
Detrás de escena de los navegadores web modernos


Prefacio
Este manual integral sobre las operaciones internas de WebKit y Gecko es el resultado de una gran investigación realizada por el desarrollador israelí Tali Garsiel. Durante algunos años, revisó todos los datos publicados sobre los componentes internos del navegador y pasó mucho tiempo leyendo el código fuente del navegador web. Ella escribió lo siguiente:
Como desarrollador web, aprender los aspectos internos de las operaciones del navegador te ayuda a tomar mejores decisiones y conocer las justificaciones detrás de las prácticas recomendadas de desarrollo. Si bien este es un documento bastante extenso, te recomendamos que le dediques un tiempo. Te alegrarás de haberlo hecho.
Paul Irish, Relaciones con Desarrolladores de Chrome
Introducción
Los navegadores web son el software más utilizado. En este instructivo, te explico cómo
funcionan en segundo plano. Veremos qué sucede cuando escribes google.com en la barra de direcciones hasta que veas la página de Google en la pantalla del navegador.
Navegadores de los que hablaremos
Actualmente, existen cinco navegadores principales que se usan en computadoras de escritorio: Chrome, Internet Explorer, Firefox, Safari y Opera. En dispositivos móviles, los navegadores principales son el navegador de Android, iPhone, Opera Mini y Opera Mobile, UC Browser, los navegadores Nokia S40/S60 y Chrome, que, excepto los navegadores de Opera, se basan en WebKit. Daré ejemplos de los navegadores de código abierto Firefox y Chrome, y Safari (que es de código abierto en parte). Según las estadísticas de StatCounter (a junio de 2013), Chrome, Firefox y Safari representan alrededor del 71% del uso global de navegadores para computadoras de escritorio. En dispositivos móviles, el navegador para Android, iPhone y Chrome representan alrededor del 54% del uso.
La funcionalidad principal del navegador
La función principal de un navegador es presentar el recurso web que elijas. Para ello, lo solicita al servidor y lo muestra en la ventana del navegador. Por lo general, el recurso es un documento HTML, pero también puede ser un PDF, una imagen o algún otro tipo de contenido. El usuario especifica la ubicación del recurso con un URI (identificador uniforme de recursos).
La forma en que el navegador interpreta y muestra los archivos HTML se especifica en las especificaciones de HTML y CSS. Estas especificaciones son mantenidas por la organización W3C (World Wide Web Consortium), que es la organización de estándares de la Web. Durante años, los navegadores se ajustaron solo a una parte de las especificaciones y desarrollaron sus propias extensiones. Eso causó problemas de compatibilidad graves para los autores web. Hoy en día, la mayoría de los navegadores cumplen más o menos con las especificaciones.
Las interfaces de usuario de los navegadores tienen mucho en común entre sí. Entre los elementos comunes de la interfaz de usuario, se incluyen los siguientes:
- Barra de direcciones para insertar un URI
- Botones Atrás y Adelante
- Opciones de favoritos
- Botones de actualización y detención para actualizar o detener la carga de documentos actuales
- Botón de inicio que te lleva a la página principal
Curiosamente, la interfaz de usuario del navegador no se especifica en ninguna especificación formal, sino que proviene de prácticas recomendadas que se han ido formando a lo largo de años de experiencia y de navegadores que se imitan entre sí. La especificación de HTML5 no define los elementos de la IU que debe tener un navegador, pero enumera algunos elementos comunes. Entre ellas, se encuentran la barra de direcciones, la barra de estado y la barra de herramientas. Por supuesto, hay funciones únicas para un navegador específico, como el administrador de descargas de Firefox.
Infraestructura de alto nivel
Los componentes principales del navegador son los siguientes:
- La interfaz de usuario: Incluye la barra de direcciones, el botón Atrás/Adelante, el menú de favoritos, etc. Todas las partes de la pantalla del navegador, excepto la ventana en la que se ve la página solicitada.
- El motor del navegador: organiza las acciones entre la IU y el motor de renderización.
- El motor de renderización: Es responsable de mostrar el contenido solicitado. Por ejemplo, si el contenido solicitado es HTML, el motor de renderización analiza HTML y CSS, y muestra el contenido analizado en la pantalla.
- Redes: Para llamadas de red, como solicitudes HTTP, usa diferentes implementaciones para diferentes plataformas detrás de una interfaz independiente de la plataforma.
- Backend de la IU: Se usa para dibujar widgets básicos, como cuadros combinados y ventanas. Este backend expone una interfaz genérica que no es específica de la plataforma. Debajo, usa métodos de interfaz de usuario del sistema operativo.
- Intérprete de JavaScript: Se usa para analizar y ejecutar código JavaScript.
- Almacenamiento de datos. Esta es una capa de persistencia. Es posible que el navegador deba guardar todo tipo de datos de forma local, como las cookies. Los navegadores también admiten mecanismos de almacenamiento, como localStorage, IndexedDB, WebSQL y FileSystem.
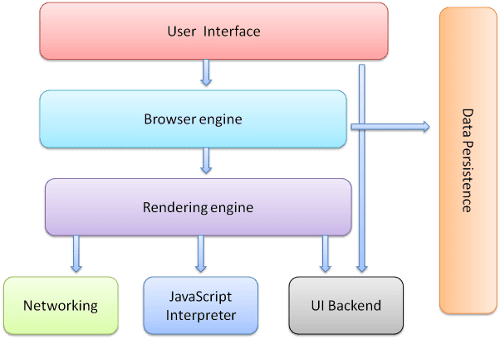
Es importante tener en cuenta que los navegadores como Chrome ejecutan varias instancias del motor de renderización: una para cada pestaña. Cada pestaña se ejecuta en un proceso independiente.
Motores de renderización
La responsabilidad del motor de renderización es, bueno… renderizar, es decir, mostrar el contenido solicitado en la pantalla del navegador.
De forma predeterminada, el motor de renderización puede mostrar imágenes y documentos HTML y XML. Puede mostrar otros tipos de datos a través de complementos o extensiones; por ejemplo, mostrar documentos PDF con un complemento de visor de PDF. Sin embargo, en este capítulo, nos enfocaremos en el caso de uso principal: mostrar HTML y imágenes con formato CSS.
Los diferentes navegadores usan diferentes motores de renderización: Internet Explorer usa Trident, Firefox usa Gecko y Safari usa WebKit. Chrome y Opera (a partir de la versión 15) usan Blink, una bifurcación de WebKit.
WebKit es un motor de renderización de código abierto que comenzó como un motor para la plataforma Linux y que Apple modificó para admitir Mac y Windows.
El flujo principal
El motor de renderización comenzará a obtener el contenido del documento solicitado de la capa de red. Por lo general, esto se hará en fragmentos de 8 KB.
Después de eso, este es el flujo básico del motor de renderización:

El motor de renderización comenzará a analizar el documento HTML y convertirá los elementos en nodos DOM en un árbol llamado "árbol de contenido". El motor analizará los datos de estilo, tanto en archivos CSS externos como en elementos de estilo. La información de diseño junto con las instrucciones visuales en el código HTML se usarán para crear otro árbol: el árbol de renderización.
El árbol de renderización contiene rectángulos con atributos visuales, como el color y las dimensiones. Los rectángulos están en el orden correcto para mostrarse en la pantalla.
Después de la construcción del árbol de renderización, pasa por un proceso de "diseño". Esto significa que se le deben asignar a cada nodo las coordenadas exactas en las que debe aparecer en la pantalla. La siguiente etapa es la pintura: se recorrerá el árbol de renderización y se pintará cada nodo con la capa de backend de la IU.
Es importante comprender que este es un proceso gradual. Para mejorar la experiencia del usuario, el motor de renderización intentará mostrar el contenido en la pantalla lo antes posible. No esperará hasta que se analice todo el código HTML antes de comenzar a compilar y diseñar el árbol de renderización. Se analizarán y mostrarán partes del contenido, mientras el proceso continúa con el resto del contenido que sigue llegando de la red.
Ejemplos de flujo principal
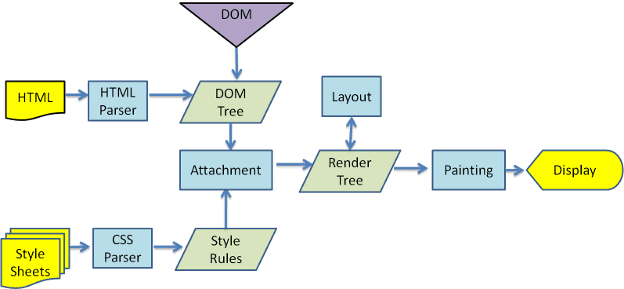
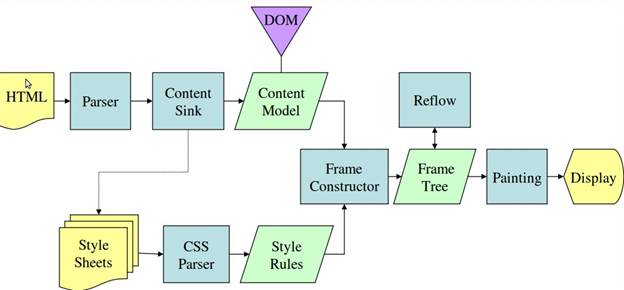
En las figuras 3 y 4, puedes ver que, aunque WebKit y Gecko usan una terminología ligeramente diferente, el flujo es básicamente el mismo.
Gecko llama al árbol de elementos con formato visual "árbol de marcos". Cada elemento es un fotograma. WebKit usa el término "Árbol de renderización" y consta de "Objetos de renderización". WebKit usa el término "diseño" para la colocación de elementos, mientras que Gecko lo llama "reflujo". "Conexión" es el término que usa WebKit para conectar nodos DOM y la información visual para crear el árbol de renderización. Una diferencia menor no semántica es que Gecko tiene una capa adicional entre el HTML y el árbol DOM. Se denomina "sumidero de contenido" y es una fábrica para crear elementos DOM. Hablaremos de cada parte del flujo:
Análisis: General
Dado que el análisis es un proceso muy significativo dentro del motor de renderización, profundizaremos un poco más en él. Comencemos con una pequeña introducción al análisis.
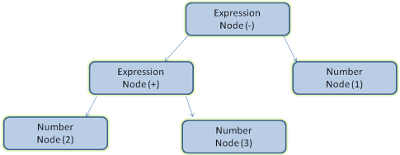
Analizar un documento significa traducirlo a una estructura que el código pueda usar. El resultado del análisis suele ser un árbol de nodos que representa la estructura del documento. Esto se denomina árbol de análisis o árbol de sintaxis.
Por ejemplo, analizar la expresión 2 + 3 - 1 podría mostrar este árbol:
Gramática
El análisis se basa en las reglas de sintaxis que obedece el documento: el lenguaje o el formato en el que se escribió. Cada formato que puedas analizar debe tener una gramática determinista que conste de reglas de vocabulario y sintaxis. Se llama gramática sin contexto. Los lenguajes humanos no son de este tipo y, por lo tanto, no se pueden analizar con técnicas de análisis convencionales.
Combinación de analizador y analizador léxico
El análisis puede separarse en dos subprocesos: el análisis léxico y el análisis de sintaxis.
El análisis léxico es el proceso de dividir la entrada en tokens. Los tokens son el vocabulario del lenguaje: la colección de componentes básicos válidos. En lenguaje humano, consistirá en todas las palabras que aparecen en el diccionario de ese idioma.
El análisis sintáctico es la aplicación de las reglas de sintaxis del lenguaje.
Los analizadores suelen dividir el trabajo entre dos componentes: el analizador de léxico (a veces llamado analizador de tokens) que se encarga de dividir la entrada en tokens válidos y el analizador que se encarga de construir el árbol de análisis mediante el análisis de la estructura del documento según las reglas de sintaxis del lenguaje.
El analizador sabe cómo quitar caracteres irrelevantes, como espacios en blanco y saltos de línea.
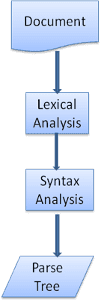
El proceso de análisis es iterativo. Por lo general, el analizador le pedirá al analizador un token nuevo y tratará de hacer coincidir el token con una de las reglas de sintaxis. Si se encuentra una regla coincidente, se agregará un nodo correspondiente al token al árbol de análisis y el analizador solicitará otro token.
Si no se encuentra ninguna regla que coincida, el analizador almacenará el token de forma interna y seguirá solicitando tokens hasta que se encuentre una regla que coincida con todos los tokens almacenados de forma interna. Si no se encuentra ninguna regla, el analizador arrojará una excepción. Esto significa que el documento no era válido y contenía errores de sintaxis.
Traducción
En muchos casos, el árbol de análisis no es el producto final. El análisis se usa a menudo en la traducción: transforma el documento de entrada a otro formato. Un ejemplo es la compilación. El compilador que compila el código fuente en código máquina primero lo analiza en un árbol de análisis y, luego, lo traduce en un documento de código máquina.
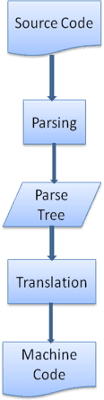
Ejemplo de análisis
En la figura 5, creamos un árbol de análisis a partir de una expresión matemática. Intentemos definir un lenguaje matemático simple y veamos el proceso de análisis.
Sintaxis:
- Los componentes básicos de la sintaxis del lenguaje son expresiones, términos y operaciones.
- Nuestro lenguaje puede incluir cualquier cantidad de expresiones.
- Una expresión se define como un “término” seguido de una “operación” seguida de otro término.
- Una operación es un token más o menos.
- Un término es un token de número entero o una expresión.
Analicemos la entrada 2 + 3 - 1.
La primera subcadena que coincide con una regla es 2: según la regla 5, es un término.
La segunda coincidencia es 2 + 3: coincide con la tercera regla: un término seguido de una operación seguido de otro término.
La siguiente coincidencia solo se realizará al final de la entrada.
2 + 3 - 1 es una expresión porque ya sabemos que 2 + 3 es un término, por lo que tenemos un término seguido de una operación y, luego, otro término.
2 + + no coincidirá con ninguna regla y, por lo tanto, es una entrada no válida.
Definiciones formales del vocabulario y la sintaxis
Por lo general, el vocabulario se expresa con expresiones regulares.
Por ejemplo, nuestro lenguaje se definirá de la siguiente manera:
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -
Como ves, los números enteros se definen con una expresión regular.
Por lo general, la sintaxis se define en un formato llamado BNF. Nuestro lenguaje se definirá de la siguiente manera:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
Dijimos que un lenguaje puede ser analizado por analizadores normales si su gramática es una gramática sin contexto. Una definición intuitiva de una gramática sin contexto es una gramática que se puede expresar por completo en BNF. Para obtener una definición formal, consulta el artículo de Wikipedia sobre gramática sin contexto.
Tipos de analizadores
Existen dos tipos de analizadores: analizadores ascendentes y descendentes. Una explicación intuitiva es que los analizadores ascendentes examinan la estructura de alto nivel de la sintaxis y tratan de encontrar una coincidencia de reglas. Los analizadores ascendentes comienzan con la entrada y la transforman gradualmente en las reglas de sintaxis, a partir de las reglas de bajo nivel hasta que se cumplen las reglas de alto nivel.
Veamos cómo los dos tipos de analizadores analizarán nuestro ejemplo.
El analizador ascendente comenzará desde la regla de nivel superior: identificará 2 + 3 como una expresión. Luego, identificará 2 + 3 - 1 como una expresión (el proceso de identificación de la expresión evoluciona y coincide con las otras reglas, pero el punto de partida es la regla de nivel más alto).
El analizador ascendente analizará la entrada hasta que se encuentre una regla que coincida. Luego, reemplazará la entrada coincidente con la regla. Esto continuará hasta el final de la entrada. La expresión que coincide parcialmente se coloca en la pila del analizador.
Este tipo de analizador ascendente se denomina analizador de desplazamiento y reducción, ya que la entrada se desplaza hacia la derecha (imagina un puntero que primero apunta al inicio de la entrada y se mueve hacia la derecha) y se reduce gradualmente a reglas de sintaxis.
Cómo generar analizadores automáticamente
Existen herramientas que pueden generar un analizador. Le proporcionas la gramática de tu lenguaje (su vocabulario y reglas de sintaxis) y genera un analizador que funciona. Crear un analizador requiere un conocimiento profundo del análisis y no es fácil crear un analizador optimizado de forma manual, por lo que los generadores de analizadores pueden ser muy útiles.
WebKit usa dos generadores de analizadores conocidos: Flex para crear un analizador léxico y Bison para crear un analizador (es posible que los encuentres con los nombres Lex y Yacc). La entrada de Flex es un archivo que contiene definiciones de expresiones regulares de los tokens. La entrada de Bison son las reglas de sintaxis del lenguaje en formato BNF.
Analizador de HTML
La tarea del analizador de HTML es analizar el lenguaje de marcado HTML en un árbol de análisis.
Gramática HTML
El vocabulario y la sintaxis de HTML se definen en las especificaciones creadas por la organización W3C.
Como vimos en la introducción al análisis, la sintaxis de la gramática se puede definir formalmente con formatos como BNF.
Lamentablemente, todos los temas de analizadores convencionales no se aplican al HTML (no los mencioné solo por diversión, se usarán en el análisis de CSS y JavaScript). El HTML no se puede definir fácilmente con una gramática sin contexto que necesitan los analizadores.
Existe un formato formal para definir HTML: el DTD (definición del tipo de documento), pero no es una gramática sin contexto.
Esto puede parecer extraño a primera vista, ya que HTML es bastante similar a XML. Hay muchos analizadores de XML disponibles. Existe una variación XML de HTML: XHTML. ¿Cuál es la gran diferencia?
La diferencia es que el enfoque HTML es más "tolerante": te permite omitir ciertas etiquetas (que luego se agregan de forma implícita) o, a veces, omitir etiquetas de inicio o fin, etcétera. En general, es una sintaxis “flexible”, a diferencia de la sintaxis rígida y exigente de XML.
Este detalle aparentemente pequeño marca una gran diferencia. Por un lado, esta es la razón principal por la que HTML es tan popular: perdona tus errores y le facilita la vida al autor web. Por otro lado, dificulta la escritura de una gramática formal. En resumen, los analizadores convencionales no pueden analizar el HTML fácilmente, ya que su gramática no es independiente del contexto. Los analizadores de XML no pueden analizar el HTML.
DTD de HTML
La definición de HTML está en formato DTD. Este formato se usa para definir lenguajes de la familia SGML. El formato contiene definiciones de todos los elementos permitidos, sus atributos y jerarquía. Como vimos antes, el DTD de HTML no forma una gramática sin contexto.
Existen algunas variaciones del DTD. El modo estricto se ajusta únicamente a las especificaciones, pero otros modos admiten el marcado que usaban los navegadores en el pasado. El objetivo es brindar compatibilidad con versiones anteriores del contenido. El DTD estricto actual se encuentra aquí: www.w3.org/TR/html4/strict.dtd
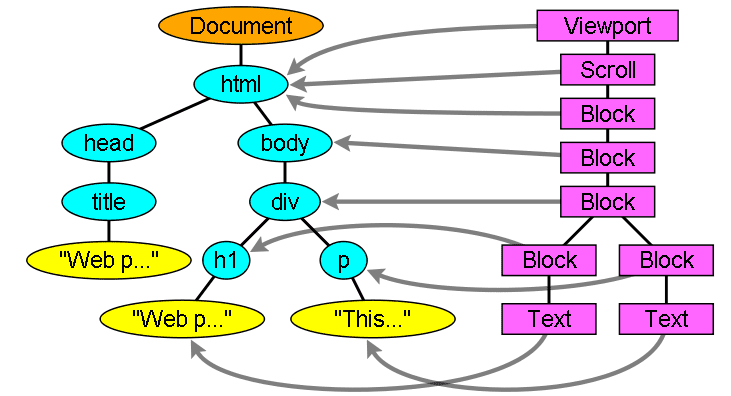
DOM
El árbol de salida (el "árbol de análisis") es un árbol de elementos y nodos de atributos del DOM. DOM es la sigla en inglés de modelo de objetos del documento. Es la presentación del objeto del documento HTML y la interfaz de los elementos HTML para el mundo exterior, como JavaScript.
La raíz del árbol es el objeto "Document".
El DOM tiene una relación casi uno a uno con el marcado. Por ejemplo:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
Este lenguaje de marcado se traduciría al siguiente árbol DOM:
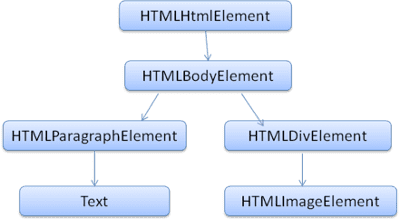
Al igual que HTML, la organización W3C especifica el DOM. Consulta www.w3.org/DOM/DOMTR. Es una especificación genérica para manipular documentos. Un módulo específico describe elementos específicos de HTML. Puedes encontrar las definiciones de HTML aquí: www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html.
Cuando digo que el árbol contiene nodos DOM, quiero decir que el árbol está construido con elementos que implementan una de las interfaces de DOM. Los navegadores usan implementaciones concretas que tienen otros atributos que el navegador usa de forma interna.
El algoritmo de análisis
Como vimos en las secciones anteriores, el HTML no se puede analizar con los analizadores ascendentes o descendentes normales.
Estos son los motivos:
- La naturaleza tolerante del lenguaje.
- El hecho de que los navegadores tengan una tolerancia a errores tradicional para admitir casos conocidos de HTML no válido.
- El proceso de análisis es reentrante. En otros lenguajes, la fuente no cambia durante el análisis, pero en HTML, el código dinámico (como los elementos de secuencia de comandos que contienen llamadas
document.write()) puede agregar tokens adicionales, por lo que el proceso de análisis en realidad modifica la entrada.
Como no pueden usar las técnicas de análisis normales, los navegadores crean analizadores personalizados para analizar el código HTML.
La especificación de HTML5 describe en detalle el algoritmo de análisis. El algoritmo consta de dos etapas: la tokenización y la construcción de árboles.
La tokenización es el análisis léxico, que analiza la entrada en tokens. Entre los tokens HTML, se incluyen etiquetas de apertura, etiquetas de cierre, nombres de atributos y valores de atributos.
El analizador de tokens reconoce el token, se lo pasa al constructor de árboles y consume el siguiente carácter para reconocer el siguiente token, y así sucesivamente hasta el final de la entrada.
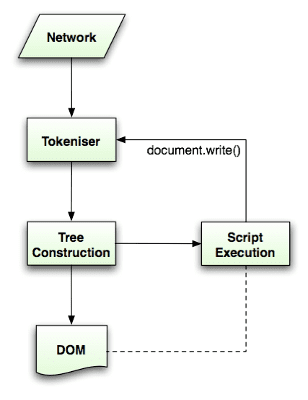
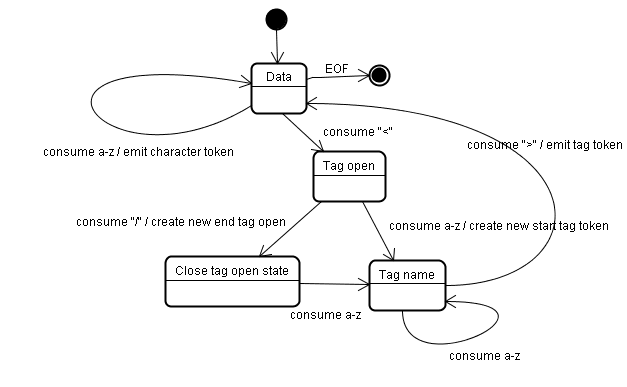
El algoritmo de tokenización
El resultado del algoritmo es un token HTML. El algoritmo se expresa como una máquina de estados. Cada estado consume uno o más caracteres del flujo de entrada y actualiza el siguiente estado según esos caracteres. La decisión está influenciada por el estado actual de la tokenización y por el estado de construcción del árbol. Esto significa que el mismo carácter consumido generará diferentes resultados para el siguiente estado correcto, según el estado actual. El algoritmo es demasiado complejo para describirlo en su totalidad, así que veamos un ejemplo sencillo que nos ayudará a comprender el principio.
Ejemplo básico: Tokenización del siguiente código HTML:
<html>
<body>
Hello world
</body>
</html>
El estado inicial es el "Estado de los datos".
Cuando se encuentra el carácter <, el estado cambia a "Tag open state".
El consumo de un carácter a-z causa la creación de un "token de etiqueta de inicio", y el estado cambia a "Estado del nombre de la etiqueta".
Permanecemos en este estado hasta que se consume el carácter >. Cada carácter se adjunta al nombre del token nuevo. En nuestro caso, el token creado es un token html.
Cuando se alcanza la etiqueta >, se emite el token actual y el estado vuelve a cambiar al "Estado de datos".
La etiqueta <body> se tratará con los mismos pasos.
Hasta el momento, se emitieron las etiquetas html y body. Volvemos a la sección "Estado de los datos".
Si se consume el carácter H de Hello world, se creará y emitirá un token de carácter, y esto continuará hasta que se alcance el < de </body>. Emitiremos un token de carácter para cada carácter de Hello world.
Ahora estamos en el "Estado de etiqueta abierta".
Si se consume la siguiente entrada /, se creará un end tag token y se pasará al "Estado de nombre de etiqueta". Una vez más, nos quedamos en este estado hasta que llegamos a >.Luego, se emitirá el nuevo token de etiqueta y volveremos al "Estado de los datos".
La entrada </html> se tratará como en el caso anterior.
Algoritmo de construcción de árboles
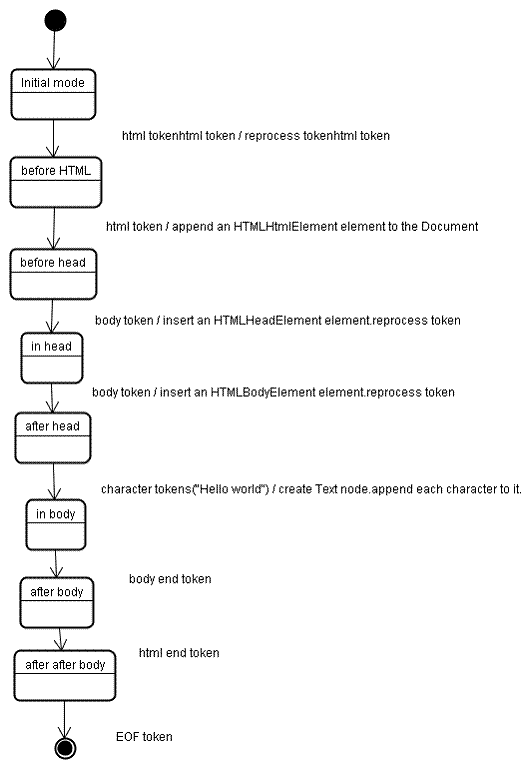
Cuando se crea el analizador, se crea el objeto Document. Durante la etapa de construcción del árbol, se modificará el árbol del DOM con el documento en su raíz y se le agregarán elementos. El constructor de árboles procesará cada nodo que emita el analizador. Para cada token, la especificación define qué elemento DOM es relevante para él y se creará para este token. El elemento se agrega al árbol de DOM y también a la pila de elementos abiertos. Esta pila se usa para corregir discrepancias de anidación y etiquetas no cerradas. El algoritmo también se describe como una máquina de estados. Los estados se denominan "modos de inserción".
Veamos el proceso de construcción del árbol para la entrada de ejemplo:
<html>
<body>
Hello world
</body>
</html>
La entrada a la etapa de construcción del árbol es una secuencia de tokens de la etapa de tokenización. El primer modo es el "modo inicial". Recibir el token "html" provocará un cambio al modo "antes de html" y un nuevo procesamiento del token en ese modo. Esto hará que se cree el elemento HTMLHtmlElement, que se agregará al objeto Document raíz.
El estado cambiará a "before head". Luego, se recibe el token de "cuerpo". Se creará un HTMLHeadElement de forma implícita, aunque no tengamos un token "head", y se agregará al árbol.
Ahora, pasamos al modo "en la cabeza" y, luego, al modo "después de la cabeza". Se vuelve a procesar el token del cuerpo, se crea y se inserta un HTMLBodyElement, y el modo se transfiere a "in body".
Ahora se reciben los tokens de caracteres de la cadena "Hello world". El primero provocará la creación y inserción de un nodo "Text", y los otros caracteres se agregarán a ese nodo.
La recepción del token de fin del cuerpo provocará una transferencia al modo "después del cuerpo". Ahora recibiremos la etiqueta de fin de HTML, que nos llevará al modo "after after body". Recibir el token de fin de archivo finalizará el análisis.
Acciones cuando finaliza el análisis
En esta etapa, el navegador marcará el documento como interactivo y comenzará a analizar las secuencias de comandos que están en modo "diferido": aquellas que se deben ejecutar después de analizar el documento. Luego, el estado del documento se establecerá en "completo" y se activará un evento "cargar".
Puedes ver los algoritmos completos de tokenización y construcción de árboles en la especificación de HTML5.
Tolerancia a errores de los navegadores
Nunca se muestra un error de "Sintaxis no válida" en una página HTML. Los navegadores corrigen el contenido no válido y siguen adelante.
Tomemos este código HTML como ejemplo:
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
Debí haber incumplido alrededor de un millón de reglas ("mytag" no es una etiqueta estándar, anidación incorrecta de los elementos "p" y "div", entre otros), pero el navegador aún la muestra correctamente y no se queja. Por lo tanto, gran parte del código del analizador corrige los errores del autor de HTML.
El manejo de errores es bastante coherente en los navegadores, pero, sorprendentemente, no ha sido parte de las especificaciones de HTML. Al igual que los favoritos y los botones Atrás/Adelante, es algo que se desarrolló en los navegadores a lo largo de los años. Existen construcciones HTML no válidas que se repiten en muchos sitios, y los navegadores intentan corregirlas de una manera compatible con otros navegadores.
La especificación HTML5 define algunos de estos requisitos. (WebKit lo resume muy bien en el comentario al comienzo de la clase del analizador de HTML).
El analizador analiza la entrada tokenizada en el documento y crea el árbol de documentos. Si el documento tiene el formato correcto, el análisis es sencillo.
Lamentablemente, debemos controlar muchos documentos HTML que no tienen el formato correcto, por lo que el analizador debe ser tolerante con los errores.
Debemos tener en cuenta al menos las siguientes condiciones de error:
- El elemento que se agrega está prohibido de forma explícita dentro de alguna etiqueta externa. En este caso, debemos cerrar todas las etiquetas hasta la que prohíbe el elemento y, luego, agregarlo.
- No podemos agregar el elemento directamente. Es posible que la persona que escribió el documento se haya olvidado de alguna etiqueta intermedia (o que la etiqueta intermedia sea opcional). Este podría ser el caso de las siguientes etiquetas: HTML HEAD BODY TBODY TR TD LI (¿me olvidé de alguna?).
- Queremos agregar un elemento de bloque dentro de un elemento intercalado. Cierra todos los elementos intercalados hasta el siguiente elemento de bloque superior.
- Si esto no funciona, cierra los elementos hasta que podamos agregarlos o ignora la etiqueta.
Veamos algunos ejemplos de tolerancia a errores de WebKit:
</br> en lugar de <br>
Algunos sitios usan </br> en lugar de <br>. Para ser compatible con IE y Firefox, WebKit lo trata como <br>.
El código:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
Ten en cuenta que el control de errores es interno: no se presentará al usuario.
Una tabla perdida
Una tabla errante es una tabla dentro de otra, pero no dentro de una celda de tabla.
Por ejemplo:
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
WebKit cambiará la jerarquía a dos tablas hermanas:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
El código:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
WebKit usa una pila para el contenido del elemento actual: sacará la tabla interna de la pila de tablas externa. Las tablas ahora serán del mismo nivel.
Elementos de formulario anidados
En caso de que el usuario coloque un formulario dentro de otro, se ignorará el segundo.
El código:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
Una jerarquía de etiquetas demasiado profunda
El comentario habla por sí solo.
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
Etiquetas de cierre de cuerpo o HTML fuera de lugar
Una vez más, el comentario habla por sí mismo.
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
Por lo tanto, ten cuidado, autores web: a menos que quieras aparecer como ejemplo en un fragmento de código de tolerancia a errores de WebKit, escribe HTML bien formado.
Análisis de CSS
¿Recuerdas los conceptos de análisis en la introducción? Bueno, a diferencia del HTML, CSS es una gramática sin contexto y se puede analizar con los tipos de analizadores que se describen en la introducción. De hecho, la especificación de CSS define la gramática léxica y sintáctica de CSS.
Veamos algunos ejemplos:
La gramática léxica (vocabulario) se define con expresiones regulares para cada token:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
"ident" es la forma abreviada de identificador, como un nombre de clase. "name" es un ID de elemento (al que se hace referencia con "#").
La gramática de sintaxis se describe en BNF.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
Explicación:
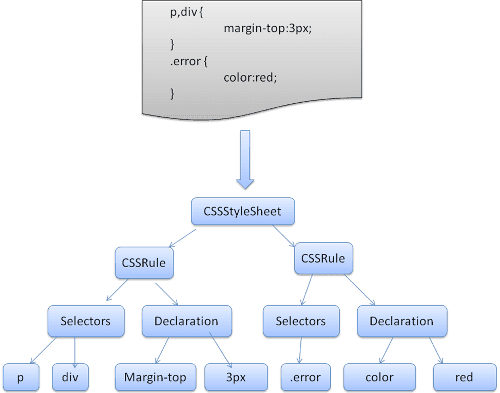
Un conjunto de reglas tiene esta estructura:
div.error, a.error {
color:red;
font-weight:bold;
}
div.error y a.error son selectores. La parte dentro de las llaves contiene las reglas que aplica este conjunto de reglas.
Esta estructura se define formalmente en esta definición:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
Esto significa que un conjunto de reglas es un selector o, de manera opcional, una serie de selectores separados por comas y espacios (S significa espacio en blanco). Un conjunto de reglas contiene llaves y, dentro de ellas, una declaración o, de forma opcional, varias declaraciones separadas por un punto y coma. "declaración" y "selector" se definirán en las siguientes definiciones de BNF.
Analizador de CSS de WebKit
WebKit usa generadores de analizadores Flex y Bison para crear analizadores automáticamente a partir de los archivos de gramática CSS. Como recordarás de la introducción al analizador, Bison crea un analizador de desplazamiento y reducción ascendente. Firefox usa un analizador de arriba abajo escrito de forma manual. En ambos casos, cada archivo CSS se analiza en un objeto StyleSheet. Cada objeto contiene reglas CSS. Los objetos de reglas CSS contienen objetos de selector y declaración, y otros objetos correspondientes a la gramática CSS.
Orden de procesamiento de secuencias de comandos y hojas de estilo
Secuencias de comandos
El modelo de la Web es síncrono. Los autores esperan que las secuencias de comandos se analicen y ejecuten de inmediato cuando el analizador llega a una etiqueta <script>.
El análisis del documento se detiene hasta que se ejecuta la secuencia de comandos.
Si la secuencia de comandos es externa, primero se debe recuperar el recurso de la red. Esto también se hace de forma síncrona, y el análisis se detiene hasta que se recupera el recurso.
Este fue el modelo durante muchos años y también se especifica en las especificaciones HTML4 y 5.
Los autores pueden agregar el atributo "aplaza" a una secuencia de comandos, en cuyo caso no detendrá el análisis del documento y se ejecutará después de que se analice. HTML5 agrega una opción para marcar la secuencia de comandos como asíncrona, de modo que un subproceso diferente la analice y ejecute.
Análisis especulativo
Tanto WebKit como Firefox realizan esta optimización. Mientras se ejecutan las secuencias de comandos, otro subproceso analiza el resto del documento y descubre qué otros recursos se deben cargar desde la red y los carga. De esta manera, los recursos se pueden cargar en conexiones en paralelo y se mejora la velocidad general. Nota: El analizador especulativo solo analiza referencias a recursos externos, como imágenes, hojas de estilo y secuencias de comandos externas. No modifica el árbol DOM, lo que se deja al analizador principal.
Hojas de estilo
Las hojas de estilo, por otro lado, tienen un modelo diferente. Conceptualmente, parece que, dado que las hojas de estilo no cambian el árbol DOM, no hay razón para esperarlas y detener el análisis del documento. Sin embargo, hay un problema con las secuencias de comandos que solicitan información de estilo durante la etapa de análisis de documentos. Si el estilo aún no se carga ni analiza, la secuencia de comandos obtendrá respuestas incorrectas y, al parecer, esto causó muchos problemas. Parece un caso extremo, pero es bastante común. Firefox bloquea todas las secuencias de comandos cuando hay una hoja de estilo que aún se está cargando y analizando. WebKit bloquea las secuencias de comandos solo cuando intentan acceder a ciertas propiedades de estilo que pueden verse afectadas por hojas de estilo no cargadas.
Renderización de la construcción de árboles
Mientras se construye el árbol del DOM, el navegador construye otro árbol, el árbol de renderización. Este árbol es de elementos visuales en el orden en que se mostrarán. Es la representación visual del documento. El propósito de este árbol es permitir pintar el contenido en el orden correcto.
Firefox llama a los elementos del árbol de renderización "marcos". WebKit usa el término renderizador o objeto de renderización.
Un renderizador sabe cómo diseñarse y pintarse a sí mismo y a sus elementos secundarios.
La clase RenderObject de WebKit, la clase base de los renderizadores, tiene la siguiente definición:
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
Cada renderizador representa un área rectangular que, por lo general, corresponde al cuadro CSS de un nodo, como se describe en la especificación CSS2. Incluye información geométrica, como el ancho, la altura y la posición.
El tipo de cuadro se ve afectado por el valor "display" del atributo de estilo que es relevante para el nodo (consulta la sección Cálculo de estilo). Este es el código de WebKit para decidir qué tipo de renderizador se debe crear para un nodo DOM, según el atributo de visualización:
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
También se considera el tipo de elemento: por ejemplo, los controles de formulario y las tablas tienen marcos especiales.
En WebKit, si un elemento quiere crear un renderizador especial, anulará el método createRenderer().
Los renderizadores apuntan a objetos de diseño que contienen información no geométrica.
La relación del árbol de renderización con el árbol del DOM
Los renderizadores corresponden a elementos DOM, pero la relación no es uno a uno. Los elementos DOM no visuales no se insertarán en el árbol de renderización. Un ejemplo es el elemento "head". Además, los elementos cuyo valor de visualización se asignó a "none" no aparecerán en el árbol (mientras que los elementos con visibilidad "hidden" sí aparecerán en el árbol).
Hay elementos DOM que corresponden a varios objetos visuales. Por lo general, son elementos con una estructura compleja que no se puede describir con un solo rectángulo. Por ejemplo, el elemento "select" tiene tres renderizadores: uno para el área de visualización, uno para el cuadro de lista desplegable y uno para el botón. Además, cuando el texto se divide en varias líneas porque el ancho no es suficiente para una, las líneas nuevas se agregarán como renderizadores adicionales.
Otro ejemplo de varios renderizadores es el HTML dañado. Según la especificación de CSS, un elemento intercalado debe contener solo elementos de bloque o solo elementos intercalados. En el caso del contenido mixto, se crearán renderizadores de bloques anónimos para unir los elementos intercalados.
Algunos objetos de renderización corresponden a un nodo DOM, pero no en el mismo lugar del árbol. Los elementos flotantes y de posicionamiento absoluto están fuera de flujo, se colocan en una parte diferente del árbol y se asignan al marco real. Un marco de marcador de posición es donde deberían estar.
El flujo de construcción del árbol
En Firefox, la presentación se registra como un objeto de escucha para las actualizaciones del DOM.
La presentación delega la creación de marcos a FrameConstructor y el constructor resuelve el estilo (consulta Cálculo de diseño) y crea un marco.
En WebKit, el proceso de resolver el estilo y crear un renderizador se denomina "adjunto". Cada nodo del DOM tiene un método "attach". El adjunto es síncrono, la inserción de nodos en el árbol del DOM llama al método "attach" del nodo nuevo.
El procesamiento de las etiquetas html y body genera la raíz del árbol de renderización.
El objeto de renderización raíz corresponde a lo que la especificación CSS denomina bloque contenedor: el bloque superior que contiene todos los demás bloques. Sus dimensiones son el viewport: las dimensiones del área de visualización de la ventana del navegador.
Firefox lo llama ViewPortFrame y WebKit lo llama RenderView.
Este es el objeto de renderización al que apunta el documento.
El resto del árbol se construye como una inserción de nodos DOM.
Consulta la especificación CSS2 sobre el modelo de procesamiento.
Cálculo de estilo
La compilación del árbol de renderización requiere calcular las propiedades visuales de cada objeto de renderización. Para ello, se calculan las propiedades de estilo de cada elemento.
El estilo incluye hojas de estilo de varios orígenes, elementos de estilo intercalados y propiedades visuales en el HTML (como la propiedad "bgcolor").Este último se traduce a propiedades de estilo CSS coincidentes.
Los orígenes de las hojas de estilo son las hojas de estilo predeterminadas del navegador, las hojas de estilo que proporciona el autor de la página y las hojas de estilo del usuario, que son las hojas de estilo que proporciona el usuario del navegador (los navegadores te permiten definir tus estilos favoritos). En Firefox, por ejemplo, esto se hace colocando una hoja de estilo en la carpeta “Perfil de Firefox”.
El procesamiento de estilos presenta algunas dificultades:
- Los datos de estilo son una construcción muy grande que contiene las numerosas propiedades de estilo, lo que puede causar problemas de memoria.
Encontrar las reglas de coincidencia para cada elemento puede causar problemas de rendimiento si no están optimizadas. Explorar toda la lista de reglas para cada elemento y encontrar coincidencias es una tarea pesada. Los selectores pueden tener una estructura compleja que puede hacer que el proceso de coincidencia comience en una ruta aparentemente prometedora que se demuestra que es inútil y se debe probar otra ruta.
Por ejemplo, este selector compuesto:
div div div div{ ... }Significa que las reglas se aplican a un
<div>que es descendiente de 3 divs. Supongamos que quieres verificar si la regla se aplica a un elemento<div>determinado. Eliges una ruta determinada en el árbol para verificarla. Es posible que debas recorrer el árbol de nodos hacia arriba solo para descubrir que solo hay dos divs y que la regla no se aplica. Luego, debes probar otras rutas en el árbol.La aplicación de las reglas implica reglas en cascada bastante complejas que definen la jerarquía de las reglas.
Veamos cómo los navegadores enfrentan estos problemas:
Cómo compartir datos de estilo
Los nodos WebKit hacen referencia a objetos de estilo (RenderStyle). En algunas condiciones, los nodos pueden compartir estos objetos. Los nodos son hermanos o primos y tienen las siguientes características:
- Los elementos deben estar en el mismo estado del mouse (p. ej., uno no puede estar en :hover mientras que el otro no).
- Ningún elemento debe tener un ID.
- Los nombres de las etiquetas deben coincidir
- Los atributos de clase deben coincidir
- El conjunto de atributos asignados debe ser idéntico
- Los estados de los vínculos deben coincidir
- Los estados de enfoque deben coincidir
- Ningún elemento debe verse afectado por los selectores de atributos, donde se define como afectado tener cualquier coincidencia de selector que use un selector de atributos en cualquier posición dentro del selector.
- No debe haber ningún atributo de estilo intercalado en los elementos.
- No debe haber selectores hermanos en uso. WebCore simplemente arroja un interruptor global cuando se encuentra cualquier selector de hermanos y, cuando están presentes, inhabilita el uso compartido de estilos para todo el documento. Esto incluye el selector + y selectores como :first-child y :last-child.
Árbol de reglas de Firefox
Firefox tiene dos árboles adicionales para facilitar el procesamiento de estilos: el árbol de reglas y el árbol de contexto de estilo. WebKit también tiene objetos de diseño, pero no se almacenan en un árbol como el árbol de contexto de diseño, solo el nodo DOM apunta a su diseño relevante.
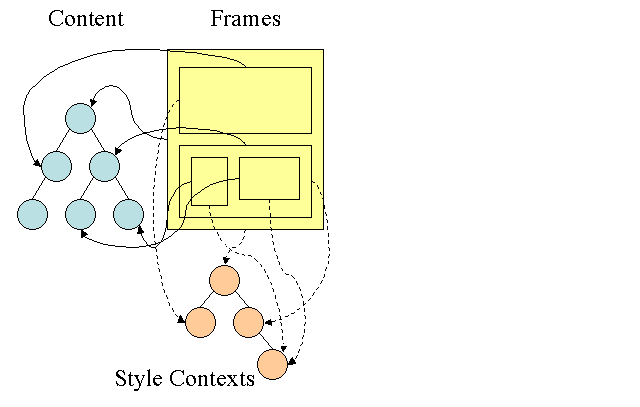
Los contextos de diseño contienen valores finales. Para calcular los valores, se aplican todas las reglas de coincidencia en el orden correcto y se realizan manipulaciones que los transforman de valores lógicos a valores concretos. Por ejemplo, si el valor lógico es un porcentaje de la pantalla, se calculará y se transformará en unidades absolutas. La idea del árbol de reglas es muy inteligente. Permite compartir estos valores entre nodos para evitar volver a calcularlos. Esto también ahorra espacio.
Todas las reglas que coinciden se almacenan en un árbol. Los nodos inferiores de una ruta tienen una prioridad más alta. El árbol contiene todas las rutas de acceso de las coincidencias de reglas que se encontraron. El almacenamiento de las reglas se realiza de forma diferida. El árbol no se calcula al principio para cada nodo, pero cada vez que se debe calcular un estilo de nodo, las rutas calculadas se agregan al árbol.
La idea es ver las rutas del árbol como palabras en un léxico. Supongamos que ya calculamos este árbol de reglas:
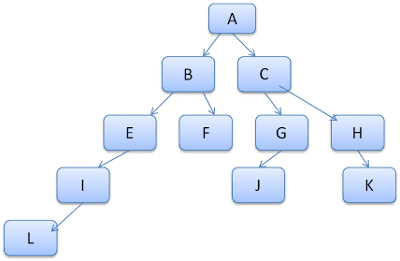
Supongamos que necesitamos hacer coincidir reglas para otro elemento en el árbol de contenido y descubrir que las reglas coincidentes (en el orden correcto) son B-E-I. Ya tenemos esta ruta en el árbol porque ya calculamos la ruta A-B-E-I-L. Ahora tendremos menos trabajo.
Veamos cómo el árbol nos ahorra trabajo.
División en estructuras
Los contextos de diseño se dividen en estructuras. Esas estructuras contienen información de estilo para una categoría determinada, como el borde o el color. Todas las propiedades de una struct se heredan o no. Las propiedades heredadas son aquellas que, a menos que el elemento las defina, se heredan de su elemento superior. Las propiedades no heredadas (llamadas propiedades "restablecidas") usan valores predeterminados si no se definen.
El árbol nos ayuda a almacenar en caché estructuras completas (que contienen los valores finales calculados) en el árbol. La idea es que, si el nodo inferior no proporcionó una definición para una estructura, se puede usar una estructura almacenada en caché en un nodo superior.
Cálculo de los contextos de diseño con el árbol de reglas
Cuando se calcula el contexto de diseño de un elemento determinado, primero se calcula una ruta de acceso en el árbol de reglas o se usa una existente. Luego, comenzamos a aplicar las reglas de la ruta para completar las estructuras en nuestro nuevo contexto de estilo. Comenzamos en el nodo inferior de la ruta, el que tiene la prioridad más alta (por lo general, el selector más específico) y recorremos el árbol hasta que nuestra estructura esté completa. Si no hay una especificación para la estructura en ese nodo de regla, podemos realizar una gran optimización: subimos por el árbol hasta encontrar un nodo que la especifique por completo y lo apuntamos. Esa es la mejor optimización: se comparte toda la estructura. Esto ahorra el procesamiento de los valores finales y la memoria.
Si encontramos definiciones parciales, subimos por el árbol hasta que se complete la estructura.
Si no encontramos ninguna definición para nuestra estructura, en caso de que la estructura sea un tipo “heredado”, apuntamos a la estructura de nuestro elemento superior en el árbol de contexto. En este caso, también pudimos compartir estructuras. Si es una estructura de restablecimiento, se usarán los valores predeterminados.
Si el nodo más específico agrega valores, debemos realizar algunos cálculos adicionales para transformarlos en valores reales. Luego, almacenamos en caché el resultado en el nodo del árbol para que los subnodos puedan usarlo.
En caso de que un elemento tenga un hermano que apunte al mismo nodo del árbol, se puede compartir el contexto de estilo completo entre ellos.
Veamos un ejemplo: Supongamos que tenemos este código HTML:
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
Y las siguientes reglas:
div {margin: 5px; color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
Para simplificar, supongamos que solo necesitamos completar dos estructuras: la estructura de color y la estructura de margen. La estructura de color contiene solo un miembro: el color. La estructura de margen contiene los cuatro lados.
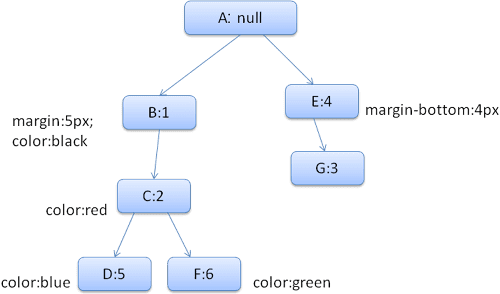
El árbol de reglas resultante se verá de la siguiente manera (los nodos están marcados con el nombre del nodo: el número de la regla a la que apuntan):
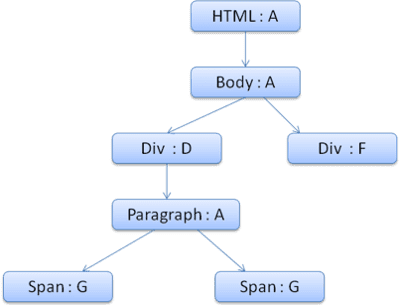
El árbol de contexto se verá de la siguiente manera (nombre del nodo: nodo de regla al que apuntan):
Supongamos que analizamos el código HTML y llegamos a la segunda etiqueta <div>. Necesitamos crear un contexto de diseño para este nodo y completar sus estructuras de diseño.
Haremos coincidir las reglas y descubriremos que las reglas de coincidencia para <div> son 1, 2 y 6.
Esto significa que ya existe una ruta de acceso en el árbol que nuestro elemento puede usar y solo debemos agregarle otro nodo para la regla 6 (nodo F en el árbol de reglas).
Crearemos un contexto de diseño y lo colocaremos en el árbol de contexto. El nuevo contexto de estilo apuntará al nodo F en el árbol de reglas.
Ahora debemos completar las estructuras de estilo. Comenzaremos por completar la estructura de margen. Como el último nodo de regla (F) no se agrega a la estructura de margen, podemos subir por el árbol hasta encontrar una estructura almacenada en caché calculada en una inserción de nodo anterior y usarla. La encontraremos en el nodo B, que es el nodo más alto que especificó las reglas de margen.
Tenemos una definición para la estructura de color, por lo que no podemos usar una estructura almacenada en caché. Como el color tiene un atributo, no es necesario subir en el árbol para completar otros atributos. Calcularemos el valor final (convertiremos la cadena a RGB, etc.) y almacenaremos en caché la estructura calculada en este nodo.
El trabajo en el segundo elemento <span> es aún más fácil. Haremos coincidir las reglas y llegaremos a la conclusión de que apunta a la regla G, como el intervalo anterior.
Dado que tenemos elementos hermanos que apuntan al mismo nodo, podemos compartir todo el contexto de diseño y solo apuntar al contexto del intervalo anterior.
En el caso de las estructuras que contienen reglas que se heredan del elemento superior, el almacenamiento en caché se realiza en el árbol de contexto (la propiedad de color se hereda, pero Firefox la trata como un restablecimiento y la almacena en caché en el árbol de reglas).
Por ejemplo, si agregamos reglas para las fuentes en un párrafo, ocurrirá lo siguiente:
p {font-family: Verdana; font size: 10px; font-weight: bold}
Luego, el elemento de párrafo, que es un elemento secundario del div en el árbol de contexto, podría haber compartido la misma estructura de fuente que su elemento superior. Esto sucede si no se especificaron reglas de fuente para el párrafo.
En WebKit, que no tiene un árbol de reglas, las declaraciones coincidentes se recorren cuatro veces. Primero, se aplican las propiedades de alta prioridad no importantes (propiedades que deben aplicarse primero porque otras dependen de ellas, como la visualización), luego las importantes de alta prioridad, las no importantes de prioridad normal y, por último, las importantes de prioridad normal. Esto significa que las propiedades que aparezcan varias veces se resolverán según el orden en cascada correcto. El último gana.
En resumen, compartir los objetos de estilo (por completo o algunas de las estructuras que contienen) resuelve los problemas 1 y 3. El árbol de reglas de Firefox también ayuda a aplicar las propiedades en el orden correcto.
Cómo manipular las reglas para lograr una coincidencia fácil
Existen varias fuentes de reglas de estilo:
- Reglas de CSS, ya sea en hojas de estilo externas o en elementos de estilo.
css p {color: blue} - Atributos de estilo intercalado, como
html <p style="color: blue" /> - Atributos visuales HTML (que se asignan a reglas de diseño relevantes)
html <p bgcolor="blue" />Los dos últimos coinciden fácilmente con el elemento, ya que es propietario de los atributos de diseño y los atributos HTML se pueden asignar con el elemento como clave.
Como se señaló anteriormente en el problema 2, la coincidencia de reglas de CSS puede ser más complicada. Para resolver la dificultad, se manipulan las reglas para facilitar el acceso.
Después de analizar la hoja de estilo, las reglas se agregan a uno de varios mapas hash, según el selector. Hay mapas por ID, por nombre de clase, por nombre de etiqueta y un mapa general para todo lo que no se ajusta a esas categorías. Si el selector es un ID, la regla se agregará al mapa de ID; si es una clase, se agregará al mapa de clase, etcétera.
Esta manipulación facilita mucho la coincidencia de reglas. No es necesario buscar en cada declaración: podemos extraer las reglas relevantes para un elemento de los mapas. Esta optimización elimina más del 95% de las reglas, por lo que ni siquiera es necesario considerarlas durante el proceso de coincidencia(4.1).
Veamos, por ejemplo, las siguientes reglas de estilo:
p.error {color: red}
#messageDiv {height: 50px}
div {margin: 5px}
La primera regla se insertará en el mapa de clases. El segundo en el mapa de ID y el tercero en el mapa de etiquetas.
Para el siguiente fragmento HTML:
<p class="error">an error occurred</p>
<div id=" messageDiv">this is a message</div>
Primero, intentaremos encontrar reglas para el elemento p. El mapa de clases contendrá una clave "error" en la que se encuentra la regla para "p.error". El elemento div tendrá reglas relevantes en el mapa de ID (la clave es el ID) y en el mapa de etiquetas. Por lo tanto, lo único que queda por hacer es averiguar cuáles de las reglas que extrajeron las claves realmente coinciden.
Por ejemplo, si la regla para el div fuera la siguiente:
table div {margin: 5px}
Se seguirá extrayendo del mapa de etiquetas, ya que la clave es el selector más a la derecha, pero no coincidiría con nuestro elemento div, que no tiene un ancestro de tabla.
Tanto WebKit como Firefox realizan esta manipulación.
Orden en cascada de las hojas de estilo
El objeto de estilo tiene propiedades correspondientes a cada atributo visual (todos los atributos de CSS, pero más genéricos). Si ninguna de las reglas coincidentes define la propiedad, el objeto de estilo del elemento superior puede heredar algunas propiedades. Otras propiedades tienen valores predeterminados.
El problema comienza cuando hay más de una definición. Aquí entra en juego el orden en cascada para resolver el problema.
Una declaración para una propiedad de diseño puede aparecer en varias hojas de estilo y varias veces dentro de una hoja de estilo. Esto significa que el orden en que se aplican las reglas es muy importante. Esto se denomina orden "en cascada". Según la especificación CSS2, el orden en cascada es el siguiente (de menor a mayor):
- Declaraciones del navegador
- Declaraciones normales del usuario
- Declaraciones normales del autor
- Declaraciones importantes del autor
- Declaraciones importantes para el usuario
Las declaraciones del navegador son menos importantes y el usuario anula al autor solo si la declaración se marcó como importante. Las declaraciones con el mismo orden se ordenarán por especificidad y, luego, por el orden en que se especifican. Los atributos visuales HTML se traducen a declaraciones CSS coincidentes . Se tratan como reglas de autor con prioridad baja.
Especificidad
La especificidad del selector se define en la especificación CSS2 de la siguiente manera:
- Cuenta 1 si la declaración de la que proviene es un atributo "style" en lugar de una regla con un selector, 0 de lo contrario (= a)
- contar la cantidad de atributos de ID en el selector (= b)
- cuenta la cantidad de otros atributos y pseudoclases en el selector (= c)
- cuenta la cantidad de nombres de elementos y pseudoelementos en el selector (= d)
La concatenación de los cuatro números a-b-c-d (en un sistema numérico con una base grande) proporciona la especificidad.
La base numérica que debes usar se define según el recuento más alto que tengas en una de las categorías.
Por ejemplo, si a=14, puedes usar la base hexadecimal. En el caso improbable de que a=17, necesitarás una base numérica de 17 dígitos. La última situación puede ocurrir con un selector como este: html body div div p… (17 etiquetas en tu selector… no es muy probable).
Estos son algunos ejemplos:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
Ordena las reglas
Después de que se encuentren coincidencias con las reglas, se ordenan según las reglas en cascada.
WebKit usa el ordenamiento por burbuja para listas pequeñas y el ordenamiento intercalado para las grandes.
WebKit implementa la ordenación anulando el operador > para las reglas:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
Proceso gradual
WebKit usa una marca que indica si se cargaron todas las hojas de estilo de nivel superior (incluidos los @imports). Si el estilo no se carga por completo cuando se adjunta, se usan marcadores de posición y se marca en el documento, y se volverán a calcular una vez que se carguen las hojas de estilo.
Diseño
Cuando se crea el renderizador y se agrega al árbol, no tiene una posición ni un tamaño. El cálculo de estos valores se denomina diseño o reabastecimiento.
HTML usa un modelo de diseño basado en flujos, lo que significa que, la mayoría de las veces, es posible calcular la geometría en un solo pase. Por lo general, los elementos que se encuentran más adelante “en el flujo” no afectan la geometría de los elementos que se encuentran más atrás “en el flujo”, por lo que el diseño puede avanzar de izquierda a derecha y de arriba abajo a través del documento. Hay excepciones: por ejemplo, las tablas HTML pueden requerir más de un pase.
El sistema de coordenadas es relativo al marco raíz. Se usan las coordenadas superior e izquierda.
El diseño es un proceso recursivo. Comienza en el renderizador raíz, que corresponde al elemento <html> del documento HTML. El diseño continúa de forma recursiva a través de parte o toda la jerarquía de marcos, y calcula la información geométrica para cada renderizador que la requiera.
La posición del renderizador raíz es 0,0 y sus dimensiones son el viewport, la parte visible de la ventana del navegador.
Todos los renderizadores tienen un método "layout" o "reflow", y cada uno invoca el método de diseño de sus elementos secundarios que lo necesitan.
Sistema de bits sucios
Para no hacer un diseño completo para cada cambio pequeño, los navegadores usan un sistema de "bits sucios". Un renderizador que se cambia o se agrega se marca a sí mismo y a sus elementos secundarios como "no sincronizados": necesitan diseño.
Hay dos marcas: "dirty" y "children are dirty", lo que significa que, aunque el renderizador en sí puede estar bien, tiene al menos un elemento secundario que necesita un diseño.
Diseño global e incremental
El diseño se puede activar en todo el árbol de renderización, que es el diseño "global". Esto puede suceder por los siguientes motivos:
- Es un cambio de estilo global que afecta a todos los renderizadores, como un cambio de tamaño de fuente.
- Como resultado de cambiar el tamaño de una pantalla
El diseño puede ser incremental, solo se diseñarán los renderizadores sucios (esto puede causar algunos daños que requerirán diseños adicionales).
El diseño incremental se activa (de forma asíncrona) cuando los renderizadores están sucios. Por ejemplo, cuando se agregan nuevos renderizadores al árbol de renderización después de que el contenido adicional proviene de la red y se agrega al árbol de DOM.
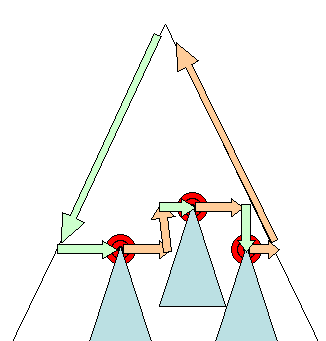
Diseño síncrono y asíncrono
El diseño incremental se realiza de forma asíncrona. Firefox pone en cola "comandos de reflujo" para diseños incrementales, y un programador activa la ejecución por lotes de estos comandos. WebKit también tiene un temporizador que ejecuta un diseño incremental: se recorre el árbol y se diseñan los renderizadores "no sincronizados".
Las secuencias de comandos que solicitan información de estilo, como "offsetHeight", pueden activar el diseño incremental de forma síncrona.
Por lo general, el diseño global se activará de forma síncrona.
A veces, el diseño se activa como una devolución de llamada después de un diseño inicial porque cambiaron algunos atributos, como la posición de desplazamiento.
Optimizaciones
Cuando un diseño se activa con un "redimensionamiento" o un cambio en la posición del renderizador(y no en el tamaño), los tamaños de renderización se toman de una caché y no se vuelven a calcular.
En algunos casos, solo se modifica un subárbol y el diseño no comienza desde la raíz. Esto puede suceder en los casos en que el cambio es local y no afecta a su entorno, como el texto insertado en campos de texto (de lo contrario, cada vez que se presiona una tecla, se activa un diseño que comienza desde la raíz).
El proceso de diseño
Por lo general, el diseño tiene el siguiente patrón:
- El renderizador superior determina su propio ancho.
- El elemento superior revisa los elementos secundarios y hace lo siguiente:
- Coloca el renderizador secundario (establece su X e Y).
- Llama al diseño secundario si es necesario (si está sucio, si estamos en un diseño global o por algún otro motivo), lo que calcula la altura del secundario.
- El elemento superior usa las alturas acumulativas de los elementos secundarios y las alturas de los márgenes y el padding para establecer su propia altura, que usará el elemento superior del renderizador superior.
- Establece su bit de estado modificado en falso.
Firefox usa un objeto "state" (nsHTMLReflowState) como parámetro para el diseño (denominado "reflow"). Entre otros, el estado incluye el ancho de los elementos superiores.
El resultado del diseño de Firefox es un objeto "metrics" (nsHTMLReflowMetrics). Contendrá la altura calculada del renderizador.
Cálculo del ancho
El ancho del renderizador se calcula con el ancho del bloque del contenedor, la propiedad "width" del estilo del renderizador, los márgenes y los bordes.
Por ejemplo, el ancho del siguiente div:
<div style="width: 30%"/>
WebKit lo calcularía de la siguiente manera(método calcWidth de la clase RenderBox):
- El ancho del contenedor es el máximo de los contenedores availableWidth y 0. En este caso, availableWidth es el contentWidth, que se calcula de la siguiente manera:
clientWidth() - paddingLeft() - paddingRight()
clientWidth y clientHeight representan el interior de un objeto, excluyendo el borde y la barra de desplazamiento.
El ancho de los elementos es el atributo de estilo "width". Se calculará como un valor absoluto mediante el cálculo del porcentaje del ancho del contenedor.
Ahora se agregaron los bordes y rellenos horizontales.
Hasta ahora, este fue el cálculo del "ancho preferido". Ahora se calcularán los anchos mínimo y máximo.
Si el ancho preferido es mayor que el ancho máximo, se usa el ancho máximo. Si es menor que el ancho mínimo (la unidad más pequeña que no se puede romper), se usa el ancho mínimo.
Los valores se almacenan en caché en caso de que se necesite un diseño, pero el ancho no cambia.
Saltos de línea
Cuando un renderizador en medio de un diseño decide que debe interrumpirse, se detiene y propaga al elemento superior del diseño que debe interrumpirse. El elemento superior crea los renderizadores adicionales y llama al diseño en ellos.
Pintura
En la etapa de pintura, se recorre el árbol de renderización y se llama al método "paint()" del renderizador para mostrar contenido en la pantalla. El pintado usa el componente de infraestructura de la IU.
Globales e incrementales
Al igual que el diseño, la pintura también puede ser global (se pinta todo el árbol) o incremental. En la pintura incremental, algunos de los renderizadores cambian de una manera que no afecta a todo el árbol. El renderizador modificado invalida su rectángulo en la pantalla. Esto hace que el SO la vea como una "región no actualizada" y genere un evento de "pintura". El SO lo hace de forma inteligente y combina varias regiones en una. En Chrome, es más complicado porque el renderizador se encuentra en un proceso diferente al proceso principal. Chrome simula el comportamiento del SO hasta cierto punto. La presentación escucha estos eventos y delega el mensaje a la raíz de renderización. Se recorre el árbol hasta llegar al renderizador relevante. Se volverá a pintar (y, por lo general, también sus elementos secundarios).
El orden de pintura
CSS2 define el orden del proceso de pintura. En realidad, este es el orden en el que se apilan los elementos en los contextos de apilamiento. Este orden afecta a la pintura, ya que las pilas se pintan de atrás hacia adelante. El orden de apilamiento de un renderizador de bloques es el siguiente:
- background color
- imagen de fondo
- borde
- niños
- descripción
Lista de visualización de Firefox
Firefox revisa el árbol de renderización y compila una lista de visualización para el rectángulo pintado. Contiene los renderizadores relevantes para el rectangular, en el orden de pintura correcto (fondos de los renderizadores, luego bordes, etcétera).
De esta manera, el árbol se debe recorrer solo una vez para volver a pintarlo en lugar de varias veces: pintar todos los fondos, luego todas las imágenes, luego todos los bordes, etcétera.
Firefox optimiza el proceso porque no agrega elementos que se ocultarán, como los que están completamente debajo de otros elementos opacos.
Almacenamiento de rectángulos de WebKit
Antes de volver a pintar, WebKit guarda el rectángulo anterior como un mapa de bits. Luego, pinta solo la diferencia entre los rectángulos nuevos y los anteriores.
Cambios dinámicos
Los navegadores intentan realizar las acciones mínimas posibles en respuesta a un cambio. Por lo tanto, los cambios en el color de un elemento solo causarán que se vuelva a pintar. Los cambios en la posición del elemento provocarán el diseño y la repintura del elemento, sus elementos secundarios y, posiblemente, sus elementos hermanos. Si agregas un nodo DOM, se volverá a dibujar el nodo y se volverá a aplicar el diseño. Los cambios importantes, como aumentar el tamaño de la fuente del elemento "html", invalidarán las cachés, volverán a diseñar y volverán a pintar todo el árbol.
Los subprocesos del motor de renderización
El motor de renderización es de un solo subproceso. Casi todo, excepto las operaciones de red, ocurre en un solo subproceso. En Firefox y Safari, este es el subproceso principal del navegador. En Chrome, es el subproceso principal del proceso de la pestaña.
Las operaciones de red se pueden realizar en varios subprocesos en paralelo. La cantidad de conexiones paralelas es limitada (por lo general, de 2 a 6 conexiones).
Bucle de eventos
El subproceso principal del navegador es un bucle de eventos. Es un bucle infinito que mantiene el proceso activo. Espera a que ocurran eventos (como eventos de diseño y pintura) y los procesa. Este es el código de Firefox para el bucle de eventos principal:
while (!mExiting)
NS_ProcessNextEvent(thread);
Modelo visual de CSS2
El lienzo
Según la especificación CSS2, el término lienzo describe “el espacio en el que se renderiza la estructura de formato”, es decir, donde el navegador pinta el contenido.
El lienzo es infinito para cada dimensión del espacio, pero los navegadores eligen un ancho inicial según las dimensiones del viewport.
Según www.w3.org/TR/CSS2/zindex.html, el lienzo es transparente si está contenido en otro y se le asigna un color definido por el navegador si no es así.
Modelo de caja de CSS
El modelo de cuadro de CSS describe los cuadros rectangulares que se generan para los elementos del árbol de documentos y se organizan según el modelo de formato visual.
Cada cuadro tiene un área de contenido (p.ej., texto, una imagen, etc.) y áreas de padding, borde y margen opcionales.
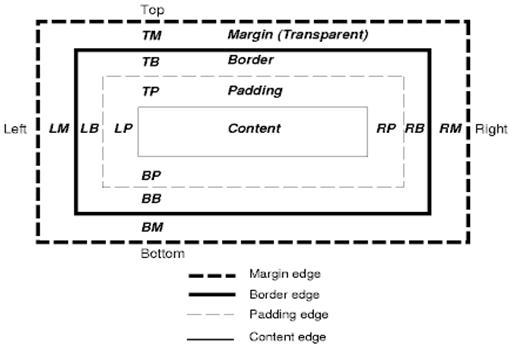
Cada nodo genera entre 0 y n de esos cuadros.
Todos los elementos tienen una propiedad "display" que determina el tipo de cuadro que se generará.
Ejemplos:
block: generates a block box.
inline: generates one or more inline boxes.
none: no box is generated.
El valor predeterminado es intercalado, pero la hoja de estilo del navegador puede establecer otros valores predeterminados. Por ejemplo, la visualización predeterminada del elemento "div" es de bloque.
Puedes encontrar un ejemplo de hoja de estilo predeterminada aquí: www.w3.org/TR/CSS2/sample.html.
Esquema de posicionamiento
Existen tres esquemas:
- Normal: El objeto se posiciona según su lugar en el documento. Esto significa que su lugar en el árbol de renderización es como su lugar en el árbol de DOM y se organiza según su tipo de cuadro y sus dimensiones.
- Flotante: El objeto se coloca primero como un flujo normal y, luego, se mueve lo más a la izquierda o a la derecha posible.
- Absoluto: El objeto se coloca en el árbol de renderización en un lugar diferente al del árbol del DOM.
El esquema de posicionamiento se establece con la propiedad "position" y el atributo "float".
- estáticos y relativos generan un flujo normal
- absolute y fixed causan posicionamiento absoluto
En el posicionamiento estático, no se define ninguna posición y se usa el posicionamiento predeterminado. En los otros esquemas, el autor especifica la posición: arriba, abajo, izquierda y derecha.
La forma en que se organiza el cuadro se determina según lo siguiente:
- Tipo de cuadro
- Dimensiones de la caja
- Esquema de posicionamiento
- Información externa, como el tamaño de la imagen y el de la pantalla
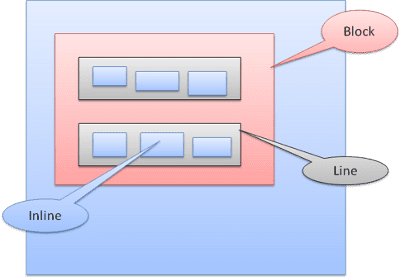
Tipos de cuadros
Cuadro de bloque: forma un bloque y tiene su propio rectángulo en la ventana del navegador.

Cuadro intercalado: No tiene su propio bloque, pero está dentro de un bloque contenedor.
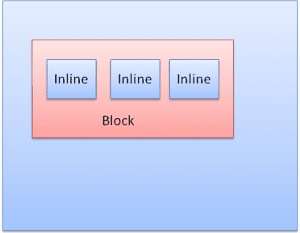
Los bloques se formatean verticalmente uno tras otro. Los elementos intercalados tienen formato horizontal.
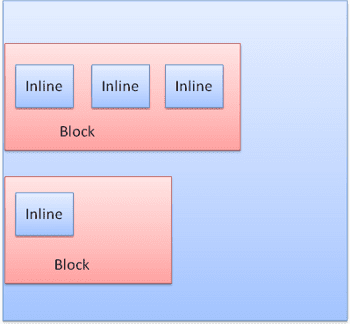
Los cuadros intercalados se colocan dentro de líneas o "cuadros de línea". Las líneas tienen al menos la altura del cuadro más alto, pero pueden ser más altas cuando los cuadros están alineados en la "línea de base", es decir, la parte inferior de un elemento está alineada en un punto de otro cuadro que no es el inferior. Si el ancho del contenedor no es suficiente, los elementos intercalados se colocarán en varias líneas. Por lo general, esto es lo que sucede en un párrafo.
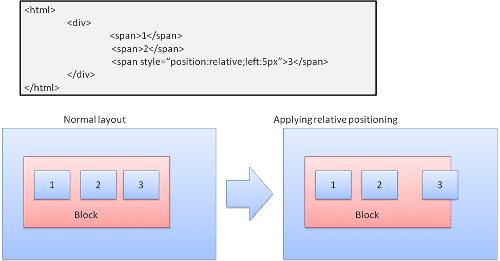
Posicionamiento
Relativo
Posicionamiento relativo: Se posiciona de la forma habitual y, luego, se mueve según la delta requerida.
Anuncio flotante
Un cuadro flotante se desplaza hacia la izquierda o la derecha de una línea. La característica interesante es que los otros cuadros fluyen a su alrededor. El código HTML:
<p>
<img style="float: right" src="images/image.gif" width="100" height="100">
Lorem ipsum dolor sit amet, consectetuer...
</p>
Se verá de la siguiente manera:

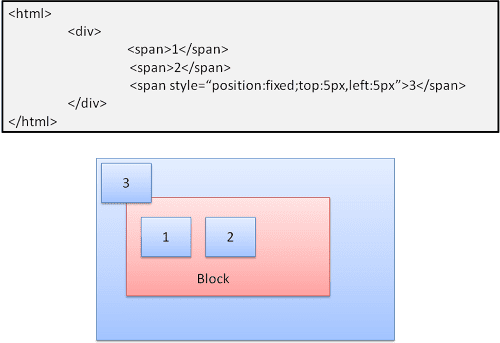
Absoluto y fijo
El diseño se define exactamente independientemente del flujo normal. El elemento no participa en el flujo normal. Las dimensiones son relativas al contenedor. En fixed, el contenedor es el viewport.
Representación en capas
Esto se especifica mediante la propiedad CSS z-index. Representa la tercera dimensión del cuadro: su posición a lo largo del "eje z".
Las cajas se dividen en pilas (llamadas contextos de apilamiento). En cada pila, los elementos de atrás se pintarán primero y los elementos hacia adelante en la parte superior, más cerca del usuario. En caso de superposición, el elemento más destacado ocultará el anterior.
Las pilas se ordenan según la propiedad z-index. Las cajas con la propiedad "z-index" forman una pila local. El viewport tiene la pila externa.
Ejemplo:
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
El resultado será el siguiente:

Aunque el div rojo precede al verde en el marcado y se habría pintado antes en el flujo normal, la propiedad z-index es más alta, por lo que está más adelante en la pila que contiene el cuadro raíz.
Recursos
Arquitectura del navegador
- Grosskurth, Alan. A Reference Architecture for Web Browsers (pdf)
- Gupta, Vineet. Cómo funcionan los navegadores: Parte 1: Arquitectura
Análisis
- Aho, Sethi, Ullman, Compilers: Principles, Techniques, and Tools (también conocido como "Dragon book"), Addison-Wesley, 1986
- Rick Jelliffe. The Bold and the Beautiful: dos nuevos borradores para HTML 5.
Firefox
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers.
- L. David Baron, HTML y CSS más rápidos: Funcionamiento interno del motor de diseño para desarrolladores web (video de charla sobre tecnología de Google)
- L. David Baron, motor de diseño de Mozilla
- L. David Baron, Documentación del sistema de diseño de Mozilla
- Chris Waterson, Notes on HTML Reflow
- Chris Waterson, Descripción general de Gecko
- Alexander Larsson, The life of an HTML HTTP request
WebKit
- David Hyatt, Implementing CSS(part 1)
- David Hyatt, An Overview of WebCore
- David Hyatt, Renderización de WebCore
- David Hyatt, The FOUC Problem
Especificaciones del W3C
Instrucciones de compilación de navegadores
Traducciones
Esta página se tradujo al japonés dos veces:
- How Browsers Work - Behind the Scenes of Modern Web Browsers (ja) de @kosei
- ブラウザってどうやって動いてるの?(モダンWEBブラウザシーンの裏側 de @ikeike443 y @kiyoto01.
Puedes ver las traducciones alojadas de forma externa al idioma coreano y turco.
¡Gracias a todos!