
Bastidores dos navegadores modernos da Web


Prefácio
Este guia completo sobre as operações internas do WebKit e do Gecko é o resultado de muitas pesquisas feitas pela desenvolvedora israelense Tali Garsiel. Ao longo de alguns anos, ela analisou todos os dados publicados sobre o funcionamento interno do navegador e passou muito tempo lendo o código-fonte do navegador da Web. Ela escreveu:
Como desenvolvedor da Web, aprender os aspectos internos das operações do navegador ajuda você a tomar decisões melhores e conhecer as justificativas por trás das práticas recomendadas de desenvolvimento. Embora este seja um documento bastante longo, recomendamos que você dedique algum tempo para analisá-lo. Você vai gostar do resultado.
Paul Irish, relações com desenvolvedores do Chrome
Introdução
Os navegadores da Web são os softwares mais usados. Neste artigo introdutório, explico como
elas funcionam nos bastidores. Vamos ver o que acontece quando você digita google.com
na barra de endereço até que a página do Google apareça na tela do navegador.
Navegadores que vamos abordar
Atualmente, os cinco principais navegadores usados em computadores são Chrome, Internet Explorer, Firefox, Safari e Opera. Em dispositivos móveis, os principais navegadores são o Android Browser, o iPhone, o Opera Mini e o Opera Mobile, o UC Browser, os navegadores Nokia S40/S60 e o Chrome, todos baseados no WebKit, exceto os navegadores Opera. Vou dar exemplos dos navegadores de código aberto Firefox e Chrome e do Safari (que é parcialmente de código aberto). De acordo com as estatísticas do StatCounter (em junho de 2013), o Chrome, o Firefox e o Safari representam cerca de 71% do uso global de navegadores para computador. Em dispositivos móveis, o navegador Android, o iPhone e o Chrome representam cerca de 54% do uso.
A principal funcionalidade do navegador
A principal função de um navegador é apresentar o recurso da Web escolhido, solicitando-o do servidor e exibindo-o na janela do navegador. O recurso geralmente é um documento HTML, mas também pode ser um PDF, uma imagem ou outro tipo de conteúdo. O local do recurso é especificado pelo usuário usando um URI (Uniform Resource Identifier).
A maneira como o navegador interpreta e exibe arquivos HTML é especificada nas especificações de HTML e CSS. Essas especificações são mantidas pelo W3C (World Wide Web Consortium), a organização de padrões da Web. Por anos, os navegadores se adequaram a apenas uma parte das especificações e desenvolveram as próprias extensões. Isso causou sérios problemas de compatibilidade para os autores da Web. Atualmente, a maioria dos navegadores está mais ou menos em conformidade com as especificações.
As interfaces do usuário do navegador têm muitas coisas em comum. Entre os elementos comuns da interface do usuário, estão:
- Barra de endereço para inserir um URI
- Botões "Voltar" e "Avançar"
- Opções de favoritos
- Botões de atualização e interrupção para atualizar ou interromper o carregamento dos documentos atuais
- Botão "Página inicial" que leva você à página inicial
Curiosamente, a interface do usuário do navegador não é especificada em nenhuma especificação formal, ela vem de boas práticas moldadas ao longo de anos de experiência e de navegadores que imitam uns aos outros. A especificação HTML5 não define elementos de interface que um navegador precisa ter, mas lista alguns elementos comuns. Entre elas estão a barra de endereço, a barra de status e a barra de ferramentas. Há, é claro, recursos exclusivos de um navegador específico, como o gerenciador de downloads do Firefox.
Infraestrutura de alto nível
Os principais componentes do navegador são:
- A interface do usuário: inclui a barra de endereço, o botão "Voltar/Avançar", o menu de favoritos etc. Todas as partes da tela do navegador, exceto a janela em que a página solicitada aparece.
- O mecanismo do navegador: organiza ações entre a interface e o mecanismo de renderização.
- O mecanismo de renderização: responsável por mostrar o conteúdo solicitado. Por exemplo, se o conteúdo solicitado for HTML, o mecanismo de renderização vai analisar o HTML e o CSS e mostrar o conteúdo analisado na tela.
- Rede: para chamadas de rede, como solicitações HTTP, use implementações diferentes para plataformas diferentes em uma interface independente de plataforma.
- Back-end da interface: usado para desenhar widgets básicos, como caixas combinadas e janelas. Esse back-end expõe uma interface genérica que não é específica da plataforma. Abaixo dele, são usados métodos de interface do usuário do sistema operacional.
- Intérprete de JavaScript. Usado para analisar e executar códigos JavaScript.
- Armazenamento de dados. Essa é uma camada de persistência. O navegador pode precisar salvar todos os tipos de dados localmente, como cookies. Os navegadores também oferecem suporte a mecanismos de armazenamento, como localStorage, IndexedDB, WebSQL e FileSystem.
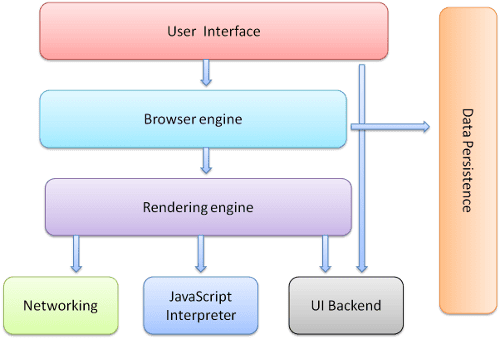
É importante observar que navegadores como o Chrome executam várias instâncias do mecanismo de renderização: uma para cada guia. Cada guia é executada em um processo separado.
Mecanismos de renderização
A responsabilidade do mecanismo de renderização é… bem… renderizar, ou seja, mostrar o conteúdo solicitado na tela do navegador.
Por padrão, o mecanismo de renderização pode exibir documentos e imagens HTML e XML. Ele pode mostrar outros tipos de dados usando plug-ins ou extensões. Por exemplo, documentos PDF com um plug-in de visualizador de PDF. No entanto, neste capítulo, vamos nos concentrar no caso de uso principal: mostrar HTML e imagens formatadas usando CSS.
Navegadores diferentes usam mecanismos de renderização diferentes: o Internet Explorer usa o Trident, o Firefox usa o Gecko e o Safari usa o WebKit. O Chrome e o Opera (a partir da versão 15) usam o Blink, uma bifurcação do WebKit.
O WebKit é um mecanismo de renderização de código aberto que começou como um mecanismo para a plataforma Linux e foi modificado pela Apple para oferecer suporte a Mac e Windows.
O fluxo principal
O mecanismo de renderização vai começar a receber o conteúdo do documento solicitado da camada de rede. Isso geralmente é feito em blocos de 8 kB.
Depois disso, este é o fluxo básico do mecanismo de renderização:

O mecanismo de renderização vai começar a analisar o documento HTML e converter elementos em nós DOM em uma árvore chamada "árvore de conteúdo". O mecanismo vai analisar os dados de estilo, tanto em arquivos CSS externos quanto em elementos de estilo. As informações de estilo e as instruções visuais no HTML serão usadas para criar outra árvore: a árvore de renderização.
A árvore de renderização contém retângulos com atributos visuais, como cor e dimensões. Os retângulos estão na ordem certa para serem exibidos na tela.
Após a construção da árvore de renderização, ela passa por um processo de layout. Isso significa dar a cada nó as coordenadas exatas em que ele precisa aparecer na tela. A próxima etapa é a pintura, em que a árvore de renderização é percorrida e cada nó é pintado usando a camada de back-end da interface.
É importante entender que esse é um processo gradual. Para melhorar a experiência do usuário, o mecanismo de renderização tenta mostrar o conteúdo na tela o mais rápido possível. Ele não vai esperar até que todo o HTML seja analisado antes de começar a criar e posicionar a árvore de renderização. Partes do conteúdo serão analisadas e exibidas, enquanto o processo continua com o restante do conteúdo que continua vindo da rede.
Exemplos de fluxo principal
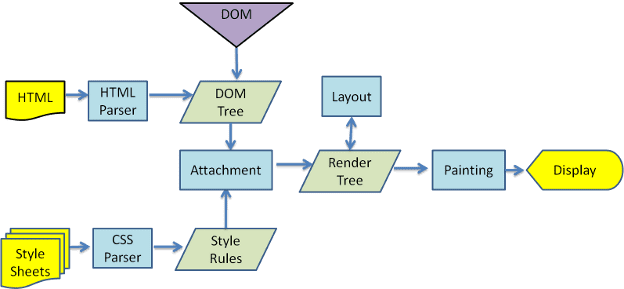
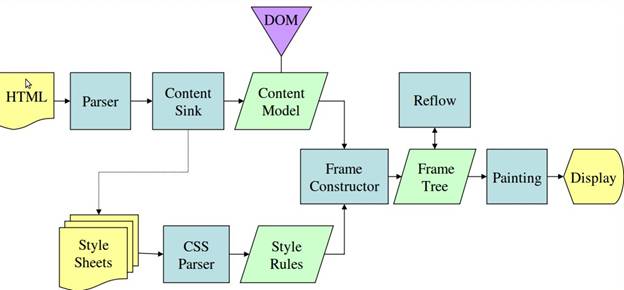
Nas figuras 3 e 4, você pode ver que, embora o WebKit e o Gecko usem terminologias um pouco diferentes, o fluxo é basicamente o mesmo.
O Gecko chama a árvore de elementos formatados visualmente de "árvore de frames". Cada elemento é um frame. O WebKit usa o termo "árvore de renderização", que consiste em "objetos de renderização". O WebKit usa o termo "layout" para a colocação de elementos, enquanto o Gecko o chama de "Reflow". "Attachment" é o termo do WebKit para conectar nós DOM e informações visuais para criar a árvore de renderização. Uma diferença menor não semântica é que o Gecko tem uma camada extra entre o HTML e a árvore DOM. Ele é chamado de "content sink" e é uma fábrica para criar elementos DOM. Vamos falar sobre cada parte do fluxo:
Análise: geral
Como a análise é um processo muito importante no mecanismo de renderização, vamos nos aprofundar um pouco mais. Vamos começar com uma pequena introdução sobre o parsing.
Analisar um documento significa traduzi-lo para uma estrutura que o código possa usar. O resultado da análise geralmente é uma árvore de nós que representa a estrutura do documento. Isso é chamado de árvore de análise ou árvore de sintaxe.
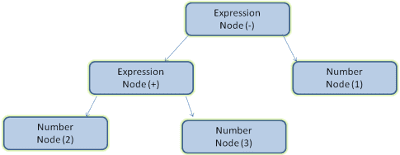
Por exemplo, analisar a expressão 2 + 3 - 1 pode retornar esta árvore:
Gramática
A análise é baseada nas regras de sintaxe que o documento obedece: o idioma ou formato em que foi escrito. Todos os formatos que você pode analisar precisam ter uma gramática determinística que consiste em regras de vocabulário e sintaxe. Ela é chamada de gramática livre de contexto. As línguas humanas não são desse tipo e, portanto, não podem ser analisadas com técnicas de análise convencionais.
Parser: combinação de analisador
A análise pode ser separada em dois subprocessos: análise lexical e análise de sintaxe.
A análise lexical é o processo de dividir a entrada em tokens. Os tokens são o vocabulário do idioma: a coleção de elementos básicos válidos. Em linguagem humana, ele consiste em todas as palavras que aparecem no dicionário desse idioma.
A análise sintática é a aplicação das regras de sintaxe da linguagem.
Os analisadores geralmente dividem o trabalho entre dois componentes: o lexer (às vezes chamado de tokenizer), que é responsável por dividir a entrada em tokens válidos, e o parser, que é responsável por construir a árvore de análise analisando a estrutura do documento de acordo com as regras de sintaxe do idioma.
O analisador sabe como remover caracteres irrelevantes, como espaços em branco e quebras de linha.
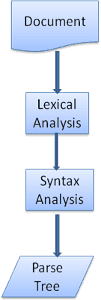
O processo de análise é iterativo. O analisador geralmente solicita um novo token ao analisador lexical e tenta fazer a correspondência com uma das regras de sintaxe. Se uma regra for atendida, um nó correspondente ao token será adicionado à árvore de análise, e o analisador vai solicitar outro token.
Se nenhuma regra corresponder, o analisador vai armazenar o token internamente e continuar solicitando tokens até encontrar uma regra que corresponda a todos os tokens armazenados internamente. Se nenhuma regra for encontrada, o analisador vai gerar uma exceção. Isso significa que o documento não era válido e continha erros de sintaxe.
Tradução
Em muitos casos, a árvore de análise não é o produto final. A análise é frequentemente usada na tradução: transformar o documento de entrada em outro formato. Um exemplo é a compilação. O compilador que compila o código-fonte em código de máquina primeiro o analisa em uma árvore de análise e, em seguida, traduz a árvore em um documento de código de máquina.
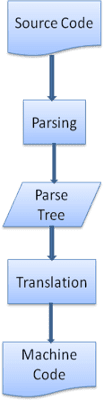
Exemplo de análise
Na Figura 5, criamos uma árvore de análise a partir de uma expressão matemática. Vamos tentar definir uma linguagem matemática simples e conferir o processo de análise.
Sintaxe:
- Os elementos básicos da sintaxe da linguagem são expressões, termos e operações.
- Nossa linguagem pode incluir qualquer número de expressões.
- Uma expressão é definida como um "termo" seguido por uma "operação" seguida por outro termo
- Uma operação é um token de mais ou de menos
- Um termo é um token de número inteiro ou uma expressão
Vamos analisar a entrada 2 + 3 - 1.
A primeira substring que corresponde a uma regra é 2: de acordo com a regra 5, ela é um termo.
A segunda correspondência é 2 + 3: ela corresponde à terceira regra: um termo seguido de uma operação seguido de outro termo.
A próxima correspondência só vai acontecer no final da entrada.
2 + 3 - 1 é uma expressão porque já sabemos que 2 + 3 é um termo. Portanto, temos um termo seguido por uma operação e por outro termo.
2 + + não corresponde a nenhuma regra e, portanto, é uma entrada inválida.
Definições formais de vocabulário e sintaxe
O vocabulário geralmente é expresso por expressões regulares.
Por exemplo, nosso idioma será definido como:
INTEGER: 0|[1-9][0-9]*
PLUS: +
MINUS: -
Como você pode ver, os números inteiros são definidos por uma expressão regular.
A sintaxe geralmente é definida em um formato chamado BNF. Nosso idioma será definido como:
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
Dissemos que uma linguagem pode ser analisada por analisadores regulares se a gramática dela for livre de contexto. Uma definição intuitiva de uma gramática livre de contexto é uma gramática que pode ser totalmente expressa em BNF. Para uma definição formal, consulte o artigo da Wikipédia sobre gramática livre de contexto.
Tipos de analisadores
Há dois tipos de analisadores: em cascata e ascendente. Uma explicação intuitiva é que os analisadores de cima para baixo examinam a estrutura de alto nível da sintaxe e tentam encontrar uma correspondência de regra. Os analisadores bottom-up começam com a entrada e a transformam gradualmente nas regras de sintaxe, começando pelas regras de nível baixo até as de nível alto.
Vamos conferir como os dois tipos de analisadores vão analisar nosso exemplo.
O analisador de cima para baixo vai começar pela regra de nível mais alto: ele vai identificar 2 + 3 como uma expressão. Em seguida, ele vai identificar 2 + 3 - 1 como uma expressão. O processo de identificação da expressão evolui, correspondendo às outras regras, mas o ponto de partida é a regra de nível mais alto.
O analisador bottom up vai verificar a entrada até que uma regra seja encontrada. Em seguida, ele substitui a entrada correspondente pela regra. Isso vai continuar até o fim da entrada. A expressão parcialmente correspondente é colocada na pilha do analisador.
Esse tipo de analisador bottom-up é chamado de analisador de mudança-redução, porque a entrada é deslocada para a direita (imagine um ponteiro apontando primeiro para o início da entrada e se movendo para a direita) e é gradualmente reduzido a regras de sintaxe.
Como gerar analisadores automaticamente
Há ferramentas que podem gerar um analisador. Você alimenta a gramática do seu idioma (vocabulário e regras de sintaxe) e ele gera um analisador funcional. Criar um analisador requer um entendimento profundo de análise, e não é fácil criar um analisador otimizado manualmente. Por isso, os geradores de analisadores podem ser muito úteis.
O WebKit usa dois geradores de analisadores bem conhecidos: Flex para criar um analisador léxico e Bison para criar um analisador (talvez você encontre esses nomes como Lex e Yacc). A entrada flex é um arquivo com definições de expressão regular dos tokens. A entrada do Bison são as regras de sintaxe do idioma no formato BNF.
Parser de HTML
A função do analisador HTML é analisar a marcação HTML em uma árvore de análise.
Gramática HTML
O vocabulário e a sintaxe do HTML são definidos em especificações criadas pela organização W3C.
Como vimos na introdução à análise, a sintaxe da gramática pode ser definida formalmente usando formatos como BNF.
Infelizmente, todos os tópicos de analisador convencionais não se aplicam ao HTML. Não os mencionei só por diversão, eles serão usados na análise de CSS e JavaScript. O HTML não pode ser definido facilmente por uma gramática livre de contexto necessária para os analisadores.
Há um formato formal para definir HTML, o DTD (definição de tipo de documento), mas ele não é uma gramática livre de contexto.
Isso parece estranho à primeira vista, porque o HTML é muito parecido com o XML. Há muitos analisadores XML disponíveis. Há uma variação XML do HTML, o XHTML. Qual é a grande diferença?
A diferença é que a abordagem HTML é mais "indulgente": ela permite omitir determinadas tags (que são adicionadas implicitamente) ou, às vezes, omitir tags de início ou fim e assim por diante. No geral, é uma sintaxe "flexível", em vez da sintaxe rígida e exigente do XML.
Esse detalhe aparentemente pequeno faz toda a diferença. Por um lado, essa é a principal razão pela qual o HTML é tão popular: ele perdoa seus erros e facilita a vida do autor da Web. Por outro lado, isso dificulta a escrita de uma gramática formal. Em resumo, o HTML não pode ser analisado facilmente por analisadores convencionais, já que a gramática não é livre de contexto. O HTML não pode ser analisado por analisadores XML.
DTD do HTML
A definição de HTML está em um formato DTD. Esse formato é usado para definir idiomas da família SGML. O formato contém definições de todos os elementos permitidos, atributos e hierarquia. Como vimos anteriormente, o DTD do HTML não forma uma gramática livre de contexto.
Há algumas variações do DTD. O modo estrito está em conformidade apenas com as especificações, mas outros modos contêm suporte para marcação usada por navegadores no passado. O objetivo é a compatibilidade com versões anteriores do conteúdo. O DTD estrito atual está aqui: www.w3.org/TR/html4/strict.dtd
DOM
A árvore de saída (a "árvore de análise") é uma árvore de elementos DOM e nós de atributos. DOM é a abreviação de "modelo de objeto de documento". É a apresentação do objeto do documento HTML e a interface de elementos HTML para o mundo externo, como JavaScript.
A raiz da árvore é o objeto Document.
O DOM tem uma relação quase um para um com a marcação. Exemplo:
<html>
<body>
<p>
Hello World
</p>
<div> <img src="example.png"/></div>
</body>
</html>
Essa marcação seria traduzida para a seguinte árvore DOM:
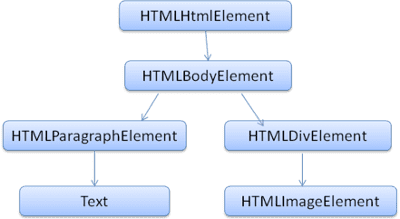
Assim como o HTML, o DOM é especificado pela organização W3C. Consulte www.w3.org/DOM/DOMTR. É uma especificação genérica para manipular documentos. Um módulo específico descreve elementos específicos do HTML. As definições de HTML podem ser encontradas aqui: www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html.
Quando digo que a árvore contém nós DOM, quero dizer que ela é construída com elementos que implementam uma das interfaces do DOM. Os navegadores usam implementações concretas que têm outros atributos usados internamente.
O algoritmo de análise
Como vimos nas seções anteriores, o HTML não pode ser analisado usando os analisadores regulares de cima para baixo ou de baixo para cima.
Os motivos são:
- A natureza tolerante do idioma.
- O fato de os navegadores terem tolerância a erros tradicionais para oferecer suporte a casos conhecidos de HTML inválido.
- O processo de análise é reentrante. Em outros idiomas, a origem não muda durante a análise, mas no HTML, o código dinâmico (como elementos de script que contêm chamadas
document.write()) pode adicionar tokens extras, de modo que o processo de análise modifica a entrada.
Como não é possível usar as técnicas de análise regulares, os navegadores criam analisadores personalizados para analisar HTML.
O algoritmo de análise é descrito em detalhes pela especificação HTML5. O algoritmo consiste em duas etapas: tokenização e construção de árvore.
A tokenização é a análise lexical, que analisa a entrada em tokens. Entre os tokens HTML estão tags de abertura, tags de fechamento, nomes de atributos e valores de atributos.
O tokenizer reconhece o token, o transmite ao construtor da árvore e consome o próximo caractere para reconhecer o próximo token, e assim por diante até o fim da entrada.
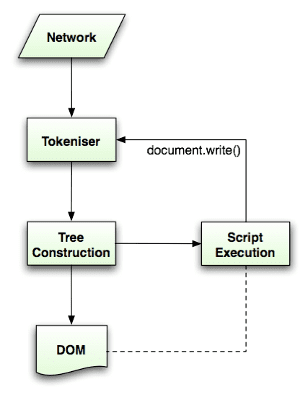
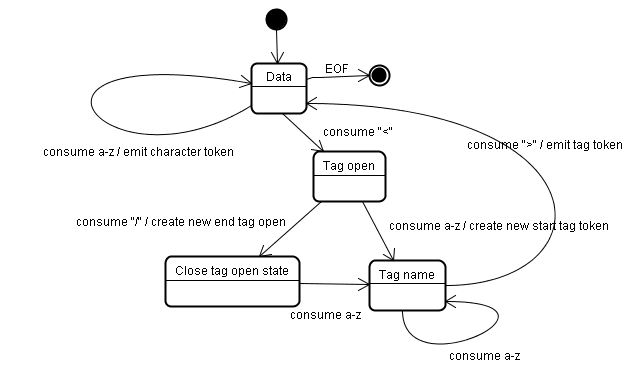
O algoritmo de tokenização
A saída do algoritmo é um token HTML. O algoritmo é expresso como uma máquina de estados. Cada estado consome um ou mais caracteres do fluxo de entrada e atualiza o próximo estado de acordo com esses caracteres. A decisão é influenciada pelo estado atual de tokenização e pelo estado de construção da árvore. Isso significa que o mesmo caractere consumido vai gerar resultados diferentes para o próximo estado correto, dependendo do estado atual. O algoritmo é muito complexo para ser descrito completamente. Então, vamos conferir um exemplo simples que vai nos ajudar a entender o princípio.
Exemplo básico: tokenização do seguinte HTML:
<html>
<body>
Hello world
</body>
</html>
O estado inicial é o "estado de dados".
Quando o caractere < é encontrado, o estado muda para "Tag open state".
O consumo de um caractere a-z faz com que um "token de início de tag" seja criado, e o estado muda para "Estado do nome da tag".
Vamos permanecer nesse estado até que o caractere > seja consumido. Cada caractere é anexado ao nome do novo token. No nosso caso, o token criado é um html.
Quando a tag > é alcançada, o token atual é emitido e o estado volta para "Estado de dados".
A tag <body> vai ser tratada pelas mesmas etapas.
Até agora, as tags html e body foram emitidas. Voltamos ao "Estado dos dados".
O consumo do caractere H de Hello world vai causar a criação e a emissão de um token de caractere, o que vai continuar até que o < de </body> seja alcançado. Vamos emitir um token de caractere para cada caractere de Hello world.
Agora estamos de volta ao "Estado de abertura da tag".
O consumo da próxima entrada / vai causar a criação de um end tag token e uma mudança para o "Estado do nome da tag". Novamente, permanecemos nesse estado até chegarmos a >.Em seguida, o novo token da tag será emitido e voltaremos para o "Estado dos dados".
A entrada </html> será tratada como o caso anterior.
Algoritmo de construção de árvores
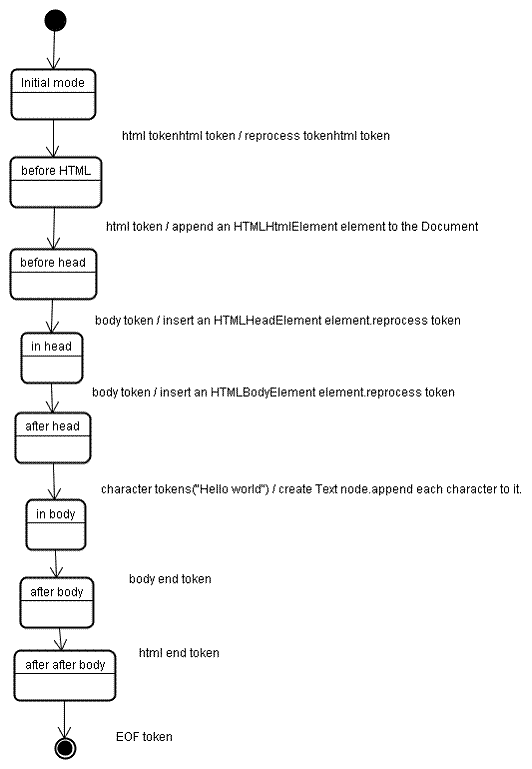
Quando o analisador é criado, o objeto Document também é criado. Durante a construção da árvore, a árvore DOM com o documento na raiz será modificada e elementos serão adicionados a ela. Cada nó emitido pelo tokenizer será processado pelo construtor da árvore. Para cada token, a especificação define qual elemento DOM é relevante para ele e será criado. O elemento é adicionado à árvore DOM e também à pilha de elementos abertos. Essa pilha é usada para corrigir incompatibilidades de aninhamento e tags não fechadas. O algoritmo também é descrito como uma máquina de estados. Os estados são chamados de "modos de inserção".
Vamos conferir o processo de construção da árvore para o exemplo de entrada:
<html>
<body>
Hello world
</body>
</html>
A entrada para o estágio de construção da árvore é uma sequência de tokens do estágio de tokenização. O primeiro modo é o "modo inicial". O recebimento do token "html" vai causar uma mudança para o modo "antes do html" e um novo processamento do token nesse modo. Isso vai causar a criação do elemento HTMLHtmlElement, que será anexado ao objeto de documento raiz.
O estado será alterado para "before head". O token "body" é recebido. Um HTMLHeadElement será criado implicitamente, embora não tenhamos um token "head", e ele será adicionado à árvore.
Agora vamos para o modo "na cabeça" e depois para o "depois da cabeça". O token do corpo é reprocessado, um HTMLBodyElement é criado e inserido, e o modo é transferido para "in body".
Os tokens de caracteres da string "Hello world" agora são recebidos. O primeiro vai causar a criação e inserção de um nó "Texto", e os outros caracteres serão anexados a esse nó.
O recebimento do token de fim do corpo vai causar uma transferência para o modo "after body". Agora vamos receber a tag de fim do HTML, que vai nos levar ao modo "after after body". A recepção do token de fim de arquivo encerra a análise.
Ações quando a análise for concluída
Nesse estágio, o navegador marca o documento como interativo e começa a analisar scripts que estão no modo "adiado": aqueles que precisam ser executados depois que o documento é analisado. O estado do documento será definido como "completo", e um evento de "carregamento" será acionado.
Confira os algoritmos completos para tokenização e construção de árvores na especificação HTML5.
Tolerância a erros dos navegadores
Você nunca recebe um erro de "Sintaxe inválida" em uma página HTML. Os navegadores corrigem qualquer conteúdo inválido e continuam.
Veja este HTML como exemplo:
<html>
<mytag>
</mytag>
<div>
<p>
</div>
Really lousy HTML
</p>
</html>
Eu devo ter violado cerca de um milhão de regras ("mytag" não é uma tag padrão, aninhamento errado dos elementos "p" e "div" e muito mais), mas o navegador ainda mostra corretamente e não reclama. Portanto, grande parte do código do analisador corrige os erros do autor do HTML.
A manipulação de erros é bastante consistente nos navegadores, mas, surpreendentemente, não faz parte das especificações do HTML. Assim como os botões de favoritos e voltar/avançar, isso é algo que foi desenvolvido nos navegadores ao longo dos anos. Há construções HTML inválidas conhecidas repetidas em muitos sites, e os navegadores tentam corrigi-las de forma compatível com outros navegadores.
A especificação HTML5 define alguns desses requisitos. O WebKit resume isso bem no comentário no início da classe de analisador de HTML.
O analisador analisa a entrada tokenizada no documento, criando a árvore de documentos. Se o documento estiver bem formatado, a análise será simples.
Infelizmente, precisamos processar muitos documentos HTML que não estão bem formados. Portanto, o analisador precisa ser tolerante a erros.
Precisamos cuidar de pelo menos as seguintes condições de erro:
- O elemento adicionado é explicitamente proibido dentro de alguma tag externa. Nesse caso, devemos fechar todas as tags até a que proíbe o elemento e adicioná-lo depois.
- Não é permitido adicionar o elemento diretamente. Pode ser que a pessoa que escreveu o documento tenha esquecido de colocar uma tag ou que a tag seja opcional. Isso pode acontecer com as seguintes tags: HTML HEAD BODY TBODY TR TD LI (esqueci alguma?).
- Queremos adicionar um elemento de bloco dentro de um elemento inline. Feche todos os elementos inline até o próximo elemento de bloco de nível superior.
- Se isso não ajudar, feche os elementos até que seja possível adicionar o elemento ou ignore a tag.
Confira alguns exemplos de tolerância a erros do WebKit:
</br> em vez de <br>
Alguns sites usam </br> em vez de <br>. Para ser compatível com o IE e o Firefox, o WebKit trata isso como <br>.
O código:
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
O processamento de erros é interno: ele não é apresentado ao usuário.
Uma tabela perdida
Uma tabela perdida é uma tabela dentro de outra, mas não dentro de uma célula de tabela.
Exemplo:
<table>
<table>
<tr><td>inner table</td></tr>
</table>
<tr><td>outer table</td></tr>
</table>
O WebKit vai mudar a hierarquia para duas tabelas irmãs:
<table>
<tr><td>outer table</td></tr>
</table>
<table>
<tr><td>inner table</td></tr>
</table>
O código:
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
O WebKit usa uma pilha para o conteúdo do elemento atual: ele remove a tabela interna da pilha de tabelas externa. As tabelas vão ser irmãs.
Elementos de formulário aninhados
Se o usuário colocar um formulário dentro de outro, o segundo formulário será ignorado.
O código:
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
Uma hierarquia de tags muito profunda
O comentário fala por si só.
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
Tags de fim de corpo ou HTML deslocadas
Novamente, o comentário fala por si só.
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
Portanto, autores da Web, cuidado: a menos que você queira aparecer como um exemplo em um snippet de código de tolerância a erros do WebKit, escreva HTML bem formado.
Análise de CSS
Lembra dos conceitos de análise na introdução? Ao contrário do HTML, o CSS é uma gramática sem contexto e pode ser analisado usando os tipos de analisadores descritos na introdução. Na verdade, a especificação do CSS define a gramática lexical e de sintaxe do CSS.
Confira alguns exemplos:
A gramática lexical (vocabulário) é definida por expressões regulares para cada token:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
"ident" é abreviação de identificador, como um nome de classe. "name" é um ID de elemento (referenciado por "#")
A gramática de sintaxe é descrita em BNF.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
Explicação:
Uma regra tem esta estrutura:
div.error, a.error {
color:red;
font-weight:bold;
}
div.error e a.error são seletores. A parte dentro das chaves contém as regras aplicadas por esse conjunto.
Essa estrutura é definida formalmente nesta definição:
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
Isso significa que uma regra é um seletor ou, opcionalmente, um número de seletores separados por vírgula e espaços (S significa espaço em branco). Uma regra contém chaves e, dentro delas, uma declaração ou, opcionalmente, um número de declarações separadas por ponto e vírgula. "declaration" e "selector" serão definidos nas seguintes definições de BNF.
Analisador de CSS do WebKit
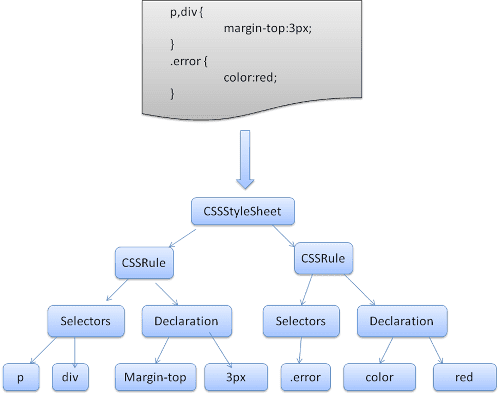
O WebKit usa geradores de analisadores Flex e Bison para criar analisadores automaticamente nos arquivos de gramática CSS. Como você se lembra da introdução ao analisador, o Bison cria um analisador de redução de deslocamento bottom-up. O Firefox usa um analisador de cima para baixo escrito manualmente. Em ambos os casos, cada arquivo CSS é analisado em um objeto StyleSheet. Cada objeto contém regras CSS. Os objetos de regra do CSS contêm objetos de seletor e declaração e outros objetos correspondentes à gramática do CSS.
Ordem de processamento de scripts e folhas de estilo
Scripts
O modelo da Web é síncrono. Os autores esperam que os scripts sejam analisados e executados imediatamente quando o analisador chegar a uma tag <script>.
A análise do documento é interrompida até que o script seja executado.
Se o script for externo, o recurso primeiro precisa ser buscado da rede. Isso também é feito de forma síncrona, e a análise é interrompida até que o recurso seja buscado.
Esse foi o modelo por muitos anos e também é especificado nas especificações HTML4 e 5.
Os autores podem adicionar o atributo "defer" a um script. Nesse caso, ele não vai interromper a análise do documento e será executado depois que o documento for analisado. O HTML5 adiciona uma opção para marcar o script como assíncrono, para que ele seja analisado e executado por uma linha de execução diferente.
Análise especulativa
O WebKit e o Firefox fazem essa otimização. Durante a execução de scripts, outra linha de execução analisa o restante do documento e descobre quais outros recursos precisam ser carregados da rede e os carrega. Dessa forma, os recursos podem ser carregados em conexões paralelas e a velocidade geral é melhorada. Observação: o analisador especulativo só analisa referências a recursos externos, como scripts, folhas de estilo e imagens externos. Ele não modifica a árvore DOM, que é deixada para o analisador principal.
Folhas de estilo
As folhas de estilo, por outro lado, têm um modelo diferente. Conceitualmente, parece que, como as folhas de estilo não mudam a árvore DOM, não há motivo para esperar por elas e interromper a análise do documento. No entanto, há um problema com scripts que solicitam informações de estilo durante a etapa de análise do documento. Se o estilo não for carregado e analisado, o script vai receber respostas incorretas, o que aparentemente causou muitos problemas. Parece um caso extremo, mas é bastante comum. O Firefox bloqueia todos os scripts quando há uma folha de estilo que ainda está sendo carregada e analisada. O WebKit bloqueia scripts apenas quando eles tentam acessar determinadas propriedades de estilo que podem ser afetadas por folhas de estilo não carregadas.
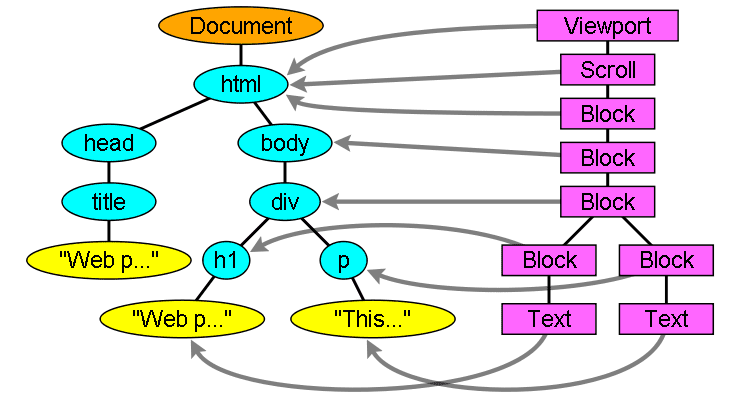
Renderização da construção da árvore
Enquanto a árvore DOM está sendo construída, o navegador constrói outra árvore, a árvore de renderização. Essa árvore é de elementos visuais na ordem em que eles serão exibidos. É a representação visual do documento. O objetivo dessa árvore é permitir a pintura do conteúdo na ordem correta.
O Firefox chama os elementos na árvore de renderização de "frames". O WebKit usa o termo renderizador ou objeto de renderização.
Um renderizador sabe como exibir e pintar a si mesmo e seus filhos.
A classe RenderObject do WebKit, a classe base dos renderizadores, tem a seguinte definição:
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
Cada renderizador representa uma área retangular que geralmente corresponde à caixa CSS de um nó, conforme descrito na especificação CSS2. Ele inclui informações geométricas como largura, altura e posição.
O tipo de caixa é afetado pelo valor "display" do atributo de estilo relevante para o nó (consulte a seção Cálculo do estilo). Este é o código do WebKit para decidir que tipo de renderizador deve ser criado para um nó DOM, de acordo com o atributo de exibição:
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
O tipo de elemento também é considerado: por exemplo, controles de formulário e tabelas têm frames especiais.
No WebKit, se um elemento quiser criar um renderizador especial, ele vai substituir o método createRenderer().
Os renderizadores apontam para objetos de estilo que contêm informações não geométricas.
A relação da árvore de renderização com a árvore do DOM
Os renderizadores correspondem a elementos DOM, mas a relação não é de um para um. Elementos DOM não visuais não serão inseridos na árvore de renderização. Um exemplo é o elemento "head". Além disso, os elementos cujo valor de exibição foi atribuído a "nenhum" não vão aparecer na árvore, enquanto os elementos com visibilidade "oculta" vão aparecer na árvore.
Existem elementos DOM que correspondem a vários objetos visuais. Geralmente, são elementos com estrutura complexa que não podem ser descritos por um único retângulo. Por exemplo, o elemento "select" tem três renderizadores: um para a área de exibição, outro para a caixa de lista suspensa e outro para o botão. Além disso, quando o texto é dividido em várias linhas porque a largura não é suficiente para uma linha, as novas linhas são adicionadas como renderizadores extras.
Outro exemplo de vários renderizadores é o HTML corrompido. De acordo com a especificação do CSS, um elemento inline precisa conter apenas elementos de bloco ou apenas elementos inline. No caso de conteúdo misto, renderizadores de blocos anônimos serão criados para agrupar os elementos inline.
Alguns objetos de renderização correspondem a um nó DOM, mas não no mesmo lugar na árvore. Os elementos flutuantes e posicionados de forma absoluta estão fora do fluxo, colocados em uma parte diferente da árvore e mapeados para o frame real. Um frame de marcador de posição é onde eles deveriam estar.
O fluxo de construção da árvore
No Firefox, a apresentação é registrada como um listener para atualizações do DOM.
A apresentação delega a criação de frames ao FrameConstructor, e o construtor resolve o estilo (consulte computação de estilo) e cria um frame.
No WebKit, o processo de resolução do estilo e criação de um renderizador é chamado de "anexo". Cada nó DOM tem um método "attach". A anexação é síncrona, a inserção de nós na árvore DOM chama o novo método "attach" do nó.
O processamento das tags html e body resulta na construção da raiz da árvore de renderização.
O objeto de renderização raiz corresponde ao que a especificação CSS chama de bloco de contenção: o bloco mais alto que contém todos os outros. As dimensões são a janela de visualização: as dimensões da área de exibição da janela do navegador.
O Firefox chama de ViewPortFrame, e o WebKit chama de RenderView.
É o objeto de renderização para o qual o documento aponta.
O restante da árvore é construído como uma inserção de nós do DOM.
Consulte a especificação CSS2 sobre o modelo de processamento.
Cálculo de estilo
A criação da árvore de renderização exige o cálculo das propriedades visuais de cada objeto de renderização. Isso é feito calculando as propriedades de estilo de cada elemento.
O estilo inclui folhas de estilo de várias origens, elementos de estilo inline e propriedades visuais no HTML (como a propriedade "bgcolor").O último é traduzido para propriedades de estilo CSS correspondentes.
As origens das folhas de estilo são as folhas de estilo padrão do navegador, as fornecidas pelo autor da página e as folhas de estilo do usuário, que são fornecidas pelo usuário do navegador (os navegadores permitem que você defina seus estilos favoritos. No Firefox, por exemplo, isso é feito colocando uma folha de estilo na pasta "Perfil do Firefox".
A computação de estilo apresenta algumas dificuldades:
- Os dados de estilo são uma construção muito grande, que contém as várias propriedades de estilo. Isso pode causar problemas de memória.
Encontrar as regras correspondentes para cada elemento pode causar problemas de desempenho se não for otimizado. Acessar toda a lista de regras para cada elemento para encontrar correspondências é uma tarefa pesada. Os seletores podem ter uma estrutura complexa que pode fazer com que o processo de correspondência comece em um caminho aparentemente promissor que se mostra fútil e outro caminho precisa ser tentado.
Por exemplo, este seletor composto:
div div div div{ ... }Significa que as regras se aplicam a um
<div>que é descendente de três divs. Suponha que você queira verificar se a regra se aplica a um determinado elemento<div>. Você escolhe um determinado caminho na árvore para verificar. Talvez seja necessário percorrer a árvore de nós para descobrir que há apenas duas divisões e que a regra não se aplica. Então, você precisa tentar outros caminhos na árvore.A aplicação das regras envolve regras em cascata bastante complexas que definem a hierarquia das regras.
Vamos conferir como os navegadores enfrentam esses problemas:
Como compartilhar dados de estilo
Os nós do WebKit fazem referência a objetos de estilo (RenderStyle). Esses objetos podem ser compartilhados por nós em algumas condições. Os nós são irmãos ou primos e:
- Os elementos precisam estar no mesmo estado do mouse (por exemplo, um não pode estar em :hover enquanto o outro não está)
- Nenhum dos elementos precisa ter um ID.
- Os nomes das tags precisam ser iguais
- Os atributos da classe precisam corresponder
- O conjunto de atributos mapeados precisa ser idêntico
- Os estados do link precisam ser iguais
- Os estados de foco precisam ser correspondentes
- Nenhum elemento deve ser afetado por seletores de atributo, em que "afetado" é definido como ter qualquer correspondência de seletor que use um seletor de atributo em qualquer posição dentro do seletor
- Não pode haver um atributo de estilo inline nos elementos.
- Não pode haver seletores irmãos em uso. O WebCore simplesmente lança uma chave global quando qualquer seletor irmão é encontrado e desativa o compartilhamento de estilo para todo o documento quando eles estão presentes. Isso inclui o seletor + e seletores como :first-child e :last-child.
Árvore de regras do Firefox
O Firefox tem duas árvores extras para facilitar a computação de estilos: a árvore de regras e a árvore de contexto de estilo. O WebKit também tem objetos de estilo, mas eles não são armazenados em uma árvore como a árvore de contexto de estilo. Apenas o nó DOM aponta para o estilo relevante.
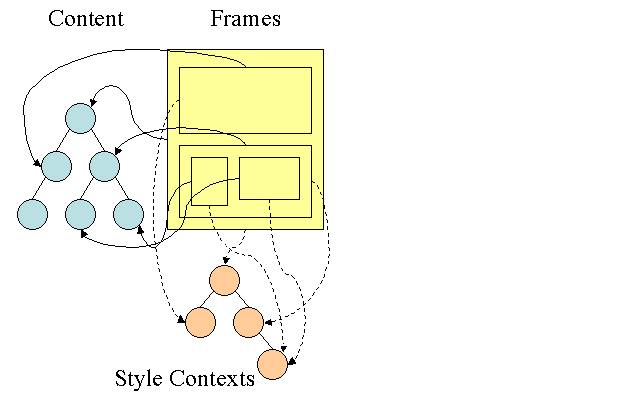
Os contextos de estilo contêm valores finais. Os valores são calculados aplicando todas as regras de correspondência na ordem correta e realizando manipulações que os transformam de valores lógicos em concretos. Por exemplo, se o valor lógico for uma porcentagem da tela, ele será calculado e transformado em unidades absolutas. A ideia da árvore de regras é muito inteligente. Ele permite o compartilhamento desses valores entre nós para evitar que sejam calculados novamente. Isso também economiza espaço.
Todas as regras correspondentes são armazenadas em uma árvore. Os nós de baixo em um caminho têm prioridade mais alta. A árvore contém todos os caminhos para as correspondências de regras encontradas. O armazenamento das regras é feito de forma lenta. A árvore não é calculada no início para todos os nós, mas sempre que um estilo de nó precisa ser computado, os caminhos computados são adicionados à árvore.
A ideia é ver os caminhos da árvore como palavras em um léxico. Digamos que já calculamos esta árvore de regras:
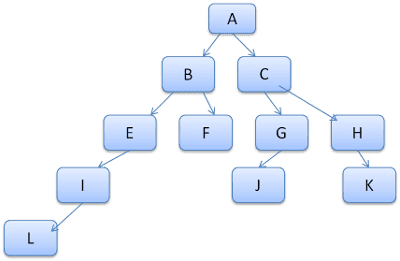
Suponha que precisamos combinar regras para outro elemento na árvore de conteúdo e descobrir que as regras correspondentes (na ordem correta) são B-E-I. Já temos esse caminho na árvore porque já calculamos o caminho A-B-E-I-L. Agora temos menos trabalho.
Vamos ver como a árvore nos ajuda a economizar trabalho.
Divisão em estruturas
Os contextos de estilo são divididos em structs. Essas estruturas contêm informações de estilo para uma determinada categoria, como borda ou cor. Todas as propriedades em um struct são herdadas ou não herdadas. As propriedades herdadas são aquelas que, a menos que sejam definidas pelo elemento, são herdadas do elemento pai. As propriedades não herdadas (chamadas de "redefinição") usam valores padrão se não forem definidas.
A árvore nos ajuda a armazenar em cache estruturas inteiras (que contêm os valores finais calculados) na árvore. A ideia é que, se o nó de baixo não fornecer uma definição para um struct, um struct armazenado em cache em um nó superior poderá ser usado.
Como calcular os contextos de estilo usando a árvore de regras
Ao calcular o contexto de estilo de um determinado elemento, primeiro calculamos um caminho na árvore de regras ou usamos um caminho existente. Em seguida, começamos a aplicar as regras no caminho para preencher as estruturas no nosso novo contexto de estilo. Começamos no nó inferior do caminho, aquele com a maior precedência (geralmente o seletor mais específico) e percorremos a árvore para cima até que a estrutura esteja completa. Se não houver uma especificação para a estrutura no nó da regra, poderemos otimizar muito. Vamos subir na árvore até encontrar um nó que a especifique totalmente e apontar para ela. Essa é a melhor otimização. A estrutura inteira é compartilhada. Isso economiza a computação de valores finais e memória.
Se encontrarmos definições parciais, vamos subir na árvore até que a estrutura seja preenchida.
Se não encontrarmos definições para nossa estrutura, e se ela for um tipo "herdado", apontamos para a estrutura do nosso pai na árvore de contexto. Nesse caso, também conseguimos compartilhar estruturas. Se for uma estrutura de redefinição, os valores padrão serão usados.
Se o nó mais específico adicionar valores, será necessário fazer alguns cálculos extras para transformá-lo em valores reais. Em seguida, armazenamos o resultado em cache no nó da árvore para que ele possa ser usado por crianças.
Caso um elemento tenha um irmão ou irmã que aponte para o mesmo nó da árvore, o contexto de estilo completo poderá ser compartilhado entre eles.
Vamos conferir um exemplo: Suponha que temos este HTML:
<html>
<body>
<div class="err" id="div1">
<p>
this is a <span class="big"> big error </span>
this is also a
<span class="big"> very big error</span> error
</p>
</div>
<div class="err" id="div2">another error</div>
</body>
</html>
E as seguintes regras:
div {margin: 5px; color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
Para simplificar, digamos que precisamos preencher apenas dois structs: o struct de cor e o struct de margem. A struct de cor contém apenas um membro: a cor. A struct de margem contém os quatro lados.
A árvore de regras resultante vai ficar assim (os nós são marcados com o nome do nó: o número da regra a que ele aponta):
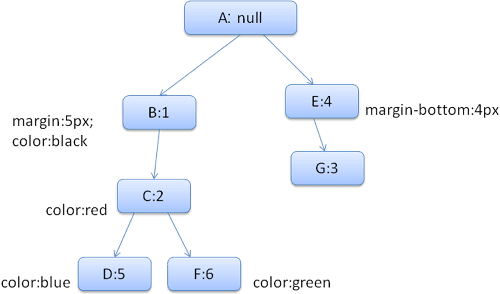
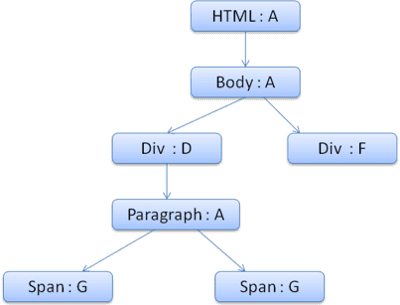
A árvore de contexto vai ficar assim (nome do nó: nó de regra a que ele aponta):
Suponha que analisemos o HTML e cheguemos à segunda tag <div>. Precisamos criar um contexto de estilo para esse nó e preencher as estruturas de estilo dele.
Vamos fazer a correspondência e descobrir que as regras correspondentes para o <div> são 1, 2 e 6.
Isso significa que já existe um caminho na árvore que nosso elemento pode usar e só precisamos adicionar outro nó a ele para a regra 6 (nó F na árvore de regras).
Vamos criar um contexto de estilo e colocá-lo na árvore de contexto. O novo contexto de estilo vai apontar para o nó F na árvore de regras.
Agora precisamos preencher as estruturas de estilo. Vamos começar preenchendo a estrutura de margem. Como o último nó da regra (F) não é adicionado à estrutura de margem, podemos subir na árvore até encontrar uma estrutura em cache calculada em uma inserção de nó anterior e usá-la. Vamos encontrá-lo no nó B, que é o nó mais alto que especificou as regras de margem.
Temos uma definição para a estrutura de cores, então não podemos usar uma estrutura em cache. Como a cor tem um atributo, não precisamos subir na árvore para preencher outros atributos. Vamos computar o valor final (converter a string em RGB etc.) e armazenar em cache a estrutura computada neste nó.
O trabalho no segundo elemento <span> é ainda mais fácil. Vamos fazer a correspondência das regras e chegar à conclusão de que ela aponta para a regra G, como o intervalo anterior.
Como temos irmãos que apontam para o mesmo nó, podemos compartilhar todo o contexto de estilo e apontar apenas para o contexto do intervalo anterior.
Para structs que contêm regras herdadas do pai, o armazenamento em cache é feito na árvore de contexto. A propriedade de cor é herdada, mas o Firefox a trata como redefinida e a armazena em cache na árvore de regras.
Por exemplo, se adicionarmos regras para fontes em um parágrafo:
p {font-family: Verdana; font size: 10px; font-weight: bold}
O elemento de parágrafo, que é filho do div na árvore de contexto, poderia ter compartilhado a mesma estrutura de fonte que o elemento pai. Isso acontece quando nenhuma regra de fonte é especificada para o parágrafo.
No WebKit, que não tem uma árvore de regras, as declarações correspondentes são percorridas quatro vezes. Primeiro, as propriedades não importantes de alta prioridade são aplicadas (propriedades que precisam ser aplicadas primeiro porque outras dependem delas, como a tela), depois as importantes de alta prioridade, depois as não importantes de prioridade normal e, por último, as importantes de prioridade normal. Isso significa que as propriedades que aparecem várias vezes serão resolvidas de acordo com a ordem correta em cascata. O último vence.
Resumindo: compartilhar os objetos de estilo (inteiros ou alguns dos structs dentro deles) resolve os problemas 1 e 3. A árvore de regras do Firefox também ajuda a aplicar as propriedades na ordem correta.
Como manipular as regras para uma correspondência fácil
Há várias fontes de regras de estilo:
- Regras CSS, em folhas de estilo externas ou em elementos de estilo.
css p {color: blue} - Atributos de estilo inline, como
html <p style="color: blue" /> - Atributos visuais HTML (mapeados para regras de estilo relevantes)
html <p bgcolor="blue" />Os dois últimos são facilmente associados ao elemento, já que ele é proprietário dos atributos de estilo e os atributos HTML podem ser mapeados usando o elemento como chave.
Como observado anteriormente na questão 2, a correspondência de regras CSS pode ser mais complicada. Para resolver a dificuldade, as regras são manipuladas para facilitar o acesso.
Depois de analisar a folha de estilo, as regras são adicionadas a um dos vários mapas de hash, de acordo com o seletor. Há mapas por ID, nome de classe, nome de tag e um mapa geral para tudo o que não se encaixa nessas categorias. Se o seletor for um ID, a regra será adicionada ao mapa de ID. Se for uma classe, será adicionada ao mapa de classes etc.
Essa manipulação facilita muito a correspondência de regras. Não é necessário procurar em todas as declarações: podemos extrair as regras relevantes de um elemento dos mapas. Essa otimização elimina mais de 95% das regras, para que elas nem precisem ser consideradas durante o processo de correspondência(4.1).
Vamos conferir as seguintes regras de estilo:
p.error {color: red}
#messageDiv {height: 50px}
div {margin: 5px}
A primeira regra será inserida no mapa de classes. O segundo no mapa de ID e o terceiro no mapa de tags.
Para o seguinte fragmento HTML:
<p class="error">an error occurred</p>
<div id=" messageDiv">this is a message</div>
Primeiro, vamos tentar encontrar regras para o elemento p. O mapa de classes vai conter uma chave "error" em que a regra para "p.error" é encontrada. O elemento div vai ter regras relevantes no mapa de ID (a chave é o ID) e no mapa de tags. Portanto, o único trabalho restante é descobrir quais das regras extraídas pelas chaves realmente correspondem.
Por exemplo, se a regra para o div fosse:
table div {margin: 5px}
Ele ainda será extraído do mapa de tags, porque a chave é o seletor mais à direita, mas não corresponde ao nosso elemento div, que não tem um ancestral de tabela.
O WebKit e o Firefox fazem essa manipulação.
Ordem de cascata da folha de estilo
O objeto de estilo tem propriedades correspondentes a cada atributo visual (todos os atributos CSS, mas mais genéricos). Se a propriedade não for definida por nenhuma das regras correspondentes, algumas propriedades poderão ser herdadas pelo objeto de estilo do elemento pai. Outras propriedades têm valores padrão.
O problema começa quando há mais de uma definição. É aí que entra a ordem em cascata para resolver o problema.
Uma declaração de propriedade de estilo pode aparecer em várias folhas de estilo e várias vezes em uma folha de estilo. Isso significa que a ordem de aplicação das regras é muito importante. Isso é chamado de ordem "em cascata". De acordo com a especificação CSS2, a ordem de cascata é (do menor para o maior):
- Declarações do navegador
- Declarações normais do usuário
- Declarações normais do autor
- Declarações importantes do autor
- Declarações importantes para o usuário
As declarações do navegador são menos importantes, e o usuário substitui o autor apenas se a declaração for marcada como importante. As declarações com a mesma ordem serão classificadas por especificidade e depois pela ordem em que foram especificadas. Os atributos visuais HTML são convertidos em declarações CSS correspondentes . Elas são tratadas como regras de autor com prioridade baixa.
Especificidade
A especificidade do seletor é definida pela especificação CSS2 da seguinte maneira:
- Conta 1 se a declaração for um atributo "style" em vez de uma regra com um seletor. Caso contrário, será 0 (= a).
- contar o número de atributos de ID no seletor (= b)
- contar o número de outros atributos e pseudoclasses no seletor (= c)
- contar o número de nomes de elementos e pseudoelementos no seletor (= d)
A concatenação dos quatro números a-b-c-d (em um sistema numérico com uma base grande) fornece a especificidade.
A base numérica que você precisa usar é definida pela contagem mais alta que você tem em uma das categorias.
Por exemplo, se a=14, você pode usar a base hexadecimal. No caso improvável de a=17, você vai precisar de uma base numérica de 17 dígitos. A situação mais recente pode acontecer com um seletor como este: html body div div p… (17 tags no seletor… não muito provável).
Alguns exemplos:
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
Como classificar as regras
Depois que as regras são correspondidas, elas são classificadas de acordo com as regras em cascata.
O WebKit usa a ordenação de bolhas para listas pequenas e a ordenação por mesclagem para listas grandes.
O WebKit implementa a ordenação substituindo o operador > para as regras:
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
Processo gradual
O WebKit usa uma flag que marca se todas as folhas de estilo de nível superior (incluindo @imports) foram carregadas. Se o estilo não for totalmente carregado ao ser anexado, marcadores de posição serão usados e ele será marcado no documento. Eles serão recalculados quando as folhas de estilo forem carregadas.
Layout
Quando o renderizador é criado e adicionado à árvore, ele não tem posição nem tamanho. O cálculo desses valores é chamado de layout ou refluxo.
O HTML usa um modelo de layout baseado em fluxo, o que significa que, na maioria das vezes, é possível calcular a geometria em uma única passagem. Elementos posteriores "no fluxo" geralmente não afetam a geometria dos elementos anteriores "no fluxo". Portanto, o layout pode ser feito da esquerda para a direita, de cima para baixo no documento. Há exceções: por exemplo, tabelas HTML podem exigir mais de uma passagem.
O sistema de coordenadas é relativo ao frame raiz. As coordenadas de cima e à esquerda são usadas.
O layout é um processo recursivo. Ele começa no renderizador raiz, que corresponde ao elemento <html> do documento HTML. O layout continua recursivamente em parte ou em toda a hierarquia de frames, calculando informações geométricas para cada renderizador que as exige.
A posição do renderizador raiz é 0,0, e as dimensões são a viewport, ou seja, a parte visível da janela do navegador.
Todos os renderizadores têm um método de "layout" ou "reflow". Cada renderizador invoca o método de layout dos filhos que precisam de layout.
Sistema de bits sujos
Para não fazer um layout completo para cada pequena mudança, os navegadores usam um sistema de "bit sujo". Um renderizador que é alterado ou adicionado marca a si mesmo e os filhos como "sujos": precisando de layout.
Há duas flags: "dirty" e "children are dirty", que significam que, embora o renderizador possa estar OK, ele tem pelo menos uma criança que precisa de um layout.
Layout global e incremental
O layout pode ser acionado em toda a árvore de renderização, que é o layout "global". Isso pode acontecer por:
- Uma mudança de estilo global que afeta todos os renderizadores, como uma mudança no tamanho da fonte.
- Como resultado do redimensionamento de uma tela
O layout pode ser incremental, apenas os renderizadores sujos serão dispostos. Isso pode causar alguns danos que exigem layouts extras.
O layout incremental é acionado (assíncronamente) quando os renderizadores estão sujos. Por exemplo, quando novos renderizadores são anexados à árvore de renderização depois que conteúdo extra veio da rede e foi adicionado à árvore DOM.
Layout assíncrono e síncrono
O layout incremental é feito de forma assíncrona. O Firefox enfileira "comandos de refluxo" para layouts incrementais, e um programador aciona a execução em lote desses comandos. O WebKit também tem um timer que executa um layout incremental. A árvore é percorrida e os renderizadores "sujos" são dispostos.
Os scripts que solicitam informações de estilo, como "offsetHeight", podem acionar o layout incremental de forma síncrona.
O layout global geralmente é acionado de forma síncrona.
Às vezes, o layout é acionado como um callback após um layout inicial porque alguns atributos, como a posição de rolagem, foram alterados.
Otimizações
Quando um layout é acionado por um "redimensionamento" ou uma mudança na posição do renderizador(e não no tamanho), os tamanhos de renderização são retirados de um cache e não são recalculados.
Em alguns casos, apenas uma subárvore é modificada e o layout não começa pela raiz. Isso pode acontecer nos casos em que a mudança é local e não afeta o ambiente, como texto inserido em campos de texto. Caso contrário, cada tecla pressionada acionaria um layout a partir da raiz.
O processo de layout
O layout geralmente tem o seguinte padrão:
- O renderizador pai determina a própria largura.
- O elemento pai passa pelos filhos e:
- Posicione o renderizador filho (define x e y).
- Chama o layout filho, se necessário, quando ele está sujo ou em um layout global ou por algum outro motivo, o que calcula a altura do filho.
- O pai usa as alturas acumuladas das crianças e as alturas das margens e do padding para definir a própria altura. Isso será usado pelo pai do renderizador pai.
- Define o bit sujo como falso.
O Firefox usa um objeto "state" (nsHTMLReflowState) como um parâmetro para layout (chamado de "reflow"). Entre outras coisas, o estado inclui a largura dos pais.
A saída do layout do Firefox é um objeto "metrics" (nsHTMLReflowMetrics). Ele vai conter a altura computada do renderizador.
Cálculo da largura
A largura do renderizador é calculada usando a largura do bloco do contêiner, a propriedade "largura" do estilo do renderizador, as margens e as bordas.
Por exemplo, a largura do seguinte div:
<div style="width: 30%"/>
Seria calculado pelo WebKit da seguinte forma(método calcWidth da classe RenderBox):
- A largura do contêiner é o máximo dos contêineres "availableWidth" e 0. O availableWidth, nesse caso, é o contentWidth, que é calculado da seguinte forma:
clientWidth() - paddingLeft() - paddingRight()
clientWidth e clientHeight representam o interior de um objeto excluindo a borda e a barra de rolagem.
A largura dos elementos é o atributo de estilo "width". Ele será calculado como um valor absoluto ao computar a porcentagem da largura do contêiner.
As bordas horizontais e os paddings foram adicionados.
Até agora, esse foi o cálculo da "largura preferencial". Agora as larguras mínima e máxima serão calculadas.
Se a largura preferencial for maior que a largura máxima, a largura máxima será usada. Se for menor que a largura mínima (a menor unidade inquebrável), a largura mínima será usada.
Os valores são armazenados em cache caso um layout seja necessário, mas a largura não mude.
Quebra de linha
Quando um renderizador no meio de um layout decide que precisa ser interrompido, ele para e propaga para o pai do layout que precisa ser interrompido. O elemento pai cria os renderizadores extras e chama o layout neles.
Pintura
Na fase de pintura, a árvore de renderização é percorrida e o método "paint()" do renderizador é chamado para exibir o conteúdo na tela. A pintura usa o componente de infraestrutura da interface.
Global e incremental
Assim como o layout, a pintura também pode ser global, ou seja, a árvore inteira é pintada, ou incremental. Na pintura incremental, alguns dos renderizadores mudam de uma maneira que não afeta toda a árvore. O renderizador alterado invalida o retângulo na tela. Isso faz com que o SO a veja como uma "região suja" e gere um evento de "pintura". O SO faz isso de forma inteligente e combina várias regiões em uma. No Chrome, é mais complicado porque o renderizador está em um processo diferente do principal. O Chrome simula o comportamento do SO até certo ponto. A apresentação detecta esses eventos e delega a mensagem à raiz de renderização. A árvore é percorrida até que o renderizador relevante seja alcançado. Ele vai ser repintado (e geralmente os filhos dele).
Ordem da pintura
O CSS2 define a ordem do processo de pintura. Essa é a ordem em que os elementos são empilhados nos contextos de empilhamento. Essa ordem afeta a pintura, já que as pilhas são pintadas da parte de trás para a parte da frente. A ordem de empilhamento de um renderizador de bloco é:
- cor do plano de fundo
- imagem de plano de fundo
- border
- crianças
- outline
Lista de exibição do Firefox
O Firefox analisa a árvore de renderização e cria uma lista de exibição para o retângulo pintado. Ele contém os renderizadores relevantes para o retangular, na ordem de pintura correta (planos de fundo dos renderizadores, bordas etc.).
Dessa forma, a árvore precisa ser percorrida apenas uma vez para uma repintura, em vez de várias vezes, pintando todos os planos de fundo, depois todas as imagens, depois todas as bordas etc.
O Firefox otimiza o processo não adicionando elementos que serão ocultos, como elementos completamente abaixo de outros elementos opacos.
Armazenamento de retângulos do WebKit
Antes de repintar, o WebKit salva o retângulo antigo como um bitmap. Em seguida, ele pinta apenas a diferença entre os retângulos novos e antigos.
Mudanças dinâmicas
Os navegadores tentam fazer o mínimo possível de ações em resposta a uma mudança. Assim, as mudanças na cor de um elemento vão causar apenas a repintura dele. As mudanças na posição do elemento vão causar o layout e a pintura do elemento, dos filhos dele e possivelmente dos irmãos. Adicionar um nó DOM vai causar o layout e a repintura do nó. Mudanças importantes, como aumentar o tamanho da fonte do elemento "html", invalidam os caches, redimensionam e repintam toda a árvore.
As linhas de execução do mecanismo de renderização
O mecanismo de renderização tem uma única linha de execução. Quase tudo, exceto operações de rede, acontece em uma única linha de execução. No Firefox e no Safari, essa é a linha de execução principal do navegador. No Chrome, é a linha de execução principal do processo da guia.
As operações de rede podem ser realizadas por várias linhas de execução paralelas. O número de conexões paralelas é limitado (geralmente de 2 a 6 conexões).
Loop de eventos
A linha de execução principal do navegador é um loop de eventos. É um loop infinito que mantém o processo ativo. Ele aguarda eventos (como eventos de layout e pintura) e os processa. Este é o código do Firefox para a repetição de eventos principal:
while (!mExiting)
NS_ProcessNextEvent(thread);
Modelo visual CSS2
A tela
De acordo com a especificação CSS2, o termo "canvas" descreve "o espaço em que a estrutura de formatação é renderizada": onde o navegador pinta o conteúdo.
A tela é infinita para cada dimensão do espaço, mas os navegadores escolhem uma largura inicial com base nas dimensões da janela de visualização.
De acordo com www.w3.org/TR/CSS2/zindex.html, a tela é transparente se contida em outra e recebe uma cor definida pelo navegador se não for.
Modelo de caixa CSS
O modelo de caixa do CSS descreve as caixas retangulares geradas para elementos na árvore de documentos e dispostas de acordo com o modelo de formatação visual.
Cada caixa tem uma área de conteúdo (por exemplo, texto, imagem etc.) e áreas opcionais de padding, borda e margem.
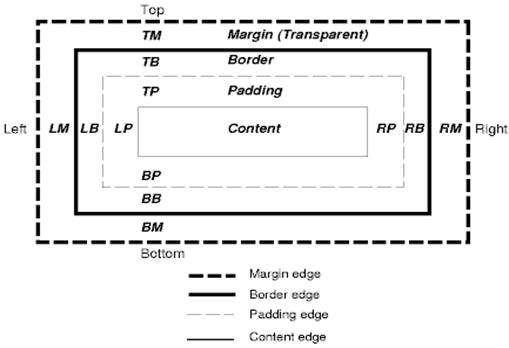
Cada nó gera de 0 a n caixas.
Todos os elementos têm uma propriedade "display" que determina o tipo de caixa que será gerado.
Exemplos:
block: generates a block box.
inline: generates one or more inline boxes.
none: no box is generated.
O padrão é inline, mas a folha de estilo do navegador pode definir outros padrões. Por exemplo, a exibição padrão do elemento "div" é bloco.
Confira um exemplo de folha de estilo padrão aqui: www.w3.org/TR/CSS2/sample.html.
Esquema de posicionamento
Há três esquemas:
- Normal: o objeto é posicionado de acordo com o lugar dele no documento. Isso significa que o lugar dele na árvore de renderização é semelhante ao lugar dele na árvore DOM e é organizado de acordo com o tipo de caixa e as dimensões.
- Flutuante: o objeto é primeiro disposto como um fluxo normal e depois movido o máximo possível para a esquerda ou direita.
- Absoluto: o objeto é colocado na árvore de renderização em um lugar diferente da árvore DOM
O esquema de posicionamento é definido pela propriedade "position" e pelo atributo "float".
- estática e relativa causam um fluxo normal
- absoluto e fixo causam posicionamento absoluto
No posicionamento estático, nenhuma posição é definida, e o posicionamento padrão é usado. Nos outros esquemas, o autor especifica a posição: superior, inferior, esquerda, direita.
A forma como a caixa é disposta é determinada por:
- Tipo de caixa
- Dimensões da caixa
- Esquema de posicionamento
- Informações externas, como o tamanho da imagem e da tela
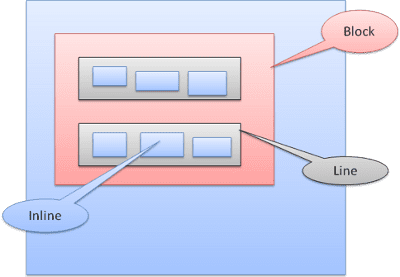
Tipos de Box
Caixa de bloco: forma um bloco e tem um retângulo próprio na janela do navegador.

Caixa inline: não tem um bloco próprio, mas está dentro de um bloco que contém.
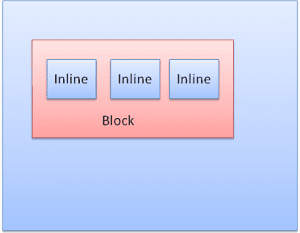
Os blocos são formatados verticalmente, um após o outro. Os elementos inline são formatados horizontalmente.
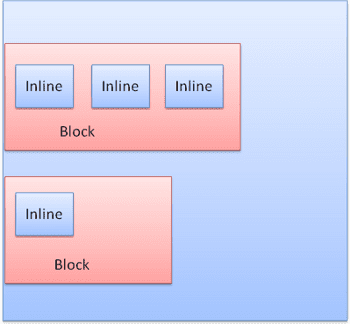
Os boxes inline são colocados dentro de linhas ou "boxes de linha". As linhas têm pelo menos a altura da caixa mais alta, mas podem ser mais altas quando as caixas estão alinhadas à "linha de base", ou seja, quando a parte de baixo de um elemento está alinhada a um ponto de outra caixa que não é a de baixo. Se a largura do contêiner não for suficiente, os inlines serão colocados em várias linhas. Isso geralmente acontece em um parágrafo.
Posicionamento
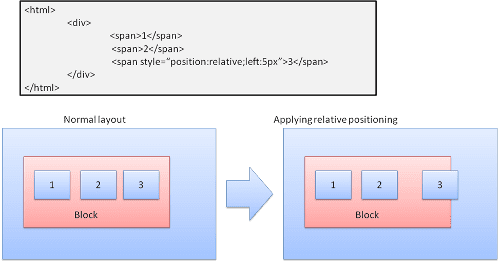
Relativo
Posicionamento relativo: posicionado como de costume e depois movido pelo delta necessário.
Variações
Uma caixa flutuante é deslocada para a esquerda ou direita de uma linha. O recurso interessante é que as outras caixas fluem em torno dele. O HTML:
<p>
<img style="float: right" src="images/image.gif" width="100" height="100">
Lorem ipsum dolor sit amet, consectetuer...
</p>
Vai ficar assim:

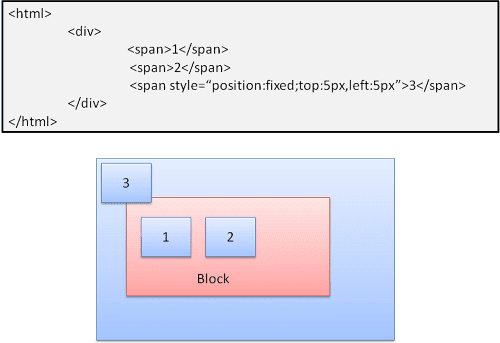
Absoluto e fixo
O layout é definido exatamente, independentemente do fluxo normal. O elemento não participa do fluxo normal. As dimensões são relativas ao contêiner. Em "fixo", o contêiner é a janela de visualização.
Representação em camadas
Isso é especificado pela propriedade CSS z-index. Ele representa a terceira dimensão da caixa: a posição dela ao longo do "eixo z".
As caixas são divididas em pilhas (chamadas de contextos de empilhamento). Em cada pilha, os elementos de volta são pintados primeiro, e os elementos de avanço ficam na parte de cima, mais perto do usuário. Em caso de sobreposição, o elemento principal vai ocultar o elemento anterior.
As pilhas são ordenadas de acordo com a propriedade z-index. Caixas com a propriedade "z-index" formam uma pilha local. A viewport tem a pilha externa.
Exemplo:
<style type="text/css">
div {
position: absolute;
left: 2in;
top: 2in;
}
</style>
<p>
<div
style="z-index: 3;background-color:red; width: 1in; height: 1in; ">
</div>
<div
style="z-index: 1;background-color:green;width: 2in; height: 2in;">
</div>
</p>
O resultado será este:

Embora o div vermelho preceda o verde na marcação e fosse pintado antes no fluxo normal, a propriedade z-index é mais alta, então ele está mais à frente na pilha mantida pela caixa raiz.
Recursos
Arquitetura do navegador
- Grosskurth, Alan. A Reference Architecture for Web Browsers (pdf)
- Gupta, Vineet. Como os navegadores funcionam: Parte 1 - Arquitetura
Análise
- Aho, Sethi, Ullman, Compilers: Principles, Techniques, and Tools (também conhecido como "Livro do Dragão"), Addison-Wesley, 1986
- Rick Jelliffe. The Bold and the Beautiful: dois novos rascunhos para HTML 5.
Firefox
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers.
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers (Google tech talk video)
- L. David Baron, Layout Engine da Mozilla
- L. David Baron, Mozilla Style System Documentation
- Chris Waterson, Notes on HTML Reflow (em inglês)
- Chris Waterson, Visão geral do Gecko
- Alexander Larsson, A vida de uma solicitação HTTP HTML
WebKit
- David Hyatt, Implementing CSS(part 1)
- David Hyatt, Uma visão geral do WebCore
- David Hyatt, WebCore Rendering
- David Hyatt, The FOUC Problem (em inglês)
Especificações do W3C
Instruções de build de navegadores
Traduções
Esta página foi traduzida para o japonês duas vezes:
- Como os navegadores funcionam: os bastidores dos navegadores modernos da Web (ja) por @kosei
- ブラウザってどうやって動いてる?(モダンWEBブラウザシーンの裏側 de @ikeike443 e @kiyoto01.
Confira as traduções hospedadas externamente em coreano e turco.
Agradecemos a todos!