

雖然大型語言模型 (LLM) 中的「L」代表「large」(大型),但實際上情況更為複雜。有些大型語言模型含有數兆個參數,有些則只需少量參數即可有效運作。
請參考幾個實際範例,瞭解不同模型大小的實際影響。
LLM 大小和大小類別
身為網頁開發人員,我們傾向將資源大小視為下載大小。模型的文件大小是指參數數量。舉例來說,Gemma 2B 代表 Gemma 有 20 億個參數。
大型語言模型可能含有數十萬、數百萬、數十億甚至數兆個參數。
大型 LLM 的參數比小型 LLM 多,因此可擷取更複雜的語言關係,並處理細微的提示。也經常使用較大的資料集進行訓練。
您可能會發現,某些模型大小 (例如 20 億或 70 億) 很常見。例如 Gemma 2B、Gemma 7B 或 Mistral 7B。模型大小類別是近似分組。舉例來說,Gemma 2B 有「大約」 20 億個參數,但並非確切的 20 億。
模型大小類別是評估 LLM 效能的實用方法。這就像拳擊中的體重級別一樣:同樣體型類別的模型比較容易比較。兩個 2B 模型應提供相似的效能。
不過,對於特定工作而言,較小的模型可以達到與大型模型相同的效能。

雖然最新的頂尖 LLM (例如 GPT-4 和 Gemini Pro 或 Ultra) 的模型大小不一定會公開,但據信這些模型的參數數量可能高達數十億或數兆個參數。

並非所有型號的名稱都會顯示參數數量。部分型號的後綴會加上版本號碼。舉例來說,Gemini 1.5 Pro 是指 1.5 版模型 (接續 1 版)。
是否為 LLM?
模型太小無法成為 LLM 時,在 AI 和 ML 社群中,大型語言模型的定義可能會有所不同。
有些人認為只有含有數十億個參數的大型模型才是真正的 LLM,而較小的模型 (例如 DistilBERT) 則被視為簡單的 NLP 模型。其他人則將較小但仍強大的模型納入 LLM 定義,例如 DistilBERT。
針對裝置端用途提供較小的 LLM
大型 LLM 需要大量儲存空間和運算資源才能進行推論。需要在配備特定硬體 (例如 TPU) 的專用強大伺服器上執行。
做為網頁開發人員,我們有興趣瞭解模型是否足夠小,可在使用者的裝置上下載及執行。
但這很難回答!目前沒有簡單的方法可以讓您知道「這個模型可以在大多數中階裝置上執行」,原因如下:
- 裝置的記憶體、GPU/CPU 規格等功能各有不同,低階 Android 手機和 NVIDIA® RTX 筆電的差異極大。您可能會取得一些關於使用者裝置的資料點。我們尚未定義用於存取網際網路的基準裝置。
- 模型或其執行的架構可能會經過最佳化,以便在特定硬體上執行。
- 無法透過程式設計方式判斷特定 LLM 是否可下載並在特定裝置上執行。裝置的下載能力取決於 GPU 的 VRAM 容量和其他因素。
不過,我們有一些實證知識:目前,某些具有數百萬至數十億個參數的模型,可以在消費者級裝置的瀏覽器中執行。
例如:
- Gemma 2B 搭配 MediaPipe LLM 推論 API (甚至適用於僅 CPU 裝置)。試試看。
- DistilBERT 搭配 Transformers.js。
這是一個新興領域。您可以預期廣告環境會有所變化:
- 有了 WebAssembly 和 WebGPU 創新技術,WebGPU 支援功能將可在更多程式庫、新程式庫和最佳化中推出,使用者裝置將能更有效率地執行各種大小的 LLM。
- 隨著新興的縮減技巧問世,預期小型且成效極佳的 LLM 將越來越普遍。
小型 LLM 的注意事項
使用較小的 LLM 時,請務必考量效能和下載大小。
成效
任何模型的功能都取決於您的用途!針對用途進行微調的小型 LLM 可能比大型通用 LLM 的效能更好。
不過,在同一個模型系列中,較小的 LLM 功能較少。對於相同的用途,如果使用較小的 LLM,通常需要進行更多即時工程作業。
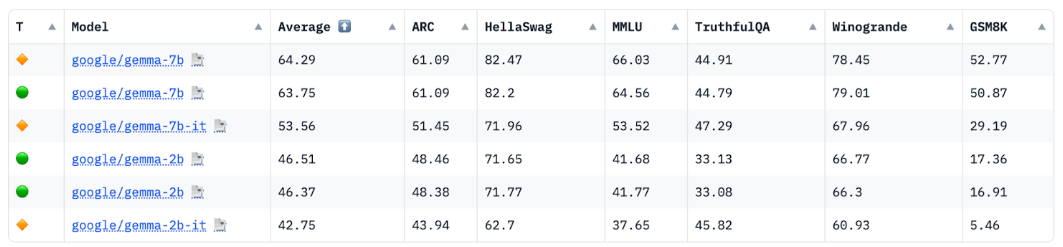
資料來源:HuggingFace Open LLM 排行榜,2024 年 4 月
下載大小
參數越多,下載大小就越大,這也會影響模型是否能合理下載,以便在裝置端使用。
雖然有技巧可根據參數數量計算模型的下載大小,但這項作業可能相當複雜。
截至 2024 年初,模型下載大小很少會記錄在文件中。因此,針對裝置端和瀏覽器內的用途,建議您在 Chrome 開發人員工具的「Network」面板中,或使用其他瀏覽器開發人員工具,以實證方式查看下載大小。

Gemma 會與 MediaPipe LLM Inference API 搭配使用。DistilBERT 會與 Transformers.js 搭配使用。
模型縮減技巧
您可以使用多種方法大幅降低模型的記憶體需求:
- LoRA (低秩調整):微調技巧,其中預先訓練的權重會凍結。進一步瞭解 LoRA。
- 修剪:從模型中移除較不重要的權重,以縮減模型大小。
- 量化:將權重的精確度從浮點數 (例如 32 位元) 降低至較低位元表示法 (例如 8 位元)。
- 知識蒸餾:訓練較小的模型,模仿較大型的預先訓練模型行為。
- 參數共用:為模型的多個部分使用相同權重,減少不重複參數的總數。