
クリエイターは、強力な API(IndexedDB や WebCodecs など)とパフォーマンス ツールにより、Kapwing で高品質の動画コンテンツを編集できるようになりました。

パンデミックの始まり以来、オンライン動画の視聴は急速に増加しています。ユーザーは、TikTok、Instagram、YouTube などのプラットフォームで、高品質の動画に多くの時間を費やしています。世界中のクリエイターや小規模ビジネス オーナーは、動画コンテンツを作成するための迅速で使いやすいツールを必要としています。
Kapwing などの企業は、最新の強力な API とパフォーマンス ツールを使用して、こうした動画コンテンツをすべてウェブ上で作成できるようにしています。
Kapwing について
Kapwing は、ゲーム ストリーマー、ミュージシャン、YouTube クリエイター、ミーマーなどのカジュアルなクリエイターを主な対象として設計された、ウェブベースのコラボレーション動画エディタです。また、Facebook や Instagram 広告などの独自のソーシャル コンテンツを簡単に制作する方法を必要とするビジネス オーナーにとっても頼りになるリソースです。
ユーザーは、「動画の切り抜き方法」、「動画に音楽を追加する方法」、「動画のサイズを変更する方法」など、特定のタスクを検索して Kapwing を見つけます。アプリストアに移動してアプリをダウンロードする手間をかけることなく、検索した内容をワンクリックで実行できます。ウェブでは、サポートが必要なタスクを正確に検索して実行できます。
最初のクリックの後、Kapwing ユーザーはさらに多くのことができます。無料のテンプレートを探したり、無料のストック動画の新しいレイヤを追加したり、字幕を挿入したり、動画を文字起こししたり、バックグラウンド ミュージックをアップロードしたりできます。
Kapwing がウェブにリアルタイム編集とコラボレーションをもたらす仕組み
ウェブには独自のメリットがありますが、独自の課題もあります。Kapwing は、さまざまなデバイスとネットワークの状況で、複雑で多層的なプロジェクトをスムーズかつ正確に再生する必要があります。そのために、さまざまなウェブ API を使用して、パフォーマンスと機能の目標を達成しています。
IndexedDB
高パフォーマンスの編集では、ユーザーのすべてのコンテンツがクライアントに存在し、可能な限りネットワークを回避する必要があります。通常、ユーザーがコンテンツに 1 回アクセスするだけのストリーミング サービスとは異なり、YouTube のユーザーは、アップロード後数日、数か月経ってもアセットを頻繁に再利用します。
IndexedDB を使用すると、ファイル システムのような永続ストレージをユーザーに提供できます。その結果、アプリ内のメディア リクエストの 90% 以上がローカルで処理されます。IndexedDB のシステムへの統合は非常に簡単でした。
アプリの読み込み時に実行されるボイラープレートの初期化コードを以下に示します。
import {DBSchema, openDB, deleteDB, IDBPDatabase} from 'idb';
let openIdb: Promise <IDBPDatabase<Schema>>;
const db =
(await openDB) <
Schema >
(
'kapwing',
version, {
upgrade(db, oldVersion) {
if (oldVersion >= 1) {
// assets store schema changed, need to recreate
db.deleteObjectStore('assets');
}
db.createObjectStore('assets', {
keyPath: 'mediaLibraryID'
});
},
async blocked() {
await deleteDB('kapwing');
},
async blocking() {
await deleteDB('kapwing');
},
}
);
バージョンを渡して upgrade 関数を定義します。これは、初期化や、必要に応じてスキーマの更新に使用されます。エラー処理コールバック(blocked と blocking)を渡します。これは、システムが不安定なユーザーの問題を防ぐのに役立つことが判明しています。
最後に、主キー keyPath の定義に注意してください。この例では、mediaLibraryID という一意の ID です。ユーザーがアップローダーまたはサードパーティ拡張機能を使用してメディアをシステムに追加すると、次のコードを使用してメディアをメディア ライブラリに追加します。
export async function addAsset(mediaLibraryID: string, file: File) {
return runWithAssetMutex(mediaLibraryID, async () => {
const assetAlreadyInStore = await (await openIdb).get(
'assets',
mediaLibraryID
);
if (assetAlreadyInStore) return;
const idbVideo: IdbVideo = {
file,
mediaLibraryID,
};
await (await openIdb).add('assets', idbVideo);
});
}
runWithAssetMutex は、IndexedDB アクセスをシリアル化する Google 独自の内部定義関数です。IndexedDB API は非同期であるため、これは読み取り / 変更 / 書き込みタイプのオペレーションに必要です。
次に、ファイルにアクセスする方法について説明します。getAsset 関数は次のとおりです。
export async function getAsset(
mediaLibraryID: string,
source: LayerSource | null | undefined,
location: string
): Promise<IdbAsset | undefined> {
let asset: IdbAsset | undefined;
const { idbCache } = window;
const assetInCache = idbCache[mediaLibraryID];
if (assetInCache && assetInCache.status === 'complete') {
asset = assetInCache.asset;
} else if (assetInCache && assetInCache.status === 'pending') {
asset = await new Promise((res) => {
assetInCache.subscribers.push(res);
});
} else {
idbCache[mediaLibraryID] = { subscribers: [], status: 'pending' };
asset = (await openIdb).get('assets', mediaLibraryID);
idbCache[mediaLibraryID].asset = asset;
idbCache[mediaLibraryID].subscribers.forEach((res: any) => {
res(asset);
});
delete (idbCache[mediaLibraryID] as any).subscribers;
if (asset) {
idbCache[mediaLibraryID].status = 'complete';
} else {
idbCache[mediaLibraryID].status = 'failed';
}
}
return asset;
}
IndexedDB へのアクセスを最小限に抑えるために、独自のデータ構造 idbCache が使用されます。IndexedDB は高速ですが、ローカルメモリへのアクセスは高速です。キャッシュのサイズを管理する場合は、この方法をおすすめします。
IndexedDB への同時アクセスを防ぐために使用される subscribers 配列は、それ以外の場合は読み込み時に共通です。
Web Audio API
動画編集では、音声の可視化が非常に重要です。理由を理解するには、エディタのスクリーンショットをご覧ください。
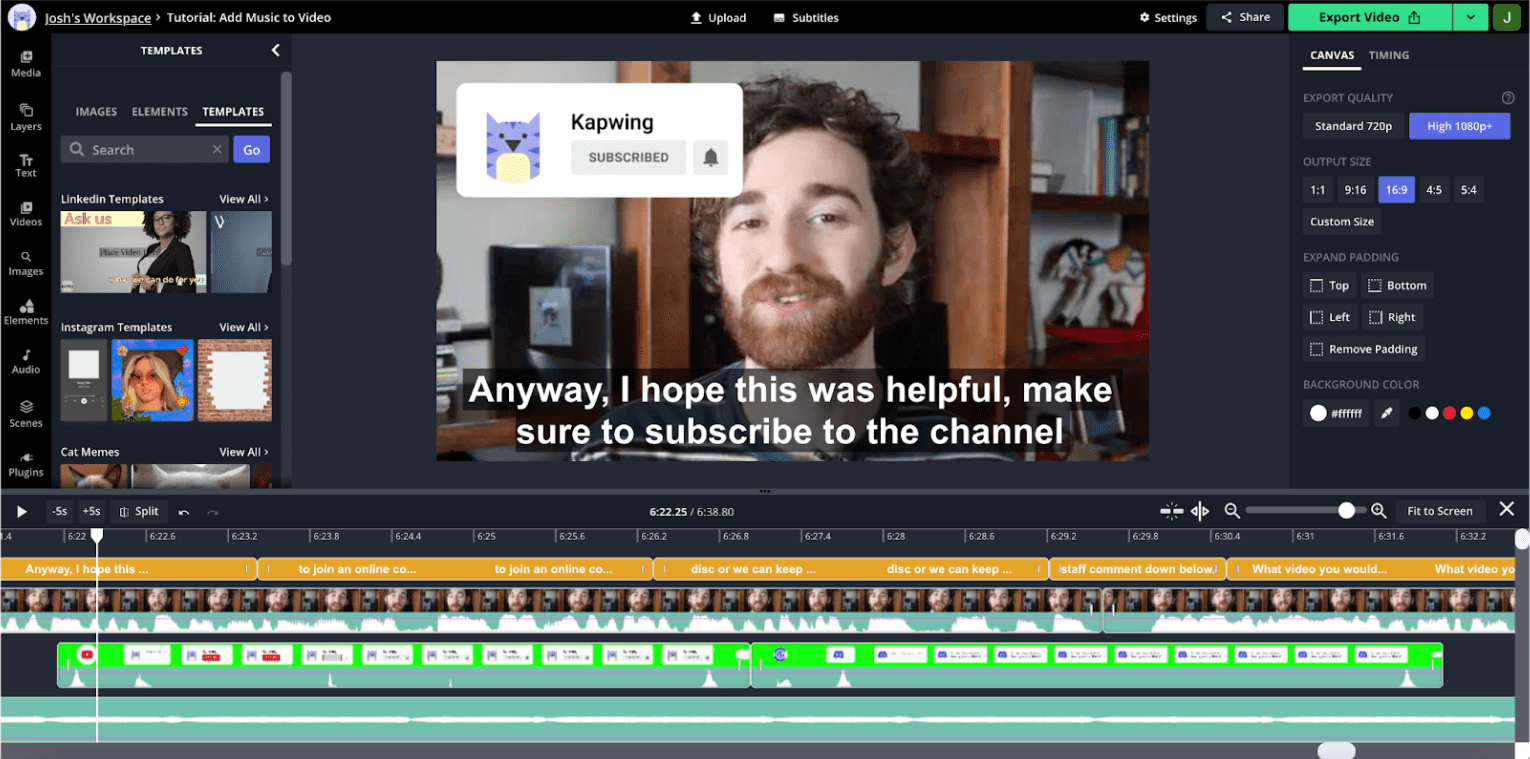
これは YouTube スタイルの動画で、YouTube アプリでよく見られます。ユーザーがクリップ内を移動することはほとんどないため、タイムラインのビジュアル サムネイルはセクション間の移動にはあまり役立ちません。一方、音声の波形にはピークと谷があり、谷は通常、録音中のデッドタイムに対応しています。タイムラインを拡大すると、途切れや一時停止に対応する谷がある、よりきめ細かいオーディオ情報が表示されます。
ユーザー調査によると、クリエイターはコンテンツを分割する際に、これらの波形を参考にすることがよくあります。web audio API を使用すると、この情報を高パフォーマンスで表示し、タイムラインのズームやパンで迅速に更新できます。
以下のスニペットは、その方法を示しています。
const getDownsampledBuffer = (idbAsset: IdbAsset) =>
decodeMutex.runExclusive(
async (): Promise<Float32Array> => {
const arrayBuffer = await idbAsset.file.arrayBuffer();
const audioContext = new AudioContext();
const audioBuffer = await audioContext.decodeAudioData(arrayBuffer);
const offline = new OfflineAudioContext(
audioBuffer.numberOfChannels,
audioBuffer.duration * MIN_BROWSER_SUPPORTED_SAMPLE_RATE,
MIN_BROWSER_SUPPORTED_SAMPLE_RATE
);
const downsampleSource = offline.createBufferSource();
downsampleSource.buffer = audioBuffer;
downsampleSource.start(0);
downsampleSource.connect(offline.destination);
const downsampledBuffer22K = await offline.startRendering();
const downsampledBuffer22KData = downsampledBuffer22K.getChannelData(0);
const downsampledBuffer = new Float32Array(
Math.floor(
downsampledBuffer22KData.length / POST_BROWSER_SAMPLE_INTERVAL
)
);
for (
let i = 0, j = 0;
i < downsampledBuffer22KData.length;
i += POST_BROWSER_SAMPLE_INTERVAL, j += 1
) {
let sum = 0;
for (let k = 0; k < POST_BROWSER_SAMPLE_INTERVAL; k += 1) {
sum += Math.abs(downsampledBuffer22KData[i + k]);
}
const avg = sum / POST_BROWSER_SAMPLE_INTERVAL;
downsampledBuffer[j] = avg;
}
return downsampledBuffer;
}
);
このヘルパーには、IndexedDB に保存されているアセットを渡します。完了すると、IndexedDB のアセットと独自のキャッシュが更新されます。
AudioContext コンストラクタを使用して audioBuffer に関するデータを収集しますが、デバイスのハードウェアにレンダリングしないため、OfflineAudioContext を使用して ArrayBuffer にレンダリングし、振幅データを保存します。
API 自体は、効果的な可視化に必要なサンプリング レートよりもはるかに高いサンプリング レートでデータを返します。そのため、Google では 200 Hz に手動でダウンサンプリングしています。これは、視覚的に魅力的で有用な波形に十分であることがわかったためです。
WebCodecs
動画によっては、タイムライン ナビゲーションには波形よりもトラックのサムネイルの方が役に立つことがあります。ただし、サムネイルの生成は、波形の生成よりもリソースを消費します。
読み込み時にすべてのサムネイルをキャッシュに保存することはできないため、タイムラインのパン / ズームでの高速デコードは、パフォーマンスと応答性に優れたアプリにとって重要です。フレームのスムーズな描画のボトルネックとなるのはフレームのデコードです。最近までは、HTML5 動画プレーヤーを使用していました。このアプローチのパフォーマンスは信頼性が低く、フレーム レンダリング中にアプリの応答性が低下することがよくありました。
最近、ウェブワーカーで使用できる WebCodecs に移行しました。これにより、メインスレッドのパフォーマンスに影響を与えることなく、大量のレイヤのサムネイルを描画できるようになります。ウェブワーカーの実装はまだ進行中ですが、既存のメインスレッドの実装の概要を以下に示します。
動画ファイルには、動画、音声、字幕などの複数のストリームが「結合」されています。WebCodecs を使用するには、まずデマルチプレックスされた動画ストリームが必要です。以下に示すように、mp4box ライブラリで mp4s を demux します。
async function create(demuxer: any) {
demuxer.file = (await MP4Box).createFile();
demuxer.file.onReady = (info: any) => {
demuxer.info = info;
demuxer._info_resolver(info);
};
demuxer.loadMetadata();
}
const loadMetadata = async () => {
let offset = 0;
const asset = await getAsset(this.mediaLibraryId, null, this.url);
const maxFetchOffset = asset?.file.size || 0;
const end = offset + FETCH_SIZE;
const response = await fetch(this.url, {
headers: { range: `bytes=${offset}-${end}` },
});
const reader = response.body.getReader();
let done, value;
while (!done) {
({ done, value } = await reader.read());
if (done) {
this.file.flush();
break;
}
const buf: ArrayBufferLike & { fileStart?: number } = value.buffer;
buf.fileStart = offset;
offset = this.file.appendBuffer(buf);
}
};
このスニペットは demuxer クラスを参照します。このクラスは、MP4Box へのインターフェースのカプセル化に使用します。IndexedDB からアセットに再度アクセスします。これらのセグメントはバイト順で保存されている必要はなく、appendBuffer メソッドは次のチャンクのオフセットを返します。
動画フレームをデコードする方法を次に示します。
const getFrameFromVideoDecoder = async (demuxer: any): Promise<any> => {
let desiredSampleIndex = demuxer.getFrameIndexForTimestamp(this.frameTime);
let timestampToMatch: number;
let decodedSample: VideoFrame | null = null;
const outputCallback = (frame: VideoFrame) => {
if (frame.timestamp === timestampToMatch) decodedSample = frame;
else frame.close();
};
const decoder = new VideoDecoder({
output: outputCallback,
});
const {
codec,
codecWidth,
codecHeight,
description,
} = demuxer.getDecoderConfigurationInfo();
decoder.configure({ codec, codecWidth, codecHeight, description });
/* begin demuxer interface */
const preceedingKeyFrameIndex = demuxer.getPreceedingKeyFrameIndex(
desiredSampleIndex
);
const trak_id = demuxer.trak_id
const trak = demuxer.moov.traks.find((trak: any) => trak.tkhd.track_id === trak_id);
const data = await demuxer.getFrameDataRange(
preceedingKeyFrameIndex,
desiredSampleIndex
);
/* end demuxer interface */
for (let i = preceedingKeyFrameIndex; i <= desiredSampleIndex; i += 1) {
const sample = trak.samples[i];
const sampleData = data.readNBytes(
sample.offset,
sample.size
);
const sampleType = sample.is_sync ? 'key' : 'delta';
const encodedFrame = new EncodedVideoChunk({
sampleType,
timestamp: sample.cts,
duration: sample.duration,
samapleData,
});
if (i === desiredSampleIndex)
timestampToMatch = encodedFrame.timestamp;
decoder.decodeEncodedFrame(encodedFrame, i);
}
await decoder.flush();
return { type: 'value', value: decodedSample };
};
デマルチプレクサーの構造は非常に複雑なため、この記事では扱いません。各フレームは、samples というタイトルの配列に保存されます。デマルチプライヤーを使用して、目的のタイムスタンプに最も近い前のキーフレームを見つけます。このフレームで動画のデコードを開始する必要があります。
動画は、キーフレームまたは I フレームと呼ばれるフルフレームと、p フレームまたは b フレームと呼ばれるはるかに小さい差分フレームで構成されています。デコードは常にキーフレームから開始する必要があります。
アプリケーションは次の方法でフレームをデコードします。
- フレーム出力コールバックを使用してデコーダをインスタンス化する。
- 特定のコーデックと入力解像度のデコーダを構成する。
- デマルチプライヤーのデータを使用して
encodedVideoChunkを作成する。 decodeEncodedFrameメソッドを呼び出す。
これを、目的のタイムスタンプを持つフレームに到達するまで実行します。
次のステップ
Google では、フロントエンドにおけるスケールを、プロジェクトが大規模化、複雑化しても、正確でパフォーマンスの高い再生を維持する能力と定義しています。パフォーマンスをスケーリングする 1 つの方法は、一度にマウントする動画をできるだけ少なくすることですが、そうすると、切り替えが遅く途切れる可能性があります。Google は、動画コンポーネントをキャッシュに保存して再利用するための内部システムを開発していますが、HTML5 動画タグで提供できる制御には限界があります。
今後、すべてのメディアを WebCodecs を使用して再生する可能性があります。これにより、パフォーマンスのスケーリングに役立つバッファリングするデータを正確に把握することができます。
また、大規模なトラックパッドの計算を ウェブワーカーにオフロードする処理をより効率的に行うことができ、ファイルのプリフェッチやフレームのプリ生成をよりスマートに行うことができます。アプリケーション全体のパフォーマンスを最適化し、WebGL などのツールを使用して機能を拡張する大きな機会があります。
Google は、現在インテリジェントな背景除去に使用している TensorFlow.js への投資を継続したいと考えています。Google は、オブジェクト検出、特徴抽出、スタイル転送などの他の高度なタスクにも TensorFlow.js を活用する予定です。
最終的には、無料かつオープンなウェブ上で、ネイティブに近いパフォーマンスと機能を備えたプロダクトの開発を継続していく予定です。