উপস্থিত থাকে না এবং এতে বেশ কিছু ঐচ্ছিক ফিল্ড থাকে। এই ডেমোর জন্য, মিডিয়ার উপর আমাদের নিয়ন্ত্রণ আছে, কিন্তু বাস্তবে গ্যাপলেস মেটাডেটা কখন আসলেই পাওয়া যাবে তা জানার জন্য কিছু অতিরিক্ত যৌক্তিকতা যাচাইয়ের প্রয়োজন হবে।
প্রথমে আমরা মোট স্যাম্পল সংখ্যাটি বের করব। কাজটি সহজ করার জন্য আমরা এটি Xing হেডার থেকে নেব, কিন্তু এটি সাধারণ MPEG অডিও হেডার থেকেও তৈরি করা যেতে পারে। Xing হেডারকে Xing অথবা Info ট্যাগ দ্বারা চিহ্নিত করা যায়। এই ট্যাগের ঠিক ৪ বাইট পরে ৩২-বিটের একটি ডেটা থাকে, যা ফাইলটির মোট ফ্রেম সংখ্যা নির্দেশ করে; এই মানটিকে প্রতি ফ্রেমের স্যাম্পল সংখ্যা দিয়ে গুণ করলে আমরা ফাইলটির মোট স্যাম্পল সংখ্যা পেয়ে যাব।
// Xing padding is encoded as 24bits within the header. Note: This code will
// only work for Layer3 Version 1 and Layer2 MP3 files with XING frame counts
// and gapless information. See the following document for more details:
// http://www.codeproject.com/Articles/8295/MPEG-Audio-Frame-Header
var xingDataIndex = byteStr.indexOf('Xing');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Info');
if (xingDataIndex != -1) {
// See section 2.3.1 in the link above for the specifics on parsing the Xing
// frame count.
var frameCountIndex = xingDataIndex + 8;
var frameCount = ReadInt(byteStr.substr(frameCountIndex, 4));
// For Layer3 Version 1 and Layer2 there are 1152 samples per frame. See
// section 2.1.5 in the link above for more details.
var paddedSamples = frameCount * 1152;
// ... we'll cover this below.
এখন যেহেতু আমাদের কাছে মোট স্যাম্পলের সংখ্যা আছে, আমরা প্যাডিং স্যাম্পলের সংখ্যা পড়ার দিকে এগোতে পারি। আপনার এনকোডারের উপর নির্ভর করে, এটি Xing হেডারের মধ্যে থাকা একটি LAME বা Lavf ট্যাগের অধীনে লেখা থাকতে পারে। এই হেডারের ঠিক ১৭ বাইট পরে ৩ বাইট থাকে, যা যথাক্রমে ১২-বিটের ফ্রন্ট এবং এন্ড প্যাডিংকে নির্দেশ করে।
xingDataIndex = byteStr.indexOf('LAME');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Lavf');
if (xingDataIndex != -1) {
// See http://gabriel.mp3-tech.org/mp3infotag.html#delays for details of
// how this information is encoded and parsed.
var gaplessDataIndex = xingDataIndex + 21;
var gaplessBits = ReadInt(byteStr.substr(gaplessDataIndex, 3));
// Upper 12 bits are the front padding, lower are the end padding.
frontPadding = gaplessBits >> 12;
endPadding = gaplessBits & 0xFFF;
}
realSamples = paddedSamples - (frontPadding + endPadding);
}
return {
audioDuration: realSamples * SECONDS_PER_SAMPLE,
frontPaddingDuration: frontPadding * SECONDS_PER_SAMPLE
};
}
এর মাধ্যমে আমরা বেশিরভাগ ফাঁকহীন কন্টেন্ট পার্স করার জন্য একটি সম্পূর্ণ ফাংশন পেয়েছি। তবে, ব্যতিক্রমী পরিস্থিতি (edge cases) অবশ্যই প্রচুর রয়েছে, তাই প্রোডাকশনে অনুরূপ কোড ব্যবহার করার আগে সতর্কতা অবলম্বন করার পরামর্শ দেওয়া হচ্ছে।
পরিশিষ্ট গ: আবর্জনা সংগ্রহ প্রসঙ্গে
কন্টেন্ট টাইপ, প্ল্যাটফর্ম-নির্দিষ্ট সীমা এবং বর্তমান প্লে পজিশন অনুযায়ী SourceBuffer ইনস্ট্যান্সগুলোর মেমরি সক্রিয়ভাবে গার্বেজ কালেক্ট করা হয়। ক্রোমে, প্রথমে ইতিমধ্যে প্লে হওয়া বাফারগুলো থেকে মেমরি পুনরুদ্ধার করা হবে। তবে, যদি মেমরির ব্যবহার প্ল্যাটফর্ম-নির্দিষ্ট সীমা অতিক্রম করে, তাহলে এটি প্লে না হওয়া বাফারগুলো থেকে মেমরি সরিয়ে ফেলবে।
মেমরি পুনরুদ্ধারের কারণে প্লেব্যাক যখন টাইমলাইনের কোনো ফাঁকা জায়গায় পৌঁছায়, তখন সেই ফাঁকা স্থানটি খুব ছোট হলে প্লেব্যাকে ত্রুটি দেখা দিতে পারে, অথবা খুব বড় হলে এটি পুরোপুরি থেমে যেতে পারে। এই দুটি অভিজ্ঞতার কোনোটিই ব্যবহারকারীর জন্য সুখকর নয়, তাই একবারে খুব বেশি ডেটা যুক্ত করা এড়িয়ে চলা এবং মিডিয়া টাইমলাইন থেকে অপ্রয়োজনীয় অংশগুলো ম্যানুয়ালি মুছে ফেলা গুরুত্বপূর্ণ।
প্রতিটি SourceBuffer এর remove() মেথডের মাধ্যমে রেঞ্জ মুছে ফেলা যায়; এটি সেকেন্ডে একটি [start, end] রেঞ্জ গ্রহণ করে। appendBuffer() এর মতোই, প্রতিটি remove() সম্পন্ন হলে একটি updateend ইভেন্ট ফায়ার করবে। এই ইভেন্টটি ফায়ার না হওয়া পর্যন্ত অন্য কোনো remove বা append অপারেশন চালানো উচিত নয়।
ডেস্কটপ ক্রোমে, আপনি একবারে মেমোরিতে প্রায় ১২ মেগাবাইট অডিও কন্টেন্ট এবং ১৫০ মেগাবাইট ভিডিও কন্টেন্ট রাখতে পারেন। বিভিন্ন ব্রাউজার বা প্ল্যাটফর্মে এই মানগুলোর উপর নির্ভর করা উচিত নয়; যেমন, এগুলো মোবাইল ডিভাইসের ক্ষেত্রে একেবারেই প্রযোজ্য নয়।
গার্বেজ কালেকশন শুধুমাত্র SourceBuffers এ যোগ করা ডেটার উপর প্রভাব ফেলে; জাভাস্ক্রিপ্ট ভেরিয়েবলে আপনি কী পরিমাণ ডেটা বাফার করে রাখতে পারবেন তার কোনো সীমা নেই। প্রয়োজনে আপনি একই ডেটা একই অবস্থানে পুনরায় যুক্তও করতে পারেন।