

האות L במודלים גדולים של שפה (LLM) מציינת שהם גדולים מאוד, אבל המציאות מורכבת יותר. חלק ממודלים ה-LLM מכילים טריליוני פרמטרים, ואחרים פועלים ביעילות עם הרבה פחות פרמטרים.
ריכזנו כאן כמה דוגמאות מהעולם האמיתי והשלכות מעשיות של גדלים שונים של מודלים.
גדלים וקטגוריות גדלים של מודלים LLM
כמפתחי אתרים, אנחנו נוטים לחשוב על גודל המשאב כגודל ההורדה שלו. במקום זאת, הגודל הרשום של מודל מתייחס למספר הפרמטרים שלו. לדוגמה, Gemma 2B מציין את Gemma עם 2 מיליארד פרמטרים.
למודלים של שפה גדולה יכולים להיות מאות אלפי, מיליוני, מיליארדי או אפילו טריליוני פרמטרים.
למודלים גדולים יותר של שפה (LLM) יש יותר פרמטרים מאשר למודלים קטנים יותר, ולכן הם יכולים לתעד קשרים מורכבים יותר בין שפות ולטפל בהנחיות עם ניואנסים. בנוסף, הם מתאמנים לעיתים קרובות על מערכי נתונים גדולים יותר.
יכול להיות שמתם לב שגדלים מסוימים של מודלים, כמו 2 מיליארד או 7 מיליארד, נפוצים. לדוגמה, Gemma 2B, Gemma 7B או Mistral 7B. הכיתות של גודל המודל הן קיבוצים משוערים. לדוגמה, ל-Gemma 2B יש כ- 2 מיליארד פרמטרים, אבל לא בדיוק.
סיווג המודלים לפי גודל הוא דרך מעשית למדוד את הביצועים של מודלים גדולים של שפה (LLM). אפשר להתייחס לקטגוריות האלה כמו לקטגוריות משקל באגרוף: קל יותר להשוות בין מודלים באותה קטגוריית גודל. שני מודלים מסוג 2B אמורים לספק ביצועים דומים.
עם זאת, מודל קטן יותר יכול לספק את אותם ביצועים כמו מודל גדול יותר במשימות ספציפיות.

לא תמיד מדווחים על גודל המודלים של רוב ה-LLMs המתקדמים ביותר, כמו GPT-4 ו-Gemini Pro או Ultra, אבל ההערכה היא שהם מכילים מאות מיליארדי פרמטרים או טריליוני פרמטרים.

לא בכל השמות של המודלים מצוין מספר הפרמטרים. לחלק מהדגמים מצורף מספר גרסה בתור סיומת. לדוגמה, Gemini 1.5 Pro מתייחס לגרסה 1.5 של המודל (אחרי הגרסה 1).
LLM או לא?
מתי מודל קטן מדי כדי להיחשב כ-LLM? ההגדרה של LLM יכולה להיות די גמישה בקרב קהילת ה-AI וה-ML.
יש אנשים שמתייחסים רק למודלים הגדולים ביותר עם מיליארדי פרמטרים כמודלים אמיתיים של שפה גדולה (LLM), בעוד שמודלים קטנים יותר, כמו DistilBERT, נחשבים למודלים פשוטים של עיבוד שפה טבעי (NLP). הגדרות אחרות של LLM כוללות מודלים קטנים יותר, אבל עדיין חזקים, כמו DistilBERT.
מודלים קטנים יותר של LLM לתרחישי שימוש במכשיר
כדי לבצע את ההסקה, LLM גדולים יותר דורשים הרבה נפח אחסון וכוח מחשוב. הן צריכות לפעול בשרתים חזקים ייעודיים עם חומרה ספציפית (כמו TPU).
כמפתחי אינטרנט, אנחנו מתעניינים בכך שהמודל יהיה קטן מספיק כדי שניתן יהיה להוריד אותו ולהריץ אותו במכשיר של המשתמש.
אבל זו שאלה קשה לענות עליה! נכון להיום, אין דרך קלה לדעת "הדגם הזה יכול לפעול ברוב המכשירים ברמת הביניים", מכמה סיבות:
- יכולות המכשירים משתנות מאוד בהתאם לקיבולת הזיכרון, למפרטי ה-GPU/CPU ועוד. יש הבדל עצום בין טלפון Android ברמה נמוכה לבין מחשב נייד עם NVIDIA® RTX. יכול להיות שיש לכם כמה נקודות נתונים לגבי המכשירים של המשתמשים שלכם. עדיין אין לנו הגדרה למכשיר בסיס שמשמש לגישה לאינטרנט.
- יכול להיות שהמודל או המסגרת שבה הוא פועל יעברו אופטימיזציה כך שיתאימו לפעולה בחומרה מסוימת.
- אין דרך פרוגרמטית לקבוע אם אפשר להוריד LLM ספציפי ולהריץ אותו במכשיר ספציפי. יכולת ההורדה של המכשיר תלויה, בין היתר, בנפח ה-VRAM של המעבד הגרפי.
עם זאת, יש לנו ידע אמפירי מסוים: היום, חלק מהמודלים עם כמה מיליוני עד כמה מיליארדי פרמטרים יכולים לפעול בדפדפן, במכשירים ברמת הצרכן.
לדוגמה:
- Gemma 2B עם MediaPipe LLM Inference API (מתאים גם למכשירים עם מעבד בלבד). כדאי לנסות.
- DistilBERT באמצעות Transformers.js.
זהו תחום חדש יחסית. אפשר לצפות שהסביבה העסקית תשתנה:
- בעזרת החידושים של WebAssembly ו-WebGPU, תמיכת WebGPU תגיע ליותר ספריות, ספריות חדשות ואופטימיזציות, כך שמכשירי המשתמשים יוכלו להריץ ביעילות רבה יותר מודלים מסוג LLM בגדלים שונים.
- מודלים גדולים של שפה (LLMs) קטנים יותר עם ביצועים גבוהים צפויים להיות נפוצים יותר ויותר, באמצעות שיטות חדשות לצמצום.
שיקולים לגבי מודלים קטנים יותר של שפה
כשעובדים עם LLMs קטנים יותר, תמיד צריך להביא בחשבון את הביצועים ואת גודל ההורדה.
ביצועים
היכולות של כל מודל תלויות מאוד בתרחיש לדוגמה שלכם. יכול להיות שמודל LLM קטן יותר שהותאם לתרחיש לדוגמה שלכם יניב ביצועים טובים יותר ממודל LLM גדול יותר וגנרלי.
עם זאת, באותה משפחת מודלים, מודלים קטנים יותר של LLM הם פחות מתקדמים ממודלים גדולים יותר. באותו תרחיש לדוגמה, בדרך כלל תצטרכו לבצע יותר עבודת תכנון כשמשתמשים ב-LLM קטן יותר.
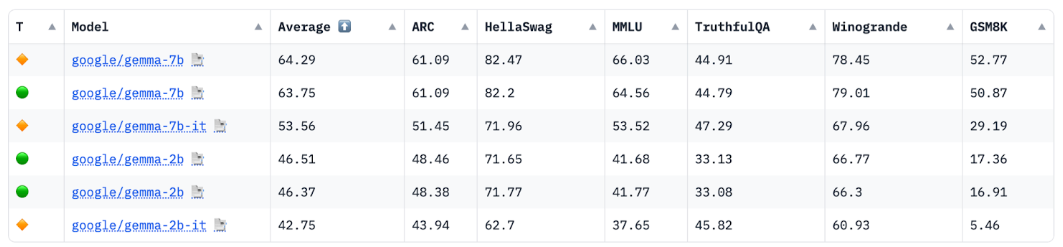
מקור: HuggingFace Open LLM Leaderboard, אפריל 2024
גודל הורדה
ככל שיש יותר פרמטרים, כך גודל ההורדה גדול יותר. הדבר משפיע גם על האפשרות להוריד מודל באופן סביר, גם אם הוא נחשב לקטן, לתרחישי שימוש במכשיר.
יש שיטות לחישוב גודל ההורדה של מודל על סמך מספר הפרמטרים, אבל החישוב הזה יכול להיות מורכב.
נכון לתחילת 2024, גודל ההורדה של מודלים מתועד לעיתים רחוקות. לכן, בתרחישי לדוגמה שבהם הנתונים נמצאים במכשיר או בדפדפן, מומלץ לבדוק את גודל ההורדה באופן אמפירי בחלונית Network (רשת) של Chrome DevTools או בכלים אחרים למפתחים בדפדפן.

Gemma משמש עם MediaPipe LLM Inference API. משתמשים ב-DistilBERT עם Transformers.js.
שיטות לצמצום המודל
יש כמה שיטות להפחית באופן משמעותי את דרישות הזיכרון של מודל:
- LoRA (התאמה ברמה נמוכה): טכניקה של כוונון עדין שבה המשקולות שהותאמו מראש קפואים. מידע נוסף על LoRA
- גיזום: הסרת משקלים פחות חשובים מהמודל כדי לצמצם את הגודל שלו.
- קווינטציה: הפחתת הדיוק של המשקלים ממספרים בספרות עשרוניות (למשל, 32 ביט) לייצוגים בפחות ביט (למשל, 8 ביט).
- זיקוק ידע: אימון מודל קטן יותר כדי לחקות את ההתנהגות של מודל גדול יותר שעבר אימון מראש.
- שיתוף פרמטרים: שימוש באותם משקלים במספר חלקים של המודל, כדי לצמצם את המספר הכולל של הפרמטרים הייחודיים.