

تاریخ انتشار: 30 ژانویه 2025
بسیاری از برنامههای WebAssembly در وب، مانند برنامههای بومی، از multithreading بهره میبرند. رشته های متعدد اجازه می دهند کارهای بیشتری به صورت موازی انجام شود و کارهای سنگین را از رشته اصلی جابجا می کند تا از مشکلات تاخیر جلوگیری شود. تا همین اواخر، نقاط درد مشترکی وجود داشت که میتوانست با چنین برنامههای چند رشتهای، مربوط به تخصیص و I/O اتفاق بیفتد. خوشبختانه، ویژگی های اخیر در Emscripten می تواند کمک زیادی به این مسائل کند. این راهنما نشان می دهد که چگونه این ویژگی ها می توانند در برخی موارد منجر به بهبود سرعت 10 برابر یا بیشتر شوند.
مقیاس بندی
نمودار زیر مقیاس بندی کارآمد چند رشته ای را در حجم کار ریاضی خالص نشان می دهد (از معیاری که در این مقاله استفاده خواهیم کرد ):
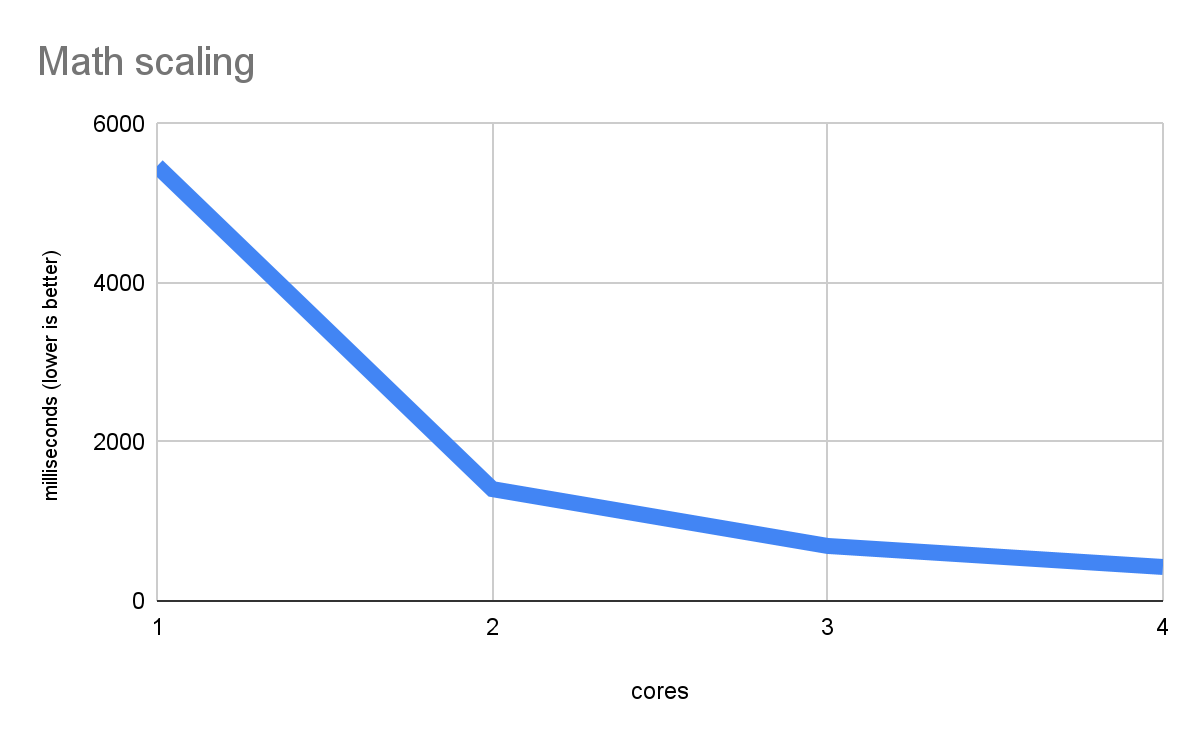
این محاسبات خالص را اندازه گیری می کند، چیزی که هر هسته CPU می تواند به تنهایی انجام دهد، بنابراین عملکرد با هسته های بیشتر بهبود می یابد. چنین خط نزولی عملکرد سریعتر دقیقاً همان چیزی است که مقیاس بندی خوب به نظر می رسد. و نشان میدهد که پلتفرم وب میتواند کدهای بومی چند رشتهای را به خوبی اجرا کند، علیرغم استفاده از وبکارگرها بهعنوان پایهای برای موازیسازی، استفاده از Wasm به جای کد اصلی واقعی، و جزئیات دیگری که ممکن است کمتر بهینه به نظر برسند.
مدیریت پشته: malloc / free
malloc و free توابع استاندارد حیاتی کتابخانه در همه زبانهای حافظه خطی (به عنوان مثال C، C++، Rust و Zig) هستند که برای مدیریت تمام حافظههایی که کاملاً ثابت یا روی پشته نیستند، به آنها تکیه میشود. Emscripten به طور پیشفرض dlmalloc استفاده میکند که یک پیادهسازی فشرده اما کارآمد است (همچنین emmalloc پشتیبانی میکند که حتی فشردهتر اما در برخی موارد کندتر است). با این حال، عملکرد چند رشته ای dlmalloc محدود است زیرا روی هر malloc / free یک قفل می گیرد (زیرا یک اختصاص دهنده جهانی وجود دارد). بنابراین، اگر تخصیص های زیادی در چندین رشته به طور همزمان داشته باشید، می توانید با اختلاف و کندی مواجه شوید. وقتی یک معیار فوق العاده malloc -heavy را اجرا می کنید چه اتفاقی می افتد:
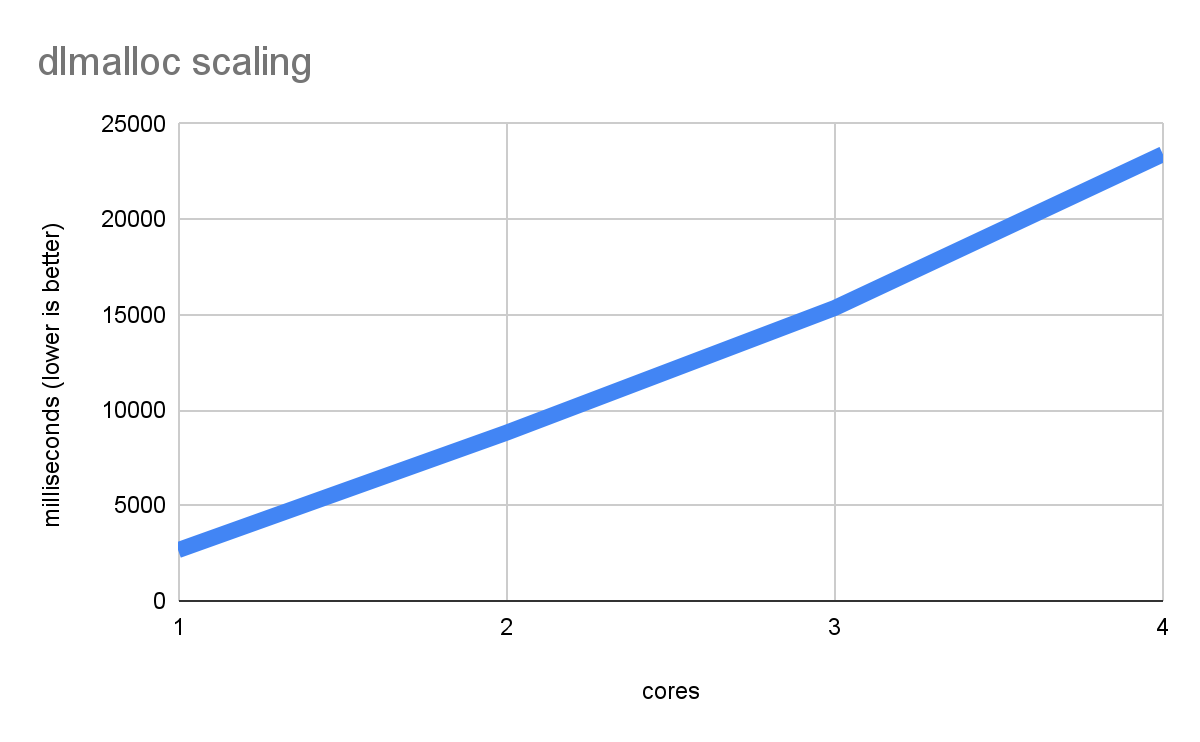
عملکرد نه تنها با هستههای بیشتر بهبود نمییابد، بلکه بدتر و بدتر میشود، زیرا هر رشته برای مدت طولانی برای قفل malloc منتظر میماند. این بدترین حالت ممکن است، اما اگر تخصیص کافی وجود داشته باشد، می تواند در حجم کاری واقعی اتفاق بیفتد.
mimalloc
نسخههای بهینهسازی چند رشتهای از dlmalloc وجود دارد، مانند ptmalloc3 ، که یک نمونه تخصیصدهنده مجزا را در هر رشته پیادهسازی میکند، و از مشاجره اجتناب میکند. چندین تخصیص دهنده دیگر با بهینه سازی های چند رشته ای مانند jemalloc و tcmalloc وجود دارند. Emscripten تصمیم گرفت بر روی پروژه اخیر mimalloc تمرکز کند، که یک تخصیص دهنده با طراحی زیبا از مایکروسافت با قابلیت حمل و کارایی بسیار خوب است. به صورت زیر از آن استفاده کنید:
emcc -sMALLOC=mimalloc
در اینجا نتایج برای معیار malloc با استفاده از mimalloc آمده است:
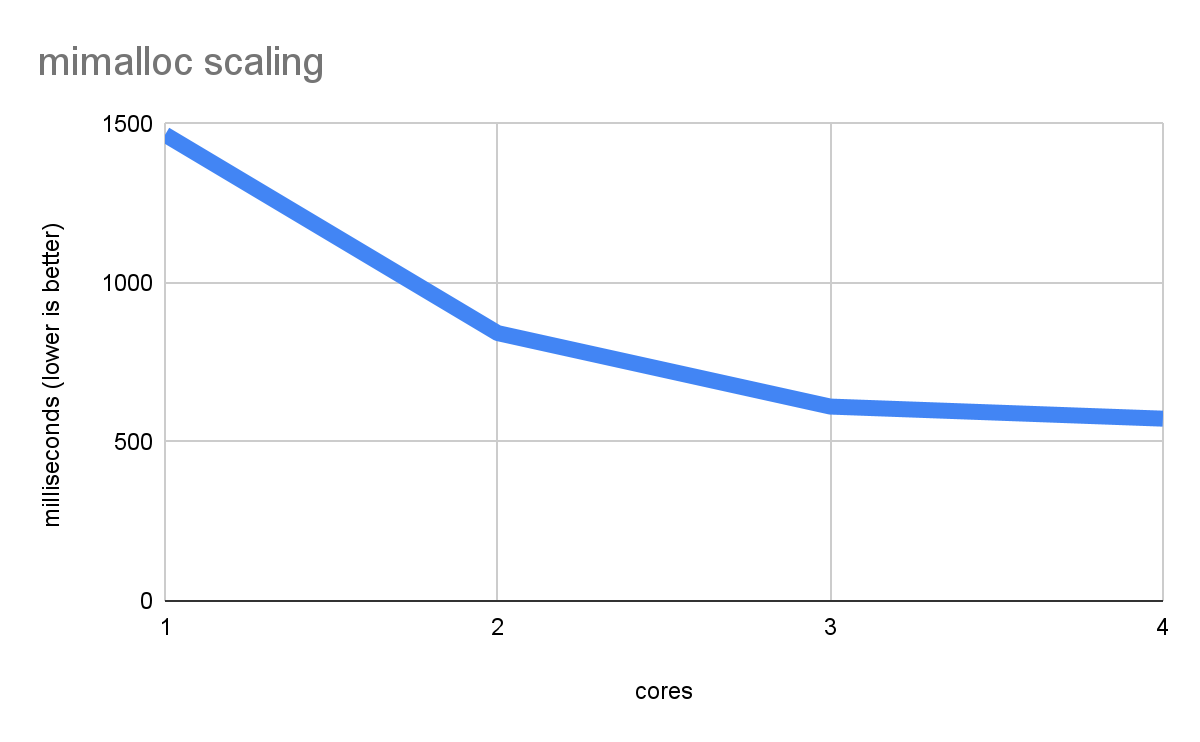
کامل! اکنون عملکرد به طور موثر مقیاس می شود و با هر هسته سریعتر و سریعتر می شود.
اگر به دادههای مربوط به عملکرد تک هستهای در دو نمودار گذشته با دقت نگاه کنید، خواهید دید که dlmalloc 2660 میلیثانیه و mimalloc فقط 1466 طول کشیده است که تقریباً 2 بار سرعت بهبود یافته است. این نشان میدهد که حتی در یک برنامه تک رشتهای، ممکن است مزایای بهینهسازیهای پیچیدهتر mimalloc را مشاهده کنید، هرچند توجه داشته باشید که هزینه آن از نظر اندازه کد و استفاده از حافظه است (به همین دلیل، dlmalloc پیشفرض باقی میماند).
فایل ها و ورودی/خروجی
بسیاری از برنامه ها به دلایل مختلف نیاز به استفاده از فایل ها دارند. به عنوان مثال، برای بارگیری سطوح در یک بازی، یا فونت ها در ویرایشگر تصویر. حتی عملیاتی مانند printf از سیستم فایل زیر هود استفاده می کند، زیرا با نوشتن داده ها در stdout چاپ می کند.
در برنامههای تک رشتهای، این معمولاً مشکلی نیست و Emscripten به طور خودکار از پیوند دادن در پشتیبانی کامل فایل سیستم اجتناب میکند، اگر تنها چیزی که نیاز دارید printf باشد. با این حال، اگر از فایلها استفاده میکنید، دسترسی به سیستم فایل چند رشتهای مشکل است زیرا دسترسی به فایل باید بین رشتهها همگام شود. پیاده سازی سیستم فایل اصلی در Emscripten که "JS FS" نامیده می شود زیرا در جاوا اسکریپت پیاده سازی شده بود، از مدل ساده پیاده سازی سیستم فایل فقط بر روی رشته اصلی استفاده می کرد. هرگاه رشته دیگری بخواهد به فایلی دسترسی پیدا کند، درخواستی را به رشته اصلی پراکسی می کند. این بدان معنی است که رشته های دیگر در یک درخواست cross-thread بلوک می شوند، که در نهایت رشته اصلی به آن رسیدگی می کند.
این مدل ساده در صورتی بهینه است که فقط رشته اصلی به فایلها دسترسی داشته باشد، که یک الگوی رایج است. با این حال، اگر رشته های دیگر خواندن و نوشتن را انجام دهند، مشکلاتی پیش می آید. اول، رشته اصلی در پایان کار را برای رشته های دیگر انجام می دهد و باعث تاخیر قابل مشاهده توسط کاربر می شود. سپس، رشتههای پسزمینه برای انجام کارهای مورد نیاز خود منتظر میمانند تا رشته اصلی آزاد شود، بنابراین کارها کندتر میشوند (یا بدتر از آن، اگر نخ اصلی در حال حاضر در آن نخ کارگر منتظر باشد، میتوانید به بنبست برسید).
WasmFS
برای رفع این مشکل، Emscripten یک سیستم فایل جدید پیاده سازی کرده است، WasmFS . WasmFS بر خلاف فایل سیستم اصلی که در جاوا اسکریپت بود، به زبان C++ نوشته شده و در Wasm کامپایل شده است. WasmFS با ذخیره فایلها در حافظه خطی Wasm که بین همه رشتهها به اشتراک گذاشته میشود، از دسترسی به سیستم فایل از چندین رشته با حداقل سربار پشتیبانی میکند. اکنون همه رشتهها میتوانند فایل ورودی/خروجی را با کارایی یکسان انجام دهند و اغلب حتی میتوانند از مسدود کردن یکدیگر جلوگیری کنند.
یک معیار ساده سیستم فایل مزیت بزرگ WasmFS را در مقایسه با JS FS قدیمی نشان می دهد.
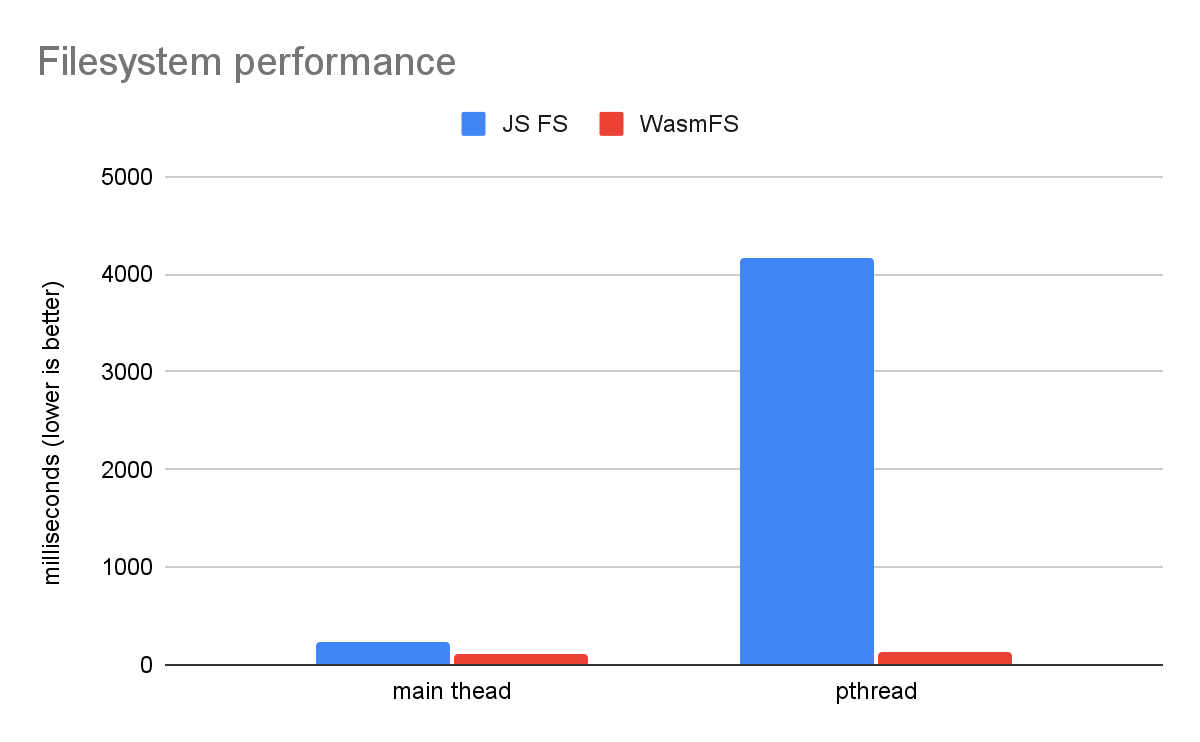
این کار کدهای در حال اجرا فایل سیستم را مستقیماً روی رشته اصلی با اجرای آن بر روی یک thread مقایسه می کند. در JS FS قدیمی، هر عملیات سیستم فایل باید به thread اصلی پروکسی شود، که باعث می شود در یک thread یک مرتبه از قدر کندتر شود! دلیل آن این است که JS FS به جای خواندن/نوشتن برخی بایت ها، ارتباط بین رشته ای را انجام می دهد که شامل قفل، صف و انتظار می شود. در مقابل، WasmFS میتواند به یکسان به فایلها از هر رشته دسترسی داشته باشد، بنابراین نمودار نشان میدهد که عملاً هیچ تفاوتی بین رشته اصلی و یک thread وجود ندارد. در نتیجه، WasmFS 32 برابر سریعتر از JS FS وقتی روی یک pthread است.
توجه داشته باشید که در موضوع اصلی نیز تفاوت وجود دارد که WasmFS 2 برابر سریعتر است. دلیل آن این است که JS FS برای هر عملیات سیستم فایل به جاوا اسکریپت فراخوانی می کند، که WasmFS از آن اجتناب می کند. WasmFS فقط در صورت لزوم از جاوا اسکریپت استفاده می کند (مثلاً برای استفاده از Web API)، که اکثر فایل های WasmFS را در Wasm باقی می گذارد. همچنین، حتی زمانی که جاوا اسکریپت مورد نیاز است، WasmFS می تواند از یک رشته کمکی به جای رشته اصلی استفاده کند تا از تأخیر قابل مشاهده توسط کاربر جلوگیری کند. به همین دلیل، حتی اگر برنامه شما چند رشته ای نباشد (یا اگر چند رشته ای باشد اما از فایل ها فقط در رشته اصلی استفاده می کند)، ممکن است با استفاده از WasmFS بهبودهایی در سرعت مشاهده کنید.
از WasmFS به صورت زیر استفاده کنید:
emcc -sWASMFS
WasmFS در تولید استفاده می شود و پایدار در نظر گرفته می شود، اما هنوز از تمام ویژگی های قدیمی JS FS پشتیبانی نمی کند. از سوی دیگر، برخی از ویژگیهای مهم جدید مانند پشتیبانی از سیستم فایل خصوصی مبدا (OPFS، که برای ذخیرهسازی مداوم به شدت توصیه میشود) را شامل میشود. تیم Emscripten استفاده از WasmFS را توصیه می کند، مگر اینکه به ویژگی ای نیاز داشته باشید که هنوز پورت نشده باشد.
نتیجه گیری
اگر یک برنامه چند رشته ای دارید که تخصیص های زیادی را انجام می دهد یا از فایل ها استفاده می کند، ممکن است با استفاده از WasmFS و/یا mimalloc سود زیادی ببرید. هر دوی آنها در پروژه Emscripten با کامپایل مجدد با پرچم های توضیح داده شده در این پست ساده است.
اگر از رشتهها استفاده نمیکنید، حتی ممکن است بخواهید آن ویژگیها را امتحان کنید: همانطور که قبلاً ذکر شد، پیادهسازیهای مدرنتر با بهینهسازیهایی همراه هستند که در برخی موارد حتی روی یک هسته قابل توجه هستند.