
Moderne Webbrowser – ein Blick hinter die Kulissen


Vorwort
Diese umfassende Einführung in die internen Abläufe von WebKit und Gecko ist das Ergebnis umfangreicher Recherchen der israelischen Entwicklerin Tali Garsiel. Im Laufe der Jahre hat sie alle veröffentlichten Daten zu den internen Funktionen von Browsern geprüft und viel Zeit damit verbracht, den Quellcode von Webbrowsern zu lesen. Sie schrieb:
Als Webentwickler können Sie durch das Erlernen der internen Abläufe von Browsern bessere Entscheidungen treffen und die Begründungen für Best Practices bei der Entwicklung kennen. Dieses Dokument ist zwar recht lang, wir empfehlen Ihnen aber, sich die Zeit zu nehmen, es zu lesen. Sie werden es nicht bereuen.
Paul Irish, Chrome Developer Relations
Einführung
Webbrowser sind die am häufigsten verwendete Software. In diesem Artikel erkläre ich, wie sie im Hintergrund funktionieren. Geben Sie google.com in die Adressleiste ein, bis die Google-Seite auf dem Browserbildschirm erscheint.
Browser, die wir behandeln
Es gibt fünf gängige Browser für Desktop-Computer: Chrome, Internet Explorer, Firefox, Safari und Opera. Auf Mobilgeräten sind die wichtigsten Browser der Android-Browser, iPhone, Opera Mini und Opera Mobile, UC Browser, die Nokia S40/S60-Browser und Chrome. Mit Ausnahme der Opera-Browser basieren alle auf WebKit. Ich werde Beispiele aus den Open-Source-Browsern Firefox und Chrome sowie aus Safari (teilweise Open Source) nennen. Laut den StatCounter-Statistiken (Stand Juni 2013) machen Chrome, Firefox und Safari zusammen etwa 71% der weltweiten Desktop-Browsernutzung aus. Auf Mobilgeräten machen der Android-Browser, das iPhone und Chrome zusammen etwa 54% der Nutzung aus.
Die Hauptfunktionen des Browsers
Die Hauptfunktion eines Browsers besteht darin, die von Ihnen ausgewählte Webressource anzuzeigen, indem sie vom Server angefordert und im Browserfenster angezeigt wird. Die Ressource ist in der Regel ein HTML-Dokument, kann aber auch eine PDF-Datei, ein Bild oder eine andere Art von Inhalt sein. Der Speicherort der Ressource wird vom Nutzer mit einem URI (Uniform Resource Identifier) angegeben.
Wie der Browser HTML-Dateien interpretiert und darstellt, wird in den HTML- und CSS-Spezifikationen festgelegt. Diese Spezifikationen werden vom W3C (World Wide Web Consortium) verwaltet, der Standardsorganisation für das Web. Jahrelang haben Browser nur einen Teil der Spezifikationen eingehalten und eigene Erweiterungen entwickelt. Das führte zu ernsthaften Kompatibilitätsproblemen für Webautoren. Heutzutage entsprechen die meisten Browser mehr oder weniger den Spezifikationen.
Browser-Benutzeroberflächen haben viel gemeinsam. Zu den gängigen Elementen der Benutzeroberfläche gehören:
- Adressleiste zum Einfügen eines URI
- Schaltflächen „Zurück“ und „Weiter“
- Lesezeichenoptionen
- Schaltflächen zum Aktualisieren und Beenden, um aktuelle Dokumente zu aktualisieren oder das Laden zu beenden
- Startbildschirmtaste, über die Sie zur Startseite gelangen
Seltsamerweise ist die Benutzeroberfläche des Browsers in keiner formellen Spezifikation festgelegt. Sie basiert lediglich auf Best Practices, die sich über Jahre hinweg entwickelt haben, und auf der Nachahmung von Browsern durch andere Browser. Die HTML5-Spezifikation definiert keine UI-Elemente, die ein Browser haben muss, sondern listet einige gängige Elemente auf. Dazu gehören die Adressleiste, die Statusleiste und die Symbolleiste. Natürlich gibt es Funktionen, die nur für einen bestimmten Browser verfügbar sind, z. B. der Downloadmanager von Firefox.
Gesamtarchitektur
Die Hauptkomponenten des Browsers sind:
- Benutzeroberfläche: Dazu gehören die Adressleiste, die Schaltflächen „Zurück“ und „Weiter“, das Lesezeichenmenü usw. Alle Bereiche des Browserfensters mit Ausnahme des Fensters, in dem die angeforderte Seite angezeigt wird.
- Browser-Engine: Übermittelt Aktionen zwischen der Benutzeroberfläche und der Rendering-Engine.
- Die Rendering-Engine: Verantwortlich für die Anzeige der angeforderten Inhalte. Wenn der angeforderte Inhalt beispielsweise HTML ist, parset das Rendering-Engine HTML und CSS und zeigt den geparsten Inhalt auf dem Bildschirm an.
- Netzwerk: Für Netzwerkaufrufe wie HTTP-Anfragen werden verschiedene Implementierungen für verschiedene Plattformen hinter einer plattformunabhängigen Schnittstelle verwendet.
- UI-Backend: Wird zum Zeichnen einfacher Widgets wie Drop-down-Menüs und Fenster verwendet. Dieses Backend stellt eine generische Schnittstelle bereit, die nicht plattformspezifisch ist. Im Hintergrund werden Methoden der Benutzeroberfläche des Betriebssystems verwendet.
- JavaScript-Interpreter Wird zum Parsen und Ausführen von JavaScript-Code verwendet.
- Datenspeicherung: Dies ist eine Persistenzschicht. Der Browser muss möglicherweise alle möglichen Daten lokal speichern, z. B. Cookies. Browser unterstützen auch Speichermechanismen wie localStorage, IndexedDB, WebSQL und FileSystem.
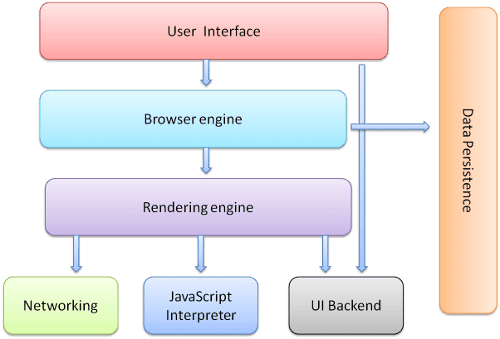
Beachten Sie, dass in Browsern wie Chrome mehrere Instanzen der Rendering-Engine ausgeführt werden: eine für jeden Tab. Jeder Tab wird in einem separaten Prozess ausgeführt.
Rendering-Engines
Die Aufgabe der Rendering-Engine besteht darin, die angeforderten Inhalte auf dem Browserbildschirm anzuzeigen.
Standardmäßig kann das Rendering-Engine HTML- und XML-Dokumente sowie Bilder anzeigen. Über Plug-ins oder Erweiterungen können andere Datentypen angezeigt werden, z. B. PDF-Dokumente mit einem PDF-Viewer-Plug-in. In diesem Kapitel konzentrieren wir uns jedoch auf den Hauptanwendungsfall: das Anzeigen von HTML und Bildern, die mit CSS formatiert sind.
Unterschiedliche Browser verwenden unterschiedliche Rendering-Engines: Internet Explorer verwendet Trident, Firefox verwendet Gecko und Safari verwendet WebKit. Chrome und Opera (ab Version 15) verwenden Blink, eine Fork von WebKit.
WebKit ist eine Open-Source-Rendering-Engine, die ursprünglich als Engine für die Linux-Plattform entwickelt wurde und von Apple für Mac und Windows angepasst wurde.
Der Hauptfluss
Die Rendering-Engine ruft den Inhalt des angeforderten Dokuments von der Netzwerkschicht ab. Dies geschieht in der Regel in 8-KB-Chunks.
Danach folgt der grundlegende Ablauf der Rendering-Engine:

Die Rendering-Engine beginnt mit dem Parsen des HTML-Dokuments und wandelt Elemente in DOM-Knoten in einem Baum um, der als „Inhaltsbaum“ bezeichnet wird. Die Engine analysiert die Stildaten sowohl in externen CSS-Dateien als auch in Stilelementen. Stilinformationen zusammen mit visuellen Anweisungen in der HTML-Datei werden verwendet, um einen weiteren Baum zu erstellen: den Renderbaum.
Der Renderbaum enthält Rechtecke mit visuellen Attributen wie Farbe und Abmessungen. Die Rechtecke sind in der richtigen Reihenfolge, um auf dem Bildschirm angezeigt zu werden.
Nach dem Erstellen des Renderbaums wird ein Layout erstellt. Das bedeutet, dass Sie jedem Knoten die genauen Koordinaten angeben müssen, an denen er auf dem Bildschirm erscheinen soll. Die nächste Phase ist die Darstellung: Der Rendering-Baum wird durchlaufen und jeder Knoten wird mithilfe der UI-Backend-Ebene dargestellt.
Es ist wichtig zu verstehen, dass dies ein allmählicher Prozess ist. Für eine bessere Nutzerfreundlichkeit versucht die Rendering-Engine, Inhalte so schnell wie möglich auf dem Bildschirm anzuzeigen. Es wird nicht gewartet, bis das gesamte HTML geparst wurde, bevor mit dem Erstellen und Layouten des Renderbaums begonnen wird. Teile des Inhalts werden geparst und angezeigt, während der Vorgang mit dem Rest des Inhalts fortgesetzt wird, der kontinuierlich vom Netzwerk kommt.
Beispiele für den Hauptablauf
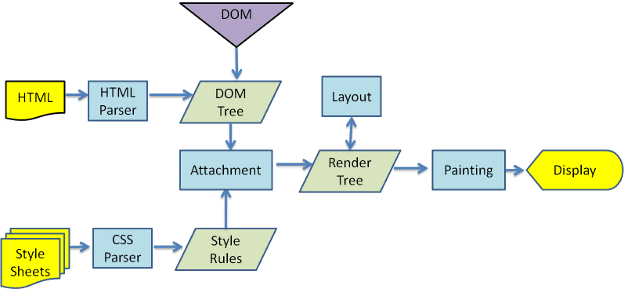
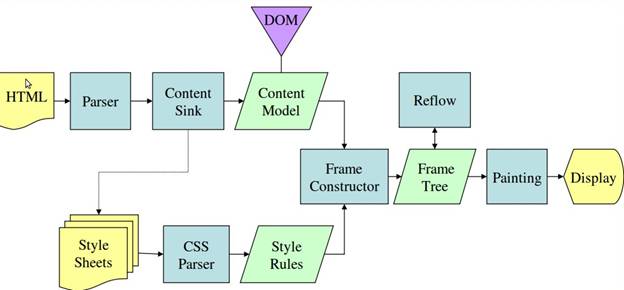
In den Abbildungen 3 und 4 sehen Sie, dass WebKit und Gecko zwar etwas unterschiedliche Terminologie verwenden, der Ablauf aber im Grunde derselbe ist.
Gecko nennt den Baum der visuell formatierten Elemente einen „Frame-Baum“. Jedes Element ist ein Frame. In WebKit wird der Begriff „Render Tree“ verwendet. Er besteht aus „Renderobjekten“. WebKit verwendet den Begriff „Layout“ für das Platzieren von Elementen, während Gecko „Neuformatierung“ verwendet. „Attachment“ ist der Begriff von WebKit für die Verbindung von DOM-Knoten und visuellen Informationen zum Erstellen des Renderbaums. Ein kleiner, nicht semantischer Unterschied besteht darin, dass Gecko eine zusätzliche Schicht zwischen dem HTML- und dem DOM-Baum hat. Er wird als „Content-Sink“ bezeichnet und ist eine Fabrik für die Erstellung von DOM-Elementen. Wir besprechen jeden Teil des Ablaufs:
Parsing – allgemein
Da das Parsen ein sehr wichtiger Prozess in der Rendering-Engine ist, gehen wir etwas näher darauf ein. Beginnen wir mit einer kurzen Einführung in das Parsen.
Das Parsen eines Dokuments bedeutet, es in eine Struktur zu übersetzen, die vom Code verwendet werden kann. Das Ergebnis des Parsings ist in der Regel ein Knotenbaum, der die Struktur des Dokuments darstellt. Dies wird als Parsebaum oder Syntaxbaum bezeichnet.
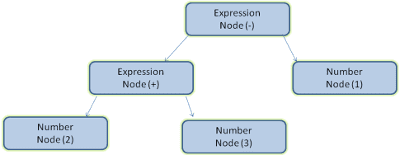
Das Parsen des Ausdrucks 2 + 3 - 1 könnte beispielsweise diesen Baum zurückgeben:
Grammatik
Das Parsen basiert auf den Syntaxregeln, die für das Dokument gelten: der Sprache oder dem Format, in dem es geschrieben wurde. Jedes Format, das Sie parsen können, muss eine deterministische Grammatik mit Wortschatz- und Syntaxregeln haben. Sie wird als kontextfreie Grammatik bezeichnet. Menschliche Sprachen sind keine solchen Sprachen und können daher nicht mit herkömmlichen Parsing-Techniken analysiert werden.
Parser – Lexer-Kombination
Das Parsen kann in zwei Teilprozesse unterteilt werden: lexikalische Analyse und Syntaxanalyse.
Bei der lexikalischen Analyse wird die Eingabe in Tokens unterteilt. Tokens sind das Vokabular der Sprache: die Sammlung gültiger Bausteine. In menschlicher Sprache besteht es aus allen Wörtern, die im Wörterbuch für diese Sprache aufgeführt sind.
Bei der Syntaxanalyse werden die Syntaxregeln der Sprache angewendet.
Parser teilen die Arbeit in der Regel auf zwei Komponenten auf: den Lexer (manchmal auch Tokenizer genannt), der für die Aufteilung der Eingabe in gültige Tokens verantwortlich ist, und den Parser, der für die Erstellung des Parsebaums verantwortlich ist, indem er die Dokumentstruktur gemäß den Syntaxregeln der Sprache analysiert.
Der Lexer weiß, wie irrelevante Zeichen wie Leerzeichen und Zeilenumbrüche entfernt werden.
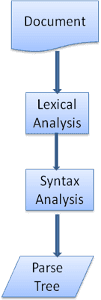
Der Parsevorgang ist iterativ. Der Parser bittet in der Regel den Lexer um ein neues Token und versucht, das Token mit einer der Syntaxregeln abzugleichen. Wenn eine Regel übereinstimmt, wird dem Parsebaum ein dem Token entsprechender Knoten hinzugefügt und der Parser fordert ein weiteres Token an.
Wenn keine Regel übereinstimmt, speichert der Parser das Token intern und fragt weiter nach Tokens, bis eine Regel gefunden wird, die mit allen intern gespeicherten Tokens übereinstimmt. Wenn keine Regel gefunden wird, löst der Parser eine Ausnahme aus. Das Dokument war also ungültig und enthielt Syntaxfehler.
Übersetzung
In vielen Fällen ist der Parsebaum nicht das Endprodukt. Das Parsen wird häufig bei der Übersetzung verwendet, um das Eingabedokument in ein anderes Format umzuwandeln. Ein Beispiel ist die Kompilierung. Der Compiler, der Quellcode in Maschinencode kompiliert, parset ihn zuerst in einen Parsebaum und übersetzt den Baum dann in ein Maschinencodedokument.
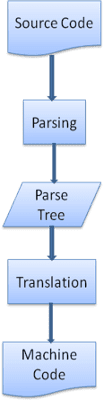
Beispiel für das Parsen
In Abbildung 5 haben wir einen Parsebaum aus einem mathematischen Ausdruck erstellt. Versuchen wir, eine einfache mathematische Sprache zu definieren und den Parsevorgang zu sehen.
Syntax:
- Die Bausteine der Sprachsyntax sind Ausdrücke, Begriffe und Vorgänge.
- Unsere Sprache kann beliebig viele Ausdrücke enthalten.
- Ein Ausdruck besteht aus einem „Terminus“, gefolgt von einer „Operation“ und einem weiteren Terminus.
- Ein Vorgang ist ein Plus- oder Minuszeichen.
- Ein Ausdruck ist ein Ganzzahltoken oder ein Ausdruck.
Sehen wir uns die Eingabe 2 + 3 - 1 an.
Der erste Teilstring, der mit einer Regel übereinstimmt, ist 2. Gemäß Regel 5 ist dies ein Begriff.
Die zweite Übereinstimmung ist 2 + 3. Dies entspricht der dritten Regel: ein Begriff gefolgt von einem Operator gefolgt von einem anderen Begriff.
Die nächste Übereinstimmung wird erst am Ende der Eingabe gefunden.
2 + 3 - 1 ist ein Ausdruck, da wir bereits wissen, dass 2 + 3 ein Term ist. Wir haben also einen Term, gefolgt von einem Vorgang, gefolgt von einem weiteren Term.
2 + + stimmt mit keiner Regel überein und ist daher eine ungültige Eingabe.
Formale Definitionen für Vokabular und Syntax
Vokabeln werden in der Regel durch reguläre Ausdrücke ausgedrückt.
Unsere Sprache wird beispielsweise so definiert:
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -
Wie Sie sehen, werden Ganzzahlen durch einen regulären Ausdruck definiert.
Die Syntax wird in der Regel in einem Format namens BNF definiert. Unsere Sprache wird so definiert:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
Wir haben gesagt, dass eine Sprache von regulären Parsern geparst werden kann, wenn ihre Grammatik eine kontextfreie Grammatik ist. Eine intuitive Definition einer kontextfreien Grammatik ist eine Grammatik, die vollständig in BNF ausgedrückt werden kann. Eine formale Definition finden Sie im Wikipedia-Artikel zur kontextfreien Grammatik.
Arten von Parsern
Es gibt zwei Arten von Parsern: Top-Down-Parser und Bottom-Up-Parser. Eine intuitive Erklärung ist, dass Top-Down-Parser die Syntax auf hoher Ebene prüfen und versuchen, eine Übereinstimmung mit einer Regel zu finden. Bottom-Up-Parser beginnen mit der Eingabe und wandeln sie nach und nach in die Syntaxregeln um, beginnend mit den Regeln der unteren Ebene, bis die Regeln der höheren Ebene erfüllt sind.
Sehen wir uns an, wie die beiden Arten von Parsern unser Beispiel verarbeiten.
Der Top-Down-Parser beginnt mit der Regel der höheren Ebene: Er identifiziert 2 + 3 als Ausdruck. 2 + 3 - 1 wird dann als Ausdruck identifiziert. Der Prozess der Identifizierung des Ausdrucks entwickelt sich, indem die anderen Regeln abgeglichen werden, aber der Ausgangspunkt ist die Regel der obersten Ebene.
Der Bottom-Up-Parser scannt die Eingabe, bis eine Regel gefunden wird. Die übereinstimmende Eingabe wird dann durch die Regel ersetzt. Das geht so lange weiter, bis die Eingabe beendet ist. Der teilweise übereinstimmende Ausdruck wird auf den Stack des Parsers gelegt.
Dieser Bottom-Up-Parser wird als Verschiebe-Reduzierungs-Parser bezeichnet, da die Eingabe nach rechts verschoben wird (stellen Sie sich einen Cursor vor, der zuerst auf den Anfang der Eingabe zeigt und dann nach rechts bewegt wird) und nach und nach auf Syntaxregeln reduziert wird.
Parser automatisch generieren
Es gibt Tools, mit denen ein Parser generiert werden kann. Sie geben die Grammatik Ihrer Sprache ein – ihr Vokabular und ihre Syntaxregeln – und das Programm generiert einen funktionierenden Parser. Das Erstellen eines Parsers erfordert ein umfassendes Verständnis des Parsings und es ist nicht einfach, einen optimierten Parser von Hand zu erstellen. Daher können Parsergeneratoren sehr nützlich sein.
WebKit verwendet zwei bekannte Parsergeneratoren: Flex zum Erstellen eines Lexers und Bison zum Erstellen eines Parsers (möglicherweise auch unter den Namen Lex und Yacc). Die Flex-Eingabe ist eine Datei mit regulären Ausdrucksdefinitionen der Tokens. Die Eingabe von Bison sind die Sprachsyntaxregeln im BNF-Format.
HTML-Parser
Die Aufgabe des HTML-Parsers besteht darin, das HTML-Markup in einen Parsebaum zu parsen.
HTML-Grammatik
Der Wortschatz und die Syntax von HTML sind in Spezifikationen der W3C-Organisation definiert.
Wie wir in der Einführung in das Parsen gesehen haben, kann die Grammatiksyntax formal mithilfe von Formaten wie BNF definiert werden.
Leider gelten die herkömmlichen Parserthemen nicht für HTML. Ich habe sie nicht nur zum Spaß erwähnt, sondern sie werden beim Parsen von CSS und JavaScript verwendet. HTML lässt sich nicht einfach durch eine kontextfreie Grammatik definieren, die Parser benötigen.
Es gibt ein formales Format zur Definition von HTML – DTD (Document Type Definition). Es handelt sich jedoch nicht um eine kontextfreie Grammatik.
Das erscheint auf den ersten Blick seltsam, da HTML XML sehr ähnelt. Es gibt viele verfügbare XML-Parser. Es gibt eine XML-Variante von HTML – XHTML. Was ist der große Unterschied?
Der Unterschied besteht darin, dass der HTML-Ansatz toleranter ist: Sie können bestimmte Tags weglassen (die dann implizit hinzugefügt werden) oder manchmal Start- oder End-Tags weglassen usw. Insgesamt ist es eine „weiche“ Syntax, im Gegensatz zur starren und anspruchsvollen Syntax von XML.
Dieses scheinbar kleine Detail macht einen großen Unterschied. Das ist einerseits der Hauptgrund, warum HTML so beliebt ist: Es verzeiht Fehler und macht das Leben für Webautoren einfacher. Andererseits erschwert es die Erstellung einer formellen Grammatik. Zusammenfassend lässt sich sagen, dass HTML nicht einfach mit herkömmlichen Parsern geparst werden kann, da seine Grammatik nicht kontextfrei ist. HTML kann nicht von XML-Parsern geparst werden.
HTML-DTD
Die HTML-Definition ist im DTD-Format. Dieses Format wird verwendet, um Sprachen der SGML-Familie zu definieren. Das Format enthält Definitionen für alle zulässigen Elemente, ihre Attribute und ihre Hierarchie. Wie bereits erwähnt, bildet die HTML-DTD keine kontextfreie Grammatik.
Es gibt einige Varianten der DTD. Der strenge Modus entspricht nur den Spezifikationen, andere Modi unterstützen jedoch Markup, das in der Vergangenheit von Browsern verwendet wurde. Das soll die Abwärtskompatibilität mit älteren Inhalten ermöglichen. Die aktuelle strenge DTD finden Sie hier: www.w3.org/TR/html4/strict.dtd
DOM
Der Ausgabebaum (der „Parsebaum“) ist ein Baum aus DOM-Element- und Attributknoten. DOM steht für „Document Object Model“. Es ist die Objektpräsentation des HTML-Dokuments und die Schnittstelle von HTML-Elementen nach außen, z. B. JavaScript.
Die Wurzel des Baums ist das Objekt Document.
Das DOM hat eine fast 1:1-Beziehung zum Markup. Beispiel:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
Dieses Markup würde in den folgenden DOM-Baum umgewandelt:
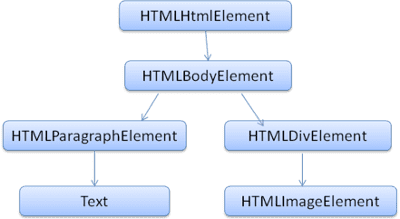
Wie HTML wird auch das DOM von der W3C-Organisation festgelegt. Weitere Informationen finden Sie unter www.w3.org/DOM/DOMTR. Es ist eine generische Spezifikation für die Manipulation von Dokumenten. Ein bestimmtes Modul beschreibt HTML-spezifische Elemente. Die HTML-Definitionen finden Sie hier: www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html.
Wenn ich sage, dass der Baum DOM-Knoten enthält, meine ich, dass der Baum aus Elementen besteht, die eine der DOM-Schnittstellen implementieren. Browser verwenden konkrete Implementierungen mit anderen Attributen, die vom Browser intern verwendet werden.
Der Parsealgorithmus
Wie wir in den vorherigen Abschnitten gesehen haben, kann HTML nicht mit den regulären Top-Down- oder Bottom-Up-Parsern geparst werden.
Hierfür gibt es folgende Gründe:
- Die fehlertolerante Natur der Sprache.
- Die Tatsache, dass Browser eine traditionelle Fehlertoleranz haben, um bekannte Fälle von ungültigem HTML zu unterstützen.
- Der Parsevorgang ist reentrant. Bei anderen Sprachen ändert sich die Quelle beim Parsen nicht. In HTML können jedoch durch dynamischen Code (z. B. Scriptelemente mit
document.write()-Aufrufen) zusätzliche Tokens hinzugefügt werden, sodass die Eingabe durch den Parsevorgang tatsächlich geändert wird.
Da die regulären Parsing-Techniken nicht verwendet werden können, erstellen Browser benutzerdefinierte Parser zum Parsen von HTML.
Der Parse-Algorithmus wird in der HTML5-Spezifikation ausführlich beschrieben. Der Algorithmus besteht aus zwei Phasen: Tokenisierung und Baumkonstruktion.
Die Tokenisierung ist die lexikalische Analyse, bei der die Eingabe in Tokens geparst wird. Zu den HTML-Tokens gehören Start- und End-Tags, Attributnamen und Attributwerte.
Der Tokenisierer erkennt das Token, übergibt es an den Baumkonstruktor und liest das nächste Zeichen zum Erkennen des nächsten Tokens ein. So geht es weiter bis zum Ende der Eingabe.
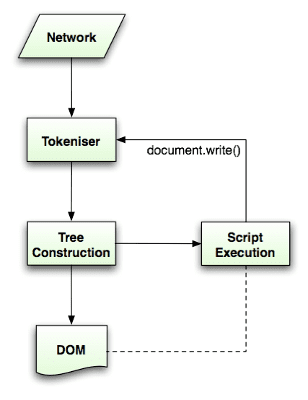
Der Tokenisierungsalgorithmus
Die Ausgabe des Algorithmus ist ein HTML-Token. Der Algorithmus wird als Zustandsmaschine dargestellt. Jeder Status verbraucht ein oder mehrere Zeichen des Eingabestreams und aktualisiert den nächsten Status entsprechend diesen Zeichen. Die Entscheidung wird vom aktuellen Tokenisierungsstatus und vom Status der Baumkonstruktion beeinflusst. Das bedeutet, dass dasselbe konsumierte Zeichen je nach aktuellem Status unterschiedliche Ergebnisse für den korrekten nächsten Status liefert. Der Algorithmus ist zu komplex, um ihn vollständig zu beschreiben. Sehen wir uns daher ein einfaches Beispiel an, das uns hilft, das Prinzip zu verstehen.
Einfaches Beispiel – Tokenisierung des folgenden HTML-Codes:
<html>
<body>
Hello world
</body>
</html>
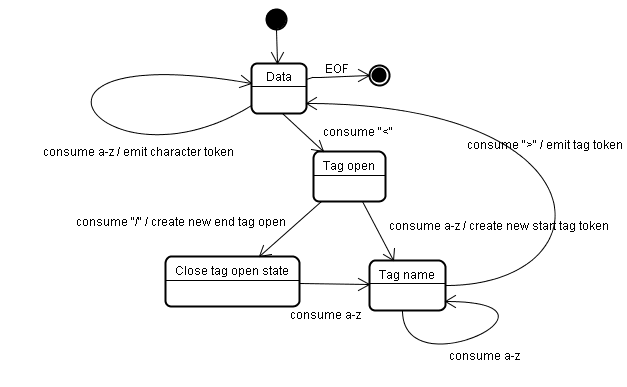
Der Anfangsstatus ist der „Datenstatus“.
Wenn das Zeichen < gefunden wird, ändert sich der Status in „Tag-offen-Status“.
Wenn ein a-z-Zeichen verarbeitet wird, wird ein „Start-Tag-Token“ erstellt und der Status in „Tag-Namen-Status“ geändert.
Wir bleiben in diesem Status, bis das Zeichen > verarbeitet wurde. Jedes Zeichen wird an den neuen Tokennamen angehängt. In unserem Fall ist das erstellte Token ein html-Token.
Wenn das >-Tag erreicht ist, wird das aktuelle Token gesendet und der Status ändert sich wieder in Datenstatus.
Für das <body>-Tag werden dieselben Schritte ausgeführt.
Bisher wurden die Tags html und body gesendet. Wir sind jetzt wieder bei Datenstatus.
Wenn das Zeichen H von Hello world konsumiert wird, wird ein Zeichentoken erstellt und gesendet. Dies geschieht so lange, bis die < von </body> erreicht wird. Wir geben für jedes Zeichen von Hello world ein Zeichentoken aus.
Wir sind jetzt wieder beim Status „Tag geöffnet“.
Wenn die nächste Eingabe / verarbeitet wird, wird ein end tag token erstellt und der Status in „Tag-Namenstatus“ geändert. Wir bleiben in diesem Status, bis wir > erreichen.Dann wird das neue Tag-Token ausgegeben und wir kehren zum Datenstatus zurück.
Die Eingabe von </html> wird wie im vorherigen Fall behandelt.
Algorithmus zum Erstellen von Bäumen
Wenn der Parser erstellt wird, wird auch das Dokumentobjekt erstellt. Während der Baumkonstruktionsphase wird der DOM-Baum mit dem Dokument als Wurzel geändert und ihm werden Elemente hinzugefügt. Jeder vom Tokenisierer emittierte Knoten wird vom Baumkonstruktor verarbeitet. Für jedes Token wird in der Spezifikation festgelegt, welches DOM-Element für das Token relevant ist und für dieses Token erstellt wird. Das Element wird dem DOM-Baum und dem Stapel der offenen Elemente hinzugefügt. Mit diesem Stack werden Unstimmigkeiten bei Verschachtelungen und nicht geschlossene Tags korrigiert. Der Algorithmus wird auch als Zustandsmaschine beschrieben. Diese Zustände werden als „Einfügemodi“ bezeichnet.
Sehen wir uns den Aufbau des Baums für die Beispieleingaben an:
<html>
<body>
Hello world
</body>
</html>
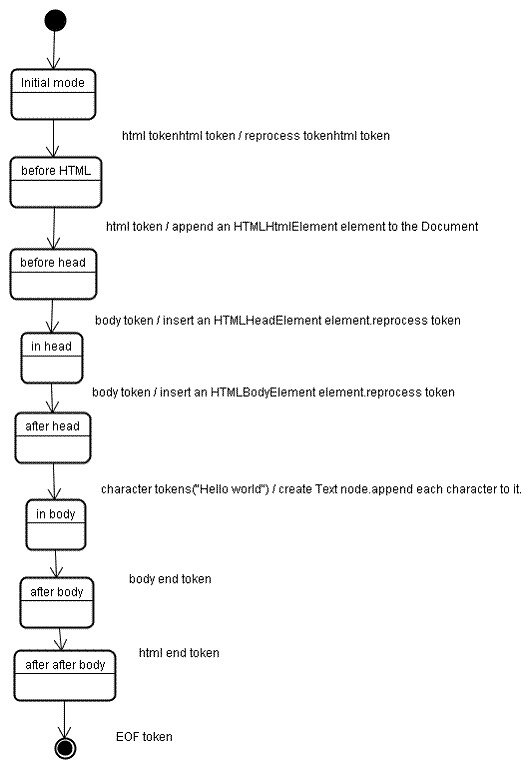
Die Eingabe für die Phase des Baumaufbaus ist eine Sequenz von Tokens aus der Tokenisierungsphase. Der erste Modus ist der Anfangsmodus. Wenn das „html“-Token empfangen wird, wird der Modus in „vor html“ geändert und das Token in diesem Modus noch einmal verarbeitet. Dadurch wird das Element „HTMLHtmlElement“ erstellt, das dem Stammdokumentobjekt angehängt wird.
Der Status wird in „before head“ geändert. Das „body“-Token wird dann empfangen. Ein HTMLHeadElement wird implizit erstellt, obwohl wir kein „head“-Token haben, und dem Baum hinzugefügt.
Wir wechseln jetzt zum Modus „in Kopf“ und dann zu „nach Kopf“. Das Body-Token wird noch einmal verarbeitet, ein HTMLBodyElement wird erstellt und eingefügt und der Modus wird in "in body" geändert.
Die Zeichentokens des Strings „Hallo Welt“ werden jetzt empfangen. Das erste Zeichen führt zum Erstellen und Einfügen eines „Text“-Knotens und die anderen Zeichen werden an diesen Knoten angehängt.
Wenn das Endtoken für den Textkörper empfangen wird, wird der Modus in „Nach Textkörper“ geändert. Jetzt erhalten wir das HTML-End-Tag, wodurch wir in den Modus „nach dem Body“ wechseln. Wenn das Token für das Ende der Datei empfangen wird, wird das Parsen beendet.
Aktionen nach Abschluss des Parsings
In dieser Phase kennzeichnet der Browser das Dokument als interaktiv und beginnt mit dem Parsen von Scripts, die sich im Modus „Verzögert“ befinden, d. h. die nach dem Parsen des Dokuments ausgeführt werden sollen. Der Dokumentstatus wird dann auf „vollständig“ gesetzt und ein „Lade“-Ereignis wird ausgelöst.
Die vollständigen Algorithmen für die Tokenisierung und Baumstruktur finden Sie in der HTML5-Spezifikation.
Fehlertoleranz von Browsern
Auf einer HTML-Seite wird nie der Fehler „Ungültige Syntax“ angezeigt. Browser korrigieren ungültige Inhalte und fahren fort.
Nehmen wir als Beispiel diesen HTML-Code:
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
Ich habe wahrscheinlich gegen etwa eine Million Regeln verstoßen („mytag“ ist kein Standard-Tag, falsche Verschachtelung der „p“- und „div“-Elemente usw.), aber der Browser zeigt es trotzdem korrekt an und meldet keine Fehler. Ein Großteil des Parsercodes dient also dazu, die Fehler des HTML-Autors zu korrigieren.
Die Fehlerbehandlung ist in Browsern ziemlich konsistent, aber erstaunlicherweise war sie nicht Teil der HTML-Spezifikationen. Wie Lesezeichen und die Schaltflächen „Zurück“ und „Weiter“ hat sich auch die Suchleiste im Laufe der Jahre in Browsern entwickelt. Es gibt bekannte ungültige HTML-Konstrukte, die auf vielen Websites wiederholt werden. Die Browser versuchen, sie so zu korrigieren, dass sie mit anderen Browsern kompatibel sind.
Einige dieser Anforderungen werden in der HTML5-Spezifikation definiert. (WebKit fasst dies im Kommentar am Anfang der HTML-Parser-Klasse gut zusammen.)
Der Parser analysiert die tokenisierte Eingabe im Dokument und erstellt den Dokumentbaum. Wenn das Dokument korrekt formatiert ist, ist das Parsen unkompliziert.
Leider müssen wir viele nicht korrekt formatierte HTML-Dokumente verarbeiten. Daher muss der Parser tolerant gegenüber Fehlern sein.
Wir müssen mindestens die folgenden Fehlerbedingungen berücksichtigen:
- Das hinzugefügte Element ist in einem äußeren Tag ausdrücklich verboten. In diesem Fall sollten wir alle Tags bis zu dem schließen, das das Element verbietet, und es danach hinzufügen.
- Wir dürfen das Element nicht direkt hinzufügen. Möglicherweise hat die Person, die das Dokument erstellt hat, ein Tag dazwischen vergessen (oder das Tag dazwischen ist optional). Das kann bei den folgenden Tags der Fall sein: HTML HEAD BODY TBODY TR TD LI (habe ich welche vergessen?).
- Wir möchten ein Blockelement in ein Inline-Element einfügen. Schließen Sie alle Inline-Elemente bis zum nächsten übergeordneten Blockelement.
- Wenn das Problem dadurch nicht behoben wird, schließen Sie Elemente, bis wir das Element hinzufügen können, oder ignorieren Sie das Tag.
Sehen wir uns einige Beispiele für die WebKit-Fehlertoleranz an:
</br> statt <br>
Einige Websites verwenden </br> anstelle von <br>. Zur Kompatibilität mit IE und Firefox behandelt WebKit dies wie <br>.
Der Code:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
Die Fehlerbehandlung ist intern und wird dem Nutzer nicht angezeigt.
Eine verlorene Tabelle
Eine solche Tabelle befindet sich in einer anderen Tabelle, aber nicht in einer Tabellenzelle.
Beispiel:
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
WebKit ändert die Hierarchie in zwei Schwestertabellen:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
Der Code:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
WebKit verwendet einen Stapel für den Inhalt des aktuellen Elements: Die innere Tabelle wird aus dem äußeren Tabellenstapel entfernt. Die Tabellen sind jetzt Geschwister.
Verschachtelte Formularelemente
Wenn der Nutzer ein Formular in ein anderes Formular einfügt, wird das zweite Formular ignoriert.
Der Code:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
Eine zu tiefe Tag-Hierarchie
Der Kommentar spricht für sich.
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
Falsch platzierte End-Tags für „html“ oder „body“
Nochmals: Der Kommentar spricht für sich.
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
Webentwickler aufgepasst: Außer Sie möchten als Beispiel in einem WebKit-Fehlertoleranz-Code-Snippet erscheinen, sollten Sie gut formatierten HTML-Code schreiben.
CSS-Parsing
Erinnern Sie sich an die Parsing-Konzepte in der Einführung? Im Gegensatz zu HTML ist CSS eine kontextfreie Grammatik und kann mit den in der Einführung beschriebenen Parsertypen geparst werden. Tatsächlich definiert die CSS-Spezifikation die lexikalische und syntaktische Grammatik von CSS.
Sehen wir uns einige Beispiele an:
Die lexikalische Grammatik (Wörterbuch) wird für jedes Token durch reguläre Ausdrücke definiert:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
„ident“ steht für „Kennung“, z. B. einen Klassennamen. „name“ ist eine Element-ID, auf die mit „#“ verwiesen wird.
Die Syntaxgrammatik wird in BNF beschrieben.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
Erklärung:
Eine Regelgruppe hat folgende Struktur:
div.error, a.error {
color:red;
font-weight:bold;
}
div.error und a.error sind Selektoren. Der Teil innerhalb der geschweiften Klammern enthält die Regeln, die von dieser Regelgruppe angewendet werden.
Diese Struktur wird in dieser Definition formal definiert:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
Das bedeutet, dass eine Regel ein Selektor oder optional mehrere Selektoren sind, die durch Kommas und Leerzeichen getrennt sind (S steht für Leerzeichen). Ein Regelsatz enthält geschweifte Klammern und darin eine Deklaration oder optional mehrere Deklarationen, die durch ein Semikolon getrennt sind. „declaration“ und „selector“ werden in den folgenden BNF-Definitionen definiert.
WebKit-CSS-Parser
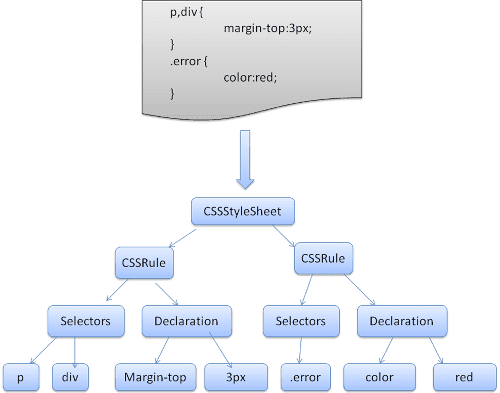
WebKit verwendet die Parsergeneratoren Flex und Bison, um Parser automatisch aus den CSS-Grammatikdateien zu erstellen. Wie Sie aus der Einführung in Parser wissen, erstellt Bison einen Bottom-Up-Shift-Reduce-Parser. Firefox verwendet einen manuell erstellten Top-Down-Parser. In beiden Fällen wird jede CSS-Datei in ein StyleSheet-Objekt geparst. Jedes Objekt enthält CSS-Regeln. Die CSS-Regelobjekte enthalten Selektor- und Deklarationsobjekte sowie andere Objekte, die der CSS-Grammatik entsprechen.
Verarbeitungsreihenfolge für Scripts und Stylesheets
Skripts
Das Web ist ein synchrones Modell. Autoren erwarten, dass Scripts sofort geparst und ausgeführt werden, wenn der Parser ein <script>-Tag erreicht.
Das Parsen des Dokuments wird angehalten, bis das Script ausgeführt wurde.
Wenn das Script extern ist, muss die Ressource zuerst aus dem Netzwerk abgerufen werden. Dies geschieht ebenfalls synchron und das Parsen wird angehalten, bis die Ressource abgerufen wurde.
Dieses Modell wurde viele Jahre lang verwendet und ist auch in den HTML4- und 5-Spezifikationen festgelegt.
Autoren können einem Script das Attribut „defer“ hinzufügen. In diesem Fall wird das Dokument nicht angehalten und das Script wird nach dem Parsen des Dokuments ausgeführt. HTML5 bietet eine Option, mit der das Script als asynchron gekennzeichnet werden kann, damit es von einem anderen Thread geparst und ausgeführt wird.
Spekulatives Parsen
Sowohl WebKit als auch Firefox führen diese Optimierung durch. Während der Ausführung von Scripts analysiert ein anderer Thread den Rest des Dokuments und ermittelt, welche anderen Ressourcen aus dem Netzwerk geladen werden müssen. So können Ressourcen über parallele Verbindungen geladen und die Gesamtgeschwindigkeit verbessert werden. Hinweis: Der spekulative Parser analysiert nur Verweise auf externe Ressourcen wie externe Scripts, Stylesheets und Bilder. Er ändert den DOM-Baum nicht. Das bleibt dem Hauptparser überlassen.
Style sheets
Stylesheets haben dagegen ein anderes Modell. Da Stylesheets das DOM-Baum nicht ändern, gibt es keinen Grund, auf sie zu warten und das Dokument-Parsing zu beenden. Es gibt jedoch ein Problem mit Scripts, die während der Dokument-Parsing-Phase nach Stilinformationen fragen. Wenn der Stil noch nicht geladen und geparst wurde, erhält das Script falsche Antworten. Dies hat offenbar viele Probleme verursacht. Es scheint ein Grenzfall zu sein, ist aber ziemlich häufig. Firefox blockiert alle Scripts, wenn ein Stylesheet noch geladen und geparst wird. WebKit blockiert Scripts nur, wenn sie versuchen, auf bestimmte Stileigenschaften zuzugreifen, die von nicht geladenen Stylesheets beeinflusst werden können.
Renderbaum erstellen
Während der DOM-Baum erstellt wird, erstellt der Browser einen weiteren Baum, den Renderbaum. Dieser Baum enthält visuelle Elemente in der Reihenfolge, in der sie angezeigt werden. Sie ist die visuelle Darstellung des Dokuments. Mit diesem Baum können die Inhalte in der richtigen Reihenfolge dargestellt werden.
In Firefox werden die Elemente im Renderbaum als „Frames“ bezeichnet. In WebKit wird der Begriff „Renderer“ oder „Renderobjekt“ verwendet.
Ein Renderer weiß, wie er sich selbst und seine untergeordneten Elemente ausrichten und zeichnen muss.
Die RenderObject-Klasse von WebKit, die Basisklasse der Renderer, hat folgende Definition:
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
Jeder Renderer stellt einen rechteckigen Bereich dar, der normalerweise dem CSS-Box eines Knotens entspricht, wie in der CSS2-Spezifikation beschrieben. Er enthält geometrische Informationen wie Breite, Höhe und Position.
Der Boxtyp wird vom Wert „display“ des Stilattributs beeinflusst, das für den Knoten relevant ist (siehe Abschnitt Stilberechnung). Hier ist WebKit-Code, mit dem entschieden wird, welcher Renderer für einen DOM-Knoten gemäß dem Attribut „display“ erstellt werden soll:
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
Der Elementtyp wird ebenfalls berücksichtigt: Formularsteuerelemente und Tabellen haben beispielsweise spezielle Frames.
Wenn in WebKit ein Element einen speziellen Renderer erstellen möchte, wird die createRenderer()-Methode überschrieben.
Die Renderer verweisen auf Stilobjekte, die keine geometrischen Informationen enthalten.
Die Beziehung des Renderbaums zum DOM-Baum
Die Renderer entsprechen DOM-Elementen, die Beziehung ist jedoch nicht eins zu eins. Nicht sichtbare DOM-Elemente werden nicht in den Renderbaum eingefügt. Ein Beispiel ist das Element „head“. Auch Elemente, deren Anzeigewert „nicht“ zugewiesen wurde, werden nicht im Baum angezeigt. Elemente mit der Sichtbarkeit „ausgeblendet“ werden dagegen im Baum angezeigt.
Es gibt DOM-Elemente, die mehreren visuellen Objekten entsprechen. Das sind in der Regel Elemente mit komplexer Struktur, die nicht durch ein einzelnes Rechteck beschrieben werden können. Das Element „select“ hat beispielsweise drei Renderer: einen für den Anzeigebereich, einen für das Drop-down-Listenfeld und einen für die Schaltfläche. Auch wenn Text in mehrere Zeilen aufgeteilt wird, weil die Breite nicht für eine Zeile ausreicht, werden die neuen Zeilen als zusätzliche Renderer hinzugefügt.
Ein weiteres Beispiel für mehrere Renderer ist fehlerhaftes HTML. Gemäß der CSS-Spezifikation darf ein Inline-Element entweder nur Blockelemente oder nur Inline-Elemente enthalten. Bei gemischten Inhalten werden anonyme Block-Renderer erstellt, um die Inline-Elemente einzubetten.
Einige Rendering-Objekte entsprechen einem DOM-Knoten, aber nicht an derselben Stelle im Baum. Elemente, die „floaten“ und absolut positioniert sind, befinden sich nicht im Fluss, werden an einem anderen Teil des Baums platziert und dem tatsächlichen Frame zugeordnet. An dieser Stelle sollte ein Platzhalterrahmen zu sehen sein.
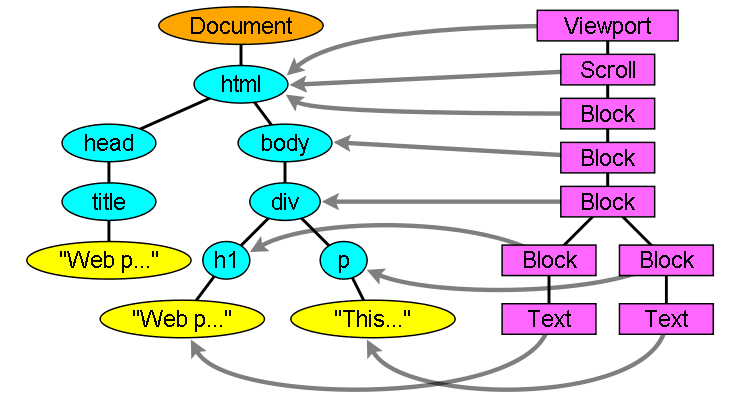
Ablauf des Erstellens des Baums
In Firefox wird die Präsentation als Listener für DOM-Aktualisierungen registriert.
Die Präsentation delegiert die Frame-Erstellung an den FrameConstructor und der Konstruktor löst den Stil auf (siehe Stilberechnung) und erstellt einen Frame.
In WebKit wird das Auflösen des Stils und Erstellen eines Renderers als „Attachment“ bezeichnet. Jeder DOM-Knoten hat eine „attach“-Methode. Das Anhängen ist synchron. Beim Einfügen eines Knotens in den DOM-Baum wird die Methode „attach“ des neuen Knotens aufgerufen.
Durch die Verarbeitung der html- und body-Tags wird der Stamm des Renderbaums erstellt.
Das Stamm-Renderobjekt entspricht dem sogenannten „enthaltenden Block“ in der CSS-Spezifikation: dem obersten Block, der alle anderen Blöcke enthält. Die Abmessungen sind der Darstellungsbereich: die Abmessungen des Anzeigebereichs des Browserfensters.
In Firefox wird es als ViewPortFrame und in WebKit als RenderView bezeichnet.
Das ist das Renderobjekt, auf das das Dokument verweist.
Der Rest des Baums wird als DOM-Knoten eingefügt.
Weitere Informationen finden Sie in der CSS2-Spezifikation zum Verarbeitungsmodell.
Stilberechnung
Zum Erstellen des Renderbaums müssen die visuellen Eigenschaften jedes Renderobjekts berechnet werden. Dazu werden die Stileigenschaften der einzelnen Elemente berechnet.
Der Stil enthält Stylesheets verschiedener Herkunft, Inline-Stilelemente und visuelle Eigenschaften in der HTML-Datei (z. B. die Eigenschaft „bgcolor“). Letztere werden in entsprechende CSS-Stileigenschaften übersetzt.
Die Ursprünge von Stylesheets sind die Standard-Stylesheets des Browsers, die vom Seitenautor bereitgestellten Stylesheets und die Stylesheets der Nutzer. Letztere werden vom Browsernutzer bereitgestellt. In Browsern können Sie Ihre bevorzugten Stile definieren. In Firefox legen Sie dazu beispielsweise ein Stylesheet im Ordner „Firefox-Profil“ ab.
Die Stilberechnung birgt einige Schwierigkeiten:
- Stildaten sind ein sehr großes Konstrukt, das die zahlreichen Stileigenschaften enthält. Dies kann zu Speicherproblemen führen.
Wenn die Abgleichsregeln für jedes Element nicht optimiert sind, kann das zu Leistungsproblemen führen. Es ist sehr aufwendig, die gesamte Regelliste für jedes Element zu durchsuchen, um Übereinstimmungen zu finden. Auswählen können eine komplexe Struktur haben, die dazu führen kann, dass der Abgleichsprozess auf einem scheinbar vielversprechenden Pfad beginnt, der sich als nutzlos erweist und ein anderer Pfad ausprobiert werden muss.
Beispiel: Dieser zusammengesetzte Selektor:
div div div div{ ... }Die Regeln gelten für ein
<div>, das ein Abkömmling von drei Divs ist. Angenommen, Sie möchten prüfen, ob die Regel für ein bestimmtes<div>-Element gilt. Sie wählen einen bestimmten Pfad im Baum für die Prüfung aus. Möglicherweise müssen Sie den Knotenbaum nach oben durchgehen, um festzustellen, dass es nur zwei divs gibt und die Regel nicht zutrifft. Sie müssen dann andere Pfade im Baum ausprobieren.Die Anwendung der Regeln umfasst recht komplexe Kaskadenregeln, die die Hierarchie der Regeln definieren.
Sehen wir uns an, wie die Browser mit diesen Problemen umgehen:
Stildaten teilen
WebKit-Knoten verweisen auf Stilobjekte (RenderStyle). Diese Objekte können unter bestimmten Bedingungen von Knoten gemeinsam genutzt werden. Die Knoten sind Geschwister oder Cousins und:
- Die Elemente müssen sich im selben Mausstatus befinden.Ein Element kann also nicht :hover sein, während das andere nicht :hover ist.
- Keines der Elemente sollte eine ID haben.
- Die Tag-Namen müssen übereinstimmen.
- Die Klassenattribute müssen übereinstimmen.
- Die zugeordneten Attribute müssen identisch sein.
- Die Status der Verknüpfungen müssen übereinstimmen.
- Die Fokuszustände müssen übereinstimmen.
- Keines der Elemente sollte von Attributselektoren betroffen sein. Als betroffen gilt, wenn ein Selektor mit einem Attributselektor an einer beliebigen Position im Selektor übereinstimmt.
- Die Elemente dürfen kein Inline-Style-Attribut haben.
- Es dürfen keine Geschwisterselektoren verwendet werden. WebCore löst einfach einen globalen Schalter aus, wenn eine Geschwisterauswahl gefunden wird, und deaktiviert die Stilfreigabe für das gesamte Dokument, wenn solche vorhanden sind. Dazu gehören der Selektor „+“ und Selektoren wie „:first-child“ und „:last-child“.
Firefox-Regelbaum
Firefox hat zwei zusätzliche Bäume für eine einfachere Stilberechnung: den Regelbaum und den Stilkontextbaum. WebKit hat auch Stilobjekte, die jedoch nicht in einem Baum wie dem Stilkontextbaum gespeichert werden. Nur der DOM-Knoten verweist auf den entsprechenden Stil.
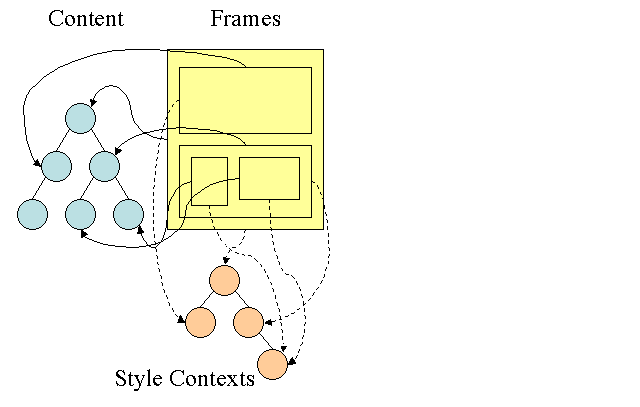
Die Stilkontexte enthalten Endwerte. Die Werte werden berechnet, indem alle Abgleichsregeln in der richtigen Reihenfolge angewendet und Manipulationen durchgeführt werden, die sie von logischen in konkrete Werte umwandeln. Wenn der logische Wert beispielsweise ein Prozentsatz des Bildschirms ist, wird er berechnet und in absolute Einheiten umgewandelt. Die Idee des Regelbaums ist wirklich clever. So können diese Werte zwischen Knoten geteilt werden, um eine erneute Berechnung zu vermeiden. Außerdem sparen Sie Platz.
Alle übereinstimmenden Regeln werden in einem Baum gespeichert. Die untersten Knoten in einem Pfad haben eine höhere Priorität. Der Baum enthält alle Pfade für Regelübereinstimmungen, die gefunden wurden. Das Speichern der Regeln erfolgt verzögert. Der Baum wird nicht zu Beginn für jeden Knoten berechnet. Wenn jedoch ein Knotenstil berechnet werden muss, werden die berechneten Pfade dem Baum hinzugefügt.
Die Baumpfade sollen als Wörter in einem Lexikon betrachtet werden. Angenommen, wir haben diesen Regelbaum bereits berechnet:
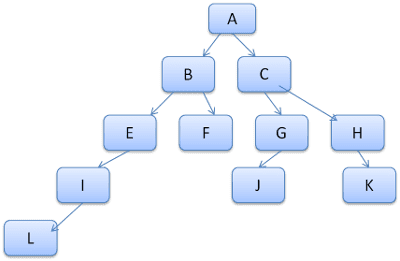
Angenommen, wir müssen Regeln für ein anderes Element im Inhaltsbaum abgleichen und stellen fest, dass die übereinstimmenden Regeln (in der richtigen Reihenfolge) B-E-I sind. Dieser Pfad ist bereits im Baum enthalten, da wir den Pfad A-B-E-I-L bereits berechnet haben. Wir haben jetzt weniger Arbeit.
Sehen wir uns an, wie uns der Baum Arbeit erspart.
Aufteilung in Strukturen
Die Stilkontexte sind in Strukturen unterteilt. Diese Strukturen enthalten Stilinformationen für eine bestimmte Kategorie wie Rahmen oder Farbe. Alle Attribute in einem Typ sind entweder vererbt oder nicht vererbt. Übernommene Eigenschaften sind Eigenschaften, die vom Element übernommen werden, sofern sie nicht vom übergeordneten Element definiert wurden. Für nicht übernommene Eigenschaften (sogenannte „Zurücksetzen“-Eigenschaften) werden Standardwerte verwendet, wenn sie nicht definiert sind.
Der Baum hilft uns, indem er ganze Strukturen (mit den berechneten Endwerten) im Baum zwischenspeichert. Wenn der unterste Knoten keine Definition für ein Strukturobjekt liefert, kann ein im Cache gespeichertes Strukturobjekt in einem übergeordneten Knoten verwendet werden.
Stilkontexte mithilfe des Regelbaums berechnen
Beim Berechnen des Stilkontexts für ein bestimmtes Element berechnen wir zuerst einen Pfad im Regelbaum oder verwenden einen vorhandenen. Anschließend wenden wir die Regeln im Pfad an, um die Strukturen in unserem neuen Stilkontext zu füllen. Wir beginnen am untersten Knoten des Pfades, dem mit der höchsten Priorität (normalerweise der spezifischeste Selektor), und durchlaufen den Baum, bis unser Strukturelement voll ist. Wenn es in diesem Regelknoten keine Spezifikation für das ‑{0} gibt, können wir die Optimierung erheblich verbessern. Dazu gehen wir den Baum nach oben, bis wir einen Knoten finden, der es vollständig spezifiziert und darauf verweist. Das ist die beste Optimierung, da der gesamte ‑{0} geteilt wird. So werden die Berechnung von Endwerten und der Arbeitsspeicher gespart.
Wenn wir teilweise Definitionen finden, gehen wir den Baum nach oben, bis die Struktur vollständig ist.
Wenn wir keine Definitionen für unseren Typ gefunden haben, verweisen wir im Kontextbaum auf den Typ des übergeordneten Elements, falls es sich um einen abgeleiteten Typ handelt. In diesem Fall konnten wir auch Strukturen freigeben. Bei einer zurückgesetzten Struktur werden Standardwerte verwendet.
Wenn der spezifischeste Knoten Werte hinzufügt, müssen wir einige zusätzliche Berechnungen durchführen, um sie in tatsächliche Werte umzuwandeln. Das Ergebnis wird dann im Baumknoten im Cache gespeichert, damit es von untergeordneten Knoten verwendet werden kann.
Wenn ein Element ein Geschwisterelement hat, das auf denselben Baumknoten verweist, kann der gesamte Stilkontext zwischen ihnen geteilt werden.
Sehen wir uns ein Beispiel an: Angenommen, wir haben diesen HTML-Code:
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
Außerdem gelten die folgenden Regeln:
div {margin: 5px; color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
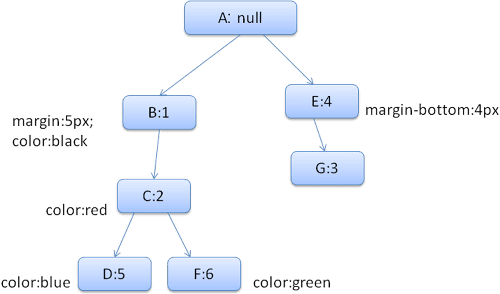
Zur Vereinfachung nehmen wir an, dass wir nur zwei Strukturen ausfüllen müssen: das Farb- und das Rand-Objekt. Das Farb-Objekt enthält nur ein Mitglied: die Farbe. Das Rand-Objekt enthält die vier Seiten.
Das Ergebnis sieht dann so aus (die Knoten sind mit dem Knotennamen gekennzeichnet, also der Nummer der Regel, auf die sie verweisen):
Der Kontextbaum sieht dann so aus (Knotenname: Regelknoten, auf den verwiesen wird):
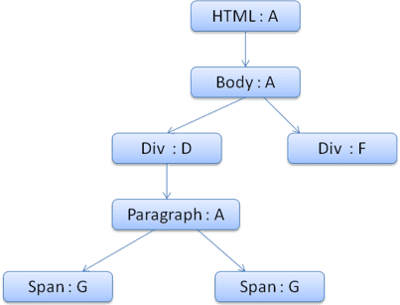
Angenommen, wir analysieren den HTML-Code und gelangen zum zweiten <div>-Tag. Wir müssen einen Stilkontext für diesen Knoten erstellen und seine Stilstrukturen füllen.
Wir vergleichen die Regeln und stellen fest, dass die Regeln 1, 2 und 6 für die <div> gelten.
Das bedeutet, dass im Baum bereits ein Pfad vorhanden ist, den unser Element verwenden kann. Wir müssen ihm nur noch einen weiteren Knoten für Regel 6 (Knoten F im Regelbaum) hinzufügen.
Wir erstellen einen Stilkontext und fügen ihn in den Kontextbaum ein. Der neue Stilkontext verweist auf Knoten F im Regelbaum.
Jetzt müssen wir die Stilstrukturen ausfüllen. Zuerst füllen wir das Margin-Objekt aus. Da der letzte Regelknoten (F) dem Margin-Attribut nichts hinzufügt, können wir den Baum nach oben durchgehen, bis wir ein im Cache gespeichertes Attribut finden, das bei einer vorherigen Knoteneinfügung berechnet wurde, und es verwenden. Wir finden sie bei Knoten B, dem obersten Knoten, für den Randregeln angegeben wurden.
Wir haben eine Definition für die Farbstruktur, daher können wir keine im Cache gespeicherte Struktur verwenden. Da Farbe nur ein Attribut hat, müssen wir nicht den Baum nach oben durchgehen, um andere Attribute auszufüllen. Wir berechnen den Endwert (String in RGB konvertieren usw.) und speichern die berechnete Struktur in diesem Knoten im Cache.
Die Arbeit am zweiten <span>-Element ist noch einfacher. Wir vergleichen die Regeln und stellen fest, dass sie wie die vorherige Spanne auf Regel G verweist.
Da wir Geschwister haben, die auf denselben Knoten verweisen, können wir den gesamten Stilkontext teilen und nur auf den Kontext der vorherigen Spanne verweisen.
Bei Strukturen, die Regeln enthalten, die vom übergeordneten Element übernommen werden, erfolgt das Caching im Kontextbaum. Die Farbeigenschaft wird zwar übernommen, aber in Firefox als zurückgesetzt behandelt und im Regelbaum im Cache gespeichert.
Angenommen, wir haben Regeln für Schriftarten in einem Absatz hinzugefügt:
p {font-family: Verdana; font size: 10px; font-weight: bold}
Dann könnte das Absatzelement, das im Kontextbaum ein untergeordnetes Element des div-Elements ist, dieselbe Schriftstruktur wie sein übergeordnetes Element haben. Das ist der Fall, wenn für den Absatz keine Schriftschnittregeln festgelegt wurden.
In WebKit, das kein Regelbaum hat, werden die übereinstimmenden Deklarationen viermal durchlaufen. Zuerst werden nicht wichtige Properties mit hoher Priorität angewendet (Properties, die zuerst angewendet werden sollten, weil andere davon abhängen, z. B. Displayanzeigen), dann wichtige Properties mit hoher Priorität, dann nicht wichtige Properties mit normaler Priorität und schließlich wichtige Regeln mit normaler Priorität. Das bedeutet, dass Properties, die mehrmals vorkommen, gemäß der richtigen Kaskadenabfolge aufgelöst werden. Der Letzte gewinnt.
Zusammenfassend lässt sich sagen: Wenn Sie die Stilobjekte (vollständig oder einige der darin enthaltenen Strukturen) teilen, werden Probleme 1 und 3 behoben. Das Firefox-Regelnetzwerk hilft auch dabei, die Properties in der richtigen Reihenfolge anzuwenden.
Regeln für eine einfache Übereinstimmung anpassen
Es gibt mehrere Quellen für Stilregeln:
- CSS-Regeln, entweder in externen Stylesheets oder in Stilelementen.
css p {color: blue} - Inline-Style-Attribute wie
html <p style="color: blue" /> - Visuelle HTML-Attribute (die den relevanten Stilregeln zugeordnet sind)
html <p bgcolor="blue" />Die letzten beiden können leicht mit dem Element abgeglichen werden, da es die Stilattribute besitzt und HTML-Attribute mit dem Element als Schlüssel zugeordnet werden können.
Wie bereits bei Problem 2 erwähnt, kann die Übereinstimmung mit CSS-Regeln etwas kniffliger sein. Um das Problem zu lösen, werden die Regeln für einen einfacheren Zugriff manipuliert.
Nach dem Parsen des Stylesheets werden die Regeln je nach Auswahl einer von mehreren Hash-Maps hinzugefügt. Es gibt Zuordnungen nach ID, nach Kursnamen, nach Tagnamen und eine allgemeine Zuordnung für alles, was nicht in diese Kategorien fällt. Wenn die Auswahl eine ID ist, wird die Regel der ID-Zuordnung hinzugefügt. Bei einer Klasse wird sie der Klassenzuordnung hinzugefügt usw.
Dadurch lassen sich Regeln viel einfacher abgleichen. Es ist nicht nötig, in jeder Deklaration nachzusehen: Wir können die relevanten Regeln für ein Element aus den Zuordnungen extrahieren. Durch diese Optimierung werden über 95% der Regeln eliminiert, sodass sie beim Abgleich(4.1) nicht berücksichtigt werden müssen.
Sehen wir uns beispielsweise die folgenden Stilregeln an:
p.error {color: red}
#messageDiv {height: 50px}
div {margin: 5px}
Die erste Regel wird in die Klassenzuordnung eingefügt. Die zweite in die ID-Zuordnung und die dritte in die Tag-Zuordnung.
Für das folgende HTML-Fragment:
<p class="error">an error occurred</p>
<div id=" messageDiv">this is a message</div>
Wir versuchen zuerst, Regeln für das Element „p“ zu finden. Die Klassenzuordnung enthält den Schlüssel „error“, unter dem die Regel für „p.error“ gefunden wird. Das div-Element enthält relevante Regeln in der ID-Zuordnung (Schlüssel ist die ID) und in der Tag-Zuordnung. Jetzt müssen Sie nur noch herausfinden, welche der Regeln, die anhand der Schlüssel extrahiert wurden, wirklich übereinstimmen.
Angenommen, die Regel für das Div-Element lautet:
table div {margin: 5px}
Es wird weiterhin aus der Tag-Map extrahiert, da der Schlüssel der rechtseste Selektor ist, aber es würde nicht mit unserem Div-Element übereinstimmen, das keinen übergeordneten Tabellenknoten hat.
Sowohl WebKit als auch Firefox führen diese Manipulation durch.
Cascading Style Sheet-Reihenfolge
Das Stilobjekt hat Eigenschaften, die jedem visuellen Attribut entsprechen (alle CSS-Attribute, aber allgemeiner). Wenn die Eigenschaft von keinem der übereinstimmenden Regeln definiert ist, können einige Eigenschaften vom Stilobjekt des übergeordneten Elements übernommen werden. Für andere Properties gelten Standardwerte.
Das Problem beginnt, wenn es mehr als eine Definition gibt. Hier kommt die Kaskadenabfolge zur Lösung des Problems.
Eine Deklaration für eine Stileigenschaft kann in mehreren Stylesheets und mehrmals in einem Stylesheet vorkommen. Die Reihenfolge der Anwendung der Regeln ist daher sehr wichtig. Dies wird als „Kaskadierung“ bezeichnet. Gemäß der CSS2-Spezifikation ist die Kaskadenreihenfolge (von niedrig nach hoch):
- Browserdeklarationen
- Normale Erklärungen für Nutzer
- Normale Deklarationen von Autoren
- Wichtige Erklärungen des Autors
- Wichtige Erklärungen für Nutzer
Die Browserdeklarationen sind am wenigsten wichtig und der Nutzer überschreibt die Angaben des Autors nur, wenn die Deklaration als wichtig gekennzeichnet wurde. Deklarationen mit derselben Reihenfolge werden nach Spezifität und dann nach der Reihenfolge sortiert, in der sie angegeben sind. Die visuellen HTML-Attribute werden in übereinstimmende CSS-Deklarationen umgewandelt . Sie werden als Autorregeln mit niedriger Priorität behandelt.
Spezifität
Die Spezifität des Selektors wird in der CSS2-Spezifikation so definiert:
- „1“, wenn die Deklaration ein „style“-Attribut und keine Regel mit einem Selektor ist, andernfalls „0“ (= a)
- Anzahl der ID-Attribute im Selektor zählen (= b)
- Anzahl der anderen Attribute und Pseudoklassen in der Auswahl (= c)
- die Anzahl der Elementnamen und Pseudoelemente im Selektor zählen (= d)
Die Zusammensetzung der vier Zahlen a-b-c-d (in einem Zahlensystem mit einer großen Basis) ergibt die Spezifität.
Die zu verwendende Basis wird durch die höchste Anzahl in einer der Kategorien bestimmt.
Wenn a beispielsweise 14 ist, können Sie die Hexadezimalbasis verwenden. Für den unwahrscheinlichen Fall, dass a=17 ist, benötigen Sie eine 17-stellige Zahlenbasis. Letzteres kann mit einem solchen Selector passieren: html body div div p… (17 Tags in Ihrem Selector… nicht sehr wahrscheinlich).
Beispiele:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
Regeln sortieren
Nach der Übereinstimmung werden die Regeln gemäß den Kaskadenregeln sortiert.
WebKit verwendet die Bubble-Sortierung für kleine Listen und die Zusammenführungssortierung für große Listen.
WebKit implementiert die Sortierung, indem der >-Operator für die Regeln überschrieben wird:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
Gradueller Prozess
WebKit verwendet ein Flag, das angibt, ob alle Stylesheets der obersten Ebene (einschließlich @imports) geladen wurden. Wenn der Stil beim Anhängen nicht vollständig geladen ist, werden Platzhalter verwendet und das Dokument wird entsprechend gekennzeichnet. Die Platzhalter werden neu berechnet, sobald die Stylesheets geladen wurden.
Layout
Wenn der Renderer erstellt und dem Baum hinzugefügt wird, hat er keine Position und Größe. Die Berechnung dieser Werte wird als Layout oder Reflow bezeichnet.
HTML verwendet ein flussbasiertes Layoutmodell. Das bedeutet, dass die Geometrie in den meisten Fällen in einem einzigen Durchlauf berechnet werden kann. Elemente, die später im Fluss sind, wirken sich in der Regel nicht auf die Geometrie von Elementen aus, die früher im Fluss sind. Das Layout kann also von links nach rechts und von oben nach unten durch das Dokument verlaufen. Es gibt Ausnahmen: Für HTML-Tabellen ist beispielsweise möglicherweise mehr als ein Pass erforderlich.
Das Koordinatensystem ist relativ zum Stamm-Frame. Es werden die Koordinaten für oben und links verwendet.
Das Layout ist ein rekursiver Prozess. Es beginnt beim Stamm-Renderer, der dem <html>-Element des HTML-Dokuments entspricht. Das Layout wird rekursiv durch einen Teil oder die gesamte Framehierarchie fortgesetzt und geometrische Informationen für jeden Renderer berechnet, der sie benötigt.
Die Position des Stamm-Renderers ist 0,0 und seine Abmessungen entsprechen dem Darstellungsbereich, also dem sichtbaren Teil des Browserfensters.
Alle Renderer haben eine „layout“- oder „reflow“-Methode. Jeder Renderer ruft die Layoutmethode seiner untergeordneten Elemente auf, die ein Layout benötigen.
Dirty-Bit-System
Damit nicht bei jeder kleinen Änderung ein vollständiges Layout erstellt werden muss, verwenden Browser ein „Dirty-Bit“-System. Ein Renderer, der geändert oder hinzugefügt wird, kennzeichnet sich selbst und seine untergeordneten Elemente als „schmutzig“ und muss neu layoutet werden.
Es gibt zwei Flags: „dirty“ und „children are dirty“. Das bedeutet, dass der Renderer selbst zwar in Ordnung sein kann, aber mindestens ein untergeordnetes Element ein Layout benötigt.
Globales und inkrementelles Layout
Das Layout kann für den gesamten Renderbaum ausgelöst werden – dies ist das „globale“ Layout. Das kann folgende Ursachen haben:
- Eine globale Stiländerung, die sich auf alle Renderer auswirkt, z. B. eine Änderung der Schriftgröße.
- Aufgrund einer Größenänderung des Bildschirms
Das Layout kann inkrementell erfolgen, d. h., nur die Renderer, die geändert wurden, werden neu angeordnet. Dies kann zu Schäden führen, die zusätzliche Layouts erfordern.
Das inkrementelle Layout wird (asynchron) ausgelöst, wenn Renderer ungültig sind. Das ist beispielsweise der Fall, wenn dem Renderbaum neue Renderer hinzugefügt werden, nachdem zusätzliche Inhalte aus dem Netzwerk gekommen und dem DOM-Baum hinzugefügt wurden.
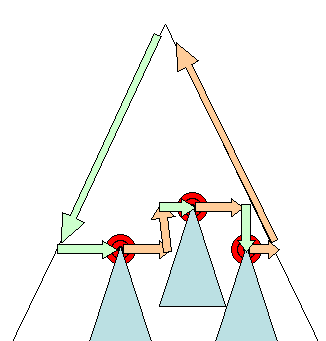
Asynchrones und synchrones Layout
Das inkrementelle Layout wird asynchron ausgeführt. Firefox stellt „Neuformatierungsbefehle“ für inkrementelle Layouts in die Warteschlange und ein Scheduler löst die Batchausführung dieser Befehle aus. WebKit hat auch einen Timer, der ein inkrementelles Layout ausführt. Der Baum wird durchlaufen und „schmutzige“ Renderer werden neu layoutet.
Scripts, die nach Stilinformationen wie „offsetHeight“ fragen, können ein inkrementelles Layout synchron auslösen.
Das globale Layout wird in der Regel synchron ausgelöst.
Manchmal wird das Layout als Rückruf nach einem ersten Layout ausgelöst, weil sich einige Attribute wie die Scrollposition geändert haben.
Optimierungen
Wenn ein Layout durch eine „Größenänderung“ oder eine Änderung der Renderer-Position(nicht der Größe) ausgelöst wird, werden die Rendering-Größen aus einem Cache übernommen und nicht neu berechnet.
In einigen Fällen wird nur ein untergeordneter Baum geändert und das Layout beginnt nicht am Stamm. Das kann passieren, wenn die Änderung lokal ist und sich nicht auf die Umgebung auswirkt, z. B. Text, der in Textfelder eingefügt wird. Andernfalls würde jeder Tastenanschlag ein Layout auslösen, das vom Stammelement ausgeht.
Der Layoutprozess
Das Layout hat in der Regel das folgende Muster:
- Der übergeordnete Renderer bestimmt seine eigene Breite.
- Das übergeordnete Element enthält untergeordnete Elemente und:
- Platzieren Sie den untergeordneten Renderer (festlegen von x und y).
- Ruft bei Bedarf das untergeordnete Layout auf, wenn es ungültig ist oder sich in einem globalen Layout befindet oder aus einem anderen Grund, wodurch die Höhe des untergeordneten Elements berechnet wird.
- Das übergeordnete Element verwendet die Gesamthöhe der untergeordneten Elemente und die Höhen von Rändern und Abständen, um seine eigene Höhe festzulegen. Diese wird vom übergeordneten Element des übergeordneten Renderers verwendet.
- Setzt das schmutzige Bit auf „false“.
Firefox verwendet ein „Status“-Objekt(nsHTMLReflowState) als Parameter für das Layout (sogenannter „Reflow“). Der Status enthält unter anderem die Breite des übergeordneten Elements.
Die Ausgabe des Firefox-Layouts ist ein „metrics“-Objekt(nsHTMLReflowMetrics). Sie enthält die vom Renderer berechnete Höhe.
Breite berechnen
Die Breite des Renderers wird anhand der Breite des Containerblocks, des Stilattributs „width“ des Renderers sowie der Ränder und Rahmen berechnet.
Beispielsweise die Breite des folgenden Div-Elements:
<div style="width: 30%"/>
Wird von WebKit so berechnet(Klasse RenderBox, Methode calcWidth):
- Die Containerbreite ist das Maximum aus „availableWidth“ und 0. In diesem Fall ist „availableWidth“ die „contentWidth“, die so berechnet wird:
clientWidth() - paddingLeft() - paddingRight()
clientWidth und clientHeight geben die Innenabmessungen eines Objekts an, ohne Rahmen und Bildlaufleiste.
Die Breite des Elements wird durch das Stilattribut „width“ festgelegt. Er wird als absoluter Wert berechnet, indem der Prozentsatz der Containerbreite ermittelt wird.
Die horizontalen Rahmen und Abstände sind jetzt hinzugefügt.
Bisher ging es um die Berechnung der „bevorzugten Breite“. Jetzt werden die minimale und maximale Breite berechnet.
Wenn die bevorzugte Breite größer als die maximale Breite ist, wird die maximale Breite verwendet. Ist sie kleiner als die Mindestbreite (die kleinste unzerbrechliche Einheit), wird die Mindestbreite verwendet.
Die Werte werden im Cache gespeichert, falls ein Layout benötigt wird, sich die Breite aber nicht ändert.
Zeilenumbrüche
Wenn ein Renderer in der Mitte eines Layouts feststellt, dass ein Seitenumbruch erforderlich ist, stoppt er und überträgt die Information an das übergeordnete Element des Layouts, dass ein Seitenumbruch erforderlich ist. Das übergeordnete Element erstellt die zusätzlichen Renderer und ruft das Layout auf.
Malerei
In der Malphase wird der Renderbaum durchlaufen und die Methode „paint()“ des Renderers aufgerufen, um Inhalte auf dem Bildschirm anzuzeigen. Für das Malen wird die UI-Infrastrukturkomponente verwendet.
Global und inkrementell
Wie das Layout kann auch das Malen global sein – der gesamte Baum wird gemalt – oder inkrementell. Bei der inkrementellen Darstellung ändern sich einige der Renderer so, dass sich das nicht auf den gesamten Baum auswirkt. Der geänderte Renderer macht sein Rechteck auf dem Bildschirm ungültig. Das Betriebssystem erkennt dies als „unbeschriebene Region“ und generiert ein „Paint“-Ereignis. Das Betriebssystem macht das auf clevere Weise und verschmilzt mehrere Regionen zu einer. In Chrome ist es komplizierter, da sich der Renderer in einem anderen Prozess als der Hauptprozess befindet. Chrome simuliert das Betriebssystemverhalten in gewissem Maße. Die Präsentation überwacht diese Ereignisse und delegiert die Nachricht an den Render-Stamm. Der Baum wird durchlaufen, bis der entsprechende Renderer erreicht wird. Es wird neu gemalt (und in der Regel auch seine untergeordneten Elemente).
Die Malanordnung
CSS2 definiert die Reihenfolge des Malvorgangs. Das ist die Reihenfolge, in der die Elemente in den Stapelungskontexten gestapelt werden. Diese Reihenfolge wirkt sich auf das Malen aus, da die Stapel von hinten nach vorne gemalt werden. Die Stapelreihenfolge eines Block-Renderers ist:
- Hintergrundfarbe
- Hintergrundbild
- border
- Kinder
- Outline
Firefox-Anzeigeliste
Firefox durchsucht den Renderbaum und erstellt eine Displayliste für das gemalte Rechteck. Es enthält die für das Rechteck relevanten Renderer in der richtigen Malreihenfolge (Hintergründe der Renderer, dann Rahmen usw.).
So muss der Baum nur einmal für eine Neumalerei durchlaufen werden, anstatt mehrmals – alle Hintergründe, dann alle Bilder, dann alle Rahmen usw.
Firefox optimiert den Prozess, indem keine Elemente hinzugefügt werden, die ausgeblendet werden, z. B. Elemente, die vollständig unter anderen undurchsichtigen Elementen liegen.
WebKit-Rechteckspeicher
Vor dem Neuzeichnen speichert WebKit das alte Rechteck als Bitmap. Es wird dann nur das Delta zwischen dem neuen und dem alten Rechteck dargestellt.
Dynamische Änderungen
Die Browser versuchen, auf eine Änderung so wenig wie möglich zu reagieren. Änderungen an der Farbe eines Elements führen also nur dazu, dass das Element neu gemalt wird. Änderungen an der Elementposition führen dazu, dass das Element, seine untergeordneten Elemente und möglicherweise auch seine Geschwister neu angeordnet und neu gerendert werden. Wenn Sie einen DOM-Knoten hinzufügen, wird das Layout neu erstellt und der Knoten neu gemalt. Größere Änderungen, z. B. die Erhöhung der Schriftgröße des „html“-Elements, führen dazu, dass Caches ungültig werden, das Layout neu erstellt und der gesamte Baum neu gerendert wird.
Die Threads der Rendering-Engine
Die Rendering-Engine ist ein einzelner Thread. Fast alles, mit Ausnahme von Netzwerkoperationen, geschieht in einem einzigen Thread. In Firefox und Safari ist dies der Hauptthread des Browsers. In Chrome ist es der Haupt-Thread des Tab-Prozesses.
Netzwerkvorgänge können von mehreren parallelen Threads ausgeführt werden. Die Anzahl der parallelen Verbindungen ist begrenzt (in der Regel 2 bis 6 Verbindungen).
Ereignisschleife
Der Haupt-Thread des Browsers ist ein Ereignis-Loop. Es ist eine Endlosschleife, die den Prozess am Laufen hält. Es wartet auf Ereignisse wie Layout- und Paint-Ereignisse und verarbeitet sie. Dies ist der Firefox-Code für den Haupt-Ereignis-Loop:
while (!mExiting)
NS_ProcessNextEvent(thread);
Visuelles CSS2-Modell
Canvas
Gemäß der CSS2-Spezifikation beschreibt der Begriff „Canvas“ den „Raum, in dem die Formatierungsstruktur gerendert wird“, also den Bereich, in dem der Browser den Inhalt anzeigt.
Der Canvas ist für jede Dimension des Bereichs unendlich, aber Browser wählen eine anfängliche Breite basierend auf den Dimensionen des Darstellungsbereichs aus.
Gemäß www.w3.org/TR/CSS2/zindex.html ist der Canvas transparent, wenn er sich in einem anderen Canvas befindet, und hat eine vom Browser definierte Farbe, wenn dies nicht der Fall ist.
CSS-Box-Modell
Das CSS-Box-Modell beschreibt die rechteckigen Felder, die für Elemente im Dokumentenbaum generiert und gemäß dem visuellen Formatierungsmodell angeordnet werden.
Jedes Feld hat einen Inhaltsbereich (z.B. Text, ein Bild usw.) und optionale Ränder, Rahmen und Margen.
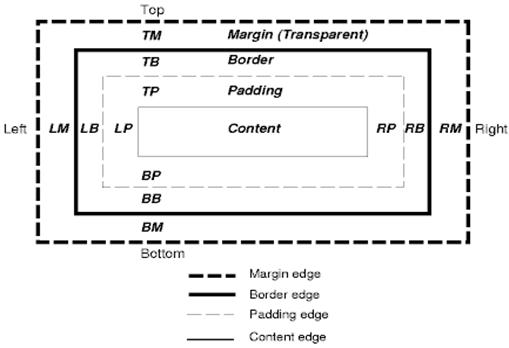
Jeder Knoten generiert 0…n solche Felder.
Alle Elemente haben das Attribut „display“, das den Typ des Felds bestimmt, das generiert wird.
Beispiele:
block: generates a block box.
inline: generates one or more inline boxes.
none: no box is generated.
Standardmäßig ist „inline“ festgelegt, aber das Browser-Stylesheet kann andere Standardeinstellungen festlegen. Beispiel: Die Standardanzeige für das „div“-Element ist „block“.
Ein Beispiel für ein Standard-Stylesheet finden Sie hier: www.w3.org/TR/CSS2/sample.html.
Positionierungsschema
Es gibt drei Systeme:
- Normal: Das Objekt wird an seiner Position im Dokument platziert. Das bedeutet, dass sein Platz im Renderbaum dem Platz im DOM-Baum entspricht und er entsprechend seinem Boxtyp und seinen Abmessungen angeordnet wird.
- „Float“ (Schweben): Das Objekt wird zuerst wie beim normalen Fluss angeordnet und dann so weit wie möglich nach links oder rechts verschoben.
- Absolut: Das Objekt wird im Renderbaum an einer anderen Stelle als im DOM-Baum platziert.
Das Positionierungsschema wird durch die Eigenschaft „position“ und das Attribut „float“ festgelegt.
- „static“ und „relative“ führen zu einem normalen Ablauf.
- „absolute“ und „fixed“ führen zu einer absoluten Positionierung.
Bei der statischen Positionierung wird keine Position definiert und die Standardpositionierung verwendet. Bei den anderen Schemata gibt der Autor die Position an: oben, unten, links oder rechts.
Die Anordnung des Felds wird durch Folgendes bestimmt:
- Box-Typ
- Boxabmessungen
- Positionierungsschema
- Externe Informationen wie Bildgröße und Bildschirmgröße
Box-Typen
Blockfeld: bildet einen Block und hat ein eigenes Rechteck im Browserfenster.

Inline-Box: Hat keinen eigenen Block, sondern befindet sich in einem enthaltenden Block.
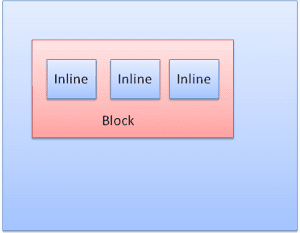
Die Blöcke werden nacheinander vertikal formatiert. Inline-Elemente werden horizontal formatiert.
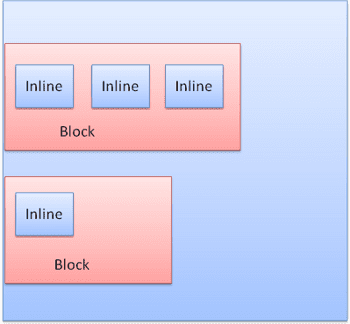
Inline-Boxen werden in Linien oder „Zeilen-Boxen“ eingefügt. Die Linien sind mindestens so hoch wie das höchste Feld, können aber auch höher sein, wenn die Felder „an der Basis“ ausgerichtet sind. Das bedeutet, dass der untere Teil eines Elements an einem Punkt eines anderen Felds ausgerichtet ist, der nicht der untere Rand ist. Wenn die Containerbreite nicht ausreicht, werden die Inline-Elemente auf mehrere Zeilen verteilt. Das ist in der Regel in einem Absatz der Fall.
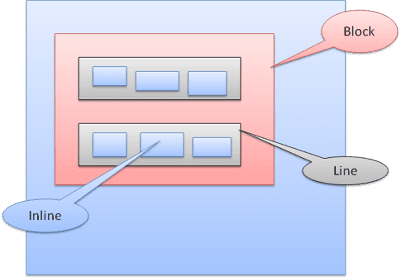
Positionierung
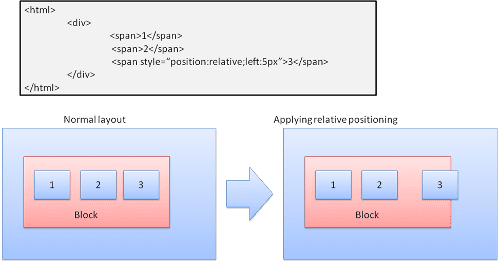
Verwandter
Relative Positionierung: Die Elemente werden wie gewohnt positioniert und dann um das erforderliche Delta verschoben.
Float
Ein Floating-Box wird nach links oder rechts einer Zeile verschoben. Das Interessante ist, dass die anderen Felder darum herumfließen. HTML-Code:
<p>
<img style="float: right" src="images/image.gif" width="100" height="100">
Lorem ipsum dolor sit amet, consectetuer...
</p>
Sie sieht so aus:

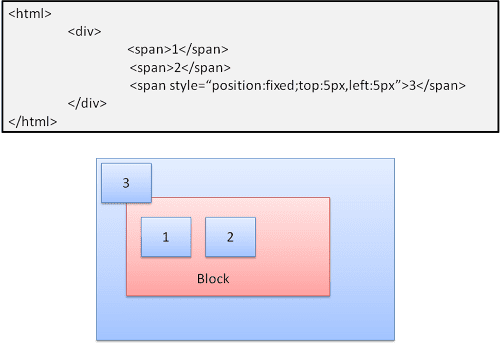
Absolut und fix
Das Layout wird unabhängig vom normalen Ablauf genau definiert. Das Element nimmt nicht am normalen Ablauf teil. Die Abmessungen beziehen sich auf den Container. Bei „fixiert“ ist der Container der Darstellungsbereich.
Schichtenbasierte Darstellung
Dies wird durch die CSS-Eigenschaft „Z-Index“ festgelegt. Er stellt die dritte Dimension des Felds dar: seine Position entlang der „Z‑Achse“.
Die Boxen sind in Stapel unterteilt (sogenannte Stapelkontexte). In jedem Stack werden die Elemente im Hintergrund zuerst und die Elemente im Vordergrund oben, also näher am Nutzer, gerendert. Bei Überschneidungen wird das vorherige Element vom vorderen Element verdeckt.
Die Stapel werden nach der Eigenschaft „Z-Index“ sortiert. Blöcke mit der Eigenschaft „Z-Index“ bilden einen lokalen Stapel. Der Darstellungsbereich enthält den äußeren Stack.
Beispiel:
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
Das Ergebnis sieht dann so aus:

Obwohl das rote div im Markup dem grünen vorangestellt ist und im normalen Fluss früher dargestellt worden wäre, ist die Z-Index-Eigenschaft höher, sodass es im Stack, der vom Root-Box gehalten wird, weiter vorne ist.
Ressourcen
Browserarchitektur
- Grosskurth, Alan. Referenzarchitektur für Webbrowser (pdf)
- Gupta, Vineet. Funktionsweise von Browsern – Teil 1: Architektur
Parsen
- Aho, Sethi, Ullman, Compilers: Principles, Techniques, and Tools (auch als „Dragon Book“ bekannt), Addison-Wesley, 1986
- Rick Jelliffe. The Bold and the Beautiful: zwei neue Entwürfe für HTML 5.
Firefox
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers (Google tech talk video)
- L. David Baron, Layout Engine von Mozilla
- L. David Baron, Mozilla Style System Documentation
- Chris Waterson, Notes on HTML Reflow
- Chris Waterson, Gecko Overview
- Alexander Larsson, The life of an HTML HTTP request
WebKit
- David Hyatt, Implementing CSS(part 1)
- David Hyatt, An Overview of WebCore
- David Hyatt, WebCore-Rendering
- David Hyatt, The FOUC Problem
W3C-Spezifikationen
Anleitung zum Erstellen von Browsern
Übersetzungen
Diese Seite wurde zweimal ins Japanische übersetzt:
- How Browsers Work – Behind the Scenes of Modern Web Browsers (ja) von @kosei
- ブラウザってどうやって動いてるの?(モダンWEBブラウザシーンの裏側 von @ikeike443 und @kiyoto01.
Die extern gehosteten Übersetzungen in Koreanisch und Türkisch können Sie sich ansehen.
Vielen Dank an alle!