

대규모 언어 모델 (LLM)의 'L'은 대규모를 의미하지만 실제로는 더 미묘한 차이가 있습니다. 일부 LLM은 수조 개의 매개변수를 포함하고 있고, 다른 LLM은 훨씬 적은 수의 매개변수로 효과적으로 작동합니다.
몇 가지 실제 사례와 다양한 모델 크기의 실질적인 의미를 살펴보세요.
LLM 크기 및 크기 클래스
웹 개발자는 리소스의 크기를 다운로드 크기로 생각하는 경향이 있습니다. 문서화된 모델 크기는 대신 매개변수 수를 나타냅니다. 예를 들어 Gemma 2B는 20억 개의 매개변수가 있는 Gemma를 나타냅니다.
LLM에는 수십만, 수백만, 수십억, 심지어 수조 개의 매개변수가 있을 수 있습니다.
대규모 LLM은 소규모 LLM보다 매개변수가 더 많으므로 더 복잡한 언어 관계를 포착하고 미묘한 프롬프트를 처리할 수 있습니다. 또한 대규모 데이터 세트로 학습되는 경우가 많습니다.
20억 또는 70억과 같은 특정 모델 크기가 일반적이라는 것을 눈치채셨을 수도 있습니다. 예를 들면 Gemma 2B, Gemma 7B 또는 Mistral 7B입니다. 모델 크기 클래스는 대략적인 그룹입니다. 예를 들어 Gemma 2B에는 20억 개의 매개변수가 대략 있지만 정확하지는 않습니다.
모델 크기 클래스는 LLM 성능을 측정하는 실용적인 방법을 제공합니다. 권투의 체급과 비슷하다고 생각하면 됩니다. 동일한 크기 클래스의 모델은 더 쉽게 비교할 수 있습니다. 두 개의 2B 모델은 비슷한 성능을 제공해야 합니다.
하지만 특정 작업의 경우 더 작은 모델이 더 큰 모델과 동일한 성능을 발휘할 수 있습니다.

GPT-4, Gemini Pro 또는 Ultra와 같은 최신 최신 LLM의 모델 크기는 항상 공개되지는 않지만 수백억 개 또는 수조 개의 매개변수로 추정됩니다.

일부 모델은 이름에 매개변수 수를 표시하지 않습니다. 일부 모델에는 버전 번호가 접미사로 추가됩니다. 예를 들어 Gemini 1.5 Pro는 버전 1 다음에 오는 모델의 1.5 버전을 나타냅니다.
LLM 사용 여부
모델이 너무 작아서 LLM이 될 수 없는 경우는 언제인가요? LLM의 정의는 AI 및 ML 커뮤니티 내에서 다소 유동적일 수 있습니다.
일부에서는 수십억 개의 매개변수가 있는 가장 큰 모델만 LLM으로 간주하고 DistilBERT와 같은 소형 모델은 간단한 NLP 모델로 간주합니다. 다른 LLM 정의에는 DistilBERT와 같이 작지만 강력한 모델도 포함됩니다.
기기 내 사용 사례를 위한 소형 LLM
더 큰 LLM은 추론을 위해 많은 저장공간과 컴퓨팅 성능이 필요합니다. 특정 하드웨어(예: TPU)가 있는 강력한 전용 서버에서 실행해야 합니다.
웹 개발자에게 중요한 점은 모델이 사용자의 기기에 다운로드되어 실행될 만큼 작을지 여부입니다.
하지만 대답하기 어려운 질문입니다. 현재로서는 다음과 같은 몇 가지 이유로 '이 모델은 대부분의 미드레인지 기기에서 실행할 수 있습니다'를 쉽게 알 수 있는 방법이 없습니다.
- 기기 기능은 메모리, GPU/CPU 사양 등에 따라 크게 다릅니다. 저가형 Android 휴대전화와 NVIDIA® RTX 노트북은 매우 다릅니다. 사용자가 사용하는 기기에 관한 데이터 포인트가 있을 수 있습니다. 웹에 액세스하는 데 사용되는 기준 기기에 대한 정의는 아직 없습니다.
- 모델 또는 모델이 실행되는 프레임워크가 특정 하드웨어에서 실행되도록 최적화될 수 있습니다.
- 특정 LLM을 다운로드하여 특정 기기에서 실행할 수 있는지 확인하는 프로그래매틱 방법은 없습니다. 기기의 다운로드 기능은 GPU의 VRAM 양과 같은 요인에 따라 달라집니다.
하지만 경험적 지식은 있습니다. 현재 수백만 개에서 수십억 개 매개변수가 있는 일부 모델은 브라우저에서 소비자용 기기로 실행할 수 있습니다.
예를 들면 다음과 같습니다.
- MediaPipe LLM 추론 API를 사용하는 Gemma 2B (CPU 전용 기기에도 적합) 사용해 보세요.
- Transformers.js를 사용한 DistilBERT
아직 초기 단계에 있는 분야입니다. 다음과 같이 환경이 변화할 것으로 예상됩니다.
- WebAssembly 및 WebGPU 혁신과 함께 더 많은 라이브러리, 새로운 라이브러리, 최적화에 WebGPU 지원이 제공되면서 사용자 기기에서 다양한 크기의 LLM을 효율적으로 실행할 수 있을 것으로 기대됩니다.
- 신규 축소 기법을 통해 소형의 고성능 LLM이 점점 더 보편화될 것으로 예상됩니다.
소규모 LLM 고려사항
소규모 LLM을 사용할 때는 항상 성능과 다운로드 크기를 고려해야 합니다.
성능
모델의 기능은 사용 사례에 따라 크게 달라집니다. 사용 사례에 맞게 미세 조정된 소규모 LLM이 더 큰 범용 LLM보다 성능이 더 좋을 수 있습니다.
하지만 동일한 모델 제품군 내에서 더 작은 LLM은 더 큰 LLM보다 성능이 떨어집니다. 동일한 사용 사례에서 더 작은 LLM을 사용할 때는 일반적으로 더 많은 빠른 엔지니어링 작업을 해야 합니다.
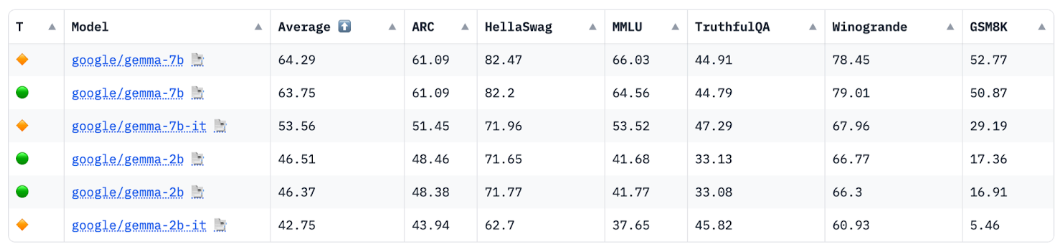
출처: HuggingFace Open LLM Leaderboard, 2024년 4월
다운로드 크기
매개변수가 많을수록 다운로드 크기가 커지며, 이는 모델이 작다고 하더라도 기기 내 사용 사례에 적절하게 다운로드될 수 있는지 여부에도 영향을 미칩니다.
매개변수 수를 기반으로 모델의 다운로드 크기를 계산하는 기법이 있지만 복잡할 수 있습니다.
2024년 초부터 모델 다운로드 크기는 거의 문서화되지 않습니다. 따라서 기기 내 및 브라우저 내 사용 사례의 경우 Chrome DevTools의 Network 패널 또는 다른 브라우저 개발자 도구에서 다운로드 크기를 실험적으로 확인하는 것이 좋습니다.

Gemma는 MediaPipe LLM 추론 API와 함께 사용됩니다. DistilBERT는 Transformers.js와 함께 사용됩니다.
모델 축소 기법
모델의 메모리 요구사항을 크게 줄이는 여러 기법이 있습니다.
- LoRA (Low-Rank Adaptation): 선행 학습된 가중치가 고정되는 미세 조정 기법입니다. LoRA에 대해 자세히 알아보기
- 예상치 못한 결과 제거: 모델에서 덜 중요한 가중치를 삭제하여 크기를 줄입니다.
- 양자화: 가중치의 정밀도를 부동 소수점 수 (예: 32비트)에서 낮은 비트 표현 (예: 8비트)으로 줄입니다.
- 지식 증류: 더 큰 사전 학습된 모델의 동작을 모방하도록 더 작은 모델을 학습합니다.
- 매개변수 공유: 모델의 여러 부분에 동일한 가중치를 사용하여 고유한 매개변수의 총 개수를 줄입니다.