
마지막 모듈에서는 웹 워커 개요를 살펴보았습니다. 웹 워커는 JavaScript를 기본 스레드에서 별도의 웹 워커 스레드로 이동하여 입력 응답성을 개선할 수 있습니다. 이렇게 하면 기본 스레드에 직접 액세스할 필요가 없는 작업이 있을 때 웹사이트의 다음 페인트까지의 상호작용 (INP)을 개선할 수 있습니다. 하지만 개요만으로는 충분하지 않으며 이 모듈에서는 웹 워커의 구체적인 사용 사례를 제공합니다.
이러한 사용 사례 중 하나는 이미지에서 Exif 메타데이터를 삭제해야 하는 웹사이트일 수 있습니다. 이는 결코 터무니없는 개념이 아닙니다. 실제로 Flickr와 같은 웹사이트에서는 사용자가 Exif 메타데이터를 볼 수 있는 방법을 제공하여 색상 심도, 카메라 제조사 및 모델, 기타 데이터와 같은 호스팅 이미지에 관한 기술 세부정보를 확인할 수 있습니다.
하지만 이미지를 가져오고 ArrayBuffer로 변환하고 Exif 메타데이터를 추출하는 로직을 기본 스레드에서 완전히 실행하면 비용이 많이 들 수 있습니다. 다행히 웹 워커 범위에서는 기본 스레드 외부에서 이 작업을 실행할 수 있습니다. 그런 다음 웹 워커의 메시지 파이프라인을 사용하여 Exif 메타데이터가 HTML 문자열로 기본 스레드에 다시 전송되고 사용자에게 표시됩니다.
웹 워커가 없는 경우 기본 스레드의 모습
먼저 웹 워커 없이 이 작업을 실행할 때 기본 스레드가 어떤 모습인지 관찰합니다. 이렇게 하려면 다음 단계를 따르세요.
- Chrome에서 새 탭을 열고 DevTools를 엽니다.
- 성능 패널을 엽니다.
- https://chrome.dev/learn-performance-exif-worker/without-worker.html로 이동합니다.
- 성능 패널에서 DevTools 창의 오른쪽 상단에 있는 기록을 클릭합니다.
- 필드에 이 이미지 링크(또는 Exif 메타데이터가 포함된 다른 링크)를 붙여넣고 JPEG 가져오기 버튼을 클릭합니다.
- 인터페이스에 Exif 메타데이터가 채워지면 녹화를 다시 클릭하여 녹화를 중지합니다.
{kind=link}
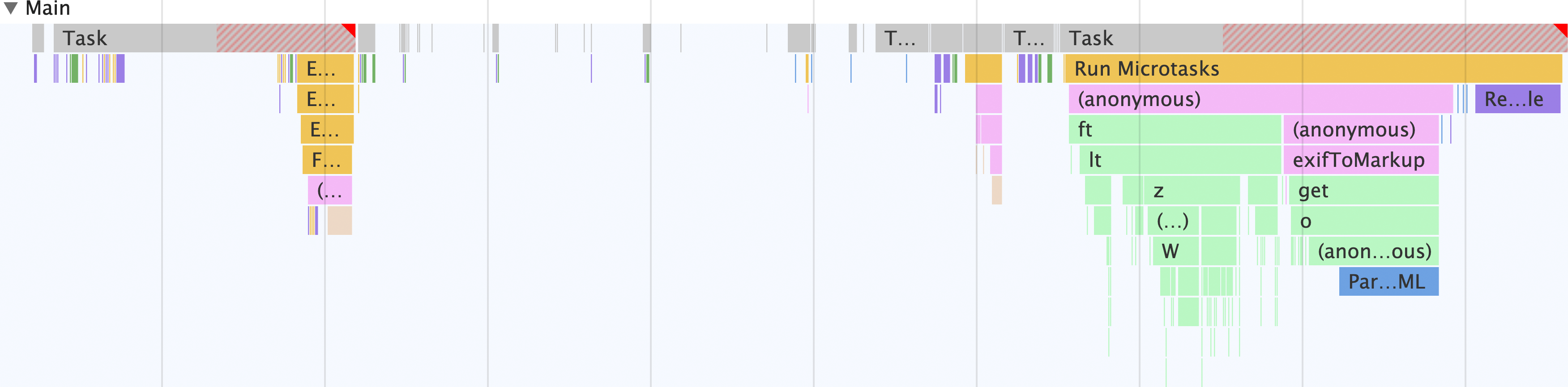
래스터라이저 스레드 등 있을 수 있는 다른 스레드를 제외하고 앱의 모든 것은 기본 스레드에서 발생합니다. 기본 스레드에서는 다음이 발생합니다.
- 이 양식은 입력을 가져와 Exif 메타데이터가 포함된 이미지의 초기 부분을 가져오기 위해
fetch요청을 디스패치합니다. - 이미지 데이터가
ArrayBuffer로 변환됩니다. exif-reader스크립트는 이미지에서 Exif 메타데이터를 추출하는 데 사용됩니다.- 메타데이터는 스크랩되어 HTML 문자열을 구성한 후 메타데이터 뷰어를 채웁니다.
이제 동일한 동작을 구현하지만 웹 워커를 사용하는 경우와 비교해 보겠습니다.
웹 작업자가 있는 경우 기본 스레드의 모습
이제 기본 스레드에서 JPEG 파일의 Exif 메타데이터를 추출하는 방법을 확인했으니 웹 워커가 포함된 경우를 살펴보겠습니다.
- Chrome에서 다른 탭을 열고 DevTools를 엽니다.
- 성능 패널을 엽니다.
- https://chrome.dev/learn-performance-exif-worker/with-worker.html로 이동합니다.
- 성능 패널에서 DevTools 창의 오른쪽 상단에 있는 녹화 버튼을 클릭합니다.
- 필드에 이 이미지 링크를 붙여넣고 JPEG 가져오기 버튼을 클릭합니다.
- 인터페이스에 Exif 메타데이터가 채워지면 녹화 버튼을 다시 클릭하여 녹화를 중지합니다.
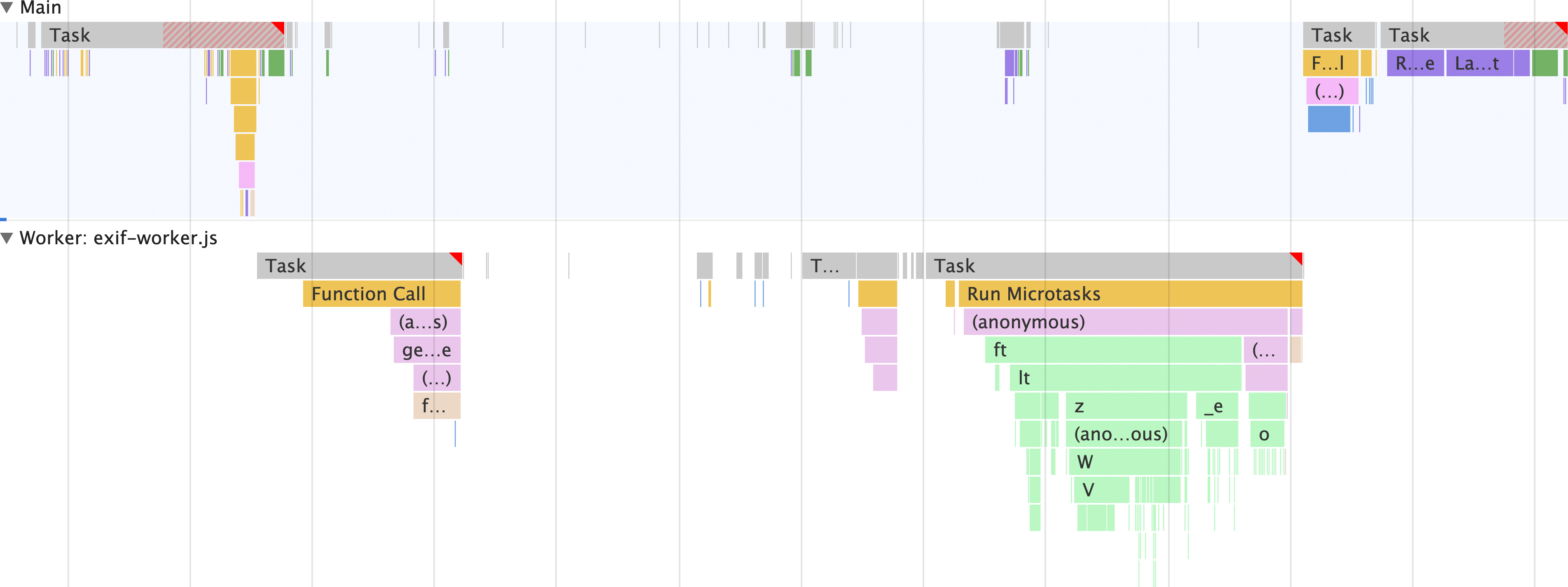
이것이 웹 워커의 힘입니다. 기본 스레드에서 모든 작업을 실행하는 대신 HTML로 메타데이터 뷰어를 채우는 작업을 제외한 모든 작업이 별도의 스레드에서 실행됩니다. 즉, 기본 스레드가 다른 작업을 할 수 있도록 해제됩니다.
여기서 가장 큰 장점은 웹 워커를 사용하지 않는 이 앱 버전과 달리 exif-reader 스크립트가 기본 스레드에 로드되지 않고 웹 워커 스레드에 로드된다는 점입니다. 즉, exif-reader 스크립트를 다운로드, 파싱, 컴파일하는 비용이 기본 스레드에서 발생합니다.
이제 이 모든 것을 가능하게 하는 웹 작업자 코드를 살펴보겠습니다.
웹 워커 코드 살펴보기
웹 워커가 만드는 차이점을 확인하는 것만으로는 충분하지 않습니다. 이 경우 웹 워커 범위에서 무엇이 가능한지 알 수 있도록 해당 코드가 어떻게 표시되는지 이해하는 것도 도움이 됩니다.
웹 워커가 그림에 들어가기 전에 발생해야 하는 기본 스레드 코드로 시작합니다.
// scripts.js
// Register the Exif reader web worker:
const exifWorker = new Worker('/js/with-worker/exif-worker.js');
// We have to send image requests through this proxy due to CORS limitations:
const imageFetchPrefix = 'https://res.cloudinary.com/demo/image/fetch/';
// Necessary elements we need to select:
const imageFetchPanel = document.getElementById('image-fetch');
const imageExifDataPanel = document.getElementById('image-exif-data');
const exifDataPanel = document.getElementById('exif-data');
const imageInput = document.getElementById('image-url');
// What to do when the form is submitted.
document.getElementById('image-form').addEventListener('submit', event => {
// Don't let the form submit by default:
event.preventDefault();
// Send the image URL to the web worker on submit:
exifWorker.postMessage(`${imageFetchPrefix}${imageInput.value}`);
});
// This listens for the Exif metadata to come back from the web worker:
exifWorker.addEventListener('message', ({ data }) => {
// This populates the Exif metadata viewer:
exifDataPanel.innerHTML = data.message;
imageFetchPanel.style.display = 'none';
imageExifDataPanel.style.display = 'block';
});
이 코드는 기본 스레드에서 실행되며 이미지 URL을 웹 워커로 전송하는 양식을 설정합니다. 여기서 웹 워커 코드는 외부 exif-reader 스크립트를 로드하는 importScripts 문으로 시작한 다음 기본 스레드에 메시지 파이프라인을 설정합니다.
// exif-worker.js
// Import the exif-reader script:
importScripts('/js/with-worker/exifreader.js');
// Set up a messaging pipeline to send the Exif data to the `window`:
self.addEventListener('message', ({ data }) => {
getExifDataFromImage(data).then(status => {
self.postMessage(status);
});
});
이 JavaScript 코드는 사용자가 JPEG 파일의 URL을 사용하여 양식을 제출할 때 URL이 웹 워커에 도착하도록 메시지 파이프라인을 설정합니다.
여기에서 다음 코드 비트는 JPEG 파일에서 Exif 메타데이터를 추출하고 HTML 문자열을 빌드하며 해당 HTML을 window에 다시 전송하여 최종적으로 사용자에게 표시합니다.
// Takes a blob to transform the image data into an `ArrayBuffer`:
// NOTE: these promises are simplified for readability, and don't include
// rejections on failures. Check out the complete web worker code:
// https://chrome.dev/learn-performance-exif-worker/js/with-worker/exif-worker.js
const readBlobAsArrayBuffer = blob => new Promise(resolve => {
const reader = new FileReader();
reader.onload = () => {
resolve(reader.result);
};
reader.readAsArrayBuffer(blob);
});
// Takes the Exif metadata and converts it to a markup string to
// display in the Exif metadata viewer in the DOM:
const exifToMarkup = exif => Object.entries(exif).map(([exifNode, exifData]) => {
return `
<details>
<summary>
<h2>${exifNode}</h2>
</summary>
<p>${exifNode === 'base64' ? `<img src="data:image/jpeg;base64,${exifData}">` : typeof exifData.value === 'undefined' ? exifData : exifData.description || exifData.value}</p>
</details>
`;
}).join('');
// Fetches a partial image and gets its Exif data
const getExifDataFromImage = imageUrl => new Promise(resolve => {
fetch(imageUrl, {
headers: {
// Use a range request to only download the first 64 KiB of an image.
// This ensures bandwidth isn't wasted by downloading what may be a huge
// JPEG file when all that's needed is the metadata.
'Range': `bytes=0-${2 ** 10 * 64}`
}
}).then(response => {
if (response.ok) {
return response.clone().blob();
}
}).then(responseBlob => {
readBlobAsArrayBuffer(responseBlob).then(arrayBuffer => {
const tags = ExifReader.load(arrayBuffer, {
expanded: true
});
resolve({
status: true,
message: Object.values(tags).map(tag => exifToMarkup(tag)).join('')
});
});
});
});
읽을 내용이 많지만 웹 작업자의 사용 사례도 상당히 복잡합니다.
하지만 결과는 노력의 가치가 있으며 이 사용 사례에만 국한되지 않습니다.
웹 워커는 fetch 호출을 격리하고 응답을 처리하거나, 메인 스레드를 차단하지 않고 대량의 데이터를 처리하는 등 다양한 용도로 사용할 수 있습니다.
웹 애플리케이션의 성능을 개선할 때는 웹 워커 컨텍스트에서 합리적으로 실행할 수 있는 모든 것을 고려하세요. 이러한 이점은 상당할 수 있으며 웹사이트의 전반적인 사용자 환경을 개선할 수 있습니다.