

مقدمة
توفر Media Source Extensions (MSE)
إمكانية التحكم في التخزين المؤقت والتشغيل الموسعين لعنصرَي HTML5 <audio> و
<video>. في ما يلي، سنرى كيف يمكن استخدام هذه الإضافات للمحتوى الصوتي، وتحديدًا لتشغيله بدون انقطاع
، مع أنّها طُوّرت في الأصل لتسهيل مشغّلات الفيديو المستندة إلى البث الديناميكي التكيُّفي عبر HTTP (DASH)
.
من المحتمل أنّك استمعت إلى ألبوم موسيقي تتدفق فيه الأغاني بسلاسة بين المقاطع، وربما تستمع إلى أحدها الآن. ينشئ الفنّانون تجارب التشغيل بدون انقطاع هذه كخيار فنّي، بالإضافة إلى أنّها كانت من خصائص أسطوانات الفينيل و الأقراص المضغوطة التي كان يتم تسجيل الصوت فيها كتيار مستمر. لسوء الحظ، غالبًا ما يتم فقدان هذه التجربة السمعية السلسة اليوم بسبب طريقة عمل برامج ترميز الصوت الحديثة، مثل MP3 و AAC.
سنتناول تفاصيل السبب أدناه، ولكن لنبدأ الآن بعرض توضيحي. في ما يلي أول ثلاثين ثانية من فيلم Sintel الرائع مقسّمة إلى خمسة ملفات MP3 منفصلة وإعادة تجميعها باستخدام MSE. تشير الخطوط الحمراء إلى الفجوات التي تم إدخالها أثناء إنشاء (ترميز) كل ملف MP3، وستسمع أخطاء في هذه النقاط.
تجربة سيئة! هذه ليست تجربة رائعة، ويمكننا تقديم تجربة أفضل. باستخدام ملفات MP3 نفسها في العرض التوضيحي أعلاه، يمكننا استخدام MSE لإزالة هذه الفجوات المزعجة. تشير الخطوط الخضراء في العرض التوضيحي التالي إلى مكان ربط الملفات وإزالة الفجوات. على Chrome 38 والإصدارات الأحدث، سيتم تشغيل هذه الملفات بسلاسة.
هناك طرق متنوعة لإنشاء محتوى بدون انقطاع. لأغراض هذا العرض التوضيحي، سنركّز على نوع الملفات التي قد تكون متوفرة لدى المستخدم العادي. تم ترميز كل ملف على حدة بدون مراعاة المقاطع الصوتية التي تسبقه أو تليه.
الإعداد الأساسي
أولاً، لنرجع إلى الخلف ونشرح الإعداد الأساسي لمثيل MediaSource.
كما يوحي الاسم، فإنّ Media Source Extensions هي مجرد إضافات لعناصر الوسائط الحالية. في ما يلي، نخصّص
Object URL،
الذي يمثّل مثيل MediaSource، لسمة المصدر لعنصر صوتي
، تمامًا كما لو كنت تضبط عنوان URL عاديًا.
var audio = document.createElement('audio');
var mediaSource = new MediaSource();
var SEGMENTS = 5;
mediaSource.addEventListener('sourceopen', function () {
var sourceBuffer = mediaSource.addSourceBuffer('audio/mpeg');
function onAudioLoaded(data, index) {
// Append the ArrayBuffer data into our new SourceBuffer.
sourceBuffer.appendBuffer(data);
}
// Retrieve an audio segment via XHR. For simplicity, we're retrieving the
// entire segment at once, but we could also retrieve it in chunks and append
// each chunk separately. MSE will take care of assembling the pieces.
GET('sintel/sintel_0.mp3', function (data) {
onAudioLoaded(data, 0);
});
});
audio.src = URL.createObjectURL(mediaSource);
بعد ربط عنصر MediaSource، سيتم إجراء بعض عمليات التهيئة
وسيتم في النهاية إطلاق حدث sourceopen، وعند هذه النقطة يمكننا إنشاء
SourceBuffer. في المثال أعلاه، ننشئ عنصرًا من النوع audio/mpeg، يمكنه تحليل مقاطع MP3 وفك ترميزها، وهناك عدة أنواع أخرى متاحة.
الأشكال الموجية الشاذة
سنعود إلى الرمز البرمجي بعد لحظة، ولكن لنلقِ نظرة الآن عن كثب على الملف الذي ألحقناه للتو، وتحديدًا على نهايته. في ما يلي رسم بياني لآخر 3000 عينة تم حساب متوسطها على قناتَي الصوت من المقطع sintel_0.mp3. كل بكسل على الخط الأحمر هو
عينة ذات فاصلة عائمة
في النطاق [-1.0, 1.0].

ما سبب كل هذه العينات الصامتة (الصفرية)؟ يرجع ذلك في الواقع إلى خصائص الضغط التي تم إدخالها أثناء الترميز. يُدخل كل برنامج ترميز تقريبًا نوعًا من المساحة المتروكة. في هذه الحالة، أضاف برنامج LAME بالضبط 576 عينة مساحة متروكة إلى نهاية الملف.
بالإضافة إلى المساحة المتروكة في النهاية، كان لكل ملف مساحة متروكة تمت إضافتها إلى البداية. إذا ألقينا نظرة على المقطع sintel_1.mp3، سنرى 576 عينة أخرى من المساحة المتروكة في البداية. يختلف مقدار
المساحة المتروكة حسب برنامج الترميز والمحتوى، ولكننا نعرف القيم الدقيقة استنادًا إلى
metadata المضمّنة في كل ملف.
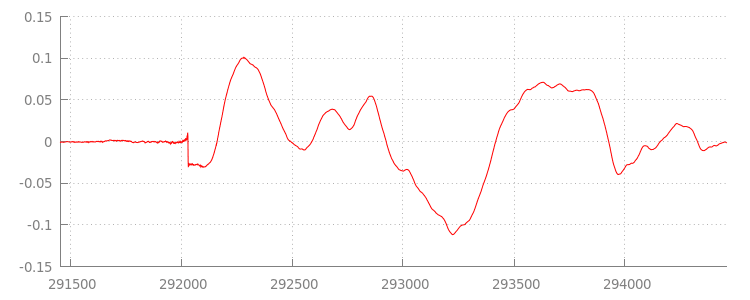
إنّ أقسام الصمت في بداية ونهاية كل ملف هي ما يسبب الأخطاء بين المقاطع في العرض التوضيحي السابق. لتحقيق التشغيل بدون انقطاع، علينا إزالة أقسام الصمت هذه. لحسن الحظ، يمكن إجراء ذلك بسهولة باستخدام MediaSource. في ما يلي، سنعدّل طريقة onAudioLoaded() لاستخدام
نافذة الإلحاق وإزاحة
الطابع الزمني لإزالة هذا الصمت.
مثال على الرمز البرمجي
function onAudioLoaded(data, index) {
// Parsing gapless metadata is unfortunately non trivial and a bit messy, so
// we'll glaze over it here; see the appendix for details.
// ParseGaplessData() will return a dictionary with two elements:
//
// audioDuration: Duration in seconds of all non-padding audio.
// frontPaddingDuration: Duration in seconds of the front padding.
//
var gaplessMetadata = ParseGaplessData(data);
// Each appended segment must be appended relative to the next. To avoid any
// overlaps, we'll use the end timestamp of the last append as the starting
// point for our next append or zero if we haven't appended anything yet.
var appendTime = index > 0 ? sourceBuffer.buffered.end(0) : 0;
// Simply put, an append window allows you to trim off audio (or video) frames
// which fall outside of a specified time range. Here, we'll use the end of
// our last append as the start of our append window and the end of the real
// audio data for this segment as the end of our append window.
sourceBuffer.appendWindowStart = appendTime;
sourceBuffer.appendWindowEnd = appendTime + gaplessMetadata.audioDuration;
// The timestampOffset field essentially tells MediaSource where in the media
// timeline the data given to appendBuffer() should be placed. I.e., if the
// timestampOffset is 1 second, the appended data will start 1 second into
// playback.
//
// MediaSource requires that the media timeline starts from time zero, so we
// need to ensure that the data left after filtering by the append window
// starts at time zero. We'll do this by shifting all of the padding we want
// to discard before our append time (and thus, before our append window).
sourceBuffer.timestampOffset =
appendTime - gaplessMetadata.frontPaddingDuration;
// When appendBuffer() completes, it will fire an updateend event signaling
// that it's okay to append another segment of media. Here, we'll chain the
// append for the next segment to the completion of our current append.
if (index == 0) {
sourceBuffer.addEventListener('updateend', function () {
if (++index < SEGMENTS) {
GET('sintel/sintel_' + index + '.mp3', function (data) {
onAudioLoaded(data, index);
});
} else {
// We've loaded all available segments, so tell MediaSource there are no
// more buffers which will be appended.
mediaSource.endOfStream();
URL.revokeObjectURL(audio.src);
}
});
}
// appendBuffer() will now use the timestamp offset and append window settings
// to filter and timestamp the data we're appending.
//
// Note: While this demo uses very little memory, more complex use cases need
// to be careful about memory usage or garbage collection may remove ranges of
// media in unexpected places.
sourceBuffer.appendBuffer(data);
}
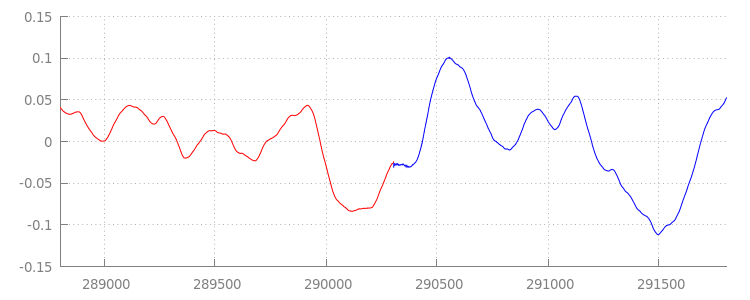
شكل موجي سلس
لنرى ما حقّقه الرمز البرمجي الجديد الرائع من خلال إلقاء نظرة أخرى على الشكل الموجي بعد تطبيق نوافذ الإلحاق. في ما يلي، يمكنك ملاحظة أنّه تمت إزالة قسم الصمت في نهاية sintel_0.mp3 (باللون الأحمر) وقسم الصمت في بداية sintel_1.mp3 (باللون الأزرق)، ما يمنحنا انتقالاً سلسًا بين المقاطع.
الخاتمة
بهذا، نكون قد ربطنا جميع المقاطع الخمسة بسلاسة في مقطع واحد ووصلنا بالتالي إلى نهاية العرض التوضيحي. قبل أن ننتقل، ربما لاحظت أنّ طريقة onAudioLoaded() لا تأخذ في الاعتبار الحاويات أو برامج الترميز.
هذا يعني أنّ كل هذه التقنيات ستعمل بغض النظر عن نوع الحاوية أو برنامج الترميز. في ما يلي، يمكنك إعادة تشغيل العرض التوضيحي الأصلي لملف MP4 مجزّأ جاهز للبث الديناميكي التكيُّفي عبر HTTP بدلاً من MP3.
إذا أردت معرفة المزيد، يمكنك الاطّلاع على الملاحق أدناه للحصول على نظرة أكثر تعمّقًا على إنشاء محتوى بدون انقطاع وتحليل البيانات الوصفية. يمكنك أيضًا استكشاف
gapless.js لإلقاء نظرة عن كثب على
الرمز البرمجي الذي يشغّل هذا العرض التوضيحي.
شكرًا على القراءة.
الملحق "أ": إنشاء محتوى بدون انقطاع
قد يكون من الصعب إنشاء محتوى بدون انقطاع بشكل صحيح. في ما يلي، سنشرح بالتفصيل كيفية إنشاء وسائط Sintel المستخدَمة في هذا العرض التوضيحي. للبدء، ستحتاج إلى نسخة من الـ موسيقى التصويرية بتنسيق FLAC بدون فقدان البيانات لفيلم Sintel، ولأغراض التوثيق، تم تضمين SHA1 أدناه. بالنسبة إلى الأدوات، ستحتاج إلى FFmpeg وMP4Box و LAME وتثبيت OSX مع afconvert.
unzip Jan_Morgenstern-Sintel-FLAC.zip
sha1sum 1-Snow_Fight.flac
# 0535ca207ccba70d538f7324916a3f1a3d550194 1-Snow_Fight.flac
أولاً، سنقسم أول 31.5 ثانية من المقطع 1-Snow_Fight.flac. نريد أيضًا إضافة تأثير التلاشي لمدة 2.5 ثانية بدءًا من الثانية 28 لتجنُّب أي نقرات عند انتهاء التشغيل. باستخدام سطر أوامر FFmpeg أدناه، يمكننا إجراء كل ذلك ووضع النتائج في sintel.flac.
ffmpeg -i 1-Snow_Fight.flac -t 31.5 -af "afade=t=out:st=28:d=2.5" sintel.flac
بعد ذلك، سنقسم الملف إلى 5 ملفات موجية
مدة كل منها 6.5 ثانية، وأسهل طريقة هي استخدام الملفات الموجية لأنّ كل برامج الترميز تقريبًا
تتيح إدخالها. مرة أخرى، يمكننا إجراء ذلك بدقة باستخدام FFmpeg، وبعد ذلك سنحصل على: sintel_0.wav وsintel_1.wav وsintel_2.wav وsintel_3.wav وsintel_4.wav.
ffmpeg -i sintel.flac -acodec pcm_f32le -map 0 -f segment \
-segment_list out.list -segment_time 6.5 sintel_%d.wav
بعد ذلك، لننشئ ملفات MP3. يتضمّن برنامج LAME عدة خيارات لإنشاء محتوى بدون انقطاع. إذا كنت تتحكّم في المحتوى، يمكنك استخدام --nogap مع عملية ترميز دفعة لجميع الملفات لتجنُّب المساحة المتروكة بين المقاطع تمامًا.
لأغراض هذا العرض التوضيحي، نريد هذه المساحة المتروكة، لذا سنستخدم ترميز VBR عالي الجودة عاديًا للملفات الموجية.
lame -V=2 sintel_0.wav sintel_0.mp3
lame -V=2 sintel_1.wav sintel_1.mp3
lame -V=2 sintel_2.wav sintel_2.mp3
lame -V=2 sintel_3.wav sintel_3.mp3
lame -V=2 sintel_4.wav sintel_4.mp3
هذا كل ما هو ضروري لإنشاء ملفات MP3. لننتقل الآن إلى إنشاء ملفات MP4 المجزّأة. سنتبع تعليمات Apple لإنشاء الوسائط التي تم إعدادها لـ iTunes. في ما يلي، سنحوّل الملفات الموجية إلى ملفات CAF وسيطة، وفقًا للتعليمات، قبل ترميزها بتنسيق AAC في حاوية MP4 باستخدام المعلمات المقترَحة.
afconvert sintel_0.wav sintel_0_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_1.wav sintel_1_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_2.wav sintel_2_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_3.wav sintel_3_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_4.wav sintel_4_intermediate.caf -d 0 -f caff \
--soundcheck-generate
afconvert sintel_0_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_0.m4a
afconvert sintel_1_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_1.m4a
afconvert sintel_2_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_2.m4a
afconvert sintel_3_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_3.m4a
afconvert sintel_4_intermediate.caf -d aac -f m4af -u pgcm 2 --soundcheck-read \
-b 256000 -q 127 -s 2 sintel_4.m4a
لدينا الآن عدة ملفات M4A يجب تجزئتها بشكل مناسب قبل أن يمكن استخدامها مع
MediaSource. لأغراضنا، سنستخدم حجم مقطع يبلغ ثانية واحدة. سيكتب MP4Box كل ملف MP4 مجزّأ باسم sintel_#_dashinit.mp4 بالإضافة إلى بيان MPEG-DASH (sintel_#_dash.mpd) يمكن تجاهله.
MP4Box -dash 1000 sintel_0.m4a && mv sintel_0_dashinit.mp4 sintel_0.mp4
MP4Box -dash 1000 sintel_1.m4a && mv sintel_1_dashinit.mp4 sintel_1.mp4
MP4Box -dash 1000 sintel_2.m4a && mv sintel_2_dashinit.mp4 sintel_2.mp4
MP4Box -dash 1000 sintel_3.m4a && mv sintel_3_dashinit.mp4 sintel_3.mp4
MP4Box -dash 1000 sintel_4.m4a && mv sintel_4_dashinit.mp4 sintel_4.mp4
rm sintel_{0,1,2,3,4}_dash.mpd
هذا كل شيء! لدينا الآن ملفات MP4 وMP3 مجزّأة تتضمّن البيانات الوصفية الصحيحة اللازمة للتشغيل بدون انقطاع. يمكنك الاطّلاع على الملحق "ب" لمزيد من التفاصيل حول شكل هذه البيانات الوصفية.
الملحق "ب": تحليل البيانات الوصفية بدون انقطاع
تمامًا مثل إنشاء محتوى بدون انقطاع، قد يكون تحليل البيانات الوصفية بدون انقطاع أمرًا صعبًا لأنّه لا توجد طريقة تخزين موحّدة. في ما يلي، سنشرح كيف يخزّن برنامجَا الترميز الأكثر شيوعًا، LAME وiTunes، البيانات الوصفية بدون انقطاع. لنبدأ بإعداد بعض الطرق المساعدة ومخطط لـ ParseGaplessData() المستخدَمة أعلاه.
// Since most MP3 encoders store the gapless metadata in binary, we'll need a
// method for turning bytes into integers. Note: This doesn't work for values
// larger than 2^30 since we'll overflow the signed integer type when shifting.
function ReadInt(buffer) {
var result = buffer.charCodeAt(0);
for (var i = 1; i < buffer.length; ++i) {
result <<= 8;
result += buffer.charCodeAt(i);
}
return result;
}
function ParseGaplessData(arrayBuffer) {
// Gapless data is generally within the first 512 bytes, so limit parsing.
var byteStr = new TextDecoder().decode(arrayBuffer.slice(0, 512));
var frontPadding = 0, endPadding = 0, realSamples = 0;
// ... we'll fill this in as we go below.
سنشرح أولاً تنسيق البيانات الوصفية لبرنامج iTunes من Apple لأنّه الأسهل تحليلًا وشرحًا. ضمن ملفات MP3 وM4A، يكتب iTunes (وafconvert) قسمًا قصيرًا بتنسيق ASCII على النحو التالي:
iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00
تتم كتابة هذا القسم داخل علامة ID3 ضمن حاوية MP3 وداخل عنصر بيانات وصفية ضمن حاوية MP4. لأغراضنا، يمكننا تجاهل الرمز المميز الأول 0000000. الرموز المميزة الثلاثة التالية هي المساحة المتروكة في البداية والمساحة المتروكة في النهاية وعدد العينات الإجمالي بدون مساحة متروكة. إنّ قسمة كل من هذه الرموز على معدّل عيّنات الصوت يمنحنا مدة كل منها.
// iTunes encodes the gapless data as hex strings like so:
//
// 'iTunSMPB[ 26 bytes ]0000000 00000840 000001C0 0000000000046E00'
// 'iTunSMPB[ 26 bytes ]####### frontpad endpad real samples'
//
// The approach here elides the complexity of actually parsing MP4 atoms. It
// may not work for all files without some tweaks.
var iTunesDataIndex = byteStr.indexOf('iTunSMPB');
if (iTunesDataIndex != -1) {
var frontPaddingIndex = iTunesDataIndex + 34;
frontPadding = parseInt(byteStr.substr(frontPaddingIndex, 8), 16);
var endPaddingIndex = frontPaddingIndex + 9;
endPadding = parseInt(byteStr.substr(endPaddingIndex, 8), 16);
var sampleCountIndex = endPaddingIndex + 9;
realSamples = parseInt(byteStr.substr(sampleCountIndex, 16), 16);
}
على الجانب الآخر، ستخزّن معظم برامج ترميز MP3 المفتوحة المصدر البيانات الوصفية بدون انقطاع ضمن رأس Xing خاص موضوع داخل إطار MPEG صامت (صامت حتى يتمكّن برنامج فك الترميز الذي لا يفهم رأس Xing من تشغيل الصمت ببساطة). لسوء الحظ، لا تكون هذه العلامة موجودة دائمًا وتتضمّن عددًا من الحقول الاختيارية. لأغراض هذا العرض التوضيحي، نتحكّم في الوسائط، ولكن من الناحية العملية، ستكون هناك حاجة إلى بعض عمليات التحقّق الإضافية لمعرفة متى تكون البيانات الوصفية بدون انقطاع متاحة فعليًا.
أولاً، سنحلّل عدد العينات الإجمالي. لتبسيط الأمر، سنقرأ هذا العدد من
رأس Xing، ولكن يمكن إنشاؤه من رأس صوت MPEG العادي
.
يمكن تمييز رؤوس Xing بعلامة Xing أو Info. بعد 4 بايتات بالضبط من هذه العلامة، هناك 32 بتًا تمثّل العدد الإجمالي للإطارات في الملف، وسيمنحنا ضرب هذه القيمة في عدد العينات لكل إطار العدد الإجمالي للعينات في الملف.
// Xing padding is encoded as 24bits within the header. Note: This code will
// only work for Layer3 Version 1 and Layer2 MP3 files with XING frame counts
// and gapless information. See the following document for more details:
// http://www.codeproject.com/Articles/8295/MPEG-Audio-Frame-Header
var xingDataIndex = byteStr.indexOf('Xing');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Info');
if (xingDataIndex != -1) {
// See section 2.3.1 in the link above for the specifics on parsing the Xing
// frame count.
var frameCountIndex = xingDataIndex + 8;
var frameCount = ReadInt(byteStr.substr(frameCountIndex, 4));
// For Layer3 Version 1 and Layer2 there are 1152 samples per frame. See
// section 2.1.5 in the link above for more details.
var paddedSamples = frameCount * 1152;
// ... we'll cover this below.
بعد أن أصبح لدينا العدد الإجمالي للعينات، يمكننا الانتقال إلى قراءة عدد عينات المساحة المتروكة. استنادًا إلى برنامج الترميز، قد تتم كتابة ذلك ضمن علامة LAME أو Lavf متداخلة في رأس Xing. بعد 17 بايتًا بالضبط من هذا الرأس، هناك 3 بايتات تمثّل المساحة المتروكة في البداية والنهاية في 12 بتًا لكل منهما على التوالي.
xingDataIndex = byteStr.indexOf('LAME');
if (xingDataIndex == -1) xingDataIndex = byteStr.indexOf('Lavf');
if (xingDataIndex != -1) {
// See http://gabriel.mp3-tech.org/mp3infotag.html#delays for details of
// how this information is encoded and parsed.
var gaplessDataIndex = xingDataIndex + 21;
var gaplessBits = ReadInt(byteStr.substr(gaplessDataIndex, 3));
// Upper 12 bits are the front padding, lower are the end padding.
frontPadding = gaplessBits >> 12;
endPadding = gaplessBits & 0xFFF;
}
realSamples = paddedSamples - (frontPadding + endPadding);
}
return {
audioDuration: realSamples * SECONDS_PER_SAMPLE,
frontPaddingDuration: frontPadding * SECONDS_PER_SAMPLE
};
}
بهذا، أصبح لدينا دالة كاملة لتحليل الغالبية العظمى من المحتوى بدون انقطاع. من المؤكد أنّ هناك حالات خاصة، لذا يُنصح بالحذر قبل استخدام رمز برمجي مشابه في مرحلة الإنتاج.
الملحق "ج": حول جمع البيانات غير الضرورية
يتم جمع البيانات غير الضرورية بشكل نشط من الذاكرة التي تنتمي إلى مثيلات SourceBuffer
وفقًا لنوع المحتوى والحدود الخاصة بالمنصّة وموضع التشغيل الحالي.
في Chrome، سيتم أولاً استرداد الذاكرة من المخازن المؤقتة التي تم تشغيلها من قبل.
ومع ذلك، إذا تجاوز استخدام الذاكرة الحدود الخاصة بالمنصّة، ستتم إزالة الذاكرة من المخازن المؤقتة التي لم يتم تشغيلها.
عندما يصل التشغيل إلى فجوة في المخطط الزمني بسبب الذاكرة المستردة، قد يحدث خطأ إذا كانت الفجوة صغيرة بما يكفي أو قد يتوقف التشغيل تمامًا إذا كانت الفجوة كبيرة جدًا. لا يقدّم أي من هذين السيناريوهَين تجربة رائعة للمستخدم، لذا من المهم تجنُّب إلحاق الكثير من البيانات في وقت واحد وإزالة النطاقات يدويًا من المخطط الزمني للوسائط التي لم تعد ضرورية.
يمكن إزالة النطاقات من خلال الـ
remove()
طريقة في كل SourceBuffer، التي تأخذ نطاق [start, end] بالثواني.
على غرار appendBuffer()، سيطلق كل remove() حدث updateend عند اكتماله. يجب عدم إصدار عمليات إزالة أو إلحاق أخرى إلى أن يتم إطلاق الحدث.
على Chrome لأجهزة الكمبيوتر، يمكنك الاحتفاظ بحوالي 12 ميغابايت من المحتوى الصوتي و150 ميغابايت من محتوى الفيديو في الذاكرة في وقت واحد. يجب عدم الاعتماد على هذه القيم على مستوى المتصفحات أو المنصات، على سبيل المثال، من المؤكد أنّها لا تمثّل الأجهزة الجوّالة.
لا يؤثّر جمع البيانات غير الضرورية إلا في البيانات التي تمت إضافتها إلى SourceBuffers، ولا توجد حدود لمقدار البيانات التي يمكنك الاحتفاظ بها في المخزن المؤقت في متغيرات JavaScript. يمكنك أيضًا إعادة إلحاق البيانات نفسها في الموضع نفسه إذا لزم الأمر.