
Coulisses des navigateurs Web modernes


Préface
Cet article de référence complet sur les opérations internes de WebKit et de Gecko est le résultat de nombreuses recherches menées par le développeur israélien Tali Garsiel. Au cours de plusieurs années, elle a examiné toutes les données publiées sur le fonctionnement interne des navigateurs et a passé beaucoup de temps à lire le code source des navigateurs Web. Elle a écrit:
En tant que développeur Web, apprendre le fonctionnement interne des navigateurs vous aide à prendre de meilleures décisions et à connaître les raisons des bonnes pratiques de développement. Bien qu'il s'agisse d'un document assez long, nous vous recommandons de prendre le temps de l'examiner. Vous ne le regretterez pas.
Paul Irish, relations avec les développeurs Chrome
Introduction
Les navigateurs Web sont les logiciels les plus utilisés. Dans cet article, je vous explique comment ils fonctionnent en coulisses. Nous allons voir ce qui se passe lorsque vous saisissez google.com dans la barre d'adresse jusqu'à ce que la page Google s'affiche à l'écran du navigateur.
Navigateurs que nous allons aborder
Cinq principaux navigateurs sont utilisés sur ordinateur de bureau aujourd'hui: Chrome, Internet Explorer, Firefox, Safari et Opera. Sur mobile, les principaux navigateurs sont Android Browser, iPhone, Opera Mini et Opera Mobile, UC Browser, les navigateurs Nokia S40/S60 et Chrome, tous basés sur WebKit, à l'exception des navigateurs Opera. Je vais donner des exemples à partir des navigateurs open source Firefox et Chrome, ainsi que de Safari (qui est partiellement open source). Selon les statistiques StatCounter (en juin 2013), Chrome, Firefox et Safari représentent environ 71% de l'utilisation mondiale des navigateurs pour ordinateur. Sur mobile, le navigateur Android, l'iPhone et Chrome représentent environ 54% de l'utilisation.
Fonctionnalité principale du navigateur
La fonction principale d'un navigateur est de présenter la ressource Web de votre choix en la demandant au serveur et en l'affichant dans la fenêtre du navigateur. Il s'agit généralement d'un document HTML, mais il peut également s'agir d'un PDF, d'une image ou d'un autre type de contenu. L'emplacement de la ressource est spécifié par l'utilisateur à l'aide d'un URI (Uniform Resource Identifier).
La façon dont le navigateur interprète et affiche les fichiers HTML est spécifiée dans les spécifications HTML et CSS. Ces spécifications sont gérées par le W3C (World Wide Web Consortium), l'organisation chargée de la normalisation du Web. Pendant des années, les navigateurs ne respectaient qu'une partie des spécifications et développaient leurs propres extensions. Cela a entraîné de sérieux problèmes de compatibilité pour les auteurs Web. Aujourd'hui, la plupart des navigateurs sont plus ou moins conformes aux spécifications.
Les interfaces utilisateur des navigateurs ont beaucoup en commun. Voici quelques éléments d'interface utilisateur courants:
- Barre d'adresse pour insérer un URI
- Boutons "Retour" et "Suivant"
- Options de favoris
- Boutons "Actualiser" et "Arrêter" pour actualiser ou arrêter le chargement des documents en cours
- Bouton "Accueil" qui vous permet d'accéder à votre page d'accueil
Curieusement, l'interface utilisateur du navigateur n'est spécifiée dans aucune spécification formelle. Elle découle simplement de bonnes pratiques façonnées par des années d'expérience et par des navigateurs qui s'imitent les uns les autres. La spécification HTML5 ne définit pas les éléments d'interface utilisateur qu'un navigateur doit posséder, mais elle en liste certains. Il s'agit notamment de la barre d'adresse, de la barre d'état et de la barre d'outils. Il existe bien sûr des fonctionnalités propres à un navigateur spécifique, comme le gestionnaire de téléchargements de Firefox.
Infrastructure de haut niveau
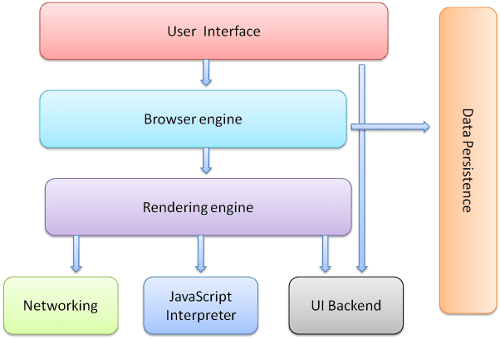
Les principaux composants du navigateur sont les suivants:
- L'interface utilisateur: elle comprend la barre d'adresse, le bouton "Précédent/Suivant", le menu de favoris, etc. Chaque partie de l'écran du navigateur, à l'exception de la fenêtre dans laquelle s'affiche la page demandée.
- Moteur du navigateur: organise les actions entre l'UI et le moteur de rendu.
- Moteur de rendu: responsable de l'affichage du contenu demandé. Par exemple, si le contenu demandé est au format HTML, le moteur de rendu analyse le code HTML et CSS, puis affiche le contenu analysé à l'écran.
- Réseautage: pour les appels réseau tels que les requêtes HTTP, en utilisant différentes implémentations pour différentes plates-formes derrière une interface indépendante de la plate-forme.
- Backend de l'UI: permet de dessiner des widgets de base tels que des zones de liste déroulante et des fenêtres. Ce backend expose une interface générique qui n'est pas spécifique à la plate-forme. En dessous, il utilise les méthodes de l'interface utilisateur du système d'exploitation.
- Interpréteur JavaScript Permet d'analyser et d'exécuter du code JavaScript.
- Stockage de données. Il s'agit d'une couche de persistance. Le navigateur peut être amené à enregistrer toutes sortes de données localement, comme des cookies. Les navigateurs sont également compatibles avec des mécanismes de stockage tels que localStorage, IndexedDB, WebSQL et FileSystem.
Il est important de noter que les navigateurs tels que Chrome exécutent plusieurs instances du moteur de rendu: une pour chaque onglet. Chaque onglet s'exécute dans un processus distinct.
Moteurs de rendu
Le moteur de rendu a pour fonction de… rendre, c'est-à-dire d'afficher les contenus demandés à l'écran du navigateur.
Par défaut, le moteur de rendu peut afficher des documents et des images HTML et XML. Il peut afficher d'autres types de données via des plug-ins ou des extensions, par exemple en affichant des documents PDF à l'aide d'un plug-in de lecteur PDF. Toutefois, dans ce chapitre, nous allons nous concentrer sur le cas d'utilisation principal: l'affichage de code HTML et d'images mises en forme à l'aide de CSS.
Les différents navigateurs utilisent différents moteurs de rendu: Internet Explorer utilise Trident, Firefox utilise Gecko et Safari utilise WebKit. Chrome et Opera (à partir de la version 15) utilisent Blink, une fourchette de WebKit.
WebKit est un moteur de rendu Open Source qui a commencé comme moteur pour la plate-forme Linux, puis a été modifié par Apple pour être compatible avec Mac et Windows.
Flux principal
Le moteur de rendu commence à récupérer le contenu du document demandé à partir de la couche réseau. Cela se fait généralement par blocs de 8 ko.
Voici le flux de base du moteur de rendu:

Le moteur de rendu commence à analyser le document HTML et à convertir les éléments en nœuds DOM dans un arbre appelé "arborescence de contenu". Le moteur analyse les données de style, à la fois dans les fichiers CSS externes et dans les éléments de style. Les informations de style ainsi que les instructions visuelles du code HTML seront utilisées pour créer un autre arbre: l'arborescence de rendu.
L'arborescence de rendu contient des rectangles avec des attributs visuels tels que la couleur et les dimensions. Les rectangles sont dans le bon ordre pour être affichés à l'écran.
Après la construction de l'arborescence de rendu, elle passe par un processus de mise en page. Cela signifie que vous devez indiquer à chaque nœud les coordonnées exactes où il doit apparaître à l'écran. L'étape suivante consiste à peindre. L'arborescence de rendu sera parcourue et chaque nœud sera peint à l'aide de la couche backend de l'UI.
Il est important de comprendre qu'il s'agit d'un processus progressif. Pour une meilleure expérience utilisateur, le moteur de rendu tente d'afficher les contenus à l'écran dès que possible. Il n'attend pas que tout le code HTML soit analysé avant de commencer à créer et à mettre en page l'arborescence de rendu. Certaines parties du contenu seront analysées et affichées, tandis que le processus continue avec le reste du contenu provenant du réseau.
Exemples de flux principaux
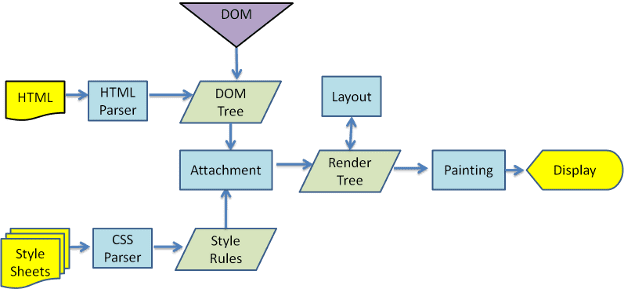
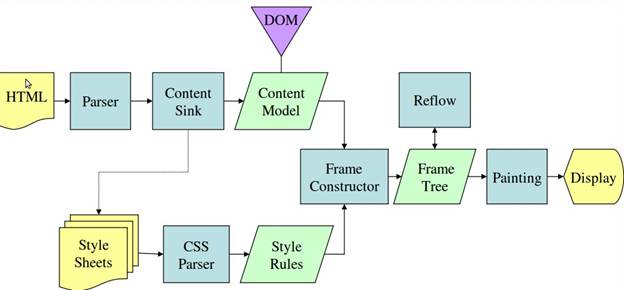
Les figures 3 et 4 montrent que, bien que WebKit et Gecko utilisent une terminologie légèrement différente, le flux est fondamentalement le même.
Gecko appelle l'arborescence des éléments mis en forme visuellement un "Frame tree" (arborescence de cadres). Chaque élément est un frame. WebKit utilise le terme "arbre de rendu", qui se compose d'objets de rendu. WebKit utilise le terme "mise en page" pour désigner l'emplacement des éléments, tandis que Gecko l'appelle "mise en forme". "Attachment" est le terme utilisé par WebKit pour connecter les nœuds DOM et les informations visuelles afin de créer l'arborescence de rendu. Une différence non sémantique mineure est que Gecko comporte une couche supplémentaire entre le code HTML et l'arborescence DOM. Il s'agit du "sink de contenu", une fabrique d'éléments DOM. Nous allons examiner chaque partie du flux:
Analyse – Général
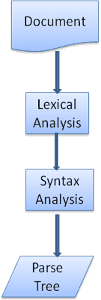
Étant donné que l'analyse syntaxique est un processus très important dans le moteur de rendu, nous allons l'examiner plus en détail. Commençons par une petite introduction à l'analyse.
L'analyse d'un document consiste à le traduire en une structure que le code peut utiliser. Le résultat de l'analyse est généralement un arbre de nœuds qui représente la structure du document. C'est ce qu'on appelle un arbre d'analyse ou un arbre syntaxique.
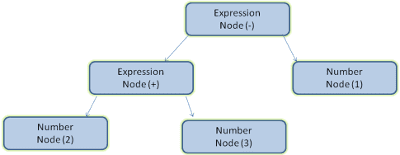
Par exemple, l'analyse de l'expression 2 + 3 - 1 peut renvoyer cet arbre:
Grammaire
L'analyse syntaxique repose sur les règles de syntaxe auxquelles le document est soumis, c'est-à-dire la langue ou le format dans lesquels il a été rédigé. Chaque format que vous pouvez analyser doit avoir une grammaire déterministe composée de règles de vocabulaire et de syntaxe. Il s'agit d'une grammaire sans contexte. Les langues humaines ne sont pas de telles langues et ne peuvent donc pas être analysées à l'aide de techniques d'analyse conventionnelles.
Combinaison analyseur-analyseur lexical
L'analyse syntaxique peut être divisée en deux sous-processus: l'analyse lexicale et l'analyse syntaxique.
L'analyse lexicale consiste à diviser l'entrée en jetons. Les jetons constituent le vocabulaire de la langue, c'est-à-dire l'ensemble des éléments de base valides. En langage humain, il s'agit de tous les mots qui figurent dans le dictionnaire de cette langue.
L'analyse syntaxique consiste à appliquer les règles de syntaxe du langage.
Les analyseurs divisent généralement le travail en deux composants: le lexificateur (parfois appelé "tokenizer") qui est chargé de diviser l'entrée en jetons valides, et l'analyseur qui est chargé de construire l'arborescence d'analyse en analysant la structure du document conformément aux règles de syntaxe du langage.
Le lexer sait supprimer les caractères non pertinents, tels que les espaces blancs et les sauts de ligne.
Le processus d'analyse est itératif. L'analyseur demande généralement un nouveau jeton au lexer et tente de le faire correspondre à l'une des règles de syntaxe. Si une règle est appliquée, un nœud correspondant au jeton est ajouté à l'arborescence d'analyse, et l'analyseur demande un autre jeton.
Si aucune règle ne correspond, l'analyseur stocke le jeton en interne et continue de demander des jetons jusqu'à ce qu'une règle correspondant à tous les jetons stockés en interne soit trouvée. Si aucune règle n'est trouvée, l'analyseur génère une exception. Cela signifie que le document n'était pas valide et contenait des erreurs de syntaxe.
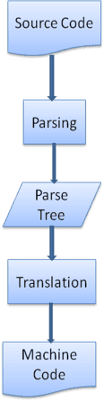
Traduction
Dans de nombreux cas, l'arbre d'analyse n'est pas le produit final. L'analyse syntaxique est souvent utilisée dans la traduction: elle permet de transformer le document d'entrée en un autre format. (par exemple, la compilation). Le compilateur qui compile le code source en code machine l'analyse d'abord dans un arbre d'analyse, puis traduit l'arbre en document de code machine.
Exemple d'analyse
Dans la figure 5, nous avons créé une arborescence d'analyse à partir d'une expression mathématique. Essayons de définir un langage mathématique simple et de voir le processus d'analyse.
Syntaxe :
- Les éléments de base de la syntaxe du langage sont les expressions, les termes et les opérations.
- Notre langage peut inclure un nombre illimité d'expressions.
- Une expression se définit comme un "terme" suivi d'une "opération", puis d'un autre terme.
- Une opération est un jeton plus ou un jeton moins.
- Un terme est un jeton entier ou une expression.
Analysons l'entrée 2 + 3 - 1.
La première sous-chaîne qui correspond à une règle est 2. Selon la règle 5, il s'agit d'un terme.
La deuxième correspondance est 2 + 3. Elle correspond à la troisième règle : un terme suivi d'une opération, puis d'un autre terme.
La correspondance suivante ne sera effectuée qu'à la fin de la saisie.
2 + 3 - 1 est une expression, car nous savons déjà que 2 + 3 est un terme. Nous avons donc un terme suivi d'une opération, puis d'un autre terme.
2 + + ne correspond à aucune règle et est donc une entrée non valide.
Définitions formelles du vocabulaire et de la syntaxe
Le vocabulaire est généralement exprimé à l'aide d'expressions régulières.
Par exemple, notre langue sera définie comme suit:
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -
Comme vous pouvez le constater, les entiers sont définis par une expression régulière.
La syntaxe est généralement définie dans un format appelé BNF. Notre langage sera défini comme suit:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
Nous avons dit qu'une langue peut être analysée par des analyseurs réguliers si sa grammaire est une grammaire sans contexte. Une définition intuitive d'une grammaire sans contexte est une grammaire qui peut être entièrement exprimée en BNF. Pour une définition formelle, consultez l'article Wikipédia sur la grammaire sans contexte.
Types d'analyseurs
Il existe deux types d'analyseurs: les analyseurs top-down et les analyseurs bottom-up. Une explication intuitive est que les analyseurs top-down examinent la structure de haut niveau de la syntaxe et tentent de trouver une correspondance de règle. Les analyseurs ascendants commencent par l'entrée et la transforment progressivement en règles de syntaxe, en commençant par les règles de bas niveau jusqu'à ce que les règles de haut niveau soient respectées.
Voyons comment les deux types d'analyseurs analysent notre exemple.
L'analyseur descendant commencera par la règle de niveau supérieur: il identifiera 2 + 3 comme une expression. Il identifie ensuite 2 + 3 - 1 comme une expression (le processus d'identification de l'expression évolue, en fonction des autres règles, mais le point de départ est la règle de niveau le plus élevé).
L'analyseur ascendant analyse l'entrée jusqu'à ce qu'une règle soit appliquée. La règle remplace ensuite l'entrée correspondante. Cette opération se poursuit jusqu'à la fin de la saisie. L'expression partiellement mise en correspondance est placée sur la pile de l'analyseur.
Ce type d'analyseur ascendant est appelé analyseur par décalage-réduction, car l'entrée est décalée vers la droite (imaginez un pointeur pointant d'abord sur le début de l'entrée et se déplaçant vers la droite) et est progressivement réduite à des règles de syntaxe.
Générer automatiquement des analyseurs
Il existe des outils qui peuvent générer un analyseur. Vous leur fournissez la grammaire de votre langue (son vocabulaire et ses règles de syntaxe), et ils génèrent un analyseur fonctionnel. La création d'un analyseur nécessite une compréhension approfondie de l'analyse, et il n'est pas facile de créer un analyseur optimisé manuellement. Les générateurs d'analyseurs peuvent donc s'avérer très utiles.
WebKit utilise deux générateurs d'analyseurs bien connus: Flex pour créer un analyseur lexical et Bison pour créer un analyseur (vous les trouverez peut-être sous les noms Lex et Yacc). L'entrée Flex est un fichier contenant des définitions d'expressions régulières pour les jetons. La saisie de Bison correspond aux règles de syntaxe de la langue au format BNF.
Analyseur HTML
L'analyseur HTML a pour fonction d'analyser le balisage HTML dans une arborescence d'analyse.
Grammaire HTML
Le vocabulaire et la syntaxe du langage HTML sont définis dans les spécifications créées par l'organisation W3C.
Comme nous l'avons vu dans l'introduction à l'analyse syntaxique, la syntaxe grammaticale peut être définie formellement à l'aide de formats tels que la BNF.
Malheureusement, tous les sujets d'analyseur conventionnels ne s'appliquent pas au code HTML (je ne les ai pas évoqués juste pour le plaisir : ils seront utilisés pour l'analyse du code CSS et JavaScript). Le code HTML ne peut pas être facilement défini par une grammaire sans contexte dont les analyseurs ont besoin.
Il existe un format formel pour définir le code HTML : la définition de type de document (DTD), mais il ne s'agit pas d'une grammaire sans contexte.
Cela peut sembler étrange à première vue, car le code HTML est assez proche du code XML. De nombreux outils d'analyse XML sont disponibles. Il existe une variante XML du langage HTML, le XHTML. Quelle est la grande différence ?
La différence est que l'approche HTML est plus "indulgente": elle vous permet d'omettre certaines balises (qui sont ensuite ajoutées implicitement), ou parfois d'omettre des balises de début ou de fin, etc. Dans l'ensemble, il s'agit d'une syntaxe "souple", par opposition à la syntaxe rigide et exigeante du XML.
Ce détail apparemment mineur fait toute la différence. D'une part, c'est la raison principale pour laquelle le langage HTML est si populaire: il pardonne vos erreurs et facilite la vie de l'auteur Web. En revanche, cela rend l'écriture d'une grammaire formelle difficile. Pour résumer, le code HTML ne peut pas être facilement analysé par les analyseurs conventionnels, car sa grammaire n'est pas indépendante du contexte. Les analyseurs XML ne peuvent pas analyser le code HTML.
DTD HTML
La définition HTML est au format DTD. Ce format permet de définir les langues de la famille SGML. Le format contient des définitions pour tous les éléments autorisés, leurs attributs et leur hiérarchie. Comme nous l'avons vu précédemment, la DTD HTML ne forme pas une grammaire sans contexte.
Il existe quelques variantes de la DTD. Le mode strict se conforme uniquement aux spécifications, mais les autres modes sont compatibles avec le balisage utilisé par les navigateurs par le passé. L'objectif est de garantir la rétrocompatibilité avec les contenus plus anciens. Vous trouverez la DTD stricte actuelle ici : www.w3.org/TR/html4/strict.dtd.
DOM
L'arborescence de sortie (l'"arborescence d'analyse") est une arborescence d'éléments DOM et de nœuds d'attributs. DOM signifie "Document Object Model". Il s'agit de la présentation de l'objet du document HTML et de l'interface des éléments HTML avec le monde extérieur, comme JavaScript.
La racine de l'arborescence est l'objet Document.
Le DOM a une relation presque individuelle avec le balisage. Exemple :
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
Ce balisage serait traduit en arborescence DOM suivante:
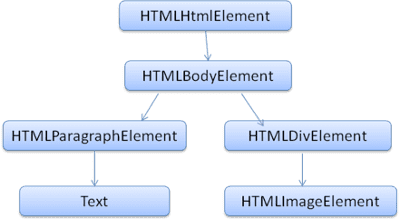
Comme le HTML, le DOM est spécifié par l'organisation W3C. Consultez www.w3.org/DOM/DOMTR. Il s'agit d'une spécification générique pour la manipulation de documents. Un module spécifique décrit les éléments spécifiques au langage HTML. Vous trouverez les définitions HTML sur la page www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html.
Lorsque je dis que l'arborescence contient des nœuds DOM, cela signifie qu'elle est constituée d'éléments qui implémentent l'une des interfaces DOM. Les navigateurs utilisent des implémentations concrètes qui comportent d'autres attributs utilisés en interne par le navigateur.
L'algorithme d'analyse
Comme nous l'avons vu dans les sections précédentes, le code HTML ne peut pas être analysé à l'aide des analyseurs ascendants ou descendants standards.
Pour les raisons suivantes :
- La nature tolérante de la langue.
- Le fait que les navigateurs disposent d'une tolérance aux erreurs traditionnelle pour prendre en charge les cas bien connus de code HTML non valide.
- Le processus d'analyse est réentrant. Pour les autres langages, la source ne change pas lors de l'analyse, mais en HTML, le code dynamique (tels que les éléments de script contenant des appels
document.write()) peut ajouter des jetons supplémentaires. Le processus d'analyse modifie donc l'entrée.
Ne pouvant pas utiliser les techniques d'analyse régulières, les navigateurs créent des analyseurs personnalisés pour l'analyse du code HTML.
L'algorithme d'analyse est décrit en détail dans la spécification HTML5. L'algorithme comprend deux étapes: la tokenisation et la création d'un arbre.
La tokenisation est l'analyse lexicale, qui analyse l'entrée en jetons. Les jetons HTML incluent les balises de début, les balises de fin, les noms d'attributs et les valeurs d'attributs.
Le tokenizer reconnaît le jeton, le transmet au constructeur d'arbre et consomme le caractère suivant pour reconnaître le jeton suivant, et ainsi de suite jusqu'à la fin de l'entrée.
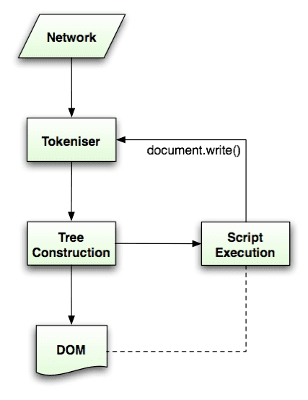
L'algorithme de tokenisation
La sortie de l'algorithme est un jeton HTML. L'algorithme est exprimé sous la forme d'une machine à états. Chaque état consomme un ou plusieurs caractères du flux d'entrée et met à jour l'état suivant en fonction de ces caractères. La décision est influencée par l'état actuel de la tokenisation et par l'état de la construction de l'arborescence. Cela signifie que le même caractère consommé génère des résultats différents pour l'état suivant correct, en fonction de l'état actuel. L'algorithme est trop complexe pour être décrit dans son intégralité. Voyons donc un exemple simple qui nous aidera à comprendre le principe.
Exemple de base : tokenisation du code HTML suivant :
<html>
<body>
Hello world
</body>
</html>
L'état initial est "État des données".
Lorsque le caractère < est rencontré, l'état est défini sur "Tag open state" (État d'ouverture de la balise).
La consommation d'un caractère a-z entraîne la création d'un "jeton de balise de début". L'état est modifié en "État du nom de la balise".
Nous restons dans cet état jusqu'à ce que le caractère > soit consommé. Chaque caractère est ajouté au nom du nouveau jeton. Dans notre cas, le jeton créé est un jeton html.
Lorsque la balise > est atteinte, le jeton actuel est émis et l'état revient à "État des données".
La balise <body> sera traitée de la même manière.
Jusqu'à présent, les balises html et body ont été émises. Nous sommes maintenant de retour dans la section État des données.
La consommation du caractère H de Hello world entraîne la création et l'émission d'un jeton de caractère, qui se poursuit jusqu'à ce que le < de </body> soit atteint. Nous émettrons un jeton de caractère pour chaque caractère de Hello world.
Nous sommes maintenant de retour à l'étape "État d'ouverture de la balise".
La consommation de l'/ d'entrée suivante entraîne la création d'un end tag token et le passage à l'état "État du nom de la balise". Nous restons à nouveau dans cet état jusqu'à ce que nous atteignions >.Le nouveau jeton de balise est alors émis, et nous revenons à l'état "État des données".
L'entrée </html> sera traitée comme dans le cas précédent.
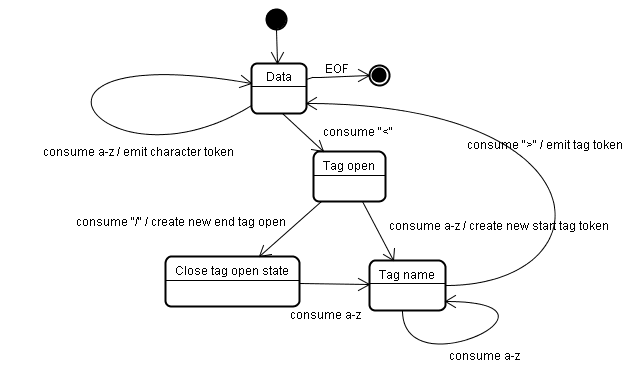
Algorithme de création d'arbre
Lorsque l'analyseur est créé, l'objet Document est également créé. Lors de la phase de construction de l'arborescence, l'arborescence DOM avec le document en racine sera modifiée et des éléments y seront ajoutés. Chaque nœud émis par le tokenizer sera traité par le constructeur d'arbre. Pour chaque jeton, la spécification définit l'élément DOM qui lui est pertinent et qui sera créé pour ce jeton. L'élément est ajouté à l'arborescence DOM et à la pile d'éléments ouverts. Cette pile permet de corriger les incohérences d'imbrication et les balises non fermées. L'algorithme est également décrit comme une machine à états. Ces états sont appelés "modes d'insertion".
Voyons le processus de construction de l'arbre pour l'exemple d'entrée:
<html>
<body>
Hello world
</body>
</html>
L'entrée de l'étape de construction de l'arborescence est une séquence de jetons issus de l'étape de tokenisation. Le premier mode est le mode initial. La réception du jeton "html" entraîne le passage au mode "avant HTML" et un nouveau traitement du jeton dans ce mode. L'élément HTMLHtmlElement est alors créé et ajouté à l'objet Document racine.
L'état est remplacé par "before head". Le jeton "body" est ensuite reçu. Un élément HTMLHeadElement sera créé implicitement, même si nous ne disposons pas d'un jeton "head", et il sera ajouté à l'arborescence.
Nous passons maintenant au mode "dans la tête", puis au mode "après la tête". Le jeton de corps est ré-analysé, un élément HTMLBodyElement est créé et inséré, et le mode est transféré vers "in body" (dans le corps).
Les jetons de caractères de la chaîne "Hello world" sont maintenant reçus. Le premier provoque la création et l'insertion d'un nœud "Texte", et les autres caractères sont ajoutés à ce nœud.
La réception du jeton de fin du corps entraîne un transfert vers le mode "après le corps". Nous allons maintenant recevoir la balise de fin HTML, qui nous permettra de passer en mode "après le corps". La réception du jeton de fin de fichier met fin à l'analyse.
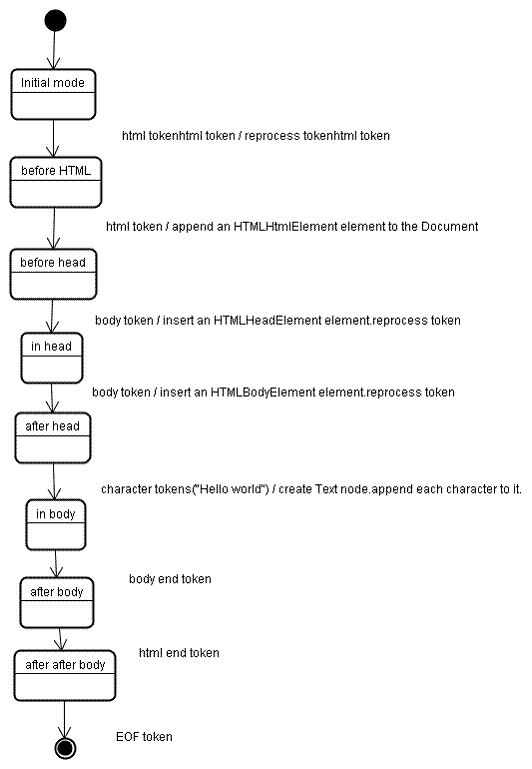
Actions à effectuer une fois l'analyse terminée
À ce stade, le navigateur marque le document comme interactif et commence à analyser les scripts en mode "différé", c'est-à-dire ceux qui doivent être exécutés après l'analyse du document. L'état du document est alors défini sur "Terminé", et un événement de type "load" (chargement) est déclenché.
Vous pouvez consulter les algorithmes complets de tokenisation et de construction d'arborescence dans la spécification HTML5.
Tolérance aux erreurs des navigateurs
Vous ne recevrez jamais d'erreur "Syntaxe incorrecte" sur une page HTML. Les navigateurs corrigent le contenu non valide et continuent.
Prenons cet extrait de code HTML:
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
J'ai dû enfreindre environ un million de règles ("mytag" n'est pas une balise standard, mauvaise imbrication des éléments "p" et "div", etc.), mais le navigateur l'affiche toujours correctement et ne se plaint pas. Une grande partie du code de l'analyseur corrige les erreurs de l'auteur du code HTML.
La gestion des erreurs est assez cohérente dans les navigateurs, mais étonnamment, elle n'a jamais fait partie des spécifications HTML. Comme les boutons "Ajouter aux favoris" et "Précédent/Suivant", il s'agit d'une fonctionnalité qui s'est développée dans les navigateurs au fil des ans. Des constructions HTML non valides connues sont répétées sur de nombreux sites, et les navigateurs tentent de les corriger de manière conforme aux autres navigateurs.
La spécification HTML5 définit certaines de ces exigences. (WebKit le résume bien dans le commentaire au début de la classe d'analyseur HTML.)
L'analyseur analyse l'entrée tokenisée dans le document, créant ainsi l'arborescence du document. Si le document est bien formé, l'analyse est simple.
Malheureusement, nous devons gérer de nombreux documents HTML qui ne sont pas bien structurés. L'analyseur doit donc être tolérant face aux erreurs.
Nous devons prendre en charge au moins les conditions d'erreur suivantes:
- L'élément ajouté est explicitement interdit dans une balise externe. Dans ce cas, nous devons fermer toutes les balises jusqu'à celle qui interdit l'élément, puis l'ajouter.
- Nous ne sommes pas autorisés à ajouter l'élément directement. Il se peut que la personne qui a rédigé le document ait oublié une balise entre les deux (ou que la balise entre les deux soit facultative). Cela peut être le cas avec les balises suivantes: HTML HEAD BODY TBODY TR TD LI (ai-je oublié des balises ?).
- Nous souhaitons ajouter un élément de bloc dans un élément intégré. Fermez tous les éléments en ligne jusqu'à l'élément de bloc supérieur suivant.
- Si le problème persiste, fermez les éléments jusqu'à ce que nous soyons autorisés à ajouter l'élément ou ignorez la balise.
Voici quelques exemples de tolérance aux erreurs WebKit:
</br> au lieu de <br>
Certains sites utilisent </br> au lieu de <br>. Pour être compatible avec IE et Firefox, WebKit le traite comme <br>.
Le code:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
Notez que la gestion des erreurs est interne: elle n'est pas présentée à l'utilisateur.
Un tableau isolé
Une table errante est une table incluse dans une autre table, mais pas dans une cellule de table.
Exemple :
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
WebKit remplace la hiérarchie par deux tables sœurs:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
Le code:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
WebKit utilise une pile pour le contenu de l'élément actuel: il fait sortir la table intérieure de la pile de tables externes. Les tables sont désormais sœurs.
Éléments de formulaire imbriqués
Si l'utilisateur place un formulaire dans un autre formulaire, le second formulaire est ignoré.
Le code:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
Hiérarchie de balises trop profonde
Le commentaire parle de lui-même.
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
Balises de fin html ou body mal placées
Encore une fois, le commentaire parle de lui-même.
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
Alors, méfiez-vous, auteurs Web : à moins que vous ne souhaitiez figurer en exemple dans un extrait de code de tolérance aux erreurs WebKit, écrivez du code HTML bien formé.
Analyse CSS
Vous vous souvenez des concepts d'analyse dans l'introduction ? Contrairement au code HTML, le code CSS est une grammaire sans contexte et peut être analysé à l'aide des types d'analyseurs décrits dans l'introduction. En fait, la spécification CSS définit la grammaire lexicale et syntaxique du CSS.
Voici quelques exemples:
La grammaire lexicale (vocabulaire) est définie par des expressions régulières pour chaque jeton:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
"ident" est l'abréviation d'identifiant, comme un nom de classe. "name" est un ID d'élément (indiqué par "#")
La grammaire de syntaxe est décrite en BNF.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
Explication :
Un ensemble de règles se présente comme suit:
div.error, a.error {
color:red;
font-weight:bold;
}
div.error et a.error sont des sélecteurs. La partie située entre les accolades contient les règles appliquées par ce jeu de règles.
Cette structure est définie formellement dans cette définition:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
Cela signifie qu'un ensemble de règles est un sélecteur ou un certain nombre de sélecteurs séparés par une virgule et des espaces (S correspond à un espace blanc). Un ensemble de règles contient des accolades, dans lesquelles se trouve une déclaration ou un certain nombre de déclarations séparées par un point-virgule. "declaration" et "selector" seront définis dans les définitions BNF suivantes.
Analyseur CSS WebKit
WebKit utilise des générateurs d'analyseurs Flex et Bison pour créer automatiquement des analyseurs à partir des fichiers de grammaire CSS. Comme vous vous en souvenez de l'introduction du parseur, Bison crée un parseur par réduction par glissement de bas en haut. Firefox utilise un analyseur de haut en bas écrit manuellement. Dans les deux cas, chaque fichier CSS est analysé dans un objet StyleSheet. Chaque objet contient des règles CSS. Les objets de règle CSS contiennent des objets de sélecteur et de déclaration, ainsi que d'autres objets correspondant à la grammaire CSS.
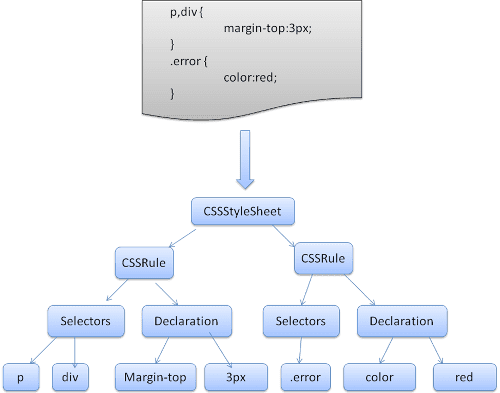
Ordre de traitement des scripts et des feuilles de style
Scripts
Le modèle du Web est synchrone. Les auteurs s'attendent à ce que les scripts soient analysés et exécutés immédiatement lorsque l'analyseur atteint une balise <script>.
L'analyse du document s'arrête jusqu'à ce que le script ait été exécuté.
Si le script est externe, la ressource doit d'abord être récupérée sur le réseau. Cette opération est également effectuée de manière synchrone, et l'analyse s'arrête jusqu'à ce que la ressource soit récupérée.
Ce modèle a été utilisé pendant de nombreuses années et est également spécifié dans les spécifications HTML4 et 5.
Les auteurs peuvent ajouter l'attribut "defer" à un script. Dans ce cas, il n'arrête pas l'analyse du document et s'exécute après l'analyse. HTML5 ajoute une option permettant de marquer le script comme asynchrone afin qu'il soit analysé et exécuté par un autre thread.
Analyse spéculative
WebKit et Firefox effectuent cette optimisation. Lors de l'exécution des scripts, un autre thread analyse le reste du document, identifie les autres ressources à charger à partir du réseau et les charge. Les ressources peuvent ainsi être chargées sur des connexions parallèles, ce qui améliore la vitesse globale. Remarque : L'analyseur spéculatif n'analyse que les références à des ressources externes telles que des scripts, des feuilles de style et des images externes. Il ne modifie pas l'arborescence DOM, ce qui est laissé à l'analyseur principal.
Feuilles de style
Les feuilles de style, en revanche, ont un modèle différent. D'un point de vue conceptuel, il semble que, comme les feuilles de style ne modifient pas l'arborescence DOM, il n'y a aucune raison d'attendre leur exécution et d'arrêter l'analyse du document. Cependant, les scripts qui demandent des informations de style lors de l'analyse du document présentent un problème. Si le style n'est pas encore chargé et analysé, le script obtient des réponses incorrectes, ce qui a apparemment causé de nombreux problèmes. Il semble s'agir d'un cas particulier, mais il est assez courant. Firefox bloque tous les scripts lorsqu'une feuille de style est encore en cours de chargement et d'analyse. WebKit ne bloque les scripts que lorsqu'ils tentent d'accéder à certaines propriétés de style pouvant être affectées par des feuilles de style non chargées.
Construction de l'arborescence de rendu
Pendant la création de l'arborescence DOM, le navigateur crée une autre arborescence, l'arborescence de rendu. Cette arborescence contient les éléments visuels dans l'ordre dans lequel ils seront affichés. Il s'agit de la représentation visuelle du document. L'objectif de cet arbre est de permettre de peindre les contenus dans le bon ordre.
Firefox appelle les éléments de l'arborescence de rendu "frames". WebKit utilise le terme "moteur de rendu" ou "objet de rendu".
Un moteur de rendu sait comment se mettre en page et se peindre, ainsi que ses enfants.
La classe RenderObject de WebKit, qui est la classe de base des moteurs de rendu, est définie comme suit:
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
Chaque moteur de rendu représente une zone rectangulaire correspondant généralement à la zone CSS d'un nœud, comme décrit dans la spécification CSS2. Il inclut des informations géométriques telles que la largeur, la hauteur et la position.
Le type de boîte est affecté par la valeur "display" de l'attribut de style pertinent pour le nœud (voir la section Calcul du style). Voici du code WebKit permettant de déterminer le type de rendu à créer pour un nœud DOM, en fonction de l'attribut "display" :
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
Le type d'élément est également pris en compte: par exemple, les commandes de formulaire et les tableaux ont des cadres spéciaux.
Dans WebKit, si un élément souhaite créer un moteur de rendu spécial, il remplace la méthode createRenderer().
Les moteurs de rendu pointent vers des objets de style contenant des informations non géométriques.
Relation de l'arborescence de rendu à l'arborescence DOM
Les moteurs de rendu correspondent à des éléments DOM, mais la relation n'est pas individuelle. Les éléments DOM non visuels ne seront pas insérés dans l'arborescence de rendu. C'est par exemple le cas de l'élément "head". De plus, les éléments dont la valeur d'affichage a été attribuée à "none" n'apparaissent pas dans l'arborescence (alors que les éléments dont la visibilité est "masquée" y apparaissent).
Il existe des éléments DOM qui correspondent à plusieurs objets visuels. Il s'agit généralement d'éléments dont la structure est complexe et qui ne peuvent pas être décrits par un seul rectangle. Par exemple, l'élément "select" comporte trois moteurs de rendu: un pour la zone d'affichage, un pour la liste déroulante et un pour le bouton. De plus, lorsque le texte est divisé en plusieurs lignes, car la largeur n'est pas suffisante pour une seule ligne, les nouvelles lignes sont ajoutées en tant que moteurs de rendu supplémentaires.
Un autre exemple de plusieurs moteurs de rendu est le code HTML incorrect. Selon la spécification CSS, un élément intégré ne doit contenir que des éléments de bloc ou des éléments intégrés. En cas de contenu mixte, des moteurs de rendu de blocs anonymes seront créés pour encapsuler les éléments intégrés.
Certains objets de rendu correspondent à un nœud DOM, mais pas au même endroit dans l'arborescence. Les éléments flottants et positionnés de manière absolue sont hors flux, placés dans une autre partie de l'arborescence et mappés sur le frame réel. Un cadre d'espace réservé est là où ils auraient dû se trouver.
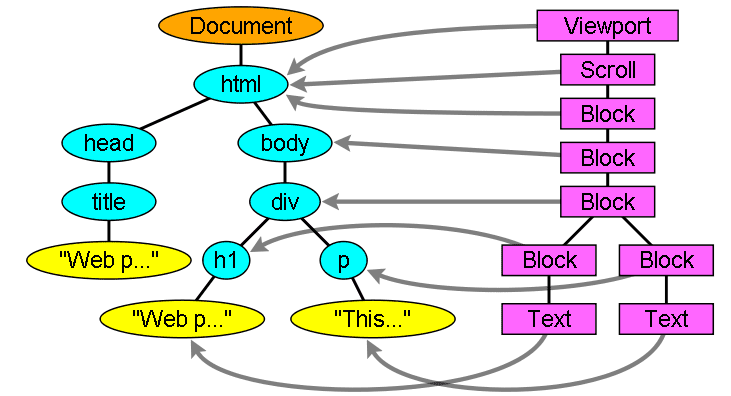
Flux de construction de l'arborescence
Dans Firefox, la présentation est enregistrée en tant qu'écouteur des mises à jour DOM.
La présentation délègue la création de frame à FrameConstructor, et le constructeur résout le style (voir Calcul du style) et crée un frame.
Dans WebKit, le processus de résolution du style et de création d'un moteur de rendu est appelé "attachement". Chaque nœud DOM dispose d'une méthode "attach". L'association est synchrone. L'insertion d'un nœud dans l'arborescence DOM appelle la méthode "attach" du nouveau nœud.
Le traitement des balises html et body permet de créer la racine de l'arborescence de rendu.
L'objet de rendu racine correspond à ce que la spécification CSS appelle le bloc contenant: le bloc le plus élevé qui contient tous les autres blocs. Ses dimensions correspondent à la fenêtre d'affichage, c'est-à-dire aux dimensions de la zone d'affichage de la fenêtre du navigateur.
Firefox l'appelle ViewPortFrame et WebKit RenderView.
Il s'agit de l'objet de rendu auquel le document fait référence.
Le reste de l'arborescence est construit en insérant des nœuds DOM.
Consultez la spécification CSS2 sur le modèle de traitement.
Calcul du style
La création de l'arborescence de rendu nécessite de calculer les propriétés visuelles de chaque objet de rendu. Pour ce faire, les propriétés de style de chaque élément sont calculées.
Le style inclut des feuilles de style de différentes origines, des éléments de style intégrés et des propriétés visuelles dans le code HTML (comme la propriété "bgcolor").Ces dernières sont traduites en propriétés de style CSS correspondantes.
Les feuilles de style proviennent des feuilles de style par défaut du navigateur, des feuilles de style fournies par l'auteur de la page et des feuilles de style utilisateur. Ces dernières sont fournies par l'utilisateur du navigateur (les navigateurs vous permettent de définir vos styles préférés). Dans Firefox, par exemple, cela se fait en plaçant une feuille de style dans le dossier "Profil Firefox".
Le calcul du style pose quelques difficultés:
- Les données de style sont un très grand ensemble qui contient de nombreuses propriétés de style. Cela peut entraîner des problèmes de mémoire.
La recherche des règles correspondantes pour chaque élément peut entraîner des problèmes de performances si elle n'est pas optimisée. Parcourir l'ensemble de la liste de règles pour chaque élément afin de trouver des correspondances est une tâche ardue. Les sélecteurs peuvent avoir une structure complexe qui peut entraîner le démarrage du processus de mise en correspondance sur un chemin apparemment prometteur qui s'avère vain et qu'un autre chemin doit être essayé.
Par exemple, ce sélecteur composé:
div div div div{ ... }Indique que les règles s'appliquent à un
<div>qui est le descendant de trois divs. Supposons que vous souhaitiez vérifier si la règle s'applique à un élément<div>donné. Vous choisissez un chemin particulier dans l'arborescence à vérifier. Vous devrez peut-être remonter l'arborescence des nœuds pour découvrir qu'il n'y a que deux div et que la règle ne s'applique pas. Vous devez ensuite essayer d'autres chemins dans l'arborescence.L'application des règles implique des règles en cascade assez complexes qui définissent la hiérarchie des règles.
Voyons comment les navigateurs font face à ces problèmes:
Partager des données de style
Les nœuds WebKit font référence à des objets de style (RenderStyle). Dans certains cas, ces objets peuvent être partagés par les nœuds. Les nœuds sont frères et sœurs ou cousins, et:
- Les éléments doivent se trouver dans le même état de la souris (par exemple, l'un ne peut pas être en :hover alors que l'autre ne l'est pas).
- Aucun des éléments ne doit avoir d'ID.
- Les noms des balises doivent correspondre
- Les attributs de classe doivent correspondre
- L'ensemble des attributs mappés doit être identique
- Les états des liens doivent correspondre
- Les états de focus doivent correspondre
- Aucun élément ne doit être affecté par les sélecteurs d'attributs, où l'affectation est définie comme étant une correspondance de sélecteur qui utilise un sélecteur d'attribut à n'importe quelle position dans le sélecteur.
- Aucun attribut de style intégré ne doit être appliqué aux éléments.
- Aucun sélecteur frère ne doit être utilisé. WebCore génère simplement un commutateur global lorsqu'un sélecteur frère est rencontré et désactive le partage de style pour l'ensemble du document lorsqu'ils sont présents. Cela inclut le sélecteur + et des sélecteurs tels que :first-child et :last-child.
Arbre des règles Firefox
Firefox dispose de deux arbres supplémentaires pour faciliter le calcul des styles: l'arborescence des règles et l'arborescence du contexte de style. WebKit comporte également des objets de style, mais ils ne sont pas stockés dans une arborescence comme l'arborescence de contexte de style. Seul le nœud DOM pointe vers le style approprié.
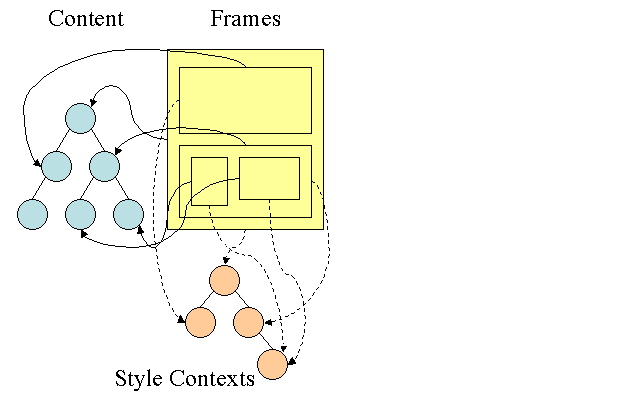
Les contextes de style contiennent des valeurs de fin. Les valeurs sont calculées en appliquant toutes les règles de correspondance dans l'ordre correct et en effectuant des manipulations qui les transforment de valeurs logiques en valeurs concrètes. Par exemple, si la valeur logique correspond à un pourcentage de l'écran, elle sera calculée et convertie en unités absolues. L'idée de l'arborescence de règles est vraiment intelligente. Il permet de partager ces valeurs entre les nœuds pour éviter de les calculer à nouveau. Cela permet également de gagner de l'espace.
Toutes les règles correspondantes sont stockées dans une arborescence. Les nœuds inférieurs d'un chemin ont une priorité plus élevée. L'arborescence contient tous les chemins d'accès aux correspondances de règles trouvées. Le stockage des règles est effectué de manière paresseuse. L'arborescence n'est pas calculée au début pour chaque nœud, mais chaque fois qu'un style de nœud doit être calculé, les chemins calculés sont ajoutés à l'arborescence.
L'idée est de considérer les chemins d'arborescence comme des mots dans un lexique. Supposons que nous ayons déjà calculé cet arbre de règles:
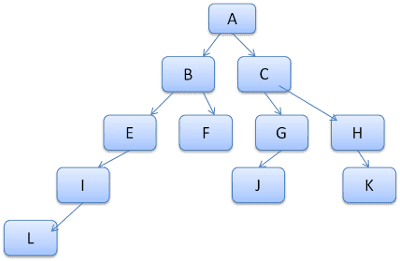
Supposons que nous devions faire correspondre des règles pour un autre élément de l'arborescence de contenu et que nous découvrions que les règles correspondantes (dans l'ordre correct) sont B-E-I. Ce chemin figure déjà dans l'arborescence, car nous avons déjà calculé le chemin A-B-E-I-L. Nous aurons ainsi moins de travail à faire.
Voyons comment l'arborescence nous fait gagner du temps.
Division en structures
Les contextes de style sont divisés en structs. Ces structures contiennent des informations de style pour une certaine catégorie, comme la bordure ou la couleur. Toutes les propriétés d'une struct sont héritées ou non. Les propriétés héritées sont des propriétés qui, sauf si elles sont définies par l'élément, sont héritées de son parent. Les propriétés non héritées (appelées "réinitialiser") utilisent des valeurs par défaut si elles ne sont pas définies.
L'arborescence nous aide en mettant en cache des structures entières (contenant les valeurs de fin calculées) dans l'arborescence. L'idée est que si le nœud inférieur n'a pas fourni de définition pour une struct, une struct mise en cache dans un nœud supérieur peut être utilisée.
Calculer les contextes de style à l'aide de l'arborescence de règles
Lorsque vous calculez le contexte de style d'un élément donné, vous calculez d'abord un chemin dans l'arborescence des règles ou utilisez-en un existant. Nous commençons ensuite à appliquer les règles du chemin d'accès pour remplir les structures dans notre nouveau contexte de style. Nous commençons par le nœud inférieur du chemin d'accès, celui ayant la priorité la plus élevée (généralement le sélecteur le plus spécifique), puis nous remontons l'arborescence jusqu'à ce que notre struct soit remplie. Si aucune spécification n'est fournie pour la struct dans ce nœud de règle, nous pouvons optimiser considérablement le code. Nous remontons l'arborescence jusqu'à trouver un nœud qui la spécifie entièrement et nous y faisons référence. C'est la meilleure optimisation possible, car l'intégralité de la struct est partagée. Cela permet d'économiser de la mémoire et de calculer les valeurs finales.
Si nous trouvons des définitions partielles, nous remontons l'arborescence jusqu'à ce que la structure soit remplie.
Si nous n'avons trouvé aucune définition pour notre struct, et si la struct est un type "hérité", nous pointons vers la struct de notre parent dans l'arborescence de contexte. Dans ce cas, nous avons également réussi à partager des structures. S'il s'agit d'une struct de réinitialisation, les valeurs par défaut sont utilisées.
Si le nœud le plus spécifique ajoute des valeurs, nous devons effectuer des calculs supplémentaires pour les transformer en valeurs réelles. Nous mettons ensuite le résultat en cache dans le nœud d'arborescence afin qu'il puisse être utilisé par les enfants.
Si un élément possède un frère ou une sœur qui pointe vers le même nœud d'arborescence, l'ensemble du contexte de style peut être partagé entre eux.
Prenons un exemple : imaginons que nous ayons le code HTML suivant :
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
Et les règles suivantes:
div {margin: 5px; color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
Pour simplifier les choses, supposons que nous n'ayons besoin de remplir que deux structures: la structure de couleur et la structure de marge. La structure de couleur ne contient qu'un seul membre: la couleur. La structure de marge contient les quatre côtés.
L'arborescence de règles obtenue se présente comme suit (les nœuds sont marqués du nom du nœud: le numéro de la règle vers laquelle ils pointent):
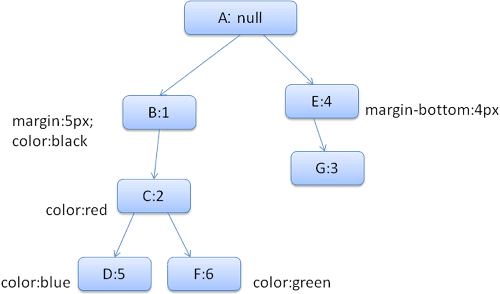
L'arborescence de contexte se présente comme suit (nom du nœud: nœud de règle auquel il fait référence):
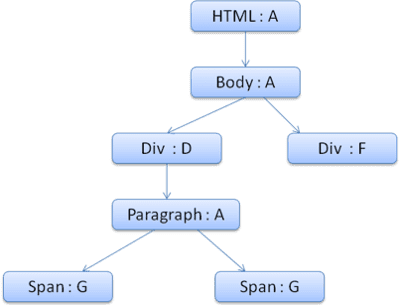
Supposons que nous analysions le code HTML et que nous arrivions à la deuxième balise <div>. Nous devons créer un contexte de style pour ce nœud et remplir ses structures de style.
Nous allons faire correspondre les règles et découvrir que les règles correspondantes pour <div> sont 1, 2 et 6.
Cela signifie qu'un chemin existe déjà dans l'arborescence et que notre élément peut l'utiliser. Il nous suffit d'y ajouter un autre nœud pour la règle 6 (nœud F dans l'arborescence des règles).
Nous allons créer un contexte de style et le placer dans l'arborescence de contexte. Le nouveau contexte de style pointera vers le nœud F dans l'arborescence des règles.
Nous devons maintenant remplir les structures de style. Nous allons commencer par remplir la struct de marge. Étant donné que le dernier nœud de règle (F) n'ajoute rien à la structure de marge, nous pouvons remonter dans l'arborescence jusqu'à trouver une structure mise en cache calculée lors d'une insertion de nœud précédente et l'utiliser. Nous le trouverons sur le nœud B, qui est le nœud le plus élevé qui a spécifié des règles de marge.
Nous avons une définition pour la structure de couleur. Nous ne pouvons donc pas utiliser une structure mise en cache. Étant donné que la couleur comporte un seul attribut, il n'est pas nécessaire de remonter dans l'arborescence pour renseigner d'autres attributs. Nous allons calculer la valeur finale (convertir la chaîne en RVB, etc.) et mettre en cache la struct calculée sur ce nœud.
Le travail sur le deuxième élément <span> est encore plus simple. Nous allons faire correspondre les règles et arriver à la conclusion qu'elle pointe vers la règle G, comme pour la plage précédente.
Étant donné que les frères et sœurs pointent vers le même nœud, nous pouvons partager l'ensemble du contexte de style et simplement pointer vers le contexte de la span précédente.
Pour les structs contenant des règles héritées du parent, la mise en cache est effectuée sur l'arborescence de contexte (la propriété de couleur est en fait héritée, mais Firefox la considère comme réinitialisée et la met en cache dans l'arborescence des règles).
Par exemple, si nous avons ajouté des règles pour les polices dans un paragraphe:
p {font-family: Verdana; font size: 10px; font-weight: bold}
L'élément de paragraphe, qui est un enfant de la div dans l'arborescence de contexte, aurait alors pu partager la même structure de police que son parent. Cela se produit si aucune règle de police n'a été spécifiée pour le paragraphe.
Dans WebKit, qui ne dispose pas d'arborescence de règles, les déclarations correspondantes sont parcourues quatre fois. Les propriétés non importantes de priorité élevée sont appliquées en premier (propriétés qui doivent être appliquées en premier, car d'autres en dépendent, comme l'affichage), puis les règles importantes de priorité élevée, puis les règles non importantes de priorité normale, puis les règles importantes de priorité normale. Cela signifie que les propriétés qui apparaissent plusieurs fois seront résolues dans l'ordre correct de cascade. Le dernier gagne.
Pour résumer: partager les objets de style (entièrement ou certains des structs qu'ils contiennent) résout les problèmes 1 et 3. L'arborescence des règles Firefox permet également d'appliquer les propriétés dans l'ordre correct.
Manipuler les règles pour une correspondance facile
Il existe plusieurs sources de règles de style:
- Les règles CSS, que ce soit dans des feuilles de style externes ou dans des éléments de style.
css p {color: blue} - Attributs de style intégrés tels que
html <p style="color: blue" /> - Attributs visuels HTML (qui sont mappés aux règles de style pertinentes)
html <p bgcolor="blue" />Les deux derniers sont facilement mis en correspondance avec l'élément, car il est propriétaire des attributs de style et les attributs HTML peuvent être mappés à l'aide de l'élément comme clé.
Comme indiqué précédemment dans le problème 2, la mise en correspondance des règles CSS peut être plus délicate. Pour résoudre ce problème, les règles sont manipulées afin de faciliter l'accès.
Après l'analyse de la feuille de style, les règles sont ajoutées à l'une des plusieurs cartes de hachage, en fonction du sélecteur. Il existe des cartes par ID, par nom de classe, par nom de balise et une carte générale pour tout ce qui ne correspond pas à ces catégories. Si le sélecteur est un ID, la règle sera ajoutée à la carte des ID, s'il s'agit d'une classe, elle sera ajoutée à la carte des classes, etc.
Cette manipulation facilite grandement la mise en correspondance des règles. Il n'est pas nécessaire de rechercher dans chaque déclaration: nous pouvons extraire les règles pertinentes pour un élément à partir des cartes. Cette optimisation élimine plus de 95% des règles, de sorte qu'elles n'ont même pas besoin d'être prises en compte lors du processus de mise en correspondance(4.1).
Prenons l'exemple des règles de style suivantes:
p.error {color: red}
#messageDiv {height: 50px}
div {margin: 5px}
La première règle sera insérée dans la carte de classe. Le deuxième dans la carte d'ID et le troisième dans la carte de tags.
Pour le fragment HTML suivant :
<p class="error">an error occurred</p>
<div id=" messageDiv">this is a message</div>
Nous allons d'abord essayer de trouver des règles pour l'élément "p". La carte des classes contient une clé "error" sous laquelle se trouve la règle pour "p.error". L'élément div comportera des règles pertinentes dans la carte d'ID (la clé est l'ID) et la carte de balises. Il ne reste donc plus qu'à déterminer quelles règles extraites par les clés correspondent réellement.
Par exemple, si la règle pour le div était:
table div {margin: 5px}
Il sera toujours extrait de la carte des balises, car la clé est le sélecteur le plus à droite, mais il ne correspondra pas à notre élément div, qui n'a pas d'ancêtre de table.
WebKit et Firefox effectuent cette manipulation.
Ordre de cascade des feuilles de style
L'objet de style comporte des propriétés correspondant à chaque attribut visuel (tous les attributs CSS, mais plus génériques). Si la propriété n'est définie par aucune des règles correspondantes, certaines propriétés peuvent être héritées par l'objet de style de l'élément parent. Les autres propriétés ont des valeurs par défaut.
Le problème commence lorsqu'il existe plusieurs définitions. L'ordre en cascade permet de résoudre le problème.
Une déclaration pour une propriété de style peut apparaître dans plusieurs feuilles de style et plusieurs fois dans une même feuille de style. Par conséquent, l'ordre d'application des règles est très important. C'est ce que l'on appelle l'ordre "cascade". Selon la spécification CSS2, l'ordre de cascade est le suivant (de la priorité la plus faible à la priorité la plus élevée):
- Déclarations de navigateur
- Déclarations normales de l'utilisateur
- Déclarations normales de l'auteur
- Déclarations importantes de l'auteur
- Déclarations importantes pour l'utilisateur
Les déclarations du navigateur sont les moins importantes, et l'utilisateur ne remplace l'auteur que si la déclaration a été marquée comme importante. Les déclarations ayant le même ordre sont triées par spécificité, puis par ordre de spécification. Les attributs visuels HTML sont traduits en déclarations CSS correspondantes . Elles sont traitées comme des règles d'auteur de faible priorité.
Spécificité
La spécificité du sélecteur est définie par la spécification CSS2 comme suit:
- Comptez 1 si la déclaration dont il s'agit est un attribut "style" plutôt qu'une règle avec un sélecteur, sinon 0 (= a).
- compter le nombre d'attributs d'ID dans le sélecteur (= b)
- compter le nombre d'autres attributs et pseudo-classes dans le sélecteur (= c)
- compter le nombre de noms d'éléments et de pseudo-éléments dans le sélecteur (= d) ;
La concatenaison des quatre nombres a-b-c-d (dans un système numérique à base élevée) permet d'obtenir la spécificité.
La base numérique que vous devez utiliser est définie par le nombre le plus élevé que vous avez dans l'une des catégories.
Par exemple, si a=14, vous pouvez utiliser la base hexadécimale. Dans le cas peu probable où a=17, vous aurez besoin d'une base numérique à 17 chiffres. La seconde situation peut se produire avec un sélecteur tel que : html body div div p… (17 balises dans votre sélecteur : peu probable).
Voici quelques exemples :
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
Trier les règles
Une fois les règles mises en correspondance, elles sont triées en fonction des règles en cascade.
WebKit utilise le tri à bulles pour les petites listes et le tri par fusion pour les grandes.
WebKit implémente le tri en ignorant l'opérateur > pour les règles:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
Processus progressif
WebKit utilise un indicateur qui indique si toutes les feuilles de style de premier niveau (y compris @imports) ont été chargées. Si le style n'est pas entièrement chargé lors de l'association, des espaces réservés sont utilisés et cela est indiqué dans le document. Ils seront recalculés une fois les feuilles de style chargées.
Mise en page
Lorsque le moteur de rendu est créé et ajouté à l'arborescence, il n'a pas de position ni de taille. Le calcul de ces valeurs s'appelle mise en page ou reflow.
Le HTML utilise un modèle de mise en page basé sur un flux, ce qui signifie que la plupart du temps, il est possible de calculer la géométrie en une seule passe. Les éléments plus tardifs dans le flux n'affectent généralement pas la géométrie des éléments plus anciens dans le flux. La mise en page peut donc se faire de gauche à droite, de haut en bas dans le document. Il existe des exceptions: par exemple, les tableaux HTML peuvent nécessiter plusieurs passes.
Le système de coordonnées est relatif au frame racine. Les coordonnées en haut et à gauche sont utilisées.
La mise en page est un processus récursif. Il commence par le moteur de rendu racine, qui correspond à l'élément <html> du document HTML. La mise en page continue de manière récursive dans une partie ou la totalité de la hiérarchie des cadres, en calculant des informations géométriques pour chaque moteur de rendu qui en a besoin.
La position du moteur de rendu racine est 0,0, et ses dimensions correspondent à la fenêtre d'affichage, c'est-à-dire à la partie visible de la fenêtre du navigateur.
Tous les moteurs de rendu disposent d'une méthode "mise en page" ou "reflow". Chaque moteur de rendu appelle la méthode de mise en page de ses enfants qui en ont besoin.
Système de bits modifiés
Pour ne pas effectuer une mise en page complète pour chaque petite modification, les navigateurs utilisent un système de "bit sale". Un moteur de rendu modifié ou ajouté se marque lui-même et ses enfants comme "souillés": ils doivent être mis en page.
Il existe deux indicateurs: "dirty" et "children are dirty", ce qui signifie que même si le moteur de rendu lui-même est OK, il comporte au moins un enfant qui nécessite une mise en page.
Mise en page globale et incrémentielle
La mise en page peut être déclenchée sur l'ensemble de l'arborescence de rendu. Il s'agit d'une mise en page "globale". Cela peut être dû aux raisons suivantes:
- Modification de style globale qui affecte tous les moteurs de rendu, comme une modification de la taille de la police.
- En raison du redimensionnement d'un écran
La mise en page peut être incrémentielle. Seuls les moteurs de rendu modifiés seront mis en page (ce qui peut entraîner des dommages nécessitant des mises en page supplémentaires).
La mise en page incrémentielle est déclenchée (de manière asynchrone) lorsque les moteurs de rendu sont sales. Par exemple, lorsque de nouveaux moteurs de rendu sont ajoutés à l'arborescence de rendu après qu'un contenu supplémentaire a été extrait du réseau et ajouté à l'arborescence DOM.
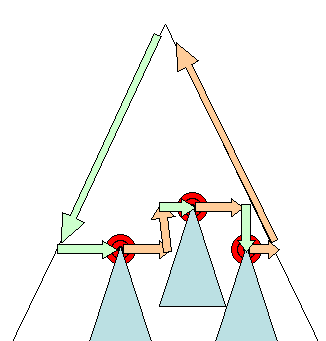
Mise en page asynchrone et synchrone
La mise en page incrémentielle s'effectue de manière asynchrone. Firefox met en file d'attente des "commandes de reflow" pour les mises en page incrémentielles, et un planificateur déclenche l'exécution par lot de ces commandes. WebKit dispose également d'un minuteur qui exécute une mise en page incrémentielle : l'arborescence est parcourue et les moteurs de rendu "sales" sont mis en page.
Les scripts demandant des informations de style, comme "offsetHeight", peuvent déclencher la mise en page incrémentielle de manière synchrone.
La mise en page globale est généralement déclenchée de manière synchrone.
Il arrive que la mise en page soit déclenchée en tant que rappel après une mise en page initiale, car certains attributs, comme la position de défilement, ont changé.
Optimisations
Lorsqu'une mise en page est déclenchée par un "redimensionnement" ou un changement de position du moteur de rendu(et non de taille), les tailles de rendu sont extraites d'un cache et non recalculées.
Dans certains cas, seul un sous-arbre est modifié et la mise en page ne commence pas à la racine. Cela peut se produire lorsque le changement est local et n'affecte pas son environnement, comme le texte inséré dans des champs de texte (sinon, chaque frappe déclencherait une mise en page à partir de la racine).
Processus de mise en page
La mise en page suit généralement le modèle suivant:
- Le moteur de rendu parent détermine sa propre largeur.
- Le parent examine les enfants et :
- Placez le moteur de rendu enfant (définit ses coordonnées x et y).
- Appele la mise en page enfant si nécessaire (elle est sale ou nous sommes dans une mise en page globale, ou pour une autre raison), ce qui calcule la hauteur de l'enfant.
- Le parent utilise les hauteurs cumulées des enfants, ainsi que les hauteurs des marges et des marges intérieures pour définir sa propre hauteur. Celle-ci sera utilisée par le parent du moteur de rendu parent.
- Définit son bit modifié sur "false".
Firefox utilise un objet "state" (nsHTMLReflowState) comme paramètre de mise en page (appelé "reflow"). L'état comprend, entre autres, la largeur des parents.
La sortie de la mise en page Firefox est un objet "métriques" (nsHTMLReflowMetrics). Il contiendra la hauteur calculée du moteur de rendu.
Calcul de la largeur
La largeur du moteur de rendu est calculée à l'aide de la largeur du bloc de conteneur, de la propriété "width" du style du moteur de rendu, des marges et des bordures.
Par exemple, la largeur du div suivant:
<div style="width: 30%"/>
Il est calculé par WebKit comme suit(méthode calcWidth de la classe RenderBox):
- La largeur du conteneur correspond à la valeur maximale de la largeur disponible du conteneur et de 0. Dans ce cas, la valeur "availableWidth" correspond à "contentWidth", qui est calculée comme suit:
clientWidth() - paddingLeft() - paddingRight()
clientWidth et clientHeight représentent l'intérieur d'un objet, à l'exception de la bordure et de la barre de défilement.
La largeur des éléments correspond à l'attribut de style "width". Il est calculé en tant que valeur absolue en calculant le pourcentage de la largeur du conteneur.
Les bordures et les marges intérieures horizontales sont désormais ajoutées.
Jusqu'à présent, il s'agissait du calcul de la "largeur préférée". Les largeurs minimale et maximale sont maintenant calculées.
Si la largeur préférée est supérieure à la largeur maximale, la largeur maximale est utilisée. Si elle est inférieure à la largeur minimale (la plus petite unité indivisible), la largeur minimale est utilisée.
Les valeurs sont mises en cache au cas où une mise en page serait nécessaire, mais la largeur ne change pas.
Sauts de ligne
Lorsqu'un moteur de rendu au milieu d'une mise en page décide qu'il doit être interrompu, il s'arrête et indique à l'élément parent de la mise en page qu'il doit être interrompu. Le parent crée les moteurs de rendu supplémentaires et appelle la mise en page sur eux.
Peinture
À l'étape de peinture, l'arborescence de rendu est parcourue et la méthode "paint()" du moteur de rendu est appelée pour afficher le contenu à l'écran. La peinture utilise le composant d'infrastructure de l'UI.
Global et incrémentiel
Comme la mise en page, la peinture peut également être globale (l'ensemble de l'arborescence est peint) ou incrémentielle. Dans la peinture incrémentielle, certains des moteurs de rendu changent de manière à ne pas affecter l'ensemble de l'arborescence. Le moteur de rendu modifié invalide son rectangle à l'écran. L'OS la considère alors comme une "région sale" et génère un événement "paint". L'OS le fait intelligemment et fusionne plusieurs régions en une seule. Dans Chrome, c'est plus compliqué, car le moteur de rendu se trouve dans un processus différent du processus principal. Chrome simule dans une certaine mesure le comportement du système d'exploitation. La présentation écoute ces événements et délègue le message à la racine de rendu. L'arborescence est parcourue jusqu'à ce que le moteur de rendu approprié soit atteint. Il se redessine (et généralement ses enfants).
Ordre de peinture
CSS2 définit l'ordre du processus de peinture. Il s'agit en fait de l'ordre dans lequel les éléments sont empilés dans les contextes d'empilement. Cet ordre affecte la peinture, car les piles sont peintes de l'arrière vers l'avant. L'ordre d'empilement d'un moteur de rendu de bloc est le suivant:
- couleur de l'arrière-plan
- Image de fond
- border
- enfants
- vue générale
Liste d'affichage Firefox
Firefox parcourt l'arborescence de rendu et crée une liste d'affichage pour le rectangle peint. Il contient les moteurs de rendu pertinents pour le rectangle, dans l'ordre de peinture approprié (arrière-plans des moteurs de rendu, puis bordures, etc.).
De cette manière, l'arbre n'a besoin d'être parcouru qu'une seule fois pour un nouveau dessin au lieu de plusieurs fois (peindre tous les arrière-plans, puis toutes les images, puis toutes les bordures, etc.).
Firefox optimise le processus en n'ajoutant pas d'éléments qui seront masqués, comme les éléments situés complètement sous d'autres éléments opaques.
Stockage de rectangles WebKit
Avant de le redessiner, WebKit enregistre l'ancien rectangle en tant que bitmap. Il ne peint ensuite que la différence entre les nouveaux et les anciens rectangles.
Modifications dynamiques
Les navigateurs tentent d'effectuer le minimum d'actions possibles en réponse à un changement. Par conséquent, les modifications apportées à la couleur d'un élément ne provoquent que son nouveau rendu. Les modifications apportées à la position de l'élément entraînent la mise en page et la remise en peinture de l'élément, de ses enfants et éventuellement de ses frères et sœurs. L'ajout d'un nœud DOM entraîne la mise en page et la remise en peinture du nœud. Les modifications majeures, comme l'augmentation de la taille de police de l'élément "html", entraînent l'invalidation des caches, la redisposition et la remise en peinture de l'ensemble de l'arborescence.
Les threads du moteur de rendu
Le moteur de rendu est à thread unique. Presque tout, à l'exception des opérations réseau, se produit dans un seul thread. Dans Firefox et Safari, il s'agit du thread principal du navigateur. Dans Chrome, il s'agit du thread principal du processus de l'onglet.
Les opérations réseau peuvent être effectuées par plusieurs threads parallèles. Le nombre de connexions parallèles est limité (généralement entre 2 et 6 connexions).
Boucle d'événements
Le thread principal du navigateur est une boucle d'événements. Il s'agit d'une boucle infinie qui maintient le processus actif. Il attend des événements (comme les événements de mise en page et de peinture) et les traite. Voici le code Firefox pour la boucle d'événements principale:
while (!mExiting)
NS_ProcessNextEvent(thread);
Modèle visuel CSS2
Le canevas
Selon la spécification CSS2, le terme "canevas" décrit "l'espace où la structure de mise en forme est affichée", c'est-à-dire l'endroit où le navigateur peint le contenu.
Le canevas est infini pour chaque dimension de l'espace, mais les navigateurs choisissent une largeur initiale en fonction des dimensions de la fenêtre d'affichage.
Selon www.w3.org/TR/CSS2/zindex.html, le canevas est transparent s'il est contenu dans un autre et reçoit une couleur définie par le navigateur s'il ne l'est pas.
Modèle de boîte CSS
Le modèle de boîte CSS décrit les boîtes rectangulaires générées pour les éléments de l'arborescence de documents et disposées selon le modèle de mise en forme visuelle.
Chaque zone comporte une zone de contenu (texte, image, etc.) et des zones de marge, de bordure et de marge intérieure facultatives.
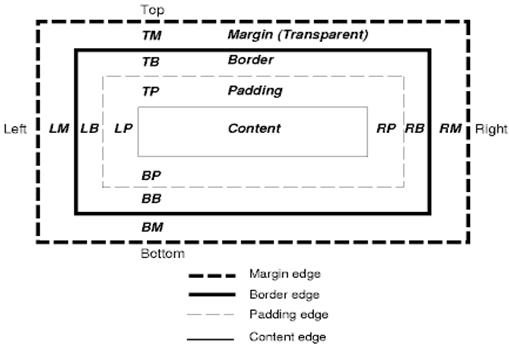
Chaque nœud génère 0 à n boîtes de ce type.
Tous les éléments disposent d'une propriété "display" qui détermine le type de zone qui sera généré.
Exemples :
block: generates a block box.
inline: generates one or more inline boxes.
none: no box is generated.
La valeur par défaut est "inline", mais la feuille de style du navigateur peut définir d'autres valeurs par défaut. Par exemple, l'affichage par défaut de l'élément "div" est "block".
Vous trouverez un exemple de feuille de style par défaut sur www.w3.org/TR/CSS2/sample.html.
Schéma de positionnement
Il existe trois schémas:
- Normal: l'objet est positionné en fonction de son emplacement dans le document. Cela signifie que sa position dans l'arborescence de rendu est semblable à celle dans l'arborescence DOM et qu'elle est mise en page en fonction de son type de boîte et de ses dimensions.
- Flottant: l'objet est d'abord mis en page comme pour un flux normal, puis déplacé aussi loin que possible vers la gauche ou la droite.
- Absolu: l'objet est placé dans l'arborescence de rendu à un emplacement différent de celui de l'arborescence DOM.
Le schéma de positionnement est défini par la propriété "position" et l'attribut "float".
- Les valeurs statiques et relatives génèrent un flux normal.
- Les valeurs "absolute" et "fixed" entraînent un positionnement absolu.
Dans le positionnement statique, aucune position n'est définie et le positionnement par défaut est utilisé. Dans les autres schémas, l'auteur spécifie la position: en haut, en bas, à gauche ou à droite.
La mise en page de la zone est déterminée par les éléments suivants:
- Type de boîte
- Dimensions de la boîte
- Schéma de positionnement
- Informations externes, telles que la taille de l'image et de l'écran
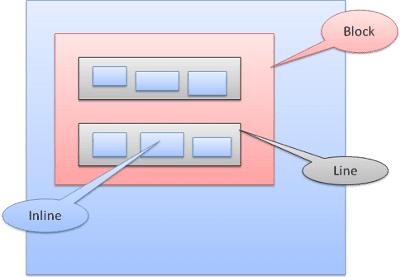
Types de boîtes
Case de bloc: forme un bloc et possède son propre rectangle dans la fenêtre du navigateur.

Boîte intégrée: n'a pas de bloc propre, mais se trouve dans un bloc contenant.
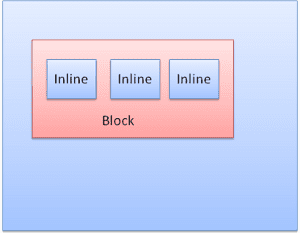
Les blocs sont formatés verticalement, l'un après l'autre. Les éléments intégrés sont formatés horizontalement.
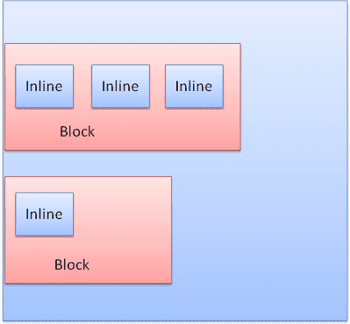
Les encadrés en ligne sont placés dans des lignes ou des "boîtes de ligne". Les lignes sont au moins aussi hautes que la boîte la plus haute, mais elles peuvent être plus hautes lorsque les boîtes sont alignées sur la ligne de base, c'est-à-dire que la partie inférieure d'un élément est alignée sur un point d'une autre boîte autre que le bas. Si la largeur du conteneur est insuffisante, les éléments intégrés seront répartis sur plusieurs lignes. C'est généralement ce qui se passe dans un paragraphe.
Positionnement
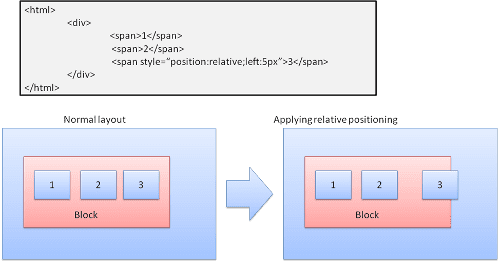
Relative
Positionnement relatif : positionné comme d'habitude, puis déplacé selon le delta requis.
Nombres décimaux
Une zone flottante est décalée vers la gauche ou vers la droite d'une ligne. La caractéristique intéressante est que les autres cases s'adaptent autour de celle-ci. Code HTML:
<p>
<img style="float: right" src="images/image.gif" width="100" height="100">
Lorem ipsum dolor sit amet, consectetuer...
</p>
Il se présentera comme suit:

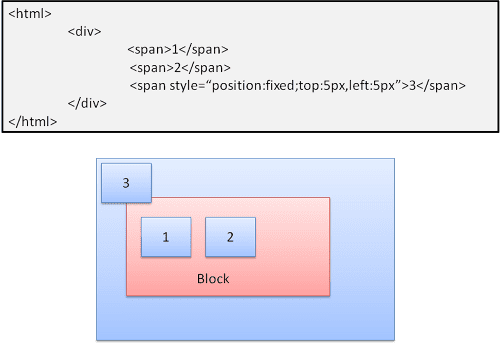
Absolue et fixe
La mise en page est définie avec précision, quel que soit le flux normal. L'élément ne participe pas au flux normal. Les dimensions sont relatives au conteneur. Dans le mode fixe, le conteneur est la fenêtre d'affichage.
Représentation en couches
Cela est spécifié par la propriété CSS z-index. Il représente la troisième dimension du cadre: sa position sur l'axe Z.
Les boîtes sont divisées en piles (appelées contextes d'empilement). Dans chaque pile, les éléments de retour sont peints en premier, et les éléments de progression en haut, plus près de l'utilisateur. En cas de chevauchement, l'élément le plus en avant masque l'élément précédent.
Les piles sont triées en fonction de la propriété z-index. Les boîtes avec la propriété "z-index" forment une pile locale. La fenêtre d'affichage comporte la pile externe.
Exemple :
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
Le résultat sera le suivant:

Bien que le div rouge précède le div vert dans le balisage et qu'il aurait été peint avant dans le flux normal, la propriété z-index est plus élevée. Il est donc plus en avant dans la pile détenue par la boîte racine.
Ressources
Architecture du navigateur
- Grosskurth, Alan. Architecture de référence pour les navigateurs Web (PDF)
- Gupta, Vineet. Fonctionnement des navigateurs - Partie 1 : Architecture
Analyse
- Aho, Sethi, Ullman, Compilers: Principles, Techniques, and Tools (aka the "Dragon book"), Addison-Wesley, 1986
- Rick Jelliffe. The Bold and the Beautiful: deux nouvelles versions préliminaires pour HTML 5.
Firefox
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers (Google tech talk video)
- L. David Baron, moteur de mise en page de Mozilla
- L. David Baron, Mozilla Style System Documentation
- Chris Waterson, Notes sur le reflow HTML
- Chris Waterson, Présentation de Gecko
- Alexander Larsson, The life of an HTML HTTP request
WebKit
- David Hyatt, Implémentation du CSS(partie 1)
- David Hyatt, Présentation de WebCore
- David Hyatt, Rendu WebCore
- David Hyatt, The FOUC Problem
Spécifications du W3C
Instructions de compilation des navigateurs
Traductions
Cette page a été traduite en japonais à deux reprises:
- How Browsers Work - Behind the Scenes of Modern Web Browsers (ja) par @kosei
- ブラウザってどうやって動いてるの?(モダンWEBブラウザシーンの裏側 par @ikeike443 et @kiyoto01.
Vous pouvez consulter les traductions hébergées en externe en coréen et en turc.
Bravo à tous !