
מאחורי הקלעים של דפדפני אינטרנט מודרניים


הקדמה
המדריך המקיף הזה על הפעולות הפנימיות של WebKit ו-Gecko הוא תוצאה של מחקר מקיף שנעשה על ידי המפתחת הישראלית טלי גרסיאל. במשך כמה שנים היא בדקה את כל הנתונים שפורסמו על הרכיבים הפנימיים של הדפדפן, והקדישה הרבה זמן לקריאת קוד המקור של דפדפני אינטרנט. היא כתבה:
כמפתחי אינטרנט, לימוד הרכיבים הפנימיים של פעולות הדפדפן עוזר לכם לקבל החלטות טובות יותר ולהבין את ההצדקות לשיטות המומלצות לפיתוח. המסמך הזה ארוך למדי, אבל מומלץ להקדיש לו זמן. ככה עדיף.
Paul Irish, צוות קשרי המפתחים של Chrome
מבוא
דפדפני אינטרנט הם התוכנות הנפוצות ביותר. במאמר הזה אסביר איך הם פועלים מאחורי הקלעים. נבדוק מה קורה כשמקלידים google.com בסרגל הכתובות עד שדף Google יופיע במסך הדפדפן.
הדפדפנים שעליהם נדבר
יש היום חמישה דפדפנים עיקריים שמשמשים במחשבים: Chrome, Internet Explorer, Firefox, Safari ו-Opera. בניידים, הדפדפנים העיקריים הם דפדפן Android, iPhone, Opera Mini ו-Opera Mobile, UC Browser, הדפדפנים של Nokia S40/S60 ו-Chrome. כל הדפדפנים האלה, מלבד דפדפני Opera, מבוססים על WebKit. אציג דוגמאות מהדפדפנים בקוד פתוח Firefox ו-Chrome, ומהדפדפן Safari (שחלקו בקוד פתוח). לפי נתוני הסטטיסטיקה של StatCounter (נכון ליוני 2013), Chrome, Firefox ו-Safari מהווים כ-71% מכלל השימוש בדפדפנים למחשבים ברחבי העולם. בנייד, דפדפן Android, iPhone ו-Chrome מהווים כ-54% מהשימוש.
הפונקציונליות הראשית של הדפדפן
הפונקציה העיקרית של דפדפן היא להציג את משאב האינטרנט שבחרתם, על ידי שליחת בקשה אליו מהשרת והצגתו בחלון הדפדפן. המשאב הוא בדרך כלל מסמך HTML, אבל הוא יכול להיות גם קובץ PDF, תמונה או סוג אחר של תוכן. המשתמש מציין את המיקום של המשאב באמצעות URI (מזהה משאב אחיד).
האופן שבו הדפדפן מפרש ומציג קובצי HTML מצוין במפרטי HTML ו-CSS. המפרטים האלה מתוחזקים על ידי ארגון W3C (World Wide Web Consortium), שהוא ארגון התקנים של האינטרנט. במשך שנים, הדפדפנים תומכים רק בחלק מהמפרטים ופתחו תוספים משלהם. זה גרם לבעיות תאימות חמורות לכותבי אתרים. כיום, רוב הדפדפנים עומדים במפרטים.
לממשקי המשתמש של הדפדפנים יש הרבה דברים משותפים. בין הרכיבים הנפוצים בממשק המשתמש:
- סרגל הכתובות להוספת URI
- לחצני 'הקודם' ו'הבא'
- אפשרויות לסימון כסימנייה
- לחצני רענון ועצירה לרענון או להפסקת הטעינה של המסמכים הנוכחיים
- לחצן דף הבית שמוביל לדף הבית
באופן מוזר, ממשק המשתמש של הדפדפן לא מוגדר במפרט רשמי כלשהו, אלא נובע משיטות מומלצות שנוצרו לאורך שנים של ניסיון ודפדפנים שמחקים זה את זה. במפרט HTML5 לא מוגדרים רכיבי ממשק משתמש שחייבים להיות בדפדפן, אבל יש בו רשימה של כמה רכיבים נפוצים. בין היתר, סרגל הכתובות, סרגל הסטטוס וסרגל הכלים. כמובן שיש תכונות ייחודיות לדפדפן ספציפי, כמו מנהל ההורדות של Firefox.
תשתית ברמה גבוהה
הרכיבים העיקריים של הדפדפן הם:
- ממשק המשתמש: כולל את סרגל הכתובות, הלחצן 'חזרה'/'המשך', תפריט הסימניות וכו'. כל חלק במסך הדפדפן, מלבד החלון שבו מוצג הדף המבוקש.
- מנוע הדפדפן: מנהל את הפעולות בין ממשק המשתמש לבין מנוע הרינדור.
- מנוע הרינדור: אחראי להצגת התוכן המבוקש. לדוגמה, אם התוכן המבוקש הוא HTML, מנוע הרינדור מנתח את ה-HTML וה-CSS ומציג את התוכן המנותח במסך.
- Networking: לקריאות לרשת, כמו בקשות HTTP, באמצעות הטמעות שונות לפלטפורמות שונות מאחורי ממשק שלא תלוי בפלטפורמה.
- קצה עורפי של ממשק משתמש: משמש לציור ווידג'טים בסיסיים כמו תיבות שילוב וחלונות. הקצה העורפי הזה חושף ממשק כללי שאינו ספציפי לפלטפורמה. מתחתיו נעשה שימוש בשיטות של ממשק המשתמש של מערכת ההפעלה.
- מַפְרִיט JavaScript. משמש לניתוח ולביצוע של קוד JavaScript.
- אחסון נתונים. זהו שכבת עקביות. יכול להיות שהדפדפן יצטרך לשמור באופן מקומי כל מיני נתונים, כמו קובצי cookie. הדפדפנים תומכים גם במנגנוני אחסון כמו localStorage, IndexedDB, WebSQL ו-FileSystem.
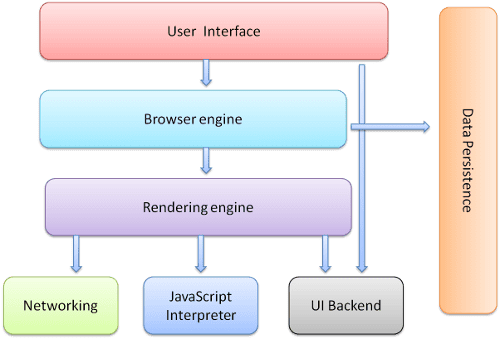
חשוב לציין שבדפדפנים כמו Chrome פועלים כמה מופעים של מנוע הרינדור: אחד לכל כרטיסייה. כל כרטיסייה פועלת בתהליך נפרד.
מנועי עיבוד
מנוע הרינדור אחראי על… רינדור, כלומר הצגת התוכן המבוקש במסך הדפדפן.
כברירת מחדל, מנוע העיבוד יכול להציג תמונות ומסמכים של HTML ו-XML. אפשר להציג סוגים אחרים של נתונים באמצעות יישומי פלאגין או תוספים. לדוגמה, הצגת מסמכי PDF באמצעות פלאגין של תוכנת צפייה ב-PDF. עם זאת, בחלק הזה נתמקד בתרחיש לדוגמה העיקרי: הצגת HTML ותמונות בפורמט CSS.
בדפדפנים שונים נעשה שימוש במנועי עיבוד שונים: ב-Internet Explorer נעשה שימוש ב-Trident, ב-Firefox נעשה שימוש ב-Gecko וב-Safari נעשה שימוש ב-WebKit. ב-Chrome וב-Opera (מגרסה 15 ואילך) נעשה שימוש ב-Blink, גרסת פורק של WebKit.
WebKit הוא מנוע עיבוד בקוד פתוח שהתחיל כמנוע לפלטפורמת Linux, ו-Apple שינתה אותו כדי לתמוך ב-Mac וב-Windows.
התהליך הראשי
מנוע הרינדור יתחיל לקבל את תוכן המסמך המבוקש משכבת הרשתות. בדרך כלל, הפעולה הזו מתבצעת בקטעים של 8KB.
לאחר מכן, זהו התהליך הבסיסי של מנוע הרינדור:

מנוע העיבוד יתחיל לנתח את מסמך ה-HTML ולהמיר רכיבים לצמתים של DOM בעץ שנקרא 'עץ התוכן'. המנוע ינתח את נתוני הסגנון, גם בקובצי CSS חיצוניים וגם ברכיבי סגנון. פרטי העיצוב יחד עם ההוראות החזוניות ב-HTML ישמשו ליצירת עץ נוסף: עץ הרינדור.
עץ הרינדור מכיל מלבנים עם מאפיינים חזותיים כמו צבע ומימדים. הריבועים נמצאים בסדר הנכון כדי שיוצגו במסך.
אחרי היצירה של עץ הרינדור, הוא עובר תהליך פריסה. כלומר, צריך לתת לכל צומת את הקואורדינטות המדויקות שבהן הוא אמור להופיע במסך. השלב הבא הוא צביעה – יתבצע סריקה של עץ הרינדור וכל צומת יצויר באמצעות שכבת הקצה העורפי של ממשק המשתמש.
חשוב להבין שמדובר בתהליך הדרגתי. כדי לשפר את חוויית המשתמש, מנוע הרינדור ינסה להציג את התוכן במסך בהקדם האפשרי. הוא לא ימתין עד שכל ה-HTML ינותח לפני שהוא יתחיל ליצור את עץ הרינדור ולתכנן את הפריסה שלו. חלקים מהתוכן ינותחו ויוצגו, והתהליך ימשיך עם שאר התוכן שממשיך להגיע מהרשת.
דוגמאות לתהליך ראשי
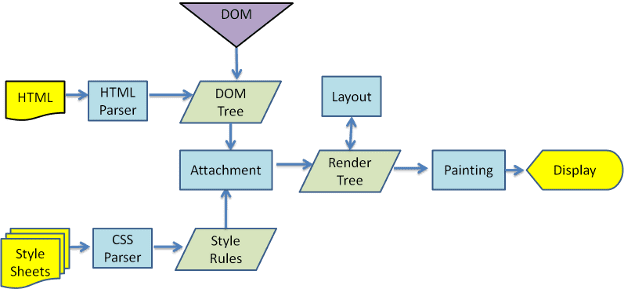
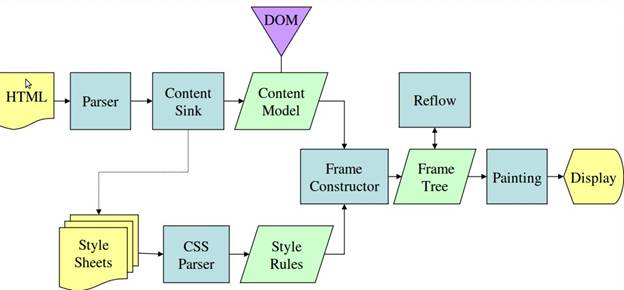
באיורים 3 ו-4 אפשר לראות שלמרות שב-WebKit וב-Gecko נעשה שימוש במונחים שונים במקצת, התהליך הוא בעצם זהה.
ב-Gecko, העץ של הרכיבים בפורמט חזותי נקרא 'עץ מסגרת'. כל רכיב הוא פריים. ב-WebKit נעשה שימוש במונח 'עץ רינדור', והוא מורכב מ'אובייקטים לרינדור'. ב-WebKit משתמשים במונח 'פריסה' למיקום הרכיבים, ואילו ב-Gecko קוראים לזה 'פריסה מחדש'. 'צירוף' הוא המונח של WebKit לחיבור צמתים של DOM ומידע חזותי כדי ליצור את עץ הרינדור. הבדל קטן שאינו סמנטי הוא של-Gecko יש שכבה נוספת בין ה-HTML לבין עץ ה-DOM. הוא נקרא 'בור ניקוז תוכן' והוא מפעל ליצירת רכיבי DOM. נדבר על כל חלק בתהליך:
ניתוח – כללי
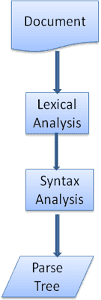
ניתוח הוא תהליך חשוב מאוד במנוע הרינדור, ולכן נרחיב עליו קצת יותר. נתחיל עם מבוא קצר על ניתוח.
ניתוח מסמך פירושו תרגום שלו למבנה שאפשר להשתמש בו בקוד. תוצאת הניתוח היא בדרך כלל עץ של צמתים שמייצגים את המבנה של המסמך. הנתונים האלה נקראים עץ ניתוח או עץ תחביר.
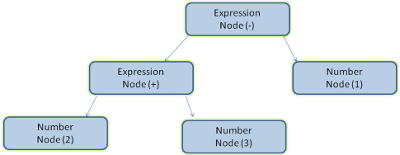
לדוגמה, ניתוח הביטוי 2 + 3 - 1 יכול להחזיר את העץ הזה:
דקדוק
הניתוח מבוסס על כללי התחביר של המסמך: השפה או הפורמט שבהם הוא נכתב. לכל פורמט שאפשר לנתח צריך להיות דקדוק דטרמיניסטי שמורכב ממילון וכללי תחביר. היא נקראת תחביר ללא הקשר. שפות אנושיות הן לא שפות כאלה, ולכן אי אפשר לנתח אותן באמצעות שיטות ניתוח רגילות.
שילוב של מנתח (parser) עם מנתח קוד (lexer)
אפשר להפריד את הניתוח לשני תהליכים משניים: ניתוח לקסיקלי וניתוח תחבירי.
ניתוח לקסיקלי הוא תהליך שבו הקלט מחולק לטוקנים. אסימונים הם אוצר המילים של השפה: האוסף של אבני הבניין התקינות. בשפה אנושית, הוא יכלול את כל המילים שמופיעות במילון של השפה הזו.
ניתוח תחביר הוא החלת כללי התחביר של השפה.
בדרך כלל, מנתח הקוד מחלק את העבודה בין שני רכיבים: מנתח המילים (שנקרא לפעמים מנתח אסימונים) שאחראי על פירוק הקלט לאסימונים תקינים, ומנתח הקוד שאחראי על בניית עץ הניתוח על ידי ניתוח מבנה המסמך בהתאם לכללי התחביר של השפה.
הניתוח יודע להסיר תווים לא רלוונטיים כמו רווחים ופסיקים.
תהליך הניתוח הוא איטרטיבי. בדרך כלל, המנתח יבקש מהמנתח סמלים טקסטואליים (lexer) טוקן חדש וינסה להתאים את הטוקן לאחד מכללי התחביר. אם מתקבלת התאמה לכלל, צומת התואם לאסימון יתווסף לעץ הניתוח והמנתח יבקש אסימון נוסף.
אם לא נמצא כלל תואם, המנתח ישמור את האסימון באופן פנימי וימשיך לבקש אסימונים עד שימצא כלל שתואם לכל האסימונים שנשמרו באופן פנימי. אם לא נמצא כלל, מנתח ה-JSON יוצר חריגה. המשמעות היא שהמסמך לא היה תקין וכלול שגיאות תחביר.
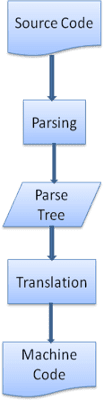
תרגום
במקרים רבים, עץ הניתוח הוא לא המוצר הסופי. ניתוח נתונים משמש לעיתים קרובות בתרגום: הוא מאפשר להפוך את מסמך הקלט לפורמט אחר. דוגמה לכך היא הידור. המהדר שמפיק קוד מקור לקוד מכונה קודם מבצע ניתוח ליצירת עץ ניתוח, ואז מתרגם את העץ למסמך של קוד מכונה.
דוגמה לניתוח
באיור 5 יצרנו עץ ניתוח מביטוי מתמטי. ננסה להגדיר שפה מתמטית פשוטה ולראות את תהליך הניתוח.
תחביר:
- אבני הבניין של תחביר השפה הן ביטויים, מונחים ופעולות.
- השפה שלנו יכולה לכלול מספר בלתי מוגבל של ביטויים.
- ביטוי מוגדר כ'מונח' ואחריו 'פעולה' ואחריה מונח נוסף
- פעולה היא אסימון פלוס או אסימון מינוס
- מונח הוא אסימון של מספר שלם או ביטוי
ננתח את הקלט 2 + 3 - 1.
מחרוזת המשנה הראשונה שתואמת לכלל היא 2: לפי כלל מס' 5, זוהי מונח.
ההתאמה השנייה היא 2 + 3: היא תואמת לכלל השלישי: מונח ואחריו פעולה ואחריו מונח נוסף.
ההתאמה הבאה תתבצע רק בסוף הקלט.
2 + 3 - 1 הוא ביטוי כי כבר יודעים ש-2 + 3 הוא מונח, כך שיש מונח ואחריו פעולה ואחריה מונח נוסף.
הערך 2 + + לא יתאים לאף כלל, ולכן הוא קלט לא תקין.
הגדרות פורמליות לאוצר המילים ולתחביר
בדרך כלל אוצר המילים מופיע כביטויים רגולריים.
לדוגמה, השפה שלנו תוגדר כך:
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -
כפי שרואים, מספרים שלמים מוגדרים באמצעות ביטוי רגולרי.
בדרך כלל, תחביר מוגדר בפורמט שנקרא BNF. השפה שלנו תוגדר כך:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
אמרנו שאפשר לנתח שפה באמצעות מנתחים רגילים אם הדקדוק שלה הוא דקדוק ללא הקשר. הגדרה אינטואיטיבית של דקדוק ללא הקשר היא דקדוק שאפשר לבטא אותו במלואו ב-BNF. להגדרה רשמית, ראו המאמר בוויקיפדיה על דקדוק ללא הקשר
סוגי מנתח הנתונים
יש שני סוגים של מנתחים: מנתחים מלמעלה למטה ומנתחים מלמטה למעלה. הסבר אינטואיטיבי הוא שמנתחי טקסט מלמעלה למטה בודקים את המבנה ברמה הגבוהה של התחביר ומנסים למצוא התאמה לכלל. מנתח מלמטה למעלה מתחיל מהקלט וממיר אותו בהדרגה לכללי התחביר, החל מהכללים ברמה הנמוכה עד לעמידה בכללים ברמה הגבוהה.
נראה איך שני סוגי המנתחים ינתחו את הדוגמה שלנו.
המנתח מלמעלה למטה יתחיל מהכלל ברמה הגבוהה יותר: הוא יזהה את 2 + 3 כביטוי. לאחר מכן, המערכת תזהה את 2 + 3 - 1 כביטוי (תהליך זיהוי הביטוי מתפתח בהתאם להתאמה לכללים האחרים, אבל נקודת ההתחלה היא הכלל ברמה הגבוהה ביותר).
המנתח מלמטה למעלה יסרוק את הקלט עד שימצא כלל שמתאים. לאחר מכן, המערכת תחליף את הקלט התואם בכלל. הפעולה הזו תמשיך עד לסיום הקלט. הביטוי שהותאם חלקית מועבר לסטאק של המנתח.
סוג המנתח הזה מלמטה למעלה נקרא מנתח shift-reduce, כי הקלט מוסט ימינה (אפשר לדמיין את הסמן מצביע קודם על תחילת הקלט וממשיך לנוע ימינה) ומצומצם בהדרגה לכללי תחביר.
יצירת מנתח באופן אוטומטי
יש כלים שיכולים ליצור מנתח. אתם מזינים את הדקדוק של השפה – אוצר המילים וכללי התחביר שלה – והן יוצרות מנתח שפועל. כדי ליצור מנתח צריך הבנה מעמיקה של ניתוח, ולא קל ליצור מנתח מותאם ביד, ולכן גנרטורים של מנתח יכולים להיות מאוד שימושיים.
ב-WebKit נעשה שימוש בשני מחוללי ניתוח ידועים: Flex ליצירת מנתח קוד ו-Bison ליצירת מנתח (יכול להיות שתראו אותם בשמות Lex ו-Yacc). קלט Flex הוא קובץ שמכיל הגדרות של ביטויים רגולריים של האסימונים. הקלט של Bison הוא כללי התחביר של השפה בפורמט BNF.
מנתח HTML
תפקיד מנתח ה-HTML הוא לנתח את תגי העיצוב של ה-HTML לעץ ניתוח.
דקדוק HTML
אוצר המילים והדקדוק של HTML מוגדרים במפרטים שנוצרו על ידי ארגון W3C.
כפי שראינו במבוא לניתוח, אפשר להגדיר באופן רשמי את התחביר הדקדוקי באמצעות פורמטים כמו BNF.
לצערנו, כל הנושאים הרגילים של מנתח הקוד לא חלים על HTML (לא הזכרתי אותם רק בשביל הכיף – הם ישמשו לניתוח של CSS ו-JavaScript). אי אפשר להגדיר בקלות את HTML באמצעות תחביר ללא הקשר שנחוץ למנתחים.
יש פורמט רשמי להגדרת HTML – DTD (Document Type Definition) – אבל זו לא תחביר ללא הקשר.
זה נראה מוזר במבט ראשון, כי HTML דומה מאוד ל-XML. יש הרבה מנתחני XML זמינים. יש וריאנט XML של HTML – XHTML – אז מה ההבדל הגדול?
ההבדל הוא שגישת ה-HTML 'סלחנית' יותר: היא מאפשרת להשמיט תגים מסוימים (שנוספים לאחר מכן באופן משתמע), או לפעמים להשמיט תגי התחלה או סיום וכו'. באופן כללי, זהו תחביר 'רך', בניגוד לתחביר הנוקשה והמאתגר של XML.
הפרט הזה, שנראה קטן, עושה את כל ההבדל. מצד אחד, זו הסיבה העיקרית לפופולריות של HTML: הוא סולח על הטעויות שלכם ומקל על החיים של מחברי האתרים. מצד שני, קשה לכתוב תחביר פורמלי. לסיכום, לא ניתן לנתח בקלות קובצי HTML באמצעות מנתחים רגילים, כי התחביר שלהם לא נטול הקשר. לא ניתן לנתח קובצי HTML באמצעות מנתח XML.
HTML DTD
ההגדרה של HTML היא בפורמט DTD. הפורמט הזה משמש להגדרת שפות ממשפחת SGML. הפורמט מכיל הגדרות לכל הרכיבים המותרים, למאפיינים ולהיררכיה שלהם. כפי שראינו קודם, ה-DTD של HTML לא יוצר תחביר ללא הקשר.
יש כמה וריאציות של DTD. המצב הקפדני תואם רק למפרטים, אבל מצבים אחרים מכילים תמיכה בסימון שדפדפנים השתמשו בו בעבר. המטרה היא תאימות לאחור לתוכן ישן יותר. ה-DTD הנוכחי הוא: www.w3.org/TR/html4/strict.dtd
DOM
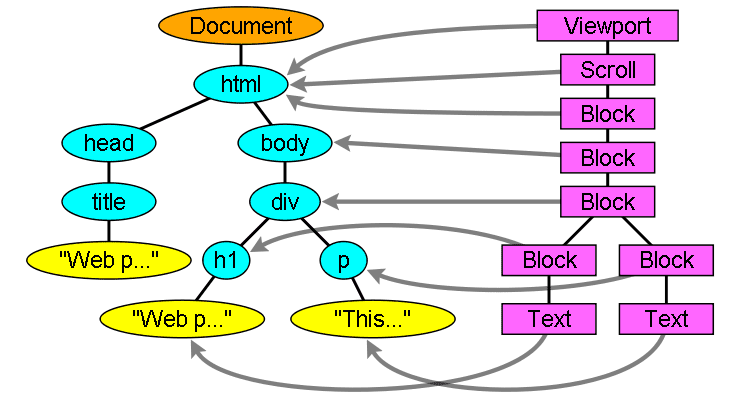
עץ הפלט ('עץ הניתוח') הוא עץ של צמתים של מאפיינים ורכיבי DOM. DOM הוא קיצור של Document Object Model (מודל אובייקט של מסמך). זהו ייצוג האובייקט של מסמך ה-HTML והממשק של רכיבי ה-HTML לעולם החיצון, כמו JavaScript.
שורש העץ הוא האובייקט Document.
ל-DOM יש קשר כמעט אחד לאחד לסימון. לדוגמה:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
תגי העיצוב האלה יתורגמו לעץ ה-DOM הבא:
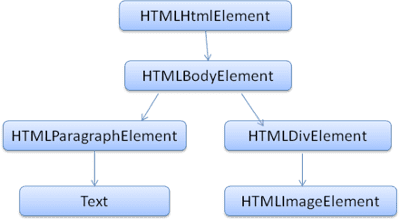
כמו HTML, גם DOM מוגדר על ידי ארגון W3C. מידע נוסף זמין בכתובת www.w3.org/DOM/DOMTR. זהו מפרט כללי לטיפול במסמכים. מודול ספציפי מתאר רכיבים ספציפיים של HTML. ההגדרות של HTML מפורטות כאן: www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html.
כשאני אומר שהעץ מכיל צמתים של DOM, הכוונה היא שהעץ מורכב מרכיבים שמטמיעים את אחד מממשקי ה-DOM. בדפדפנים נעשה שימוש בהטמעות קונקרטיות שיש להן מאפיינים אחרים שהדפדפן משתמש בהם באופן פנימי.
אלגוריתם הניתוח
כפי שראינו בקטעים הקודמים, אי אפשר לנתח HTML באמצעות מנתח רגיל מלמעלה למטה או מלמטה למעלה.
הסיבות לכך הן:
- אופי השפה שמאפשר לכם להתנסות.
- העובדה שלדפדפנים יש יכולת מסורתית לסבול שגיאות כדי לתמוך במקרים ידועים של HTML לא תקין.
- תהליך הניתוח הוא פוליגונומי. בשפות אחרות, המקור לא משתנה במהלך הניתוח, אבל ב-HTML, קוד דינמי (כמו רכיבי סקריפט שמכילים קריאות ל-
document.write()) יכול להוסיף אסימונים נוספים, כך שתהליך הניתוח למעשה משנה את הקלט.
מאחר שלא ניתן להשתמש בשיטות הניתוח הרגילות, הדפדפנים יוצרים מנתחים מותאמים אישית לניתוח HTML.
אלגוריתם הניתוח מתואר בפירוט במפרט HTML5. האלגוריתם מורכב משני שלבים: יצירת אסימונים ובניית עץ.
יצירת אסימונים היא הניתוח הלוקאלי, ניתוח הקלט לאסימונים. בין האסימונים של HTML יש תגי התחלה, תגי סיום, שמות מאפיינים וערכים של מאפיינים.
מחוללי האסימונים מזהים את האסימון, מעבירים אותו לבורא העץ ומשתמשים בתו הבא לזיהוי האסימון הבא, וכן הלאה עד סוף הקלט.
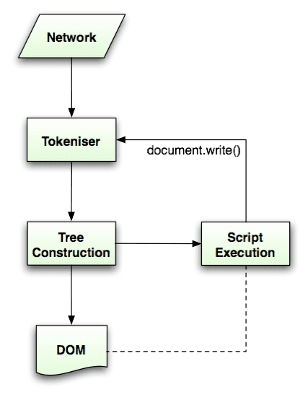
האלגוריתם להקצאת טוקנים
הפלט של האלגוריתם הוא אסימון HTML. האלגוריתם מתואר כמכונה מצבי. כל מצב צורך תו אחד או יותר מזרם הקלט ומעדכן את המצב הבא בהתאם לתוים האלה. ההחלטה מושפעת ממצב היצירה הנוכחי של האסימונים וממצב היצירה של העץ. המשמעות היא שאותו תו שנצרך יניב תוצאות שונות למצב הבא הנכון, בהתאם למצב הנוכחי. האלגוריתם מורכב מדי כדי לתאר אותו במלואו, לכן נציג דוגמה פשוטה שתעזור לנו להבין את העיקרון.
דוגמה בסיסית – יצירת אסימונים מקוד ה-HTML הבא:
<html>
<body>
Hello world
</body>
</html>
המצב הראשוני הוא 'מצב הנתונים'.
כשמתגלה התו <, המצב משתנה ל-'Tag open state'.
שימוש בתווית a-z יוצר 'אסימון של תג התחלה', והמצב משתנה ל-'מצב שם התג'.
אנחנו נשארים במצב הזה עד שתו ה-> מנוצל. כל תו מצורף לשם האסימון החדש. במקרה שלנו, הטוקן שנוצר הוא html.
כשמגיעים לתג >, האסימון הנוכחי נפלט והמצב חוזר ל'מצב נתונים'.
התג <body> יטופל באותו אופן.
עד עכשיו, התגים html ו-body הונפקו. אנחנו חוזרים אל 'מצב הנתונים'.
שימוש בתווית H של Hello world יגרום ליצירה ולהפצה של אסימון תו, והפעולה הזו תמשיך עד שמגיעים ל-< של </body>. נשמיע אסימון תו לכל תו של Hello world.
אנחנו חוזרים ל'מצב פתוח של תג'.
שימוש בקלט הבא / יגרום ליצירה של end tag token ולמעבר ל'מצב שם התג'. שוב, אנחנו נשארים במצב הזה עד שמגיעים ל->.לאחר מכן, אסימון התג החדש יופיע ונחזור ל'מצב נתונים'.
המערכת תתייחס לקלט </html> כמו למקרה הקודם.
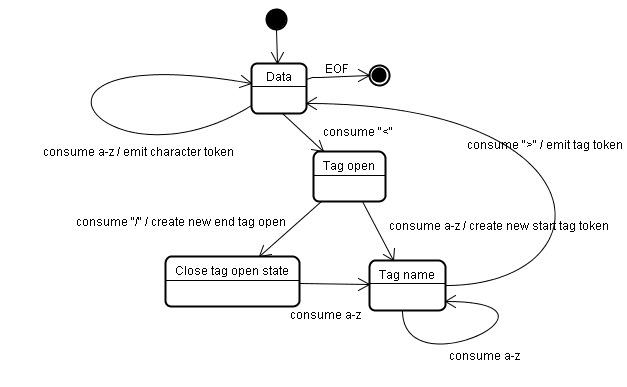
אלגוריתם ליצירת עץ
כשהמנתח נוצר, נוצר אובייקט Document. בשלב יצירת העץ, עץ ה-DOM עם המסמך בשורש שלו ישתנה ויתווספו אליו רכיבים. כל צומת שיופץ על ידי מחוללי המחרוזות יטופל על ידי ה-constructor של העץ. לכל אסימון, המפרט מגדיר איזה רכיב DOM רלוונטי לו וייווצר עבור האסימון הזה. הרכיב מתווסף לעץ ה-DOM וגם לסטאק של הרכיבים הפתוחים. הערימה הזו משמשת לתיקון אי-התאמות של עיטורים ותגים לא סגורים. האלגוריתם מתואר גם כמכונה מצבי. המצבים האלה נקראים 'מצבי הטמעה'.
נראה את תהליך יצירת העץ לפי הקלט לדוגמה:
<html>
<body>
Hello world
</body>
</html>
הקלט לשלב יצירת העץ הוא רצף של אסימונים משלב היצירה של האסימונים. המצב הראשון הוא 'המצב הראשוני'. קבלת האסימון 'html' תגרום למעבר למצב 'לפני html' ולעיבוד מחדש של האסימון במצב הזה. הפעולה הזו תגרום ליצירה של הרכיב HTMLHtmlElement, שיצורף לאובייקט Document ברמה הבסיסית.
המצב ישתנה ל-"before head". לאחר מכן מתקבל האסימון 'body'. המערכת תיצור באופן משתמע רכיב HTMLHeadElement, למרות שאין לנו אסימון 'head', והוא יתווסף לעץ.
עכשיו עוברים למצב 'בתוך הראש' ואז למצב 'אחרי הראש'. טוקן הגוף עובר עיבוד מחדש, נוצר ומוחדר רכיב HTMLBodyElement והמצב מועבר ל-"in body".
עכשיו מתקבלים אסימוני התווים של המחרוזת 'Hello world'. התו הראשון יגרום ליצירה ולהוספה של צומת 'טקסט', והתווים האחרים יתווספו לצומת הזה.
קבלת האסימון לסיום הגוף תגרום להעברה למצב 'אחרי הגוף'. עכשיו נקבל את תג הסיום של ה-HTML, שיעביר אותנו למצב 'אחרי אחרי body'. קבלת האסימון של סוף הקובץ תסתיים את הניתוח.
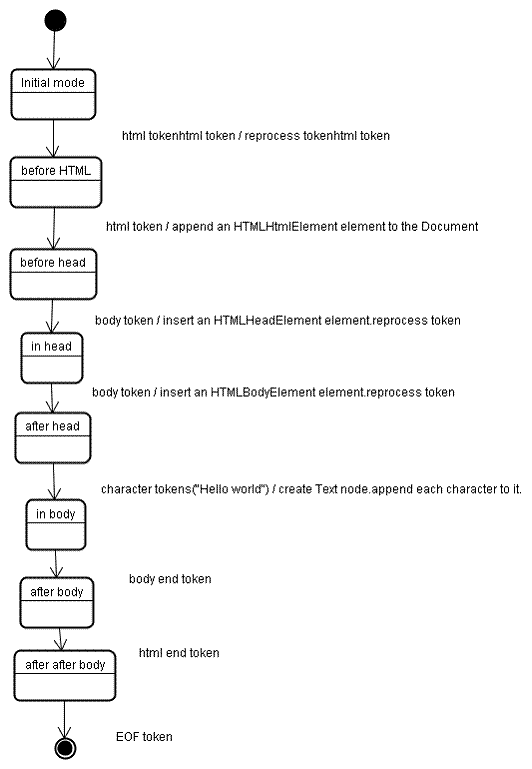
פעולות לביצוע בסיום הניתוח
בשלב הזה הדפדפן יסמן את המסמך כאינטראקטיבי ויתחיל לנתח סקריפטים שנמצאים במצב 'מושהה': אלה שצריך להריץ אחרי ניתוח המסמך. לאחר מכן, מצב המסמך יוגדר כ'הושלם' ויופעל אירוע 'טעינה'.
האלגוריתמים המלאים ליצירת אסימונים ולבניית עץ מפורטים במפרט HTML5.
הסבילות לשגיאות בדפדפנים
אף פעם לא מופיעה השגיאה 'תחביר לא תקין' בדף HTML. הדפדפנים מתקנים תוכן לא תקין וממשיכים.
לדוגמה, הקוד הבא ב-HTML:
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
בטח הפרתי מיליון כללים ('mytag' הוא לא תג רגיל, עיצוב תצוגה שגוי של הרכיבים 'p' ו-'div' ועוד), אבל הדפדפן עדיין מציג את זה בצורה נכונה ולא מתלונן. לכן, חלק גדול מקוד המנתח מיועד לתיקון הטעויות של מחברי ה-HTML.
טיפול בשגיאות הוא עקבי למדי בדפדפנים, אבל באופן מפתיע הוא לא היה חלק מהמפרטים של HTML. כמו סימניות ולחצני 'הקודם'/'הבא', זה פשוט משהו שהתפתח בדפדפנים במשך השנים. יש מבנים HTML לא חוקיים ידועים שמופיעים באתרים רבים, והדפדפנים מנסים לתקן אותם באופן תואם לדפדפנים אחרים.
חלק מהדרישות האלה מוגדרות במפרט HTML5. (הסבר מפורט על כך מופיע בתגובה בתחילת הכיתה של מנתח ה-HTML ב-WebKit).
המנתח מנתח את הקלט המפוצל לאסימונים במסמך, ובונה את עץ המסמך. אם המסמך תקין, הניתוח שלו פשוט.
לצערנו, אנחנו צריכים לטפל במסמכי HTML רבים שלא נוצרו בצורה תקינה, ולכן מנתח ה-HTML צריך להיות סובלני לשגיאות.
אנחנו צריכים לטפל לפחות בתנאי השגיאה הבאים:
- אסור להוסיף את הרכיב הזה באופן מפורש בתוך תג חיצוני כלשהו. במקרה כזה, צריך לסגור את כל התגים עד לתג שאוסר את הרכיב, ולהוסיף אותו לאחר מכן.
- אסור לנו להוסיף את הרכיב ישירות. יכול להיות שהאדם שכתב את המסמך שכח תג כלשהו באמצע (או שהתג באמצע הוא אופציונלי). זה יכול לקרות עם התגים הבאים: HTML HEAD BODY TBODY TR TD LI (שכחתי תג כלשהו?).
- אנחנו רוצים להוסיף רכיב בלוק בתוך רכיב בשורה. סוגרים את כל הרכיבים בשורה עד לרכיב הבלוקים הבא ברמה גבוהה יותר.
- אם הפעולה הזו לא עוזרת, אפשר לסגור רכיבים עד שנקבל הרשאה להוסיף את הרכיב – או להתעלם מהתג.
ריכזנו כאן כמה דוגמאות לסובלנות לשגיאות ב-WebKit:
</br> במקום <br>
בחלק מהאתרים נעשה שימוש ב-</br> במקום ב-<br>. כדי להיות תואם ל-IE ול-Firefox, WebKit מתייחס לזה כמו ל-<br>.
הקוד:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
חשוב לזכור שהטיפול בשגיאות הוא פנימי: הוא לא יוצג למשתמש.
טבלה חסרה
טבלה חסרת בית היא טבלה בתוך טבלה אחרת, אבל לא בתוך תא בטבלה.
לדוגמה:
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
מערכת WebKit תשנה את ההיררכיה לשתי טבלאות אחיות:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
הקוד:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
מערכת WebKit משתמשת בסטאק לתוכן הרכיב הנוכחי: היא תגרום להוצאה של הטבלה הפנימית מהסטאק של הטבלה החיצונית. הטבלאות יהיו עכשיו אחיות.
רכיבי טפסים בתצוגת עץ
אם המשתמש מכניס טופס לתוך טופס אחר, המערכת תתעלם מהטופס השני.
הקוד:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
היררכיית תגים עמוקה מדי
התגובה מדברת בעד עצמה.
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
תגי סיום של body או HTML ממוקמים באופן שגוי
שוב – התגובה מדברת בעד עצמה.
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
לכן, יוצרים של אתרים צריכים להיזהר – אלא אם אתם רוצים להופיע כדוגמה בקטע קוד של WebKit עם סובלנות לשגיאות – עליכם לכתוב קוד HTML תקין.
ניתוח CSS
זוכרים את מושגי הניתוח מהמבוא? בניגוד ל-HTML, CSS הוא תחביר ללא הקשר, ואפשר לנתח אותו באמצעות סוגי המנתחים שמתוארים בהקדמה. למעשה, מפרט ה-CSS מגדיר את תחביר הלקסיקון והתחביר של CSS.
ריכזנו כאן כמה דוגמאות:
הדקדוק הליקסי (אוצר המילים) מוגדר באמצעות ביטויים רגולריים לכל אסימון:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
"ident" הוא קיצור של המילה identifier (מזהה), כמו שם של מחלקה. 'name' הוא מזהה רכיב (שמצוין באמצעות '#')
דקדוק התחביר מתואר ב-BNF.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
הסבר:
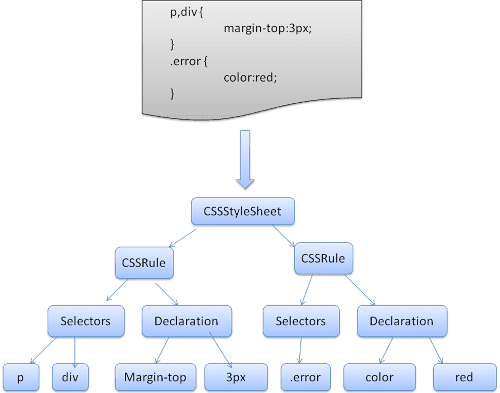
קבוצת כללים היא בעלת המבנה הבא:
div.error, a.error {
color:red;
font-weight:bold;
}
div.error ו-a.error הם בוררים. החלק בתוך סוגריים מסולסלים מכיל את הכללים שחלים על קבוצת הכללים הזו.
המבנה הזה מוגדר באופן רשמי בהגדרה הבאה:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
כלומר, כלל הוא סלקטור או מספר סלקטורים, מופרדים באמצעות פסיק ורווחים (S מייצג רווח). כללי התנהגות מכילים סוגריים מסולסלים, ובתוכם הצהרה או מספר הצהרות (אופציונלי) המופרדות באמצעות נקודה-פסיק. המונחים 'הצהרה' ו'סלקטור' יוגדרו בהגדרות ה-BNF הבאות.
מנתח CSS של WebKit
מערכת WebKit משתמשת במחוללי מנתח של Flex ו-Bison כדי ליצור מנתחים באופן אוטומטי מקובצי הדקדוק של CSS. כפי שציינו בהקדמה למעבד, Bison יוצרת מעבד שפה שמבוסס על שינוי והפחתה מלמטה למעלה. ב-Firefox נעשה שימוש בניתוח מלמעלה למטה שנכתב באופן ידני. בשני המקרים, כל קובץ CSS מנותח לאובייקט StyleSheet. כל אובייקט מכיל כללי CSS. אובייקטי הכללים של CSS מכילים אובייקטים של סלקטורים והצהרות, ואובייקטים אחרים שתואמים לדקדוק של CSS.
סדר העיבוד של סקריפטים וגיליונות סגנונות
סקריפטים
המודל של האינטרנט הוא סינכרוני. מחברי סקריפטים מצפים שהם יעברו ניתוח ויופעלו באופן מיידי כשמנתח הנתונים מגיע לתג <script>.
ניתוח המסמך מושהה עד להרצת הסקריפט.
אם הסקריפט הוא חיצוני, קודם צריך לאחזר את המשאב מהרשת – הפעולה הזו מתבצעת גם באופן סינכרוני, והניתוח מושהה עד לאחזור המשאב.
זה היה המודל במשך שנים רבות, והוא מצוין גם במפרטי HTML4 ו-HTML5.
מחברים יכולים להוסיף את המאפיין 'השהיה' לסקריפט. במקרה כזה, הוא לא יפסיק את ניתוח המסמך ויתבצע אחרי ניתוח המסמך. ב-HTML5 נוספת אפשרות לסמן את הסקריפט כלא אסינכרוני, כך שהוא ינותח ויתבצע על ידי שרשור אחר.
ניתוח ספקולטיבי
גם WebKit וגם Firefox מבצעים את האופטימיזציה הזו. בזמן ביצוע הסקריפטים, חוט אחר מנתח את שאר המסמך ומוצא אילו משאבים אחרים צריך לטעון מהרשת, ומטעין אותם. כך אפשר לטעון משאבים בחיבורים מקבילים ולשפר את המהירות הכוללת. הערה: המנתח השערוני מנתח רק הפניות למשאבים חיצוניים כמו סקריפטים חיצוניים, גיליונות סגנונות ותמונות: הוא לא משנה את עץ ה-DOM – זה נשאר למנתח הראשי.
גיליונות סגנונות
לעומת זאת, לגיליון סגנונות יש מודל שונה. מבחינה מושגית, נראה שאין סיבה להמתין לגיליונות הסגנונות ולהפסיק את ניתוח המסמך, כי הם לא משנים את עץ ה-DOM. עם זאת, יש בעיה עם סקריפטים שמבקשים מידע על סגנון במהלך שלב הניתוח של המסמך. אם הסגנון עדיין לא נטען ונותח, הסקריפט יקבל תשובות שגויות, וככל הנראה זה גרם לבעיות רבות. נראה שמדובר בתרחיש קיצוני, אבל הוא די נפוץ. דפדפן Firefox חוסם את כל הסקריפטים כשיש גיליון סגנונות שעדיין נטען ומנותח. WebKit חוסם סקריפטים רק כשהם מנסים לגשת למאפייני סגנון מסוימים שעשויים להיות מושפעים מגיליונות סגנון שלא הועלו.
בניית עץ הרינדור
בזמן יצירת עץ ה-DOM, הדפדפן יוצר עץ נוסף, עץ הרינדור. העץ הזה מכיל אלמנטים חזותיים בסדר שבו הם יוצגו. זהו הייצוג החזותי של המסמך. מטרת העץ הזה היא לאפשר ציור של התוכן בסדר הנכון.
ב-Firefox, הרכיבים בעץ הרינדור נקראים 'פריימים'. ב-WebKit נעשה שימוש במונח 'כלי רינדור' או 'אובייקט רינדור'.
למעבד גרפיקה יש אפשרות למקם ולצייר את עצמו ואת הצאצאים שלו.
הגדרת הכיתה RenderObject של WebKit, הכיתה הבסיסית של המכשירים להצגת גרפיקה, היא:
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
כל רכיב עיבוד מייצג אזור מלבני שתואם בדרך כלל לתיבת ה-CSS של צומת, כפי שמתואר במפרט CSS2. הוא כולל מידע גיאומורפי כמו רוחב, גובה ומיקום.
סוג התיבה מושפע מהערך 'display' של מאפיין הסגנון שרלוונטי לצומת (ראו הקטע חישוב הסגנון). זהו קוד WebKit להחלטה איזה סוג של עיבוד (renderer) צריך ליצור לצומת DOM, בהתאם למאפיין התצוגה:
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
המערכת גם מביאה בחשבון את סוג הרכיב: לדוגמה, לפקדות בטופס ולטבלאות יש מסגרות מיוחדות.
ב-WebKit, אם רכיב רוצה ליצור עיבוד מיוחד, הוא יגביל את השיטה createRenderer().
הרסטוררים מפנים לאובייקטי סגנון שמכילים מידע לא גיאומורפי.
הקשר של עץ הרינדור לעץ ה-DOM
הרסטוררים תואמים לרכיבי DOM, אבל היחס הוא לא אחד לאחד. רכיבי DOM לא חזותיים לא ייכללו בעץ הרינדור. דוגמה לכך היא הרכיב 'head'. בנוסף, אלמנטים שהערך שלהם בתצוגה הוקצה ל-'none' לא יופיעו בעץ (אבל אלמנטים עם רמת חשיפה 'מוסתרת' יופיעו בעץ).
יש רכיבי DOM שתואמים לכמה אובייקטים חזותיים. בדרך כלל מדובר ברכיבים עם מבנה מורכב שלא ניתן לתאר באמצעות מלבן אחד. לדוגמה, לאלמנט 'select' יש שלושה מנועי עיבוד: אחד לאזור התצוגה, אחד לתיבת הרשימה הנפתחת ואחד לכפתור. כמו כן, כשטקסט מחולק לכמה שורות כי הרוחב לא מספיק לשורה אחת, השורות החדשות יתווספו כמעבדי גרפיקה נוספים.
דוגמה נוספת למספר מנועי עיבוד היא HTML שגוי. לפי מפרט ה-CSS, אלמנט בשורה חייב להכיל רק רכיבי בלוק או רק רכיבים בשורה. במקרה של תוכן מעורב, המערכת תיצור רכיבי עיבוד אנונימיים של בלוקים כדי לעטוף את הרכיבים שמוצגים בתוך שורות הטקסט.
חלק מאובייקטי הרינדור תואמים לצומת DOM, אבל לא באותו מקום בעץ. רכיבים צפים ורכיבים שממוקמים באופן מוחלט לא נמצאים בזרימה, הם ממוקמים בחלק אחר של העץ וממופים למסגרת האמיתית. מסגרת placeholder תופיע במקום שבו אמורים להופיע התמונות.
תהליך היצירה של העץ
ב-Firefox, המצגת רשומה כמאזין לעדכוני DOM.
היצירה מעבירה את היצירה של המסגרת ל-FrameConstructor, והמבנה קובע את הסגנון (ראו חישוב הסגנון) ויוצר מסגרת.
ב-WebKit, התהליך של פתרון הסגנון ויצירת המנגן נקרא 'צירוף'. לכל צומת DOM יש שיטה 'attach'. הצירוף הוא סינכרוני, והוספת הצומת לעץ ה-DOM גורמת לקריאה ל-method 'attach' של הצומת החדש.
עיבוד התגים html ו-body מוביל ליצירת הבסיס של עץ הרינדור.
אובייקט הרינדור ברמה הבסיסית (root) תואם למה שמוגדר במפרט CSS כבלוק המכיל: הבלוק העליון שמכיל את כל שאר הבלוקים. המימדים שלו הם אזור התצוגה: המימדים של אזור התצוגה בחלון הדפדפן.
ב-Firefox הוא נקרא ViewPortFrame וב-WebKit הוא נקרא RenderView.
זהו אובייקט הרינדור שאליו המסמך מפנה.
שאר העץ נוצר כהוספה של צומתי DOM.
המפרט של CSS2 לגבי מודל העיבוד
חישוב סגנון
כדי ליצור את עץ הרינדור, צריך לחשב את המאפיינים החזותיים של כל אובייקט רינדור. כדי לעשות זאת, מחשבים את מאפייני הסגנון של כל רכיב.
הסגנון כולל גיליונות סגנונות ממקורות שונים, רכיבי סגנון מוטמעים ומאפיינים חזותיים ב-HTML (כמו המאפיין 'bgcolor').המאפיינים האחרונים מתורגמים למאפייני סגנון CSS תואמים.
מקורות הגיליונות הם גיליונות הסגנון שמוגדרים כברירת מחדל בדפדפן, גיליונות הסגנון שסופקו על ידי מחבר הדף וגיליונות הסגנון של המשתמש – אלה גיליונות סגנון שסופקו על ידי משתמש הדפדפן (דפדפנים מאפשרים לכם להגדיר את הסגנונות המועדפים עליכם. לדוגמה, ב-Firefox, עושים זאת על ידי הוספת גיליון סגנונות לתיקייה 'פרופיל Firefox').
חישוב הסגנון כרוך בכמה קשיים:
- נתוני הסגנון הם מבנה גדול מאוד שמכיל את מאפייני הסגנון הרבים, ויכול לגרום לבעיות בזיכרון.
חיפוש כללי ההתאמה לכל רכיב עלול לגרום לבעיות בביצועים אם לא מבצעים אופטימיזציה. סריקה של כל רשימת הכללים לכל רכיב כדי למצוא התאמות היא משימה קשה. לבוררים יכול להיות מבנה מורכב שעלול לגרום לתהליך ההתאמה להתחיל בנתיב שנראה מבטיח אבל מתברר שהוא לא מוביל לתוצאה, ולכן צריך לנסות נתיב אחר.
לדוגמה, הבורר המורכב הזה:
div div div div{ ... }המשמעות היא שהכללים חלים על
<div>שהוא הצאצא של 3 divs. נניח שרוצים לבדוק אם הכלל חל על רכיב<div>נתון. בוחרים נתיב מסוים בעץ לבדיקה. יכול להיות שתצטרכו לעבור למעלה בעץ הצמתים כדי לגלות שיש רק שני div והכלל לא חל. לאחר מכן, צריך לנסות נתיבים אחרים בעץ.כדי להחיל את הכללים, צריך להשתמש בכללי שרשור מורכבים למדי שמגדירים את היררכיית הכללים.
נראה איך הדפדפנים מתמודדים עם הבעיות האלה:
שיתוף נתוני סגנון
צמתים של WebKit מפנים לאובייקטי סגנון (RenderStyle). אפשר לשתף את האובייקטים האלה בין צמתים בתנאים מסוימים. הצמתים הם אחים או בני דודים, ו:
- האלמנטים חייבים להיות באותו מצב של העכבר (למשל, לא ניתן להגדיר לאחד מהם את המצב :hover בזמן שהמצב הזה לא מוגדר לשני)
- לאף אחד מהרכיבים לא צריך להיות מזהה
- שמות התגים צריכים להיות זהים
- מאפייני הכיתה צריכים להתאים
- קבוצת המאפיינים הממופים חייבת להיות זהה
- מצבי הקישור צריכים להיות זהים
- מצבי המיקוד צריכים להיות זהים
- אף אחד מהרכיבים לא אמור להיות מושפע מבוררי מאפיינים, כאשר 'מושפע' מוגדר כקיומו של התאמה לבורר שמשתמש בבורר מאפיינים בכל מיקום בתוך הבורר.
- אסור שיהיה מאפיין סגנון בתוך השורה ברכיבים
- אסור להשתמש בכלל בבוררים של אחים. כשנתקלים בבורר אחים, WebCore פשוט מפעיל מתג גלובלי ומשבית את שיתוף הסגנונות בכל המסמך אם הבוררים האלה נמצאים. זה כולל את הסלקטורים + ו-:first-child ו-:last-child.
עץ הכללים של Firefox
ב-Firefox יש שני עצים נוספים לחישוב קל יותר של סגנונות: עץ הכללים ועץ ההקשר של הסגנון. ל-WebKit יש גם אובייקטים של סגנונות, אבל הם לא מאוחסנים בעץ כמו עץ ההקשר של הסגנון. רק צומת ה-DOM מפנה לסגנון הרלוונטי שלו.
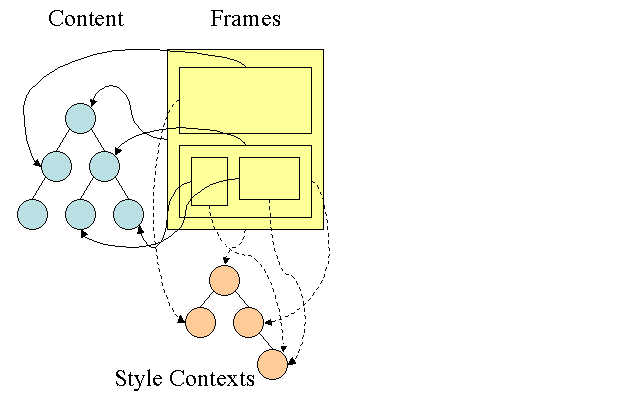
הקשרי הסגנון מכילים ערכים סופיים. הערכים מחושבים על ידי החלת כל כללי ההתאמה בסדר הנכון וביצוע פעולות מניפולציה שמעבירות אותם מערכים לוגיים לערכים קונקרטיים. לדוגמה, אם הערך הלוגי הוא אחוז מהמסך, הוא יחושב ויעבור טרנספורמציה ליחידות מוחלטות. הרעיון של עץ הכללים הוא ממש חכם. הוא מאפשר לשתף את הערכים האלה בין צמתים כדי למנוע חישוב שלהם שוב. כך גם חוסכים מקום.
כל הכללים שהותאמו מאוחסנים בעץ. לצמתים התחתונים בנתיב יש עדיפות גבוהה יותר. העץ מכיל את כל הנתיבים להתאמות של כללים שנמצאו. אחסון הכללים מתבצע באופן עצל. העץ לא מחושב בהתחלה לכל צומת, אבל בכל פעם שצריך לחשב סגנון של צומת, הנתיבים המחושבים מתווספים לעץ.
הרעיון הוא לראות את נתיבי העץ כמילים במילון. נניח שכבר חישבנו את עץ הכללים הזה:
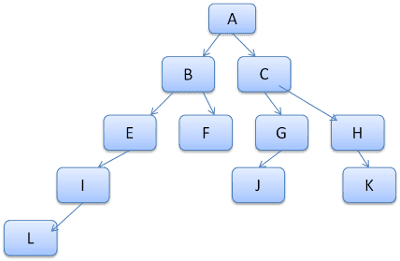
נניח שאנחנו צריכים להתאים כללים לרכיב אחר בעץ התוכן, ומגלים שהכללים שתואמים (בסדר הנכון) הם B-E-I. הנתיב הזה כבר קיים בעץ כי כבר חישבנו את הנתיב A-B-E-I-L. עכשיו יהיה לנו פחות עבודה.
נראה איך העץ חוסך לנו עבודה.
חלוקה למבנים
הקשרי הסגנון מחולקים למבנים. המבנים האלה מכילים מידע על סגנון של קטגוריה מסוימת, כמו גבול או צבע. כל המאפיינים במבנה הם בירושה או לא בירושה. מאפיינים שעוברים בירושה הם מאפיינים שעוברים בירושה מהאלמנט ההורה, אלא אם הם מוגדרים על ידי האלמנט. במאפיינים שלא עוברים בירושה (שנקראים מאפייני 'איפוס') נעשה שימוש בערכי ברירת מחדל אם הם לא מוגדרים.
בעזרת העץ אנחנו שומרים במטמון מבנים שלמים (שמכילים את ערכי הסיום המחושבים) בעץ. הרעיון הוא שאם הצומת התחתון לא סיפק הגדרה ל-struct, אפשר להשתמש ב-struct ששמור במטמון בצומת גבוה יותר.
חישוב ההקשרים של הסגנון באמצעות עץ הכללים
כשמחשבים את הקשר הסגנון של רכיב מסוים, קודם מחשבים נתיב בעץ הכללים או משתמשים בנתיב קיים. לאחר מכן מתחילים להחיל את הכללים בנתיב כדי למלא את המבנים בקונטקסט של הסגנון החדש. אנחנו מתחילים בצומת התחתון של הנתיב – זה עם העדיפות הגבוהה ביותר (בדרך כלל הבורר הספציפי ביותר) ועוברים בעץ עד שהמבנה שלנו מלא. אם אין מפרט של המבנה באותו צומת של הכלל, אנחנו יכולים לבצע אופטימיזציה משמעותית – אנחנו עולים על העץ עד שאנחנו מוצאים צומת שמפרט אותו באופן מלא ומצביע עליו – זו האופטימיזציה הטובה ביותר – המבנה כולו משותף. כך חוסכים בזיכרון ובחישוב של ערכי הסיום.
אם נמצא הגדרות חלקיות, נמשיך לעלות בעץ עד שהמבנה יתמלא.
אם לא מצאנו הגדרות למבנה הנתונים, במקרה שהוא מסוג 'עובר בירושה', אנחנו מפנים למבנה הנתונים של ההורה בעץ ההקשר. במקרה הזה הצלחנו גם לשתף מבנים. אם מדובר במבנה reset, המערכת תשתמש בערכי ברירת המחדל.
אם הצומת הספציפי ביותר מוסיף ערכים, צריך לבצע חישובים נוספים כדי להפוך אותו לערכים בפועל. לאחר מכן אנחנו שומרים את התוצאה במטמון בצומת העץ כדי שצאצאים יוכלו להשתמש בה.
אם לרכיב יש אח או אחות שמצביעים על אותו צומת עץ, אפשר לשתף ביניהם את כל הקשר הסגנון.
בואו נראה דוגמה: נניח שיש לנו את הקוד הבא ב-HTML
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
וגם את הכללים הבאים:
div {margin: 5px; color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
כדי לפשט את הדברים, נניח שאנחנו צריכים למלא רק שני מבני struct: מבנה ה-struct של הצבע ומבנה ה-struct של השוליים. המבנה color מכיל רק חבר אחד: הצבע. המבנה margin מכיל את ארבעת הצדדים.
עץ הכללים שייווצר ייראה כך (הצומתים מסומנים בשם הצומת: מספר הכלל שאליו הם מפנים):
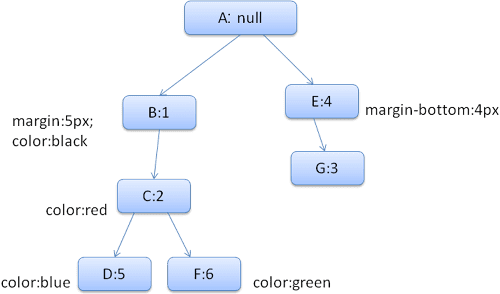
עץ ההקשר ייראה כך (שם הצומת: צומת הכלל שאליו הוא מפנה):
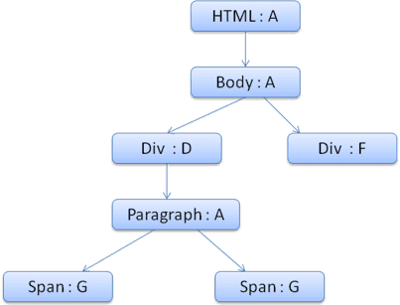
נניח שאנחנו מנתחים את ה-HTML ומגיעים לתג <div> השני. אנחנו צריכים ליצור הקשר סגנון לצומת הזה ולמלא את מבני הנתונים של הסגנון שלו.
נתאמת את הכללים ונגלה שכללי ההתאמה של <div> הם 1, 2 ו-6.
כלומר, כבר יש נתיב קיים בעץ שבו הרכיב שלנו יכול להשתמש, ואנחנו רק צריכים להוסיף אליו צומת נוסף עבור כלל 6 (צומת F בעץ הכללים).
נוצר הקשר סגנון ונוסיף אותו לעץ ההקשר. ההקשר של הסגנון החדש יצביע על הצומת F בעץ הכללים.
עכשיו אנחנו צריכים למלא את המבנים של הסגנונות. נתחיל במילוי המבנה של השוליים. מאחר שצומת הכלל האחרון (F) לא מוסיף למבנה של השוליים, אפשר לעלות במורד העץ עד שמוצאים מבנה ששמור במטמון וחושב בהוספת צומת קודמת, ולהשתמש בו. נמצא אותו בצומת B, שהוא הצומת העליון שבו צוינו כללי שוליים.
יש לנו הגדרה למבנה הצבעים, ולכן אנחנו לא יכולים להשתמש במבנה ששמור במטמון. מכיוון שלצבע יש מאפיין אחד, אין צורך לעלות למעלה בעץ כדי למלא מאפיינים אחרים. נחשב את ערך הסיום (נמיר מחרוזת ל-RGB וכו') ונשמור במטמון את המבנה המחושב בצומת הזה.
העבודה על הרכיב השני <span> היא עוד יותר קלה. נבצע התאמה של הכללים ונגיע למסקנה שהוא מפנה לכלל G, כמו ה-span הקודם.
מכיוון שיש לנו אחים שמפנים לאותו צומת, אנחנו יכולים לשתף את כל הקשר הסגנון ולהפנות רק להקשר של הפס הקודם.
למבנים שמכילים כללים שעוברים בירושה מההורה, האחסון במטמון מתבצע בעץ ההקשר (מאפיין הצבע עובר בירושה, אבל Firefox מתייחס אליו כאל איפוס ומאחסן אותו במטמון בעץ הכללים).
לדוגמה, אם הוספנו כללים לגופנים בפסקה:
p {font-family: Verdana; font size: 10px; font-weight: bold}
במקרה כזה, אלמנט הפסקה, שהוא צאצא של ה-div בעץ ההקשר, יכול היה לשתף את אותה מבנה גופן כמו ההורה שלו. זה קורה אם לא צוינו כללי גופן לפסקה.
ב-WebKit, שאין בו עץ כללים, ההצהרות שתואמות עוברות סריקה ארבע פעמים. קודם מופעלים כללים לא חשובים בעדיפות גבוהה (נכסים שצריך להחיל קודם כי אחרים תלויים בהם, כמו תצוגה), אחר כך כללים חשובים בעדיפות גבוהה, אחר כך כללים לא חשובים בעדיפות רגילה ואז כללים חשובים בעדיפות רגילה. המשמעות היא שמאפיינים שמופיעים כמה פעמים ימומשו לפי סדר התורן הנכון. האחרון מנצח.
לסיכום: שיתוף אובייקטי הסגנון (במלואם או חלק מהמבנים הפנימיים שלהם) פותר את הבעיות 1 ו-3. עץ הכללים של Firefox עוזר גם להחיל את המאפיינים בסדר הנכון.
מניפולציה של הכללים לצורך התאמה קלה
יש כמה מקורות לכללי סגנון:
- כללי CSS, בגיליונות סגנונות חיצוניים או ברכיבי סגנון.
css p {color: blue} - מאפייני סגנון בתוך השורה, כמו
html <p style="color: blue" /> - מאפיינים חזותיים של HTML (שמותאמים לכללי סגנון רלוונטיים)
html <p bgcolor="blue" />שני המאפיינים האחרונים תואמים בקלות לרכיב, כי הוא הבעלים של מאפייני הסגנון, וניתן למפות מאפייני HTML באמצעות הרכיב בתור המפתח.
כפי שציינתי קודם בבעיה מס' 2, ההתאמה של כללי ה-CSS יכולה להיות מורכבת יותר. כדי לפתור את הבעיה, משנים את הכללים כדי לאפשר גישה נוחה יותר.
אחרי ניתוח גיליון הסגנונות, הכללים מתווספים לאחת מכמה מפות גיבוב, בהתאם לבורר. יש מפות לפי מזהה, לפי שם הכיתה, לפי שם התג ומפה כללית לכל מה שלא מתאים לקטגוריות האלה. אם הבורר הוא מזהה, הכלל יתווסף למפת המזהים, אם הוא כיתה, הוא יתווסף למפת הכיתות וכו'.
כך קל יותר להתאים את הכללים. אין צורך לבדוק בכל הצהרה: אנחנו יכולים לחלץ מהמפות את הכללים הרלוונטיים לאלמנט. האופטימיזציה הזו מסירה יותר מ-95% מהכללים, כך שאין צורך אפילו להביא אותם בחשבון במהלך תהליך ההתאמה(4.1).
לדוגמה, אלה כללי הסגנון הבאים:
p.error {color: red}
#messageDiv {height: 50px}
div {margin: 5px}
הכלל הראשון יתווסף למיפוי הכיתות. השני למיפוי המזהים והשלישי למיפוי התגים.
בקטע ה-HTML הבא:
<p class="error">an error occurred</p>
<div id=" messageDiv">this is a message</div>
קודם ננסה למצוא כללים לרכיב p. מפת הכיתה תכיל מפתח 'error', שבמסגרתו נמצא הכלל של 'p.error'. לאלמנט ה-div יהיו כללים רלוונטיים במיפוי המזהים (המפתח הוא המזהה) ובמפת התגים. כל מה שנשאר לעשות הוא לבדוק אילו מהכללים שחולצו על ידי המפתחות אכן תואמים.
לדוגמה, אם הכלל של ה-div היה:
table div {margin: 5px}
הוא עדיין יופק ממפת התגים, כי המפתח הוא הבורר הימני ביותר, אבל הוא לא יתאים לרכיב ה-div שלנו, שאין לו אב טבלה.
גם WebKit וגם Firefox מבצעים את אותה מניפולציה.
סדר היררכי של גיליונות סגנונות
לאובייקט הסגנון יש מאפיינים שתואמים לכל מאפיין חזותי (כל מאפייני ה-CSS, אבל בצורה כללית יותר). אם הנכס לא מוגדר באף אחד מהכללים שתואמים לו, חלק מהמאפיינים יכולים לעבור בירושה לאובייקט הסגנון של אלמנט ההורה. למאפיינים אחרים יש ערכי ברירת מחדל.
הבעיה מתחילה כשיש יותר מהגדרה אחת – כאן מגיע סדר ההעברה (cascade) כדי לפתור את הבעיה.
הצהרה על מאפיין סגנון יכולה להופיע בכמה גיליונות סגנונות, וכמה פעמים בתוך גיליון סגנונות. כלומר, סדר החלת הכללים חשוב מאוד. הסדר הזה נקרא 'סדר מדורג'. לפי מפרט CSS2, סדר המפל הוא (מהנמוך לגבוה):
- הצהרות בדפדפן
- הצהרות רגילות של משתמשים
- הצהרות רגילות של מחברים
- כתיבת הצהרות חשובות
- הצהרות חשובות למשתמש
הצהרות הדפדפן הן הפחות חשובות, והמשתמש מבטל את ההצהרה של המחבר רק אם ההצהרה סומנה כחשובה. הצהרות באותו סדר ימוינו לפי רמת הספציפיות ולאחר מכן לפי הסדר שבו הן צוינו. המאפיינים החזותיים של HTML מתורגמים להצהרות CSS תואמות . הם נחשבים לכללים של המחבר עם עדיפות נמוכה.
ספציפיות
הספציפיות של הסלקטורים מוגדרת במפרט CSS2 באופן הבא:
- ספירה של 1 אם ההצהרה שממנה היא מגיעה היא מאפיין 'style' ולא כלל עם סלקטור, 0 אחרת (= a)
- ספירת מספר מאפייני המזהה בבורר (= b)
- ספירת מספר המאפיינים והפסאודו-כיתות האחרים בבורר (= c)
- ספירת מספר שמות הרכיבים והפסאודו-רכיבים בבורר (= d)
שרשור של ארבעת המספרים a-b-c-d (במערכת מספרים עם בסיס גדול) נותן את הספציפיות.
בסיס המספר שבו צריך להשתמש מוגדר לפי המספר הגבוה ביותר שיש לכם באחת מהקטגוריות.
לדוגמה, אם a=14, אפשר להשתמש בבסיס הקסדצימלי. במקרה הלא סביר שבו a=17, תצטרכו בסיס מספרי של 17 ספרות. המצב השני יכול לקרות עם בורר כזה: html body div div p… (17 תגים בבורר… לא סביר מאוד).
מספר דוגמאות:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
מיון הכללים
אחרי שהכללים מותאמים, הם ממוינים לפי כללי המפל.
ב-WebKit נעשה שימוש במיון בועות לרשימות קטנות ובמיון מיזוג לרשימות גדולות.
WebKit מטמיע את המיון על ידי שינוי של אופרטור > לכללים:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
תהליך הדרגתי
מערכת WebKit משתמשת בדגל שמציין אם כל גיליונות הסגנונות ברמה העליונה (כולל @imports) נטענו. אם הסגנון לא נטען במלואו בזמן ההצמדה, המערכת משתמשת בסמלי placeholder ומסמנת אותו במסמך. החישובים שלהם יתבצעו מחדש אחרי טעינת גיליונות הסגנונות.
פריסה
כשיוצרים את המכשיר להצגה ומוסיפים אותו לעץ, אין לו מיקום וגודל. חישוב הערכים האלה נקרא פריסה או עיצוב מחדש.
ב-HTML נעשה שימוש במודל פריסה מבוסס-זרימה, כלומר ברוב המקרים אפשר לחשב את הגיאומטריה במעבר יחיד. בדרך כלל, רכיבים שנמצאים 'בהמשך התהליך' לא משפיעים על הגיאומטריה של רכיבים שנמצאים 'בתחילת התהליך', כך שהפריסה יכולה להתקדם במסמך משמאל לימין ומלמעלה למטה. יש יוצאי דופן: לדוגמה, יכול להיות שתצטרכו יותר מעבר אחד כדי לעבד טבלאות HTML.
מערכת הקואורדינטות היא ביחס למסגרת הבסיס. נעשה שימוש בקואורדינטות העליונות והשמאליות.
הפריסה היא תהליך רקורסיבי. הוא מתחיל במעבד הבסיסי (root renderer), שתואם לרכיב <html> במסמך ה-HTML. הפריסה ממשיכה באופן רפלקסיבי דרך חלק מההיררכיה של המסגרות או את כולה, ומחשבת מידע גיאומורפי לכל נגן שמחייב זאת.
המיקום של המרתח ברמה הבסיסית הוא 0,0 והמידות שלו הן אזור התצוגה – החלק הגלוי של חלון הדפדפן.
לכל המכשירים להצגת תוכן יש שיטת 'פריסה' או 'זרימה מחדש', וכל מכשיר להצגת תוכן מפעיל את שיטת הפריסה של הצאצאים שלו שצריכים פריסה.
מערכת של סיביות מלוכלכות
כדי לא לבצע פריסה מלאה בכל שינוי קטן, הדפדפנים משתמשים במערכת 'bit מלוכלך'. רכיב עיבוד גרפיקה ששונה או נוסף מסמנים את עצמו ואת הצאצאים שלו כ'לא תקין': צריך לבצע לו פריסה.
יש שני דגלים: 'לא תקין' ו'הצאצאים לא תקינים'. המשמעות היא שיכול להיות שהמנטרל עצמו תקין, אבל יש לו לפחות צאצא אחד שצריך פריסה.
פריסה גלובלית ומצטברת
אפשר להפעיל את הפריסה בכל עץ הרינדור – זוהי פריסה 'גלובלית'. המצב הזה יכול לקרות כתוצאה מ:
- שינוי סגנון גלובלי שמשפיע על כל המכשירים שמריצים את ה-renderer, כמו שינוי גודל הגופן.
- כתוצאה משינוי גודל המסך
אפשר להגדיר פריסה מצטברת, שבה רק העצמים ששונו ימוינו (הדבר עלול לגרום לנזק מסוים שיחייב פריסות נוספות).
הפריסה המצטברת מופעלת (באופן אסינכרוני) כשהמרתרים מלוכלכים. לדוגמה, כשמתבצע צירוף של מעבדי גרפיקה חדשים לעץ הרינדור אחרי שהגיע תוכן נוסף מהרשת והתווסף לעץ ה-DOM.
פריסה אסינכרונית וסינכרונית
הפריסה המצטברת מתבצעת באופן אסינכרוני. ב-Firefox נוצרות תורים של 'פקודות זרימה מחדש' לפריסות מצטברות, ומתזמן מפעיל את ביצוע הקבוצה של הפקודות האלה. ב-WebKit יש גם טיימר שמפעיל פריסה מצטברת – העץ עובר סריקה ומתבצעת פריסה של המרתונים 'מלוכלכים'.
סקריפטים שמבקשים מידע על סגנון, כמו "offsetHeight", יכולים להפעיל סידור מצטבר באופן סינכרוני.
בדרך כלל, הפריסה הגלובלית מופעלת באופן סינכרוני.
לפעמים האירוע layout מופעל כקריאה חוזרת (callback) אחרי פריסה ראשונית, כי מאפיינים מסוימים, כמו מיקום הגלילה, השתנו.
אופטימיזציות
כשפריסה מופעלת על ידי 'שינוי גודל' או שינוי במיקום של ה-renderer(ולא בגודל), גדלי הרינדור נלקחים מהמטמון ולא מחושבים מחדש…
במקרים מסוימים רק עץ משנה משתנה והפריסה לא מתחילה מהשורש. המצב הזה יכול לקרות במקרים שבהם השינוי הוא מקומי ולא משפיע על הסביבה שלו – כמו טקסט שמוחדר לשדות טקסט (אחרת כל הקשה על מקש תפעיל פריסה שמתחילה מהשורש).
תהליך היצירה של הפריסה
בדרך כלל, הפריסה בנויה לפי התבנית הבאה:
- ה-renderer של ההורה קובע את הרוחב שלו.
- ההורה עובר על הילדים ו:
- ממקמים את ה-renderer הצאצא (מגדירים את הערכים x ו-y שלו).
- אם צריך, קוראים לפריסה של הצאצא – אם היא לא נקייה, אם אנחנו בפריסה גלובלית או מסיבה אחרת – ומחשבים את הגובה של הצאצא.
- האב משתמש בגובה המצטבר של הצאצאים ובגובה השוליים והרווחים כדי להגדיר את הגובה שלו – ההורה של האב של ה-renderer ישתמש בגובה הזה.
- מגדיר את הביט המשויך לזיהום כ-false.
דפדפן Firefox משתמש באובייקט 'מצב' (nsHTMLReflowState) כפרמטר לפריסה (שנקראת 'זרימה מחדש'). בין היתר, המצב כולל את רוחב ההורה.
הפלט של הפריסה ב-Firefox הוא אובייקט 'metrics'(nsHTMLReflowMetrics). הוא יכיל את הגובה המחושב של ה-renderer.
חישוב רוחב
רוחב המכשיר להצגת הגרפיקה מחושב על סמך רוחב בלוק המאגר, מאפיין 'רוחב' של סגנון המכשיר להצגת הגרפיקה, השוליים והגבולות.
לדוגמה, רוחב ה-div הבא:
<div style="width: 30%"/>
המערכת של WebKit תחשב את הערך הזה באופן הבא(השיטה calcWidth של הכיתה RenderBox):
- רוחב הקונטיינר הוא הערך המקסימלי של availableWidth של הקונטיינר ו-0. במקרה הזה, הערך של availableWidth הוא contentWidth, שמחושב באופן הבא:
clientWidth() - paddingLeft() - paddingRight()
הערכים של clientWidth ו-clientHeight מייצגים את החלק הפנימי של אובייקט, לא כולל שוליים וסרגל גלילה.
רוחב הרכיבים הוא מאפיין הסגנון 'width'. הוא יחושב כערך מוחלט על ידי חישוב האחוז מתוך רוחב הקונטיינר.
הגבולות האופקיים והרווחים נוספים עכשיו.
עד כאן זהו החישוב של 'הרוחב המועדף'. עכשיו המערכת תחשב את הרוחב המינימלי והמקסימלי.
אם הרוחב המועדף גדול מהרוחב המקסימלי, המערכת משתמשת ברוחב המקסימלי. אם הוא קטן מהרוחב המינימלי (היחידת הקטנה ביותר שלא ניתן לשבור אותה), המערכת משתמשת ברוחב המינימלי.
הערכים מאוחסנים במטמון למקרה שיהיה צורך בפריסה, אבל הרוחב לא משתנה.
מעבר שורה
כשמתבצע עיבוד באמצע פריסה והוא מחליט שצריך להפסיק, הוא מפסיק את העיבוד ומעביר להורה של הפריסה את ההודעה שצריך להפסיק. האב יוצר את המכשירים הנוספים לעיבוד גרפיקה וקורא להם את הפריסה.
ציור
בשלב הציור, מתבצע סריקה של עץ הרינדור ומופעל השיטה 'paint()' של ה-renderer כדי להציג את התוכן במסך. ב-Painting נעשה שימוש ברכיב התשתית של ממשק המשתמש.
גלובלי ומצטבר
בדומה לפריסה, גם הצביעה יכולה להיות גלובלית – כל העץ צבוע – או מצטברת. בציור מצטבר, חלק מהמנפיקים משתנים באופן שלא משפיע על כל העץ. ה-renderer שהשתנה מבטל את המלבן שלו במסך. כתוצאה מכך, מערכת ההפעלה מתייחסת אליו כאל 'אזור מלוכלך' ויוצרת אירוע 'צביעה'. מערכת ההפעלה עושה זאת בצורה חכמה וממזגת כמה אזורים לאחד. ב-Chrome זה מורכב יותר כי המנגנון לעיבוד גרפיקה נמצא בתהליך שונה מהתהליך הראשי. Chrome מדמה את התנהגות מערכת ההפעלה במידה מסוימת. המצגת מקשיבה לאירועים האלה ומעבירה את ההודעה לשורש העיבוד. המערכת עוברת על העץ עד שמגיעה למעבד התצוגה הרלוונטי. הוא יתעדכן מחדש (ובדרך כלל גם הצאצאים שלו).
סדר הציור
ב-CSS2 מוגדר הסדר של תהליך הציור. זהו למעשה הסדר שבו הרכיבים נערמים בהקשרי הערימה. הסדר הזה משפיע על הציור, כי הערימות צבועות מהחלק האחורי לחלק הקדמי. סדר העריכה של רכיב עיבוד בלוקים הוא:
- צבע רקע
- תמונת רקע
- border
- ילדים
- outline
רשימת התצוגה של Firefox
Firefox עובר על עץ הרינדור ויוצר רשימת תצוגה של המלבן המצויר. הוא מכיל את המכשירים הרלוונטיים לתמונה המלבנית, בסדר הצביעה הנכון (רקעים של המכשירים, ואז גבולות וכו').
כך צריך לעבור על העץ רק פעם אחת לצורך צביעה מחדש, במקום כמה פעמים – צביעה של כל הרקעים, אחר כך של כל התמונות, אחר כך של כל השוליים וכו'.
כדי לבצע אופטימיזציה של התהליך, Firefox לא מוסיף אלמנטים שיוסתרו, כמו אלמנטים שנמצאים לגמרי מתחת לאלמנטים אטומים אחרים.
אחסון של מלבן ב-WebKit
לפני הצביעה מחדש, מערכת WebKit שומרת את המלבן הישן כקובץ בייטמאפ. לאחר מכן, הוא מצייר רק את ההפרש בין המלבנים החדש והישן.
שינויים דינמיים
הדפדפנים מנסים לבצע את הפעולות המינימליות האפשריות בתגובה לשינוי. לכן, שינויים בצבע של רכיב יגרמו רק לצביעה מחדש של הרכיב. שינויים במיקום של האלמנט יגרמו לפריסה ולצביעה מחדש של האלמנט, של הצאצאים שלו ואולי גם של האחים שלו. הוספת צומת DOM תגרום לפריסה ולצביעה מחדש של הצומת. שינויים משמעותיים, כמו הגדלת גודל הגופן של רכיב ה-html, יגרמו לביטול התוקף של מטמון, לפריסה מחדש ולצביעה מחדש של כל העץ.
השרשורים של מנוע הרינדור
מנוע הרינדור הוא בעל ליבה אחת. כמעט כל הפעולות, מלבד פעולות רשת, מתבצעות בשרשור אחד. ב-Firefox וב-Safari, זהו השרשור הראשי של הדפדפן. ב-Chrome, זהו ה-thread הראשי של תהליך הכרטיסייה.
אפשר לבצע פעולות רשת בכמה שרשורים מקבילים. מספר החיבורים המקבילים מוגבל (בדרך כלל 2 עד 6 חיבורים).
לולאת אירועים
הליבה הראשית של הדפדפן היא לולאת אירועים. זו לולאה אינסופית שמאפשרת לתהליך להמשיך לפעול. הוא ממתין לאירועים (כמו אירועי פריסה ואירועי צביעה) ומעבד אותם. זהו הקוד של Firefox לולאת האירועים הראשית:
while (!mExiting)
NS_ProcessNextEvent(thread);
מודל חזותי של CSS2
הקנבס
לפי מפרט CSS2, המונח 'לוח' מתאר את 'המרחב שבו מבוצעת הרינדור של מבנה הפורמט': המקום שבו הדפדפן מצייר את התוכן.
שטח הציור הוא אינסופי בכל אחד מהמימדים של המרחב, אבל הדפדפנים בוחרים רוחב ראשוני על סמך המימדים של אזור התצוגה.
לפי www.w3.org/TR/CSS2/zindex.html, הלוח שקוף אם הוא נכלל בלוח אחר, וצבע שלו מוגדר על ידי הדפדפן אם הוא לא נכלל בלוח אחר.
מודל Box ב-CSS
מודל התיבות של CSS מתאר את התיבות המלבניות שנוצרות עבור רכיבים בעץ המסמך וממוקמות בהתאם למודל הפורמט החזותי.
לכל תיבה יש אזור תוכן (למשל טקסט, תמונה וכו') ואזורים אופציונליים של שוליים, גבולות וריפוי מסביב.
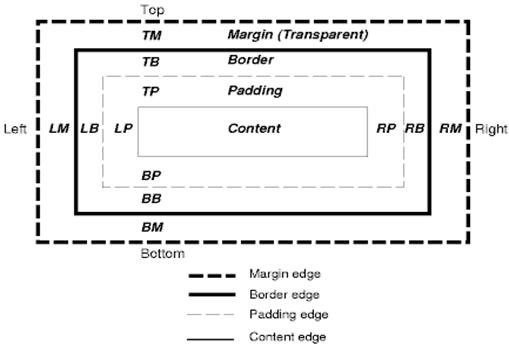
כל צומת יוצר 0…n תיבות כאלה.
לכל הרכיבים יש מאפיין 'display' שקובע את סוג התיבה שתיווצר.
דוגמאות:
block: generates a block box.
inline: generates one or more inline boxes.
none: no box is generated.
ברירת המחדל היא שורה אחר שורה, אבל גיליון הסגנונות של הדפדפן עשוי להגדיר הגדרות ברירת מחדל אחרות. לדוגמה: תצוגת ברירת המחדל של רכיב ה-div היא block.
דוגמה לגיליון סגנונות ברירת מחדל זמינה כאן: www.w3.org/TR/CSS2/sample.html.
סכמת מיקום
יש שלוש סכימות:
- רגיל: האובייקט ממוקם בהתאם למיקום שלו במסמך. המשמעות היא שהמיקום שלו בעץ הרינדור דומה למיקום שלו בעץ ה-DOM, והוא מוצג בהתאם לסוג התיבה ולמידות שלה.
- צף: האובייקט מוצג קודם כמו בזרימה רגילה, ואז מועבר כמה שיותר שמאלה או ימינה
- מוחלט: האובייקט ממוקם בעץ הרינדור במקום שונה מזה שבו הוא ממוקם בעץ ה-DOM
סכימה למיקום מוגדרת על ידי המאפיין position והמאפיין float.
- סטטי ויחסי גורמים לזרימה רגילה
- הערכים absolute ו-fixed גורמים למיקום מוחלט
במיקום סטטי לא מוגדר מיקום, והמערכת משתמשת במיקום ברירת המחדל. בסכמות האחרות, המחבר מציין את המיקום: למעלה, למטה, ימין, שמאל.
אופן הפריסה של התיבה נקבע לפי:
- סוג הקופסה
- מידות הקופסה
- סכמת מיקום
- מידע חיצוני כמו גודל התמונה וגודל המסך
סוגי הקופסאות
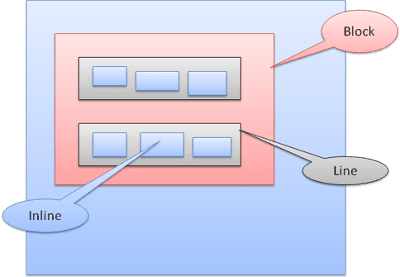
תיבת בלוק: יוצרת בלוק – יש לה מלבן משלה בחלון הדפדפן.

תיבה בתוך שורה: אין לה בלוק משלה, אבל היא נמצאת בתוך בלוק מכיל.
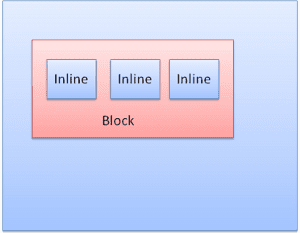
הפורמט של הבלוק הוא אנכי, אחד אחרי השני. הפורמט של טקסט בשורה אחת הוא אופקי.
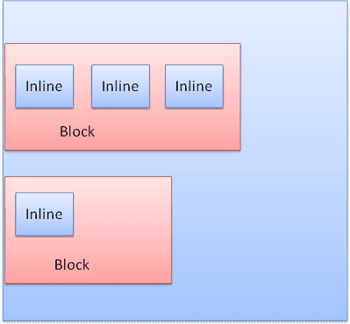
תיבות בתוך שורה ממוקמות בתוך שורות או 'תיבות שורה'. הקווים הם לפחות בגובה התיבה הגבוהה ביותר, אבל יכולים להיות גבוהים יותר כשהתיבות מותאמות 'לקו הבסיס' – כלומר החלק התחתון של הרכיב מיושר לנקודה בתיבה אחרת שאינה התחתונה. אם רוחב המארז לא מספיק, הטקסטים בתוך השורה יופיעו בכמה שורות. בדרך כלל זה מה שקורה בפסקה.
מיקום
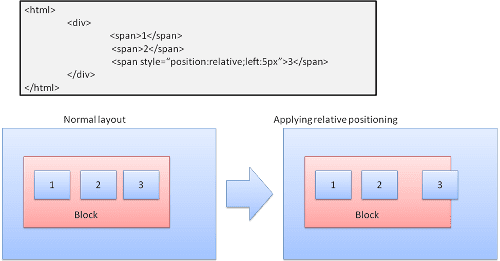
קרוב-משפחה
מיקום יחסי – המיקום נקבע כרגיל ולאחר מכן הוא מועבר לפי הערך של הדלתה הנדרשת.
צף
תיבת צף מוסטת שמאלה או ימינה לקו. התכונה המעניינת היא שהתיבות האחרות זורמות מסביב לה. ה-HTML:
<p>
<img style="float: right" src="images/image.gif" width="100" height="100">
Lorem ipsum dolor sit amet, consectetuer...
</p>
ייראה כך:

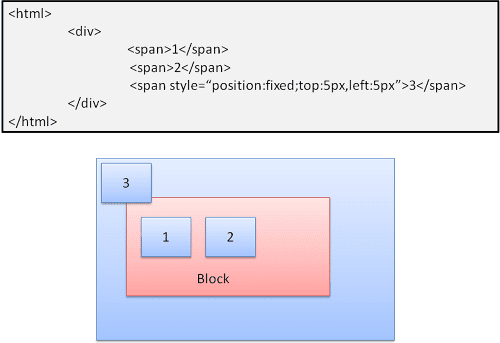
מוחלט וקבוע
הפריסה מוגדרת בדיוק ללא קשר לתהליך הרגיל. האלמנט לא משתתף בתהליך הרגיל. המאפיינים האלה הם יחסיים לקונטיינר. ב-fixed, המארז הוא אזור התצוגה.
ייצוג בשכבות
המאפיין הזה מצוין על ידי מאפיין ה-CSS z-index. הוא מייצג את המאפיין השלישי של התיבה: המיקום שלה לאורך 'ציר z'.
התיבות מחולקות לערמות (שנקראות הקשרי סטאקינג). בכל סטאק, הרכיבים שבחלק האחורי יצוירו קודם, והרכיבים שבחלק הקדמי יצוירו מעליהם, קרוב יותר למשתמש. במקרה של חפיפה, הרכיב הקדמי ביותר יסתיר את הרכיב הקודם.
הערימות מסודרות לפי המאפיין z-index. תיבות עם המאפיין 'z-index' יוצרות סטאק מקומי. אזור התצוגה מכיל את הסטאק החיצוני.
דוגמה:
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
התוצאה תהיה:

למרות ש-div האדום מופיע לפני ה-div הירוק בסימון, והוא היה צבוע לפניו בתהליך הרגיל, ערך המאפיין z-index שלו גבוה יותר, ולכן הוא מופיע מוקדם יותר בסטאק שנמצא בקופסה ברמה הבסיסית.
משאבים
ארכיטקטורת הדפדפן
- Grosskurth, Alan. ארכיטקטורת עזר לדפדפני אינטרנט (pdf)
- Gupta, Vineet. איך פועלים דפדפנים – חלק 1 – ארכיטקטורה
ניתוח
- Aho, Sethi, Ullman, Compilers: Principles, Techniques, and Tools (נקרא גם 'ספר הדרקון'), Addison-Wesley, 1986
- ריק ג'ליף (Rick Jelliffe). היפה והחיה: שני טיוטות חדשות ל-HTML 5
Firefox
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers
- L. דייוויד ברון, HTML ו-CSS מהירים יותר: הרכיבים הפנימיים של מנוע הפריסה למפתחי אינטרנט (סרטון של Google Tech Talk)
- L. David Baron, מנוע הפריסה של Mozilla
- L. David Baron, Mozilla Style System Documentation
- Chris Waterson, Notes on HTML Reflow
- Chris Waterson, סקירה כללית על Gecko
- Alexander Larsson, The life of an HTML HTTP request
WebKit
- David Hyatt, Implementing CSS(part 1)
- David Hyatt, סקירה כללית של WebCore
- דייוויד הייט (David Hyatt), עיבוד של WebCore
- David Hyatt, The FOUC Problem
מפרטים של W3C
הוראות ליצירת גרסאות build של דפדפנים
- Firefox. https://developer.mozilla.org/Build_Documentation
- WebKit. http://webkit.org/building/build.html
תרגומים
הדף הזה תורגם ליפנית, פעמיים:
- איך פועלים הדפדפנים – מאחורי הקלעים של דפדפני האינטרנט המודרניים (ja) מאת @kosei
- ブラウザってどうやって動いてるの?(モダンWEBブラウザシーンの裏側 מאת @ikeike443 ו@kiyoto01.
תוכלו לראות את התרגומים המארחים באופן חיצוני של קוריאנית ושל טורקית.
תודה לכולם!