

웹 애플리케이션의 범위, 포부, 기능이 계속 확장되고 있습니다. 이는 좋은 일입니다. 그러나 더욱 풍부한 웹을 향한 끊임없는 행진은 또 다른 추세를 주도하고 있습니다. 각 애플리케이션에서 다운로드하는 데이터의 양이 꾸준히 증가하고 있습니다. 우수한 성능을 제공하려면 모든 바이트의 전송을 최적화해야 합니다.
최신 웹 애플리케이션은 어떤 모습일까요? HTTP 보관을 사용하면 이 질문에 답변할 수 있습니다. 이 프로젝트는 가장 인기 있는 사이트 (Alexa 인기 100만 사이트 목록에서 30만 개 이상)를 주기적으로 크롤링하고 각 개별 대상의 리소스 수, 콘텐츠 유형, 기타 메타데이터에 관한 분석을 기록 및 집계하여 웹이 빌드되는 방식을 추적합니다.
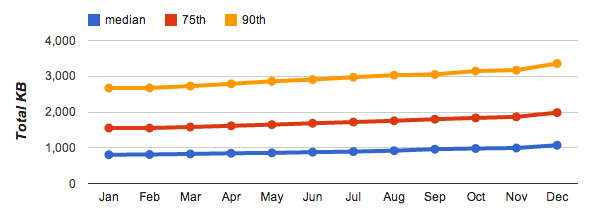
위 데이터는 2013년 1월과 2014년 1월 사이에 웹에서 인기 있는 도착 페이지의 다운로드된 바이트 수 증가 추세를 보여줍니다. 물론 모든 사이트가 동일한 속도로 성장하거나 동일한 양의 데이터를 필요로 하는 것은 아닙니다. 따라서 배포 내의 다양한 50번째 (중앙값), 75번째, 90번째 중앙값을 강조 표시합니다.
2014년 초의 중앙값 사이트는 총 1,054KB의 전송된 총 바이트 수를 합산하는 75개의 요청으로 구성되며, 총 바이트 수 (및 요청 수)는 전년 내내 꾸준한 속도로 증가했습니다. 이 자체는 그리 놀라운 일이 아니지만 중요한 성능 관련 의미가 있습니다. 인터넷 속도는 점점 빨라지고 있지만 국가마다 속도가 빨라지는 속도가 다르며, 특히 모바일의 경우 많은 사용자가 데이터 한도와 비용이 많이 드는 요금제의 영향을 받고 있습니다.
데스크톱 애플리케이션과 달리 웹 애플리케이션에는 별도의 설치 프로세스가 필요하지 않습니다. URL을 입력하면 바로 실행됩니다. 이것이 웹의 핵심 기능입니다. 하지만 이를 위해서는 수십 개, 때로는 수백 개의 다양한 리소스를 가져와야 합니다. 이러한 리소스는 모두 합쳐서 최대 메가바이트의 데이터가 될 수 있으며, Google이 추구하는 즉시 웹 환경을 지원하기 위해 수백 밀리초 내에 함께 제공되어야 합니다.
이러한 요구사항을 고려하여 즉각적인 웹 환경을 구현하는 것은 쉬운 일이 아닙니다. 따라서 콘텐츠 효율성을 최적화하는 것이 중요합니다. 즉, 불필요한 다운로드를 제거하고, 다양한 압축 기법을 통해 각 리소스의 전송 인코딩을 최적화하고, 가능하면 캐싱을 활용하여 중복 다운로드를 제거해야 합니다.