
Jak powstają nowoczesne przeglądarki


Wstęp
Ten obszerny przewodnik po wewnętrznych działaniach WebKita i Gecko jest wynikiem wielu badań przeprowadzonych przez izraelskiego programistę Tali Garsiel. Przez kilka lat analizowała wszystkie opublikowane dane o wewnętrznych mechanizmach przeglądarki i poświęciła dużo czasu na czytanie kodu źródłowego przeglądarki internetowej. Napisała:
Jako deweloper witryn internetowych poznanie wewnętrznych mechanizmów działania przeglądarek pomoże Ci podejmować lepsze decyzje i poznać uzasadnienie sprawdzonych metod rozwoju. Ten dokument jest dość obszerny, ale warto poświęcić trochę czasu na zapoznanie się z jego treścią. Warto.
Paul Irish, zespół ds. relacji z deweloperami Chrome
Wprowadzenie
Przeglądarki internetowe to najczęściej używane oprogramowanie. W tym wprowadzeniu wyjaśnię, jak działają one w tle. Zobaczymy, co się dzieje, gdy wpisujesz google.comw pasku adresu, aż do momentu, gdy na ekranie przeglądarki pojawi się strona Google.
Przeglądarki, o których będziemy mówić
Obecnie na komputerach używa się 5 głównych przeglądarek: Chrome, Internet Explorer, Firefox, Safari i Opera. Na urządzeniach mobilnych główne przeglądarki to Android Browser, iPhone, Opera Mini i Opera Mobile, UC Browser, przeglądarki Nokia S40/S60 i Chrome. Wszystkie one, z wyjątkiem przeglądarek Opera, są oparte na WebKit. Podam przykłady z przeglądarek open source Firefox i Chrome oraz Safari (który jest częściowo open source). Według statystyk StatCounter (stan na czerwiec 2013 r.) przeglądarki Chrome, Firefox i Safari stanowią około 71% użytkowników przeglądarek na komputery. Na urządzeniach mobilnych przeglądarki Android, iPhone i Chrome stanowią około 54% użytkowników.
Główne funkcje przeglądarki
Główną funkcją przeglądarki jest prezentowanie wybranych zasobów internetowych. Aby to zrobić, przeglądarka wysyła żądanie do serwera i wyświetla zasób w oknie przeglądarki. Zasób jest zwykle dokumentem HTML, ale może też być plikiem PDF, obrazem lub innym rodzajem treści. Lokalizacja zasobu jest określana przez użytkownika za pomocą identyfikatora URI (Uniform Resource Identifier).
Sposób interpretowania i wyświetlania plików HTML przez przeglądarkę jest określony w specyfikacjach HTML i CSS. Te specyfikacje są utrzymywane przez organizację W3C (World Wide Web Consortium), która jest organizacją zajmującą się opracowywaniem standardów internetowych. Przez lata przeglądarki stosowały się tylko do części specyfikacji i opracowywały własne rozszerzenia. Spowodowało to poważne problemy ze zgodnością dla autorów stron internetowych. Obecnie większość przeglądarek mniej lub bardziej odpowiada specyfikacji.
Interfejsy przeglądarek mają ze sobą wiele wspólnego. Typowe elementy interfejsu użytkownika:
- Pasek adresu do wstawiania identyfikatora URI
- przyciski Wstecz i Dalej,
- Opcje zakładek
- przyciski odświeżania i zatrzymywania służące do odświeżania lub zatrzymywania wczytywania bieżących dokumentów;
- przycisk ekranu głównego, który przenosi Cię na stronę główną;
Co ciekawe, interfejs użytkownika przeglądarki nie jest określony w żadnej specyfikacji, a po prostu wynika z dobrych praktyk kształtowanych przez lata doświadczenia i przez przeglądarki naśladujące siebie nawzajem. Specyfikacja HTML5 nie definiuje elementów interfejsu, które musi zawierać przeglądarka, ale wymienia niektóre typowe elementy. Dotyczy to na przykład paska adresu, paska stanu i paska narzędzi. Oczywiście istnieją funkcje charakterystyczne dla danej przeglądarki, takie jak menedżer pobierania w Firefoksie.
Infrastruktura na wysokim poziomie
Główne komponenty przeglądarki to:
- Interfejs użytkownika: obejmuje pasek adresu, przycisk Wstecz/Dalej, menu zakładek itp. Każdą część ekranu przeglądarki, z wyjątkiem okna, w którym wyświetla się żądana strona.
- Silnik przeglądarki: zarządza działaniami między interfejsem użytkownika a silnikiem renderowania.
- Silnik renderowania: odpowiada za wyświetlanie żądanych treści. Jeśli na przykład żądane treści to HTML, mechanizm renderowania przeanalizuje kod HTML i CSS, a następnie wyświetli przeanalizowane treści na ekranie.
- Sieci: do wywołań sieciowych, takich jak żądania HTTP, z użyciem różnych implementacji na różnych platformach za pomocą interfejsu niezależnego od platformy.
- UI backend: służy do wyświetlania podstawowych widżetów, takich jak listy rozwijane i okna. Ten backend udostępnia ogólny interfejs, który nie jest powiązany z konkretną platformą. Pod spodem używa metod interfejsu systemu operacyjnego.
- Współczynnik JavaScript. Służy do analizowania i wykonywania kodu JavaScript.
- Przechowywanie danych. Jest to warstwa trwałości. Przeglądarka może potrzebować zapisywania na urządzeniu wszystkich rodzajów danych, takich jak pliki cookie. Przeglądarki obsługują też mechanizmy przechowywania takie jak localStorage, IndexedDB, WebSQL i FileSystem.
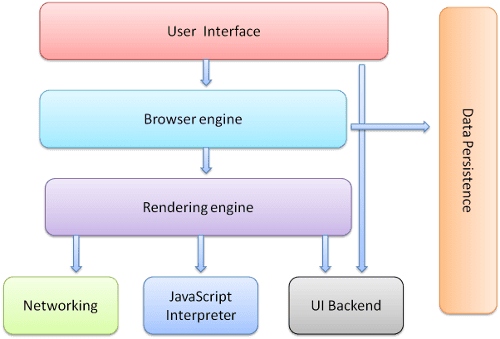
Pamiętaj, że przeglądarki takie jak Chrome uruchamiają wiele instancji silnika renderowania: po jednej na każdą kartę. Każda karta działa w osobnym procesie.
Silniki renderowania
Odpowiada on za renderowanie, czyli wyświetlanie żądanych treści na ekranie przeglądarki.
Domyślnie mechanizm renderowania może wyświetlać dokumenty i obrazy w formacie HTML oraz XML. Może wyświetlać inne typy danych za pomocą wtyczek lub rozszerzeń, np. wyświetlać dokumenty PDF za pomocą wtyczki do przeglądania PDF. W tym rozdziale skupimy się jednak na głównym zastosowaniu: wyświetlaniu kodu HTML i obrazów sformatowanych za pomocą CSS.
Różne przeglądarki używają różnych silników renderowania: Internet Explorer używa Trident, Firefox używa Gecko, a Safari używa WebKit. Chrome i Opera (od wersji 15) używają Blink, który jest odgałęzią WebKit.
WebKit to silnik renderowania typu open source, który początkowo był silnikiem dla platformy Linux, a później został zmodyfikowany przez Apple, aby obsługiwał systemy Mac i Windows.
Główny przepływ
Silnik renderowania zacznie pobierać zawartość żądanego dokumentu z warstwy sieciowej. Zwykle odbywa się to w porcjach po 8 KB.
Następnie silnik renderowania działa w ten sposób:

Silnik renderowania zacznie analizować dokument HTML i konwertować elementy na węzły DOM w drzewie o nazwie „drzewo treści”. Silnik przeanalizuje dane stylu zarówno w zewnętrznych plikach CSS, jak i w elementach stylu. Informacje o stylach wraz z instrukcjami wizualnymi w pliku HTML zostaną wykorzystane do utworzenia innego drzewa: drzewa renderowania.
Drzewo renderowania zawiera prostokąty z atrybutami wizualnymi, takimi jak kolor i wymiary. Prostokąty są w prawidłowej kolejności, aby wyświetlić je na ekranie.
Po utworzeniu drzewa renderowania przechodzi ono proces „layoutu”. Oznacza to, że należy podać dla każdego węzła dokładne współrzędne, w których ma się on pojawić na ekranie. Następnym etapem jest renderowanie – drzewo renderowania zostanie przeanalizowane, a każdy węzeł zostanie namalowany za pomocą warstwy backendowej interfejsu.
Pamiętaj, że jest to proces stopniowy. Aby zapewnić większą wygodę użytkownikom, silnik renderowania będzie się starał wyświetlać treści na ekranie tak szybko, jak to możliwe. Nie będzie czekać, aż cały kod HTML zostanie przeanalizowany, zanim zacznie budować i układać drzewo renderowania. Część treści zostanie przeanalizowana i wyświetlona, a proces będzie kontynuowany w przypadku pozostałych treści, które będą nadal napływać z sieci.
Przykłady głównego przepływu
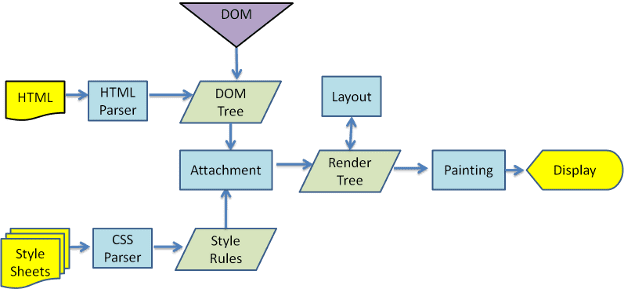
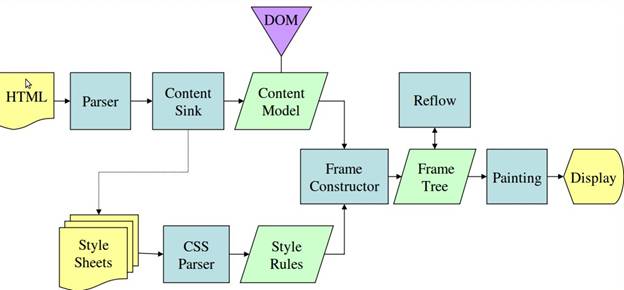
Z rysunków 3 i 4 wynika, że chociaż WebKit i Gecko używają nieco innej terminologii, proces jest w podstawie taki sam.
W Gecko drzewo elementów z wizualnie sformatowanymi elementami nazywa się „drzewem ramki”. Każdy element jest ramką. WebKit używa terminu „drzewo renderowania”, które składa się z „obiektów renderowania”. WebKit używa terminu „layout” do określania rozmieszczania elementów, podczas gdy Gecko używa terminu „Reflow”. „Załącznik” to termin używany w WebKit do określania łączenia węzłów DOM i informacji wizualnych w celu utworzenia drzewa renderowania. Niewielka różnica niesemantyczną jest taka, że Gecko ma dodatkową warstwę między HTML a drzewem DOM. Nazywa się go „content sink” (zbiornik treści) i jest fabryką elementów DOM. Omówimy każdy etap tego procesu:
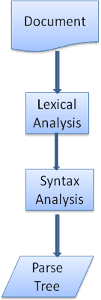
Analizowanie – ogólne
Ponieważ parsowanie jest bardzo ważnym procesem w ramach silnika renderowania, omówimy go nieco dokładniej. Zacznijmy od krótkiego wprowadzenia do analizowania danych.
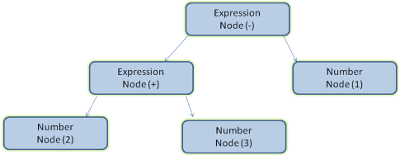
Przetwarzanie dokumentu oznacza przekształcanie go w strukturę, której może używać kod. Wynikiem parsowania jest zwykle drzewo węzłów, które odzwierciedla strukturę dokumentu. Nazywamy ją drzewem analizy lub drzewem składni.
Na przykład zanalizowanie wyrażenia 2 + 3 - 1 może zwrócić to drzewo:
Gramatyka
Analiza opiera się na regułach składni, których przestrzega dokument: języku lub formacie, w którym został napisany. Każdy format, który możesz przeanalizować, musi mieć gramatykę deterministyczną składającą się z słownictwa i reguł składni. Nazywa się ją gramatyką bezkontekstową. Języki ludzkie nie są takimi językami, dlatego nie można ich analizować za pomocą konwencjonalnych technik analizy.
Parser – kombinacja z lexerem
Analiza może być podzielona na 2 podprocesy: analizę leksykalną i analizę składni.
Analiza leksykalna to proces dzielenia danych wejściowych na tokeny. Tokeny to słownictwo językowe: zbiór prawidłowych elementów składowych. W języku ludzkim będzie zawierać wszystkie słowa, które występują w słowniku tego języka.
Analiza składni to stosowanie reguł składni języka.
Przetwarzanie zwykle dzieli się na 2 części: analizator (czasami nazywany też tokenizerem), który odpowiada za dzielenie danych wejściowych na prawidłowe tokeny, oraz analizator, który odpowiada za tworzenie drzewa analizy przez analizowanie struktury dokumentu zgodnie z zasadami składni języka.
Analizator wie, jak usuwać nieistotne znaki, takie jak spacje i znaki podziału wiersza.
Proces analizowania jest iteracyjny. Przetwarzacz zwykle prosi leksykona o nowy token i próbuje dopasować go do jednej z reguł składni. Jeśli reguła zostanie dopasowana, do drzewa parsowania zostanie dodany węzeł odpowiadający temu tokenowi, a parsownik poprosi o kolejne dane.
Jeśli żadna reguła nie pasuje, parsujący będzie przechowywać token wewnętrznie i nadal prosić o tokeny, aż znajdzie regułę pasującą do wszystkich tokenów przechowywanych wewnętrznie. Jeśli nie zostanie znaleziona żadna reguła, parsujący wyrzuci wyjątek. Oznacza to, że dokument był nieprawidłowy i zawierał błędy składni.
Tłumaczenie
W wielu przypadkach drzewo parsowania nie jest produktem końcowym. Analiza jest często używana w tłumaczeniu: przekształca dokument wejściowy w inny format. Przykładem jest kompilacja. Kompilator, który kompiluje kod źródłowy na kod maszynowy, najpierw przetwarza go na drzewo parsowania, a potem przekształca to drzewo w dokument kodu maszynowego.
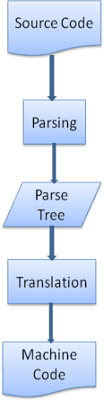
Przykład analizy
Na rysunku 5 widać drzewo parsowania utworzone na podstawie wyrażenia matematycznego. Spróbujmy zdefiniować prosty język matematyczny i zobaczmy, jak przebiega proces analizy.
Składnia:
- Budulcami składni języka są wyrażenia, terminy i operacje.
- Nasz język może zawierać dowolną liczbę wyrażeń.
- Wyrażenie to „wyrażenie” poprzedzone „operacją”, a następnie kolejne „wyrażenie”.
- operacja jest symbolem plusa lub minusa,
- Wyrażenie to liczba całkowita lub wyrażenie
Przeanalizujmy dane wejściowe. 2 + 3 - 1
Pierwszy podciąg pasujący do reguły to 2: zgodnie z regułą 5 jest to termin.
Drugie dopasowanie to 2 + 3: odpowiada ono trzeciej regule: terminowi, po którym następuje operacja, a potem kolejny termin.
Kolejne dopasowanie zostanie znalezione dopiero na końcu ciągu znaków.
2 + 3 - 1 jest wyrażeniem, ponieważ wiemy już, że 2 + 3 jest terminem, więc mamy termin, po którym następuje operacja, a potem kolejny termin.
2 + + nie pasuje do żadnej reguły i dlatego jest nieprawidłowym wejściem.
formalne definicje słownictwa i składni;
Słownictwo jest zwykle wyrażane za pomocą wyrażeń regularnych.
Na przykład nasz język będzie zdefiniowany jako:
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -
Jak widzisz, liczby całkowite są definiowane za pomocą wyrażenia regularnego.
Składnia jest zwykle definiowana w formacie BNF. Nasz język będzie zdefiniowany jako:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
Jak już wspomnieliśmy, język może być analizowany przez zwykłe parsery, jeśli jego gramatyka jest gramatyką bezkontekstową. Intuicyjna definicja gramatyki bezkontekstowej to gramatyka, którą można w pełni wyrazić w BNF. Formalną definicję znajdziesz w artykule w Wikipedii na temat gramatyki bezkontekstowej.
Typy parsowników
Istnieją 2 rodzaje parsowników: od góry do dołu i od dołu do góry. Intuicyjne wyjaśnienie jest takie, że parsery od góry do dołu analizują strukturę składni na wysokim poziomie i próbują znaleźć dopasowanie do reguły. Analizatory od dołu do góry zaczynają od danych wejściowych i stopniowo przekształcają je w reguły składniowe, zaczynając od reguł niskiego poziomu, aż do spełnienia reguł wysokiego poziomu.
Zobaczmy, jak dwa typy parserów przeanalizują nasz przykład.
Analizator od góry do dołu zacznie od reguły wyższego poziomu: zidentyfikuje 2 + 3 jako wyrażenie. Następnie zidentyfikuje 2 + 3 - 1 jako wyrażenie (proces identyfikowania wyrażenia ewoluuje, dopasowując się do innych reguł, ale punktem wyjścia jest reguła najwyższego poziomu).
Parsowanie od dołu będzie skanować dane wejściowe, aż dopasuje regułę. Następnie zastąpi ona pasujące dane wejściowe regułą. Będzie to trwało do końca danych wejściowych. Wyrażenie częściowo dopasowane jest umieszczane na stosie parsowania.
Ten typ parsowania od dołu nazywany jest parsowaniem z przesunięciem i redukcją, ponieważ dane wejściowe są przesuwane w prawo (wyobraź sobie wskaźnik wskazujący na początku danych wejściowych i poruszający się w prawo) oraz stopniowo redukowane do reguł składniowych.
Automatyczne generowanie parsowników
Istnieją narzędzia, które mogą wygenerować parsownik. Podajesz im gramatykę języka – jego słownictwo i reguły składni – a one generują działający parsownik. Tworzenie parsera wymaga dogłębnego poznania procesu parsowania, a ręczne tworzenie zoptymalizowanego parsera nie jest łatwe, dlatego generatory parserów mogą być bardzo przydatne.
WebKit używa dwóch dobrze znanych generatorów analizatorów: Flex do tworzenia leksyfikatora i Bison do tworzenia analizatora (możesz je spotkać pod nazwami Lex i Yacc). Dane wejściowe Flex to plik zawierający definicje wyrażeń regularnych tokenów. Dane wejściowe dla Bison to reguły składni języka w formacie BNF.
Parser HTML
Zadaniem parsera HTML jest przeanalizowanie znaczników HTML i utworzenie drzewa analizy.
Gramatyka HTML
Słownictwo i składnia HTML są zdefiniowane w specyfikacjach opracowanych przez organizację W3C.
Jak już wspomnieliśmy w części poświęconej parsowaniu, składnia gramatyki może być definiowana formalnie za pomocą formatów takich jak BNF.
Niestety wszystkie konwencjonalne tematy dotyczące parsowania nie mają zastosowania w przypadku HTML (nie wspominam o nich tylko dla zabawy – będą używane do parsowania CSS i JavaScript). HTML nie może być łatwo zdefiniowany za pomocą gramatyki bezkontekstowej, której potrzebują parsery.
Istnieje formalny format definiowania HTML – DTD (Document Type Definition), ale nie jest to gramatyka bezkontekstowa.
Na pierwszy rzut oka może to wyglądać dziwnie, ponieważ HTML jest dość podobny do XML. Dostępnych jest wiele analizujących XML. Istnieje odmiana XML HTML – XHTML – jaka jest główna różnica?
Różnica polega na tym, że podejście HTML jest bardziej „wyrozumiałe”: pozwala pominąć niektóre tagi (które są następnie dodawane domyślnie) lub czasami pominąć tagi początkowe i końcowe itp. W ogóle jest to „miękka” składnia, w przeciwieństwie do sztywnej i wymagającej składni XML.
Ta pozornie niewielka zmiana ma ogromne znaczenie. Z jednej strony jest to główny powód, dla którego HTML jest tak popularny: wybacza błędy i ułatwia życie autorowi strony. Z drugiej strony utrudnia to tworzenie gramatyki formalnej. Podsumowując, konwencjonalne parsery nie mogą łatwo przeanalizować kodu HTML, ponieważ jego gramatyka nie jest niezależna od kontekstu. Analizatory XML nie mogą przeanalizować kodu HTML.
DTD HTML
Definicja HTML jest w formacie DTD. Ten format służy do definiowania języków z rodziny SGML. Format zawiera definicje wszystkich dozwolonych elementów, ich atrybutów i hierarchii. Jak już wiemy, DTD HTML nie tworzy gramatyki bezkontekstowej.
Istnieje kilka wersji DTD. Tryb rygorystyczny jest zgodny wyłącznie ze specyfikacjami, ale inne tryby obsługują znaczniki używane przez przeglądarki w przeszłości. Ma to na celu zapewnienie zgodności wstecznej ze starszymi treściami. Aktualna ścisła DTD znajduje się tutaj: www.w3.org/TR/html4/strict.dtd
DOM
Drzewo wyjściowe („drzewo analizy”) to drzewo węzłów atrybutów i elementów DOM. DOM to skrót od Document Object Model (obietkowy model dokumentu). Jest to obiektowa prezentacja dokumentu HTML i interfejs elementów HTML dla świata zewnętrznego, np. JavaScript.
Korzeń drzewa to obiekt „Document”.
DOM jest niemal w 100% powiązany z oznaczaniem. Na przykład:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
Ten znacznik zostanie przekształcony w drzewo DOM o takim wyglądzie:
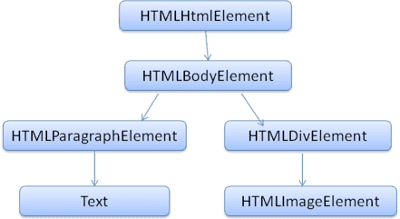
Podobnie jak HTML, DOM jest określany przez organizację W3C. Zobacz www.w3.org/DOM/DOMTR. Jest to ogólna specyfikacja manipulowania dokumentami. Konkretny moduł opisuje konkretne elementy HTML. Definicje HTML można znaleźć tutaj: www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html.
Gdy mówię, że drzewo zawiera węzły DOM, mam na myśli, że drzewo jest zbudowane z elementów, które implementują jeden z interfejsów DOM. Przeglądarki używają konkretnych implementacji, które mają inne atrybuty używane wewnętrznie przez przeglądarkę.
Algorytm analizy
Jak już wspomnieliśmy w poprzednich sekcjach, kodu HTML nie można przeanalizować za pomocą zwykłych analizujących od góry do dołu ani od dołu do góry.
Powody:
- wybaczający charakter języka,
- Fakt, że przeglądarki mają tradycyjną tolerancję na błędy, aby obsługiwać dobrze znane przypadki nieprawidłowego kodu HTML.
- Proces analizy jest wielokrotnie wywoływalny. W przypadku innych języków źródło nie zmienia się podczas analizowania, ale w HTML kod dynamiczny (taki jak elementy skryptu zawierające wywołania
document.write()) może dodawać dodatkowe tokeny, więc proces analizowania faktycznie modyfikuje dane wejściowe.
Ponieważ nie można używać zwykłych technik analizowania, przeglądarki tworzą niestandardowe parsery do analizowania kodu HTML.
Algorytm analizy jest szczegółowo opisany w specyfikacji HTML5. Algorytm składa się z 2 etapów: tokenizacji i tworzenia drzewa.
Tokenizacja to analiza leksykalna, która dzieli dane na tokeny. Do tokenów HTML należą tagi początkowe, tagi końcowe, nazwy atrybutów i wartości atrybutów.
Tokenizer rozpoznaje token, przekazuje go konstruktorowi drzewa i pobiera kolejny znak do rozpoznania kolejnego tokena, i tak dalej aż do końca danych wejściowych.
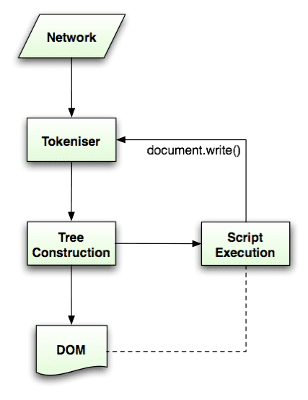
algorytm tokenizacji,
Dane wyjściowe algorytmu to token HTML. Algorytm jest wyrażony jako maszyna stanów. Każdy stan zużywa co najmniej 1 znak ze strumienia wejściowego i zmienia następny stan zgodnie z tymi znakami. Na decyzję ma wpływ bieżący stan tokenizacji i stan tworzenia drzewa. Oznacza to, że ten sam znak konsumpcji da różne wyniki w zależności od bieżącego stanu. Algorytm jest zbyt skomplikowany, aby można go było w pełni opisać, więc zobaczmy prosty przykład, który pomoże nam zrozumieć tę zasadę.
Podstawowy przykład – tokenizacja tego kodu HTML:
<html>
<body>
Hello world
</body>
</html>
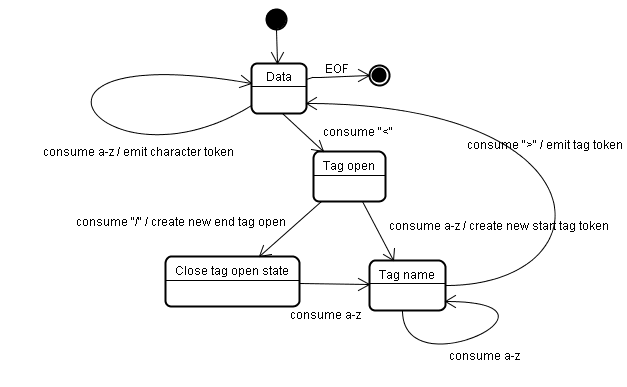
Stan początkowy to „Stan danych”.
Gdy napotka znak <, stan zmienia się na „Tag open state”.
Użycie znaku a-z powoduje utworzenie „tokenu startowego tagu” i zmianę stanu na „Stan nazwy tagu”.
Pozostaniemy w tym stanie, dopóki znak > nie zostanie wykorzystany. Każdy znak jest dołączany do nazwy nowego tokena. W naszym przypadku utworzony token to token html.
Gdy tag > zostanie osiągnięty, zostanie wyemitowany bieżący token, a stan zmieni się z powrotem na „Stan danych”.
Tag <body> będzie traktowany w ten sam sposób.
Do tej pory zostały wyemitowane tagi html i body. Wracamy do „Stanu danych”.
Użycie znaku H w ciągu ciągu Hello world spowoduje utworzenie i wydanie tokena znaku. Będzie to trwać, dopóki nie osiągnie się wartość < w ciągu </body>. Emitujemy token znaku dla każdego znaku w Hello world.
Wracamy do stanu „Tag otwarty”.
Przetworzenie następnego wejścia / spowoduje utworzenie end tag token i przejście do stanu „Nazwa tagu”. Ponownie pozostajemy w tym stanie, dopóki nie dojdziemy do etapu >.Wtedy zostanie wyemitowany nowy token tagu i wrócimy do stanu „Dane”.
Dane wejściowe </html> będą traktowane tak samo jak w poprzednim przypadku.
Algorytm tworzenia drzewa
Podczas tworzenia parsowania tworzony jest obiekt Document. Na etapie tworzenia drzewa zostanie zmodyfikowane drzewo DOM z dokumentem w korzeniach i dodane do niego elementy. Każdy węzeł wyemitowany przez tokenizer zostanie przetworzony przez konstruktor drzewa. W przypadku każdego tokena specyfikacja określa, który element DOM jest dla niego odpowiedni i zostanie utworzony. Element jest dodawany do drzewa DOM, a także do stosu otwartych elementów. Ten element służy do poprawiania niespójności zagnieżdżania i niezamkniętych tagów. Algorytm jest też opisywany jako maszyna stanów. Te stany nazywamy „trybami wstawiania”.
Zobaczmy, jak wygląda proces tworzenia drzewa w przypadku przykładowych danych wejściowych:
<html>
<body>
Hello world
</body>
</html>
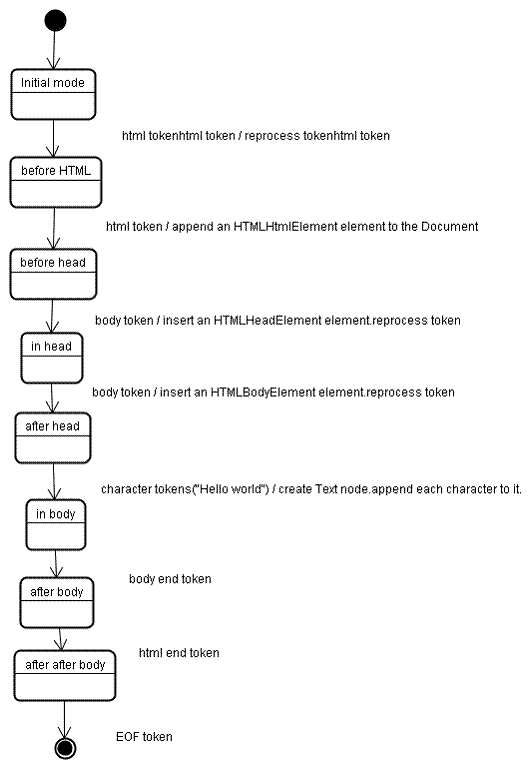
Dane wejściowe na etapie tworzenia drzewa to sekwencja tokenów z etapu tokenizacji. Pierwszy tryb to „tryb początkowy”. Otrzymanie tokenu „html” spowoduje przejście do trybu „przed html” i ponowne przetworzenie tokenu w tym trybie. Spowoduje to utworzenie elementu HTMLHtmlElement, który zostanie dołączony do obiektu Document wyższego poziomu.
Stan zostanie zmieniony na „przed głową”. Następnie otrzymuje się token „body”. Element HTMLHeadElement zostanie utworzony domyślnie, mimo że nie mamy elementu „head”, i zostanie dodany do drzewa.
Przechodzimy teraz do trybu „w głowie”, a potem do trybu „po głowie”. Token treści głównej jest ponownie przetwarzany, tworzony i wstawiany jest element HTMLBodyElement, a tryb jest przenoszony do „w treści głównej”.
Tokeny znaków ciągu „Witaj świecie” zostały już odebrane. Pierwszy z nich spowoduje utworzenie i wstawienie węzła „Tekst”, a pozostałe znaki zostaną do niego dołączone.
Odbieranie tokena zakończenia treści powoduje przejście do trybu „po treści”. Teraz otrzymamy tag końcowy HTML, który przeniesie nas do trybu „after after body”. Odbieranie tokena końca pliku kończy analizowanie.
Działania po zakończeniu analizowania
Na tym etapie przeglądarka oznacza dokument jako interaktywny i rozpoczyna analizowanie skryptów, które są w trybie „opóźnionym”: skryptów, które powinny zostać wykonane po przeanalizowaniu dokumentu. Stan dokumentu zostanie ustawiony na „ukończony”, a zdarzenie „load” zostanie wywołane.
Pełne algorytmy tokenizacji i tworzenia drzewa znajdziesz w specyfikacji HTML5.
Tolerancja błędów w przeglądarkach
Na stronie HTML nigdy nie wystąpi błąd „Nieprawidłowa składnia”. Przeglądarki naprawiają nieprawidłowe treści i kontynuują działanie.
Weźmy na przykład kod HTML:
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
Musimy naruszyć około miliona zasad („mytag” nie jest tagiem standardowym, niewłaściwe zagnieżdżanie elementów „p” i „div” itp.), ale przeglądarka nadal wyświetla go prawidłowo i nie zgłasza żadnych błędów. Większość kodu parsowania służy do poprawiania błędów autora kodu HTML.
Obsługa błędów jest dość spójna w przeglądarkach, ale co zaskakujące, nie była częścią specyfikacji HTML. Podobnie jak przyciski dodawania do zakładek i wstecz/dalej, jest to coś, co w przeglądarkach pojawiło się na przestrzeni lat. W wielu witrynach występują nieprawidłowe konstrukcje HTML, które przeglądarki próbują naprawić w sposób zgodny z innymi przeglądarkami.
Specyfikacja HTML5 definiuje niektóre z tych wymagań. (WebKit ładnie to podsumowuje w komentarzu na początku klasy parsowania HTML).
Parser analizuje podzielony na tokeny tekst, tworząc drzewo dokumentu. Jeśli dokument jest poprawnie sformatowany, jego analizowanie jest proste.
Niestety musimy obsługiwać wiele dokumentów HTML, które nie są poprawnie sformułowane, więc parsujący musi być tolerancyjny wobec błędów.
Musimy rozwiązać co najmniej te problemy:
- Dodawany element jest wyraźnie zabroniony w jakimś tagu zewnętrznym. W tym przypadku powinniśmy zamknąć wszystkie tagi aż do tego, który zakazuje elementu, a potem dodać go.
- Nie możemy dodać elementu bezpośrednio. Być może osoba tworząca dokument zapomniała dodać jakiś tag (lub tag jest opcjonalny). Może to być przypadek z tymi tagami: HTML HEAD BODY TBODY TR TD LI (czy zapomniałem o jakimś?).
- Chcemy dodać element bloku wewnątrz elementu wbudowanego. Zamknij wszystkie elementy wstawiane do następnego elementu bloku o wyższym priorytecie.
- Jeśli to nie pomoże, zamknij elementy, dopóki nie będziemy mogli dodać elementu, lub zignoruj tag.
Oto kilka przykładów tolerancji błędów w WebKit:
</br> zamiast <br>
Niektóre strony używają </br> zamiast <br>. Aby zapewnić zgodność z IE i Firefox, WebKit traktuje to jako <br>.
Kod:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
Pamiętaj, że obsługa błędów jest wewnętrzna: nie będzie widoczna dla użytkownika.
Tabela z błędem
Tabela zewnętrzna to tabela znajdująca się w innej tabeli, ale nie w komórce tabeli.
Na przykład:
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
WebKit zmieni hierarchię na 2 siostry tabel:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
Kod:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
WebKit używa stosu do przechowywania zawartości bieżącego elementu: wyjmuje wewnętrzną tabelę ze stosu zewnętrznej tabeli. Tabele będą teraz tabelami siostrzanymi.
Zagnieżdżone elementy formularza
Jeśli użytkownik umieści formularz w innym formularzu, drugi formularz zostanie zignorowany.
Kod:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
zbyt głęboka hierarchia tagów,
Komentarz mówi sam za siebie.
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
Nieprawidłowo umieszczone tagi zakończenia html lub body
Ponownie – komentarz mówi sam za siebie.
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
Uwaga dla autorów stron internetowych: jeśli nie chcesz, aby Twój kod był przykładem w fragmentach kodu WebKit obsługujących błędy, pisz poprawny kod HTML.
Analiza kodu CSS
Pamiętasz pojęcia dotyczące analizowania z wstępu? W przeciwieństwie do HTML, CSS jest gramatyką bezkontekstową i można ją analizować za pomocą typów parserów opisanych we wstępie. W istocie specyfikacja CSS definiuje składnię i gramatykę leksykalną CSS.
Oto kilka przykładów:
Gramatyka leksykalna (słownictwo) jest definiowana za pomocą wyrażeń regularnych dla każdego elementu:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
„Ident” to skrót od identyfikatora, np. nazwy klasy. „name” to identyfikator elementu (odwołujący się do „#”)
Składnia gramatyki jest opisana w BNF.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
Objaśnienie:
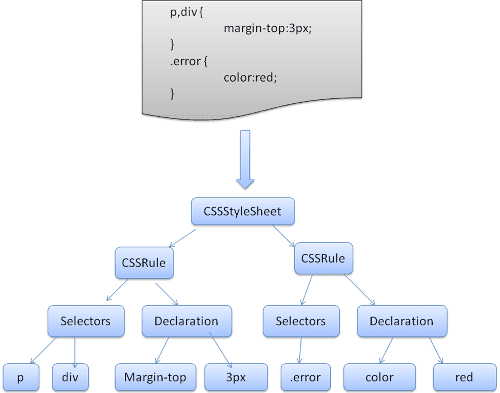
Zestaw reguł ma taką strukturę:
div.error, a.error {
color:red;
font-weight:bold;
}
div.error i a.error to selektory. Część wewnątrz nawiasów klamrowych zawiera reguły stosowane przez ten zestaw reguł.
Ta struktura jest formalnie zdefiniowana w tej definicji:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
Oznacza to, że zestaw reguł to selektor lub opcjonalnie kilka selektorów oddzielonych przecinkami i spacją (S oznacza białą spację). Reguły zawierają nawiasy klamrowe, a w nich deklarację lub opcjonalnie kilka deklaracji oddzielonych średnikami. „declaration” i „selector” zostaną zdefiniowane w następujących definicjach BNF.
WebKit CSS parser
WebKit używa generatorów parserów Flex i Bison do automatycznego tworzenia parserów na podstawie plików gramatyki CSS. Jak zapewne pamiętasz z wprowadzenia do analizatora, Bison tworzy analizatory typu od dołu do góry, które zmniejszają przesunięcie. Firefox używa ręcznie napisanego parsowania od góry do dołu. W obu przypadkach każdy plik CSS jest analizowany w ramach obiektu StyleSheet. Każdy obiekt zawiera reguły CSS. Obiekty reguły CSS zawierają obiekty selektora i deklaracji oraz inne obiekty odpowiadające gramatyce CSS.
Przetwarzanie zamówienia dotyczącego skryptów i arkuszy stylów
Skrypty
Model sieci jest synchroniczny. Autorzy oczekują, że skrypty będą analizowane i wykonywane natychmiast po osiągnięciu przez parsowanie tagu <script>.
Analizowanie dokumentu zostaje wstrzymane do momentu wykonania skryptu.
Jeśli skrypt jest zewnętrzny, zasób musi najpierw zostać pobrany z sieci. Odbywa się to również w sposób synchroniczny, a przetwarzanie zostaje wstrzymane do momentu pobrania zasobu.
Był to model przez wiele lat i jest również określony w specyfikacjach HTML4 i 5.
Autorzy mogą dodać do skryptu atrybut „defer”. W takim przypadku nie zatrzyma on analizowania dokumentu, lecz wykona się po jego zakończeniu. HTML5 umożliwia oznaczenie skryptu jako asynchroniczny, aby został przeanalizowany i wykonany przez inny wątek.
Analiza spekulacyjna
Zarówno WebKit, jak i Firefox wykonują tę optymalizację. Podczas wykonywania skryptów inny wątek analizuje pozostałą część dokumentu i wykrywa, jakie inne zasoby należy pobrać z sieci. Dzięki temu zasoby mogą być ładowane na połączeniach równoległych, co poprawia ogólną szybkość. Uwaga: spekulatywny parser analizuje tylko odwołania do zasobów zewnętrznych, takich jak skrypty zewnętrzne, arkusze stylów i obrazy. Nie modyfikuje drzewa DOM – to zadanie parsera głównego.
arkusze stylów,
Arkusze stylów mają natomiast inny model. Teoretycznie, skoro arkusze stylów nie zmieniają drzewa DOM, nie ma powodu, aby na nie czekać i zatrzymywać analizowania dokumentu. Występuje jednak problem ze skryptami, które wymagają informacji o stylu na etapie analizowania dokumentu. Jeśli styl nie został jeszcze załadowany i przeanalizowany, skrypt otrzyma błędne odpowiedzi, co prawdopodobnie spowodowało wiele problemów. Wygląda na to, że jest to przypadek szczególny, ale dość powszechny. Firefox blokuje wszystkie skrypty, gdy arkusz stylów jest nadal wczytywany i analizowany. WebKit blokuje skrypty tylko wtedy, gdy próbują uzyskać dostęp do określonych właściwości stylów, na które mogą mieć wpływ niewczytane arkusze stylów.
Budowa drzewa w renderze
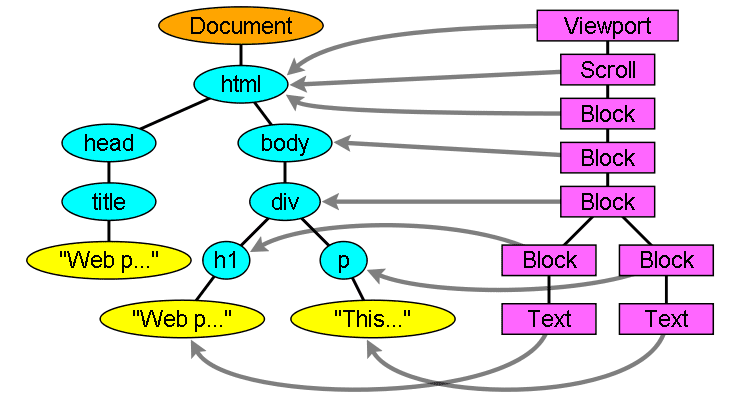
Podczas tworzenia drzewa DOM przeglądarka tworzy też inne drzewo, czyli drzewo renderowania. To drzewo zawiera elementy wizualne w kolejności, w jakiej będą wyświetlane. Jest to wizualna reprezentacja dokumentu. Celem tego drzewa jest umożliwienie wyświetlania treści w prawidłowej kolejności.
W Firefoxie elementy w drzewie renderowania nazywane są „ramkami”. WebKit używa terminu „renderowanie” lub „obiekt renderowania”.
Renderowanie wie, jak rozmieścić i wymalować siebie i swoje podrzędne elementy.
Klasa RenderObject WebKit, która jest klasą podstawową dla renderujących, ma następującą definicję:
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
Każdy renderer reprezentuje prostokątny obszar, który zwykle odpowiada pudełku CSS węzła zgodnie ze specyfikacją CSS2. Zawiera on informacje geometryczne, takie jak szerokość, wysokość i pozycja.
Typ pola zależy od wartości „display” atrybutu style, który jest odpowiedni dla węzła (patrz sekcja obliczanie stylu). Oto kod WebKit, który określa, jaki typ renderowania ma być utworzony dla węzła DOM na podstawie atrybutu wyświetlania:
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
Uwzględniany jest też typ elementu: na przykład elementy sterujące formularza i tabele mają specjalne ramki.
Jeśli element w WebKit chce utworzyć specjalny moduł renderujący, zastąpi on metodę createRenderer().
Wyświetlacze wskazują obiekty stylu, które zawierają informacje niegeometryczne.
relacja drzewa renderowania do drzewa DOM,
Renderery odpowiadają elementom DOM, ale relacja nie jest jeden do jednego. Niewizualne elementy DOM nie zostaną wstawione do drzewa renderowania. Przykładem jest element „head”. Na drzewie nie będą też widoczne elementy, których wartość wyświetlania została ustawiona na „brak” (elementy z widocznością „ukryte” będą widoczne na drzewie).
Istnieją elementy DOM, które odpowiadają kilku elementom wizualnym. Zwykle są to elementy o kompleksowej strukturze, których nie można opisać za pomocą pojedynczego prostokąta. Na przykład element „select” ma 3 renderowanie: jedno dla obszaru wyświetlania, drugie dla pola listy rozwijanej i trzecie dla przycisku. Jeśli tekst jest podzielony na kilka linii, ponieważ nie mieści się na jednej, nowe linie zostaną dodane jako dodatkowe renderowanie.
Innym przykładem wielu procesorów jest uszkodzony kod HTML. Zgodnie ze specyfikacją CSS element wbudowany może zawierać tylko elementy blokowe lub tylko elementy wbudowane. W przypadku treści mieszanych zostaną utworzone anonimowe moduły renderowania bloków, które otaczają elementy wstawiane.
Niektóre obiekty renderowania odpowiadają węzłowi DOM, ale nie znajdują się w tym samym miejscu w drzewie. Elementy pływające i elementy z bezwzględnym pozycjonowaniem są poza przepływem, umieszczone w innej części drzewa i zmapowane na rzeczywistą ramkę. W miejscu, w którym powinny się znajdować, znajduje się ramka z placeholderem.
Proces tworzenia drzewa
W Firefoxie prezentacja jest zarejestrowana jako słuchacz aktualizacji DOM.
Prezentacja deleguje tworzenie ramki do FrameConstructor, a konstruktor rozwiązuje styl (patrz obliczanie stylu) i tworzy ramkę.
W WebKit proces rozwiązywania stylu i tworzenia modułu renderującego nazywa się „attachment” (dodatek). Każdy węzeł DOM ma metodę „attach”. Załącznik jest synchroniczny, a wstawianie węzła do drzewa DOM wywołuje nową metodę węzła „attach”.
Przetwarzanie tagów HTML i body powoduje utworzenie głównego elementu drzewa renderowania.
Obiekt renderowania skojarzony z korzeniami odpowiada temu, co w specyfikacji CSS nazywa się blokiem zawierającym: najwyższym blokiem, który zawiera wszystkie pozostałe bloki. Jego wymiary to widoczny obszar: wymiary obszaru wyświetlania okna przeglądarki.
W Firefox nazywa się to ViewPortFrame, a w WebKit – RenderView.
Jest to obiekt renderowania, do którego odwołuje się dokument.
Pozostała część drzewa jest tworzona jako wstawianie węzłów DOM.
Zapoznaj się ze specyfikacją CSS2 dotyczącą modelu przetwarzania.
Obliczanie stylu
Tworzenie drzewa renderowania wymaga obliczenia właściwości wizualnych każdego obiektu renderowania. Polega to na obliczeniu właściwości stylów poszczególnych elementów.
Styl zawiera arkusze stylów o różnym pochodzeniu, elementy stylów wbudowanych i właściwości wizualne w HTML (np. właściwość „bgcolor”). Te ostatnie są tłumaczone na odpowiadające im właściwości stylu CSS.
Pierwotnymi źródłami arkuszy stylów są domyślne arkusze stylów przeglądarki, arkusze stylów dostarczone przez autora strony oraz arkusze stylów użytkownika – czyli arkusze stylów dostarczone przez użytkownika przeglądarki (przeglądarki umożliwiają definiowanie ulubionych stylów. W Firefoxie można to zrobić, umieszczając arkusz stylów w folderze „Profil Firefoxa”.
Obliczanie stylu wiąże się z kilkoma trudnościami:
- Dane stylu to bardzo duża konstrukcja zawierająca liczne właściwości stylu, co może powodować problemy z pamięcią.
Wyszukiwanie reguł dopasowywania dla poszczególnych elementów może powodować problemy ze skutecznością, jeśli nie są one zoptymalizowane. Przeszukiwanie całej listy reguł w przypadku każdego elementu w celu znalezienia dopasowań jest czasochłonne. Selektory mogą mieć złożoną strukturę, która może spowodować, że proces dopasowywania rozpocznie się od pozornie obiecującej ścieżki, która okaże się bezcelowa, i będzie trzeba wypróbować inną ścieżkę.
Na przykład ten selektor złożony:
div div div div{ ... }Oznacza, że reguły dotyczą elementu
<div>, który jest potomkiem 3 elementów div. Załóżmy, że chcesz sprawdzić, czy reguła ma zastosowanie do danego elementu<div>. Wybierasz pewną ścieżkę w drzewie do sprawdzenia. Możesz musieć przejść przez drzewo węzłów, aby dowiedzieć się, że są tylko 2 divy i że reguła nie ma zastosowania. W takim przypadku musisz wypróbować inne ścieżki w drzewie.Stosowanie reguł wymaga stosowania dość złożonych reguł kaskadowych, które definiują hierarchię reguł.
Zobaczmy, jak przeglądarki radzą sobie z tymi problemami:
Udostępnianie danych o stylach
Węzły WebKit odwołują się do obiektów stylów (RenderStyle). W niektórych przypadkach węzły mogą udostępniać te obiekty. Węzły są węzłami równorzędnymi lub spokrewnionymi:
- Elementy muszą mieć ten sam stan myszy (np.jeden nie może być w stanie :hover, a drugi nie).
- Żaden z elementów nie powinien mieć identyfikatora.
- Nazwy tagów powinny być takie same.
- Atrybuty klasy powinny być takie same.
- Zestaw zmapowanych atrybutów musi być identyczny.
- Stany linków muszą być takie same
- Stany fokusa muszą być takie same
- Żaden z tych elementów nie powinien być dotknięty przez selektory atrybutów, gdzie „dotknięty” oznacza, że dopasowanie selektora używa selektora atrybutu w dowolnej pozycji w selektorze.
- Elementy nie mogą mieć atrybutu stylu wbudowanego.
- Nie można używać żadnych selektorów siostrza. WebCore po prostu uruchamia globalny przełącznik, gdy napotka dowolny selektor siostrza, i wyłącza udostępnianie stylów dla całego dokumentu, gdy takie selektory są obecne. Obejmuje to selektor + oraz selektory takie jak :first-child i :last-child.
Drzewo reguł w Firefoksie
Firefox ma 2 dodatkowe drzewa, które ułatwiają obliczanie stylów: drzewo reguł i drzewo kontekstu stylów. WebKit ma też obiekty stylów, ale nie są one przechowywane w drzewie, tak jak w przypadku drzewa kontekstu stylów. Tylko węzeł DOM wskazuje odpowiedni styl.
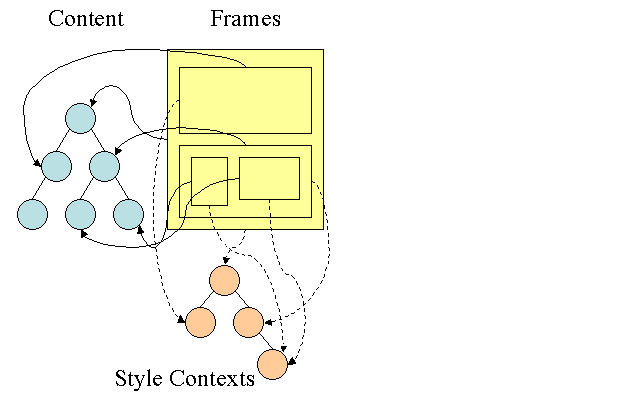
Konteksty stylów zawierają wartości końcowe. Wartości są obliczane przez zastosowanie wszystkich reguł dopasowania w prawidłowej kolejności i przeprowadzenie na nich przekształceń, które przekształcają je z wartości logicznych w konkretne wartości. Jeśli na przykład wartość logiczna jest wyrażona w procentach ekranu, zostanie obliczona i przekształcona na jednostki bezwzględne. Pomysł drzewa reguł jest naprawdę sprytny. Umożliwia to udostępnianie tych wartości między węzłami, aby uniknąć ich ponownego obliczania. Pozwala to też zaoszczędzić miejsce.
Wszystkie dopasowane reguły są przechowywane w drzewie. Dolne węzły na ścieżce mają wyższy priorytet. Drzewo zawiera wszystkie ścieżki do znalezionych dopasowań reguł. Przechowywanie reguł odbywa się w sposób leniwy. Drzewo nie jest obliczane na początku dla każdego węzła, ale zawsze, gdy trzeba obliczyć styl węzła, do drzewa są dodawane obliczone ścieżki.
Chodzi o to, aby zobaczyć ścieżki w drzewie jako słowa w leksykonie. Załóżmy, że mamy już obliczony ten diagram reguł:
Załóżmy, że musimy dopasować reguły do innego elementu w drzewie treści i sprawdzić, które reguły (w prawidłowej kolejności) zostały dopasowane: B-E-I. Ta ścieżka jest już obecna w drzewie, ponieważ została już obliczona ścieżka A-B-E-I-L. Teraz będziemy mieć mniej pracy.
Zobaczmy, jak drzewo oszczędza nam pracę.
Podział na struktury
Konteksty stylów są podzielone na struktury. Te struktury zawierają informacje o stylu dotyczące określonej kategorii, np. obramowania lub koloru. Wszystkie właściwości w strukturze są dziedziczone lub niedziedziczone. Dziedziczone właściwości to właściwości, które, jeśli nie zostały zdefiniowane przez element, są dziedziczone z jego elementu nadrzędnego. Właściwości nie dziedziczone (nazywane „zresetowanymi”) używają wartości domyślnych, jeśli nie zostały zdefiniowane.
Drzewo pomaga nam w przypadku buforowania w drzewie całych struktur (zawierających obliczone wartości końcowe). Jeśli dolny węzeł nie zawiera definicji struktury, można użyć z pamięci podręcznej struktury z węzła wyższego poziomu.
Obliczanie kontekstów stylów za pomocą drzewa reguł
Podczas obliczania kontekstu stylu dla danego elementu najpierw obliczamy ścieżkę w drzewie reguł lub używamy istniejącej ścieżki. Następnie zaczynamy stosować reguły na ścieżce, aby wypełnić struktury w kontekście nowego stylu. Zaczynamy od dolnego węzła ścieżki – tego o najwyższej kolejności (zwykle najbardziej szczegółowego selektora) i przechodzimy w drzewie w górę, aż nasza struktura będzie pełna. Jeśli w danym węźle reguły nie ma specyfikacji struktury, możemy znacznie zoptymalizować działanie. Przechodzimy w drzewie w górę, aż znajdziemy węzeł, który ją w pełni określa i na niego wskazuje. Jest to najlepsza optymalizacja, ponieważ udostępniana jest cała struktura. Pozwala to zaoszczędzić pamięć i czas na obliczenie wartości końcowych.
Jeśli znajdziemy częściowe definicje, przejdziemy w drzewie wyżej, aż struktura zostanie wypełniona.
Jeśli nie znajdziemy żadnych definicji struktury, a struktura jest typu „odziedziczone”, wskazujemy na strukturę rodzica w drzewie kontekstu. W tym przypadku udało nam się też udostępnić struktury. Jeśli jest to struktura resetu, zostaną użyte wartości domyślne.
Jeśli najbardziej szczegółowy węzeł dodaje wartości, musimy wykonać dodatkowe obliczenia, aby przekształcić je w rzeczywiste wartości. Następnie przechowujemy wynik w konkretnym węźle drzewa, aby dzieci mogły z niego korzystać.
Jeśli element ma element siostrzany lub braterski, który wskazuje ten sam węzeł drzewa, cały kontekst stylów może być udostępniany między nimi.
Oto przykład:
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
oraz te reguły:
div {margin: 5px; color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
Aby uprościć sprawę, załóżmy, że musimy wypełnić tylko 2 struktury: kolor i margines. Struktura kolorów zawiera tylko 1 element: kolor. Struktura marginesów zawiera 4 strony.
Wygenerowane drzewo reguł będzie wyglądać tak (węzły są oznaczone nazwą węzła: numerem reguły, do której odnoszą):
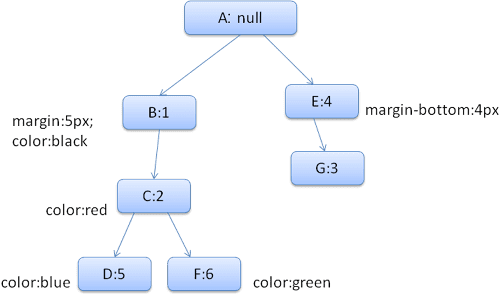
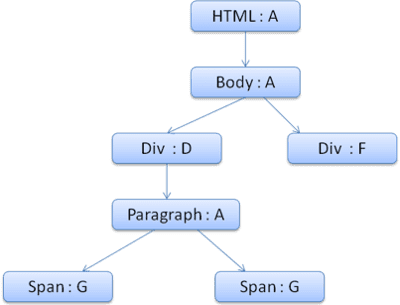
Drzewo kontekstu będzie wyglądać tak (nazwa węzła: węzeł reguły, na który wskazują):
Załóżmy, że zanalizowaliśmy kod HTML i dotarliśmy do drugiego tagu <div>. Musimy utworzyć kontekst stylu dla tego węzła i wypełnić jego struktury stylu.
Dopasujemy reguły i sprawdzimy, że pasujące reguły dla <div> to 1, 2 i 6.
Oznacza to, że w drzewie istnieje już ścieżka, której może użyć nasz element. Musimy tylko dodać do niej kolejny węzeł dla reguły 6 (węzeł F w drzewie reguł).
Utworzymy kontekst stylów i umieścimy go w drzewie kontekstów. Nowy kontekst stylu będzie wskazywać węzeł F w drzewie reguł.
Teraz musimy wypełnić struktury stylów. Zaczniemy od wypełnienia struktury marginesu. Ponieważ ostatni węzeł reguły (F) nie zwiększa struktury marginesów, możemy przejść w drzewie w górę, aż znajdziemy strukturę buforowaną obliczoną w poprzednim wstawieniu węzła, i ją wykorzystać. Znajdziemy go w węźle B, który jest najwyższym węzłem, w którym określone są reguły dotyczące marginesu.
Mamy definicję elementu struct koloru, więc nie możemy użyć elementu struct z bufora. Ponieważ kolor ma jeden atrybut, nie musimy przechodzić w górę drzewa, aby wypełnić inne atrybuty. Obliczymy wartość końcową (konwertujemy ciąg znaków na RGB itp.) i zapiszemy obliczoną strukturę w tym węźle.
Praca nad drugim elementem <span> jest jeszcze łatwiejsza. Dopasujemy reguły i dojdziemy do wniosku, że wskazują one na regułę G, tak jak poprzedni zakres.
Ponieważ mamy elementy siostrzane, które wskazują na ten sam węzeł, możemy udostępnić cały kontekst stylu i wskazywać tylko kontekst poprzedniego elementu.
W przypadku struktur zawierających reguły dziedziczone z elementu nadrzędnego buforowanie odbywa się w drzewie kontekstu (właściwość koloru jest dziedziczona, ale Firefox traktuje ją jako zresetowaną i przechowuje w drzewie reguł).
Jeśli na przykład dodamy reguły dotyczące czcionek w akapicie:
p {font-family: Verdana; font size: 10px; font-weight: bold}
Wtedy element akapitu, który jest elementem podrzędnym elementu div w drzewie kontekstowym, mógł udostępniać tę samą strukturę czcionki co jego element nadrzędny. Jest to możliwe, jeśli nie określono żadnych reguł dotyczących czcionek dla akapitu.
W WebKit, który nie ma drzewa reguł, zgodne deklaracje są przetwarzane 4 razy. Najpierw są stosowane nieważne reguły o wysokim priorytecie (czyli reguły, które powinny być stosowane jako pierwsze, ponieważ inne reguły od nich zależą, np. reguły wyświetlania), potem ważne reguły o wysokim priorytecie, potem nieważne reguły o normalnym priorytecie i na końcu ważne reguły o normalnym priorytecie. Oznacza to, że właściwości, które pojawiają się wielokrotnie, zostaną rozwiązane zgodnie z prawidłową kolejnością kaskadową. Wygrywa ostatni.
Podsumowując: udostępnianie obiektów stylów (w całości lub niektórych struktur w ich wnętrzu) rozwiązuje problemy 1 i 3. Drzewo reguł Firefoxa pomaga też stosować właściwości w prawidłowej kolejności.
Manipulowanie regułami w celu łatwego dopasowania
Istnieje kilka źródeł reguł stylów:
- reguły CSS w zewnętrznych arkuszach stylów lub w elementach stylów.
css p {color: blue} - atrybuty stylów wbudowanych, takie jak
html <p style="color: blue" />; - wizualne atrybuty HTML (które są mapowane na odpowiednie reguły stylu),
html <p bgcolor="blue" />te ostatnie można łatwo dopasować do elementu, ponieważ ma on atrybuty stylu, a atrybuty HTML można mapować, używając elementu jako klucza.
Jak już wspomnieliśmy w problemie 2, dopasowywanie reguł CSS może być bardziej skomplikowane. Aby ułatwić rozwiązanie problemu, reguły są modyfikowane w celu ułatwienia dostępu.
Po przeanalizowaniu arkusza stylów reguły są dodawane do jednej z kilku map haszowych zgodnie z selektorem. Istnieją mapy według identyfikatora, nazwy klasy, nazwy tagu oraz ogólna mapa dla wszystkich elementów, które nie pasują do tych kategorii. Jeśli selektorem jest identyfikator, reguła zostanie dodana do mapy identyfikatorów, a jeśli jest to klasa, zostanie dodana do mapy klas itd.
Ta manipulacja znacznie ułatwia dopasowywanie reguł. Nie trzeba sprawdzać każdej deklaracji: możemy wyodrębnić odpowiednie reguły dla elementu z map. Ta optymalizacja eliminuje ponad 95% reguł, dzięki czemu nie trzeba ich nawet uwzględniać podczas procesu dopasowywania(4.1).
Przyjrzyjmy się na przykład tym regułom dotyczącym stylu:
p.error {color: red}
#messageDiv {height: 50px}
div {margin: 5px}
Pierwsza reguła zostanie wstawiona do mapy zajęć. Drugi do mapy identyfikatorów, a trzeci do mapy tagów.
W przypadku tego fragmentu kodu HTML:
<p class="error">an error occurred</p>
<div id=" messageDiv">this is a message</div>
Najpierw spróbujemy znaleźć reguły dla elementu p. Mapa klasy będzie zawierać klucz „error”, pod którym znajduje się reguła „p.error”. Element div będzie mieć odpowiednie reguły w mapie identyfikatorów (kluczem jest identyfikator) i mapie tagów. Pozostało więc tylko ustalenie, które z reguł wyodrębnionych przez klucze rzeczywiście pasują.
Jeśli na przykład reguła dla elementu div była taka:
table div {margin: 5px}
Nadal będzie wyodrębniany z mapy tagów, ponieważ klucz to selektor znajdujący się najdalej w prawo, ale nie będzie pasować do elementu div, który nie ma przodka tabeli.
Zarówno WebKit, jak i Firefox wykonują tę manipulację.
Kolejność stosowania arkuszy stylów
Obiekt style ma właściwości odpowiadające wszystkim atrybutom wizualnym (wszystkim atrybutom CSS, ale bardziej ogólnym). Jeśli dana właściwość nie jest zdefiniowana przez żadne z pasujących reguł, niektóre właściwości mogą zostać odziedziczone przez obiekt stylu elementu nadrzędnego. Inne właściwości mają wartości domyślne.
Problem pojawia się, gdy istnieje więcej niż 1 definicja – tutaj pojawia się kolejność kaskadowa, która rozwiązuje problem.
Deklaracja właściwości stylu może występować w kilku arkuszach stylów i kilka razy w arkuszu stylu. Oznacza to, że kolejność stosowania reguł jest bardzo ważna. Jest to tzw. kolejność „kaskadowa”. Zgodnie ze specyfikacją CSS2 kolejność kaskadowa (od niskiej do wysokiej) to:
- Deklaracje przeglądarki
- Deklaracje dotyczące normalnych użytkowników
- Deklaracje autora
- Autorzy ważnych deklaracji
- Ważne deklaracje użytkownika
Deklaracje przeglądarki są najmniej ważne, a użytkownik zastępuje deklarację autora tylko wtedy, gdy została ona oznaczona jako ważna. Deklaracje o tym samym porządku zostaną posortowane według szczegółowości, a następnie według kolejności ich podania. Atrybuty wizualne HTML są tłumaczone na odpowiadające im deklaracje CSS . Są one traktowane jako reguły autora o niskim priorytecie.
Zgodność ze specyfikacją
Specyficzność selektora jest zdefiniowana w specyfikacji CSS2 w ten sposób:
- zlicz 1, jeśli deklaracja pochodzi z atrybutu „style”, a nie z reguły z selektorem, a w przeciwnym razie – 0 (= a).
- zlicz liczbę atrybutów identyfikatora w selektorze (= b);
- zlicz liczbę innych atrybutów i pseudoklas w selektorze (= c);
- zlicza liczbę nazw elementów i pseudoelementów w selektorze (= d);
Połączenie 4 liczb a-b-c-d (w systemie liczbowym o dużej podstawie) daje specyficzność.
Podstawa liczbowa, której musisz użyć, jest określona przez najwyższą liczbę w jednej z kategorii.
Jeśli na przykład a=14, możesz użyć podstawy szesnastkowej. W nieprawdopodobnym przypadku, gdy a=17, potrzebna będzie baza liczbowa o długości 17 cyfr. Druga sytuacja może wystąpić przy selektorze takiego jak ten: html body div div p… (17 tagów w selektorze… mało prawdopodobne).
Oto kilka przykładów:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
Sortowanie reguł
Po dopasowaniu reguł są one sortowane zgodnie z regułami kaskadowymi.
WebKit używa sortowania bąbelkowego w przypadku małych list i sortowania scalającego w przypadku dużych.
WebKit implementuje sortowanie przez zastąpienie operatora > w regułach:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
Proces stopniowy
WebKit używa flagi, która wskazuje, czy wszystkie arkusze stylów najwyższego poziomu (w tym @imports) zostały załadowane. Jeśli styl nie jest w pełni załadowany podczas dołączania, używane są substytuty, a styl jest zaznaczony w dokumencie. Po załadowaniu arkuszy stylów zostaną one ponownie obliczone.
Układ
Gdy renderer zostanie utworzony i dodany do drzewa, nie ma pozycji ani rozmiaru. Obliczanie tych wartości nazywa się układem lub ponownym układem.
HTML używa modelu układu opartego na przepływie, co oznacza, że w większości przypadków można obliczyć geometrię w pojedynczym przejściu. Elementy znajdujące się „później w przepływie” zwykle nie wpływają na geometrię elementów znajdujących się „wcześniej w przepływie”, więc układ może być stosowany w dokumentach od lewej do prawej lub od góry do dołu. Wyjątkiem są tabele HTML, które mogą wymagać więcej niż jednego przejścia.
System współrzędnych jest względny względem ramki głównej. Używane są współrzędne góra i lewo.
Układ jest procesem rekurencyjnym. Rozpoczyna się od głównego mechanizmu renderowania, który odpowiada elementowi <html> w dokumencie HTML. Układ przechodzi rekurencyjnie przez całą lub częściową hierarchię ramek, obliczając informacje geometryczne dla każdego wymagającego tego renderowania.
Pozycja głównego renderera to 0,0, a jego wymiary to widoczny obszar przeglądarki.
Wszystkie renderery mają metodę „layout” lub „reflow”. Każdy renderer wywołuje metodę layout swoich elementów, które wymagają ułożenia.
System bitów brudnych
Aby nie tworzyć pełnego układu przy każdej drobnej zmianie, przeglądarki używają systemu „brudnego bitu”. Renderer, który został zmieniony lub dodany, oznacza siebie i swoje elementy podrzędne jako „brudne”: wymagające ułożenia.
Istnieją 2 flagi: „dirty” i „children are dirty”, co oznacza, że chociaż sam renderujący może być OK, ma co najmniej 1 element podrzędny, który wymaga ułożenia.
Układ globalny i przyrostowy
Układ może być uruchamiany w całym drzewie renderowania – jest to „globalny” układ. Może się to zdarzyć z tych powodów:
- Zmiana globalna stylu, która wpływa na wszystkich procesorów, np. zmiana rozmiaru czcionki.
- W wyniku zmiany rozmiaru ekranu
Układ może być stopniowy, a renderowanie będzie dotyczyć tylko nieukończonych renderów (może to spowodować pewne uszkodzenia, które będą wymagać dodatkowych układów).
Układ przyrostowy jest uruchamiany (asymetrycznie), gdy renderowanie jest nieaktualne. Na przykład gdy nowe renderowanie zostanie dodane do drzewa renderowania po tym, jak dodatkowe treści zostały przesłane z sieci i dodane do drzewa DOM.
Układ asynchroniczny i synchroniczny
Układ przyrostowy jest tworzony asynchronicznie. Firefox kolejkuje „polecenia ponownego przepływu” dla przyrostowych układów, a planista uruchamia ich grupowe wykonywanie. WebKit ma też zegar, który wykonuje stopniowe rozmieszczanie – drzewo jest przeszukiwane, a renderowanie „brudnych” renderów jest wyłączane.
Skrypty proszące o informacje o stylu, takie jak „offsetHeight”, mogą wywoływać synchroniczne układy przyrostowe.
Układ globalny jest zwykle uruchamiany synchronicznie.
Czasami układ jest wywoływany jako funkcja zwracająca wartość po początkowym układzie, ponieważ niektóre atrybuty, np. pozycja przewijania, uległy zmianie.
Optymalizacje
Gdy układ jest uruchamiany przez „zmiana rozmiaru” lub zmianę pozycji renderowania(a nie rozmiaru), rozmiary renderowania są pobierane z pamięci podręcznej i nie są ponownie obliczane.
W niektórych przypadkach modyfikowane jest tylko poddrzewo, a nie układ od korzenia. Może się tak zdarzyć, gdy zmiana jest lokalna i nie wpływa na otoczenie – np. tekst wstawiany w polach tekstowych (w przeciwnym razie każda zmiana wciśnięcia klawisza uruchamia układ od korzenia).
Proces układu
Układ ma zwykle taki wzór:
- Nadrzędny moduł renderujący określa własną szerokość.
- Rodzic sprawdza dzieci i:
- Umieść podrzędny procesor graficzny (ustaw jego współrzędne x i y).
- W razie potrzeby wywołuje układ podrzędny (jeśli jest nieczysty lub znajdujemy się w układzie globalnym albo z innego powodu), który oblicza wysokość podrzędnego.
- Element nadrzędny używa łącznej wysokości elementów podrzędnych oraz wysokości marginesów i odstępów, aby ustawić własną wysokość. Będzie ona używana przez element nadrzędny renderowania.
- Ustawia bit zanieczyszczenia na wartość „false” (fałsz).
Firefox używa obiektu „state” (nsHTMLReflowState) jako parametru układu (tzw. „reflow”). Stan zawiera m.in. szerokość rodziców.
Dane wyjściowe układu Firefoxa to obiekt „metrics” (nsHTMLReflowMetrics). Zawiera ona wysokość obliczoną przez renderer.
Obliczanie szerokości
Szerokość renderera jest obliczana na podstawie szerokości bloku kontenera, właściwości stylu „szerokość” renderera oraz marginesów i obramowań.
Na przykład szerokość tego elementu div:
<div style="width: 30%"/>
Obliczane przez WebKit w ten sposób(metoda klasy RenderBox calcWidth):
- Szerokość kontenera to maksymalna wartość z availableWidth i 0. W tym przypadku dostępnychSzerokość to contentWidth, który jest obliczany według wzoru:
clientWidth() - paddingLeft() - paddingRight()
clientWidth i clientHeight reprezentują wnętrze obiektu z wyjątkiem obramowania i paska przewijania.
Szerokość elementów to atrybut stylu „width”. Będzie ona obliczana jako wartość bezwzględna przez obliczenie procentu szerokości kontenera.
Dodano poziome obramowania i odstępy.
Do tej pory było to obliczenie „preferowanej szerokości”. Teraz zostanie obliczona minimalna i maksymalna szerokość.
Jeśli preferowana szerokość jest większa niż maksymalna szerokość, używana jest maksymalna szerokość. Jeśli jest mniejsza niż minimalna szerokość (najmniejsza nierozpadalna jednostka), używana jest minimalna szerokość.
Wartości są zapisywane w pamięci podręcznej na wypadek, gdyby potrzebny był układ, ale jego szerokość nie uległaby zmianie.
Podział wiersza
Gdy w trakcie renderowania układu okazuje się, że trzeba go przerwać, renderowanie zostaje wstrzymane i przekazywane do elementu nadrzędnego układu, aby przerwać renderowanie. Rodzic tworzy dodatkowe moduły renderujące i wywołuje ich układ.
Malarstwo
Na etapie malowania drzewo renderowania jest przeszukiwane, a metoda „paint()” w renderze jest wywoływana, aby wyświetlić zawartość na ekranie. Malowanie używa komponentu infrastruktury interfejsu użytkownika.
Globalne i przyrostowe
Podobnie jak układ, malowanie może być globalne (malowane jest całe drzewo) lub przyrostowe. W ramach malowania cząsteczkowego niektóre z renderowanych elementów zmieniają się w sposób, który nie wpływa na całe drzewo. Zmieniony renderer unieważnia swój prostokąt na ekranie. W rezultacie system operacyjny uzna go za „brudny obszar” i wygeneruje zdarzenie „malowania”. System operacyjny robi to sprytnie, łącząc kilka regionów w jeden. W Chrome jest to bardziej skomplikowane, ponieważ procesor graficzny działa w ramach innego procesu niż proces główny. Chrome w pewnym stopniu symuluje działanie systemu operacyjnego. Prezentacja nasłuchuje tych zdarzeń i przekazuje wiadomość do korzenia renderowania. Drzewo jest przeszukiwane, aż do znalezienia odpowiedniego modułu renderującego. Odświeży się ona sama (i zwykle też jej elementy podrzędne).
Zamówienie na malowanie
CSS2 określa kolejność procesu malowania. Jest to kolejność, w jakiej elementy są ułożone w kontekstach nakładania. Ta kolejność ma wpływ na malowanie, ponieważ elementy są malowane od tyłu do przodu. Kolejność układania bloku:
- background color
- obraz tła
- border
- dzieci
- konspekt
Lista wyświetlania w Firefoksie
Firefox przegląda drzewo renderowania i tworzy listę wyświetlania dla narysowanego prostokąta. Zawiera rendery odpowiednie dla prostokąta w odpowiedniej kolejności wyświetlania (tła renderów, a potem obramowania itd.).
Dzięki temu drzewo musi być przeszukiwane tylko raz podczas odświeżania, zamiast kilka razy – malowania wszystkich tła, a potem wszystkich obrazów, a potem wszystkich obramowań itd.
Firefox optymalizuje ten proces, nie dodając elementów, które będą niewidoczne, takich jak elementy całkowicie ukryte pod innymi nieprzezroczystymi elementami.
Pamięć prostokąta WebKit
Przed ponownym narysowaniem WebKit zapisuje stary prostokąt jako bitmapę. Następnie maluje tylko różnicę między nowym a starym prostokątem.
Zmiany dynamiczne
Przeglądarki starają się wykonywać jak najmniej działań w odpowiedzi na zmiany. Oznacza to, że zmiany koloru elementu spowodują tylko jego ponowne narysowanie. Zmiany pozycji elementu spowodują ułożenie i ponowne narysowanie elementu, jego elementów podrzędnych oraz ewentualnie elementów siostrzanych. Dodanie węzła DOM spowoduje jego ponowne wyrenderowanie i zmianę układu. Duże zmiany, np. zwiększenie rozmiaru czcionki elementu „html”, spowodują unieważnienie pamięci podręcznej, ponowne ułożenie i odświeżenie całego drzewa.
wątki silnika renderującego;
Silnik renderowania jest jednowątkowy. Prawie wszystko, z wyjątkiem operacji sieciowych, odbywa się w ramach jednego wątku. W Firefox i Safari jest to główny wątek przeglądarki. W Chrome jest to główny wątek procesu karty.
Operacje sieciowe mogą być wykonywane przez kilka równoległych wątków. Liczba równoległych połączeń jest ograniczona (zwykle 2–6 połączeń).
pętla zdarzeń,
Główny wątek przeglądarki to pętla zdarzeń. Jest to nieskończona pętla, która utrzymuje proces w ruchu. Czeka na zdarzenia (np. zdarzenia układu i malowania) i je przetwarza. Oto kod Firefoxa dla głównego pętli zdarzeń:
while (!mExiting)
NS_ProcessNextEvent(thread);
Model wizualny CSS2
Obszar roboczy
Zgodnie z specyfikacją CSS2 termin „canvas” oznacza „przestrzeń, w której renderowana jest struktura formatowania”: miejsce, w którym przeglądarka wyświetla zawartość.
Płótno jest nieskończone w przypadku każdego wymiaru przestrzeni, ale przeglądarki wybierają początkową szerokość na podstawie wymiarów obszaru widocznego.
Zgodnie z www.w3.org/TR/CSS2/zindex.html tło jest przezroczyste, jeśli jest zawarte w innym, i ma kolor zdefiniowany przez przeglądarkę, jeśli nie.
Model CSS Box
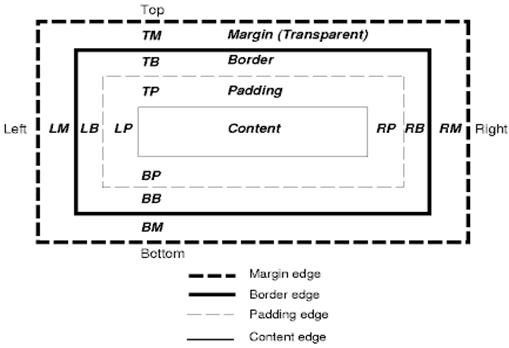
Model pudełka CSS opisuje prostokątne pudełka generowane dla elementów w drzewie dokumentu i układane zgodnie z modelem formatowania wizualnego.
Każde pole ma obszar treści (np. tekst, obraz) oraz opcjonalne obszary obramowania, marginesu i wypełnienia.
Każdy węzeł generuje 0…n takich pudełek.
Wszystkie elementy mają właściwość „display”, która określa typ generowanego pola.
Przykłady:
block: generates a block box.
inline: generates one or more inline boxes.
none: no box is generated.
Domyślnie jest to wartość wbudowana, ale arkusz stylów przeglądarki może ustawiać inne wartości domyślne. Przykład: domyślne wyświetlanie elementu „div” to blok.
Przykład domyślnego arkusza stylów znajdziesz tutaj: www.w3.org/TR/CSS2/sample.html.
Schemat pozycjonowania
Istnieją 3 systemy:
- Normalny: obiekt jest umieszczony zgodnie z miejscem w dokumencie. Oznacza to, że jego miejsce w drzewie renderowania jest takie samo jak w drzewie DOM i jest rozmieszczone zgodnie z rodzajem i wymiarami pudełka.
- Przesuwanie: obiekt jest najpierw rozmieszczany jak w normalnym przepływie, a potem przesuwany w lewo lub w prawo tak daleko, jak to możliwe.
- Absolutna: obiekt jest umieszczany w drzewie renderowania w innym miejscu niż w drzewie DOM.
Schemat pozycjonowania jest ustawiany przez właściwość „position” i atrybut „float”.
- statyczne i względne powodują normalny przepływ
- bezwzględne i stałe powodują pozycjonowanie bezwzględne
W przypadku pozycjonowania stałego nie jest zdefiniowana żadna pozycja i używane jest pozycjonowanie domyślne. W innych schematach autor określa pozycję: góra, dół, lewo, prawo.
Sposób rozmieszczenia pola zależy od:
- Typ skrzynki
- Wymiary pudełka
- Schemat pozycjonowania
- informacje zewnętrzne, takie jak rozmiar obrazu i rozmiar ekranu;
Typy Box
Pole bloku: tworzy blok – ma własny prostokąt w oknie przeglądarki.

Pole wstawione: nie ma własnego bloku, ale znajduje się w bloku zawierającym.
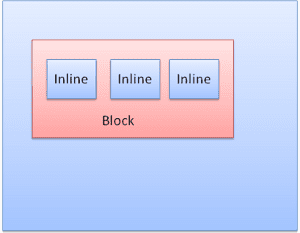
Bloki są sformatowane pionowo jeden po drugim. Wstawione są formatowane poziomo.
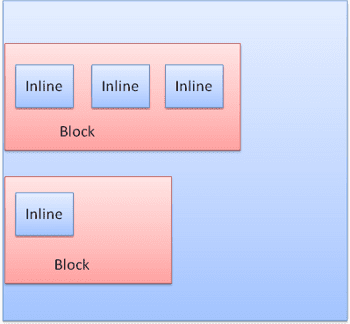
Ramki wstawia się wewnątrz linii lub „ramek linii”. Linie mają co najmniej taką samą wysokość jak najwyższy boks, ale mogą być wyższe, gdy boksy są wyrównane „pod linią bazową”, co oznacza, że dolna część elementu jest wyrównana do punktu innego boksu niż dolna krawędź. Jeśli szerokość kontenera jest niewystarczająca, tekst wstawiany w tekście będzie rozmieszczony na kilku wierszach. Zwykle tak się dzieje w przypadku akapitu.
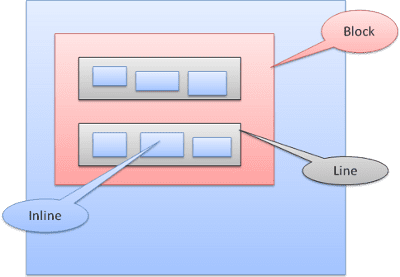
Pozycjonowanie
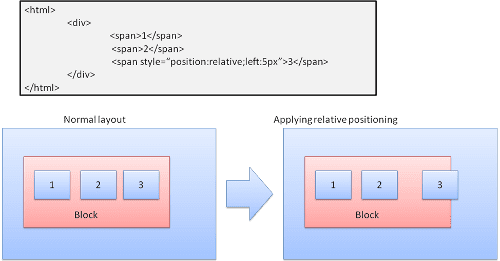
Krewny
Pozycjonowanie względne – pozycjonowanie jak zwykle, a następnie przesunięcie o wymaganą wartość.
Swobodne
Element pływający jest przesunięty w lewo lub w prawo od linii. Ciekawostką jest to, że inne pola płyną wokół niego. Kod HTML:
<p>
<img style="float: right" src="images/image.gif" width="100" height="100">
Lorem ipsum dolor sit amet, consectetuer...
</p>
Wyglądać będzie tak:

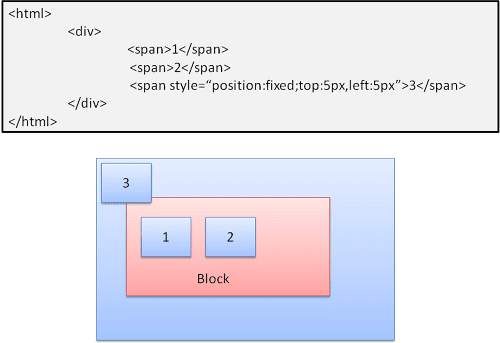
Bezwzględne i stałe
Układ jest definiowany dokładnie niezależnie od normalnego przepływu. Element nie uczestniczy w normalnym przepływie danych. Wymiary są podawane względem kontenera. W przypadku opcji „fixed” kontener jest widocznym obszarem.
Warstwowy sposób przedstawiania informacji
Jest ona określana przez właściwość CSS z-index. Jest to trzeci wymiar pola: jego położenie wzdłuż „osi z”.
Pudełka są podzielone na stosy (nazywane kontekstami nakładania). W każdej grupie elementy z tyłu będą renderowane jako pierwsze, a elementy z przodu – na wierzchu, bliżej użytkownika. W przypadku nakładania się elementów element z przodu będzie zakrywać poprzedni element.
Warstwy są uporządkowane według właściwości z-index. Pola z właściwością „z-index” tworzą lokalny stos. Widok zawiera zewnętrzny stos.
Przykład:
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
Wynik będzie wyglądał tak:

Chociaż czerwony div jest w tagach HTML przed zielonym i w ramach zwykłego procesu zostałby narysowany wcześniej, jego właściwość z-index jest wyższa, więc znajduje się wyżej w steku elementów w polu głównym.
Zasoby
Architektura przeglądarki
- Grosskurth, Alan. Architektura referencyjna przeglądarek internetowych (plik PDF)
- Gupta, Vineet. Jak działają przeglądarki – część 1. Architektura
Analizowanie
- Aho, Sethi, Ullman, Compilers: Principles, Techniques, and Tools (aka the "Dragon book"), Addison-Wesley, 1986
- Rick Jelliffe. The Bold and the Beautiful: 2 nowe wersje robocze HTML 5
Firefox
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers (Szybszy HTML i CSS: wewnętrzne mechanizmy silnika układu dla programistów internetowych).
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers (Google tech talk video) (w języku angielskim)
- L. David Baron, architekt silnika układu Mozilla
- L. David Baron, Mozilla Style System Documentation
- Chris Waterson, Uwagi na temat reflow HTML
- Chris Waterson, Gecko Overview
- Alexander Larsson, The life of an HTML HTTP request
WebKit
- David Hyatt, Implementing CSS(part 1)
- David Hyatt, An Overview of WebCore
- David Hyatt, WebCore Rendering
- David Hyatt, The FOUC Problem
Specyfikacje W3C
Instrukcje dotyczące kompilacji przeglądarek
Tłumaczenia
このページは2回にわたって、日本語に翻訳されています
- How Browsers Work - Behind the Scenes of Modern Web Browsers (ja) (@kosei)
- ブラウザってどうやって動いてるの?(モダンWEBブラウザシーンの裏側 by @ikeike443 and @kiyoto01.
Możesz wyświetlić przetłumaczone treści w języku koreańskim i tureckim, które są hostowane na zewnętrznych serwerach.
Dziękuję wszystkim!