
最新のウェブブラウザの舞台裏


序文
WebKit と Gecko の内部動作に関するこの包括的な入門書は、イスラエルのデベロッパー Tali Garsiel による多くの調査の結果です。数年にわたって、ブラウザ内部に関する公開されているデータをすべて確認し、ウェブブラウザのソースコードを読み込むことに多くの時間を費やしました。彼女は次のように書いています。
ウェブ デベロッパーにとって、ブラウザの動作の内部を学ぶことは、より適切な意思決定を行い、開発のベスト プラクティスの根拠を理解するのに役立ちます。このドキュメントは長いですが、時間をかけてよく読んでいただくことをおすすめします。やって良かったと思えるはずです。
Paul Irish、Chrome デベロッパー リレーションズ
はじめに
ウェブブラウザは最も広く使用されているソフトウェアです。このプリマーでは、これらの機能がどのように動作するかについて説明します。ブラウザの画面に Google ページが表示されるまで、アドレスバーに google.com と入力するとどうなるかを確認します。
説明するブラウザ
現在、デスクトップで使用されている主要なブラウザは 5 つあります。Chrome、Internet Explorer、Firefox、Safari、Opera です。モバイルでは、主なブラウザは Android ブラウザ、iPhone、Opera Mini、Opera Mobile、UC ブラウザ、Nokia S40/S60 ブラウザ、Chrome です。Opera ブラウザを除くすべてのブラウザは WebKit をベースにしています。ここでは、オープンソース ブラウザの Firefox、Chrome、Safari(一部オープンソース)の例を挙げます。StatCounter の統計情報(2013 年 6 月時点)によると、Chrome、Firefox、Safari は、世界中のデスクトップ ブラウザの使用率の約 71% を占めています。モバイルでは、Android ブラウザ、iPhone、Chrome が使用頻度の 54% を占めています。
ブラウザの主な機能
ブラウザの主な機能は、選択したウェブリソースをサーバーからリクエストし、ブラウザ ウィンドウに表示することです。リソースは通常 HTML ドキュメントですが、PDF、画像、その他の種類のコンテンツにすることもできます。リソースのロケーションは、URI(Uniform Resource Identifier)を使用してユーザーが指定します。
ブラウザが HTML ファイルを解釈して表示する方法は、HTML 仕様と CSS 仕様で指定されています。これらの仕様は、ウェブの標準化団体である W3C(World Wide Web Consortium)によって管理されています。長年にわたり、ブラウザは仕様の一部にのみ準拠し、独自の拡張機能を開発してきました。これにより、ウェブ作成者にとって深刻な互換性の問題が発生しました。現在、ほとんどのブラウザは、多かれ少なかれ仕様に準拠しています。
ブラウザのユーザー インターフェースは、互いに多くの共通点があります。一般的なユーザー インターフェース要素には次のようなものがあります。
- URI を挿入するためのアドレスバー
- 戻るボタンと進むボタン
- ブックマークのオプション
- 現在のドキュメントの更新または読み込みの停止を行う更新ボタンと停止ボタン
- ホームページに移動するホームボタン
奇妙なことに、ブラウザのユーザー インターフェースは正式な仕様で指定されていません。長年の経験から形成されたベスト プラクティスと、ブラウザ同士の模倣によって作られたものです。HTML5 仕様では、ブラウザに必須の UI 要素は定義されていませんが、一般的な要素がいくつかリストされています。アドレスバー、ステータスバー、ツールバーなどです。もちろん、Firefox のダウンロード マネージャーなど、特定のブラウザに固有の機能もあります。
上位インフラストラクチャ
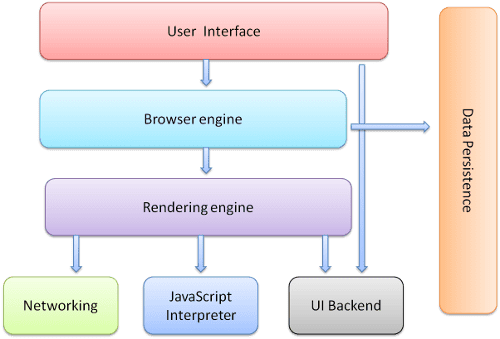
ブラウザの主なコンポーネントは次のとおりです。
- ユーザー インターフェース: アドレスバー、戻る/進むボタン、ブックマーク メニューなど。リクエストされたページが表示されるウィンドウを除く、ブラウザのディスプレイのすべての部分。
- ブラウザ エンジン: UI とレンダリング エンジンの間でアクションをマーシャリングします。
- レンダリング エンジン: リクエストされたコンテンツの表示を担当します。たとえば、リクエストされたコンテンツが HTML の場合、レンダリング エンジンは HTML と CSS を解析し、解析されたコンテンツを画面に表示します。
- ネットワーキング: HTTP リクエストなどのネットワーク呼び出しの場合、プラットフォームに依存しないインターフェースの背後で、プラットフォームごとに異なる実装を使用します。
- UI バックエンド: コンボボックスやウィンドウなどの基本的なウィジェットの描画に使用されます。このバックエンドは、プラットフォームに依存しない汎用インターフェースを公開します。内部では、オペレーティング システムのユーザー インターフェース メソッドを使用します。
- JavaScript インタープリタ。JavaScript コードの解析と実行に使用されます。
- データ ストレージ。これは永続レイヤです。ブラウザでは、Cookie など、さまざまなデータをローカルに保存する必要がある場合があります。ブラウザは、localStorage、IndexedDB、WebSQL、FileSystem などのストレージ メカニズムもサポートしています。
Chrome などのブラウザでは、レンダリング エンジンの複数のインスタンスがタブごとに実行されます。各タブは個別のプロセスで実行されます。
レンダリング エンジン
レンダリング エンジンの役割は、レンダリングです。つまり、リクエストされたコンテンツをブラウザの画面に表示します。
デフォルトでは、レンダリング エンジンは HTML ドキュメント、XML ドキュメント、画像を表示できます。プラグインや拡張機能を使用して、他の種類のデータを表示することもできます。たとえば、PDF ビューア プラグインを使用して PDF ドキュメントを表示できます。しかし、この章では、CSS を使用してフォーマットされた HTML と画像を表示するという主なユースケースに焦点を当てます。
ブラウザによってレンダリング エンジンが異なります。Internet Explorer は Trident、Firefox は Gecko、Safari は WebKit を使用します。Chrome と Opera(バージョン 15 以降)は、WebKit のフォークである Blink を使用しています。
WebKit はオープンソースのレンダリング エンジンです。Linux プラットフォーム用のエンジンとして始まり、Mac と Windows をサポートするように Apple によって変更されました。
メインフロー
レンダリング エンジンは、リクエストされたドキュメントの内容をネットワーキング レイヤから取得します。これは通常、8 kB のチャンクで行われます。
レンダリング エンジンの基本的な流れは次のとおりです。

レンダリング エンジンは HTML ドキュメントの解析を開始し、要素を「コンテンツ ツリー」と呼ばれるツリー内の DOM ノードに変換します。エンジンは、外部 CSS ファイルとスタイル要素の両方でスタイルデータを解析します。スタイル情報と HTML の視覚的な指示を使用して、別のツリー(レンダリング ツリー)が作成されます。
レンダリング ツリーには、色やサイズなどの視覚的属性を持つ長方形が含まれています。長方形が画面に表示される正しい順序になっています。
レンダリング ツリーが構築されると、レイアウト プロセスに進みます。つまり、各ノードに、画面上に表示する正確な座標を指定します。次のステージはペイントです。レンダリング ツリーが走査され、各ノードが UI バックエンド レイヤを使用してペイントされます。
これは段階的なプロセスであることを理解することが重要です。ユーザー エクスペリエンスを向上させるため、レンダリング エンジンはできる限り早くコンテンツを画面に表示しようとします。すべての HTML が解析されるまで待機せずに、レンダリング ツリーの構築とレイアウトを開始します。コンテンツの一部が解析されて表示され、ネットワークから送信され続ける残りのコンテンツでプロセスが続行されます。
メインフローの例
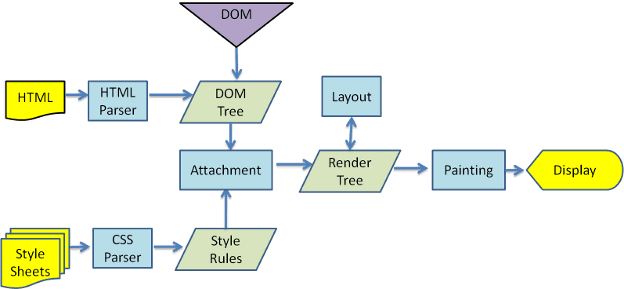
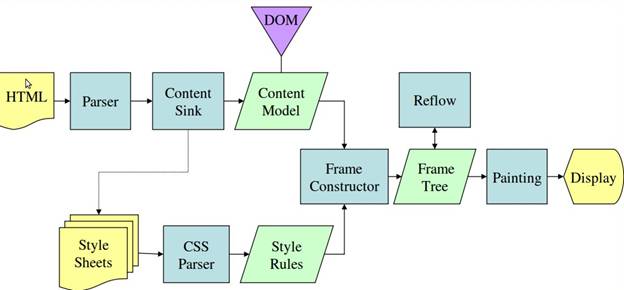
図 3 と図 4 からわかるように、WebKit と Gecko では用語が若干異なりますが、フローは基本的に同じです。
Gecko では、視覚的にフォーマットされた要素のツリーを「フレームツリー」と呼びます。各要素はフレームです。WebKit では「レンダリング ツリー」という用語が使用され、これは「レンダリング オブジェクト」で構成されています。WebKit では要素の配置に「レイアウト」という用語が使用されますが、Gecko では「再フロウ」と呼ばれます。「アタッチメント」は、DOM ノードと視覚情報を接続してレンダリング ツリーを作成する WebKit の用語です。セマンティクス以外の小さな違いとして、Gecko には HTML と DOM ツリーの間に追加のレイヤがあることが挙げられます。これは「コンテンツ シンク」と呼ばれ、DOM 要素を作成するファクトリです。フローについて、各部分を説明します。
解析 - 全般
パースはレンダリング エンジン内の非常に重要なプロセスであるため、もう少し詳しく説明します。まず、パースについて簡単に説明します。
ドキュメントを解析するということは、コードで使用できる構造に変換することを意味します。通常、解析の結果は、ドキュメントの構造を表すノードのツリーです。これは、構文木または構文ツリーと呼ばれます。
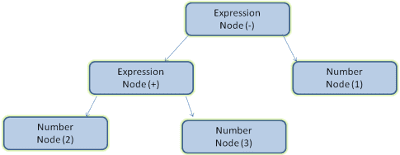
たとえば、式 2 + 3 - 1 を解析すると、次のようなツリーが返されます。
文法
解析は、ドキュメントが従う構文ルール(ドキュメントが記述されている言語または形式)に基づいて行われます。解析できる形式にはすべて、語彙と構文ルールで構成される確定的文法が必要です。これは文脈自由文法と呼ばれます。人間の言語はそのような言語ではないため、従来の解析手法では解析できません。
パーサー - レキサーの組み合わせ
解析は、形態素解析と構文解析の 2 つのサブプロセスに分割できます。
字句分析は、入力をトークンに分割するプロセスです。トークンは言語の語彙であり、有効な構成要素の集合です。人間の言語では、その言語の辞書に記載されているすべての単語で構成されます。
構文解析とは、言語の構文規則を適用することです。
通常、パーサーは、入力を有効なトークンに分割する レキサー(トークン化ツールと呼ばれることもあります)と、言語の構文ルールに従ってドキュメント構造を分析してパースツリーを構築する パーサーの 2 つのコンポーネントに作業を分割します。
レキサーは、空白文字や改行などの無関係な文字を取り除く方法を認識しています。
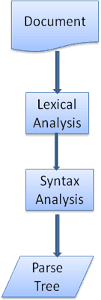
解析プロセスは反復的です。通常、パーサーは新しいトークンをレキサーに要求し、トークンをいずれかの構文ルールと照合しようとします。ルールが一致すると、トークンに相当するノードが解析ツリーに追加され、パーサーは別のトークンを要求します。
一致するルールがない場合、パーサーはトークンを内部に保存し、内部に保存されているすべてのトークンに一致するルールが見つかるまでトークンを要求し続けます。ルールが見つからない場合、パーサーは例外をスローします。つまり、ドキュメントが無効で、構文エラーが含まれていることを意味します。
翻訳
多くの場合、パースツリーは最終的なプロダクトではありません。解析は、入力ドキュメントを別の形式に変換する翻訳でよく使用されます。コンパイルがその一例です。ソースコードをマシンコードにコンパイルするコンパイラは、まずソースコードを解析して解析ツリーに変換し、次にそのツリーをマシンコード ドキュメントに変換します。
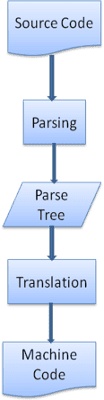
解析の例
図 5 では、数式から構文解析ツリーを構築しています。簡単な数学言語を定義して、解析プロセスを見てみましょう。
構文:
- 言語構文の構成要素は、式、項、演算です。
- 言語には任意の数の式を含めることができます。
- 式は、「項」の後に「演算子」の後に別の「項」が続くものとして定義されます。
- オペレーションがプラストークンまたはマイナストークンである
- 項は整数トークンまたは式です。
入力 2 + 3 - 1 を分析しましょう。
ルールに一致する最初の部分文字列は 2 です。ルール 5 によると、これは語句です。2 番目の一致は 2 + 3 です。これは、3 番目のルール(演算子に続く項に続く別の項)に一致します。次の一致は、入力の最後でのみヒットします。2 + 3 - 1 は式です。2 + 3 が項であることはすでにわかっています。つまり、項の後に演算子、さらに別の項が続いています。2 + + はどのルールにも一致しないため、無効な入力です。
語彙と構文の正式な定義
語彙は通常、正規表現で表されます。
たとえば、言語は次のように定義されます。
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -
ご覧のとおり、整数は正規表現で定義されています。
構文は通常、BNF という形式で定義されます。使用できる言語は次のとおりです。
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
文法がコンテキスト自由文法であれば、その言語は正規パーサーで解析できると述べました。コンテキスト自由文法の直感的な定義は、BNF で完全に表現できる文法です。正式な定義については、Wikipedia の文脈自由文法に関する記事をご覧ください。
パーサーの種類
パーサーには、トップダウン パーサーとボトムアップ パーサーの 2 種類があります。直感的な説明としては、トップダウン パーサーは構文の上位レベルの構造を調べて、ルールに一致するものを見つけようとします。ボトムアップ パーサーは、入力から始めて、下位レベルのルールから上位レベルのルールが満たされるまで、徐々に構文ルールに変換します。
2 種類のパーサーがこの例をどのように解析するかを見てみましょう。
トップダウン パーサーは上位レベルのルールから開始し、2 + 3 を式として識別します。次に、2 + 3 - 1 が式として識別されます(式の識別プロセスは、他のルールに合わせて進化しますが、開始点は最上位のルールです)。
ボトムアップ パーサーは、ルールが一致するまで入力をスキャンします。一致する入力がルールに置き換えられます。これは入力が終了するまで続きます。部分的に一致した式は、パーサーのスタックに配置されます。
このタイプのボトムアップ パーサーはシフト リデュース パーサーと呼ばれます。これは、入力が右にシフトされ(ポインタが最初に入力の開始を指して右に移動すると想像してください)、徐々に構文ルールにリデュースされるためです。
パーサーの自動生成
パーサーを生成できるツールがあります。言語の文法(語彙と構文ルール)を入力すると、動作するパーサーが生成されます。パーサーの作成にはパースに関する深い理解が必要であり、最適化されたパーサーを手動で作成するのは簡単ではないため、パーサー ジェネレータは非常に便利です。
WebKit では、2 つのよく知られたパーサー ジェネレータを使用しています。レキサを作成するための Flex と、パーサーを作成するための Bison です(Lex と Yacc という名前で使用されることもあります)。Flex 入力は、トークンの正規表現定義を含むファイルです。Bison の入力は、BNF 形式の言語構文ルールです。
HTML パーサー
HTML パーサーは、HTML マークアップを解析して解析ツリーに変換します。
HTML の文法
HTML の語彙と構文は、W3C 組織によって作成された仕様で定義されています。
解析の概要で説明したように、文法構文は BNF などの形式を使用して正式に定義できます。
残念ながら、従来のパーサーのトピックはすべて HTML には適用されません(CSS と JavaScript の解析で使用されるため、あえて取り上げました)。HTML は、パーサーに必要なコンテキストフリー グラマーで簡単に定義することはできません。
HTML を定義するための正式な形式(DTD(ドキュメント タイプ定義))はありますが、これはコンテキスト自由文法ではありません。
これは一見奇妙に思えます。HTML は XML にかなり近い言語です。利用可能な XML パーサーは多数あります。HTML には XML のバリエーションである XHTML がありますが、大きな違いは何ですか?
違いは、HTML アプローチの方が「寛容」である点です。HTML では、特定のタグを省略したり(省略されたタグは暗黙的に追加されます)、開始タグや終了タグを省略したりできます。全体的に、XML の厳格で厳しい構文とは対照的に、「柔らかい」構文です。
一見小さな違いでも、大きな違いを生む可能性があります。一方で、HTML がこれほどまでに人気があるのは、間違いを許容し、ウェブ作成者の負担を軽減する点が主な理由です。一方で、形式的な文法を記述することは困難です。要約すると、HTML の文法はコンテキストフリーではないため、従来のパーサーでは簡単に解析できません。XML パーサーは HTML を解析できません。
HTML DTD
HTML 定義は DTD 形式です。この形式は、SGML ファミリーの言語を定義するために使用されます。このフォーマットには、使用可能なすべての要素、その属性、階層の定義が含まれています。前述のように、HTML DTD はコンテキスト自由文法ではありません。
DTD にはいくつかのバリエーションがあります。厳格モードは仕様にのみ準拠していますが、他のモードには、過去にブラウザで使用されていたマークアップがサポートされています。古いコンテンツとの下位互換性を維持することが目的です。現在の厳格な DTD は、www.w3.org/TR/html4/strict.dtd にあります。
DOM
出力ツリー(「解析ツリー」)は、DOM 要素と属性ノードのツリーです。DOM はドキュメント オブジェクト モデルの略です。これは、HTML ドキュメントのオブジェクト プレゼンテーションであり、HTML 要素と JavaScript などの外部とのインターフェースです。
ツリーのルートには「Document」オブジェクトがあります。
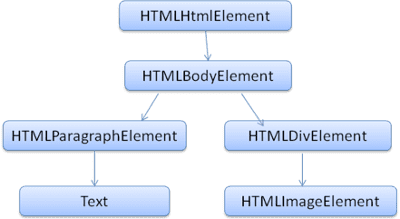
DOM はマークアップとほぼ 1 対 1 の関係にあります。次に例を示します。
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
このマークアップは、次の DOM ツリーに変換されます。
HTML と同様に、DOM は W3C 組織によって指定されています。www.w3.org/DOM/DOMTR をご覧ください。これは、ドキュメントを操作するための汎用仕様です。特定のモジュールは、HTML 固有の要素を記述します。HTML の定義については、www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html をご覧ください。
ツリーに DOM ノードが含まれているとは、ツリーが DOM インターフェースのいずれかを実装する要素で構成されていることを意味します。ブラウザは、ブラウザ内部で使用される他の属性を持つ具体的な実装を使用します。
解析アルゴリズム
前のセクションで説明したように、HTML は通常のトップダウン パーサーまたはボトムアップ パーサーを使用して解析できません。
その理由は次のとおりです。
- 言語の許容性。
- ブラウザには、無効な HTML の既知のケースをサポートするために、従来の許容エラーがあるという事実。
- 解析プロセスは再入可能で、他の言語では、ソースは解析中に変更されませんが、HTML では、動的コード(
document.write()呼び出しを含むスクリプト要素など)によって追加のトークンが追加されるため、解析プロセスで実際に入力が変更されます。
通常の解析手法を使用できないため、ブラウザは HTML を解析するためのカスタム パーサーを作成します。
解析アルゴリズムについては、HTML5 仕様で詳しく説明されています。このアルゴリズムは、トークン化とツリー構築の 2 つのステージで構成されています。
トークン化は、入力をトークンに解析する、形態素解析です。HTML トークンには、開始タグ、終了タグ、属性名、属性値があります。
トークン認識ツールはトークンを認識し、それをツリー コンストラクタに渡します。次に、次の文字を消費して次のトークンを認識し、入力の最後まで続けます。
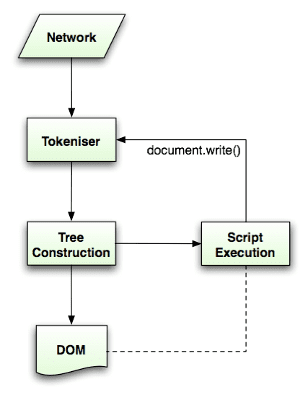
トークン化アルゴリズム
アルゴリズムの出力は HTML トークンです。アルゴリズムはステートマシンとして表現されます。各状態は、入力ストリームの 1 つ以上の文字を消費し、それらの文字に応じて次の状態を更新します。この決定は、現在のトークン化の状態とツリー構築の状態によって影響を受けます。つまり、同じ消費文字でも、現在の状態に応じて、正しい次の状態が異なる結果になります。このアルゴリズムは複雑すぎて詳細を説明できないため、原則を理解するために簡単な例を見てみましょう。
基本的な例 - 次の HTML をトークン化する
<html>
<body>
Hello world
</body>
</html>
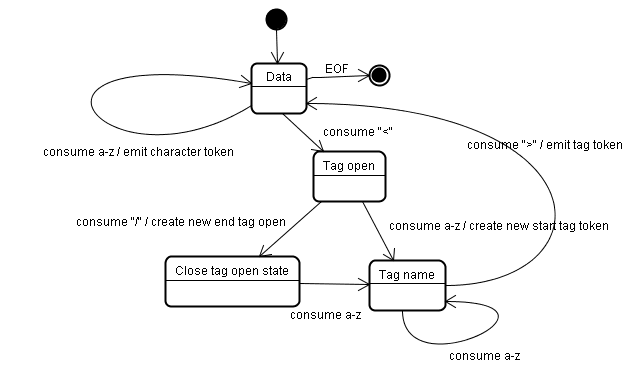
初期状態は「データ状態」です。< 文字が検出されると、状態は「タグオープン状態」に変更されます。a-z 文字を消費すると、「開始タグトークン」が作成され、状態が「タグ名の状態」に変更されます。> 文字が消費されるまで、この状態が維持されます。各文字が新しいトークン名に追加されます。この例では、作成されたトークンは html トークンです。
> タグに達すると、現在のトークンが出力され、状態は「データ状態」に戻ります。<body> タグは同じ手順で処理されます。これまでは、html タグと body タグが生成されていました。これで [データの状態] に戻りました。Hello world の H 文字を消費すると、文字トークンが作成されて出力されます。これは、</body> の < に達するまで続きます。Hello world の各文字に対して文字トークンが出力されます。
これで、「タグのオープン状態」に戻りました。次の入力 / を使用すると、end tag token が作成され、「タグ名の状態」に移動します。> に到達するまで、この状態が維持されます。その後、新しいタグトークンが出力され、「データ状態」に戻ります。</html> 入力は、前述のケースと同様に処理されます。
ツリー構築アルゴリズム
パーサーが作成されると、Document オブジェクトが作成されます。ツリー構築の段階で、Document がルートにある DOM ツリーが変更され、要素が追加されます。トークン化ツールによって出力された各ノードは、ツリー コンストラクタによって処理されます。トークンごとに、トークンに関連し、トークン用に作成される DOM 要素が仕様で定義されています。要素は DOM ツリーと、開いている要素のスタックに追加されます。このスタックは、ネストの不一致と閉じていないタグを修正するために使用されます。このアルゴリズムはステートマシンとしても記述されます。これらの状態は「挿入モード」と呼ばれます。
入力例のツリー構築プロセスを見てみましょう。
<html>
<body>
Hello world
</body>
</html>
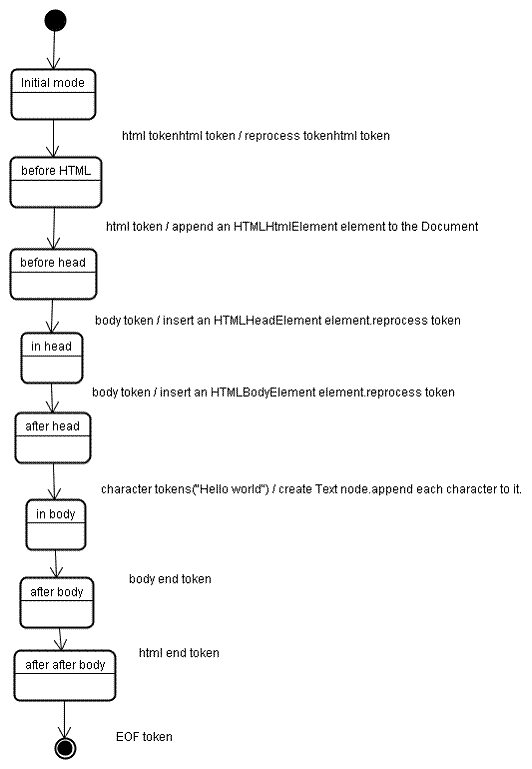
ツリー構築ステージへの入力は、トークン化ステージからの一連のトークンです。最初のモードは「初期モード」です。「html」トークンを受け取ると、「html 前」モードに移行し、そのモードでトークンが再処理されます。これにより、HTMLHtmlElement 要素が作成され、ルート Document オブジェクトに追加されます。
ステータスは 「before head」 に変更されます。その後、「body」トークンが受信されます。「head」トークンはありませんが、HTMLHeadElement が暗黙的に作成され、ツリーに追加されます。
次に、「頭上」モードに移行し、その後「頭後」モードに移行します。本文トークンが再処理され、HTMLBodyElement が作成されて挿入され、モードが「本文内」に移行されます。
「Hello world」文字列の文字トークンが受信されました。最初の文字は「Text」ノードが作成されて挿入され、他の文字はそのノードに追加されます。
本文終了トークンを受け取ると、「本文後」モードに移行します。html 終了タグが届き、「body の次」モードに移行します。ファイルの末尾トークンを受け取ると、解析が終了します。
解析が完了したときの対処
この段階で、ブラウザはドキュメントをインタラクティブとしてマークし、「遅延」モードのスクリプト(ドキュメントの解析後に実行されるスクリプト)の解析を開始します。ドキュメントの状態は「complete」に設定され、「load」イベントがトリガーされます。
トークン化とツリー構築の完全なアルゴリズムは、HTML5 仕様で確認できます。
ブラウザのエラー許容度
HTML ページで「無効な構文」エラーが発生することはありません。ブラウザは、無効なコンテンツを修正して処理を続行します。
次の HTML を例にしましょう。
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
100 万個ほどのルールに違反しているはずなのに(「mytag」は標準タグではない、"p" 要素と "div" 要素のネストがおかしいなど)、ブラウザは正しく表示し、エラーも発生しません。そのため、パーサーコードの多くは HTML 作成者の間違いを修正しています。
エラー処理はブラウザ間で非常に一貫していますが、驚くべきことに、HTML 仕様には含まれていません。ブックマークや [戻る] ボタン、[進む] ボタンと同様に、長年にわたってブラウザで開発されたものです。多くのサイトで繰り返し使用されている、既知の無効な HTML 構文があります。ブラウザは、他のブラウザに準拠した方法でこれらの問題を修正しようとします。
HTML5 仕様では、これらの要件の一部が定義されています。(WebKit では、HTML パーサー クラスの先頭のコメントでこのことが簡潔にまとめられています)。
パーサーは、トークン化された入力をドキュメントに解析し、ドキュメント ツリーを構築します。ドキュメントが適切に記述されている場合、解析は簡単です。
残念ながら、形式が適切でない HTML ドキュメントを多数処理する必要があるため、解析ツールはエラーに寛容である必要があります。
少なくとも次のエラー条件に対処する必要があります。
- 追加される要素は、一部の外側のタグ内で明示的に禁止されています。この場合は、要素を禁止するタグまですべてのタグを閉じてから、そのタグを追加する必要があります。
- 要素を直接追加することはできません。ドキュメントを作成した人が、その間にタグを忘れた(またはその間のタグが省略可能)可能性があります。たとえば、HTML HEAD BODY TBODY TR TD LI などのタグが該当します(他にもあるかもしれません)。
- インライン要素内にブロック要素を追加します。次の上位のブロック要素まで、すべてのインライン要素を閉じます。
- それでも問題が解決しない場合は、要素を追加できるようになるまで要素を閉じるか、タグを無視してください。
WebKit のエラー許容の例をいくつか見てみましょう。
</br>(<br> の代わりに使用)
一部のサイトでは、<br> ではなく </br> が使用されています。WebKit は IE と Firefox との互換性を確保するため、これを <br> のように扱います。
コード:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
エラー処理は内部的なものであり、ユーザーには表示されません。
迷子になったテーブル
迷子テーブルとは、別のテーブル内にあるテーブルで、テーブルセル内にあるテーブルではないものです。
次に例を示します。
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
WebKit は、階層を 2 つの兄弟テーブルに変更します。
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
コード:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
WebKit は現在の要素の内容にスタックを使用します。外側のテーブル スタックから内側のテーブルをポップします。テーブルは兄弟になります。
ネストされたフォーム要素
ユーザーがフォームを別のフォーム内に配置した場合、2 番目のフォームは無視されます。
コード:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
タグの階層が深すぎる
コメントの内容がすべてです。
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
html タグまたは body 終了タグの位置がずれている
コメントの内容がすべてを物語っています。
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
したがって、ウェブ作成者は、WebKit のエラー許容コード スニペットの例として掲載されたくない限り、適切に記述された HTML を作成してください。
CSS 解析
導入で説明したパースのコンセプトを覚えていますか?HTML とは異なり、CSS はコンテキストフリー グラマーであり、導入で説明したタイプのパーサーを使用して解析できます。実際、CSS 仕様では CSS の語彙と構文の文法が定義されています。
例をいくつか見てみましょう。
字句文法(語彙)は、各トークンの正規表現で定義されます。
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
「ident」は、クラス名などの識別子の略です。「name」は要素 ID(「#」で参照)です。
構文の文法は BNF で記述されています。
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
説明:
ルールセットの構造は次のとおりです。
div.error, a.error {
color:red;
font-weight:bold;
}
div.error と a.error はセレクタです。中かっこ内の部分には、このルールセットによって適用されるルールが含まれています。この構造は、次の定義で正式に定義されています。
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
つまり、ルールセットはセレクタ、またはカンマとスペースで区切られた複数のセレクタ(S は空白文字を表します)です。ルールセットには中かっこが含まれ、その中かっこの中に宣言が 1 つまたは複数(セミコロンで区切る)が含まれます。「宣言」と「セレクタ」は、次の BNF 定義で定義されます。
WebKit CSS パーサー
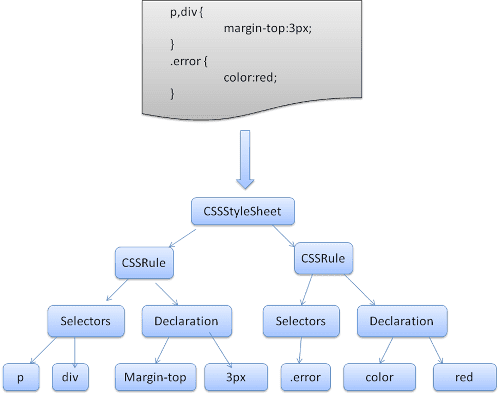
WebKit は、Flex と Bison のパーサ生成ツールを使用して、CSS 文法ファイルからパーサを自動的に作成します。パーサーの概要で説明したように、Bison はボトムアップの Shift-Reduce パーサーを作成します。Firefox では、手動で記述されたトップダウン パーサーが使用されます。どちらの場合も、各 CSS ファイルは StyleSheet オブジェクトに解析されます。各オブジェクトには CSS ルールが含まれています。CSS ルール オブジェクトには、セレクタ オブジェクト、宣言オブジェクト、CSS 構文に対応するその他のオブジェクトが含まれます。
スクリプトとスタイルシートの処理順序
スクリプト
ウェブのモデルは同期的です。作成者は、パーサーが <script> タグに到達すると、スクリプトが解析され、すぐに実行されることを想定しています。スクリプトが実行されるまで、ドキュメントの解析は停止します。スクリプトが外部にある場合は、まずネットワークからリソースを取得する必要があります。これも同期的に行われ、リソースが取得されるまで解析は停止します。これは長年にわたって使用されてきたモデルであり、HTML4 および 5 の仕様でも指定されています。作成者はスクリプトに「defer」属性を追加できます。この場合、ドキュメントの解析は停止されず、ドキュメントの解析後に実行されます。HTML5 では、スクリプトを非同期としてマークし、別のスレッドで解析および実行されるようにするオプションが追加されています。
推測的解析
WebKit と Firefox の両方でこの最適化が行われます。スクリプトの実行中に、別のスレッドがドキュメントの残りの部分を解析し、ネットワークから読み込む必要がある他のリソースを検出して読み込みます。これにより、リソースを並列接続で読み込み、全体的な速度を向上させることができます。注: 推測型パーサーは、外部スクリプト、スタイルシート、画像などの外部リソースへの参照のみを解析します。DOM ツリーは変更しません。これはメイン パーサーに任されます。
スタイルシート
一方、スタイルシートのモデルは異なります。概念的には、スタイルシートは DOM ツリーを変更しないため、スタイルシートを待ってドキュメントの解析を停止する理由はないようです。ただし、ドキュメントの解析段階でスクリプトがスタイル情報を要求するという問題があります。スタイルがまだ読み込まれておらず解析されていない場合、スクリプトは間違った回答を取得し、これが多くの問題を引き起こしたようです。特殊なケースのように思えますが、非常によくあるケースです。Firefox では、読み込みと解析がまだ完了していないスタイルシートがある場合、すべてのスクリプトがブロックされます。WebKit は、読み込まれていないスタイルシートの影響を受ける可能性がある特定のスタイル プロパティにアクセスしようとした場合にのみ、スクリプトをブロックします。
レンダリング ツリーの作成
DOM ツリーが構築されている間、ブラウザは別のツリー(レンダリング ツリー)を構築します。このツリーは、表示される順序で視覚要素を示しています。ドキュメントの視覚的な表現です。このツリーは、コンテンツを正しい順序でペイントできるようにすることを目的としています。
Firefox では、レンダリング ツリー内の要素を「フレーム」と呼びます。WebKit では、レンダラまたはレンダリング オブジェクトという用語が使用されます。
レンダラは、自身とその子のレイアウトとペイント方法を把握しています。
レンダラ基盤クラスである WebKit の RenderObject クラスは、次のように定義されています。
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
各レンダラは、通常は CSS2 仕様で説明されているノードの CSS ボックスに対応する長方形の領域を表します。これには、幅、高さ、位置などの幾何学的情報が含まれます。
ボックスタイプは、ノードに関連するスタイル属性の「display」値の影響を受けます(スタイルの計算のセクションを参照)。ディスプレイ属性に応じて DOM ノードに作成するレンダラ タイプを決定する WebKit コードを次に示します。
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
要素のタイプも考慮されます。たとえば、フォーム コントロールとテーブルには特別なフレームがあります。
WebKit では、要素が特別なレンダラを作成する場合は、createRenderer() メソッドをオーバーライドします。レンダラは、幾何学的でない情報が含まれるスタイル オブジェクトを参照します。
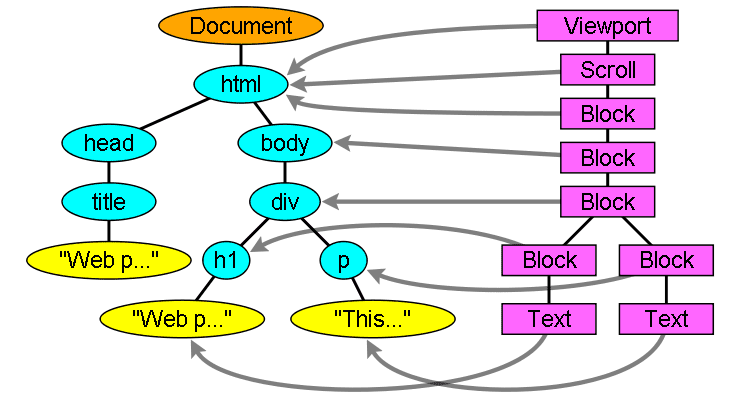
レンダリング ツリーと DOM ツリーの関係
レンダラは DOM 要素に対応していますが、その関係は 1 対 1 ではありません。可視 DOM 要素はレンダリング ツリーに挿入されません。たとえば、「head」要素です。また、表示値が「none」に割り当てられた要素はツリーに表示されません(「hidden」の可視性の要素はツリーに表示されます)。
複数の視覚オブジェクトに対応する DOM 要素があります。通常、これらは複雑な構造の要素であり、1 つの長方形で記述できません。たとえば、「select」要素には、表示領域用、プルダウン リストボックス用、ボタン用の 3 つのレンダラがあります。また、幅が 1 行に収まらないためにテキストが複数行に分割される場合、新しい行が追加のレンダラとして追加されます。
複数のレンダラを使用する別の例として、HTML の破損があります。CSS 仕様では、インライン要素にはブロック要素のみ、またはインライン要素のみを含める必要があります。混合コンテンツの場合、匿名ブロック レンダラが作成され、インライン要素がラップされます。
一部のレンダリング オブジェクトは DOM ノードに対応していますが、ツリー内の同じ場所にあるわけではありません。フロートと絶対位置の要素はフローから外れ、ツリーの別の部分に配置され、実際のフレームにマッピングされます。プレースホルダ フレームが配置されているはずの場所です。
ツリーを構築するフロー
Firefox では、プレゼンテーションは DOM 更新のリスナーとして登録されます。プレゼンテーションはフレームの作成を FrameConstructor に委任し、コンストラクタはスタイルを解決して(スタイルの計算を参照)フレームを作成します。
WebKit では、スタイルを解決してレンダラを作成するプロセスを「アタッチメント」と呼びます。すべての DOM ノードには「attach」メソッドがあります。アタッチメントは同期型で、DOM ツリーへのノードの挿入は新しいノードの「attach」メソッドを呼び出します。
html タグと body タグを処理すると、レンダリング ツリーのルート ノードが作成されます。ルート レンダラ オブジェクトは、CSS 仕様で「包含ブロック」と呼ばれるものに相当します。これは、他のすべてのブロックを含む最上位のブロックです。ディメンションはビューポート(ブラウザ ウィンドウの表示領域のディメンション)です。Firefox では ViewPortFrame、WebKit では RenderView と呼ばれます。これは、ドキュメントが参照するレンダリング オブジェクトです。残りのツリーは、DOM ノードの挿入として作成されます。
処理モデルに関する CSS2 仕様をご覧ください。
スタイルの計算
レンダリング ツリーを構築するには、各レンダリング オブジェクトの視覚プロパティを計算する必要があります。これは、各要素のスタイル プロパティを計算することで行われます。
スタイルには、さまざまなオリジンのスタイルシート、HTML の行内スタイル要素、視覚プロパティ(「bgcolor」プロパティなど)が含まれます。後者は、一致する CSS スタイル プロパティに変換されます。
スタイルシートの起源は、ブラウザのデフォルトのスタイルシート、ページ作成者によって提供されるスタイルシート、ユーザー スタイルシートです。これらはブラウザ ユーザーによって提供されるスタイルシートです(ブラウザでは、お気に入りのスタイルを定義できます。たとえば、Firefox では、スタイルシートを [Firefox プロファイル] フォルダに配置します。
スタイルの計算にはいくつかの難点があります。
- スタイルデータは非常に大きな構造で、多数のスタイル プロパティを保持しているため、メモリの問題が発生する可能性があります。
各要素のマッチング ルールを検出する際に、最適化されていないとパフォーマンスの問題が発生する可能性があります。各要素のルールリスト全体を走査して一致を見つけるのは負荷の高いタスクです。セレクタの構造が複雑な場合、有望なパスでマッチング プロセスが開始されることがあります。しかし、そのパスが不実であることが判明し、別のパスを試す必要がある場合もあります。
たとえば、次の複合セレクタは、
div div div div{ ... }3 つの div の子孫である
<div>にルールが適用されます。特定の<div>要素にルールが適用されるかどうかを確認するとします。チェックするツリー上の特定のパスを指定します。div が 2 つしかないためルールが適用されないことを確認するために、ノードツリーを上へ移動する必要がある場合があります。その後、ツリー内の他のパスを試す必要があります。ルールの適用には、ルールの階層を定義する非常に複雑なカスケード ルールが関与します。
ブラウザがこれらの問題にどのように対処しているかを見てみましょう。
スタイルデータの共有
WebKit ノードはスタイル オブジェクト(RenderStyle)を参照します。これらのオブジェクトは、特定の条件下でノード間で共有できます。ノードが兄弟またはいとこであり、次の条件を満たしている場合:
- 要素は同じマウス状態である必要があります(一方が :hover で、もう一方がそうでない場合など)。
- どちらの要素にも ID を指定しないでください
- タグ名は一致している必要があります
- クラス属性が一致している
- マッピングされた属性のセットは同じである必要があります
- リンクの状態が一致している必要があります
- フォーカス状態が一致している必要があります
- どちらの要素も属性セレクタの影響を受けないようにします。ここで、影響を受けるとは、セレクタ内の任意の位置で属性セレクタを使用するセレクタが一致することを意味します。
- 要素にインライン スタイル属性が設定されていないこと
- 兄弟セレクタは使用しないでください。WebCore は、兄弟セレクタが検出されたときにグローバル スイッチをスローし、兄弟セレクタが存在する場合はドキュメント全体のスタイル共有を無効にします。これには、+ セレクタや :first-child や :last-child などのセレクタが含まれます。
Firefox ルールツリー
Firefox には、スタイル計算を容易にするために、ルールツリーとスタイル コンテキスト ツリーの 2 つの追加ツリーがあります。WebKit にもスタイル オブジェクトがありますが、スタイル コンテキスト ツリーのようなツリーには保存されず、関連するスタイルを参照するのは DOM ノードのみです。
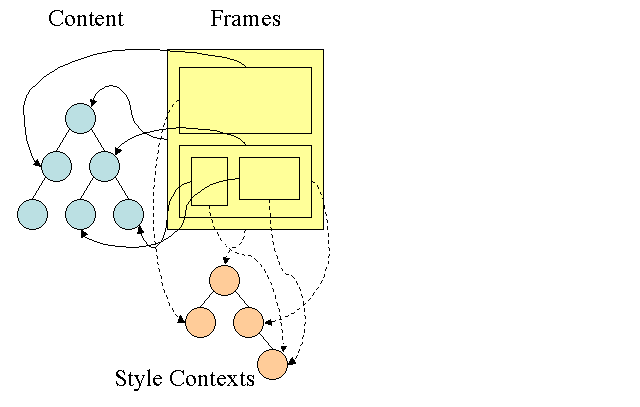
スタイル コンテキストには終了値が含まれます。値は、すべての一致ルールを正しい順序で適用し、論理値から具体的な値に変換する操作を実行することで計算されます。たとえば、論理値が画面の割合である場合、計算されて絶対単位に変換されます。ルールツリーというアイデアは非常に賢明です。これにより、これらの値をノード間で共有して、再計算を回避できます。これにより、スペースも節約できます。
一致したルールはすべてツリーに保存されます。パスの下位ノードの方が優先度が高くなります。ツリーには、検出されたルール一致のすべてのパスが含まれます。ルールの保存は遅延処理されます。ツリーは、すべてのノードに対して最初から計算されるわけではありません。ノードスタイルの計算が必要になるたびに、計算されたパスがツリーに追加されます。
木のパスをレキシコン内の単語と見なします。次のようなルールツリーをすでに計算したとします。
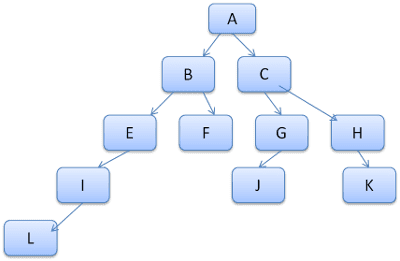
コンテンツ ツリー内の別の要素のルールを照合する必要があり、一致するルールが B-E-I であることを確認したとします。パス A-B-E-I-L はすでに計算されているため、このパスはツリーにすでに存在します。作業量が減ります。
ツリーがどのように作業を省略できるか見てみましょう。
構造体への分割
スタイル コンテキストは構造体に分割されます。これらの構造体には、境界や色などの特定のカテゴリのスタイル情報が含まれています。構造体内のすべてのプロパティは、継承または非継承のいずれかです。継承プロパティは、要素で定義されていない限り、親から継承されるプロパティです。継承されないプロパティ(「リセット」プロパティ)は、定義されていない場合はデフォルト値を使用します。
このツリーは、計算された終端値を含む構造体全体をツリーにキャッシュに保存することで役立ちます。下位ノードで構造体の定義が指定されていない場合、上位ノードのキャッシュに保存された構造体を使用できます。
ルールツリーを使用してスタイル コンテキストを計算する
特定の要素のスタイル コンテキストを計算する場合、まずルールツリー内のパスを計算するか、既存のパスを適用します。次に、パス内のルールを適用して、新しいスタイル コンテキストに構造体を入力します。パスの一番下のノード(優先度が最も高いノード(通常は最も具体的なセレクタ))から始めて、構造体がいっぱいになるまでツリーを走査します。そのルールノードに構造体の指定がない場合、大幅に最適化できます。完全に指定し、その構造体を参照するノードを見つけるまでツリーを上昇します。これが最適化の最適な方法です。構造体全体が共有されます。これにより、最終値の計算とメモリを節約できます。
部分定義が見つかった場合は、構造体が埋まるまでツリーを上昇します。
構造体の定義が見つからない場合は、構造体が「継承」型である場合、コンテキスト ツリー内の親の構造体を参照します。この場合、構造体も共有できました。リセット ストラクチャの場合は、デフォルト値が使用されます。
最も具体的なノードが値を追加する場合は、実際の値に変換するために追加の計算を行う必要があります。その後、結果をツリーノードにキャッシュに保存して、子プロセスが使用できるようにします。
要素に同じツリーノードを指す兄弟要素がある場合は、スタイル コンテキスト全体をそれらの要素間で共有できます。
例を見てみましょう。次の HTML があるとします。
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
次のルールも適用されます。
div {margin: 5px; color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
簡素化のため、色の構造体とマージンの構造体の 2 つの構造体のみ入力するとします。color 構造体には、color という 1 つのメンバーのみが含まれます。margin 構造体には、4 つの側面が含まれます。
作成されたルールツリーは次のようになります(ノードには、ノード名(指しているルール番号)が付けられています)。
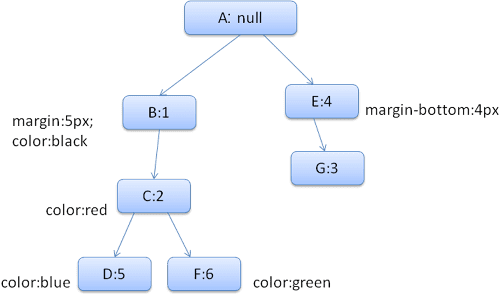
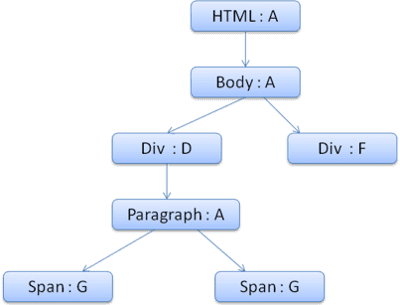
コンテキスト ツリーは次のようになります(ノード名: 参照先のルールノード)。
HTML を解析して 2 番目の <div> タグに到達したとします。このノードにスタイル コンテキストを作成し、そのスタイル ストラクチャに入力する必要があります。
ルールを照合すると、<div> の一致ルールは 1、2、6 であることがわかります。つまり、要素が使用できるパスがツリーにすでに存在し、ルール 6(ルールツリーのノード F)用のノードを追加するだけで済みます。
スタイル コンテキストを作成し、コンテキスト ツリーに配置します。新しいスタイル コンテキストは、ルールツリーのノード F を参照します。
次に、スタイル構造体を入力する必要があります。まず、マージン構造を入力します。最後のルールノード(F)はマージン構造に追加しないため、前のノードの挿入時に計算されたキャッシュに保存された構造を見つけるまでツリーを上っていき、その構造を使用できます。余白ルールを指定した最上位のノードであるノード B にあります。
色の構造体は定義されているため、キャッシュに保存された構造体は使用できません。色には 1 つの属性があるため、他の属性を入力するためにツリーを上っていく必要はありません。最終的な値を計算し(文字列を RGB に変換するなど)、このノードで計算された構造体をキャッシュに保存します。
2 番目の <span> 要素の作業はさらに簡単です。ルールを照合すると、前のスパンと同様に、ルール G を指していることがわかります。同じノードを指す兄弟要素があるため、スタイル コンテキスト全体を共有し、前のスパンのコンテキストを指すだけで済みます。
親から継承されたルールを含む構造体の場合、キャッシュはコンテキスト ツリーで行われますが(color プロパティは実際には継承されますが、Firefox ではリセットとして扱われ、ルールツリーにキャッシュされます)、
たとえば、段落内のフォントのルールを追加した場合は、次のようにします。
p {font-family: Verdana; font size: 10px; font-weight: bold}
コンテキスト ツリー内の div の子である段落要素は、親と同じフォント構造を共有できます。これは、段落にフォントルールが指定されていない場合です。
WebKit にはルールツリーがないため、一致した宣言は 4 回走査されます。まず、重要でない優先度の高いプロパティ(他のプロパティが依存しているため、最初に適用する必要があるプロパティ、ディスプレイなど)が適用され、次に優先度の高い重要なプロパティ、次に優先度の低い重要でないプロパティ、最後に優先度の低い重要なプロパティが適用されます。つまり、複数回出現するプロパティは、正しいカスケード順序に従って解決されます。最後まで残った人が勝ちます。
まとめると、スタイル オブジェクト(全体または内部の一部のスロット)を共有することで、問題 1 と 3 を解決できます。Firefox のルールツリーは、プロパティを正しい順序で適用するのにも役立ちます。
ルールを操作して簡単に一致させる
スタイルルールにはいくつかのソースがあります。
- CSS ルール(外部スタイルシートまたはスタイル要素)。
css p {color: blue} html <p style="color: blue" />などのインライン スタイル属性- HTML ビジュアル属性(関連するスタイルルールにマッピング)
html <p bgcolor="blue" />最後の 2 つは、スタイル属性を所有し、HTML 属性を要素をキーとしてマッピングできるため、要素と簡単に照合できます。
問題 2 で説明したように、CSS ルールのマッチングは複雑になる場合があります。この問題を解決するため、ルールを操作してアクセスを容易にしています。
スタイルシートが解析されると、セレクタに応じて、ルールが複数のハッシュマップのいずれかに追加されます。ID 別、クラス名別、タグ名別、およびこれらのカテゴリに該当しないすべてのオブジェクト用の一般的なマップがあります。セレクタが ID の場合は ID マップ、クラスの場合はクラスマップなどにルールが追加されます。
この操作により、ルールの照合が大幅に容易になります。すべての宣言を確認する必要はありません。マップから要素に関連するルールを抽出できます。この最適化により、95% 以上のルールが除外されるため、照合プロセス(4.1)で考慮する必要がなくなります。
たとえば、次のスタイルルールについて見てみましょう。
p.error {color: red}
#messageDiv {height: 50px}
div {margin: 5px}
最初のルールがクラスマップに挿入されます。2 つ目は ID マップ、3 つ目はタグマップに格納されます。
次の HTML フラグメントの場合:
<p class="error">an error occurred</p>
<div id=" messageDiv">this is a message</div>
まず、p 要素のルールを探します。クラスマップには「error」キーが含まれ、その下に「p.error」のルールが見つかります。div 要素には、ID マップ(キーは ID)とタグマップに関連するルールが設定されます。残る作業は、キーによって抽出されたルールのどれが実際に一致しているかを特定することだけです。
たとえば、div のルールが次のようなものだったとします。
table div {margin: 5px}
キーが右端のセレクタであるため、タグマップから引き続き抽出されます。ただし、テーブルの祖先を持たない div 要素には一致しません。
WebKit と Firefox の両方でこの操作が行われます。
スタイルシートのカスケード順序
スタイル オブジェクトには、すべての視覚属性(すべての CSS 属性だがより汎用的)に対応するプロパティがあります。プロパティが一致したルールで定義されていない場合、一部のプロパティは親要素のスタイル オブジェクトによって継承できます。他のプロパティにはデフォルト値があります。
問題は、定義が複数ある場合に発生します。この問題を解決するには、カスケード順序を使用します。
スタイル プロパティの宣言は、複数のスタイルシートに、またスタイルシート内で複数回指定できます。つまり、ルールの適用順序は非常に重要です。これは「カスケード」順序と呼ばれます。CSS2 仕様によると、カスケードの順序は(低い順から高い順)次のとおりです。
- ブラウザの宣言
- ユーザーの通常の宣言
- 著者の通常の宣言
- 著者の重要な申告
- ユーザーの重要な申告
ブラウザ宣言は最も重要性が低く、宣言が重要としてマークされている場合にのみ、ユーザーが作成者をオーバーライドします。同じ順序の宣言は、詳細度と指定順序で並べ替えられます。HTML の視覚属性は、一致する CSS 宣言に変換されます。優先度の低い作成者ルールとして扱われます。
特異性
セレクタの詳細度は、CSS2 仕様で次のように定義されています。
- セレクタを含むルールではなく「style」属性である宣言の場合は 1、それ以外の場合は 0(= a)
- セレクタ内の ID 属性の数をカウントする(= b)
- セレクタ内の他の属性と疑似クラスの数をカウントします(= c)
- セレクタ内の要素名と疑似要素の数をカウントします(= d)
4 つの数値(大きな基数の数値システムで)a-b-c-d を連結すると、特定性が得られます。
使用する数値ベースは、いずれかのカテゴリで最も高い数値によって決まります。
たとえば、a=14 の場合は、16 進数を使用できます。まれに a=17 となる場合、17 桁の基数が必要になります。後者の状況は、次のようなセレクタで発生する可能性があります。 html body div div p…(セレクタに 17 個のタグが含まれています…あまりありそうもありません)。
例:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
ルールの並べ替え
ルールが照合されると、カスケード ルールに従って並べ替えられます。WebKit では、小さなリストにはバブルソート、大きなリストにはマージソートを使用します。WebKit は、ルールの > 演算子をオーバーライドすることで並べ替えを実装します。
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
段階的なプロセス
WebKit は、すべてのトップレベル スタイルシート(@imports を含む)が読み込まれたかどうかを示すフラグを使用します。スタイルが添付時に完全に読み込まれていない場合は、プレースホルダが使用され、ドキュメントにマークされます。スタイルシートが読み込まれると、プレースホルダは再計算されます。
レイアウト
レンダラが作成されてツリーに追加された時点では、位置とサイズがありません。これらの値の計算をレイアウトまたは再フローと呼びます。
HTML はフローベースのレイアウト モデルを使用します。つまり、ほとんどの場合、ジオメトリを 1 回のパスで計算できます。通常、「フロー内」の後半の要素は「フロー内」の前半の要素のジオメトリに影響しないため、ドキュメント内で左から右、上から下にレイアウトを進めることができます。ただし、例外もあります。たとえば、HTML テーブルでは複数のパスが必要な場合があります。
座標系はルート フレームからの相対値です。上と左の座標が使用されます。
レイアウトは再帰的なプロセスです。ルート レンダラから始まります。これは、HTML ドキュメントの <html> 要素に対応しています。レイアウトは、フレーム階層の一部またはすべてを再帰的に処理し、必要とするレンダラごとにジオメトリ情報を計算します。
ルート レンダラは 0,0 の位置にあり、そのサイズはビューポート(ブラウザ ウィンドウの表示部分)です。
すべてのレンダラには「レイアウト」メソッドまたは「再フロー」メソッドがあり、各レンダラはレイアウトが必要な子のレイアウト メソッドを呼び出します。
ダーティビット システム
小さな変更ごとに完全なレイアウトを実行しないように、ブラウザは「ダーティビット」システムを使用します。変更または追加されたレンダラは、自身とその子を「ダーティ」(レイアウトが必要)としてマークします。
フラグには「dirty」と「children are dirty」の 2 つがあります。これは、レンダラ自体は問題ないとしても、レイアウトが必要な子が少なくとも 1 つあることを意味します。
グローバル レイアウトと増分レイアウト
レイアウトはレンダリング ツリー全体でトリガーできます。これは「グローバル」レイアウトです。次のような原因が考えられます。
- すべてのレンダラに影響するグローバル スタイルの変更(フォントサイズの変更など)。
- 画面のサイズ変更の結果
レイアウトは増分処理で、変更が加えられたレンダラのみがレイアウトされます(これにより、追加のレイアウトが必要になる損傷が発生する可能性があります)。
増分レイアウトは、レンダラがダーティなときに(非同期で)トリガーされます。たとえば、ネットワークから追加のコンテンツが届いて DOM ツリーに追加された後、新しいレンダラがレンダリング ツリーに追加される場合などです。
非同期レイアウトと同期レイアウト
増分レイアウトは非同期で実行されます。Firefox は増分レイアウトの「再フロー コマンド」をキューに追加し、スケジューラがこれらのコマンドのバッチ実行をトリガーします。WebKit には、増分レイアウトを実行するタイマーもあります。このタイマーにより、ツリーが走査され、「変更済み」レンダラがレイアウトされます。
「offsetHeight」などのスタイル情報を要求するスクリプトは、増分レイアウトを同期的にトリガーする可能性があります。
通常、グローバル レイアウトは同期的にトリガーされます。
スクロール位置などの一部の属性が変更されたため、最初のレイアウトの後にレイアウトがコールバックとしてトリガーされることがあります。
最適化
レイアウトが「サイズ変更」またはレンダラ位置の変更(サイズではない)によってトリガーされた場合、レンダリング サイズはキャッシュから取得され、再計算されません。
サブツリーのみが変更され、ルートからレイアウトが開始されない場合があります。これは、変更がローカルで、周囲に影響を与えない場合(テキスト フィールドに挿入されたテキストなど)に発生することがあります(そうでない場合、すべてのキーストロークでルートからレイアウトがトリガーされます)。
レイアウト プロセス
通常、レイアウトは次のパターンになります。
- 親レンダラが独自の幅を決定します。
- 保護者が子供を確認し、次のことを行います。
- 子レンダラを配置します(x と y を設定します)。
- 必要に応じて(子要素が変更されている場合、グローバル レイアウト内にある場合、またはその他の理由がある場合)子レイアウトを呼び出し、子要素の高さを計算します。
- 親は、子の累積高さと、マージンとパディングの高さを使用して独自の高さを設定します。これは、親レンダラが親で使用します。
- ダーティビットを false に設定します。
Firefox では、レイアウト(「再フロー」)のパラメータとして「状態」オブジェクト(nsHTMLReflowState)を使用します。状態には、親の幅が含まれます。
Firefox レイアウトの出力は「指標」オブジェクト(nsHTMLReflowMetrics)です。レンダラによって計算された高さが含まれます。
幅の計算
レンダラ幅は、コンテナ ブロックの幅、レンダラのスタイルの「width」プロパティ、余白と境界を使用して計算されます。
たとえば、次の div の幅は次のようになります。
<div style="width: 30%"/>
WebKit によって次のように計算されます(クラス RenderBox メソッド calcWidth)。
- コンテナの幅は、コンテナの availableWidth と 0 の最大値です。この場合の availableWidth は contentWidth で、次のように計算されます。
clientWidth() - paddingLeft() - paddingRight()
clientWidth と clientHeight は、境界とスクロールバーを除くオブジェクトの内部を表します。
要素の幅は「width」スタイル属性です。コンテナ幅の割合を計算して、絶対値として計算されます。
水平方向の枠線とパディングが追加されました。
ここまでは「推奨幅」の計算でした。最小幅と最大幅が計算されます。
推奨幅が最大幅より大きい場合は、最大幅が使用されます。最小幅(分割できない最小単位)より小さい場合は、最小幅が使用されます。
値は、レイアウトが必要な場合にキャッシュに保存されますが、幅は変更されません。
改行
レイアウトの途中にあるレンダラがブレークが必要と判断すると、レンダラは停止し、ブレークが必要であることをレイアウトの親に伝播します。親は追加のレンダラを作成し、それらのレンダラでレイアウトを呼び出します。
絵画
ペイント ステージでは、レンダリング ツリーが走査され、レンダラが「paint()」メソッドを呼び出してコンテンツを画面に表示します。ペインティングは UI インフラストラクチャ コンポーネントを使用します。
グローバルと増分
レイアウトと同様に、ペイントもグローバル(ツリー全体がペイントされる)または増分できます。増分ペイントでは、一部のレンダラが、ツリー全体に影響しない方法で変更されます。変更されたレンダラは、画面上の長方形を無効にします。これにより、OS はそれを「変更された領域」と見なし、「ペイント」イベントを生成します。OS はこれを巧みに行い、複数のリージョンを 1 つに統合します。Chrome では、レンダラがメインプロセスとは異なるプロセスにあるため、さらに複雑になります。Chrome は、OS の動作をある程度シミュレートします。プレゼンテーションはこれらのイベントをリッスンし、メッセージをレンダリング ルートに委任します。関連するレンダラに到達するまでツリーが走査されます。自身(通常は子)を再描画します。
塗装の順序
CSS2 ではペイント プロセスの順序が定義されています。これは、スタッキング コンテキストで要素が積み重ねられる順序です。グルーピングは、グルーピングされた要素が下から上にペイントされるため、ペイントに影響します。ブロック レンダラは、次の順序で重ねられます。
- 背景色
- 背景画像
- border
- 子供
- アウトライン
Firefox のディスプレイ リスト
Firefox はレンダリング ツリーを調べ、塗りつぶされた長方形のディスプレイ リストを作成します。長方形に関連するレンダラが、正しいペイント順序(レンダラの背景、境界など)で含まれています。
これにより、再描画時にツリーを複数回走査するのではなく、1 回だけ走査すれば済みます。たとえば、すべての背景、すべての画像、すべての境界などをペイントします。
Firefox では、他の不透明な要素の下に完全に隠れる要素など、非表示になる要素を追加しないことで、プロセスを最適化しています。
WebKit の長方形ストレージ
WebKit は、再描画の前に、古い長方形をビットマップとして保存します。新しい長方形と古い長方形の差分のみ描画されます。
動的変更
ブラウザは、変更に応じて可能な限り最小限のアクションを実行しようとします。そのため、要素の色を変更しても、要素の再描画のみが行われます。要素の位置を変更すると、要素、その子、場合によっては兄弟のレイアウトと再描画が行われます。DOM ノードを追加すると、ノードのレイアウトと再描画が行われます。「html」要素のフォントサイズの増加などの大きな変更を行うと、キャッシュが無効になり、ツリー全体の再レイアウトと再描画が行われます。
レンダリング エンジンのスレッド
レンダリング エンジンはシングルスレッドです。ネットワーク オペレーションを除き、ほとんどの処理は 1 つのスレッドで実行されます。Firefox と Safari では、これがブラウザのメインスレッドです。Chrome では、タブ プロセスのメインスレッドです。
ネットワーク オペレーションは、複数の並列スレッドによって実行できます。並列接続の数は制限されています(通常は 2 ~ 6 接続)。
イベントループ
ブラウザのメインスレッドはイベントループです。これは、プロセスを存続させる無限ループです。イベント(レイアウト イベントやペイント イベントなど)を待機して処理します。以下は、メイン イベントループの Firefox コードです。
while (!mExiting)
NS_ProcessNextEvent(thread);
CSS2 ビジュアル モデル
キャンバス
CSS2 仕様によると、キャンバスという用語は「フォーマット構造がレンダリングされるスペース」を意味します。つまり、ブラウザがコンテンツをペイントする場所です。
キャンバスは空間の各ディメンションで無限ですが、ブラウザはビューポートのディメンションに基づいて初期幅を選択します。
www.w3.org/TR/CSS2/zindex.html によると、キャンバスは別のキャンバスに含まれている場合は透明で、含まれていない場合はブラウザで定義された色になります。
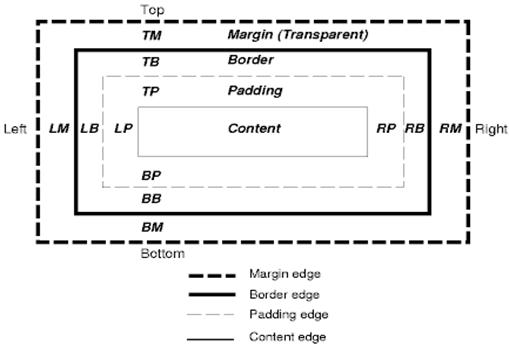
CSS ボックスモデル
CSS ボックスモデルは、ドキュメント ツリー内の要素に対して生成され、ビジュアル フォーマット モデルに従ってレイアウトされる長方形のボックスを記述します。
各ボックスには、コンテンツ領域(テキスト、画像など)と、オプションで周囲のパディング、境界、余白領域があります。
各ノードは 0 ~ n 個のボックスを生成します。
すべての要素には、生成されるボックスのタイプを決定する「display」プロパティがあります。
例:
block: generates a block box.
inline: generates one or more inline boxes.
none: no box is generated.
デフォルトはインラインですが、ブラウザのスタイルシートで他のデフォルトが設定されている場合があります。たとえば、「div」要素のデフォルトの表示はブロックです。
デフォルトのスタイルシートの例については、www.w3.org/TR/CSS2/sample.html をご覧ください。
ポジショニング スキーム
スキームは次の 3 つです。
- 通常: オブジェクトはドキュメント内の位置に応じて配置されます。つまり、レンダリング ツリー内の位置は DOM ツリー内の位置と同じであり、ボックスの種類とサイズに従ってレイアウトされます。
- フロート: オブジェクトはまず通常のフローのようにレイアウトされ、次にできるだけ左または右に移動されます。
- 絶対: オブジェクトは、DOM ツリーとは異なる場所にレンダリング ツリーに配置されます。
配置スキームは、「position」プロパティと「float」属性で設定します。
- static と relative は通常のフローを発生させる
- absolute と fixed は絶対位置指定を指定します。
静的配置では、位置は定義されず、デフォルトの配置が使用されます。他のスキームでは、作成者が位置(上、下、左、右)を指定します。
ボックスのレイアウトは、次によって決まります。
- ボックスの種類
- 箱の寸法
- ポジショニング スキーム
- 画像サイズや画面サイズなどの外部情報
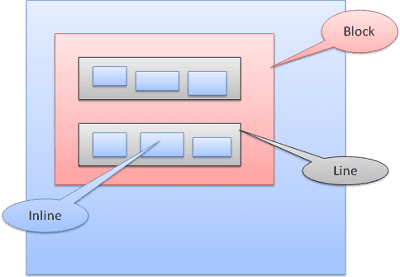
ボックスの種類
ブロック ボックス: ブロックを形成します。ブラウザ ウィンドウ内に独自の長方形があります。

インライン ボックス: 独自のブロックはなく、包含ブロック内にあります。
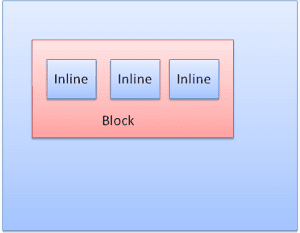
ブロックは縦方向に 1 つずつフォーマットされます。インラインは横向きに表示されます。
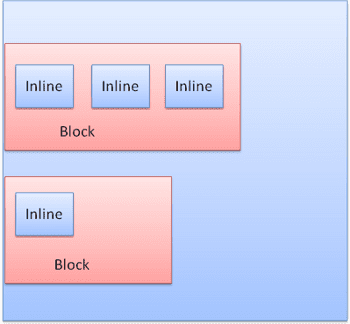
インライン ボックスは、線または「線ボックス」内に配置されます。線の長さは、最も高いボックスの長さ以上になりますが、ボックスが「ベースライン」に揃えられている場合は、それより長くなることもあります。つまり、要素の下部が、下部以外の別のボックスの点に揃えられます。コンテナの幅が足りない場合、インラインは複数行に分割されます。通常、段落内で行われます。
位置付け
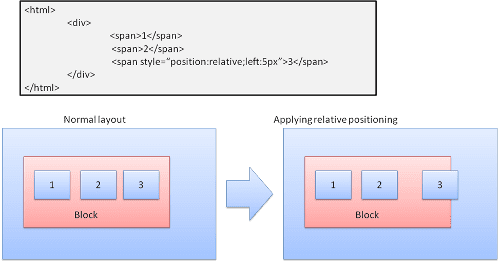
相対
相対配置 - 通常どおりに配置してから、必要なデルタ分移動します。
浮動小数点
フロート ボックスは、行の左または右に移動されます。他のボックスがその周囲を流れる点が興味深い特徴です。HTML:
<p>
<img style="float: right" src="images/image.gif" width="100" height="100">
Lorem ipsum dolor sit amet, consectetuer...
</p>
次のように表示されます。

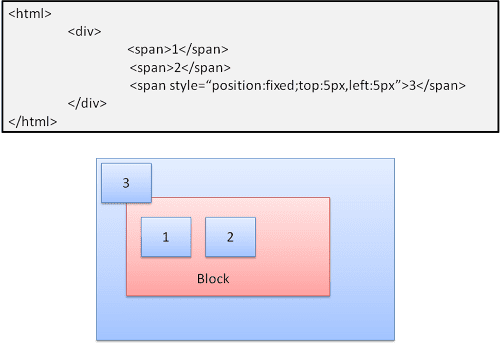
絶対値と固定値
レイアウトは、通常のフローに関係なく正確に定義されます。要素は通常のフローには参加しません。寸法はコンテナを基準としています。固定の場合、コンテナはビューポートです。
レイヤ化された表現
これは、CSS プロパティの z-index で指定します。ボックスの 3 番目のディメンション(「z 軸」に沿った位置)を表します。
ボックスはスタック(スタッキング コンテキスト)に分割されます。各スタックでは、最初に「戻る」要素がペイントされ、その上に「進む」要素がペイントされます。重複する場合は、前方の要素が前の要素を隠します。
スタックは z-index プロパティに従って並べ替えられます。「z-index」プロパティを持つボックスはローカル スタックを形成します。ビューポートには外側のスタックがあります。
例:
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
結果は次のようになります。

赤い div はマークアップでは緑の div の前に記述されており、通常のフローでは先に描画されるはずですが、z-index プロパティが大きいため、ルートボックスによって保持されるスタック内でより前方に配置されます。
リソース
ブラウザのアーキテクチャ
- Grosskurth, Alan. ウェブブラウザのリファレンス アーキテクチャ(PDF)
- Gupta、Vineetブラウザの仕組み - 第 1 部 - アーキテクチャ
解析
- Aho, Sethi, Ullman, Compilers: Principles, Techniques, and Tools(「ドラゴン ブック」)、Addison-Wesley、1986
- Rick Jelliffe 様。The Bold and the Beautiful: HTML 5 の 2 つの新しいドラフト。
Firefox
- L.David Baron、Faster HTML and CSS: Layout Engine Internals for Web Developers
- L.David Baron、Faster HTML and CSS: Layout Engine Internals for Web Developers(Google 技術系トーク動画)
- L.David Baron、Mozilla のレイアウト エンジン
- L.David Baron、Mozilla スタイルシステムのドキュメント
- Chris Waterson、HTML リフローに関するメモ
- Chris Waterson、Gecko の概要
- Alexander Larsson、The life of an HTML HTTP request
Webkit
- David Hyatt、CSS の実装(パート 1)
- David Hyatt、WebCore の概要
- David Hyatt、WebCore レンダリング
- David Hyatt、The FOUC Problem
W3C 仕様
ブラウザのビルド手順
翻訳
このページは 2 回日本語に翻訳されています。
- How Browsers Work - Behind the Scenes of Modern Web Browsers(ja)(@kosei)
- ブラウザってどうやって動いてるの?(モダン WEB ブラウザシーンの裏側 @ikeike443 と @kiyoto01 による
みなさんもおつかれさまでした。