
Di balik layar browser web modern


Pengantar
Panduan komprehensif tentang operasi internal WebKit dan Gecko ini adalah hasil dari banyak riset yang dilakukan oleh developer Israel, Tali Garsiel. Selama beberapa tahun, ia meninjau semua data yang dipublikasikan tentang internal browser dan menghabiskan banyak waktu untuk membaca kode sumber browser web. Ia menulis:
Sebagai developer web, mempelajari bagian internal operasi browser akan membantu Anda membuat keputusan yang lebih baik dan mengetahui justifikasi di balik praktik terbaik pengembangan. Meskipun dokumen ini cukup panjang, sebaiknya Anda meluangkan waktu untuk mempelajarinya. Anda tidak akan kecewa.
Paul Irish, Chrome Developer Relations
Pengantar
Browser web adalah software yang paling banyak digunakan. Dalam pengantar ini, saya menjelaskan cara kerja
di balik layar. Kita akan melihat apa yang terjadi saat Anda mengetik google.com
di kolom URL hingga Anda melihat halaman Google di layar browser.
Browser yang akan kita bahas
Ada lima browser utama yang digunakan di desktop saat ini: Chrome, Internet Explorer, Firefox, Safari, dan Opera. Di perangkat seluler, browser utamanya adalah Browser Android, iPhone, Opera Mini dan Opera Mobile, UC Browser, browser Nokia S40/S60, dan Chrome, yang semuanya, kecuali browser Opera, didasarkan pada WebKit. Saya akan memberikan contoh dari browser open source Firefox dan Chrome, serta Safari (yang sebagian merupakan open source). Menurut statistik StatCounter (per Juni 2013), Chrome, Firefox, dan Safari mencakup sekitar 71% penggunaan browser desktop global. Di perangkat seluler, Browser Android, iPhone, dan Chrome mencakup sekitar 54% penggunaan.
Fungsi utama browser
Fungsi utama browser adalah menampilkan resource web yang Anda pilih, dengan memintanya dari server dan menampilkannya di jendela browser. Resource biasanya berupa dokumen HTML, tetapi juga dapat berupa PDF, gambar, atau jenis konten lainnya. Lokasi resource ditentukan oleh pengguna menggunakan URI (Uniform Resource Identifier).
Cara browser menafsirkan dan menampilkan file HTML ditentukan dalam spesifikasi HTML dan CSS. Spesifikasi ini dikelola oleh organisasi W3C (World Wide Web Consortium), yang merupakan organisasi standar untuk web. Selama bertahun-tahun, browser hanya mematuhi sebagian spesifikasi dan mengembangkan ekstensi mereka sendiri. Hal ini menyebabkan masalah kompatibilitas yang serius bagi penulis web. Saat ini, sebagian besar browser kurang lebih sesuai dengan spesifikasi tersebut.
Antarmuka pengguna browser memiliki banyak kesamaan satu sama lain. Di antara elemen antarmuka pengguna yang umum adalah:
- Kolom URL untuk menyisipkan URI
- Tombol kembali dan maju
- Opsi bookmark
- Tombol muat ulang dan berhenti untuk memuat ulang atau menghentikan pemuatan dokumen saat ini
- Tombol layar utama yang mengarahkan Anda ke halaman beranda
Anehnya, antarmuka pengguna browser tidak ditentukan dalam spesifikasi formal apa pun, melainkan berasal dari praktik baik yang dibentuk selama bertahun-tahun pengalaman dan oleh browser yang meniru satu sama lain. Spesifikasi HTML5 tidak menentukan elemen UI yang harus dimiliki browser, tetapi mencantumkan beberapa elemen umum. Di antaranya adalah kolom URL, status bar, dan toolbar. Tentu saja, ada fitur unik untuk browser tertentu seperti pengelola download Firefox.
Infrastruktur tingkat tinggi
Komponen utama browser adalah:
- Antarmuka pengguna: ini mencakup kolom URL, tombol kembali/maju, menu bookmark, dll. Setiap bagian tampilan browser kecuali jendela tempat Anda melihat halaman yang diminta.
- Mesin browser: mengatur tindakan antara UI dan mesin rendering.
- Mesin rendering: bertanggung jawab untuk menampilkan konten yang diminta. Misalnya, jika konten yang diminta adalah HTML, mesin rendering akan mengurai HTML dan CSS, serta menampilkan konten yang diuraikan di layar.
- Jaringan: untuk panggilan jaringan seperti permintaan HTTP, menggunakan implementasi yang berbeda untuk platform yang berbeda di balik antarmuka yang tidak bergantung pada platform.
- Backend UI: digunakan untuk menggambar widget dasar seperti kotak kombinasi dan jendela. Backend ini mengekspos antarmuka umum yang tidak spesifik per platform. Di bawahnya, metode antarmuka pengguna sistem operasi digunakan.
- Penafsir JavaScript. Digunakan untuk mengurai dan mengeksekusi kode JavaScript.
- Penyimpanan Data. Ini adalah lapisan persistensi. Browser mungkin perlu menyimpan berbagai jenis data secara lokal, seperti cookie. Browser juga mendukung mekanisme penyimpanan seperti localStorage, IndexedDB, WebSQL, dan FileSystem.
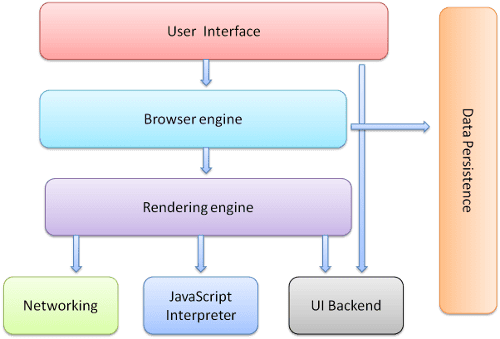
Perlu diperhatikan bahwa browser seperti Chrome menjalankan beberapa instance mesin rendering: satu untuk setiap tab. Setiap tab berjalan dalam proses terpisah.
Mesin rendering
Tanggung jawab mesin rendering adalah… Rendering, yaitu menampilkan konten yang diminta di layar browser.
Secara default, mesin rendering dapat menampilkan dokumen dan gambar HTML dan XML. Plugin ini dapat menampilkan jenis data lain melalui plugin atau ekstensi; misalnya, menampilkan dokumen PDF menggunakan plugin penampil PDF. Namun, dalam bab ini, kita akan berfokus pada kasus penggunaan utama: menampilkan HTML dan gambar yang diformat menggunakan CSS.
Browser yang berbeda menggunakan mesin rendering yang berbeda: Internet Explorer menggunakan Trident, Firefox menggunakan Gecko, Safari menggunakan WebKit. Chrome dan Opera (dari versi 15) menggunakan Blink, sebuah fork dari WebKit.
WebKit adalah mesin rendering open source yang dimulai sebagai mesin untuk platform Linux dan dimodifikasi oleh Apple untuk mendukung Mac dan Windows.
Alur utama
Mesin rendering akan mulai mendapatkan konten dokumen yang diminta dari lapisan jaringan. Hal ini biasanya dilakukan dalam potongan 8 kB.
Setelah itu, berikut adalah alur dasar mesin rendering:

Mesin rendering akan mulai mengurai dokumen HTML dan mengonversi elemen ke node DOM dalam hierarki yang disebut "hierarki konten". Mesin akan mengurai data gaya, baik dalam file CSS eksternal maupun dalam elemen gaya. Informasi gaya bersama dengan petunjuk visual di HTML akan digunakan untuk membuat hierarki lain: hierarki render.
Hierarki render berisi persegi panjang dengan atribut visual seperti warna dan dimensi. Persegi panjang berada dalam urutan yang benar untuk ditampilkan di layar.
Setelah konstruksi hierarki render, hierarki tersebut akan melalui proses "tata letak". Ini berarti memberi setiap node koordinat yang tepat tempatnya akan muncul di layar. Tahap berikutnya adalah melukis - hierarki render akan dilalui dan setiap node akan dilukis menggunakan lapisan backend UI.
Penting untuk memahami bahwa ini adalah proses bertahap. Untuk pengalaman pengguna yang lebih baik, mesin rendering akan mencoba menampilkan konten di layar sesegera mungkin. Fungsi ini tidak akan menunggu hingga semua HTML diuraikan sebelum mulai mem-build dan menata letak hierarki render. Bagian konten akan diuraikan dan ditampilkan, sementara prosesnya berlanjut dengan konten lainnya yang terus datang dari jaringan.
Contoh alur utama
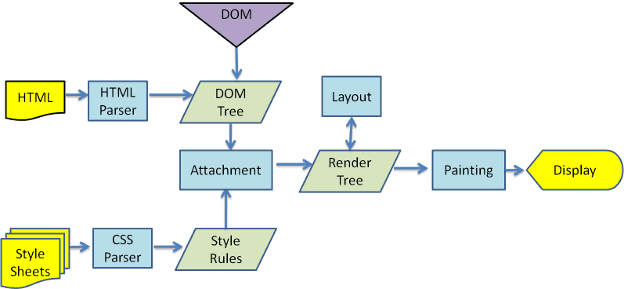
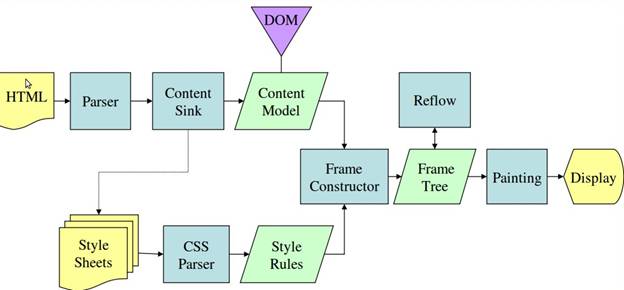
Dari gambar 3 dan 4, Anda dapat melihat bahwa meskipun WebKit dan Gecko menggunakan terminologi yang sedikit berbeda, alur dasarnya sama.
Gecko menyebut hierarki elemen yang diformat secara visual sebagai "Hierarki frame". Setiap elemen adalah frame. WebKit menggunakan istilah "Render Tree" dan terdiri dari "Render Objects". WebKit menggunakan istilah "tata letak" untuk penempatan elemen, sedangkan Gecko menyebutnya "Pembentukan Ulang". "Lampiran" adalah istilah WebKit untuk menghubungkan node DOM dan informasi visual guna membuat hierarki render. Perbedaan non-semantik kecil adalah Gecko memiliki lapisan tambahan antara hierarki HTML dan DOM. Ini disebut "penampung konten" dan merupakan factory untuk membuat elemen DOM. Kita akan membahas setiap bagian alur:
Penguraian - umum
Karena penguraian adalah proses yang sangat signifikan dalam mesin rendering, kita akan membahasnya lebih dalam. Mari kita mulai dengan sedikit pengantar tentang penguraian.
Mengurai dokumen berarti menerjemahkannya ke struktur yang dapat digunakan kode. Hasil penguraian biasanya berupa hierarki node yang mewakili struktur dokumen. Ini disebut hierarki penguraian atau hierarki sintaksis.
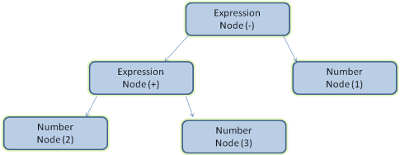
Misalnya, mengurai ekspresi 2 + 3 - 1 dapat menampilkan hierarki ini:
Tata Bahasa
Pemrosesan didasarkan pada aturan sintaksis yang dipatuhi dokumen: bahasa atau format yang digunakan untuk menulis dokumen. Setiap format yang dapat Anda uraikan harus memiliki tata bahasa deterministik yang terdiri dari aturan kosakata dan sintaksis. Ini disebut tata bahasa bebas konteks. Bahasa manusia bukanlah bahasa tersebut sehingga tidak dapat diuraikan dengan teknik penguraian konvensional.
Kombinasi Parser - Lexer
Penguraian dapat dibagi menjadi dua subproses: analisis leksik dan analisis sintaksis.
Analisis leksik adalah proses pemecahan input menjadi token. Token adalah kosakata bahasa: kumpulan elemen penyusun yang valid. Dalam bahasa manusia, kosakata akan terdiri dari semua kata yang muncul dalam kamus untuk bahasa tersebut.
Analisis sintaksis adalah penerapan aturan sintaksis bahasa.
Parser biasanya membagi pekerjaan antara dua komponen: lexer (terkadang disebut tokenizer) yang bertanggung jawab untuk membagi input menjadi token yang valid, dan parser yang bertanggung jawab untuk membuat hierarki penguraian dengan menganalisis struktur dokumen sesuai dengan aturan sintaksis bahasa.
Lexer tahu cara menghapus karakter yang tidak relevan seperti spasi kosong dan baris baru.
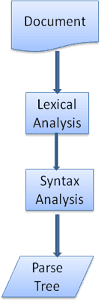
Proses penguraian bersifat iteratif. Parser biasanya akan meminta token baru dari lexer dan mencoba mencocokkan token dengan salah satu aturan sintaksis. Jika aturan cocok, node yang sesuai dengan token akan ditambahkan ke hierarki penguraian dan parser akan meminta token lain.
Jika tidak ada aturan yang cocok, parser akan menyimpan token secara internal, dan terus meminta token hingga ditemukan aturan yang cocok dengan semua token yang disimpan secara internal. Jika tidak ada aturan yang ditemukan, parser akan menampilkan pengecualian. Artinya, dokumen tidak valid dan berisi error sintaksis.
Terjemahan
Dalam banyak kasus, hierarki penguraian bukanlah produk akhir. Pemrosesan sering digunakan dalam terjemahan: mengubah dokumen input ke format lain. Contohnya adalah kompilasi. Compiler yang mengompilasi kode sumber menjadi kode mesin pertama-tama mengurainya menjadi hierarki penguraian, lalu menerjemahkan hierarki tersebut menjadi dokumen kode mesin.
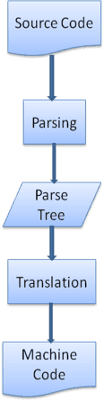
Contoh penguraian
Pada gambar 5, kita membuat hierarki penguraian dari ekspresi matematika. Mari kita coba menentukan bahasa matematika sederhana dan melihat proses penguraiannya.
Sintaksis:
- Komponen penyusun sintaksis bahasa adalah ekspresi, istilah, dan operasi.
- Bahasa kita dapat menyertakan sejumlah ekspresi.
- Ekspresi ditentukan sebagai "istilah" yang diikuti dengan "operasi" yang diikuti dengan istilah lain
- Operasi adalah token plus atau token minus
- Istilah adalah token bilangan bulat atau ekspresi
Mari kita analisis input 2 + 3 - 1.
Substring pertama yang cocok dengan aturan adalah 2: menurut aturan #5, substring ini adalah istilah.
Kecocokan kedua adalah 2 + 3: kecocokan ini sesuai dengan aturan ketiga: istilah diikuti dengan operasi, diikuti dengan istilah lain.
Pencocokan berikutnya hanya akan ditekan di akhir input.
2 + 3 - 1 adalah ekspresi karena kita sudah tahu bahwa 2 + 3 adalah istilah, sehingga kita memiliki istilah yang diikuti dengan operasi yang diikuti dengan istilah lain.
2 + + tidak akan cocok dengan aturan apa pun sehingga merupakan input yang tidak valid.
Definisi formal untuk kosakata dan sintaksis
Kosakata biasanya dinyatakan dengan ekspresi reguler.
Misalnya, bahasa kita akan ditentukan sebagai:
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -
Seperti yang Anda lihat, bilangan bulat ditentukan oleh ekspresi reguler.
Sintaksis biasanya ditentukan dalam format yang disebut BNF. Bahasa kita akan ditentukan sebagai:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
Kita telah mengatakan bahwa bahasa dapat diuraikan oleh parser reguler jika tata bahasanya adalah tata bahasa bebas konteks. Definisi intuitif dari tata bahasa bebas konteks adalah tata bahasa yang dapat sepenuhnya dinyatakan dalam BNF. Untuk definisi formal, lihat artikel Wikipedia tentang Tata bahasa bebas konteks
Jenis parser
Ada dua jenis parser: parser top-down dan parser bottom-up. Penjelasan intuitifnya adalah bahwa parser top-down memeriksa struktur sintaksis tingkat tinggi dan mencoba menemukan kecocokan aturan. Parser bottom up dimulai dengan input dan secara bertahap mengubahnya menjadi aturan sintaksis, mulai dari aturan tingkat rendah hingga aturan tingkat tinggi terpenuhi.
Mari kita lihat cara kedua jenis parser mengurai contoh kita.
Parser top down akan dimulai dari aturan tingkat yang lebih tinggi: parser akan mengidentifikasi 2 + 3 sebagai ekspresi. Kemudian, 2 + 3 - 1 akan diidentifikasi sebagai ekspresi (proses identifikasi ekspresi berkembang, yang cocok dengan aturan lain, tetapi titik awalnya adalah aturan tingkat tertinggi).
Parser bottom up akan memindai input hingga aturan cocok. Kemudian, aturan akan mengganti input yang cocok dengan aturan. Hal ini akan berlanjut hingga akhir input. Ekspresi yang cocok sebagian ditempatkan di stack parser.
Jenis parser bottom-up ini disebut parser shift-reduce, karena input digeser ke kanan (bayangkan pointer yang pertama kali mengarah ke awal input dan bergerak ke kanan) dan secara bertahap dikurangi menjadi aturan sintaksis.
Membuat parser secara otomatis
Ada alat yang dapat membuat parser. Anda memberinya tata bahasa bahasa Anda - kosakata dan aturan sintaksisnya - dan alat ini akan menghasilkan parser yang berfungsi. Membuat parser memerlukan pemahaman mendalam tentang penguraian dan tidak mudah untuk membuat parser yang dioptimalkan secara manual, sehingga generator parser dapat sangat berguna.
WebKit menggunakan dua generator parser yang terkenal: Flex untuk membuat lexer dan Bison untuk membuat parser (Anda mungkin menemukannya dengan nama Lex dan Yacc). Input fleksibel adalah file yang berisi definisi ekspresi reguler token. Input Bison adalah aturan sintaksis bahasa dalam format BNF.
HTML Parser
Tugas parser HTML adalah mengurai markup HTML menjadi hierarki penguraian.
Tata bahasa HTML
Kosakata dan sintaksis HTML ditentukan dalam spesifikasi yang dibuat oleh organisasi W3C.
Seperti yang telah kita lihat dalam pengantar penguraian, sintaksis tata bahasa dapat ditentukan secara formal menggunakan format seperti BNF.
Sayangnya, semua topik parser konvensional tidak berlaku untuk HTML (saya tidak membahasnya hanya untuk bersenang-senang - topik tersebut akan digunakan dalam mengurai CSS dan JavaScript). HTML tidak dapat dengan mudah ditentukan oleh tata bahasa bebas konteks yang diperlukan parser.
Ada format formal untuk menentukan HTML - DTD (Document Type Definition) - tetapi bukan merupakan tata bahasa bebas konteks.
Hal ini tampak aneh pada pandangan pertama; HTML agak mirip dengan XML. Ada banyak parser XML yang tersedia. Ada variasi XML dari HTML - XHTML - jadi apa perbedaan utamanya?
Perbedaannya adalah pendekatan HTML lebih "longgar": pendekatan ini memungkinkan Anda menghilangkan tag tertentu (yang kemudian ditambahkan secara implisit), atau terkadang menghilangkan tag awal atau akhir, dan sebagainya. Secara keseluruhan, ini adalah sintaksis "lunak", bukan sintaksis XML yang kaku dan menuntut.
Detail yang tampaknya kecil ini sangatlah penting. Di satu sisi, ini adalah alasan utama mengapa HTML sangat populer: HTML memaafkan kesalahan Anda dan memudahkan penulis web. Di sisi lain, hal ini menyulitkan penulisan tata bahasa formal. Jadi, untuk meringkas, HTML tidak dapat diuraikan dengan mudah oleh parser konvensional, karena tata bahasanya tidak bebas konteks. HTML tidak dapat diuraikan oleh parser XML.
DTD HTML
Definisi HTML dalam format DTD. Format ini digunakan untuk menentukan bahasa dari keluarga SGML. Format ini berisi definisi untuk semua elemen yang diizinkan, atribut, dan hierarkinya. Seperti yang kita lihat sebelumnya, DTD HTML tidak membentuk tata bahasa bebas konteks.
Ada beberapa variasi DTD. Mode ketat hanya sesuai dengan spesifikasi, tetapi mode lain berisi dukungan untuk markup yang digunakan oleh browser sebelumnya. Tujuannya adalah kompatibilitas mundur dengan konten lama. DTD ketat saat ini ada di sini: www.w3.org/TR/html4/strict.dtd
DOM
Hierarki output ("hierarki penguraian") adalah hierarki elemen DOM dan node atribut. DOM adalah singkatan dari Document Object Model. Ini adalah presentasi objek dokumen HTML dan antarmuka elemen HTML ke dunia luar seperti JavaScript.
Root hierarki adalah objek "Document".
DOM memiliki hubungan hampir satu-ke-satu dengan markup. Contoh:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
Markup ini akan diterjemahkan ke hierarki DOM berikut:
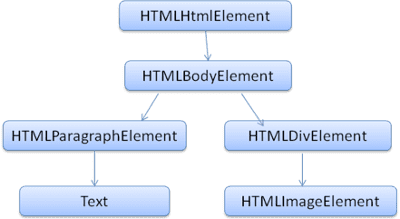
Seperti HTML, DOM ditentukan oleh organisasi W3C. Lihat www.w3.org/DOM/DOMTR. Ini adalah spesifikasi umum untuk memanipulasi dokumen. Modul tertentu menjelaskan elemen khusus HTML. Definisi HTML dapat ditemukan di sini: www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html.
Saat saya mengatakan hierarki berisi node DOM, maksud saya hierarki dibuat dari elemen yang mengimplementasikan salah satu antarmuka DOM. Browser menggunakan implementasi konkret yang memiliki atribut lain yang digunakan oleh browser secara internal.
Algoritma penguraian
Seperti yang kita lihat di bagian sebelumnya, HTML tidak dapat diuraikan menggunakan parser atas ke bawah atau bawah ke atas biasa.
Alasannya adalah:
- Sifat bahasa yang toleran.
- Fakta bahwa browser memiliki toleransi error tradisional untuk mendukung kasus HTML tidak valid yang sudah dikenal.
- Proses penguraian bersifat reentrant. Untuk bahasa lain, sumber tidak berubah selama penguraian, tetapi dalam HTML, kode dinamis (seperti elemen skrip yang berisi panggilan
document.write()) dapat menambahkan token tambahan, sehingga proses penguraian benar-benar mengubah input.
Karena tidak dapat menggunakan teknik penguraian reguler, browser membuat parser kustom untuk mengurai HTML.
Algoritma penguraian dijelaskan secara mendetail oleh spesifikasi HTML5. Algoritma ini terdiri dari dua tahap: tokenisasi dan konstruksi hierarki.
Tokenisasi adalah analisis leksikal, yang mengurai input menjadi token. Di antara token HTML adalah tag awal, tag akhir, nama atribut, dan nilai atribut.
Tokenizer mengenali token, memberikannya ke konstruktor hierarki, dan menggunakan karakter berikutnya untuk mengenali token berikutnya, dan seterusnya hingga akhir input.
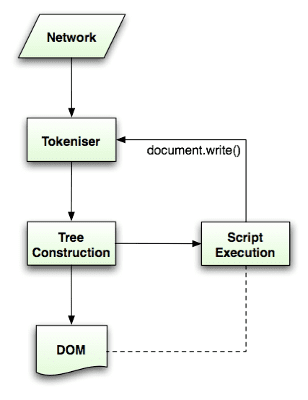
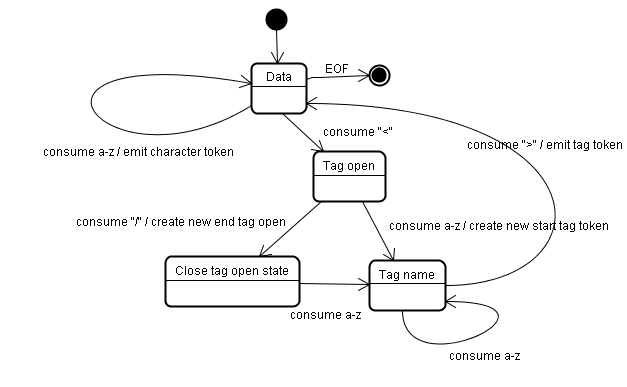
Algoritma tokenisasi
Output algoritma adalah token HTML. Algoritme dinyatakan sebagai mesin status. Setiap status menggunakan satu atau beberapa karakter dari aliran input dan memperbarui status berikutnya sesuai dengan karakter tersebut. Keputusan ini dipengaruhi oleh status tokenisasi saat ini dan status konstruksi hierarki. Ini berarti karakter yang digunakan sama akan menghasilkan hasil yang berbeda untuk status berikutnya yang benar, bergantung pada status saat ini. Algoritme ini terlalu kompleks untuk dijelaskan sepenuhnya, jadi mari kita lihat contoh sederhana yang akan membantu kita memahami prinsipnya.
Contoh dasar - membuat token HTML berikut:
<html>
<body>
Hello world
</body>
</html>
Status awal adalah "Status data".
Saat karakter < ditemukan, status akan diubah menjadi "Status tag terbuka".
Menggunakan karakter a-z akan menyebabkan pembuatan "Token tag awal", statusnya diubah menjadi "Status nama tag".
Kita tetap dalam status ini hingga karakter > digunakan. Setiap karakter ditambahkan ke nama token baru. Dalam kasus kita, token yang dibuat adalah token html.
Saat tag > tercapai, token saat ini akan dikeluarkan dan status akan berubah kembali ke "Status data".
Tag <body> akan diperlakukan dengan langkah yang sama.
Sejauh ini, tag html dan body telah dikeluarkan. Sekarang kita kembali ke "Status data".
Menggunakan karakter H dari Hello world akan menyebabkan pembuatan dan emisi token karakter, yang akan berlanjut hingga < dari </body> tercapai. Kita akan memunculkan token karakter untuk setiap karakter Hello world.
Sekarang kita kembali ke "Status tag terbuka".
Menggunakan input / berikutnya akan menyebabkan pembuatan end tag token dan perpindahan ke "Status nama tag". Sekali lagi, kita tetap berada dalam status ini hingga mencapai >.Kemudian, token tag baru akan ditampilkan dan kita kembali ke "Status data".
Input </html> akan diperlakukan seperti kasus sebelumnya.
Algoritma konstruksi hierarki
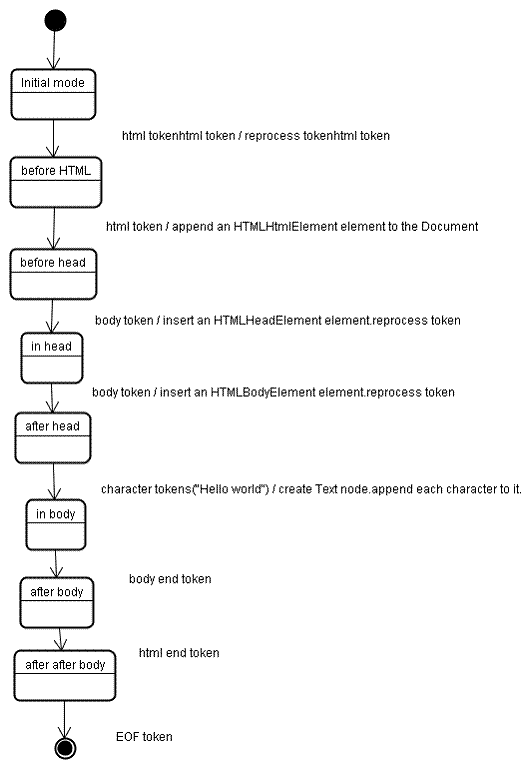
Saat parser dibuat, objek Dokumen akan dibuat. Selama tahap konstruksi hierarki, hierarki DOM dengan Dokumen di root-nya akan diubah dan elemen akan ditambahkan ke dalamnya. Setiap node yang dikeluarkan oleh tokenizer akan diproses oleh konstruktor hierarki. Untuk setiap token, spesifikasi menentukan elemen DOM yang relevan dan akan dibuat untuk token ini. Elemen ditambahkan ke hierarki DOM, dan juga tumpukan elemen terbuka. Stack ini digunakan untuk memperbaiki ketidakcocokan tingkat bertingkat dan tag yang tidak ditutup. Algoritme ini juga dijelaskan sebagai mesin status. Status ini disebut "mode penyisipan".
Mari kita lihat proses konstruksi hierarki untuk contoh input:
<html>
<body>
Hello world
</body>
</html>
Input ke tahap konstruksi hierarki adalah urutan token dari tahap tokenisasi. Mode pertama adalah "mode awal". Menerima token "html" akan menyebabkan perpindahan ke mode "sebelum html" dan pemrosesan ulang token dalam mode tersebut. Tindakan ini akan menyebabkan pembuatan elemen HTMLHtmlElement, yang akan ditambahkan ke objek Dokumen root.
Status akan diubah menjadi "before head". Token "body" kemudian diterima. HTMLHeadElement akan dibuat secara implisit meskipun kita tidak memiliki token "head" dan akan ditambahkan ke hierarki.
Sekarang kita beralih ke mode "in head", lalu ke "after head". Token isi diproses ulang, HTMLBodyElement dibuat dan disisipkan, dan mode ditransfer ke "in body".
Token karakter string "Hello world" kini diterima. Karakter pertama akan menyebabkan pembuatan dan penyisipan node "Text" dan karakter lainnya akan ditambahkan ke node tersebut.
Penerimaan token akhir isi akan menyebabkan transfer ke mode "after body". Sekarang kita akan menerima tag akhir html yang akan memindahkan kita ke mode "after after body". Menerima token akhir file akan mengakhiri penguraian.
Tindakan saat penguraian selesai
Pada tahap ini, browser akan menandai dokumen sebagai interaktif dan mulai mengurai skrip yang berada dalam mode "ditangguhkan": skrip yang harus dijalankan setelah dokumen diuraikan. Status dokumen kemudian akan disetel ke "selesai" dan peristiwa "load" akan diaktifkan.
Anda dapat melihat algoritma lengkap untuk pembuatan token dan hierarki dalam spesifikasi HTML5.
Toleransi error browser
Anda tidak akan pernah mendapatkan error "Sintaksis Tidak Valid" di halaman HTML. Browser akan memperbaiki konten yang tidak valid dan melanjutkan.
Misalnya HTML ini:
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
Saya pasti telah melanggar sekitar satu juta aturan ("mytag" bukan tag standar, penyusunan bertingkat yang salah dari elemen "p" dan "div", dan lainnya) tetapi browser masih menampilkannya dengan benar dan tidak mengeluh. Jadi, banyak kode pengurai yang memperbaiki kesalahan penulis HTML.
Penanganan error cukup konsisten di browser, tetapi anehnya, penanganan error belum menjadi bagian dari spesifikasi HTML. Seperti bookmark dan tombol kembali/maju, ini hanyalah sesuatu yang berkembang di browser selama bertahun-tahun. Ada konstruksi HTML yang diketahui tidak valid dan diulang di banyak situs, dan browser mencoba memperbaikinya dengan cara yang sesuai dengan browser lain.
Spesifikasi HTML5 menentukan beberapa persyaratan ini. (WebKit merangkumnya dengan baik dalam komentar di awal class parser HTML.)
Parser mengurai input token ke dalam dokumen, yang membuat hierarki dokumen. Jika dokumen dibuat dengan baik, penguraiannya akan mudah.
Sayangnya, kita harus menangani banyak dokumen HTML yang tidak terbentuk dengan baik, sehingga parser harus toleran terhadap error.
Kita harus menangani setidaknya kondisi error berikut:
- Elemen yang ditambahkan secara eksplisit dilarang di dalam beberapa tag luar. Dalam hal ini, kita harus menutup semua tag hingga tag yang melarang elemen, lalu menambahkannya setelah itu.
- Kita tidak diizinkan untuk menambahkan elemen secara langsung. Mungkin orang yang menulis dokumen tersebut lupa beberapa tag di antaranya (atau tag di antaranya bersifat opsional). Hal ini dapat terjadi dengan tag berikut: HTML HEAD BODY TBODY TR TD LI (apakah saya melupakan tag apa pun?).
- Kita ingin menambahkan elemen blok di dalam elemen inline. Menutup semua elemen inline hingga elemen blok yang lebih tinggi berikutnya.
- Jika cara ini tidak membantu, tutup elemen hingga kita diizinkan untuk menambahkan elemen - atau abaikan tag.
Mari kita lihat beberapa contoh toleransi error WebKit:
</br> bukan <br>
Beberapa situs menggunakan </br>, bukan <br>. Agar kompatibel dengan IE dan Firefox, WebKit memperlakukannya seperti <br>.
Kode:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
Perhatikan bahwa penanganan error bersifat internal: penanganan error tidak akan ditampilkan kepada pengguna.
Tabel yang tidak sesuai
Tabel yang tidak sesuai adalah tabel di dalam tabel lain, tetapi tidak di dalam sel tabel.
Contoh:
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
WebKit akan mengubah hierarki menjadi dua tabel yang bersaudara:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
Kode:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
WebKit menggunakan stack untuk konten elemen saat ini: stack ini akan memunculkan tabel dalam dari stack tabel luar. Tabel kini akan menjadi saudara.
Elemen formulir bertingkat
Jika pengguna menempatkan formulir di dalam formulir lain, formulir kedua akan diabaikan.
Kode:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
Hierarki tag yang terlalu dalam
Komentar tersebut sudah cukup jelas.
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
Tag akhir html atau isi salah tempat
Sekali lagi - komentar tersebut sudah jelas.
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
Jadi, penulis web harus berhati-hati - kecuali jika Anda ingin muncul sebagai contoh dalam cuplikan kode toleransi error WebKit - tulis HTML yang terbentuk dengan baik.
Mengurai CSS
Ingat konsep penguraian di bagian pengantar? Nah, tidak seperti HTML, CSS adalah tata bahasa bebas konteks dan dapat diuraikan menggunakan jenis parser yang dijelaskan dalam pengantar. Faktanya, spesifikasi CSS menentukan tata bahasa sintaksis dan leksikon CSS.
Mari kita lihat beberapa contohnya:
Tata bahasa leksikal (kosakata) ditentukan oleh ekspresi reguler untuk setiap token:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
"ident" adalah singkatan dari ID, seperti nama class. "name" adalah ID elemen (yang dirujuk oleh "#")
Tata bahasa sintaksis dijelaskan dalam BNF.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
Penjelasan:
Set aturan adalah struktur ini:
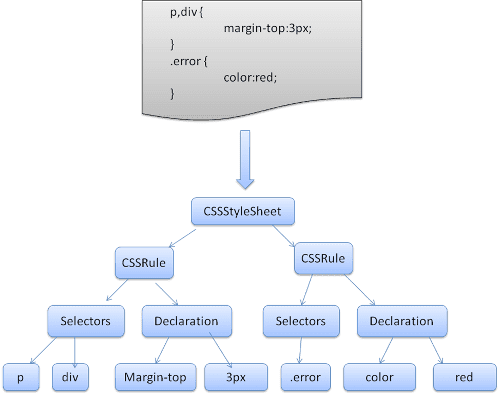
div.error, a.error {
color:red;
font-weight:bold;
}
div.error dan a.error adalah pemilih. Bagian di dalam tanda kurung kurawal berisi aturan yang diterapkan oleh kumpulan aturan ini.
Struktur ini ditentukan secara formal dalam definisi ini:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
Artinya, kumpulan aturan adalah pemilih atau secara opsional sejumlah pemilih yang dipisahkan dengan koma dan spasi (S adalah singkatan dari spasi kosong). Set aturan berisi tanda kurung kurawal dan di dalamnya terdapat deklarasi atau, jika perlu, sejumlah deklarasi yang dipisahkan dengan titik koma. "declaration" dan "selector" akan ditentukan dalam definisi BNF berikut.
Parser CSS WebKit
WebKit menggunakan generator parser Flex dan Bison untuk membuat parser secara otomatis dari file tata bahasa CSS. Seperti yang Anda ingat dari pengantar parser, Bison membuat parser shift-reduce dari bawah ke atas. Firefox menggunakan parser top down yang ditulis secara manual. Dalam kedua kasus tersebut, setiap file CSS akan diuraikan menjadi objek StyleSheet. Setiap objek berisi aturan CSS. Objek aturan CSS berisi objek pemilih dan deklarasi serta objek lain yang sesuai dengan tata bahasa CSS.
Urutan pemrosesan untuk skrip dan lembar gaya
Skrip
Model web bersifat sinkron. Penulis mengharapkan skrip segera diuraikan dan dieksekusi saat parser mencapai tag <script>.
Pemrosesan dokumen akan dihentikan hingga skrip dijalankan.
Jika skrip bersifat eksternal, resource harus diambil terlebih dahulu dari jaringan - hal ini juga dilakukan secara sinkron, dan penguraian akan dihentikan hingga resource diambil.
Model ini telah digunakan selama bertahun-tahun dan juga ditentukan dalam spesifikasi HTML4 dan 5.
Penulis dapat menambahkan atribut "defer" ke skrip, yang dalam hal ini tidak akan menghentikan penguraian dokumen dan akan dieksekusi setelah dokumen diuraikan. HTML5 menambahkan opsi untuk menandai skrip sebagai asinkron sehingga akan diuraikan dan dieksekusi oleh thread yang berbeda.
Penguraian spekulatif
WebKit dan Firefox melakukan pengoptimalan ini. Saat mengeksekusi skrip, thread lain mengurai sisa dokumen dan mencari tahu resource lain yang perlu dimuat dari jaringan dan memuat resource tersebut. Dengan cara ini, resource dapat dimuat pada koneksi paralel dan kecepatan secara keseluruhan meningkat. Catatan: parser spekulatif hanya mengurai referensi ke resource eksternal seperti skrip eksternal, lembar gaya, dan gambar: parser ini tidak mengubah hierarki DOM - yang diserahkan kepada parser utama.
Stylesheet
Di sisi lain, lembar gaya memiliki model yang berbeda. Secara konseptual, tampaknya karena stylesheet tidak mengubah hierarki DOM, tidak ada alasan untuk menunggunya dan menghentikan penguraian dokumen. Namun, ada masalah pada skrip yang meminta informasi gaya selama tahap penguraian dokumen. Jika gaya belum dimuat dan diuraikan, skrip akan mendapatkan jawaban yang salah dan tampaknya hal ini menyebabkan banyak masalah. Tampaknya ini adalah kasus ekstrem, tetapi cukup umum. Firefox memblokir semua skrip jika ada stylesheet yang masih dimuat dan diuraikan. WebKit memblokir skrip hanya saat skrip mencoba mengakses properti gaya tertentu yang mungkin terpengaruh oleh sheet gaya yang tidak dimuat.
Membuat hierarki render
Saat hierarki DOM sedang dibuat, browser akan membuat hierarki lain, yaitu hierarki render. Hierarki ini berisi elemen visual dalam urutan tampilannya. Ini adalah representasi visual dokumen. Tujuan hierarki ini adalah untuk mengaktifkan proses menggambar konten dalam urutan yang benar.
Firefox menyebut elemen dalam hierarki render sebagai "frame". WebKit menggunakan istilah perender atau objek render.
Perender tahu cara menata letak dan menggambar dirinya sendiri dan turunannya.
Class RenderObject WebKit, class dasar perender, memiliki definisi berikut:
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
Setiap perender mewakili area persegi panjang yang biasanya sesuai dengan kotak CSS node, seperti yang dijelaskan oleh spesifikasi CSS2. Area ini mencakup informasi geometris seperti lebar, tinggi, dan posisi.
Jenis kotak dipengaruhi oleh nilai "display" dari atribut gaya yang relevan dengan node (lihat bagian komputasi gaya). Berikut adalah kode WebKit untuk menentukan jenis perender yang harus dibuat untuk node DOM, sesuai dengan atribut tampilan:
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
Jenis elemen juga dipertimbangkan: misalnya, kontrol formulir dan tabel memiliki bingkai khusus.
Di WebKit, jika elemen ingin membuat perender khusus, elemen tersebut akan mengganti metode createRenderer().
Perender mengarah ke objek gaya yang berisi informasi non-geometris.
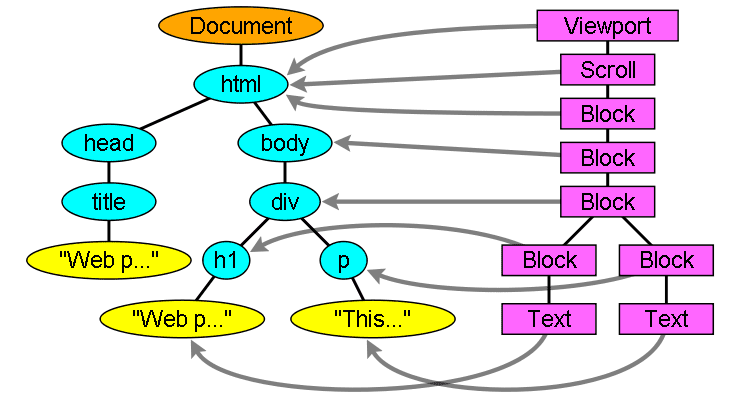
Hubungan hierarki render dengan hierarki DOM
Perender sesuai dengan elemen DOM, tetapi hubungannya tidak one-to-one. Elemen DOM non-visual tidak akan disisipkan dalam hierarki render. Contohnya adalah elemen "head". Selain itu, elemen yang nilai tampilannya ditetapkan ke "none" tidak akan muncul dalam hierarki (sedangkan elemen dengan visibilitas "hidden" akan muncul dalam hierarki).
Ada elemen DOM yang sesuai dengan beberapa objek visual. Ini biasanya adalah elemen dengan struktur kompleks yang tidak dapat dijelaskan oleh satu persegi panjang. Misalnya, elemen "select" memiliki tiga perender: satu untuk area tampilan, satu untuk kotak daftar drop-down, dan satu untuk tombol. Selain itu, saat teks dibagi menjadi beberapa baris karena lebarnya tidak cukup untuk satu baris, baris baru akan ditambahkan sebagai perender tambahan.
Contoh lain dari beberapa perender adalah HTML yang rusak. Menurut spesifikasi CSS, elemen inline hanya boleh berisi elemen blok atau elemen inline saja. Dalam kasus konten campuran, perender blok anonim akan dibuat untuk menggabungkan elemen inline.
Beberapa objek render sesuai dengan node DOM, tetapi tidak berada di tempat yang sama dalam hierarki. Elemen mengambang dan elemen yang diposisikan secara mutlak berada di luar alur, ditempatkan di bagian lain dari hierarki, dan dipetakan ke frame sebenarnya. Bingkai placeholder adalah tempat yang seharusnya.
Alur pembuatan hierarki
Di Firefox, presentasi didaftarkan sebagai pemroses untuk update DOM.
Presentasi mendelegasikan pembuatan frame ke FrameConstructor dan konstruktor me-resolve gaya (lihat komputasi gaya) dan membuat frame.
Di WebKit, proses me-resolve gaya dan membuat perender disebut "lampiran". Setiap node DOM memiliki metode "attach". Lampiran bersifat sinkron, penyisipan node ke hierarki DOM memanggil metode "lampirkan" node baru.
Memproses tag html dan isi menghasilkan konstruksi root hierarki render.
Objek render root sesuai dengan yang disebut spesifikasi CSS sebagai blok penampung: blok paling atas yang berisi semua blok lainnya. Dimensinya adalah area pandang: dimensi area tampilan jendela browser.
Firefox menyebutnya ViewPortFrame dan WebKit menyebutnya RenderView.
Ini adalah objek render yang ditunjuk oleh dokumen.
Bagian hierarki lainnya dibuat sebagai penyisipan node DOM.
Lihat spesifikasi CSS2 tentang model pemrosesan.
Komputasi gaya
Membuat hierarki render memerlukan penghitungan properti visual setiap objek render. Hal ini dilakukan dengan menghitung properti gaya setiap elemen.
Gaya ini mencakup lembar gaya dari berbagai asal, elemen gaya inline, dan properti visual di HTML (seperti properti "bgcolor").Properti ini diterjemahkan ke properti gaya CSS yang cocok.
Asal lembar gaya adalah lembar gaya default browser, lembar gaya yang disediakan oleh penulis halaman, dan lembar gaya pengguna - ini adalah lembar gaya yang disediakan oleh pengguna browser (browser memungkinkan Anda menentukan gaya favorit. Misalnya, di Firefox, hal ini dilakukan dengan menempatkan sheet gaya di folder "Profil Firefox").
Komputasi gaya menimbulkan beberapa kesulitan:
- Data gaya adalah konstruksi yang sangat besar, yang menyimpan banyak properti gaya, sehingga dapat menyebabkan masalah memori.
Menemukan aturan yang cocok untuk setiap elemen dapat menyebabkan masalah performa jika tidak dioptimalkan. Melintasi seluruh daftar aturan untuk setiap elemen guna menemukan kecocokan adalah tugas yang berat. Pemilih dapat memiliki struktur kompleks yang dapat menyebabkan proses pencocokan dimulai di jalur yang tampaknya menjanjikan, tetapi terbukti sia-sia dan jalur lain harus dicoba.
Misalnya - pemilih gabungan ini:
div div div div{ ... }Artinya, aturan berlaku untuk
<div>yang merupakan turunan dari 3 div. Misalnya, Anda ingin memeriksa apakah aturan berlaku untuk elemen<div>tertentu. Anda memilih jalur tertentu di atas hierarki untuk diperiksa. Anda mungkin perlu menelusuri hierarki node ke atas hanya untuk mengetahui bahwa hanya ada dua div dan aturan tidak berlaku. Kemudian, Anda perlu mencoba jalur lain dalam hierarki.Penerapan aturan melibatkan aturan cascade yang cukup kompleks yang menentukan hierarki aturan.
Mari kita lihat cara browser menghadapi masalah ini:
Membagikan data gaya
Node WebKit mereferensikan objek gaya (RenderStyle). Objek ini dapat dibagikan oleh node dalam beberapa kondisi. Node adalah saudara kandung atau sepupu dan:
- Elemen harus berada dalam status mouse yang sama (misalnya, satu elemen tidak boleh dalam :hover sementara elemen lainnya tidak)
- Kedua elemen tidak boleh memiliki ID
- Nama tag harus cocok
- Atribut class harus cocok
- Kumpulan atribut yang dipetakan harus identik
- Status link harus cocok
- Status fokus harus cocok
- Kedua elemen tidak boleh terpengaruh oleh pemilih atribut, dengan terpengaruh didefinisikan sebagai memiliki kecocokan pemilih yang menggunakan pemilih atribut di posisi mana pun dalam pemilih
- Tidak boleh ada atribut gaya inline pada elemen
- Tidak boleh ada pemilih saudara yang digunakan sama sekali. WebCore hanya menampilkan tombol global saat pemilih saudara ditemukan dan menonaktifkan berbagi gaya untuk seluruh dokumen jika ada. Hal ini mencakup pemilih + dan pemilih seperti :first-child dan :last-child.
Hierarki aturan Firefox
Firefox memiliki dua hierarki tambahan untuk mempermudah komputasi gaya: hierarki aturan dan hierarki konteks gaya. WebKit juga memiliki objek gaya, tetapi tidak disimpan dalam hierarki seperti hierarki konteks gaya. Hanya node DOM yang mengarah ke gaya yang relevan.
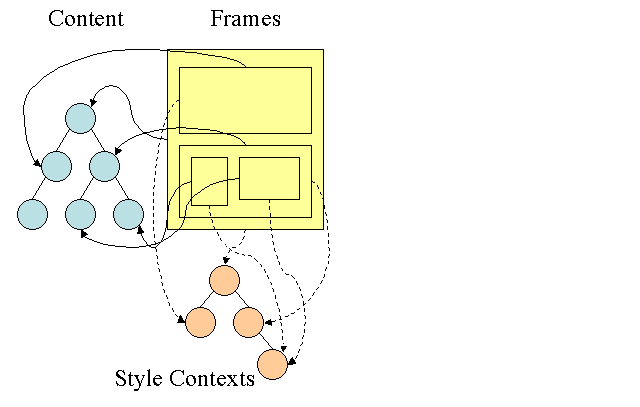
Konteks gaya berisi nilai akhir. Nilai dihitung dengan menerapkan semua aturan pencocokan dalam urutan yang benar dan melakukan manipulasi yang mengubahnya dari nilai logis menjadi nilai konkret. Misalnya, jika nilai logika adalah persentase layar, nilai tersebut akan dihitung dan diubah menjadi unit absolut. Ide hierarki aturan sangat cerdas. Hal ini memungkinkan pembagian nilai ini di antara node untuk menghindari penghitungannya lagi. Hal ini juga menghemat ruang.
Semua aturan yang cocok disimpan dalam hierarki. Node bawah dalam jalur memiliki prioritas yang lebih tinggi. Hierarki berisi semua jalur untuk kecocokan aturan yang ditemukan. Penyimpanan aturan dilakukan secara lambat. Hierarki tidak dihitung di awal untuk setiap node, tetapi setiap kali gaya node perlu dihitung, jalur yang dihitung akan ditambahkan ke hierarki.
Idenya adalah melihat jalur hierarki sebagai kata dalam leksikon. Misalnya, kita telah menghitung hierarki aturan ini:
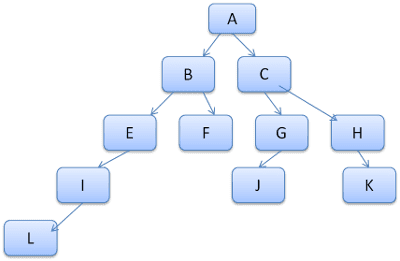
Misalkan kita perlu mencocokkan aturan untuk elemen lain dalam hierarki konten, dan mengetahui aturan yang cocok (dalam urutan yang benar) adalah B-E-I. Kita sudah memiliki jalur ini dalam hierarki karena kita sudah menghitung jalur A-B-E-I-L. Sekarang kita akan memiliki lebih sedikit pekerjaan yang harus dilakukan.
Mari kita lihat bagaimana hierarki menghemat pekerjaan kita.
Pembagian menjadi struct
Konteks gaya dibagi menjadi struct. Struktur tersebut berisi informasi gaya untuk kategori tertentu seperti batas atau warna. Semua properti dalam struct diwarisi atau tidak diwarisi. Properti yang diwarisi adalah properti yang diwarisi dari induknya, kecuali jika ditentukan oleh elemen. Properti yang tidak diwarisi (disebut properti "reset") menggunakan nilai default jika tidak ditentukan.
Hierarki membantu kita dengan meng-cache seluruh struct (berisi nilai akhir yang dihitung) dalam hierarki. Idenya adalah jika node bawah tidak menyediakan definisi untuk struct, struct yang di-cache di node atas dapat digunakan.
Menghitung konteks gaya menggunakan hierarki aturan
Saat menghitung konteks gaya untuk elemen tertentu, kita pertama-tama menghitung jalur di hierarki aturan atau menggunakan jalur yang ada. Kemudian, kita mulai menerapkan aturan di jalur untuk mengisi struct dalam konteks gaya baru. Kita mulai dari node bawah jalur - node dengan prioritas tertinggi (biasanya pemilih yang paling spesifik) dan menelusuri hierarki ke atas hingga struct kita penuh. Jika tidak ada spesifikasi untuk struct di node aturan tersebut, kita dapat melakukan pengoptimalan yang sangat besar - kita naik ke atas hierarki hingga menemukan node yang menentukannya sepenuhnya dan mengarah ke node tersebut - itulah pengoptimalan terbaik - seluruh struct dibagikan. Hal ini menghemat komputasi nilai akhir dan memori.
Jika menemukan definisi sebagian, kita akan naik ke hierarki hingga struct terisi.
Jika kita tidak menemukan definisi untuk struct, jika struct adalah jenis "diwarisi", kita akan mengarah ke struct induk di hierarki konteks. Dalam hal ini, kita juga berhasil berbagi struct. Jika ini adalah struct reset, nilai default akan digunakan.
Jika node yang paling spesifik menambahkan nilai, kita perlu melakukan beberapa penghitungan tambahan untuk mengubahnya menjadi nilai sebenarnya. Kemudian, kita menyimpan hasil dalam node hierarki agar dapat digunakan oleh turunan.
Jika elemen memiliki saudara atau kerabat yang mengarah ke node hierarki yang sama, seluruh konteks gaya dapat dibagikan di antara keduanya.
Mari kita lihat contohnya: Misalnya, kita memiliki HTML ini
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
Dan aturan berikut:
div {margin: 5px; color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
Untuk menyederhanakan, misalkan kita hanya perlu mengisi dua struct: struct warna dan struct margin. Struktur warna hanya berisi satu anggota: warna Struktur margin berisi empat sisi.
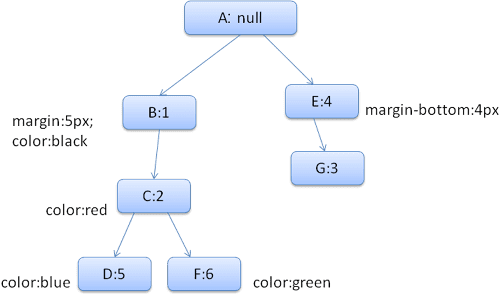
Hierarki aturan yang dihasilkan akan terlihat seperti ini (node ditandai dengan nama node: nomor aturan yang ditunjuknya):
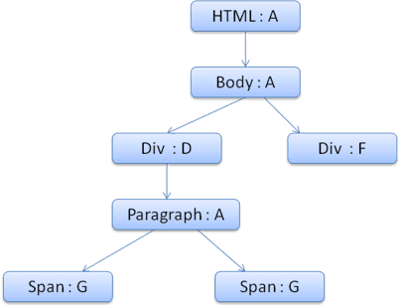
Hierarki konteks akan terlihat seperti ini (nama node: node aturan yang ditunjuknya):
Misalkan kita mengurai HTML dan membuka tag <div> kedua. Kita perlu membuat konteks gaya untuk node ini dan mengisi struct gayanya.
Kita akan mencocokkan aturan dan menemukan bahwa aturan yang cocok untuk <div> adalah 1, 2, dan 6.
Artinya, sudah ada jalur di hierarki yang dapat digunakan elemen kita dan kita hanya perlu menambahkan node lain ke jalur tersebut untuk aturan 6 (node F di hierarki aturan).
Kita akan membuat konteks gaya dan menempatkannya dalam hierarki konteks. Konteks gaya baru akan mengarah ke node F dalam hierarki aturan.
Sekarang kita perlu mengisi struct gaya. Kita akan mulai dengan mengisi struct margin. Karena node aturan terakhir (F) tidak ditambahkan ke struct margin, kita dapat naik ke hierarki hingga menemukan struct yang di-cache yang dihitung dalam penyisipan node sebelumnya dan menggunakannya. Kita akan menemukannya di node B, yang merupakan node paling atas yang menentukan aturan margin.
Kita memiliki definisi untuk struct warna, sehingga kita tidak dapat menggunakan struct yang di-cache. Karena warna memiliki satu atribut, kita tidak perlu naik ke hierarki untuk mengisi atribut lainnya. Kita akan menghitung nilai akhir (mengonversi string menjadi RGB, dll.) dan meng-cache struct yang dihitung di node ini.
Pekerjaan pada elemen <span> kedua bahkan lebih mudah. Kita akan mencocokkan aturan dan menyimpulkan bahwa aturan tersebut mengarah ke aturan G, seperti span sebelumnya.
Karena memiliki saudara yang mengarah ke node yang sama, kita dapat berbagi seluruh konteks gaya dan hanya mengarah ke konteks span sebelumnya.
Untuk struct yang berisi aturan yang diwarisi dari induk, penyimpanan dalam cache dilakukan pada hierarki konteks (properti warna sebenarnya diwarisi, tetapi Firefox memperlakukannya sebagai reset dan menyimpannya dalam cache pada hierarki aturan).
Misalnya, jika kita menambahkan aturan untuk font dalam paragraf:
p {font-family: Verdana; font size: 10px; font-weight: bold}
Kemudian, elemen paragraf, yang merupakan turunan dari div dalam hierarki konteks, dapat memiliki struktur font yang sama dengan induknya. Ini adalah jika tidak ada aturan font yang ditentukan untuk paragraf.
Di WebKit, yang tidak memiliki hierarki aturan, deklarasi yang cocok akan dilalui empat kali. Pertama, properti prioritas tinggi yang tidak penting diterapkan (properti yang harus diterapkan terlebih dahulu karena properti lain bergantung padanya, seperti tampilan), lalu aturan prioritas tinggi yang penting, lalu aturan prioritas normal yang tidak penting, lalu aturan prioritas normal yang penting. Artinya, properti yang muncul beberapa kali akan di-resolve sesuai dengan urutan cascade yang benar. Yang terakhir menang.
Jadi, untuk meringkas: berbagi objek gaya (seluruhnya atau beberapa struct di dalamnya) akan menyelesaikan masalah 1 dan 3. Hierarki aturan Firefox juga membantu menerapkan properti dalam urutan yang benar.
Memanipulasi aturan untuk pencocokan yang mudah
Ada beberapa sumber untuk aturan gaya:
- Aturan CSS, baik di lembar gaya eksternal maupun di elemen gaya.
css p {color: blue} - Atribut gaya inline seperti
html <p style="color: blue" /> - Atribut visual HTML (yang dipetakan ke aturan gaya yang relevan)
html <p bgcolor="blue" />Dua yang terakhir mudah dicocokkan dengan elemen karena memiliki atribut gaya dan atribut HTML dapat dipetakan menggunakan elemen sebagai kunci.
Seperti yang telah disebutkan sebelumnya dalam masalah #2, pencocokan aturan CSS dapat menjadi lebih rumit. Untuk mengatasi kesulitan tersebut, aturan dimanipulasi agar akses lebih mudah.
Setelah mengurai lembar gaya, aturan ditambahkan ke salah satu dari beberapa peta hash, sesuai dengan pemilih. Ada peta berdasarkan ID, nama class, nama tag, dan peta umum untuk apa pun yang tidak sesuai dengan kategori tersebut. Jika pemilih adalah ID, aturan akan ditambahkan ke peta ID, jika pemilih adalah class, aturan akan ditambahkan ke peta class, dll.
Manipulasi ini mempermudah pencocokan aturan. Tidak perlu mencari di setiap deklarasi: kita dapat mengekstrak aturan yang relevan untuk elemen dari peta. Pengoptimalan ini menghilangkan lebih dari 95% aturan, sehingga aturan tersebut bahkan tidak perlu dipertimbangkan selama proses pencocokan(4.1).
Mari kita lihat contoh aturan gaya berikut:
p.error {color: red}
#messageDiv {height: 50px}
div {margin: 5px}
Aturan pertama akan disisipkan ke dalam peta class. Yang kedua ke peta ID dan yang ketiga ke peta tag.
Untuk fragmen HTML berikut;
<p class="error">an error occurred</p>
<div id=" messageDiv">this is a message</div>
Pertama-tama, kita akan mencoba menemukan aturan untuk elemen p. Peta class akan berisi kunci "error" tempat aturan untuk "p.error" ditemukan. Elemen div akan memiliki aturan yang relevan di peta ID (kuncinya adalah ID) dan peta tag. Jadi, satu-satunya pekerjaan yang tersisa adalah mencari tahu aturan mana yang diekstrak oleh kunci yang benar-benar cocok.
Misalnya, jika aturan untuk div adalah:
table div {margin: 5px}
Elemen ini akan tetap diekstrak dari peta tag, karena kuncinya adalah pemilih paling kanan, tetapi tidak akan cocok dengan elemen div kita, yang tidak memiliki ancestor tabel.
WebKit dan Firefox melakukan manipulasi ini.
Urutan cascade lembar gaya
Objek gaya memiliki properti yang sesuai dengan setiap atribut visual (semua atribut CSS, tetapi lebih umum). Jika properti tidak ditentukan oleh aturan yang cocok, beberapa properti dapat diwarisi oleh objek gaya elemen induk. Properti lainnya memiliki nilai default.
Masalah dimulai saat ada lebih dari satu definisi - inilah urutan cascade untuk menyelesaikan masalah.
Deklarasi untuk properti gaya dapat muncul di beberapa lembar gaya, dan beberapa kali di dalam lembar gaya. Artinya, urutan penerapan aturan sangat penting. Hal ini disebut urutan "cascade". Menurut spesifikasi CSS2, urutan kaskade adalah (dari rendah ke tinggi):
- Deklarasi browser
- Deklarasi normal pengguna
- Deklarasi normal penulis
- Pernyataan penting penulis
- Pernyataan penting pengguna
Deklarasi browser adalah yang paling tidak penting dan pengguna akan mengganti penulis hanya jika deklarasi ditandai sebagai penting. Deklarasi dengan urutan yang sama akan diurutkan berdasarkan spesifikasi, lalu urutan yang ditentukan. Atribut visual HTML diterjemahkan ke deklarasi CSS yang cocok . Aturan ini diperlakukan sebagai aturan penulis dengan prioritas rendah.
Kekhususan
Spesifisitas pemilih ditentukan oleh spesifikasi CSS2 sebagai berikut:
- menghitung 1 jika deklarasi berasal dari atribut 'style', bukan aturan dengan pemilih, 0 jika tidak (= a)
- menghitung jumlah atribut ID dalam pemilih (= b)
- menghitung jumlah atribut dan pseudo-class lain dalam pemilih (= c)
- menghitung jumlah nama elemen dan pseudo-elemen dalam pemilih (= d)
Menggabungkan empat angka a-b-c-d (dalam sistem angka dengan basis besar) akan memberikan kekhususan.
Dasar bilangan yang perlu Anda gunakan ditentukan oleh jumlah tertinggi yang Anda miliki di salah satu kategori.
Misalnya, jika a=14, Anda dapat menggunakan basis heksadesimal. Jika a=17, Anda memerlukan basis angka 17 digit. Situasi yang lebih baru dapat terjadi dengan pemilih seperti ini: html body div div p… (17 tag dalam pemilih Anda… tidak terlalu mungkin).
Beberapa contohnya:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
Mengurutkan aturan
Setelah aturan dicocokkan, aturan tersebut diurutkan sesuai dengan aturan kaskade.
WebKit menggunakan pengurutan gelembung untuk daftar kecil dan pengurutan penggabungan untuk daftar besar.
WebKit menerapkan pengurutan dengan mengganti operator > untuk aturan:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
Proses bertahap
WebKit menggunakan flag yang menandai apakah semua sheet gaya tingkat atas (termasuk @imports) telah dimuat. Jika gaya tidak dimuat sepenuhnya saat dilampirkan, placeholder akan digunakan dan ditandai dalam dokumen, dan akan dihitung ulang setelah sheet gaya dimuat.
Tata Letak
Saat dibuat dan ditambahkan ke hierarki, perender tidak memiliki posisi dan ukuran. Menghitung nilai ini disebut tata letak atau reflow.
HTML menggunakan model tata letak berbasis alur, yang berarti bahwa sebagian besar waktu Anda dapat menghitung geometri dalam satu kali operasi. Elemen yang lebih baru "dalam alur" biasanya tidak memengaruhi geometri elemen yang lebih awal "dalam alur", sehingga tata letak dapat dilanjutkan dari kiri ke kanan, dari atas ke bawah melalui dokumen. Ada pengecualian: misalnya, tabel HTML mungkin memerlukan lebih dari satu kartu.
Sistem koordinat relatif terhadap frame root. Koordinat atas dan kiri digunakan.
Tata letak adalah proses rekursif. Proses ini dimulai di perender root, yang sesuai dengan elemen <html> dokumen HTML. Tata letak berlanjut secara rekursif melalui beberapa atau semua hierarki frame, yang menghitung informasi geometris untuk setiap perender yang memerlukannya.
Posisi perender root adalah 0,0 dan dimensinya adalah area pandang - bagian jendela browser yang terlihat.
Semua perender memiliki metode "tata letak" atau "aliran ulang", setiap perender memanggil metode tata letak turunannya yang memerlukan tata letak.
Sistem bit kotor
Agar tidak melakukan tata letak penuh untuk setiap perubahan kecil, browser menggunakan sistem "bit kotor". Perender yang diubah atau ditambahkan akan menandai dirinya dan turunannya sebagai "kotor": memerlukan tata letak.
Ada dua flag: "dirty", dan "children are dirty" yang berarti bahwa meskipun perender itu sendiri mungkin tidak masalah, perender tersebut memiliki setidaknya satu turunan yang memerlukan tata letak.
Tata letak global dan inkremental
Tata letak dapat dipicu di seluruh hierarki render - ini adalah tata letak "global". Hal ini dapat terjadi karena:
- Perubahan gaya global yang memengaruhi semua perender, seperti perubahan ukuran font.
- Akibat ukuran layar diubah
Tata letak dapat bersifat inkremental, hanya perender yang kotor yang akan ditata (hal ini dapat menyebabkan beberapa kerusakan yang akan memerlukan tata letak tambahan).
Tata letak inkremental dipicu (secara asinkron) saat perender kotor. Misalnya, saat perender baru ditambahkan ke hierarki render setelah konten tambahan berasal dari jaringan dan ditambahkan ke hierarki DOM.
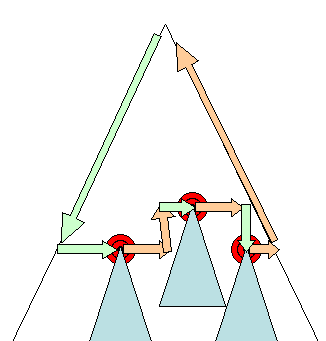
Tata letak Asinkron dan Sinkron
Tata letak inkremental dilakukan secara asinkron. Firefox mengantrekan "perintah aliran ulang" untuk tata letak inkremental dan penjadwal memicu eksekusi batch perintah ini. WebKit juga memiliki timer yang menjalankan tata letak inkremental - hierarki dilalui dan perender "kotor" ditata letak.
Skrip yang meminta informasi gaya, seperti "offsetHeight", dapat memicu tata letak inkremental secara sinkron.
Tata letak global biasanya akan dipicu secara sinkron.
Terkadang tata letak dipicu sebagai callback setelah tata letak awal karena beberapa atribut, seperti posisi scroll, berubah.
Pengoptimalan
Saat tata letak dipicu oleh "resize" atau perubahan posisi perender(dan bukan ukuran), ukuran render diambil dari cache dan tidak dihitung ulang…
Dalam beberapa kasus, hanya sub-hierarki yang diubah dan tata letak tidak dimulai dari root. Hal ini dapat terjadi jika perubahan bersifat lokal dan tidak memengaruhi lingkungannya - seperti teks yang disisipkan ke dalam kolom teks (jika tidak, setiap penekanan tombol akan memicu tata letak yang dimulai dari root).
Proses tata letak
Tata letak biasanya memiliki pola berikut:
- Perender induk menentukan lebarnya sendiri.
- Induk memeriksa turunan dan:
- Tempatkan perender turunan (menetapkan x dan y).
- Memanggil tata letak turunan jika diperlukan - tata letak tersebut kotor atau kita berada dalam tata letak global, atau karena alasan lain - yang menghitung tinggi turunan.
- Induk menggunakan tinggi kumulatif turunan dan tinggi margin serta padding untuk menetapkan tingginya sendiri - ini akan digunakan oleh induk perender induk.
- Menetapkan bit kotornya ke salah (false).
Firefox menggunakan objek "status" (nsHTMLReflowState) sebagai parameter untuk tata letak (disebut "reflow"). Di antara yang lain, status menyertakan lebar induk.
Output tata letak Firefox adalah objek "metrics"(nsHTMLReflowMetrics). Ini akan berisi tinggi yang dihitung perender.
Penghitungan lebar
Lebar perender dihitung menggunakan lebar blok penampung, properti "width" gaya perender, margin, dan batas.
Misalnya, lebar div berikut:
<div style="width: 30%"/>
Akan dihitung oleh WebKit sebagai berikut(metode calcWidth class RenderBox):
- Lebar penampung adalah maksimum dari availableWidth penampung dan 0. Dalam hal ini, availableWidth adalah contentWidth yang dihitung sebagai:
clientWidth() - paddingLeft() - paddingRight()
clientWidth dan clientHeight mewakili bagian dalam objek tidak termasuk batas dan scrollbar.
Lebar elemen adalah atribut gaya "width". Nilai ini akan dihitung sebagai nilai absolut dengan menghitung persentase lebar penampung.
Batas dan padding horizontal kini ditambahkan.
Sejauh ini, ini adalah penghitungan "lebar pilihan". Sekarang lebar minimum dan maksimum akan dihitung.
Jika lebar yang diinginkan lebih besar dari lebar maksimum, lebar maksimum akan digunakan. Jika lebih kecil dari lebar minimum (unit terkecil yang tidak dapat dipecah), lebar minimum akan digunakan.
Nilai disimpan ke dalam cache jika tata letak diperlukan, tetapi lebarnya tidak berubah.
Pemisah Baris
Saat perender di tengah tata letak memutuskan bahwa tata letak perlu dipecah, perender akan berhenti dan menyebarkan ke induk tata letak bahwa tata letak perlu dipecah. Induk membuat perender tambahan dan memanggil tata letak di atasnya.
Melukis
Pada tahap pengecatan, hierarki render dilalui dan metode "paint()" perender dipanggil untuk menampilkan konten di layar. Pengecatan menggunakan komponen infrastruktur UI.
Global dan inkremental
Seperti tata letak, proses menggambar juga dapat bersifat global - seluruh hierarki digambar - atau inkremental. Dalam proses menggambar inkremental, beberapa perender berubah dengan cara yang tidak memengaruhi seluruh hierarki. Perender yang diubah akan membatalkan persegi panjangnya di layar. Hal ini menyebabkan OS melihatnya sebagai "area kotor" dan menghasilkan peristiwa "cat". OS melakukannya dengan cerdik dan menggabungkan beberapa region menjadi satu. Di Chrome, prosesnya lebih rumit karena perender berada dalam proses yang berbeda dengan proses utama. Chrome menyimulasikan perilaku OS sampai batas tertentu. Presentasi memproses peristiwa ini dan mendelegasikan pesan ke root render. Hierarki dilalui hingga perender yang relevan tercapai. Objek ini akan melukis ulang dirinya sendiri (dan biasanya turunannya).
Urutan lukisan
CSS2 menentukan urutan proses gambar. Ini sebenarnya adalah urutan elemen yang ditumpuk dalam konteks penumpukan. Urutan ini memengaruhi proses menggambar karena stack digambar dari belakang ke depan. Urutan penumpukan perender blok adalah:
- warna latar belakang
- gambar latar
- border
- children
- outline
Daftar tampilan Firefox
Firefox memeriksa hierarki render dan membuat daftar tampilan untuk persegi panjang yang dicat. Ini berisi perender yang relevan untuk persegi panjang, dalam urutan gambar yang tepat (latar belakang perender, lalu batas, dll.).
Dengan begitu, hierarki hanya perlu dilalui satu kali untuk proses repaint, bukan beberapa kali - melukis semua latar belakang, lalu semua gambar, lalu semua batas, dll.
Firefox mengoptimalkan proses dengan tidak menambahkan elemen yang akan disembunyikan, seperti elemen yang sepenuhnya berada di bawah elemen buram lainnya.
Penyimpanan persegi panjang WebKit
Sebelum mengecat ulang, WebKit menyimpan persegi panjang lama sebagai bitmap. Kemudian, hanya delta antara persegi panjang baru dan lama yang akan digambar.
Perubahan dinamis
Browser mencoba melakukan tindakan seminimal mungkin sebagai respons terhadap perubahan. Jadi, perubahan pada warna elemen hanya akan menyebabkan elemen dicat ulang. Perubahan pada posisi elemen akan menyebabkan tata letak dan pengecatan ulang elemen, turunannya, dan mungkin saudaranya. Menambahkan node DOM akan menyebabkan tata letak dan pengecatan ulang node. Perubahan besar, seperti meningkatkan ukuran font elemen "html", akan menyebabkan pembatalan validasi cache, penataan ulang, dan pengecatan ulang seluruh hierarki.
Thread mesin rendering
Mesin rendering bersifat single-threaded. Hampir semuanya, kecuali operasi jaringan, terjadi dalam satu thread. Di Firefox dan Safari, ini adalah thread utama browser. Di Chrome, ini adalah thread utama proses tab.
Operasi jaringan dapat dilakukan oleh beberapa thread paralel. Jumlah koneksi paralel terbatas (biasanya 2 - 6 koneksi).
Loop peristiwa
Thread utama browser adalah loop peristiwa. Ini adalah loop tak terbatas yang membuat proses tetap aktif. Fungsi ini menunggu peristiwa (seperti peristiwa tata letak dan gambar) dan memprosesnya. Ini adalah kode Firefox untuk loop peristiwa utama:
while (!mExiting)
NS_ProcessNextEvent(thread);
Model visual CSS2
Kanvas
Menurut spesifikasi CSS2, istilah kanvas menjelaskan "ruang tempat struktur pemformatan dirender": tempat browser melukis konten.
Kanvas tidak terbatas untuk setiap dimensi ruang, tetapi browser memilih lebar awal berdasarkan dimensi area pandang.
Menurut www.w3.org/TR/CSS2/zindex.html, kanvas bersifat transparan jika terdapat dalam kanvas lain, dan diberi warna yang ditentukan browser jika tidak.
Model Box CSS
Model kotak CSS menjelaskan kotak persegi panjang yang dihasilkan untuk elemen dalam hierarki dokumen dan disusun sesuai dengan model pemformatan visual.
Setiap kotak memiliki area konten (misalnya teks, gambar, dll.) dan area padding, batas, dan margin di sekitarnya yang bersifat opsional.
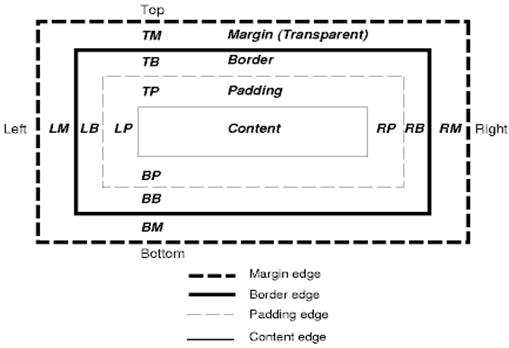
Setiap node menghasilkan 0…n kotak tersebut.
Semua elemen memiliki properti "display" yang menentukan jenis kotak yang akan dibuat.
Contoh:
block: generates a block box.
inline: generates one or more inline boxes.
none: no box is generated.
Defaultnya adalah inline, tetapi sheet gaya browser dapat menetapkan default lainnya. Misalnya: tampilan default untuk elemen "div" adalah blok.
Anda dapat menemukan contoh lembar gaya default di sini: www.w3.org/TR/CSS2/sample.html.
Skema pemosisian
Ada tiga skema:
- Normal: objek diposisikan sesuai tempatnya dalam dokumen. Artinya, posisinya dalam hierarki render sama seperti posisinya dalam hierarki DOM dan disusun sesuai dengan jenis dan dimensi kotaknya
- Mengambang: objek pertama kali ditata seperti alur normal, lalu dipindahkan sejauh mungkin ke kiri atau kanan
- Absolut: objek ditempatkan di hierarki render di tempat yang berbeda dengan di hierarki DOM
Skema pemosisian ditetapkan oleh properti "position" dan atribut "float".
- statis dan relatif menyebabkan alur normal
- absolut dan tetap menyebabkan pemosisian absolut
Dalam pengaturan posisi statis, tidak ada posisi yang ditentukan dan pengaturan posisi default akan digunakan. Dalam skema lainnya, penulis menentukan posisi: atas, bawah, kiri, kanan.
Cara kotak disusun ditentukan oleh:
- Jenis kotak
- Dimensi kotak
- Skema pemosisian
- Informasi eksternal seperti ukuran gambar dan ukuran layar
Jenis kotak
Kotak blok: membentuk blok - memiliki persegi panjangnya sendiri di jendela browser.

Kotak inline: tidak memiliki bloknya sendiri, tetapi berada di dalam blok penampung.
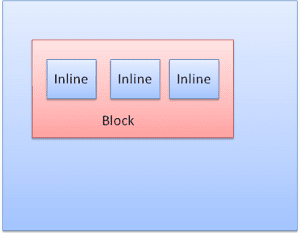
Blok diformat secara vertikal satu per satu. Inline diformat secara horizontal.
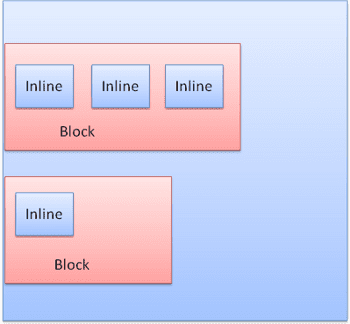
Kotak inline ditempatkan di dalam baris atau "kotak baris". Garis setidaknya setinggi kotak tertinggi, tetapi dapat lebih tinggi, jika kotak disejajarkan "dasar pengukuran" - yang berarti bagian bawah elemen disejajarkan pada titik kotak lain selain bagian bawah. Jika lebar penampung tidak cukup, inline akan ditempatkan di beberapa baris. Hal ini biasanya terjadi dalam sebuah paragraf.
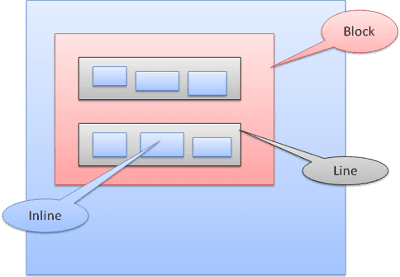
Positioning
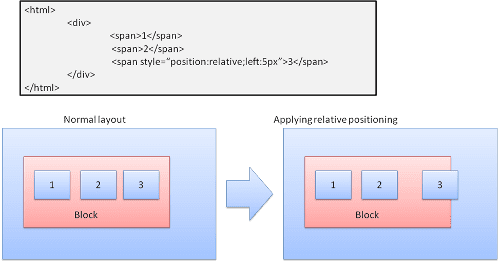
Relatif
Pemosisi relatif - diposisikan seperti biasa, lalu dipindahkan oleh delta yang diperlukan.
Float
Kotak mengambang digeser ke kiri atau kanan garis. Fitur yang menarik adalah kotak lain mengalir di sekitarnya. HTML:
<p>
<img style="float: right" src="images/image.gif" width="100" height="100">
Lorem ipsum dolor sit amet, consectetuer...
</p>
Akan terlihat seperti:

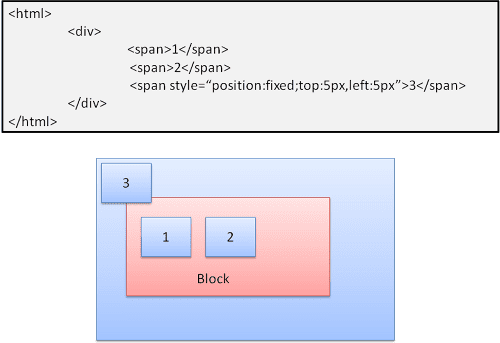
Absolut dan tetap
Tata letak ditentukan secara tepat, terlepas dari alur normal. Elemen tidak berpartisipasi dalam alur normal. Dimensi bersifat relatif terhadap penampung. Dalam mode tetap, penampung adalah area pandang.
Representasi berlapis
Hal ini ditentukan oleh properti CSS z-index. Ini mewakili dimensi ketiga kotak: posisinya di sepanjang "sumbu z".
Kotak dibagi menjadi beberapa kelompok (disebut konteks penumpukan). Di setiap stack, elemen kembali akan digambar terlebih dahulu dan elemen maju di bagian atas, lebih dekat ke pengguna. Jika terjadi tumpang-tindih, elemen paling depan akan menyembunyikan elemen sebelumnya.
Stack diurutkan sesuai dengan properti z-index. Kotak dengan properti "z-index" membentuk stack lokal. Area pandang memiliki stack luar.
Contoh:
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
Hasilnya akan menjadi seperti ini:

Meskipun div merah mendahului div hijau dalam markup, dan akan digambar sebelumnya dalam alur reguler, properti z-index lebih tinggi, sehingga lebih maju dalam stack yang disimpan oleh kotak root.
Resource
Arsitektur browser
- Grosskurth, Alan. A Reference Architecture for Web Browsers (pdf)
- Gupta, Vineet. Cara Kerja Browser - Bagian 1 - Arsitektur
Penguraian
- Aho, Sethi, Ullman, Compilers: Principles, Techniques, and Tools (alias "Dragon book"), Addison-Wesley, 1986
- Rick Jelliffe. The Bold and the Beautiful: dua draf baru untuk HTML 5.
Firefox
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers.
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers (video diskusi teknologi Google)
- L. David Baron, Layout Engine Mozilla
- L. David Baron, Mozilla Style System Documentation
- Chris Waterson, Catatan tentang Pembentukan Ulang HTML
- Chris Waterson, Ringkasan Gecko
- Alexander Larsson, Siklus proses permintaan HTTP HTML
WebKit
- David Hyatt, Mengimplementasikan CSS(bagian 1)
- David Hyatt, Ringkasan WebCore
- David Hyatt, Rendering WebCore
- David Hyatt, The FOUC Problem
Spesifikasi W3C
Petunjuk build browser
Terjemahan
Halaman ini telah diterjemahkan ke dalam bahasa Jepang sebanyak dua kali:
- Cara Kerja Browser - Di Balik Layar Browser Web Modern (ja) oleh @kosei
- ブラウザってどうやって動いてるの?(モダンWEBブラウザシーンの裏側 oleh @ikeike443 dan @kiyoto01.
Anda dapat melihat terjemahan bahasa Korea dan Turki yang dihosting secara eksternal.
Terima kasih semuanya!