
이제 크리에이터는 강력한 API (예: IndexedDB 및 WebCodecs)와 성능 도구를 통해 Kapwing으로 웹에서 고품질 동영상 콘텐츠를 편집할 수 있습니다.

팬데믹이 시작된 이후 온라인 동영상 소비가 급격히 증가했습니다. 사람들은 TikTok, Instagram, YouTube와 같은 플랫폼에서 고화질 동영상을 무한으로 시청하는 데 더 많은 시간을 보내고 있습니다. 전 세계의 크리에이터와 중소기업 소유자는 동영상 콘텐츠를 만들기 위해 빠르고 사용하기 쉬운 도구가 필요합니다.
Kapwing과 같은 회사는 강력한 최신 API와 성능 도구를 사용하여 웹에서 바로 이러한 모든 동영상 콘텐츠를 만들 수 있도록 지원합니다.
Kapwing 정보
Kapwing은 게임 스트리머, 뮤지션, YouTube 크리에이터, 밈 제작자와 같은 아마추어 크리에이터를 위해 설계된 웹 기반 공동작업 동영상 편집기입니다. Facebook 및 Instagram 광고와 같은 자체 소셜 콘텐츠를 쉽게 제작할 방법이 필요한 비즈니스 소유자에게도 유용한 리소스입니다.
사람들은 '동영상 자르기 방법', '동영상에 음악 추가 방법', '동영상 크기 조절 방법'과 같은 특정 작업을 검색하여 Kapwing을 발견합니다. 앱 스토어로 이동하고 앱을 다운로드하는 번거로움 없이 클릭 한 번으로 검색한 작업을 할 수 있습니다. 웹을 사용하면 사용자가 도움을 필요로 하는 작업을 정확하게 검색한 후 간편하게 처리할 수 있습니다.
첫 클릭 후 Kapwing 사용자는 훨씬 더 많은 작업을 할 수 있습니다. 무료 템플릿을 살펴보고, 무료 스톡 동영상의 새로운 레이어를 추가하고, 자막을 삽입하고, 동영상 스크립트를 작성하고, 배경음악을 업로드할 수 있습니다.
Kapwing에서 웹에 실시간 편집 및 공동작업을 제공하는 방법
웹은 고유한 이점을 제공하지만 고유한 문제도 있습니다. Kapwing은 다양한 기기와 네트워크 조건에서 복잡한 다층 프로젝트를 원활하고 정확하게 재생해야 합니다. 이를 위해 다양한 웹 API를 사용하여 성능 및 기능 목표를 달성합니다.
IndexedDB
고성능 편집을 사용하려면 모든 사용자의 콘텐츠가 클라이언트에 있어야 하며 가능하면 네트워크를 사용하지 않아야 합니다. 사용자가 일반적으로 콘텐츠에 한 번만 액세스하는 스트리밍 서비스와 달리 YouTube 고객은 업로드 후 며칠 또는 몇 개월이 지나도 애셋을 자주 재사용합니다.
IndexedDB를 사용하면 사용자에게 영구 파일 시스템과 같은 저장소를 제공할 수 있습니다. 그 결과 앱의 미디어 요청 중 90% 이상이 로컬에서 처리됩니다. IndexedDB를 시스템에 통합하는 것은 매우 간단했습니다.
다음은 앱 로드 시 실행되는 몇 가지 볼러 텍 초기화 코드입니다.
import {DBSchema, openDB, deleteDB, IDBPDatabase} from 'idb';
let openIdb: Promise <IDBPDatabase<Schema>>;
const db =
(await openDB) <
Schema >
(
'kapwing',
version, {
upgrade(db, oldVersion) {
if (oldVersion >= 1) {
// assets store schema changed, need to recreate
db.deleteObjectStore('assets');
}
db.createObjectStore('assets', {
keyPath: 'mediaLibraryID'
});
},
async blocked() {
await deleteDB('kapwing');
},
async blocking() {
await deleteDB('kapwing');
},
}
);
버전을 전달하고 upgrade 함수를 정의합니다. 이는 초기화 또는 필요한 경우 스키마를 업데이트하는 데 사용됩니다. 불안정한 시스템을 사용하는 사용자의 문제를 방지하는 데 유용하다고 판단되는 오류 처리 콜백 blocked 및 blocking을 전달합니다.
마지막으로 기본 키 keyPath의 정의를 확인합니다. 여기서는 mediaLibraryID라고 하는 고유 ID입니다. 사용자가 업로더 또는 서드 파티 확장 프로그램을 통해 시스템에 미디어를 추가하면 다음 코드를 사용하여 미디어 라이브러리에 미디어를 추가합니다.
export async function addAsset(mediaLibraryID: string, file: File) {
return runWithAssetMutex(mediaLibraryID, async () => {
const assetAlreadyInStore = await (await openIdb).get(
'assets',
mediaLibraryID
);
if (assetAlreadyInStore) return;
const idbVideo: IdbVideo = {
file,
mediaLibraryID,
};
await (await openIdb).add('assets', idbVideo);
});
}
runWithAssetMutex는 IndexedDB 액세스를 직렬화하는 자체 내부 정의 함수입니다. IndexedDB API는 비동기식이므로 읽기-수정-쓰기 유형 작업에는 필요합니다.
이제 파일에 액세스하는 방법을 살펴보겠습니다. 다음은 getAsset 함수입니다.
export async function getAsset(
mediaLibraryID: string,
source: LayerSource | null | undefined,
location: string
): Promise<IdbAsset | undefined> {
let asset: IdbAsset | undefined;
const { idbCache } = window;
const assetInCache = idbCache[mediaLibraryID];
if (assetInCache && assetInCache.status === 'complete') {
asset = assetInCache.asset;
} else if (assetInCache && assetInCache.status === 'pending') {
asset = await new Promise((res) => {
assetInCache.subscribers.push(res);
});
} else {
idbCache[mediaLibraryID] = { subscribers: [], status: 'pending' };
asset = (await openIdb).get('assets', mediaLibraryID);
idbCache[mediaLibraryID].asset = asset;
idbCache[mediaLibraryID].subscribers.forEach((res: any) => {
res(asset);
});
delete (idbCache[mediaLibraryID] as any).subscribers;
if (asset) {
idbCache[mediaLibraryID].status = 'complete';
} else {
idbCache[mediaLibraryID].status = 'failed';
}
}
return asset;
}
IndexedDB 액세스를 최소화하는 데 사용되는 자체 데이터 구조인 idbCache가 있습니다. IndexedDB는 빠르지만 로컬 메모리에 액세스하는 것이 더 빠릅니다. 캐시 크기를 관리하는 한 이 접근 방식을 사용하는 것이 좋습니다.
IndexedDB에 동시에 액세스하는 것을 방지하는 데 사용되는 subscribers 배열은 로드 시 일반적입니다.
Web Audio API
오디오 시각화는 동영상 편집에 매우 중요합니다. 이유를 알아보려면 편집기의 스크린샷을 살펴보세요.
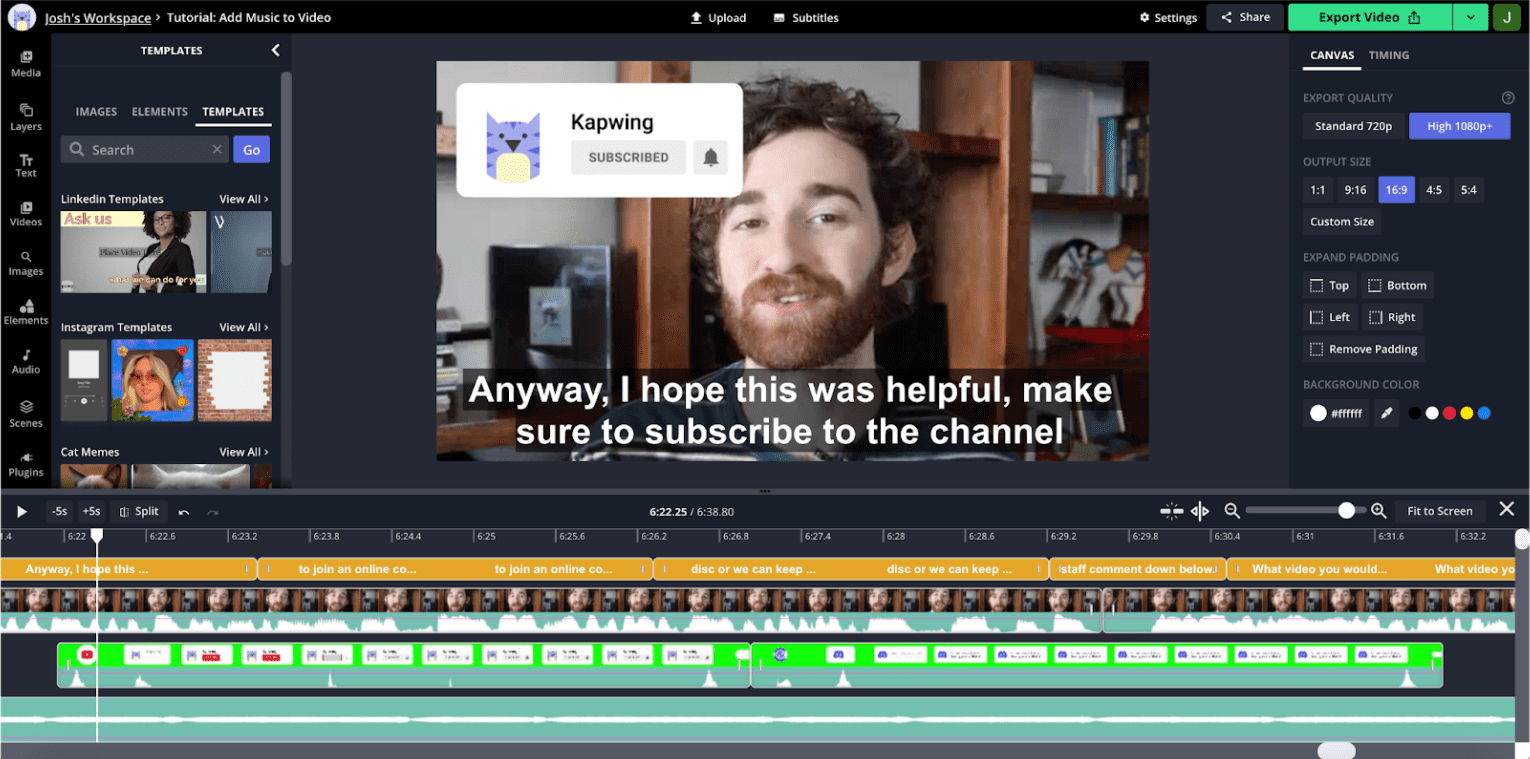
YouTube 스타일의 동영상으로, YouTube 앱에서 흔히 볼 수 있습니다. 사용자가 클립 전체에서 크게 움직이지 않으므로 타임라인 시각적 썸네일은 섹션 간에 이동하는 데 그다지 유용하지 않습니다. 반면 오디오 파형은 최대값과 최솟값을 보여주며, 최솟값은 일반적으로 녹음의 유휴 시간에 해당합니다. 타임라인을 확대하면 끊김 및 일시중지에 해당하는 골짜기가 있는 더 세분화된 오디오 정보가 표시됩니다.
사용자 연구에 따르면 크리에이터는 콘텐츠를 스플라이스할 때 이러한 웨이브폼을 참고하는 경우가 많습니다. 웹 오디오 API를 사용하면 이 정보를 성능이 우수하게 표시하고 타임라인을 확대/축소하거나 화면 이동할 때 빠르게 업데이트할 수 있습니다.
아래 스니펫은 이 작업을 수행하는 방법을 보여줍니다.
const getDownsampledBuffer = (idbAsset: IdbAsset) =>
decodeMutex.runExclusive(
async (): Promise<Float32Array> => {
const arrayBuffer = await idbAsset.file.arrayBuffer();
const audioContext = new AudioContext();
const audioBuffer = await audioContext.decodeAudioData(arrayBuffer);
const offline = new OfflineAudioContext(
audioBuffer.numberOfChannels,
audioBuffer.duration * MIN_BROWSER_SUPPORTED_SAMPLE_RATE,
MIN_BROWSER_SUPPORTED_SAMPLE_RATE
);
const downsampleSource = offline.createBufferSource();
downsampleSource.buffer = audioBuffer;
downsampleSource.start(0);
downsampleSource.connect(offline.destination);
const downsampledBuffer22K = await offline.startRendering();
const downsampledBuffer22KData = downsampledBuffer22K.getChannelData(0);
const downsampledBuffer = new Float32Array(
Math.floor(
downsampledBuffer22KData.length / POST_BROWSER_SAMPLE_INTERVAL
)
);
for (
let i = 0, j = 0;
i < downsampledBuffer22KData.length;
i += POST_BROWSER_SAMPLE_INTERVAL, j += 1
) {
let sum = 0;
for (let k = 0; k < POST_BROWSER_SAMPLE_INTERVAL; k += 1) {
sum += Math.abs(downsampledBuffer22KData[i + k]);
}
const avg = sum / POST_BROWSER_SAMPLE_INTERVAL;
downsampledBuffer[j] = avg;
}
return downsampledBuffer;
}
);
이 도우미에 IndexedDB에 저장된 애셋을 전달합니다. 완료되면 IndexedDB의 애셋과 자체 캐시가 업데이트됩니다.
AudioContext 생성자로 audioBuffer에 관한 데이터를 수집하지만 기기 하드웨어에 렌더링하지 않으므로 OfflineAudioContext를 사용하여 진폭 데이터를 저장할 ArrayBuffer에 렌더링합니다.
API 자체는 효과적인 시각화에 필요한 것보다 훨씬 높은 샘플링 레이트로 데이터를 반환합니다. 따라서 유용하고 시각적으로 매력적인 웨이브폼을 표시하기에 충분한 200Hz로 수동으로 다운샘플링합니다.
WebCodecs
특정 동영상의 경우 타임라인 탐색에 파형보다 트랙 썸네일이 더 유용합니다. 하지만 썸네일 생성은 웨이브폼 생성보다 리소스 집약적입니다.
로드 시 모든 가능한 썸네일을 캐시할 수는 없으므로 타임라인 화면 이동/확대/축소 시 빠른 디코딩은 성능이 우수하고 반응성이 뛰어난 애플리케이션에 매우 중요합니다. 원활한 프레임 그리기를 달성하는 데 걸림돌이 되는 것은 프레임 디코딩입니다. 최근까지는 HTML5 동영상 플레이어를 사용하여 디코딩했습니다. 이 접근 방식의 성능은 안정적이지 않았으며 프레임 렌더링 중에 앱 응답성이 저하되는 경우가 많았습니다.
최근에는 웹 워커에서 사용할 수 있는 WebCodecs로 전환했습니다. 이렇게 하면 메인 스레드 성능에 영향을 주지 않으면서 대량의 레이어의 썸네일을 그리는 기능이 향상됩니다. 웹 작업자 구현이 아직 진행 중이지만 아래에 기존 기본 스레드 구현의 개요를 제공합니다.
동영상 파일에는 동영상, 오디오, 자막 등 여러 스트림이 포함되어 있으며 이러한 스트림은 함께 'muxing'됩니다. WebCodecs를 사용하려면 먼저 디뮤싱된 동영상 스트림이 있어야 합니다. 다음과 같이 mp4box 라이브러리로 mp4를 디뮤싱합니다.
async function create(demuxer: any) {
demuxer.file = (await MP4Box).createFile();
demuxer.file.onReady = (info: any) => {
demuxer.info = info;
demuxer._info_resolver(info);
};
demuxer.loadMetadata();
}
const loadMetadata = async () => {
let offset = 0;
const asset = await getAsset(this.mediaLibraryId, null, this.url);
const maxFetchOffset = asset?.file.size || 0;
const end = offset + FETCH_SIZE;
const response = await fetch(this.url, {
headers: { range: `bytes=${offset}-${end}` },
});
const reader = response.body.getReader();
let done, value;
while (!done) {
({ done, value } = await reader.read());
if (done) {
this.file.flush();
break;
}
const buf: ArrayBufferLike & { fileStart?: number } = value.buffer;
buf.fileStart = offset;
offset = this.file.appendBuffer(buf);
}
};
이 스니펫은 MP4Box에 대한 인터페이스를 캡슐화하는 데 사용하는 demuxer 클래스를 참조합니다. IndexedDB에서 애셋에 다시 액세스합니다. 이러한 세그먼트는 반드시 바이트 순서로 저장되지 않으며 appendBuffer 메서드는 다음 청크의 오프셋을 반환합니다.
동영상 프레임을 디코딩하는 방법은 다음과 같습니다.
const getFrameFromVideoDecoder = async (demuxer: any): Promise<any> => {
let desiredSampleIndex = demuxer.getFrameIndexForTimestamp(this.frameTime);
let timestampToMatch: number;
let decodedSample: VideoFrame | null = null;
const outputCallback = (frame: VideoFrame) => {
if (frame.timestamp === timestampToMatch) decodedSample = frame;
else frame.close();
};
const decoder = new VideoDecoder({
output: outputCallback,
});
const {
codec,
codecWidth,
codecHeight,
description,
} = demuxer.getDecoderConfigurationInfo();
decoder.configure({ codec, codecWidth, codecHeight, description });
/* begin demuxer interface */
const preceedingKeyFrameIndex = demuxer.getPreceedingKeyFrameIndex(
desiredSampleIndex
);
const trak_id = demuxer.trak_id
const trak = demuxer.moov.traks.find((trak: any) => trak.tkhd.track_id === trak_id);
const data = await demuxer.getFrameDataRange(
preceedingKeyFrameIndex,
desiredSampleIndex
);
/* end demuxer interface */
for (let i = preceedingKeyFrameIndex; i <= desiredSampleIndex; i += 1) {
const sample = trak.samples[i];
const sampleData = data.readNBytes(
sample.offset,
sample.size
);
const sampleType = sample.is_sync ? 'key' : 'delta';
const encodedFrame = new EncodedVideoChunk({
sampleType,
timestamp: sample.cts,
duration: sample.duration,
samapleData,
});
if (i === desiredSampleIndex)
timestampToMatch = encodedFrame.timestamp;
decoder.decodeEncodedFrame(encodedFrame, i);
}
await decoder.flush();
return { type: 'value', value: decodedSample };
};
디뮤셔의 구조는 매우 복잡하며 이 도움말의 범위를 벗어납니다. 각 프레임을 samples라는 배열에 저장합니다. 디뮤셔를 사용하여 원하는 타임스탬프에 가장 근접한 이전 키 프레임을 찾습니다. 이 프레임에서 동영상 디코딩을 시작해야 합니다.
동영상은 키 프레임 또는 i-프레임이라고 하는 전체 프레임과 훨씬 더 작은 델타 프레임(p-프레임 또는 b-프레임이라고도 함)으로 구성됩니다. 디코딩은 항상 키 프레임에서 시작해야 합니다.
애플리케이션은 다음과 같이 프레임을 디코딩합니다.
- 프레임 출력 콜백으로 디코더 인스턴스화
- 특정 코덱 및 입력 해상도에 맞게 디코더를 구성합니다.
- 디뮤셔의 데이터를 사용하여
encodedVideoChunk를 만듭니다. decodeEncodedFrame메서드 호출
원하는 타임스탬프가 있는 프레임에 도달할 때까지 이 작업을 반복합니다.
다음 단계
프런트엔드에서 확장성은 프로젝트가 더 크고 복잡해질 때 정확하고 성능이 우수한 재생을 유지하는 기능으로 정의됩니다. 성능을 확장하는 한 가지 방법은 한 번에 최대한 적은 수의 동영상을 마운트하는 것이지만 이렇게 하면 전환이 느려지고 끊길 수 있습니다. 재사용을 위해 동영상 구성요소를 캐시하는 내부 시스템을 개발했지만 HTML5 동영상 태그가 제공할 수 있는 제어 수준에는 제한이 있습니다.
향후 WebCodecs를 사용하여 모든 미디어를 재생하려고 시도할 수 있습니다. 이를 통해 버퍼링할 데이터를 매우 정확하게 지정할 수 있으므로 성능을 확장하는 데 도움이 됩니다.
대규모 트랙패드 계산을 웹 워커로 오프로드하는 작업도 더 효과적으로 할 수 있으며, 파일 미리 가져오기 및 프레임 미리 생성 작업을 더 스마트하게 처리할 수 있습니다. 전반적인 애플리케이션 성능을 최적화하고 WebGL과 같은 도구로 기능을 확장할 수 있는 큰 기회가 있습니다.
현재 스마트 배경 삭제에 사용 중인 TensorFlow.js에 대한 투자를 계속할 계획입니다. Google은 객체 감지, 특징 추출, 스타일 전송과 같은 다른 정교한 작업에 TensorFlow.js를 활용할 계획입니다.
궁극적으로 Google은 무료 오픈 웹에서 네이티브와 유사한 성능과 기능으로 제품을 계속 빌드할 수 있게 되어 기쁩니다.