
Découvrez comment optimiser la métrique "Time to First Byte".


Publié le 19 janvier 2023, dernière mise à jour le 28 novembre 2025
Le Time to First Byte (TTFB) est une métrique fondamentale des performances Web qui précède toutes les autres métriques significatives de l'expérience utilisateur, telles que le First Contentful Paint (FCP) et le Largest Contentful Paint (LCP). Cela signifie que des valeurs TTFB élevées ajoutent du temps aux métriques qui suivent.
Il est recommandé que votre serveur réponde aux requêtes de navigation suffisamment rapidement pour que le 75e centile des utilisateurs bénéficie d'un FCP dans le seuil "Bon". En règle générale, la plupart des sites doivent s'efforcer d'obtenir un TTFB de 0,8 seconde ou moins.

Mesurer le TTFB
Avant d'optimiser le TTFB, vous devez observer son impact sur les utilisateurs de votre site Web. Vous devez vous appuyer sur les données de champ comme source principale pour observer le TTFB, car elles sont affectées par les redirections. En revanche, les outils basés sur des tests en laboratoire sont souvent mesurés à l'aide de l'URL finale, ce qui ne tient pas compte de ce délai supplémentaire.
PageSpeed Insights est un outil qui permet d'obtenir des informations de terrain et de laboratoire pour les sites Web publics disponibles dans le rapport d'expérience utilisateur Chrome.
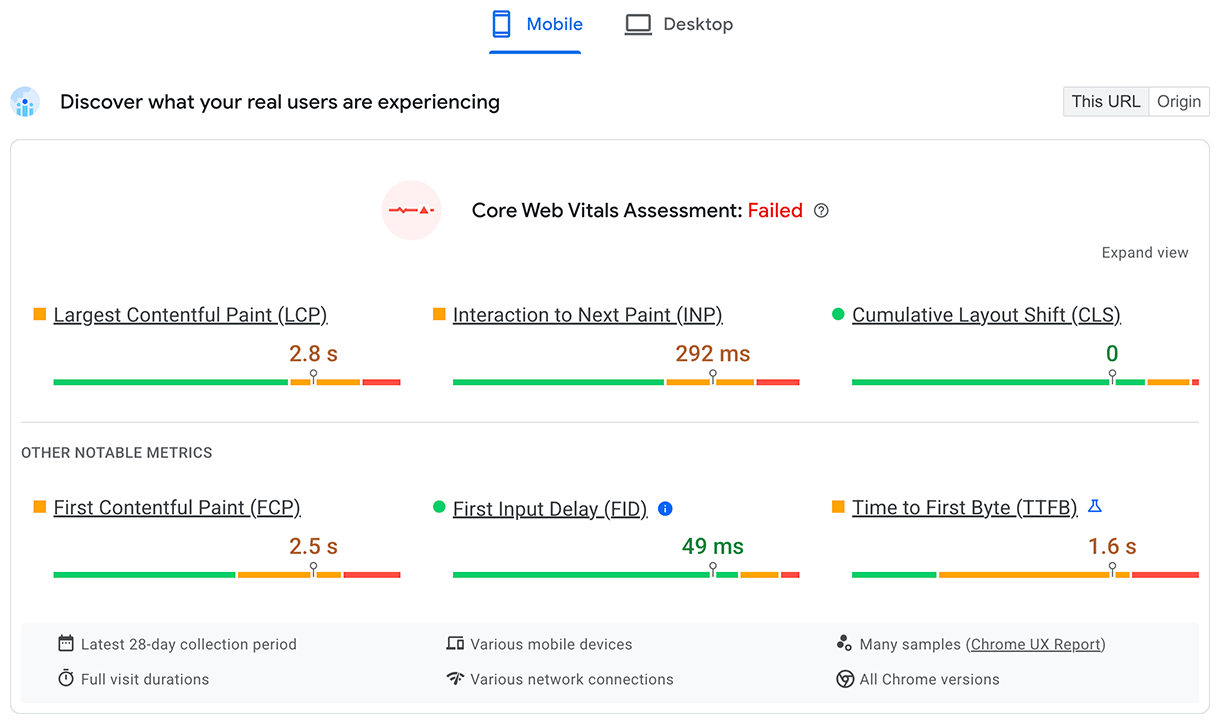
Le TTFB pour les utilisateurs réels est indiqué dans la section supérieure Découvrez l'expérience de vos utilisateurs :
Pour les données de laboratoire, les problèmes de TTFB sont indiqués dans l'insight Latence des requêtes de document :

Pour découvrir d'autres façons de mesurer le TTFB sur le terrain et en laboratoire, consultez la page sur la métrique TTFB.
Comprendre les différences entre le TTFB sur le terrain et en laboratoire
Le TTFB en laboratoire et sur le terrain peut différer pour plusieurs raisons. Lorsqu'il y a une différence, il est important de comprendre pourquoi afin de pouvoir utiliser efficacement les données de laboratoire pour améliorer l'expérience utilisateur.
Lorsque le TTFB en laboratoire est beaucoup plus élevé que le TTFB sur le terrain, cela indique que l'environnement de laboratoire est plus limité que l'expérience utilisateur typique. Ce n'est pas forcément un problème, car les résultats et les recommandations du laboratoire restent valables, mais ils peuvent exagérer l'impact et l'amélioration.
Lorsque le TTFB sur le terrain est beaucoup plus élevé que le TTFB en laboratoire, cela indique des problèmes qui ne sont pas apparents lors de l'exécution en laboratoire, comme l'utilisation de la mise en cache côté serveur, des redirections ou des différences de réseau. Dans ce cas, les résultats et les recommandations du laboratoire peuvent être moins utiles, car ils passent à côté de l'un des principaux problèmes.
Pour savoir si la mise en cache côté serveur a un impact sur le TTFB du laboratoire, essayez de tester des pages moins courantes ou d'utiliser différents paramètres d'URL pour obtenir du contenu non mis en cache. Vous pourrez ainsi vérifier si le TTFB est plus conforme au TTFB sur le terrain. Il peut également être utile de pouvoir contourner la mise en cache côté serveur avec un paramètre d'URL spécifique. Consultez la section Contenu mis en cache.
Pour les redirections et les différences de réseau, les données analytiques sur la façon dont le trafic arrive sur notre site et d'où il provient peuvent être utiles pour déterminer s'il s'agit de problèmes potentiels.
Déboguer un TTFB élevé sur le terrain avec Server-Timing
L'en-tête de réponse Server-Timing peut être utilisé dans le backend de votre application pour mesurer les différents processus de backend susceptibles de contribuer à une latence élevée. La structure de la valeur de l'en-tête est flexible et accepte, au minimum, un identifiant que vous définissez. Les valeurs facultatives incluent une valeur de durée (via dur), ainsi qu'une description facultative lisible par l'utilisateur (via desc).
Serving-Timing peut être utilisé pour mesurer de nombreux processus de backend d'application, mais certains méritent une attention particulière :
- Requêtes de base de données
- Temps d'affichage côté serveur, le cas échéant
- Recherches sur le disque
- Succès ou échecs de cache du serveur périphérique (si vous utilisez un CDN)
Toutes les parties d'une entrée Server-Timing sont séparées par un deux-points, et plusieurs entrées peuvent être séparées par une virgule :
// Two metrics with descriptions and values
Server-Timing: db;desc="Database";dur=121.3, ssr;desc="Server-side Rendering";dur=212.2
L'en-tête peut être défini dans la langue de votre choix à l'aide du backend de votre application. En PHP, par exemple, vous pouvez définir l'en-tête comme suit :
<?php
// Get a high-resolution timestamp before
// the database query is performed:
$dbReadStartTime = hrtime(true);
// Perform a database query and get results...
// ...
// Get a high-resolution timestamp after
// the database query is performed:
$dbReadEndTime = hrtime(true);
// Get the total time, converting nanoseconds to
// milliseconds (or whatever granularity you need):
$dbReadTotalTime = ($dbReadEndTime - $dbReadStartTime) / 1e+6;
// Set the Server-Timing header:
header('Server-Timing: db;desc="Database";dur=' . $dbReadTotalTime);
?>
Lorsque cet en-tête est défini, il fournit des informations que vous pouvez utiliser à la fois dans l'atelier et sur le terrain.
Dans le champ, toute page avec un en-tête de réponse Server-Timing défini remplit la propriété serverTiming dans l'API Navigation Timing :
// Get the serverTiming entry for the first navigation request:
performance.getEntries('navigation')[0].serverTiming.forEach(entry => {
// Log the server timing data:
console.log(entry.name, entry.description, entry.duration);
});
Dans le laboratoire, les données de l'en-tête de réponse Server-Timing sont visualisées dans le panneau Timing de l'onglet Réseau des outils pour les développeurs Chrome :

Ici, Server-Timing est utilisé pour mesurer si une requête de ressource a atteint le cache CDN et combien de temps il faut pour que la requête atteigne le serveur de périphérie du CDN, puis l'origine.
Les temps de réponse du serveur sont également affichés dans la section "Réseau" du panneau Performances des outils pour les développeurs Chrome :

Une fois que vous avez déterminé que votre TTFB est problématique en analysant les données disponibles, vous pouvez passer à la résolution du problème.
Optimiser le TTFB
L'aspect le plus difficile de l'optimisation du TTFB est que, bien que la pile frontend du Web soit toujours HTML, CSS et JavaScript, les piles backend peuvent varier considérablement. Il existe de nombreuses piles de backend et de produits de base de données, chacun ayant ses propres techniques d'optimisation. Par conséquent, ce guide se concentre sur ce qui s'applique à la plupart des architectures, plutôt que de se concentrer uniquement sur les conseils spécifiques à une pile.
Conseils spécifiques à la plate-forme
La plate-forme que vous utilisez pour votre site Web peut avoir un impact important sur le TTFB. Par exemple, les performances de WordPress sont affectées par le nombre et la qualité des plug-ins, ou par les thèmes utilisés. Les autres plates-formes sont également concernées lorsque la plate-forme est personnalisée. Pour obtenir des conseils spécifiques aux fournisseurs, consultez la documentation de votre plate-forme. Vous y trouverez des informations complémentaires aux conseils de performances plus généraux de cet article. L'insight Lighthouse inclut également des conseils spécifiques à la pile, mais ils sont limités.
Hébergement, hébergement, hébergement
Avant même d'envisager d'autres approches d'optimisation, l'hébergement doit être votre première préoccupation. Nous ne pouvons pas vous donner de conseils spécifiques, mais une règle générale consiste à vous assurer que l'hébergeur de votre site Web est capable de gérer le trafic que vous lui envoyez.
L'hébergement partagé est généralement plus lent. Si vous gérez un petit site Web personnel qui diffuse principalement des fichiers statiques, cela ne devrait pas poser de problème. Utilisez certaines des techniques d'optimisation suivantes pour réduire au maximum votre TTFB.
Toutefois, si vous exécutez une application plus importante avec de nombreux utilisateurs, qui implique la personnalisation, l'interrogation de bases de données et d'autres opérations intensives côté serveur, votre choix d'hébergement devient essentiel pour réduire le TTFB sur le terrain.
Lorsque vous choisissez un fournisseur d'hébergement, voici quelques éléments à prendre en compte :
- Quelle quantité de mémoire est allouée à l'instance de votre application ? Si votre application ne dispose pas de suffisamment de mémoire, elle effectuera des va-et-vient et aura du mal à diffuser les pages aussi rapidement que possible.
- Votre hébergeur maintient-il votre pile backend à jour ? À mesure que de nouvelles versions des langages de backend d'application, des implémentations HTTP et des logiciels de base de données sont publiées, les performances de ces logiciels s'améliorent au fil du temps. Il est essentiel de collaborer avec un fournisseur d'hébergement qui accorde la priorité à ce type de maintenance cruciale.
- Si vous avez des exigences très spécifiques pour votre application et que vous souhaitez accéder au niveau le plus bas des fichiers de configuration du serveur, demandez s'il est judicieux de personnaliser le backend de votre propre instance d'application.
De nombreux fournisseurs d'hébergement s'occupent de ces aspects pour vous. Toutefois, si vous constatez des valeurs TTFB élevées, même avec des fournisseurs d'hébergement dédiés, cela peut indiquer que vous devez réévaluer les capacités de votre fournisseur d'hébergement actuel afin d'offrir la meilleure expérience utilisateur possible.
Utiliser un réseau de diffusion de contenu (CDN)
L'utilisation d'un CDN est un sujet bien connu, mais pour une bonne raison : vous pouvez avoir un backend d'application très bien optimisé, mais les utilisateurs situés loin de votre serveur d'origine peuvent toujours rencontrer un TTFB élevé sur le terrain.
Les CDN résolvent le problème de proximité des utilisateurs par rapport à votre serveur d'origine en utilisant un réseau distribué de serveurs qui mettent en cache les ressources sur des serveurs physiquement plus proches de vos utilisateurs. Ces serveurs sont appelés serveurs périphériques.
Les fournisseurs de CDN peuvent également proposer des avantages au-delà des serveurs périphériques :
- Les fournisseurs de CDN proposent généralement des temps de résolution DNS extrêmement rapides.
- Un CDN diffuse probablement votre contenu à partir de serveurs périphériques à l'aide de protocoles modernes tels que HTTP/2 ou HTTP/3.
- HTTP/3 résout en particulier le problème de blocage en tête de file présent dans TCP (sur lequel repose HTTP/2) en utilisant le protocole UDP.
- Un CDN fournit probablement des versions modernes de TLS, ce qui réduit la latence liée au temps de négociation TLS. TLS 1.3, en particulier, est conçu pour que la négociation TLS soit aussi courte que possible.
- Certains fournisseurs de CDN proposent une fonctionnalité souvent appelée "edge worker", qui utilise une API semblable à celle de l'API Service Worker pour intercepter les requêtes, gérer les réponses de manière programmatique dans les caches périphériques ou réécrire complètement les réponses.
- Les fournisseurs de CDN sont très efficaces pour optimiser la compression. La compression est difficile à mettre en place par vous-même et peut entraîner des temps de réponse plus lents dans certains cas avec un balisage généré de manière dynamique, qui doit être compressé à la volée.
- De plus, les fournisseurs de CDN mettent automatiquement en cache les réponses compressées pour les ressources statiques, ce qui permet d'obtenir le meilleur compromis entre taux de compression et temps de réponse.
L'adoption d'un CDN nécessite un effort variable, allant de trivial à important. Toutefois, si votre site Web n'en utilise pas encore, vous devez en faire une priorité pour optimiser votre TTFB.
Utiliser du contenu mis en cache dans la mesure du possible
Les CDN permettent de mettre en cache le contenu sur des serveurs périphériques situés plus près des visiteurs, à condition que le contenu soit configuré avec les en-têtes HTTP Cache-Control appropriés. Bien que cela ne soit pas approprié pour le contenu personnalisé, le fait de devoir retourner à l'origine peut annuler une grande partie de la valeur d'un CDN.
Pour les sites qui mettent fréquemment à jour leur contenu, même une courte durée de mise en cache peut entraîner des gains de performances notables pour les sites très fréquentés. En effet, seul le premier visiteur pendant cette période subit la latence complète jusqu'au serveur d'origine, tandis que tous les autres visiteurs peuvent réutiliser la ressource mise en cache à partir du serveur Edge. Certains CDN permettent l'invalidation du cache lors des mises à jour du site, ce qui offre le meilleur des deux mondes : des durées de cache longues, mais des mises à jour instantanées en cas de besoin.
Même si la mise en cache est correctement configurée, vous pouvez l'ignorer en utilisant des paramètres de chaîne de requête uniques pour la mesure des données analytiques. Le CDN peut considérer qu'il s'agit de contenus différents alors qu'ils sont identiques. La version mise en cache ne sera donc pas utilisée.
Les contenus plus anciens ou moins consultés peuvent également ne pas être mis en cache, ce qui peut entraîner des valeurs TTFB plus élevées sur certaines pages que sur d'autres. Augmenter les temps de mise en cache peut réduire l'impact de ce problème, mais sachez que cela augmente également le risque de diffuser du contenu potentiellement obsolète.
L'impact du contenu mis en cache ne concerne pas uniquement les utilisateurs de CDN. L'infrastructure de serveur peut avoir besoin de générer du contenu à partir de coûteuses recherches dans la base de données lorsque le contenu mis en cache ne peut pas être réutilisé. Les données auxquelles les utilisateurs accèdent plus fréquemment ou les pages préchargées peuvent souvent être plus performantes.
Éviter d'avoir plusieurs redirections de page
Les redirections sont l'une des causes fréquentes d'un TTFB élevé. Les redirections se produisent lorsqu'une requête de navigation pour un document reçoit une réponse informant le navigateur que la ressource existe à un autre emplacement. Une redirection peut certainement ajouter une latence indésirable à une requête de navigation, mais cela peut certainement empirer si cette redirection pointe vers une autre ressource qui entraîne une autre redirection, et ainsi de suite. Cela peut avoir un impact particulier sur les sites qui reçoivent un grand nombre de visiteurs provenant d'annonces ou de newsletters, car ils sont souvent redirigés vers des services d'analyse à des fins de mesure. Éliminer les redirections que vous contrôlez directement peut vous aider à obtenir un bon TTFB.
Il existe deux types de redirections :
- Les redirections de même origine, où la redirection a lieu entièrement sur votre site Web.
- Les redirections multi-origines, où la redirection se produit initialement sur une autre origine (par exemple, à partir d'un service de raccourcissement d'URL de réseau social) avant d'arriver sur votre site Web.
Concentrez-vous sur l'élimination des redirections de même origine, car vous avez un contrôle direct sur ce point. Cela implique de vérifier les liens sur votre site Web pour voir si l'un d'entre eux génère un code de réponse 302 ou 301. Cela peut souvent être dû à l'absence du schéma https:// (les navigateurs utilisent alors http:// par défaut, qui est ensuite redirigé) ou au fait que les barres obliques de fin ne sont pas correctement incluses ou exclues dans l'URL.
Les redirections cross-origin sont plus délicates, car elles sont souvent hors de votre contrôle. Toutefois, essayez d'éviter les redirections multiples dans la mesure du possible, par exemple en utilisant plusieurs raccourcisseurs de liens lorsque vous partagez des liens. Assurez-vous que l'URL fournie aux annonceurs ou aux newsletters est l'URL finale correcte, afin de ne pas ajouter une autre redirection à celles utilisées par ces services.
Les redirections HTTP vers HTTPS peuvent également être une source importante de temps de redirection. Pour contourner ce problème, vous pouvez utiliser l'en-tête Strict-Transport-Security (HSTS), qui applique HTTPS lors de la première visite d'une origine, puis indique au navigateur d'accéder immédiatement à l'origine via le schéma HTTPS lors des visites ultérieures.
Une fois que vous avez mis en place une bonne stratégie HSTS, vous pouvez accélérer les choses lors de la première visite d'une origine en ajoutant votre site à la liste de préchargement HSTS.
Diffuser le balisage au navigateur
Les navigateurs sont optimisés pour traiter le balisage de manière efficace lorsqu'il est diffusé en continu, ce qui signifie qu'il est géré par blocs à mesure qu'il arrive du serveur. C'est essentiel pour les charges utiles de balisage volumineuses, car cela signifie que le navigateur peut analyser les blocs de balisage de manière incrémentielle, au lieu d'attendre que la réponse entière arrive avant de commencer l'analyse.
Bien que les navigateurs soient très efficaces pour gérer le balisage de flux, il est essentiel de faire tout votre possible pour que ce flux continue de circuler afin que ces bits de balisage initiaux soient envoyés le plus rapidement possible. Si le backend ralentit les choses, c'est un problème. Les piles de backend étant nombreuses, il serait hors de portée de ce guide de couvrir chaque pile et les problèmes qui pourraient survenir dans chacune d'elles.
React, par exemple, et d'autres frameworks qui peuvent rendre le balisage à la demande sur le serveur, ont utilisé une approche synchrone pour le rendu côté serveur. Toutefois, les versions plus récentes de React ont implémenté des méthodes de serveur pour le streaming du balisage lors du rendu. Cela signifie que vous n'avez pas besoin d'attendre qu'une méthode d'API de serveur React affiche l'intégralité de la réponse avant qu'elle ne soit envoyée.
Un autre moyen de s'assurer que le balisage est diffusé rapidement au navigateur consiste à s'appuyer sur le rendu statique, qui génère des fichiers HTML lors de la compilation. Le fichier complet étant disponible immédiatement, les serveurs Web peuvent commencer à l'envoyer immédiatement. La nature inhérente du protocole HTTP entraîne un balisage de flux. Bien que cette approche ne convienne pas à toutes les pages de tous les sites Web (par exemple, celles qui nécessitent une réponse dynamique dans le cadre de l'expérience utilisateur), elle peut être utile pour les pages qui ne nécessitent pas de balisage personnalisé pour un utilisateur spécifique.
Utiliser un service worker
L'API Service Worker peut avoir un impact important sur le TTFB des documents et des ressources qu'ils chargent. En effet, un service worker agit comme un proxy entre le navigateur et le serveur. Toutefois, l'impact sur le TTFB de votre site Web dépend de la façon dont vous configurez votre service worker et si cette configuration correspond aux exigences de votre application.
- Utilisez une stratégie "obsolète pendant la revalidation" pour les composants. Si un élément (document ou ressource dont le document a besoin) se trouve dans le cache du service worker, la stratégie "obsolète pendant la revalidation" le diffuse d'abord à partir du cache, puis le télécharge en arrière-plan et le diffuse à partir du cache pour les futures interactions.
- Si vous disposez de ressources de document qui ne changent pas très souvent, l'utilisation d'une stratégie "stale-while-revalidate" peut rendre le TTFB d'une page presque instantané. Toutefois, cette méthode ne fonctionne pas très bien si votre site Web envoie un balisage généré de manière dynamique, par exemple un balisage qui change selon que l'utilisateur est authentifié ou non. Dans ce cas, vous devez toujours accéder au réseau en premier pour que le document soit aussi récent que possible.
- Si votre document charge des ressources non critiques qui changent assez souvent, mais que la récupération de la ressource obsolète n'affecte pas beaucoup l'expérience utilisateur (comme certaines images ou d'autres ressources non critiques), le TTFB de ces ressources peut être considérablement réduit à l'aide d'une stratégie "obsolète pendant la revalidation".
- Utilisez le modèle d'app shell pour les applications rendues côté client. Ce modèle convient le mieux aux SPA où la "coque" de la page peut être fournie instantanément à partir du cache du service worker, et où le contenu dynamique de la page est renseigné et affiché plus tard dans le cycle de vie de la page.
Utiliser 103 Early Hints pour les ressources essentielles au rendu
Quelle que soit l'efficacité de l'optimisation du backend de votre application, le serveur peut encore avoir une quantité importante de travail à effectuer pour préparer une réponse, y compris un travail de base de données coûteux (mais nécessaire) qui retarde l'arrivée de la réponse de navigation. Cela peut avoir pour effet de retarder certaines ressources critiques pour le rendu, telles que le CSS ou, dans certains cas, le JavaScript qui affiche le balisage sur le client.
L'en-tête 103 Early Hints est un code de réponse anticipé que le serveur peut envoyer au navigateur pendant que le backend est occupé à préparer le balisage. Cet en-tête peut être utilisé pour indiquer au navigateur qu'il existe des ressources essentielles au rendu que la page doit commencer à télécharger pendant la préparation du balisage. Pour les navigateurs compatibles, l'effet peut se traduire par un rendu plus rapide des documents (CSS) et un chargement plus rapide des pages.
L'un des inconvénients des indications précoces 103 est que, comme la mise en cache, elles peuvent masquer le "vrai" TTFB d'un site. Si une infrastructure de serveur est lente (parce qu'elle est sous-alimentée ou que le code doit être optimisé), cela peut être moins évident lorsque 103 Early Hints est utilisé, car le TTFB semble rapide. Les sites qui utilisent les indications précoces 103 doivent envisager de mesurer le temps serveur réel (avec Server-Timing ou finalResponseHeadersStart de l'API PerformanceNavigationTiming).
Conclusion
Étant donné qu'il existe de nombreuses combinaisons de piles d'applications backend, aucun article ne peut englober tout ce que vous pouvez faire pour réduire le TTFB de votre site Web. Toutefois, voici quelques options que vous pouvez essayer pour accélérer un peu les choses côté serveur.
Comme pour l'optimisation de chaque métrique, l'approche est en grande partie similaire : mesurez votre TTFB sur le terrain, utilisez des outils de laboratoire pour identifier les causes, puis appliquez des optimisations si possible. Bien que certaines techniques ne soient peut-être pas adaptées à votre situation, d'autres le seront probablement. Comme toujours, vous devrez surveiller de près vos données de champ et les ajuster si nécessaire pour garantir l'expérience utilisateur la plus rapide possible.