
Obtén información para optimizar la métrica Tiempo hasta el primer byte.


El tiempo hasta el primer byte (TTFB) es una métrica fundamental del rendimiento web que precede a todas las demás métricas significativas de la experiencia del usuario, como el primer procesamiento de imagen con contenido (FCP) y el procesamiento de imagen con contenido más grande (LCP). Esto significa que los valores altos del TTFB agregan tiempo a las métricas que le siguen.
Se recomienda que tu servidor responda a las solicitudes de navegación con la suficiente rapidez para que el percentil 75 de los usuarios experimente un FCP dentro del umbral de "bueno". Como guía aproximada, la mayoría de los sitios deben esforzarse por tener un TTFB de 0.8 segundos o menos.

Cómo medir el TTFB
Antes de optimizar el TTFB, debes observar cómo afecta a los usuarios de tu sitio web. Debes confiar en los datos de campo como fuente principal para observar el TTFB, ya que se ve afectado por los redireccionamientos, mientras que las herramientas basadas en el laboratorio a menudo se miden con la URL final, por lo que se omite este retraso adicional.
PageSpeed Insights es una forma de obtener información de campo y de laboratorio para los sitios web públicos que están disponibles en el Informe sobre la experiencia del usuario en Chrome.
El TTFB para usuarios reales se muestra en la sección superior Descubre lo que experimentan tus usuarios reales:
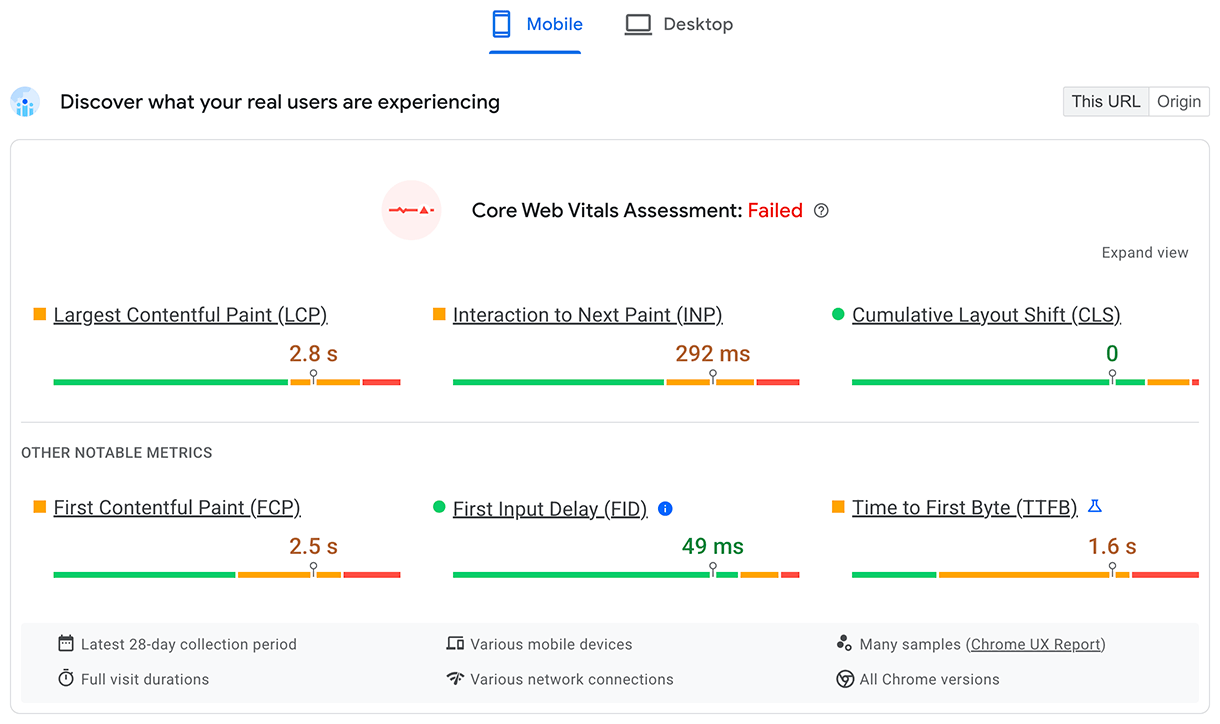
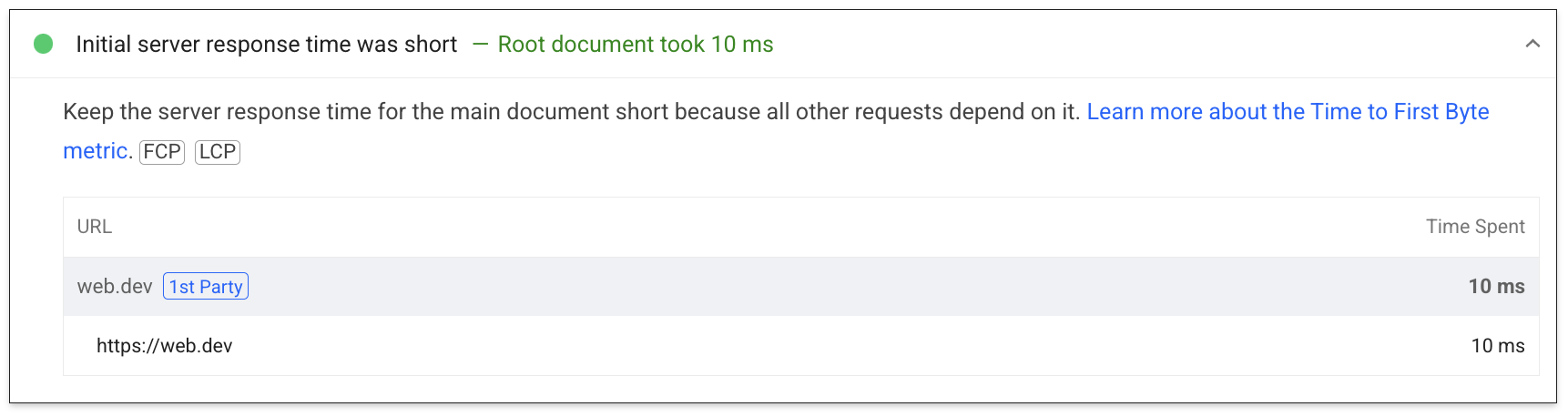
En el caso de los datos de laboratorio, se muestra un subconjunto del TTFB en la auditoría del tiempo de respuesta del servidor:
Para obtener más información sobre otras formas de medir el TTFB en el campo y en el laboratorio, consulta la página de la métrica TTFB.
Comprende las diferencias entre el TTFB de campo y el de laboratorio
El TTFB de laboratorio y el de campo pueden diferir por varios motivos, y, cuando lo hacen, es importante comprender por qué para poder usar de manera eficaz los datos de laboratorio y mejorar las experiencias del usuario.
Cuando el TTFB del lab es mucho mayor que el TTFB del campo, esto indica que el entorno del lab está más restringido que las experiencias típicas del usuario. Esto no es necesariamente un problema, ya que es probable que los resultados y las recomendaciones del laboratorio sigan siendo válidos, pero es posible que exageren el impacto y la mejora.
Cuando el TTFB de campo es mucho mayor que el TTFB de laboratorio, esto indica problemas que no se detectaron durante la ejecución del laboratorio, como el uso de almacenamiento en caché del servidor, redireccionamientos o diferencias de red. En este caso, los resultados y las recomendaciones del lab pueden ser menos útiles, ya que no tendrán en cuenta uno de los principales problemas.
Para ver si el almacenamiento en caché del servidor afecta el TTFB de laboratorio, intenta probar páginas menos comunes o usar diferentes parámetros de URL para obtener contenido sin almacenar en caché y ver si el TTFB se alinea más con el TTFB de campo. También puede ser útil poder omitir el almacenamiento en caché del servidor con un parámetro de URL específico. Consulta la sección de contenido almacenado en caché.
En el caso de los redireccionamientos y las diferencias de red, el análisis de cómo llega el tráfico a nuestro sitio y de dónde proviene puede ser útil para diagnosticar si se trata de problemas potenciales.
Depura un TTFB alto en el campo con Server-Timing
El encabezado de respuesta Server-Timing se puede usar en el backend de tu aplicación para medir los distintos procesos de backend que podrían contribuir a una latencia alta. La estructura del valor del encabezado es flexible y acepta, como mínimo, un identificador que definas. Los valores opcionales incluyen un valor de duración (a través de dur), así como una descripción opcional legible por humanos (a través de desc).
Serving-Timing se puede usar para medir muchos procesos de backend de la aplicación, pero hay algunos a los que te recomendamos que prestes especial atención:
- Consultas en bases de datos
- Tiempo de renderización del servidor, si corresponde
- Búsquedas en disco
- Aciertos o errores de caché del servidor perimetral (si se usa una CDN)
Todas las partes de una entrada Server-Timing están separadas por dos puntos, y las distintas entradas se pueden separar con una coma:
// Two metrics with descriptions and values
Server-Timing: db;desc="Database";dur=121.3, ssr;desc="Server-side Rendering";dur=212.2
El encabezado se puede configurar con el lenguaje que elijas para el backend de tu aplicación. En PHP, por ejemplo, puedes configurar el encabezado de la siguiente manera:
<?php
// Get a high-resolution timestamp before
// the database query is performed:
$dbReadStartTime = hrtime(true);
// Perform a database query and get results...
// ...
// Get a high-resolution timestamp after
// the database query is performed:
$dbReadEndTime = hrtime(true);
// Get the total time, converting nanoseconds to
// milliseconds (or whatever granularity you need):
$dbReadTotalTime = ($dbReadEndTime - $dbReadStartTime) / 1e+6;
// Set the Server-Timing header:
header('Server-Timing: db;desc="Database";dur=' . $dbReadTotalTime);
?>
Cuando se establece este encabezado, se mostrará información que puedes usar tanto en el lab como en el campo.
En el campo, cualquier página con un encabezado de respuesta Server-Timing establecido propagará la propiedad serverTiming en la API de Navigation Timing:
// Get the serverTiming entry for the first navigation request:
performance.getEntries('navigation')[0].serverTiming.forEach(entry => {
// Log the server timing data:
console.log(entry.name, entry.description, entry.duration);
});
En el lab, los datos del encabezado de respuesta Server-Timing se visualizarán en el panel de tiempos de la pestaña Red en Herramientas para desarrolladores de Chrome:

Encabezados de respuesta Server-Timing visualizados en la pestaña Network de las Herramientas para desarrolladores de Chrome. Aquí, Server-Timing se usa para medir si una solicitud de un recurso llegó a la caché de la CDN y cuánto tiempo tarda la solicitud en llegar al servidor perimetral de la CDN y, luego, al origen.
Una vez que hayas determinado que tienes un TTFB problemático analizando los datos disponibles, puedes pasar a corregir el problema.
Formas de optimizar el TTFB
El aspecto más desafiante de la optimización del TTFB es que, si bien la pila de frontend de la Web siempre será HTML, CSS y JavaScript, las pilas de backend pueden variar significativamente. Existen numerosas pilas de backend y productos de bases de datos, cada uno con sus propias técnicas de optimización. Por lo tanto, esta guía se enfocará en lo que se aplica a la mayoría de las arquitecturas, en lugar de enfocarse únicamente en la orientación específica de la pila.
Orientación específica para cada plataforma
La plataforma que usas para tu sitio web puede afectar en gran medida el TTFB. Por ejemplo, el rendimiento de WordPress se ve afectado por la cantidad y la calidad de los complementos, o por los temas que se usan. Otras plataformas se ven afectadas de manera similar cuando se personalizan. Consulta la documentación de tu plataforma para obtener asesoramiento específico del proveedor y complementar el asesoramiento más general sobre el rendimiento que se incluye en esta publicación. La auditoría de Lighthouse para reducir los tiempos de respuesta del servidor también incluye algunas orientaciones específicas de la pila limitadas.
Hosting, hosting, hosting
Antes de considerar otros enfoques de optimización, el hosting debe ser lo primero que tengas en cuenta. No hay mucha orientación específica que se pueda ofrecer aquí, pero una regla general es asegurarse de que el host de tu sitio web sea capaz de controlar el tráfico que le envías.
Por lo general, el alojamiento compartido será más lento. Si tienes un sitio web personal pequeño que publica principalmente archivos estáticos, probablemente no haya problemas, y algunas de las técnicas de optimización que se describen a continuación te ayudarán a reducir el TTFB lo más posible.
Sin embargo, si ejecutas una aplicación más grande con muchos usuarios que implica personalización, consultas de bases de datos y otras operaciones intensivas del servidor, tu elección de hosting se vuelve fundamental para reducir el TTFB en el campo.
Cuando elijas un proveedor de hosting, ten en cuenta lo siguiente:
- ¿Cuánta memoria se asigna a la instancia de tu aplicación? Si tu aplicación no tiene suficiente memoria, se producirá un thrashing y tendrá dificultades para mostrar las páginas lo más rápido posible.
- ¿Tu proveedor de hosting mantiene actualizada tu pila de backend? A medida que se lancen nuevas versiones de lenguajes de backend de aplicaciones, implementaciones de HTTP y software de bases de datos, el rendimiento de ese software mejorará con el tiempo. Es fundamental asociarse con un proveedor de hosting que priorice este tipo de mantenimiento crucial.
- Si tienes requisitos de aplicación muy específicos y deseas el nivel más bajo de acceso a los archivos de configuración del servidor, pregunta si tiene sentido personalizar el backend de tu propia instancia de aplicación.
Hay muchos proveedores de hosting que se encargarán de estas cuestiones por ti, pero si comienzas a observar valores de TTFB largos incluso en proveedores de hosting dedicados, es posible que debas reevaluar las capacidades de tu proveedor de hosting actual para poder brindar la mejor experiencia del usuario posible.
Usar una red de distribución de contenidos (CDN)
El tema del uso de CDN es muy conocido, pero por una buena razón: puedes tener un backend de aplicación muy bien optimizado, pero los usuarios ubicados lejos de tu servidor de origen aún pueden experimentar un TTFB alto en el campo.
Las CDN resuelven el problema de la proximidad del usuario a tu servidor de origen con una red distribuida de servidores que almacenan en caché los recursos en servidores que están físicamente más cerca de tus usuarios. Estos servidores se denominan servidores perimetrales.
Los proveedores de CDN también pueden ofrecer beneficios más allá de los servidores perimetrales:
- Por lo general, los proveedores de CDN ofrecen tiempos de resolución de DNS extremadamente rápidos.
- Es probable que una CDN entregue tu contenido desde servidores perimetrales con protocolos modernos, como HTTP/2 o HTTP/3.
- En particular, HTTP/3 resuelve el problema de bloqueo de cabeza de línea presente en TCP (en el que se basa HTTP/2) con el protocolo UDP.
- Es probable que una CDN también proporcione versiones modernas de TLS, lo que reduce la latencia involucrada en el tiempo de negociación de TLS. En particular, TLS 1.3 está diseñado para que la negociación de TLS sea lo más breve posible.
- Algunos proveedores de CDN ofrecen una función que suele llamarse "trabajador perimetral", que usa una API similar a la de Service Worker API para interceptar solicitudes, administrar respuestas de forma programática en las cachés perimetrales o reescribir respuestas por completo.
- Los proveedores de CDN son muy buenos para optimizar la compresión. La compresión es difícil de hacer correctamente por tu cuenta y puede generar tiempos de respuesta más lentos en ciertos casos con lenguaje de marcado generado de forma dinámica, que debe comprimirse sobre la marcha.
- Los proveedores de CDN también almacenarán automáticamente en caché las respuestas comprimidas para los recursos estáticos, lo que generará la mejor combinación de relación de compresión y tiempo de respuesta.
Si bien la adopción de una CDN implica una cantidad variable de esfuerzo, desde trivial hasta significativo, debería ser una prioridad alta para optimizar tu TTFB si tu sitio web aún no usa una.
Usa contenido almacenado en caché siempre que sea posible
Las CDN permiten que el contenido se almacene en caché en servidores perimetrales que se encuentran físicamente más cerca de los visitantes, siempre que el contenido esté configurado con los encabezados HTTP Cache-Control adecuados. Si bien esto no es adecuado para el contenido personalizado, requerir un viaje de vuelta al origen puede anular gran parte del valor de una CDN.
En el caso de los sitios que actualizan su contenido con frecuencia, incluso un tiempo de almacenamiento en caché corto puede generar mejoras notables en el rendimiento de los sitios con mucho tráfico, ya que solo el primer visitante durante ese tiempo experimenta la latencia completa hasta el servidor de origen, mientras que todos los demás visitantes pueden reutilizar el recurso almacenado en caché del servidor perimetral. Algunas CDN permiten la invalidación de la caché en las versiones del sitio, lo que permite tener lo mejor de ambos mundos: tiempos de caché largos, pero actualizaciones instantáneas cuando es necesario.
Incluso cuando el almacenamiento en caché está configurado correctamente, se puede ignorar con el uso de parámetros de cadena de consulta únicos para la medición de Analytics. Es posible que, para la CDN, parezca contenido diferente, aunque sea el mismo, por lo que no se usará la versión almacenada en caché.
Es posible que el contenido más antiguo o menos visitado tampoco se almacene en caché, lo que puede generar valores de TTFB más altos en algunas páginas que en otras. Aumentar los tiempos de almacenamiento en caché puede reducir el impacto de esto, pero ten en cuenta que, con el aumento de los tiempos de almacenamiento en caché, aumenta la posibilidad de entregar contenido potencialmente desactualizado.
El impacto del contenido almacenado en caché no solo afecta a quienes usan CDN. Es posible que la infraestructura del servidor deba generar contenido a partir de búsquedas costosas en la base de datos cuando no se pueda reutilizar el contenido almacenado en caché. Los datos a los que se accede con más frecuencia o las páginas almacenadas previamente en la caché suelen tener un mejor rendimiento.
Evita que haya varias redirecciones de página
Un factor común que contribuye a un TTFB alto son los redirects. Los redireccionamientos se producen cuando una solicitud de navegación para un documento recibe una respuesta que informa al navegador que el recurso existe en otra ubicación. Un redireccionamiento puede agregar latencia no deseada a una solicitud de navegación, pero puede empeorar si ese redireccionamiento apunta a otro recurso que genera otro redireccionamiento, y así sucesivamente. Esto puede afectar especialmente a los sitios que reciben grandes volúmenes de visitantes de anuncios o boletines informativos, ya que suelen redireccionar a través de servicios de estadísticas para fines de medición. Eliminar los redireccionamientos que están bajo tu control directo puede ayudarte a lograr un buen TTFB.
Existen dos tipos de redireccionamientos:
- Redireccionamientos del mismo origen, en los que el redireccionamiento se produce completamente en tu sitio web
- Redireccionamientos de origen cruzado, en los que el redireccionamiento se produce inicialmente en otro origen (por ejemplo, desde un servicio de acortamiento de URLs de redes sociales) antes de llegar a tu sitio web
Te recomendamos que te enfoques en eliminar los redireccionamientos del mismo origen, ya que es algo que podrás controlar directamente. Esto implicaría verificar los vínculos de tu sitio web para ver si alguno de ellos genera un código de respuesta 302 o 301. A menudo, esto puede deberse a que no se incluye el esquema https:// (por lo que los navegadores usan http:// de forma predeterminada y, luego, redireccionan) o a que las barras finales no se incluyen o excluyen de forma adecuada en la URL.
Los redireccionamientos de origen cruzado son más complicados, ya que, a menudo, están fuera de tu control, pero intenta evitar varios redireccionamientos siempre que sea posible, por ejemplo, usando varios acortadores de vínculos cuando compartas vínculos. Asegúrate de que la URL proporcionada a los anunciantes o boletines informativos sea la URL final correcta para no agregar otro redireccionamiento a los que usan esos servicios.
Otra fuente importante de tiempo de redireccionamiento pueden ser los redireccionamientos de HTTP a HTTPS. Una forma de evitar esto es usar el encabezado Strict-Transport-Security (HSTS), que aplicará HTTPS en la primera visita a un origen y, luego, le indicará al navegador que acceda de inmediato al origen a través del esquema HTTPS en visitas futuras.
Una vez que tengas una buena política de HSTS, puedes acelerar las cosas en la primera visita a un origen agregando tu sitio a la lista de precarga de HSTS.
Cómo transmitir el lenguaje de marcado al navegador
Los navegadores están optimizados para procesar el lenguaje de marcado de manera eficiente cuando se transmite, lo que significa que el lenguaje de marcado se maneja en fragmentos a medida que llega del servidor. Esto es fundamental cuando se trata de cargas útiles de marcado grandes, ya que significa que el navegador puede analizar los fragmentos de marcado de forma incremental, en lugar de esperar a que llegue toda la respuesta antes de que pueda comenzar el análisis.
Si bien los navegadores son excelentes para controlar el lenguaje de marcado de transmisión, es fundamental que hagas todo lo posible para que esa transmisión fluya, de modo que esos bits iniciales de lenguaje de marcado estén en camino lo antes posible. Si el backend está retrasando las cosas, eso es un problema. Debido a que las pilas de backend son numerosas, sería imposible abarcar cada una de ellas y los problemas que podrían surgir en cada una en esta guía.
React, por ejemplo, y otros frameworks que pueden renderizar el lenguaje de marcado a pedido en el servidor, han usado un enfoque síncrono para la renderización del servidor. Sin embargo, las versiones más recientes de React implementaron métodos del servidor para transmitir el lenguaje de marcado a medida que se renderiza. Esto significa que no tienes que esperar a que un método de la API del servidor de React renderice toda la respuesta antes de que se envíe.
Otra forma de garantizar que el marcado se transmita al navegador rápidamente es usar la renderización estática, que genera archivos HTML durante el tiempo de compilación. Con el archivo completo disponible de inmediato, los servidores web pueden comenzar a enviarlo de inmediato, y la naturaleza inherente de HTTP generará un marcado de transmisión. Si bien este enfoque no es adecuado para todas las páginas de todos los sitios web, como las que requieren una respuesta dinámica como parte de la experiencia del usuario, puede ser beneficioso para las páginas que no requieren que el lenguaje de marcado se personalice para un usuario específico.
Usa un Service Worker
La API de Service Worker puede tener un gran impacto en el TTFB tanto de los documentos como de los recursos que cargan. El motivo es que un service worker actúa como proxy entre el navegador y el servidor, pero el impacto en el TTFB de tu sitio web depende de cómo configures tu service worker y de si esa configuración se alinea con los requisitos de tu aplicación.
- Usa una estrategia de stale-while-revalidate para los recursos. Si un recurso está en la caché del service worker, ya sea un documento o un recurso que el documento requiere, la estrategia stale-while-revalidate entregará ese recurso desde la caché primero y, luego, descargará ese recurso en segundo plano y lo entregará desde la caché para futuras interacciones.
- Si tienes recursos de documentos que no cambian con frecuencia, usar una estrategia de stale-while-revalidate puede hacer que el TTFB de una página sea casi instantáneo. Sin embargo, esto no funciona tan bien si tu sitio web envía un lenguaje de marcado generado de forma dinámica, como el lenguaje de marcado que cambia según si un usuario está autenticado. En esos casos, siempre querrás acceder a la red primero para que el documento esté lo más actualizado posible.
- Si tu documento carga recursos no críticos que cambian con cierta frecuencia, pero recuperar el recurso obsoleto no afectará en gran medida la experiencia del usuario (como imágenes seleccionadas u otros recursos que no son críticos), el TTFB de esos recursos se puede reducir considerablemente con una estrategia de stale-while-revalidate.
- Usa el modelo de shell de la app para las aplicaciones renderizadas del cliente. Este modelo se adapta mejor a las SPA en las que el "shell" de la página se puede entregar de inmediato desde la caché del Service Worker, y el contenido dinámico de la página se completa y renderiza más adelante en el ciclo de vida de la página.
Usa 103 Early Hints para los recursos críticos para la renderización
Sin importar qué tan bien se optimice el backend de tu aplicación, es posible que el servidor aún deba realizar una cantidad significativa de trabajo para preparar una respuesta, incluido el trabajo costoso (pero necesario) de la base de datos que retrasa la llegada de la respuesta de navegación tan rápido como podría. El efecto potencial de esto es que algunos recursos posteriores críticos para la renderización podrían retrasarse, como CSS o, en algunos casos, JavaScript que renderiza el lenguaje de marcado en el cliente.
El encabezado 103 Early Hints es un código de respuesta anticipada que el servidor puede enviar al navegador mientras el backend está ocupado preparando el lenguaje de marcado. Este encabezado se puede usar para sugerirle al navegador que hay recursos críticos para la renderización que la página debería comenzar a descargar mientras se prepara el lenguaje de marcado. En el caso de los navegadores compatibles, el efecto puede ser un renderizado de documentos más rápido (CSS) y una carga de páginas más veloz.
Un inconveniente de las sugerencias anticipadas 103 es que, al igual que el almacenamiento en caché, pueden ocultar el TTFB "real" de un sitio. Si una infraestructura de servidor es lenta (ya sea porque no tiene la potencia suficiente o porque el código necesita optimización), esto puede ser menos evidente cuando se usa 103 Early Hints, ya que el TTFB parece rápido. Los sitios que usan 103 Early Hints deben considerar medir el tiempo real del servidor (aunque Server-Timing o finalResponseHeadersStart de la API de PerformanceNavigationTiming).
Conclusión
Dado que hay tantas combinaciones de pilas de aplicaciones de backend, no existe un artículo que pueda abarcar todo lo que puedes hacer para reducir el TTFB de tu sitio web. Sin embargo, estas son algunas opciones que puedes explorar para intentar que las cosas funcionen un poco más rápido en el servidor.
Al igual que con la optimización de cada métrica, el enfoque es muy similar: mide tu TTFB en el campo, usa herramientas de laboratorio para analizar las causas y, luego, aplica optimizaciones cuando sea posible. No todas las técnicas que se mencionan aquí pueden ser viables para tu situación, pero algunas sí lo serán. Como siempre, deberás supervisar de cerca los datos de campo y realizar los ajustes necesarios para garantizar la experiencia del usuario más rápida posible.
Imagen hero de Taylor Vick, extraída de Unsplash.