
Текстовые фрагменты позволяют указать текстовый фрагмент в URL-фрагменте. При переходе по URL-адресу с таким текстовым фрагментом браузер может подчеркнуть его и/или привлечь к нему внимание пользователя.

Идентификаторы фрагментов
Chrome 80 был большим релизом. Он содержал ряд долгожданных функций, таких как ECMAScript Modules in Web Workers , nullish coalescing , Optional chaining и многое другое. Релиз был, как обычно, анонсирован в сообщении в блоге Chromium. Вы можете увидеть отрывок сообщения в блоге на скриншоте ниже.
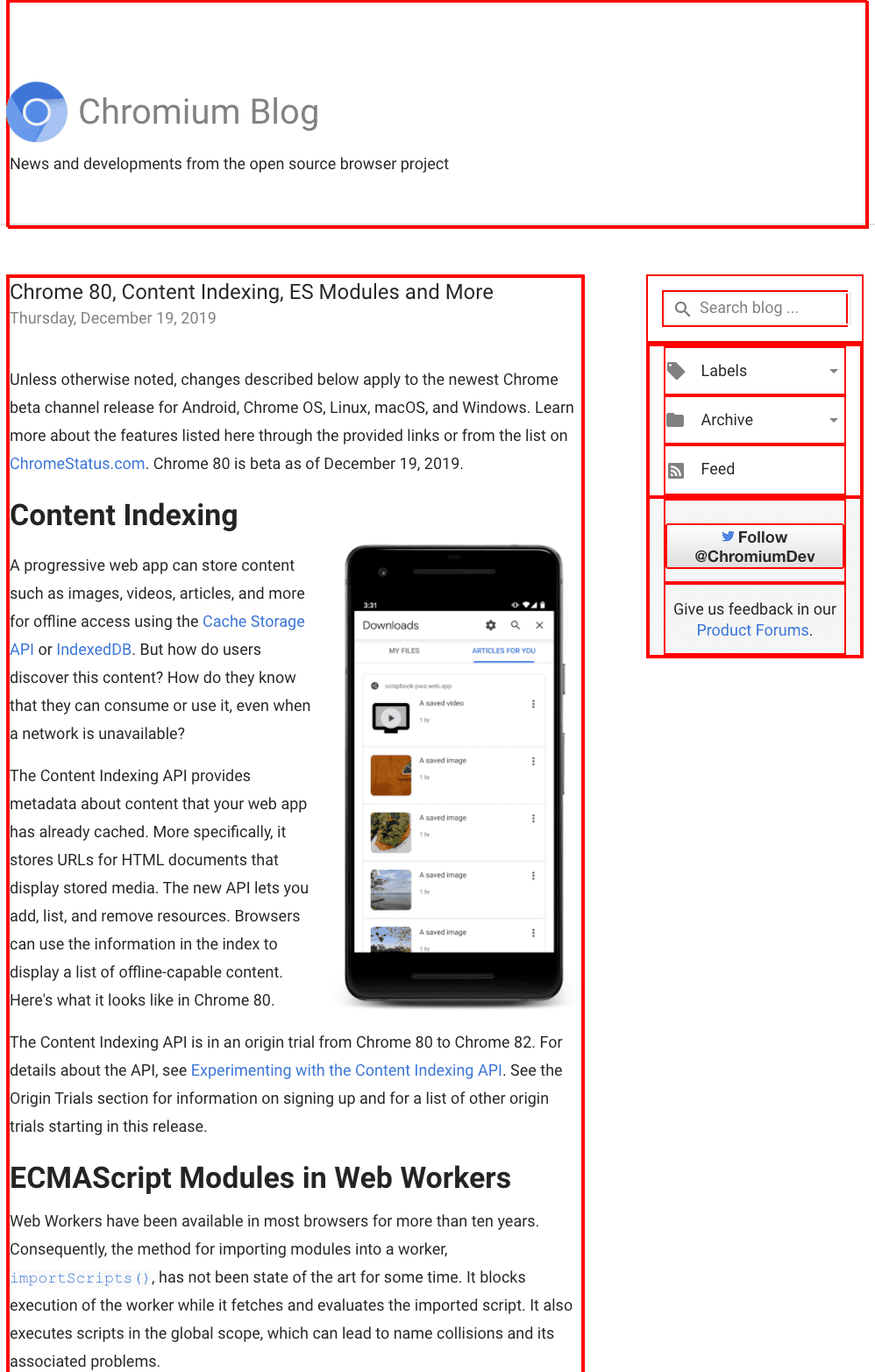
id . Вы, вероятно, спрашиваете себя, что означают все эти красные поля. Они являются результатом выполнения следующего фрагмента в DevTools. Он выделяет все элементы, имеющие атрибут id .
document.querySelectorAll('[id]').forEach((el) => {
el.style.border = 'solid 2px red';
});
Я могу разместить глубокую ссылку на любой элемент, выделенный красным прямоугольником, благодаря идентификатору фрагмента , который я затем использую в хэше URL страницы. Предположим, я хочу сделать глубокую ссылку на поле Give us feedback in our Product Forums в aside, я могу сделать это, вручную создав URL https://blog.chromium.org/2019/12/chrome-80-content-indexing-es-modules.html #HTML1 . Как вы можете видеть на панели Elements в Developer Tools, рассматриваемый элемент имеет атрибут id со значением HTML1 .

id элемента. Если я проанализирую этот URL с помощью конструктора URL() JavaScript, будут выявлены различные компоненты. Обратите внимание на свойство hash со значением #HTML1 .
new URL('https://blog.chromium.org/2019/12/chrome-80-content-indexing-es-modules.html#HTML1');
/* Creates a new `URL` object
URL {
hash: "#HTML1"
host: "blog.chromium.org"
hostname: "blog.chromium.org"
href: "https://blog.chromium.org/2019/12/chrome-80-content-indexing-es-modules.html#HTML1"
origin: "https://blog.chromium.org"
password: ""
pathname: "/2019/12/chrome-80-content-indexing-es-modules.html"
port: ""
protocol: "https:"
search: ""
searchParams: URLSearchParams {}
username: ""
}
*/
Однако тот факт, что мне пришлось открыть Инструменты разработчика, чтобы найти id элемента, красноречиво говорит о вероятности того, что автор сообщения в блоге хотел дать ссылку именно на этот раздел страницы.
Что делать, если я хочу сделать ссылку на что-то без id ? Допустим, я хочу сделать ссылку на заголовок ECMAScript Modules in Web Workers . Как вы можете видеть на снимке экрана ниже, у рассматриваемого <h1> нет атрибута id , то есть я не могу сделать ссылку на этот заголовок. Эту проблему решают текстовые фрагменты.

id .Текстовые фрагменты
Предложение Text Fragments добавляет поддержку указания текстового фрагмента в хэше URL. При переходе по URL с таким текстовым фрагментом пользовательский агент может подчеркнуть его и/или привлечь к нему внимание пользователя.
Совместимость с браузерами
' d='M96 183a64 64 0 0 1-23-23L17 64a128 128 0 0 0 111 192l55-96a64 64 0 0 1-87 23Z'/%3E%3Cpath fill='url(%23b)' d='M192 128a64 64 0 0 1-9 32l-55 96A128 128 0 0 0 239 64H128a64 64 0 0 1 64 64Z'/%3E%3Ccircle cx='128' cy='128' r='52' fill='%231a73e8'/%3E%3Cpath fill='url(%23c)' d='M96 73a64 64 0 0 1 32-9h111a128 128 0 0 0-222 0l56 96a64 64 0 0 1 23-87Z'/%3E%3C/svg%3E)
' xlink:href='%23A'%3E%3Cstop offset='.76' stop-opacity='0'/%3E%3Cstop offset='.95' stop-opacity='.5'/%3E%3Cstop offset='1'/%3E%3C/radialGradient%3E%3CradialGradient id='F' cx='2523' cy='4680' r='20243' gradientTransform='matrix(-.03715 .99931 -2.12836 -.07913 13579 3530)' xlink:href='%23A'%3E%3Cstop offset='0' stop-color='%2335c1f1'/%3E%3Cstop offset='.11' stop-color='%2334c1ed'/%3E%3Cstop offset='.23' stop-color='%232fc2df'/%3E%3Cstop offset='.31' stop-color='%232bc3d2'/%3E%3Cstop offset='.67' stop-color='%2336c752'/%3E%3C/radialGradient%3E%3CradialGradient id='G' cx='24247' cy='7758' r='9734' gradientTransform='matrix(.28109 .95968 -.78353 .22949 24510 -16292)' xlink:href='%23A'%3E%3Cstop offset='0' stop-color='%2366eb6e'/%3E%3Cstop offset='1' stop-color='%2366eb6e' stop-opacity='0'/%3E%3C/radialGradient%3E%3Cpath id='H' d='M24105 20053a9345 9345 0 01-1053 472 10202 10202 0 01-3590 646c-4732 0-8855-3255-8855-7432 0-1175 680-2193 1643-2729-4280 180-5380 4640-5380 7253 0 7387 6810 8137 8276 8137 791 0 1984-230 2704-456l130-44a12834 12834 0 006660-5282c220-350-168-757-535-565z'/%3E%3Cpath id='I' d='M11571 25141a7913 7913 0 01-2273-2137 8145 8145 0 01-1514-4740 8093 8093 0 013093-6395 8082 8082 0 011373-859c312-148 846-414 1554-404a3236 3236 0 012569 1297 3184 3184 0 01636 1866c0-21 2446-7960-8005-7960-4390 0-8004 4166-8004 7820 0 2319 538 4170 1212 5604a12833 12833 0 007684 6757 12795 12795 0 003908 610c1414 0 2774-233 4045-656a7575 7575 0 01-6278-803z'/%3E%3Cpath id='J' d='M16231 15886c-80 105-330 250-330 566 0 260 170 512 472 723 1438 1003 4149 868 4156 868a5954 5954 0 003027-839 6147 6147 0 001133-850 6180 6180 0 001910-4437c26-2242-796-3732-1133-4392-2120-4141-6694-6525-11668-6525-7011 0-12703 5635-12798 12620 47-3654 3679-6605 7996-6605 350 0 2346 34 4200 1007 1634 858 2490 1894 3086 2921 618 1067 728 2415 728 2952s-271 1333-780 1990z'/%3E%3Cuse fill='url(%23B)' xlink:href='%23H'/%3E%3Cuse fill='url(%23D)' opacity='.35' xlink:href='%23H'/%3E%3Cuse fill='url(%23C)' xlink:href='%23I'/%3E%3Cuse fill='url(%23E)' opacity='.4' xlink:href='%23I'/%3E%3Cuse fill='url(%23F)' xlink:href='%23J'/%3E%3Cuse fill='url(%23G)' xlink:href='%23J'/%3E%3C/svg%3E)
' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.2' stop-color='%239059ff' stop-opacity='0'/%3E%3Cstop offset='.3' stop-color='%238c4ff3' stop-opacity='.1'/%3E%3Cstop offset='.8' stop-color='%237716a8' stop-opacity='.5'/%3E%3Cstop offset='1' stop-color='%236e008b' stop-opacity='.6'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-g' cx='239.1' cy='34.6' r='171.6' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='0' stop-color='%23ffe226'/%3E%3Cstop offset='.1' stop-color='%23ffdb27'/%3E%3Cstop offset='.3' stop-color='%23ffc82a'/%3E%3Cstop offset='.5' stop-color='%23ffa930'/%3E%3Cstop offset='.7' stop-color='%23ff7e37'/%3E%3Cstop offset='.8' stop-color='%23ff7139'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-h' cx='374' cy='-74.3' r='732.2' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.5' stop-color='%23ff980e'/%3E%3Cstop offset='.6' stop-color='%23ff5634'/%3E%3Cstop offset='.7' stop-color='%23ff3647'/%3E%3Cstop offset='.9' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-i' cx='304.6' cy='7.1' r='536.4' gradientTransform='rotate(84 303 4)' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='0' stop-color='%23fff44f'/%3E%3Cstop offset='.1' stop-color='%23ffe847'/%3E%3Cstop offset='.2' stop-color='%23ffc830'/%3E%3Cstop offset='.3' stop-color='%23ff980e'/%3E%3Cstop offset='.4' stop-color='%23ff8b16'/%3E%3Cstop offset='.5' stop-color='%23ff672a'/%3E%3Cstop offset='.6' stop-color='%23ff3647'/%3E%3Cstop offset='.7' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-j' cx='235' cy='98.1' r='457.1' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.5' stop-color='%23ff980e'/%3E%3Cstop offset='.6' stop-color='%23ff5634'/%3E%3Cstop offset='.7' stop-color='%23ff3647'/%3E%3Cstop offset='.9' stop-color='%23e31587'/%3E%3C/radialGradient%3E%3CradialGradient id='ff-k' cx='355.7' cy='124.9' r='500.3' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.2' stop-color='%23ffe141'/%3E%3Cstop offset='.5' stop-color='%23ffaf1e'/%3E%3Cstop offset='.6' stop-color='%23ff980e'/%3E%3C/radialGradient%3E%3ClinearGradient id='ff-a' x1='446.9' y1='76.8' x2='47.9' y2='461.8' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.1' stop-color='%23fff44f'/%3E%3Cstop offset='.1' stop-color='%23ffe847'/%3E%3Cstop offset='.2' stop-color='%23ffc830'/%3E%3Cstop offset='.4' stop-color='%23ff980e'/%3E%3Cstop offset='.4' stop-color='%23ff8b16'/%3E%3Cstop offset='.5' stop-color='%23ff672a'/%3E%3Cstop offset='.5' stop-color='%23ff3647'/%3E%3Cstop offset='.7' stop-color='%23e31587'/%3E%3C/linearGradient%3E%3ClinearGradient id='ff-l' x1='442.1' y1='74.8' x2='102.6' y2='414.3' gradientUnits='userSpaceOnUse'%3E%3Cstop offset='.2' stop-color='%23fff44f' stop-opacity='.8'/%3E%3Cstop offset='.3' stop-color='%23fff44f' stop-opacity='.6'/%3E%3Cstop offset='.5' stop-color='%23fff44f' stop-opacity='.2'/%3E%3Cstop offset='.6' stop-color='%23fff44f' stop-opacity='0'/%3E%3C/linearGradient%3E%3C/defs%3E%3Cpath d='M479 166c-11-25-32-52-49-60a249 249 0 0 1 25 73c-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-60 35-81 101-83 134a120 120 0 0 0-66 25 71 71 0 0 0-6-5 111 111 0 0 1-1-58c-25 11-44 29-58 44-9-12-9-52-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73l-1 2-2 15a229 229 0 0 0-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121zM202 355l3 1-3-1zm55-145zm198-31z' fill='url(%23ff-a)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60 14 26 22 53 25 72v1a207 207 0 0 1-206 279c-113-3-212-87-231-197-3-17 0-26 2-40-2 11-3 14-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121z' fill='url(%23ff-b)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60 14 26 22 53 25 72v1a207 207 0 0 1-206 279c-113-3-212-87-231-197-3-17 0-26 2-40-2 11-3 14-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121z' fill='url(%23ff-c)'/%3E%3Cpath d='m362 195 1 1a130 130 0 0 0-22-29C266 92 322 5 331 0c-60 35-81 101-83 134l9-1c45 0 84 25 105 62z' fill='url(%23ff-d)'/%3E%3Cpath d='M257 210c-1 6-22 26-29 26-68 0-80 41-80 41 3 35 28 64 57 79l4 2 7 3a107 107 0 0 0 31 6c120 6 143-143 57-186 22-4 45 5 58 14-21-37-60-62-105-62l-9 1a120 120 0 0 0-66 25l17 16c16 16 58 33 58 35z' fill='url(%23ff-e)'/%3E%3Cpath d='M257 210c-1 6-22 26-29 26-68 0-80 41-80 41 3 35 28 64 57 79l4 2 7 3a107 107 0 0 0 31 6c120 6 143-143 57-186 22-4 45 5 58 14-21-37-60-62-105-62l-9 1a120 120 0 0 0-66 25l17 16c16 16 58 33 58 35z' fill='url(%23ff-f)'/%3E%3Cpath d='m171 151 5 3a111 111 0 0 1-1-58c-25 11-44 29-58 44 1 0 36 0 54 11z' fill='url(%23ff-g)'/%3E%3Cpath d='M18 261a242 242 0 0 0 231 197 207 207 0 0 0 206-279c8 56-20 110-64 146-86 71-169 43-186 31l-3-1c-50-24-71-70-67-110-42 0-57-35-57-35s38-28 89-4c46 22 90 4 90 4 0-2-42-19-58-35l-17-16a71 71 0 0 0-6-5l-5-3c-18-11-52-11-54-11-9-12-9-51-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73c0 1-9 38-5 57z' fill='url(%23ff-h)'/%3E%3Cpath d='M341 167a130 130 0 0 1 22 29 46 46 0 0 1 4 3c55 50 26 121 24 126 44-36 72-90 64-146-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-9 5-65 92 10 167z' fill='url(%23ff-i)'/%3E%3Cpath d='M367 199a46 46 0 0 0-4-3l-1-1c-13-9-36-18-58-15 86 44 63 193-57 187a107 107 0 0 1-31-6 131 131 0 0 1-11-5c17 12 99 39 186-31 2-5 31-76-24-126z' fill='url(%23ff-j)'/%3E%3Cpath d='M148 277s12-41 80-41c7 0 28-20 29-26s-44 18-90-4c-51-24-89 4-89 4s15 35 57 35c-4 40 16 85 67 110l3 1c-29-15-54-44-57-79z' fill='url(%23ff-k)'/%3E%3Cpath d='M479 166c-11-25-32-52-49-60a249 249 0 0 1 25 73c-27-68-73-95-111-155a255 255 0 0 1-8-14 44 44 0 0 1-4-9 1 1 0 0 0 0-1 1 1 0 0 0-1 0c-60 35-81 101-83 134l9-1c45 0 84 25 105 62-13-9-36-18-58-14 86 43 63 192-57 186a107 107 0 0 1-31-6 131 131 0 0 1-11-5l-3-1 3 1c-29-15-54-44-57-79 0 0 12-41 80-41 7 0 28-20 29-26 0-2-42-19-58-35l-17-16a71 71 0 0 0-6-5 111 111 0 0 1-1-58c-25 11-44 29-58 44-9-12-9-52-8-60l-8 4a175 175 0 0 0-24 21 210 210 0 0 0-22 26 203 203 0 0 0-32 73l-1 2-2 15a279 279 0 0 0-4 34v1a240 240 0 0 0 477 40l1-9c5-41 0-84-15-121zm-24 13z' fill='url(%23ff-l)'/%3E%3C/svg%3E)
' xlink:href='%23s-b'%3E%3Cstop offset='0' stop-color='%2324a5f3' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%231e8ceb' /%3E%3C/radialGradient%3E%3CradialGradient id='s-j' cx='109.3' cy='13.8' r='93.1' gradientTransform='matrix(-.02 1.1 -1.04 -.02 137 -115)' xlink:href='%23s-b'%3E%3Cstop offset='0' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%235488d6' stop-opacity='0' /%3E%3Cstop offset='1' stop-color='%235d96eb' /%3E%3C/radialGradient%3E%3C/defs%3E%3Crect width='220' height='220' x='22' y='-107' fill='url(%23s-a)' ry='49' transform='matrix(.57 0 0 .57 187 256)' /%3E%3Cg transform='translate(194 190)'%3E%3Ccircle cx='67.8' cy='67.7' fill='url(%23s-c)' paint-order='stroke fill markers' r='54' /%3E%3Ccircle cx='-69.9' cy='69.3' fill='url(%23s-i)' transform='translate(138 -2)' r='54' /%3E%3C/g%3E%3Cellipse cx='120' cy='14.2' fill='url(%23s-j)' rx='93.1' ry='93.7' transform='matrix(.58 0 0 .58 192 250)' /%3E%3Cg transform='matrix(.58 0 0 .57 197 182)'%3E%3Cpath fill='%23cac7c8' d='M46 192h1l72-48-7-9-66 57Z' /%3E%3Cpath fill='%23fbfffc' d='M46 191v1l66-57-7-9-59 65Z' /%3E%3Cpath fill='url(%23s-d)' d='m119 144-7-9 66-57-59 66Z' /%3E%3Cpath fill='%23fb645c' d='m105 126 7 9 66-57-1-1-72 49Z' /%3E%3C/g%3E%3Cpath stroke='%23fff' stroke-linecap='round' stroke-miterlimit='1' stroke-width='1.3' d='m287 278 3-2m-12-17 8-2m-8-3h4m-4-13 8 2m-8 3h4m-1-13 7 3m-4-11 7 4m-2-11 6 6m0-12 6 7m1-11 4 6m4-10 3 7m5-9 2 7m15-7-1 7m10-5-3 7m11-4-4 7m11-2-5 6m16 7-7 4m10 4-7 3m10 6-8 1m8 16-8-2m5 10-7-3m4 11-7-4m2 11-6-5m0 11-5-6m-2 11-4-7m-4 11-3-8m-6 10-1-8m-16 8 2-8m-10 5 3-7m-11 4 4-7m-11 2 5-6m-8 3 3-3m4 8 2-3m5 8 2-4m6 7 1-4m8 5v-4m8 4v-4m9 3-1-4m9 1-2-4m9 0-2-4m9-2-3-3m8-4-3-2m8-5-4-2m7-6-4-1m5-8h-4m4-8h-4m3-9-4 1m1-9-4 2m-1-9-3 2m-2-9-3 3m-4-8-2 3m-5-8-2 4m-6-6-1 3m-8-5v4m-8-4v4m-9-2 1 3m-9 0 2 3m-9 1 2 3m-9 2 3 3m-8 4 3 2m-8 5 4 2m-7 6 4 1m-4 25 4-1m-2 5 7-3m-6 7 4-2m-2 6 7-4m-13-21h8m41-41v-8m0 99v-8m49-42h-8' transform='translate(-65 8)' /%3E%3C/svg%3E)
По соображениям безопасности эта функция требует, чтобы ссылки открывались в контексте noopener . Поэтому обязательно включите rel="noopener" в разметку якоря <a> или добавьте noopener в список функций функциональности окна Window.open() .
start
В простейшей форме синтаксис текстовых фрагментов выглядит следующим образом: символ решетки # за которым следует :~:text= и, наконец, start , представляющий собой текст в процентном коде, на который я хочу создать ссылку.
#:~:text=start
Например, предположим, что я хочу дать ссылку на заголовок ECMAScript Modules в Web Workers в сообщении блога, анонсирующем функции в Chrome 80. URL-адрес в этом случае будет следующим:
Фрагмент текста выделен. так . Если щелкнуть ссылку в поддерживающем браузере, например Chrome, фрагмент текста будет выделен и прокручен в поле зрения:

start и end
А что, если я хочу сделать ссылку на весь раздел под названием ECMAScript Modules in Web Workers , а не только на его заголовок? Процентное кодирование всего текста раздела сделает полученный URL непрактично длинным.
К счастью, есть лучший способ. Вместо всего текста я могу обрамить нужный текст, используя синтаксис start,end . Поэтому я указываю пару слов с процентным кодированием в начале нужного текста и пару слов с процентным кодированием в конце нужного текста, разделяя их запятой , .
Это выглядит так:
Для start у меня ECMAScript%20Modules%20in%20Web%20Workers , затем запятая , а затем ES%20Modules%20in%20Web%20Workers. как end . Когда вы щелкаете в поддерживающем браузере, таком как Chrome, весь раздел выделяется и прокручивается в поле зрения:

Теперь вы можете задаться вопросом о моем выборе start и end . На самом деле, немного более короткий URL https://blog.chromium.org/2019/12/chrome-80-content-indexing-es-modules.html #:~:text=ECMAScript%20Modules,Web%20Workers. всего с двумя словами с каждой стороны тоже сработал бы. Сравните start и end с предыдущими значениями.
Если я сделаю еще один шаг и теперь буду использовать только одно слово для start и end , вы увидите, что у меня проблемы. URL https://blog.chromium.org/2019/12/chrome-80-content-indexing-es-modules.html #:~:text=ECMAScript,Workers. теперь стал еще короче, но выделенный фрагмент текста больше не тот, который изначально был нужен. Выделение останавливается на первом вхождении слова Workers. , что правильно, но не то, что я намеревался выделить. Проблема в том, что нужный раздел не идентифицируется однозначно текущими значениями start и end из одного слова:

prefix- и -suffix
Использование достаточно длинных значений для start и end является одним из решений для получения уникальной ссылки. Однако в некоторых ситуациях это невозможно. Кстати, почему я выбрал в качестве примера запись в блоге о выпуске Chrome 80? Ответ в том, что в этом выпуске были введены текстовые фрагменты:

Обратите внимание, как на скриншоте выше слово «text» встречается четыре раза. Четвертое вхождение написано зеленым шрифтом кода. Если бы я хотел сделать ссылку на это конкретное слово, я бы установил start в text . Поскольку слово «text» — это, ну, всего одно слово, не может быть end . Что теперь? URL https://blog.chromium.org/2019/12/chrome-80-content-indexing-es-modules.html #:~:text=text соответствует первому вхождению слова «Text» уже в заголовке:

К счастью, есть решение. В таких случаях я могу указать prefix- и -suffix . Слово перед зеленым кодом шрифта "text" - это "the", а слово после - "parameter". Ни одно из трех других вхождений слова "text" не имеет тех же окружающих слов. Вооружившись этими знаниями, я могу подправить предыдущий URL и добавить prefix- и -suffix . Как и другие параметры, они тоже должны быть закодированы процентами и могут содержать более одного слова. https://blog.chromium.org/2019/12/chrome-80-content-indexing-es-modules.html #:~:text=the-,text,-parameter . Чтобы позволить синтаксическому анализатору четко идентифицировать prefix- и -suffix , их необходимо отделить от start и необязательного end дефисом - .

Полный синтаксис
Полный синтаксис текстовых фрагментов показан ниже. (Квадратные скобки указывают на необязательный параметр.) Значения всех параметров должны быть закодированы в процентах. Это особенно важно для символов тире - , амперсанда & и запятой , поэтому они не интерпретируются как часть синтаксиса текстовой директивы.
#:~:text=[prefix-,]start[,end][,-suffix]
Каждый из prefix- , start , end и -suffix будет соответствовать тексту только в пределах одного элемента уровня блока , но полные диапазоны start,end могут охватывать несколько блоков. Например, :~:text=The quick,lazy dog не будет соответствовать в следующем примере, поскольку начальная строка "The quick" не появляется в пределах одного непрерывного элемента уровня блока:
<div>
The
<div></div>
quick brown fox
</div>
<div>jumped over the lazy dog</div>
Однако в этом примере он совпадает:
<div>The quick brown fox</div>
<div>jumped over the lazy dog</div>
Создание URL-адресов текстовых фрагментов с помощью расширения для браузера
Создание URL-адресов фрагментов текста вручную утомительно, особенно когда дело доходит до того, чтобы убедиться, что они уникальны. Если вы действительно хотите, в спецификации есть несколько советов и перечислены точные шаги для создания URL-адресов фрагментов текста . Мы предоставляем расширение для браузера с открытым исходным кодом под названием Link to Text Fragment , которое позволяет вам ссылаться на любой текст, выделив его и нажав «Копировать ссылку на выбранный текст» в контекстном меню. Это расширение доступно для следующих браузеров:
- Ссылка на фрагмент текста для Google Chrome
- Ссылка на фрагмент текста для Microsoft Edge
- Ссылка на фрагмент текста для Mozilla Firefox
- Ссылка на фрагмент текста для Apple Safari

Несколько текстовых фрагментов в одном URL
Обратите внимание, что в одном URL-адресе может быть несколько текстовых фрагментов. Конкретные текстовые фрагменты должны быть разделены символом амперсанда & . Вот пример ссылки с тремя текстовыми фрагментами: https://blog.chromium.org/2019/12/chrome-80-content-indexing-es-modules.html#:~: text=Text%20URL%20Fragments & text=text,-parameter & text=:~:text=On%20islands,%20birds%20can%20contribute%20as%20much%20as%2060%25%20of%20a%20cat's%20diet .

Смешивание элементов и фрагментов текста
Традиционные фрагменты элементов можно комбинировать с текстовыми фрагментами. Совершенно нормально иметь оба в одном URL, например, чтобы обеспечить осмысленный запасной вариант в случае изменения исходного текста на странице, так что текстовый фрагмент больше не будет соответствовать. URL https://blog.chromium.org/2019/12/chrome-80-content-indexing-es-modules.html #HTML1:~:text=Give%20us%20feedback%20in%20our%20Product%20Forums. ссылка на раздел «Оставьте отзыв» в наших форумах по продуктам содержит как фрагмент элемента ( HTML1 ), так и текстовый фрагмент ( text=Give%20us%20feedback%20in%20our%20Product%20Forums. ):

Директива фрагмента
Есть один элемент синтаксиса, который я еще не объяснил: директива фрагмента :~: . Чтобы избежать проблем совместимости с существующими фрагментами элементов URL, как показано выше, спецификация Text Fragments вводит директиву фрагмента. Директива фрагмента — это часть фрагмента URL, разделенная последовательностью кода :~: . Она зарезервирована для инструкций пользовательского агента, таких как text= , и удаляется из URL во время загрузки, чтобы скрипты автора не могли напрямую взаимодействовать с ней. Инструкции пользовательского агента также называются директивами . В конкретном случае text= поэтому называется текстовой директивой .
Обнаружение особенностей
Чтобы обнаружить поддержку, проверьте свойство fragmentDirective только для чтения в document . Директива fragment — это механизм для URL-адресов, позволяющий указывать инструкции, направленные браузеру, а не документу. Она предназначена для того, чтобы избежать прямого взаимодействия с авторским скриптом, чтобы можно было добавлять будущие инструкции пользовательского агента, не опасаясь внесения критических изменений в существующий контент. Одним из возможных примеров таких будущих дополнений могут быть подсказки по переводу.
if ('fragmentDirective' in document) {
// Text Fragments is supported.
}
Обнаружение функций в основном предназначено для случаев, когда ссылки генерируются динамически (например, поисковыми системами), чтобы избежать отображения ссылок на текстовые фрагменты в браузерах, которые их не поддерживают.
Стилизация фрагментов текста
По умолчанию браузеры оформляют фрагменты текста так же, как и mark (обычно черный на желтом, системные цвета CSS для mark ). Таблица стилей user-agent содержит CSS, который выглядит следующим образом:
:root::target-text {
color: MarkText;
background: Mark;
}
Как вы видите, браузер предоставляет псевдоселектор ::target-text , который вы можете использовать для настройки применяемой подсветки. Например, вы можете оформить текстовые фрагменты как черный текст на красном фоне. Как всегда, обязательно проверьте цветовой контраст , чтобы ваш переопределенный стиль не вызывал проблем с доступностью, и убедитесь, что подсветка действительно визуально выделяется на фоне остального контента.
:root::target-text {
color: black;
background-color: red;
}
Полизаполняемость
Функция Text Fragments может быть полифиллена в некоторой степени. Мы предоставляем полифил , который используется внутри расширения , для браузеров, которые не предоставляют встроенную поддержку Text Fragments, где функциональность реализована в JavaScript.
Программная генерация ссылок на фрагменты текста
Полифилл содержит файл fragment-generation-utils.js , который можно импортировать и использовать для генерации ссылок на фрагменты текста. Это описано в примере кода ниже:
const { generateFragment } = await import('https://unpkg.com/text-fragments-polyfill/dist/fragment-generation-utils.js');
const result = generateFragment(window.getSelection());
if (result.status === 0) {
let url = `${location.origin}${location.pathname}${location.search}`;
const fragment = result.fragment;
const prefix = fragment.prefix ?
`${encodeURIComponent(fragment.prefix)}-,` :
'';
const suffix = fragment.suffix ?
`,-${encodeURIComponent(fragment.suffix)}` :
'';
const start = encodeURIComponent(fragment.textStart);
const end = fragment.textEnd ?
`,${encodeURIComponent(fragment.textEnd)}` :
'';
url += `#:~:text=${prefix}${start}${end}${suffix}`;
console.log(url);
}
Получение фрагментов текста для аналитических целей
Множество сайтов используют фрагмент для маршрутизации, поэтому браузеры удаляют текстовые фрагменты, чтобы не нарушать работу этих страниц. Существует признанная необходимость в раскрытии ссылок текстовых фрагментов на страницы, например, для целей аналитики, но предлагаемое решение пока не реализовано. В качестве обходного пути на данный момент вы можете использовать код ниже для извлечения нужной информации.
new URL(performance.getEntries().find(({ type }) => type === 'navigate').name).hash;
Безопасность
Директивы фрагментов текста вызываются только при полной (не той же странице) навигации, которая является результатом активации пользователя . Кроме того, навигации, происходящие из другого источника, чем пункт назначения, потребуют, чтобы навигация происходила в контексте noopener , так что страница назначения будет известна как достаточно изолированная. Директивы фрагментов текста применяются только к основному фрейму. Это означает, что текст не будет искаться внутри iframes, а навигация iframe не будет вызывать фрагмент текста.
Конфиденциальность
Важно, чтобы реализации спецификации Text Fragments не допускали утечки информации о том, был ли найден текстовый фрагмент на странице или нет. В то время как фрагменты элементов полностью контролируются автором исходной страницы, текстовые фрагменты может создавать кто угодно. Помните, как в моем примере выше не было возможности ссылаться на заголовок ECMAScript Modules в Web Workers , поскольку <h1> не имел id , но как кто-либо, включая меня, мог просто ссылаться куда угодно, тщательно создавая текстовый фрагмент?
Представьте, что я запустил злую рекламную сеть evil-ads.example.com . Далее представьте, что в одном из моих рекламных фреймов я динамически создал скрытый кросс-источниковый фрейм для dating.example.com с URL-адресом текстового фрагмента dating.example.com #:~:text=Log%20Out как только пользователь взаимодействует с рекламой. Если текст «Log Out» найден, я знаю, что жертва в настоящее время вошла в dating.example.com , что я мог бы использовать для профилирования пользователей. Поскольку наивная реализация текстовых фрагментов может решить, что успешное совпадение должно вызвать переключение фокуса, на evil-ads.example.com я мог бы прослушивать событие blur и, таким образом, знать, когда произошло совпадение. В Chrome мы реализовали текстовые фрагменты таким образом, что вышеуказанный сценарий не может произойти.
Другая атака может заключаться в использовании сетевого трафика на основе позиции прокрутки. Предположим, что у меня есть доступ к журналам сетевого трафика моей жертвы, например, как у администратора интрасети компании. Теперь представьте, что существует длинный документ по кадрам Что делать, если вы страдаете от… , а затем список состояний, таких как выгорание , тревожность и т. д. Я мог бы разместить пиксель отслеживания рядом с каждым элементом в списке. Если я затем определю, что загрузка документа временно совпадает с загрузкой пикселя отслеживания рядом, скажем, с элементом выгорания , я могу затем, как администратор интрасети, определить, что сотрудник щелкнул по ссылке на текстовый фрагмент с :~:text=burn%20out , который сотрудник мог счесть конфиденциальным и невидимым для всех. Поскольку этот пример изначально несколько надуман и поскольку его эксплуатация требует соблюдения очень конкретных предварительных условий, группа безопасности Chrome оценила риск реализации прокрутки при навигации как управляемый. Другие пользовательские агенты могут решить вместо этого отображать элемент пользовательского интерфейса ручной прокрутки.
Для сайтов, желающих отказаться, Chromium поддерживает значение заголовка Document Policy , которое они могут отправлять, чтобы пользовательские агенты не обрабатывали URL-адреса текстовых фрагментов.
Document-Policy: force-load-at-top
Отключение фрагментов текста
Самый простой способ отключить эту функцию — использовать расширение, которое может вставлять заголовки HTTP-ответов, например, ModHeader (не продукт Google), чтобы вставить заголовок ответа ( не запроса) следующим образом:
Document-Policy: force-load-at-top
Другой, более сложный способ отказаться — использовать корпоративную настройку ScrollToTextFragmentEnabled . Чтобы сделать это на macOS, вставьте команду ниже в терминал.
defaults write com.google.Chrome ScrollToTextFragmentEnabled -bool false
В Windows следуйте документации на сайте поддержки Google Chrome Enterprise Help .
Фрагменты текста в веб-поиске
Для некоторых поисков поисковая система Google предоставляет быстрый ответ или резюме с фрагментом контента с соответствующего веб-сайта. Эти избранные фрагменты, скорее всего, будут отображаться, когда поиск имеет форму вопроса. Нажатие на избранный фрагмент перенаправляет пользователя непосредственно к тексту избранного фрагмента на исходной веб-странице. Это работает благодаря автоматически созданным URL-адресам фрагментов текста.


Заключение
URL-адрес фрагментов текста — это мощная функция для ссылок на произвольный текст на веб-страницах. Научное сообщество может использовать ее для предоставления высокоточных ссылок на цитаты или ссылки. Поисковые системы могут использовать ее для создания глубоких ссылок на текстовые результаты на страницах. Сайты социальных сетей могут использовать ее, чтобы позволить пользователям делиться определенными отрывками веб-страницы, а не недоступными скриншотами. Надеюсь, вы начнете использовать URL-адреса фрагментов текста и найдете их такими же полезными, как и я. Обязательно установите расширение для браузера Link to Text Fragment .
Ссылки по теме
- Проект спецификации
- Обзор ТЭГа
- Запись статуса платформы Chrome
- Ошибка отслеживания Chrome
- Тема «Намерение отправить»
- Тема WebKit-Dev
- Тема о положении стандартов Mozilla
Благодарности
Текстовые фрагменты были реализованы и описаны Ником Беррисом и Дэвидом Боканом при участии Гранта Вана . Благодарим Джо Медли за тщательный обзор этой статьи. Изображение героя — Грег Ракози на Unsplash .