
최신 웹브라우저의 비하인드 스토리


머리말
WebKit 및 Gecko의 내부 작동에 관한 이 포괄적인 입문서는 이스라엘 개발자 탈리 가르시엘이 수행한 많은 연구의 결과입니다. 몇 년 동안 브라우저 내부에 관한 모든 게시된 데이터를 검토하고 웹브라우저 소스 코드를 읽는 데 많은 시간을 보냈습니다. 다음과 같이 작성했습니다.
웹 개발자는 브라우저 작업의 내부 작동을 학습하면 더 나은 결정을 내리고 개발 권장사항의 근거를 파악하는 데 도움이 됩니다. 이 문서는 다소 길지만 시간을 내어 자세히 살펴보시기 바랍니다. 매우 유용합니다.
폴 아이리시, Chrome 개발자 관계팀
소개
웹브라우저는 가장 널리 사용되는 소프트웨어입니다. 이 프라이머에서는 백그라운드에서 작동하는 방식을 설명합니다. 브라우저 화면에 Google 페이지가 표시될 때까지 주소 표시줄에 google.com를 입력하면 어떤 일이 발생하는지 확인합니다.
다룰 브라우저
현재 데스크톱에서 사용되는 주요 브라우저는 Chrome, Internet Explorer, Firefox, Safari, Opera 등 5가지입니다. 모바일의 경우 주요 브라우저는 Android 브라우저, iPhone, Opera Mini, Opera Mobile, UC Browser, Nokia S40/S60 브라우저, Chrome이며, 이 중 Opera 브라우저를 제외한 모든 브라우저는 WebKit을 기반으로 합니다. 오픈소스 브라우저인 Firefox와 Chrome, 부분적으로 오픈소스인 Safari를 예로 들겠습니다. StatCounter 통계 (2013년 6월 기준)에 따르면 Chrome, Firefox, Safari가 전 세계 데스크톱 브라우저 사용의 약 71% 를 차지합니다. 모바일에서는 Android 브라우저, iPhone, Chrome이 사용량의 약 54% 를 차지합니다.
브라우저의 기본 기능
브라우저의 기본 기능은 서버에서 요청하고 브라우저 창에 표시하여 선택한 웹 리소스를 표시하는 것입니다. 리소스는 일반적으로 HTML 문서이지만 PDF, 이미지 또는 기타 유형의 콘텐츠일 수도 있습니다. 리소스의 위치는 사용자가 URI (Uniform Resource Identifier)를 사용하여 지정합니다.
브라우저가 HTML 파일을 해석하고 표시하는 방식은 HTML 및 CSS 사양에 지정되어 있습니다. 이러한 사양은 웹의 표준 조직인 W3C (World Wide Web Consortium)에서 유지관리합니다. 오랫동안 브라우저는 사양의 일부만 준수하고 자체 확장 프로그램을 개발했습니다. 이로 인해 웹 작성자에게 심각한 호환성 문제가 발생했습니다. 오늘날 대부분의 브라우저는 어느 정도 사양을 준수합니다.
브라우저 사용자 인터페이스는 서로 공통점이 많습니다. 일반적인 사용자 인터페이스 요소는 다음과 같습니다.
- URI를 삽입하기 위한 주소 표시줄
- 뒤로 및 앞으로 버튼
- 북마크 옵션
- 현재 문서를 새로고침하거나 로드 중지를 위한 새로고침 및 중지 버튼
- 홈페이지로 연결되는 홈 버튼
이상하게도 브라우저의 사용자 인터페이스는 공식 사양에 지정되어 있지 않으며, 수년간의 경험과 브라우저 간의 상호 모방을 통해 형성된 권장사항에서 비롯됩니다. HTML5 사양은 브라우저에 있어야 하는 UI 요소를 정의하지는 않지만 몇 가지 일반적인 요소를 나열합니다. 주소 표시줄, 상태 표시줄, 툴바 등이 여기에 해당합니다. 물론 Firefox의 다운로드 관리자와 같이 특정 브라우저에만 있는 고유한 기능도 있습니다.
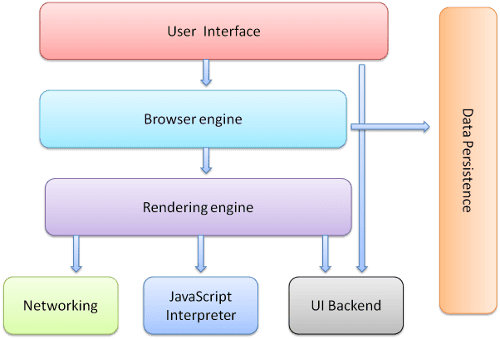
상위 수준 인프라
브라우저의 주요 구성요소는 다음과 같습니다.
- 사용자 인터페이스: 주소 표시줄, 뒤로/앞으로 버튼, 북마크 메뉴 등이 여기에 포함됩니다. 요청된 페이지가 표시되는 창을 제외한 브라우저의 모든 부분이 여기에 포함됩니다.
- 브라우저 엔진: UI와 렌더링 엔진 간의 작업을 마샬링합니다.
- 렌더링 엔진: 요청된 콘텐츠를 표시하는 역할을 합니다. 예를 들어 요청된 콘텐츠가 HTML인 경우 렌더링 엔진은 HTML 및 CSS를 파싱하고 파싱된 콘텐츠를 화면에 표시합니다.
- 네트워킹: HTTP 요청과 같은 네트워크 호출의 경우 플랫폼 독립형 인터페이스 뒤에 있는 여러 플랫폼에 서로 다른 구현을 사용합니다.
- UI 백엔드: 콤보 상자 및 창과 같은 기본 위젯을 그리기 위해 사용됩니다. 이 백엔드는 플랫폼에 종속되지 않는 일반 인터페이스를 노출합니다. 그 아래에는 운영체제 사용자 인터페이스 메서드를 사용합니다.
- JavaScript 인터프리터 JavaScript 코드를 파싱하고 실행하는 데 사용됩니다.
- 데이터 스토리지. 이는 지속성 레이어입니다. 브라우저는 쿠키와 같은 모든 종류의 데이터를 로컬에 저장해야 할 수 있습니다. 브라우저는 localStorage, IndexedDB, WebSQL, FileSystem과 같은 저장소 메커니즘도 지원합니다.
Chrome과 같은 브라우저는 렌더링 엔진의 인스턴스를 여러 개 실행합니다(탭마다 하나씩). 각 탭은 별도의 프로세스에서 실행됩니다.
렌더링 엔진
렌더링 엔진의 책임은 렌더링, 즉 요청된 콘텐츠를 브라우저 화면에 표시하는 것입니다.
기본적으로 렌더링 엔진은 HTML 및 XML 문서와 이미지를 표시할 수 있습니다. 플러그인이나 확장 프로그램을 통해 다른 유형의 데이터를 표시할 수 있습니다. 예를 들어 PDF 뷰어 플러그인을 사용하여 PDF 문서를 표시할 수 있습니다. 하지만 이 장에서는 CSS를 사용하여 형식이 지정된 HTML 및 이미지를 표시하는 기본 사용 사례에 중점을 둘 것입니다.
브라우저마다 렌더링 엔진이 다릅니다. Internet Explorer는 Trident을, Firefox는 Gecko를, Safari는 WebKit을 사용합니다. Chrome 및 Opera (버전 15부터)는 WebKit의 포크인 Blink를 사용합니다.
WebKit은 Linux 플랫폼용 엔진으로 시작되었으며 Mac 및 Windows를 지원하도록 Apple에서 수정한 오픈소스 렌더링 엔진입니다.
기본 흐름
렌더링 엔진이 네트워킹 레이어에서 요청된 문서의 콘텐츠를 가져오기 시작합니다. 일반적으로 8KB 청크 단위로 이루어집니다.
그 후 렌더링 엔진의 기본 흐름은 다음과 같습니다.

렌더링 엔진은 HTML 문서 파싱을 시작하고 '콘텐츠 트리'라는 트리의 요소를 DOM 노드로 변환합니다. 엔진은 외부 CSS 파일과 스타일 요소에서 모두 스타일 데이터를 파싱합니다. 스타일 지정 정보는 HTML의 시각적 안내와 함께 다른 트리인 렌더링 트리를 만드는 데 사용됩니다.
렌더링 트리에는 색상 및 크기와 같은 시각적 속성이 있는 직사각형이 포함됩니다. 직사각형이 화면에 표시되기 위한 올바른 순서입니다.
렌더링 트리가 생성된 후 '레이아웃' 프로세스를 거칩니다. 즉, 각 노드에 화면에 표시되어야 하는 정확한 좌표를 제공해야 합니다. 다음 단계는 페인팅입니다. 렌더링 트리가 탐색되고 각 노드가 UI 백엔드 레이어를 사용하여 페인팅됩니다.
이 과정은 점진적으로 진행된다는 점을 이해해야 합니다. 더 나은 사용자 환경을 위해 렌더링 엔진은 최대한 빨리 콘텐츠를 화면에 표시하려고 시도합니다. 렌더링 트리를 빌드하고 레이아웃하기 전에 모든 HTML이 파싱될 때까지 기다리지 않습니다. 콘텐츠의 일부가 파싱되고 표시되는 동안 네트워크에서 계속 들어오는 나머지 콘텐츠로 프로세스가 계속됩니다.
기본 흐름 예시
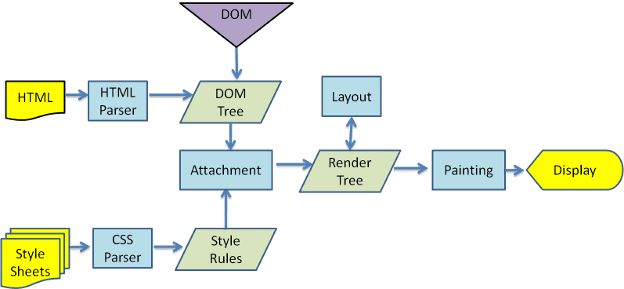
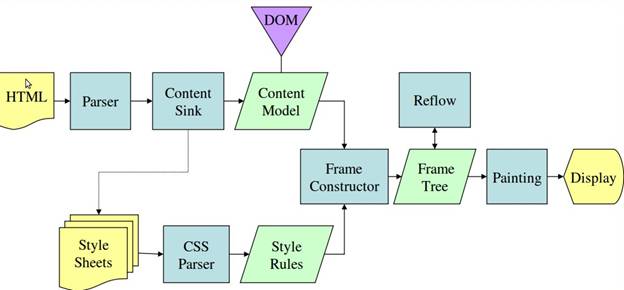
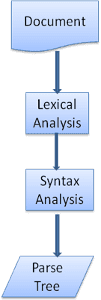
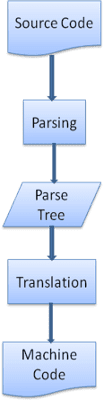
그림 3과 4에서 WebKit과 Gecko는 약간 다른 용어를 사용하지만 흐름은 기본적으로 동일하다는 것을 알 수 있습니다.
Gecko에서는 시각적으로 형식이 지정된 요소의 트리를 '프레임 트리'라고 합니다. 각 요소는 프레임입니다. WebKit에서는 '렌더링 트리'라는 용어를 사용하며, 이는 '렌더링 객체'로 구성됩니다. WebKit은 요소 배치에 '레이아웃'이라는 용어를 사용하는 반면 Gecko는 '리플로'라고 합니다. '첨부파일'은 렌더링 트리를 만들기 위해 DOM 노드와 시각적 정보를 연결하는 WebKit의 용어입니다. 시맨틱이 아닌 사소한 차이점은 Gecko에는 HTML과 DOM 트리 사이에 추가 레이어가 있다는 점입니다. '콘텐츠 싱크'라고 하며 DOM 요소를 만드는 팩토리입니다. 흐름의 각 부분을 살펴보겠습니다.
파싱 - 일반
파싱은 렌더링 엔진 내에서 매우 중요한 프로세스이므로 좀 더 자세히 살펴보겠습니다. 파싱에 관한 간단한 소개로 시작해 보겠습니다.
문서를 파싱한다는 것은 문서를 코드에서 사용할 수 있는 구조로 변환하는 것을 의미합니다. 파싱의 결과는 일반적으로 문서의 구조를 나타내는 노드 트리입니다. 이를 파싱 트리 또는 문법 트리라고 합니다.
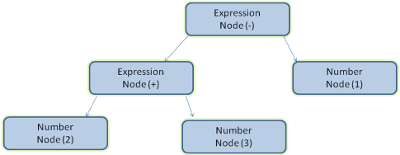
예를 들어 2 + 3 - 1 표현식을 파싱하면 다음과 같은 트리가 반환될 수 있습니다.
문법
파싱은 문서가 따르는 문법 규칙(작성된 언어 또는 형식)을 기반으로 합니다. 파싱할 수 있는 모든 형식에는 어휘 및 문법 규칙으로 구성된 결정론적 문법이 있어야 합니다. 이를 문맥 자유 문법이라고 합니다. 인간 언어는 이러한 언어가 아니므로 기존 파싱 기법으로 파싱할 수 없습니다.
파서 - 렉서 조합
파싱은 두 가지 하위 프로세스인 리터럴 분석과 문법 분석으로 나눌 수 있습니다.
리터럴 분석은 입력을 토큰으로 나누는 프로세스입니다. 토큰은 유효한 구성요소 모음인 언어 어휘입니다. 인간의 언어로 보면 해당 언어의 사전에 표시되는 모든 단어로 구성됩니다.
구문 분석은 언어 구문 규칙을 적용하는 것입니다.
파서는 일반적으로 두 구성요소 간에 작업을 나눕니다. 입력을 유효한 토큰으로 나누는 렉서 (토큰라이저라고도 함)와 언어 문법 규칙에 따라 문서 구조를 분석하여 파싱 트리를 구성하는 파서입니다.
렉서는 공백 및 줄바꿈과 같은 관련 없는 문자를 삭제하는 방법을 알고 있습니다.
파싱 프로세스는 반복적입니다. 파서는 일반적으로 렉서에게 새 토큰을 요청하고 토큰을 문법 규칙 중 하나와 일치시키려고 시도합니다. 규칙이 일치하면 토큰에 해당하는 노드가 파싱 트리에 추가되고 파서는 다른 토큰을 요청합니다.
일치하는 규칙이 없으면 파서는 토큰을 내부적으로 저장하고 내부적으로 저장된 모든 토큰과 일치하는 규칙이 발견될 때까지 토큰을 계속 요청합니다. 규칙이 없으면 파서에서 예외를 발생시킵니다. 즉, 문서가 유효하지 않고 구문 오류가 포함되어 있습니다.
번역
대부분의 경우 파싱 트리는 최종 제품이 아닙니다. 파싱은 입력 문서를 다른 형식으로 변환하는 번역에 자주 사용됩니다. 컴파일을 예로 들 수 있습니다. 소스 코드를 기계 코드로 컴파일하는 컴파일러는 먼저 소스 코드를 파싱 트리로 파싱한 다음 트리를 기계 코드 문서로 변환합니다.
파싱 예
그림 5에서는 수학 표현식에서 파싱 트리를 빌드했습니다. 간단한 수학 언어를 정의하고 파싱 프로세스를 살펴보겠습니다.
구문:
- 언어 문법 빌딩 블록은 표현식, 용어, 연산입니다.
- 언어는 표현식을 임의 개수 포함할 수 있습니다.
- 표현식은 '항' 다음에 '연산' 다음에 다른 항이 오는 것으로 정의됩니다.
- 작업이 더하기 토큰 또는 빼기 토큰입니다.
- 항은 정수 토큰 또는 표현식입니다.
입력 2 + 3 - 1를 분석해 보겠습니다.
규칙과 일치하는 첫 번째 하위 문자열은 2입니다. 규칙 5에 따라 이는 용어입니다.
두 번째 일치는 2 + 3입니다. 이는 연산자가 뒤에 오는 항 다음에 다른 항이 오는 세 번째 규칙과 일치합니다.
다음 일치는 입력의 끝에서만 발생합니다.
2 + 3이 항이라는 것을 이미 알고 있으므로 2 + 3 - 1는 표현식입니다. 즉, 항 다음에 연산자가 있고 그 다음에 다른 항이 있습니다.
2 + +는 어떤 규칙과도 일치하지 않으므로 잘못된 입력입니다.
어휘 및 문법의 공식 정의
어휘는 일반적으로 정규 표현식으로 표현됩니다.
예를 들어 언어는 다음과 같이 정의됩니다.
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -
보시다시피 정수는 정규 표현식으로 정의됩니다.
구문은 일반적으로 BNF라는 형식으로 정의됩니다. Google의 언어는 다음과 같이 정의됩니다.
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
문법이 컨텍스트 자유 문법인 경우 언어를 일반 파서로 파싱할 수 있다고 했습니다. 컨텍스트 자유 문법의 직관적인 정의는 BNF로 완전히 표현할 수 있는 문법입니다. 공식적인 정의는 위키백과에서 문맥 자유 문법에 관한 도움말을 참고하세요.
파서 유형
파서에는 위에서 아래로 파서와 아래에서 위로 파서의 두 가지 유형이 있습니다. 직관적으로 설명하자면, 위에서 아래로 파서는 문법의 상위 구조를 검사하고 규칙 일치를 찾으려고 시도합니다. 하향식 파서는 입력으로 시작하여 하위 수준 규칙부터 상위 수준 규칙이 충족될 때까지 점진적으로 문법 규칙으로 변환합니다.
두 가지 유형의 파서가 이 예시를 어떻게 파싱하는지 살펴보겠습니다.
위에서 아래로 파서는 상위 수준 규칙에서 시작합니다. 2 + 3를 표현식으로 식별합니다. 그런 다음 2 + 3 - 1를 표현식으로 식별합니다. 표현식을 식별하는 프로세스는 다른 규칙과 일치하도록 발전하지만 시작점은 최상위 규칙입니다.
하향식 파서는 규칙이 일치할 때까지 입력을 스캔합니다. 그러면 일치하는 입력이 규칙으로 대체됩니다. 입력이 끝날 때까지 계속됩니다. 부분적으로 일치하는 표현식은 파서 스택에 배치됩니다.
이러한 유형의 하향식 파서를 시프트-리듀스 파서라고 합니다. 입력이 오른쪽으로 이동하고 (포인터가 먼저 입력 시작 부분을 가리키고 오른쪽으로 이동한다고 가정) 점차 문법 규칙으로 축소되기 때문입니다.
파서 자동 생성
파서를 생성할 수 있는 도구가 있습니다. 언어의 문법(단어 및 구문 규칙)을 입력하면 작동하는 파서가 생성됩니다. 파서를 만들려면 파싱에 대한 심층적인 이해가 필요하며 최적화된 파서를 수동으로 만드는 것은 쉽지 않으므로 파서 생성기가 매우 유용할 수 있습니다.
WebKit은 두 가지 잘 알려진 파서 생성기를 사용합니다. 렉스 생성을 위한 Flex와 파서 생성을 위한 Bison (Lex 및 Yacc라는 이름으로 표시될 수 있음)입니다. Flex 입력은 토큰의 정규 표현식 정의가 포함된 파일입니다. Bison의 입력은 BNF 형식의 언어 문법 규칙입니다.
HTML 파서
HTML 파서의 역할은 HTML 마크업을 파싱 트리로 파싱하는 것입니다.
HTML 문법
HTML의 어휘와 문법은 W3C 조직에서 만든 사양에 정의되어 있습니다.
파싱 소개에서 보았듯이 문법 구문은 BNF와 같은 형식을 사용하여 공식적으로 정의할 수 있습니다.
안타깝게도 기존의 모든 파서 주제는 HTML에 적용되지 않습니다. 재미로 언급한 것이 아니라 CSS 및 JavaScript 파싱에 사용됩니다. HTML은 파서에 필요한 컨텍스트 자유 문법으로 쉽게 정의할 수 없습니다.
HTML을 정의하는 공식 형식인 DTD (문서 유형 정의)가 있지만 컨텍스트 자유 문법은 아닙니다.
언뜻 보면 이상해 보이지만 HTML은 XML과 매우 유사합니다. 사용할 수 있는 XML 파서는 많습니다. HTML의 XML 변형인 XHTML이 있습니다. 그렇다면 두 가지의 큰 차이점은 무엇인가요?
차이점은 HTML 접근 방식이 더 '관대한' 점입니다. 특정 태그를 생략할 수 있으며 (이 경우 암시적으로 추가됨) 시작 태그나 종료 태그를 생략할 수도 있습니다. 전반적으로 XML의 엄격하고 까다로운 문법과 달리 '부드러운' 문법입니다.
이러한 사소한 세부정보가 큰 차이를 만듭니다. 한편으로는 이러한 특징이 HTML이 인기 있는 주된 이유입니다. 실수를 용납하고 웹 작성자의 작업을 간소화하기 때문입니다. 반면에 정규 문법을 작성하기는 어렵습니다. 요약하자면 HTML의 문법은 컨텍스트 자유가 아니므로 기존 파서로는 HTML을 쉽게 파싱할 수 없습니다. XML 파서에서는 HTML을 파싱할 수 없습니다.
HTML DTD
HTML 정의는 DTD 형식입니다. 이 형식은 SGML 계열의 언어를 정의하는 데 사용됩니다. 이 형식에는 허용되는 모든 요소, 속성, 계층 구조에 대한 정의가 포함되어 있습니다. 앞에서 보았듯이 HTML DTD는 문맥 자유 문법을 형성하지 않습니다.
DTD에는 몇 가지 변형이 있습니다. 엄격 모드는 사양만 준수하지만 다른 모드에는 이전에 브라우저에서 사용한 마크업을 지원하는 기능이 포함되어 있습니다. 이전 콘텐츠와의 하위 호환성을 유지하기 위한 것입니다. 현재 엄격한 DTD는 www.w3.org/TR/html4/strict.dtd에서 확인할 수 있습니다.
DOM
출력 트리('파싱 트리')는 DOM 요소 및 속성 노드의 트리입니다. DOM은 문서 객체 모델의 줄임말입니다. HTML 문서의 객체 프레젠테이션이자 JavaScript와 같은 외부 세계에 대한 HTML 요소의 인터페이스입니다.
트리의 루트는 '문서' 객체입니다.
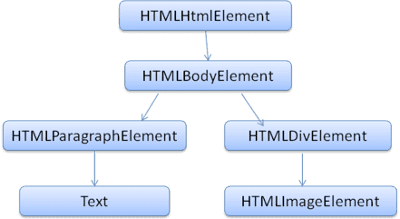
DOM은 마크업과 거의 일대일로 연결됩니다. 예를 들면 다음과 같습니다.
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
이 마크업은 다음과 같은 DOM 트리로 변환됩니다.
HTML과 마찬가지로 DOM은 W3C 조직에서 지정합니다. www.w3.org/DOM/DOMTR을 참고하세요. 문서를 조작하기 위한 일반 사양입니다. 특정 모듈은 HTML 관련 요소를 설명합니다. HTML 정의는 www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html에서 확인할 수 있습니다.
트리에 DOM 노드가 포함되어 있다고 하면 트리가 DOM 인터페이스 중 하나를 구현하는 요소로 구성되어 있음을 의미합니다. 브라우저는 브라우저에서 내부적으로 사용하는 다른 속성이 있는 구체적인 구현을 사용합니다.
파싱 알고리즘
이전 섹션에서 보았듯이 HTML은 일반 상위에서 하단으로 또는 하단에서 상단으로 파싱할 수 없습니다.
이유는 다음과 같습니다.
- 언어의 관대한 성격
- 잘 알려진 잘못된 HTML 사례를 지원하기 위해 브라우저에 기존 오류 허용 범위가 있다는 사실
- 파싱 프로세스는 재진입 가능합니다. 다른 언어의 경우 소스는 파싱 중에 변경되지 않지만 HTML에서는 동적 코드 (예:
document.write()호출이 포함된 스크립트 요소)가 추가 토큰을 추가할 수 있으므로 파싱 프로세스가 실제로 입력을 수정합니다.
일반 파싱 기법을 사용할 수 없으므로 브라우저는 HTML 파싱을 위한 맞춤 파서를 만듭니다.
파싱 알고리즘은 HTML5 사양에 자세히 설명되어 있습니다. 이 알고리즘은 토큰화와 트리 구성이라는 두 단계로 구성됩니다.
토큰화는 입력을 토큰으로 파싱하는 어휘 분석입니다. HTML 토큰에는 시작 태그, 종료 태그, 속성 이름, 속성 값이 있습니다.
토큰라이저는 토큰을 인식하여 트리 생성자에 전달하고 다음 토큰을 인식하기 위해 다음 문자를 사용하며, 입력이 끝날 때까지 계속합니다.
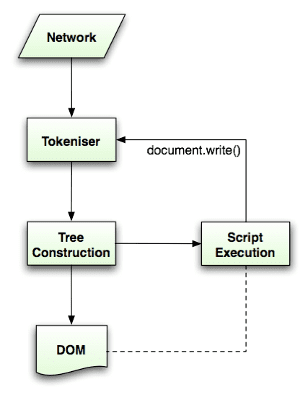
토큰화 알고리즘
알고리즘의 출력은 HTML 토큰입니다. 알고리즘은 상태 머신으로 표현됩니다. 각 상태는 입력 스트림의 하나 이상의 문자를 소비하고 해당 문자에 따라 다음 상태를 업데이트합니다. 이 결정은 현재 토큰화 상태와 트리 생성 상태의 영향을 받습니다. 즉, 동일한 소비된 문자는 현재 상태에 따라 올바른 다음 상태에 대해 다른 결과를 산출합니다. 알고리즘은 너무 복잡하여 완전히 설명하기 어렵습니다. 따라서 원리를 이해하는 데 도움이 되는 간단한 예를 살펴보겠습니다.
기본 예 - 다음 HTML 토큰화
<html>
<body>
Hello world
</body>
</html>
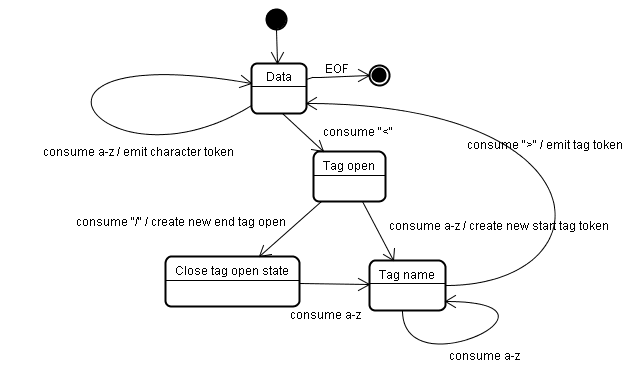
초기 상태는 '데이터 상태'입니다.
< 문자가 발견되면 상태가 '태그 열림 상태'로 변경됩니다.
a-z 문자를 사용하면 '시작 태그 토큰'이 생성되고 상태가 '태그 이름 상태'로 변경됩니다.
> 문자가 사용될 때까지 이 상태로 유지됩니다. 각 문자는 새 토큰 이름에 추가됩니다. 여기서는 생성된 토큰이 html 토큰입니다.
> 태그에 도달하면 현재 토큰이 내보내지고 상태가 '데이터 상태'로 다시 변경됩니다.
<body> 태그도 동일한 단계로 처리됩니다.
지금까지 html 및 body 태그가 내보내졌습니다. 이제 '데이터 상태'로 돌아갑니다.
Hello world의 H 문자를 사용하면 문자 토큰이 생성되고 내보내집니다. 이 과정은 </body>의 <에 도달할 때까지 계속됩니다. Hello world의 각 문자에 대해 문자 토큰을 내보냅니다.
이제 '태그 열기 상태'로 돌아갑니다.
다음 입력 /을 사용하면 end tag token가 생성되고 '태그 이름 상태'로 이동합니다. >에 도달할 때까지 다시 이 상태를 유지합니다.그러면 새 태그 토큰이 내보내지고 '데이터 상태'로 돌아갑니다.
</html> 입력은 이전 사례와 같이 처리됩니다.
트리 구성 알고리즘
파서가 생성되면 문서 객체가 생성됩니다. 트리 생성 단계에서 루트에 문서가 있는 DOM 트리가 수정되고 요소가 추가됩니다. 토큰라이저에서 내보낸 각 노드는 트리 생성자에 의해 처리됩니다. 사양은 각 토큰에 대해 이 토큰과 관련이 있으며 이 토큰에 대해 생성될 DOM 요소를 정의합니다. 요소가 DOM 트리와 열린 요소 스택에 추가됩니다. 이 스택은 중첩 불일치 및 닫지 않은 태그를 수정하는 데 사용됩니다. 이 알고리즘은 상태 머신으로서도 설명됩니다. 이러한 상태를 '삽입 모드'라고 합니다.
입력 예시의 트리 구성 프로세스를 살펴보겠습니다.
<html>
<body>
Hello world
</body>
</html>
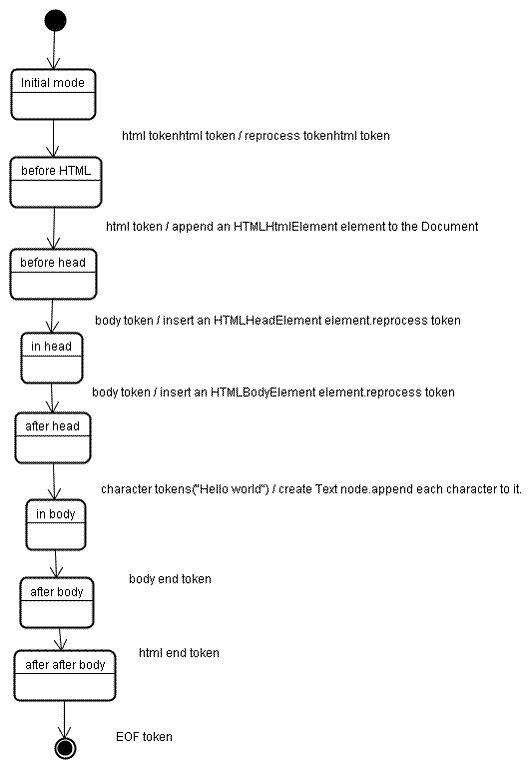
트리 생성 단계의 입력은 토큰화 단계의 토큰 시퀀스입니다. 첫 번째 모드는 '초기 모드'입니다. 'html' 토큰을 수신하면 'html 이전' 모드로 이동하고 해당 모드에서 토큰을 다시 처리합니다. 이렇게 하면 HTMLHtmlElement 요소가 생성되고 루트 Document 객체에 추가됩니다.
상태가 'before head'로 변경됩니다. 그런 다음 'body' 토큰이 수신됩니다. 'head' 토큰이 없지만 HTMLHeadElement가 암시적으로 생성되고 트리에 추가됩니다.
이제 'in head' 모드로 전환한 다음 'after head'로 전환합니다. 본문 토큰이 다시 처리되고 HTMLBodyElement가 생성 및 삽입되며 모드는 'in body'로 전송됩니다.
이제 'Hello world' 문자열의 문자 토큰이 수신됩니다. 첫 번째 문자는 '텍스트' 노드가 생성되고 삽입되도록 하고 다른 문자는 해당 노드에 추가됩니다.
본문 종료 토큰을 수신하면 '본문 뒤' 모드로 전환됩니다. 이제 html 종료 태그가 수신되어 'body 뒤' 모드로 전환됩니다. 파일 종료 토큰을 수신하면 파싱이 종료됩니다.
파싱이 완료될 때의 작업
이 단계에서 브라우저는 문서를 대화형으로 표시하고 '지연된' 모드(문서가 파싱된 후에 실행되어야 하는 스크립트)의 스크립트 파싱을 시작합니다. 그러면 문서 상태가 'complete'로 설정되고 'load' 이벤트가 실행됩니다.
HTML5 사양에서 토큰화 및 트리 구성을 위한 전체 알고리즘을 확인할 수 있습니다.
브라우저의 오류 허용 범위
HTML 페이지에 '잘못된 구문' 오류가 발생하지 않습니다. 브라우저는 잘못된 콘텐츠를 수정한 후 계속 진행합니다.
다음 HTML을 예로 들 수 있습니다.
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
약 100만 개의 규칙을 위반했을 텐데도 ('mytag'가 표준 태그가 아니고 'p' 및 'div' 요소의 중첩이 잘못됨 등) 브라우저에 여전히 올바르게 표시되고 불만사항이 없습니다. 따라서 많은 파서 코드가 HTML 작성자의 실수를 수정합니다.
오류 처리는 브라우저에서 매우 일관적이지만 놀랍게도 HTML 사양의 일부가 아닙니다. 북마크 및 뒤로/앞으로 버튼과 마찬가지로 수년간 브라우저에서 개발된 기능입니다. 많은 사이트에서 잘못된 HTML 구성이 반복적으로 발견되며 브라우저는 다른 브라우저와 호환되는 방식으로 이를 수정하려고 합니다.
HTML5 사양에서는 이러한 요구사항 중 일부를 정의합니다. WebKit은 HTML 파서 클래스 시작 부분의 주석에서 이를 잘 요약합니다.
파서는 토큰화된 입력을 문서로 파싱하여 문서 트리를 빌드합니다. 문서 형식이 올바르면 파싱이 간단합니다.
안타깝게도 형식이 올바르지 않은 HTML 문서를 많이 처리해야 하므로 파서는 오류를 허용해야 합니다.
다음과 같은 오류 조건을 최소한 처리해야 합니다.
- 추가되는 요소가 일부 외부 태그 내에서 명시적으로 금지되어 있습니다. 이 경우 요소를 금지하는 태그까지 모든 태그를 닫고 나중에 추가해야 합니다.
- YouTube에서는 요소를 직접 추가할 수 없습니다. 문서 작성자가 중간에 있는 태그를 잊어버렸거나 중간의 태그가 선택사항일 수 있습니다. HTML HEAD BODY TBODY TR TD LI 태그가 여기에 해당할 수 있습니다 (누락된 태그가 있나요?).
- 인라인 요소 내에 블록 요소를 추가하려고 합니다. 다음 상위 블록 요소까지 모든 인라인 요소를 닫습니다.
- 그래도 문제가 해결되지 않으면 요소를 추가할 수 있을 때까지 요소를 닫거나 태그를 무시하세요.
WebKit 오류 허용 예를 살펴보겠습니다.
<br> 대신 </br>
일부 사이트에서는 <br> 대신 </br>를 사용합니다. IE 및 Firefox와 호환되도록 WebKit은 이를 <br>처럼 취급합니다.
코드:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
오류 처리는 내부적으로 이루어지며 사용자에게 표시되지 않습니다.
유효하지 않은 표
외부 테이블은 다른 테이블 내부에 있지만 테이블 셀 내에 있지 않은 테이블입니다.
예를 들면 다음과 같습니다.
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
WebKit은 계층 구조를 두 개의 형제 테이블로 변경합니다.
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
코드:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
WebKit은 현재 요소 콘텐츠에 스택을 사용합니다. 내부 테이블을 외부 테이블 스택에서 팝합니다. 이제 테이블이 서로 형제 관계가 됩니다.
중첩된 양식 요소
사용자가 한 양식 내에 다른 양식을 배치하는 경우 두 번째 양식은 무시됩니다.
코드:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
태그 계층 구조가 너무 깊음
댓글이 이를 증명합니다.
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
잘못 배치된 html 또는 body 종료 태그
다시 한번 말씀드리지만 댓글은 그 자체로 의미가 있습니다.
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
따라서 웹 작성자는 WebKit 오류 허용 범위 코드 스니펫의 예시로 표시되고 싶지 않다면 올바른 형식의 HTML을 작성해야 합니다.
CSS 파싱
소개에서 다룬 파싱 개념을 기억하시나요? HTML과 달리 CSS는 문맥 자유 문법이므로 시작 부분에 설명된 파서 유형을 사용하여 파싱할 수 있습니다. 실제로 CSS 사양은 CSS 어휘 및 구문 문법을 정의합니다.
몇 가지 예를 살펴보겠습니다.
어휘 문법 (어휘)은 각 토큰의 정규 표현식으로 정의됩니다.
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
'ident'는 클래스 이름과 같은 식별자의 줄임말입니다. 'name'은 요소 ID입니다('#'으로 참조됨).
문법 문법은 BNF에 설명되어 있습니다.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
설명:
규칙 집합의 구조는 다음과 같습니다.
div.error, a.error {
color:red;
font-weight:bold;
}
div.error 및 a.error는 선택기입니다. 중괄호 안의 부분에는 이 규칙 집합에서 적용되는 규칙이 포함됩니다.
이 구조는 다음 정의에서 공식적으로 정의됩니다.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
즉, 규칙 집합은 선택자 또는 선택자 여러 개(쉼표와 공백으로 구분)입니다(S는 공백을 나타냅니다). 규칙 집합에는 중괄호가 포함되며 그 안에 선언이 하나 있거나 원하는 경우 세미콜론으로 구분된 여러 선언이 포함됩니다. '선언' 및 '선택자'는 다음 BNF 정의에서 정의됩니다.
WebKit CSS 파서
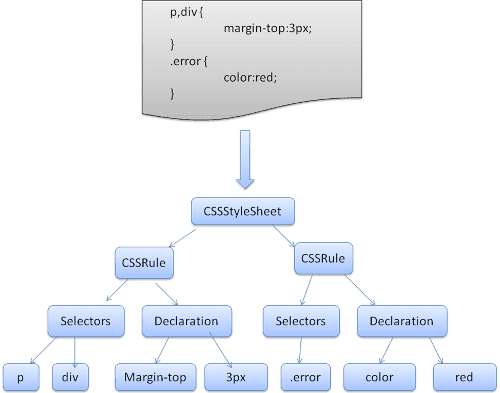
WebKit은 Flex 및 Bison 파서 생성기를 사용하여 CSS 문법 파일에서 파서를 자동으로 만듭니다. 파서 소개에서 기억하실 수 있듯이 Bison은 하향식 시프트-리듀스 파서를 만듭니다. Firefox는 수동으로 작성된 상위에서 하단으로 파서를 사용합니다. 두 경우 모두 각 CSS 파일이 StyleSheet 객체로 파싱됩니다. 각 객체에는 CSS 규칙이 포함됩니다. CSS 규칙 객체에는 선택자 및 선언 객체와 CSS 문법에 해당하는 기타 객체가 포함됩니다.
스크립트 및 스타일 시트 처리 순서
스크립트
웹의 모델은 동기식입니다. 작성자는 파서가 <script> 태그에 도달하면 스크립트가 즉시 파싱되고 실행되기를 기대합니다.
스크립트가 실행될 때까지 문서 파싱이 중지됩니다.
스크립트가 외부인 경우 먼저 네트워크에서 리소스를 가져와야 합니다. 이 작업도 동기식으로 실행되며 리소스가 가져올 때까지 파싱이 중단됩니다.
이는 오랫동안 사용된 모델이며 HTML4 및 5 사양에도 지정되어 있습니다.
작성자는 스크립트에 'defer' 속성을 추가할 수 있습니다. 이 경우 문서 파싱이 중지되지 않으며 문서가 파싱된 후에 실행됩니다. HTML5에서는 스크립트를 비동기식으로 표시하여 다른 스레드에서 파싱하고 실행할 수 있는 옵션을 추가합니다.
예측 파싱
WebKit과 Firefox 모두 이 최적화를 실행합니다. 스크립트를 실행하는 동안 다른 스레드가 문서의 나머지 부분을 파싱하고 네트워크에서 로드해야 하는 다른 리소스를 찾아 로드합니다. 이렇게 하면 리소스를 병렬 연결에 로드할 수 있고 전반적인 속도가 개선됩니다. 참고: 추측 파서는 외부 스크립트, 스타일 시트, 이미지와 같은 외부 리소스에 대한 참조만 파싱합니다. DOM 트리는 수정하지 않으며 이는 기본 파서에 맡깁니다.
스타일 시트
반면에 스타일 시트는 다른 모델을 사용합니다. 개념적으로 스타일 시트는 DOM 트리를 변경하지 않으므로 스타일 시트를 기다렸다가 문서 파싱을 중지할 이유가 없습니다. 하지만 문서 파싱 단계에서 스타일 정보를 요청하는 스크립트에는 문제가 있습니다. 스타일이 아직 로드되고 파싱되지 않으면 스크립트에서 잘못된 답변을 가져오게 되며, 이로 인해 많은 문제가 발생한 것으로 보입니다. 특이한 사례처럼 보이지만 꽤 흔한 문제입니다. 아직 로드되고 파싱되고 있는 스타일 시트가 있으면 Firefox에서 모든 스크립트를 차단합니다. WebKit은 로드되지 않은 스타일 시트의 영향을 받을 수 있는 특정 스타일 속성에 액세스하려고 할 때만 스크립트를 차단합니다.
렌더링 트리 구성
DOM 트리가 생성되는 동안 브라우저는 렌더링 트리라는 다른 트리를 생성합니다. 이 트리는 시각적 요소가 표시될 순서대로 표시됩니다. 문서를 시각적으로 나타낸 것입니다. 이 트리의 목적은 콘텐츠를 올바른 순서로 페인팅할 수 있도록 하는 것입니다.
Firefox에서는 렌더링 트리의 요소를 '프레임'이라고 합니다. WebKit에서는 렌더러 또는 렌더링 객체라는 용어를 사용합니다.
렌더러는 자신과 하위 요소를 레이아웃하고 페인트하는 방법을 알고 있습니다.
렌더러의 기본 클래스인 WebKit의 RenderObject 클래스는 다음과 같이 정의됩니다.
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
각 렌더러는 일반적으로 CSS2 사양에 설명된 대로 노드의 CSS 상자에 해당하는 직사각형 영역을 나타냅니다. 여기에는 너비, 높이, 위치와 같은 기하학적 정보가 포함됩니다.
상자 유형은 노드와 관련된 스타일 속성의 'display' 값의 영향을 받습니다 (스타일 계산 섹션 참고). 다음은 디스플레이 속성에 따라 DOM 노드에 생성할 렌더러 유형을 결정하는 WebKit 코드입니다.
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
요소 유형도 고려됩니다. 예를 들어 양식 컨트롤과 표에는 특수 프레임이 있습니다.
WebKit에서 요소가 특수 렌더러를 만들려면 createRenderer() 메서드를 재정의합니다.
렌더러는 기하학적 정보가 아닌 스타일 객체를 가리킵니다.
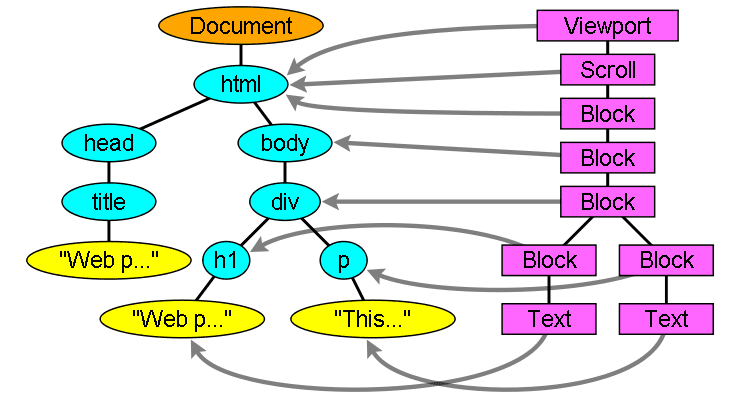
DOM 트리와의 렌더링 트리 관계
렌더러는 DOM 요소에 해당하지만 관계는 일대일로 매핑되지 않습니다. 시각적이지 않은 DOM 요소는 렌더링 트리에 삽입되지 않습니다. 'head' 요소가 그 예입니다. 또한 표시 값이 'none'으로 할당된 요소는 트리에 표시되지 않습니다('hidden' 공개 상태의 요소는 트리에 표시됨).
여러 시각적 객체에 해당하는 DOM 요소가 있습니다. 일반적으로 단일 직사각형으로 설명할 수 없는 복잡한 구조의 요소입니다. 예를 들어 'select' 요소에는 디스플레이 영역용 렌더러 1개, 드롭다운 목록 상자용 렌더러 1개, 버튼용 렌더러 1개가 있습니다. 또한 너비가 한 줄에 충분하지 않아 텍스트가 여러 줄로 나뉘는 경우 새 줄이 추가 렌더러로 추가됩니다.
여러 렌더러의 또 다른 예는 손상된 HTML입니다. CSS 사양에 따라 인라인 요소는 블록 요소만 포함하거나 인라인 요소만 포함해야 합니다. 혼합 콘텐츠의 경우 인라인 요소를 래핑하기 위해 익명의 블록 렌더러가 생성됩니다.
일부 렌더링 객체는 DOM 노드에 해당하지만 트리의 같은 위치에 있지는 않습니다. 플로팅 요소와 절대 위치로 배치된 요소는 흐름을 벗어나 트리의 다른 부분에 배치되고 실제 프레임에 매핑됩니다. 자리표시자 프레임은 이미지가 있어야 할 위치입니다.
트리 구성 흐름
Firefox에서는 프레젠테이션이 DOM 업데이트의 리스너로 등록됩니다.
프레젠테이션은 프레임 생성을 FrameConstructor에 위임하고 생성자는 스타일을 확인 (스타일 계산 참고)하고 프레임을 만듭니다.
WebKit에서 스타일을 확인하고 렌더러를 만드는 프로세스를 '첨부'라고 합니다. 모든 DOM 노드에는 'attach' 메서드가 있습니다. 연결은 동기식이며 DOM 트리에 노드를 삽입하면 새 노드 'attach' 메서드가 호출됩니다.
html 및 body 태그를 처리하면 렌더링 트리 루트가 생성됩니다.
루트 렌더링 객체는 CSS 사양에서 포함 블록이라고 부르는 것, 즉 다른 모든 블록을 포함하는 최상위 블록에 해당합니다. 크기는 브라우저 창 표시 영역 크기인 표시 영역입니다.
Firefox에서는 이를 ViewPortFrame라고 부르고 WebKit에서는 RenderView라고 부릅니다.
문서가 가리키는 렌더링 객체입니다.
나머지 트리는 DOM 노드 삽입으로 구성됩니다.
처리 모델의 CSS2 사양을 참고하세요.
스타일 계산
렌더링 트리를 빌드하려면 각 렌더링 객체의 시각적 속성을 계산해야 합니다. 이는 각 요소의 스타일 속성을 계산하여 수행됩니다.
스타일에는 다양한 출처의 스타일 시트, 인라인 스타일 요소, HTML의 시각적 속성 (예: 'bgcolor' 속성)이 포함됩니다. 후자는 일치하는 CSS 스타일 속성으로 변환됩니다.
스타일 시트의 출처는 브라우저의 기본 스타일 시트, 페이지 작성자가 제공한 스타일 시트, 사용자 스타일 시트입니다. 사용자 스타일 시트는 브라우저 사용자가 제공한 스타일 시트입니다. 브라우저를 사용하면 좋아하는 스타일을 정의할 수 있습니다. 예를 들어 Firefox에서는 'Firefox 프로필' 폴더에 스타일 시트를 배치하여 이 작업을 실행합니다.
스타일 계산은 몇 가지 어려움을 야기합니다.
- 스타일 데이터는 수많은 스타일 속성을 보유한 매우 큰 구성이므로 메모리 문제가 발생할 수 있습니다.
각 요소에 일치하는 규칙을 찾는 작업은 최적화되지 않은 경우 성능 문제를 일으킬 수 있습니다. 일치 항목을 찾기 위해 각 요소의 전체 규칙 목록을 탐색하는 것은 부담스러운 작업입니다. 선택자는 복잡한 구조를 가질 수 있으므로 일치 프로세스가 유망해 보이는 경로에서 시작하여 무용하다고 판명되고 다른 경로를 시도해야 할 수 있습니다.
예를 들어 다음과 같은 복합 선택기가 있습니다.
div div div div{ ... }3개의 div의 하위 요소인
<div>에 규칙이 적용됨을 의미합니다. 지정된<div>요소에 규칙이 적용되는지 확인하려고 한다고 가정해 보겠습니다. 확인할 트리의 특정 경로를 선택합니다. div가 2개뿐이고 규칙이 적용되지 않는다는 것을 확인하기 위해 노드 트리를 위로 이동해야 할 수도 있습니다. 그런 다음 트리의 다른 경로를 시도해 보세요.규칙을 적용하려면 규칙의 계층 구조를 정의하는 매우 복잡한 캐스케이드 규칙이 필요합니다.
브라우저에서 이러한 문제가 발생하는 방식을 살펴보겠습니다.
스타일 데이터 공유
WebKit 노드는 스타일 객체 (RenderStyle)를 참조합니다. 이러한 객체는 경우에 따라 노드에서 공유할 수 있습니다. 노드는 형제 또는 사촌이며 다음과 같은 특징이 있습니다.
- 요소가 동일한 마우스 상태여야 합니다 (예: 하나는 :hover 상태이고 다른 하나는 :hover 상태가 아니면 안 됨).
- 두 요소 모두 ID가 없어야 합니다.
- 태그 이름이 일치해야 합니다.
- 클래스 속성이 일치해야 합니다.
- 매핑된 속성 집합은 동일해야 함
- 링크 상태가 일치해야 합니다.
- 포커스 상태가 일치해야 합니다.
- 두 요소 모두 속성 선택기의 영향을 받지 않아야 합니다. 여기서 영향을 받는다는 것은 선택기 내의 모든 위치에서 속성 선택기를 사용하는 선택기 일치가 있는 것으로 정의됩니다.
- 요소에 인라인 스타일 속성이 없어야 합니다.
- 사용 중인 상위 요소 선택기가 전혀 없어야 합니다. WebCore는 상위 요소 선택기가 발견되면 전역 스위치를 발생시키고 상위 요소 선택기가 있는 경우 전체 문서의 스타일 공유를 사용 중지합니다. 여기에는 + 선택자와 :first-child 및 :last-child와 같은 선택자가 포함됩니다.
Firefox 규칙 트리
Firefox에는 더 쉬운 스타일 계산을 위한 두 가지 트리인 규칙 트리와 스타일 컨텍스트 트리가 있습니다. WebKit에도 스타일 객체가 있지만 스타일 컨텍스트 트리와 같은 트리에 저장되지는 않습니다. DOM 노드만 관련 스타일을 가리킵니다.
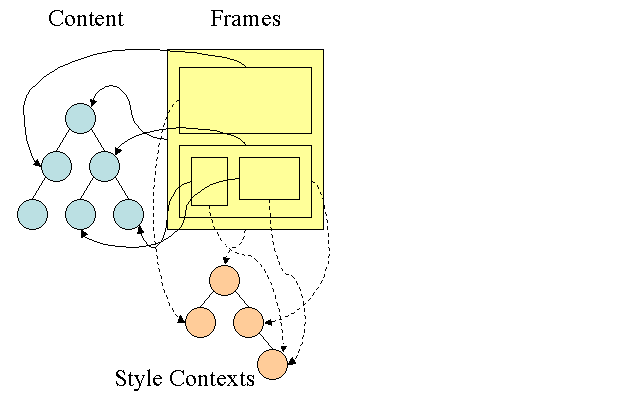
스타일 컨텍스트에는 종료 값이 포함됩니다. 값은 모든 일치 규칙을 올바른 순서로 적용하고 이를 논리적 값에서 구체적인 값으로 변환하는 조작을 실행하여 계산됩니다. 예를 들어 논리적 값이 화면의 비율인 경우 계산되어 절대 단위로 변환됩니다. 규칙 트리 아이디어는 정말 영리합니다. 이러한 값을 노드 간에 공유하여 다시 계산하지 않도록 할 수 있습니다. 이렇게 하면 공간도 절약됩니다.
일치하는 모든 규칙은 트리에 저장됩니다. 경로의 하단 노드가 우선순위가 더 높습니다. 트리에는 발견된 규칙 일치의 모든 경로가 포함됩니다. 규칙 저장은 지연되어 실행됩니다. 트리는 모든 노드에 대해 처음에 계산되지는 않지만 노드 스타일을 계산해야 할 때마다 계산된 경로가 트리에 추가됩니다.
트리 경로를 렉시콘의 단어로 보는 것이 좋습니다. 이미 이 규칙 트리를 계산했다고 가정해 보겠습니다.
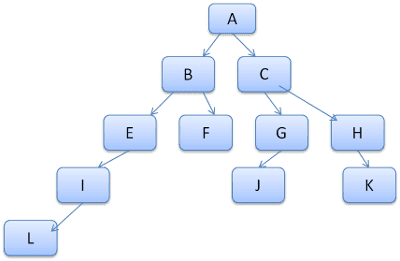
콘텐츠 트리의 다른 요소에 관한 규칙을 일치시키고 일치하는 규칙이 B-E-I임을 알아야 한다고 가정해 보겠습니다. 이미 A-B-E-I-L 경로를 계산했으므로 트리에 이 경로가 이미 있습니다. 이제 할 일이 줄어듭니다.
트리가 어떻게 작업을 줄여주는지 살펴보겠습니다.
구조체로 분할
스타일 컨텍스트는 구조체로 나뉩니다. 이러한 구조체에는 테두리 또는 색상과 같은 특정 카테고리의 스타일 정보가 포함됩니다. 구조체의 모든 속성은 상속되거나 상속되지 않습니다. 상속된 속성은 요소에서 정의하지 않는 한 상위 요소에서 상속되는 속성입니다. 상속되지 않은 속성('재설정' 속성이라고 함)은 정의되지 않은 경우 기본값을 사용합니다.
트리는 계산된 최종 값이 포함된 전체 구조체를 트리에 캐시하여 도움이 됩니다. 하단 노드가 구조체의 정의를 제공하지 않은 경우 상위 노드의 캐시된 구조체를 사용할 수 있다는 개념입니다.
규칙 트리를 사용하여 스타일 컨텍스트 계산
특정 요소의 스타일 컨텍스트를 계산할 때는 먼저 규칙 트리에서 경로를 계산하거나 기존 경로를 사용합니다. 그런 다음 경로의 규칙을 적용하여 새 스타일 컨텍스트의 구조체를 채웁니다. 우선순위가 가장 높은 노드 (일반적으로 가장 구체적인 선택기)인 경로의 하단 노드에서 시작하여 구조체가 가득 찰 때까지 트리를 탐색합니다. 해당 규칙 노드에 구조체 사양이 없는 경우 크게 최적화할 수 있습니다. 완전히 지정하고 이를 가리키는 노드를 찾을 때까지 트리를 올라갑니다. 이것이 최적의 최적화입니다. 전체 구조체가 공유됩니다. 이렇게 하면 최종 값 계산과 메모리가 절약됩니다.
부분적인 정의를 찾으면 구조체가 채워질 때까지 트리를 위로 이동합니다.
구조체에 대한 정의가 발견되지 않으면 구조체가 '상속된' 유형인 경우 컨텍스트 트리에서 상위 요소의 구조체를 가리킵니다. 이 경우 구조체도 공유할 수 있었습니다. 재설정 구조체인 경우 기본값이 사용됩니다.
가장 구체적인 노드가 값을 추가하는 경우 이를 실제 값으로 변환하기 위해 추가 계산을 실행해야 합니다. 그런 다음 하위 요소에서 사용할 수 있도록 결과를 트리 노드에 캐시합니다.
요소에 동일한 트리 노드를 가리키는 형제 요소가 있는 경우 전체 스타일 컨텍스트를 형제 요소 간에 공유할 수 있습니다.
예를 살펴보겠습니다. 다음과 같은 HTML이 있다고 가정해 보겠습니다.
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
다음 규칙도 적용됩니다.
div {margin: 5px; color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
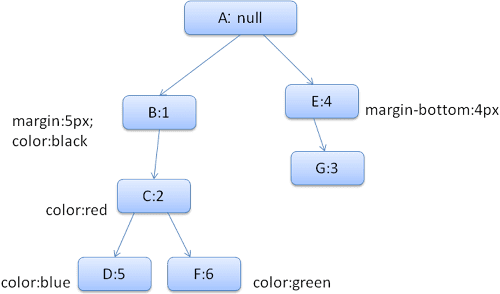
간단히 하기 위해 색상 구조체와 여백 구조체라는 두 가지 구조체만 작성해야 한다고 가정해 보겠습니다. 색상 구조체에는 색상 멤버 하나만 포함됩니다. 여백 구조체에는 네 면이 포함됩니다.
결과 규칙 트리는 다음과 같이 표시됩니다(노드는 노드 이름(가리키는 규칙의 번호)으로 표시됨).
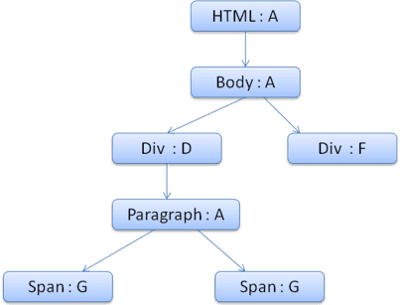
컨텍스트 트리는 다음과 같이 표시됩니다 (노드 이름: 가리키는 규칙 노드).
HTML을 파싱하여 두 번째 <div> 태그에 도달한다고 가정해 보겠습니다. 이 노드의 스타일 컨텍스트를 만들고 스타일 구조체를 채워야 합니다.
규칙을 일치시키면 <div>의 일치 규칙이 1, 2, 6임을 알 수 있습니다.
즉, 트리에 이미 요소가 사용할 수 있는 기존 경로가 있으며 규칙 6 (규칙 트리의 노드 F)에 노드를 하나 더 추가하기만 하면 됩니다.
스타일 컨텍스트를 만들고 컨텍스트 트리에 배치합니다. 새 스타일 컨텍스트는 규칙 트리의 노드 F를 가리킵니다.
이제 스타일 구조체를 채워야 합니다. 먼저 마진 구조체를 채웁니다. 마지막 규칙 노드 (F)는 여백 구조체에 추가되지 않으므로 이전 노드 삽입에서 계산된 캐시된 구조체를 찾을 때까지 트리를 위로 이동하여 사용할 수 있습니다. 여백 규칙을 지정한 최상위 노드인 노드 B에서 찾을 수 있습니다.
색상 구조체에 대한 정의가 있으므로 캐시된 구조체를 사용할 수 없습니다. 색상에는 속성이 하나 있으므로 다른 속성을 채우기 위해 트리를 위로 이동할 필요가 없습니다. 최종 값을 계산하고 (문자열을 RGB로 변환 등) 계산된 구조체를 이 노드에 캐시합니다.
두 번째 <span> 요소의 작업은 훨씬 쉽습니다. 규칙을 일치시키면 이전 스팬과 마찬가지로 규칙 G를 가리키는 것으로 확인됩니다.
동일한 노드를 가리키는 형제가 있으므로 전체 스타일 컨텍스트를 공유하고 이전 스팬의 컨텍스트를 가리키기만 하면 됩니다.
상위 요소에서 상속된 규칙이 포함된 구조체의 경우 컨텍스트 트리에서 캐싱이 실행됩니다. 색상 속성은 실제로 상속되지만 Firefox에서는 재설정으로 취급하고 규칙 트리에 캐시합니다.
예를 들어 문단에 글꼴 규칙을 추가한 경우 다음과 같습니다.
p {font-family: Verdana; font size: 10px; font-weight: bold}
그러면 컨텍스트 트리의 div의 하위 요소인 단락 요소가 상위 요소와 동일한 글꼴 구조를 공유할 수 있습니다. 단락에 글꼴 규칙이 지정되지 않은 경우입니다.
규칙 트리가 없는 WebKit에서는 일치하는 선언이 4번 트래버스됩니다. 먼저 중요하지 않은 높은 우선순위 속성이 적용되고 (다른 속성이 이를 사용하기 때문에 먼저 적용해야 하는 속성, 예: 디스플레이), 그다음에는 중요한 높은 우선순위 속성이 적용되고, 그다음에는 중요하지 않은 일반 우선순위 속성이 적용되고, 그다음에는 중요한 일반 우선순위 속성이 적용됩니다. 즉, 여러 번 표시되는 속성은 올바른 계단식 순서에 따라 확인됩니다. 마지막 값이 적용됩니다.
요약하자면 스타일 객체 (전체 또는 내부 구조체의 일부)를 공유하면 문제 1과 3이 해결됩니다. Firefox 규칙 트리는 속성을 올바른 순서로 적용하는 데도 도움이 됩니다.
간편한 일치를 위해 규칙 조작
스타일 규칙의 소스는 다음과 같습니다.
- 외부 스타일 시트 또는 스타일 요소의 CSS 규칙입니다.
css p {color: blue} html <p style="color: blue" />와 같은 인라인 스타일 속성- HTML 시각적 속성 (관련 스타일 규칙에 매핑됨)
html <p bgcolor="blue" />스타일 속성을 소유하고 있고 HTML 속성을 요소를 키로 사용하여 매핑할 수 있으므로 마지막 두 속성은 요소와 쉽게 일치합니다.
앞의 문제 2에서 언급했듯이 CSS 규칙 일치는 더 까다로울 수 있습니다. 이 문제를 해결하기 위해 더 쉽게 액세스할 수 있도록 규칙을 조작합니다.
스타일 시트를 파싱한 후 규칙은 선택기에 따라 여러 해시 맵 중 하나에 추가됩니다. ID별, 클래스 이름별, 태그 이름별 맵과 이러한 카테고리에 맞지 않는 항목을 위한 일반 맵이 있습니다. 선택기가 ID인 경우 규칙이 ID 맵에 추가되고, 클래스인 경우 클래스 맵에 추가됩니다.
이렇게 조작하면 규칙을 더 쉽게 일치시킬 수 있습니다. 모든 선언을 살펴볼 필요는 없습니다. 맵에서 요소와 관련된 규칙을 추출할 수 있습니다. 이 최적화는 95% 이상의 규칙을 제거하므로 일치 프로세스(4.1) 중에 고려할 필요가 없습니다.
예를 들어 다음과 같은 스타일 규칙을 살펴보겠습니다.
p.error {color: red}
#messageDiv {height: 50px}
div {margin: 5px}
첫 번째 규칙이 클래스 맵에 삽입됩니다. 두 번째는 ID 맵에, 세 번째는 태그 맵에 매핑됩니다.
다음 HTML 프래그먼트의 경우
<p class="error">an error occurred</p>
<div id=" messageDiv">this is a message</div>
먼저 p 요소의 규칙을 찾으려고 합니다. 클래스 맵에는 'p.error'의 규칙이 있는 'error' 키가 포함됩니다. div 요소는 ID 맵 (키는 ID) 및 태그 맵에 관련 규칙이 있습니다. 따라서 남은 작업은 키로 추출된 규칙 중 실제로 일치하는 규칙을 찾는 것입니다.
예를 들어 div의 규칙이 다음과 같다고 가정해 보겠습니다.
table div {margin: 5px}
키가 가장 오른쪽 선택기이므로 태그 맵에서 여전히 추출되지만 테이블 조상이 없는 div 요소와 일치하지는 않습니다.
WebKit과 Firefox 모두 이 조작을 실행합니다.
스타일 시트 계단식 순서
스타일 객체에는 모든 시각적 속성 (모든 CSS 속성이지만 더 일반적임)에 해당하는 속성이 있습니다. 일치하는 규칙에 의해 속성이 정의되지 않은 경우 일부 속성은 상위 요소 스타일 객체에서 상속받을 수 있습니다. 다른 속성에는 기본값이 있습니다.
정의가 두 개 이상 있으면 문제가 시작됩니다. 이때 문제를 해결하기 위한 계단식 순서가 적용됩니다.
스타일 속성 선언은 여러 스타일 시트에 표시될 수 있으며 스타일 시트 내에서 여러 번 표시될 수 있습니다. 즉, 규칙을 적용하는 순서가 매우 중요합니다. 이를 '캐스케이드' 순서라고 합니다. CSS2 사양에 따르면 계층 구조 순서는 다음과 같습니다 (낮은 순서에서 높은 순서).
- 브라우저 선언
- 사용자 일반 선언
- 작성자 일반 선언
- 작성자 중요 선언
- 사용자 중요 선언
브라우저 선언은 가장 중요하지 않으며 선언이 중요로 표시된 경우에만 사용자가 작성자를 재정의합니다. 순서가 동일한 선언은 특이성을 기준으로 정렬된 후 지정된 순서대로 정렬됩니다. HTML 시각적 속성은 일치하는 CSS 선언으로 변환됩니다 . 이러한 규칙은 우선순위가 낮은 작성자 규칙으로 취급됩니다.
특수성
선택기 특수성은 CSS2 사양에 따라 다음과 같이 정의됩니다.
- 선언이 선택기가 있는 규칙이 아닌 '스타일' 속성인 경우 1을, 그렇지 않은 경우에는 0을 계산합니다 (= a).
- 선택기에서 ID 속성의 개수를 셉니다 (= b).
- 선택기에서 다른 속성과 가상 클래스의 개수를 셉니다 (= c).
- 선택기에서 요소 이름 및 가상 요소의 개수를 계산합니다 (= d).
큰 밑수가 있는 숫자 체계에서 a-b-c-d 4개의 숫자를 연결하면 고유성이 생깁니다.
사용해야 하는 숫자 밑자는 카테고리 중 하나에 있는 가장 높은 개수로 정의됩니다.
예를 들어 a=14인 경우 16진수 기초를 사용할 수 있습니다. a=17인 경우는 거의 없지만 17자리 숫자 기반이 필요합니다. 후자의 상황은 다음과 같은 선택기로 발생할 수 있습니다. html body div div p… (선택기에 17개의 태그가 있음… 가능성 매우 낮음).
예를 들면 다음과 같습니다.
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
규칙 정렬
규칙이 일치하면 계단식 규칙에 따라 정렬됩니다.
WebKit은 작은 목록에는 버블 정렬을 사용하고 큰 목록에는 병합 정렬을 사용합니다.
WebKit은 규칙의 > 연산자를 재정의하여 정렬을 구현합니다.
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
점진적 절차
WebKit은 모든 최상위 스타일 시트(@imports 포함)가 로드되었는지 표시하는 플래그를 사용합니다. 연결 시 스타일이 완전히 로드되지 않으면 자리표시자가 사용되고 문서에 표시되며 스타일 시트가 로드되면 다시 계산됩니다.
레이아웃
렌더러가 생성되고 트리에 추가되면 위치와 크기가 없습니다. 이러한 값을 계산하는 것을 레이아웃 또는 리플로라고 합니다.
HTML은 흐름 기반 레이아웃 모델을 사용하므로 대부분의 경우 단일 패스에서 도형을 계산할 수 있습니다. '흐름'에서 나중에 나오는 요소는 일반적으로 '흐름'에서 먼저 나오는 요소의 도형에 영향을 미치지 않으므로 레이아웃은 문서를 통해 왼쪽에서 오른쪽, 위에서 아래로 진행될 수 있습니다. 예외가 있습니다. 예를 들어 HTML 테이블에는 두 번 이상의 패스가 필요할 수 있습니다.
좌표계는 루트 프레임을 기준으로 합니다. 상단 및 왼쪽 좌표가 사용됩니다.
레이아웃은 재귀 프로세스입니다. 렌더링은 HTML 문서의 <html> 요소에 해당하는 루트 렌더러에서 시작됩니다. 레이아웃은 프레임 계층 구조의 일부 또는 전체를 재귀적으로 계속해서 거치면서 필요한 각 렌더러의 기하학적 정보를 계산합니다.
루트 렌더러의 위치는 0,0이고 크기는 브라우저 창의 표시되는 부분인 뷰포트입니다.
모든 렌더러에는 'layout' 또는 'reflow' 메서드가 있으며, 각 렌더러는 레이아웃이 필요한 하위 요소의 레이아웃 메서드를 호출합니다.
더티 비트 시스템
브라우저는 사소한 변경사항이 있을 때마다 전체 레이아웃을 실행하지 않기 위해 '더티 비트' 시스템을 사용합니다. 변경되거나 추가된 렌더러는 자체와 하위 요소를 '더티'(더러운 상태)로 표시하여 레이아웃이 필요하다고 합니다.
'dirty' 및 'children are dirty'라는 두 가지 플래그가 있습니다. 이는 렌더러 자체는 문제가 없지만 레이아웃이 필요한 하위 요소가 하나 이상 있음을 의미합니다.
전역 및 증분 레이아웃
레이아웃은 전체 렌더링 트리에서 트리거될 수 있습니다. 이를 '전역' 레이아웃이라고 합니다. 다음과 같은 이유로 이 문제가 발생할 수 있습니다.
- 글꼴 크기 변경과 같이 모든 렌더러에 영향을 미치는 전역 스타일 변경입니다.
- 화면 크기가 조절된 결과
레이아웃은 점진적일 수 있으며 더러운 렌더러만 레이아웃됩니다. 이로 인해 추가 레이아웃이 필요한 손상이 발생할 수 있습니다.
증분 레이아웃은 렌더러가 더러워질 때 비동기식으로 트리거됩니다. 예를 들어 추가 콘텐츠가 네트워크에서 가져와 DOM 트리에 추가된 후 새 렌더러가 렌더링 트리에 추가되는 경우입니다.
비동기 및 동기 레이아웃
증분 레이아웃은 비동기식으로 실행됩니다. Firefox는 증분 레이아웃을 위한 '리플로 명령어'를 큐에 추가하고 스케줄러는 이러한 명령어의 일괄 실행을 트리거합니다. WebKit에는 증분 레이아웃을 실행하는 타이머도 있습니다. 트리가 탐색되고 '더러운' 렌더러가 레이아웃됩니다.
'offsetHeight'와 같이 스타일 정보를 요청하는 스크립트는 동기식으로 증분 레이아웃을 트리거할 수 있습니다.
전역 레이아웃은 일반적으로 동기식으로 트리거됩니다.
스크롤 위치와 같은 일부 속성이 변경되어 초기 레이아웃 후 레이아웃이 콜백으로 트리거되는 경우가 있습니다.
최적화
레이아웃이 '크기 조절' 또는 렌더러 위치 변경(크기가 아님)으로 트리거되면 렌더링 크기가 캐시에서 가져와 재계산되지 않습니다.
하위 트리만 수정되고 레이아웃이 루트에서 시작되지 않는 경우도 있습니다. 이는 변경사항이 로컬이고 주변에 영향을 미치지 않는 경우에 발생할 수 있습니다 (예: 텍스트 필드에 삽입된 텍스트). 그렇지 않으면 모든 키 입력이 루트에서 시작하는 레이아웃을 트리거합니다.
레이아웃 프로세스
레이아웃은 일반적으로 다음과 같은 패턴을 따릅니다.
- 상위 렌더러가 자체 너비를 결정합니다.
- 부모가 자녀를 살펴보고 다음을 실행합니다.
- 하위 렌더러를 배치합니다 (x 및 y 설정).
- 필요한 경우 하위 레이아웃을 호출합니다. 하위 레이아웃이 더티하거나 전역 레이아웃에 있거나 다른 이유로 하위 레이아웃을 호출하면 하위 요소의 높이가 계산됩니다.
- 상위 요소는 하위 요소의 누적 높이와 여백 및 패딩의 높이를 사용하여 자체 높이를 설정합니다. 이 높이는 상위 렌더러의 상위 요소에서 사용됩니다.
- 더티 비트를 false로 설정합니다.
Firefox는 '상태' 객체(nsHTMLReflowState)를 레이아웃('리플로'라고 함) 매개변수로 사용합니다. 상태에는 상위 요소의 너비가 포함됩니다.
Firefox 레이아웃의 출력은 '측정항목' 객체(nsHTMLReflowMetrics)입니다. 여기에는 렌더러에서 계산된 높이가 포함됩니다.
너비 계산
렌더러의 너비는 컨테이너 블록의 너비, 렌더러의 스타일 '너비' 속성, 여백, 테두리를 사용하여 계산됩니다.
예를 들어 다음 div의 너비를 가져올 수 있습니다.
<div style="width: 30%"/>
WebKit에서 다음과 같이 계산됩니다(RenderBox 클래스 calcWidth 메서드).
- 컨테이너 너비는 컨테이너 availableWidth와 0 중 최대값입니다. 이 경우 availableWidth는 contentWidth이며 다음과 같이 계산됩니다.
clientWidth() - paddingLeft() - paddingRight()
clientWidth 및 clientHeight는 테두리와 스크롤바를 제외한 객체 내부를 나타냅니다.
요소 너비는 'width' 스타일 속성입니다. 컨테이너 너비의 백분율을 계산하여 절대값으로 계산됩니다.
이제 가로 테두리와 패딩이 추가되었습니다.
지금까지는 '선호하는 너비'를 계산했습니다. 이제 최소 및 최대 너비가 계산됩니다.
선호하는 너비가 최대 너비보다 큰 경우 최대 너비가 사용됩니다. 최소 너비 (가장 작은 깨지지 않는 단위)보다 작은 경우 최소 너비가 사용됩니다.
레이아웃이 필요한 경우 값이 캐시되지만 너비는 변경되지 않습니다.
줄바꿈
레이아웃 중간에 있는 렌더러가 중단해야 한다고 결정하면 렌더러가 중지되고 레이아웃의 상위 요소에 중단해야 한다고 전파합니다. 상위 요소는 추가 렌더러를 만들고 렌더러에서 레이아웃을 호출합니다.
회화
페인팅 단계에서는 렌더링 트리가 탐색되고 렌더러의 'paint()' 메서드가 호출되어 화면에 콘텐츠가 표시됩니다. 페인팅은 UI 인프라 구성요소를 사용합니다.
전역 및 증분
레이아웃과 마찬가지로 페인팅도 전역(전체 트리가 페인팅됨) 또는 증분일 수 있습니다. 증분 페인팅에서는 일부 렌더러가 전체 트리에 영향을 주지 않는 방식으로 변경됩니다. 변경된 렌더러는 화면의 직사각형을 무효화합니다. 그러면 OS에서 이를 '더티 영역'으로 인식하고 '페인트' 이벤트를 생성합니다. OS는 이를 영리하게 처리하여 여러 영역을 하나로 병합합니다. Chrome에서는 렌더러가 기본 프로세스와 다른 프로세스에 있으므로 더 복잡합니다. Chrome은 어느 정도 OS 동작을 시뮬레이션합니다. 프레젠테이션은 이러한 이벤트를 수신 대기하고 메시지를 렌더링 루트에 위임합니다. 관련 렌더러에 도달할 때까지 트리가 탐색됩니다. 자체적으로 다시 칠하고 일반적으로 하위 요소도 다시 칠합니다.
그림 순서
CSS2는 페인팅 프로세스의 순서를 정의합니다. 이는 실제로 비중 맥락에서 요소가 쌓이는 순서입니다. 이 순서는 비슷한 항목이 뒤에서 앞으로 칠해지므로 페인팅에 영향을 미칩니다. 블록 렌더러의 스택 순서는 다음과 같습니다.
- background color
- 배경 이미지
- border
- 어린이
- 개요
Firefox 표시 목록
Firefox는 렌더링 트리를 살펴보고 그려진 직사각형의 디스플레이 목록을 빌드합니다. 직사각형과 관련된 렌더러가 올바른 페인팅 순서 (렌더러의 배경, 테두리 등)로 포함되어 있습니다.
이렇게 하면 모든 배경을 그린 다음 모든 이미지를 그린 다음 모든 테두리를 그리는 등 여러 번이 아니라 한 번만 트리를 탐색하여 다시 칠하면 됩니다.
Firefox는 다른 불투명 요소 아래에 완전히 있는 요소와 같이 숨겨질 요소를 추가하지 않음으로써 프로세스를 최적화합니다.
WebKit 직사각형 저장소
WebKit은 다시 그리기 전에 이전 직사각형을 비트맵으로 저장합니다. 그런 다음 새 직사각형과 이전 직사각형 간의 델타만 그립니다.
동적 변경사항
브라우저는 변경사항에 대응하여 가능한 한 최소한의 작업을 시도합니다. 따라서 요소의 색상을 변경하면 요소가 다시만들기만 됩니다. 요소 위치를 변경하면 요소, 하위 요소, 경우에 따라 형제 요소의 레이아웃과 다시 칠하기가 발생합니다. DOM 노드를 추가하면 노드가 레이아웃되고 다시 그려집니다. 'html' 요소의 글꼴 크기를 늘리는 것과 같은 큰 변경사항은 캐시 무효화, 전체 트리의 레이아웃 재설정, 다시 칠하기를 일으킵니다.
렌더링 엔진의 스레드
렌더링 엔진은 단일 스레드입니다. 네트워크 작업을 제외한 거의 모든 작업이 단일 스레드에서 실행됩니다. Firefox 및 Safari에서는 브라우저의 기본 스레드입니다. Chrome에서는 탭 프로세스 기본 스레드입니다.
네트워크 작업은 여러 병렬 스레드에서 실행할 수 있습니다. 동시 연결 수는 제한적입니다 (일반적으로 2~6개 연결).
이벤트 루프
브라우저 기본 스레드는 이벤트 루프입니다. 프로세스를 계속 실행하는 무한 루프입니다. 레이아웃 및 페인트 이벤트와 같은 이벤트를 기다렸다가 처리합니다. 다음은 기본 이벤트 루프의 Firefox 코드입니다.
while (!mExiting)
NS_ProcessNextEvent(thread);
CSS2 시각적 모델
캔버스
CSS2 사양에 따르면 캔버스라는 용어는 '서식 구조가 렌더링되는 공간', 즉 브라우저가 콘텐츠를 그리는 위치를 나타냅니다.
캔버스는 공간의 각 측정기준에 대해 무한하지만 브라우저는 표시 영역의 크기를 기반으로 초기 너비를 선택합니다.
www.w3.org/TR/CSS2/zindex.html에 따르면 캔버스는 다른 캔버스 내에 포함된 경우 투명하고 포함되지 않은 경우에는 브라우저에서 정의한 색상이 지정됩니다.
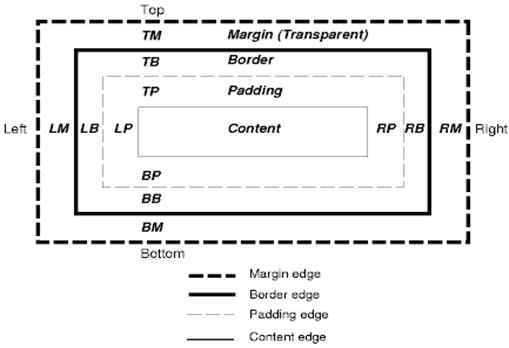
CSS 상자 모델
CSS 상자 모델은 문서 트리의 요소에 대해 생성되고 시각적 형식 지정 모델에 따라 배치되는 직사각형 상자를 설명합니다.
각 상자에는 콘텐츠 영역 (예: 텍스트, 이미지 등)과 선택적으로 주변 패딩, 테두리, 여백 영역이 있습니다.
각 노드는 이러한 상자를 0~n개 생성합니다.
모든 요소에는 생성될 상자의 유형을 결정하는 'display' 속성이 있습니다.
예:
block: generates a block box.
inline: generates one or more inline boxes.
none: no box is generated.
기본값은 인라인이지만 브라우저 스타일 시트에서 다른 기본값을 설정할 수 있습니다. 예를 들어 'div' 요소의 기본 디스플레이는 블록입니다.
기본 스타일 시트 예는 www.w3.org/TR/CSS2/sample.html에서 확인할 수 있습니다.
포지셔닝 스키마
다음과 같은 세 가지 스키마가 있습니다.
- 일반: 객체가 문서의 위치에 따라 배치됩니다. 즉, 렌더링 트리의 위치는 DOM 트리의 위치와 같으며 상자 유형 및 크기에 따라 배치됩니다.
- 플로팅: 객체가 먼저 일반 흐름처럼 배치된 다음 최대한 왼쪽 또는 오른쪽으로 이동합니다.
- 절대: 객체가 DOM 트리와 다른 위치의 렌더링 트리에 배치됩니다.
배치 스키마는 '위치' 속성과 '플로팅' 속성으로 설정됩니다.
- static 및 relative는 정상적인 흐름을 유발합니다.
- absolute 및 fixed로 인해 절대 위치 지정이 발생함
정적 위치 지정에서는 위치가 정의되지 않으며 기본 위치 지정이 사용됩니다. 다른 스키마에서는 작성자가 위치(상단, 하단, 왼쪽, 오른쪽)를 지정합니다.
상자의 레이아웃은 다음에 따라 결정됩니다.
- 상자 유형
- 상자 크기
- 포지셔닝 스키마
- 이미지 크기, 화면 크기와 같은 외부 정보
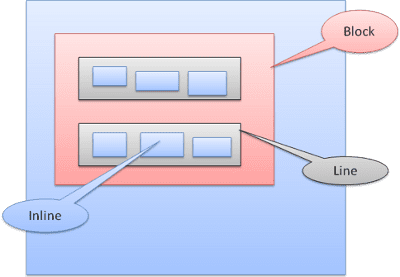
상자 유형
블록 상자: 블록을 형성합니다. 브라우저 창에 자체 직사각형이 있습니다.

인라인 상자: 자체 블록이 없지만 포함 블록 내에 있습니다.
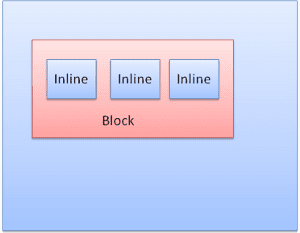
블록은 세로로 차례로 형식이 지정됩니다. 인라인은 가로로 형식이 지정됩니다.
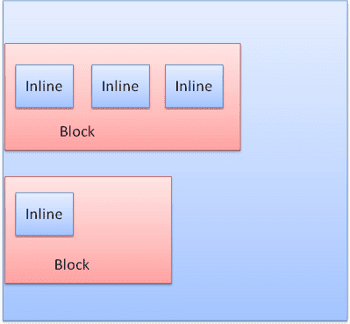
인라인 상자는 선 또는 '선 상자' 내에 배치됩니다. 선은 가장 높은 상자만큼은 되지만 상자가 '기준선'에 정렬된 경우 더 높을 수 있습니다. 즉, 요소의 하단 부분이 하단이 아닌 다른 상자의 지점에 정렬됩니다. 컨테이너 너비가 충분하지 않으면 인라인이 여러 줄에 표시됩니다. 일반적으로 한 단락에서 이러한 일이 발생합니다.
포지셔닝
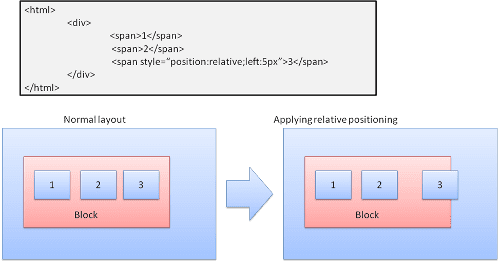
상대적
상대적 위치 지정 - 평소와 같이 배치된 후 필요한 델타만큼 이동합니다.
부동
플로팅 상자가 선의 왼쪽 또는 오른쪽으로 이동합니다. 흥미로운 점은 다른 상자가 그 주위를 흐른다는 것입니다. HTML:
<p>
<img style="float: right" src="images/image.gif" width="100" height="100">
Lorem ipsum dolor sit amet, consectetuer...
</p>
다음과 같이 표시됩니다.

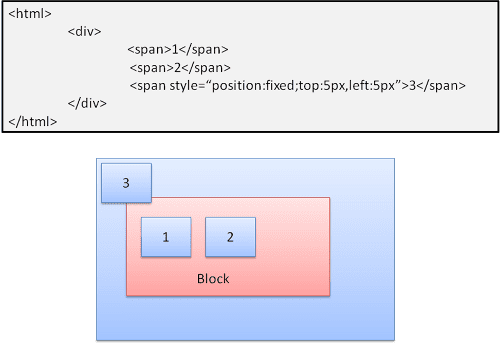
절대 및 고정
레이아웃은 일반 흐름과 관계없이 정확하게 정의됩니다. 요소가 일반 흐름에 참여하지 않습니다. 크기는 컨테이너를 기준으로 합니다. 고정된 경우 컨테이너가 표시 영역입니다.
계층화된 표현
이는 z-index CSS 속성으로 지정됩니다. 상자의 세 번째 측정기준인 'z축'을 따라의 위치를 나타냅니다.
상자는 스택 (비슷한 이미지를 쌓는 컨텍스트라고 함)으로 나뉩니다. 각 스택에서 뒤쪽 요소가 먼저 페인트되고 앞으로의 요소가 맨 위에 표시되어 사용자에게 더 가깝습니다. 겹치는 경우 가장 앞의 요소가 이전 요소를 숨깁니다.
스택은 z-index 속성에 따라 정렬됩니다. 'z-index' 속성이 있는 상자는 로컬 스택을 형성합니다. 뷰포트에 외부 스택이 있습니다.
예:
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
결과는 다음과 같습니다.

빨간색 div가 마크업에서 녹색 div보다 먼저 표시되고 일반 흐름에서 먼저 페인트되었지만 z-index 속성이 더 높으므로 루트 상자에 보관된 스택에서 더 앞에 있습니다.
리소스
브라우저 아키텍처
- 그로스커스, 앨런 웹브라우저용 참조 아키텍처 (pdf)
- 굽타, 비니트 브라우저 작동 방식 - 파트 1 - 아키텍처
파싱
- Aho, Sethi, Ullman, 컴파일러: 원리, 기법, 도구('드래곤 책'이라고도 함), Addison-Wesley, 1986
- 릭 젤리프 The Bold and the Beautiful: HTML 5의 두 가지 새로운 초안
Firefox
- L. 데이비드 바론, 더 빠른 HTML 및 CSS: 웹 개발자를 위한 레이아웃 엔진 내부
- L. 데이비드 바론, 더 빠른 HTML 및 CSS: 웹 개발자를 위한 레이아웃 엔진 내부 (Google 기술 토크 동영상)
- L. 데이비드 바론, Mozilla의 레이아웃 엔진
- L. 데이비드 바론, Mozilla 스타일 시스템 문서
- 크리스 워터슨, HTML 리플로에 관한 메모
- 크리스 워터슨, Gecko 개요
- 알렉산더 라르손, HTML HTTP 요청의 수명
WebKit
- 데이비드 하이얏트, CSS 구현(1부)
- 데이비드 하이얏트, WebCore 개요
- 데이비드 하얏트, WebCore 렌더링
- 데이비드 하이얏트, FOUC 문제
W3C 사양
브라우저 빌드 안내
번역
이 페이지는 일본어로 두 번 번역되었습니다.
- 브라우저 작동 방식 - 최신 웹브라우저의 내부 작동 방식 (ja) @kosei 작성
- ブラウザってどうやって動いてるの?@ikeike443 및 @kiyoto01의 (モダンWEBブラウザシーンの裏側
한국어 및 튀르키예어의 외부 호스팅 번역을 확인할 수 있습니다.
감사합니다.